
Some time ago I wrote an article about how to treat groups of associated, related properties of a Real World Object [“RWO”] when representing it by an object [“PWO”] in PHP.
We assumed that the property description of a certain object class is done with the help of a so called “SCHEMA” (a file with a list of definitions and rules or Schema program using definitions saved in a database Schema table). A SCHEMA is specific for a PWO class. A SCHEMA defines object relations, object properties, the relations between certain object properties, the relation of object properties with database fields and of course the type of each property, the property’s own properties as well as associated constraints. Such “SCHEMATA” would play a central role in a web application as they encapsulate vital structural and detail information about objects and their properties.
Every object constructors would refer to an appropriate SCHEMA, as well as web generators for the creation e.g. of form or web template elements would do. Actually, any reasonable (web) application would of course work with multiple SCHEMATA – each for a different object class. SCHEMATA give us a flexible mode to change or adapt a classes properties and relations. They also close the gap between the OO definitions and a relational database.
To handle groups of associated properties in such an environment I suggested the following:
- Split the SCHEMA-information for properties and related database fields into several “SLAVE-Schemata” which would be built as sub objects within the MAIN SCHEMA object. Each SCHEMA would describe a certain group of closely associated object properties.
- Create and use “SLAVE PWO SGL objects” as encapsulated sub-objects in a MAIN SGL PWO. Each SLAVE PWO object gets it’s own properties defined in a related SLAVE-SCHEMA.
- Each of the SLAVE PWO objects receives it’s knowledge about it’s individual SLAVE-SCHEMA by an injection process during construction.
See:
PHP/OO/Schemata: Decouple property groups by combined composite patterns
Each PWO object, representing a single RWO we shall call a SGL PWO. It comprises a series of sub-objects: SLAVE SGL PWOs that refer to corresponding SLAVE Schemata of a MAIN Schema. See the illustration from the article named above:
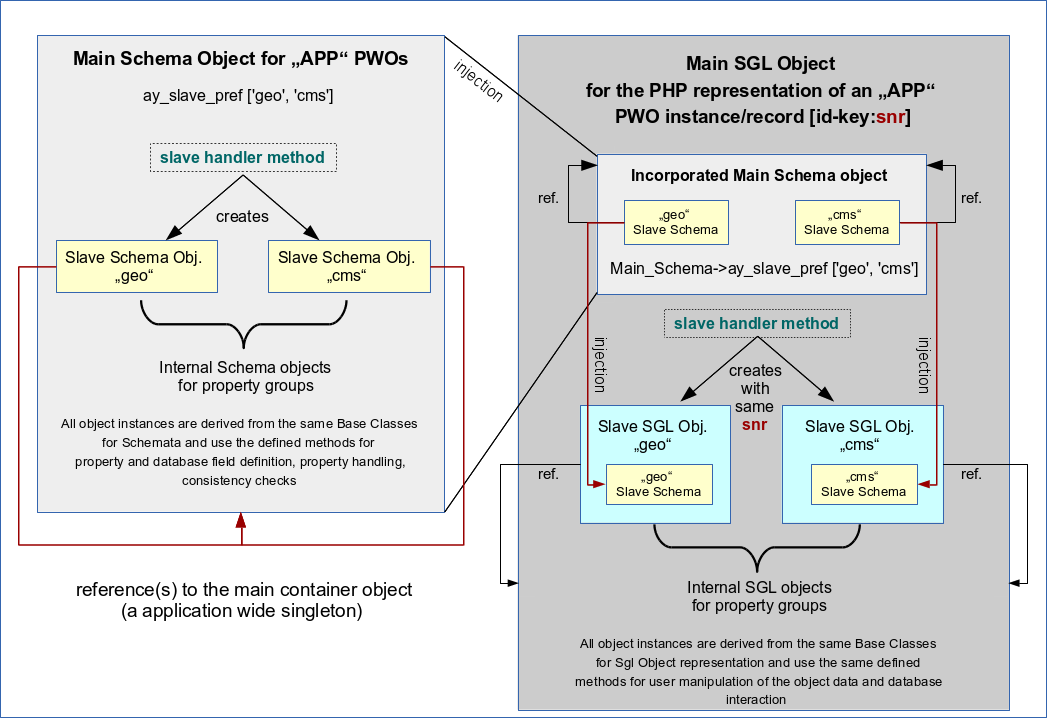
In the named article I had discussed that one can iterate methods for complete database interactions over the MAIN and the SLAVE objects. The same is true for interactions with POST or SESSION data in a CMS like web application. So, there is no need to rewrite core method code originally written for objects which comprise all object properties in just one property/field-SCHEMA without any SLAVE objects. At least with respect to field checks and database interactions.
This works if and when a SGL object is derived from a base class which comprises all required methods to deal with the database, POST and SESSION data. Each MAIN or SLAVE SGL PWO knows itself how to store/fetch it’s property data into/from database tables (or $_POST or $_SESSION arrays) and uses the same methods inherited from common SGL base classes (= parent classes) to do so.
I have meanwhile introduced and realized this SLAVE PWO and SLAVE SCHEMA approach in a quite general form in my web application framework. In this article I briefly want to discuss some unexpected consequences for HTML
generator methods in a web or CMS context.
(X)HTML-Generator methods – where to place them ?
When you design CMS like web applications you always have to deal with Template [TPL] structures and objects that fill the templates with reasonable formatted contents. The contents may be just text or images or links inserted into template placeholders. In more complicated cases (like e.g. the generation of maintenance masks with forms), however, you may have to generate complete HTML fragments which depend on property/field information given in your respective SCHEMA.
A basic design question is: Where do we place the generator methods? Should the SGL PWOs know how to generate their property contents or should rather a “Template Control Object” – a “TCO” – know what to do? I have always preferred the second approach. Reason:
TPL aspects may become very specific, so the methods may need to know something about the TPL structures – and this is nothing that I want to incorporate into the OO representation [PWO] of real world objects.
Over time I have developed a bunch of generator methods for all kind of funny things required in customer projects. The methods are defined in base classes for Template Control Objects and or special purpose sub classes injected into TCOs. A TCO knows about its type of TPL and works accordingly. (By the way: With Pear ITX or Smarty you can realize a complete separation of (X)HTML-code and the PHP code).
(X)HTML-Generator methods – which MAIN or SLAVE PWO and which MAIN/SLAVE SCHEMA are we dealing with ?
In addition to some property/field identifiers a (X)HTML generator method has of course to know what SGL PWO and what SCHEMA it has to work with. This information can be fetched either by the TCO due to some rules or can be directly injected into the methods.
In the past I wanted to keep interfaces lean. In many applications the SGL PWO object was a classical singleton. So, it could relatively easily be received or identified by the central TCO. I did not see any reason to clutter TCO method interfaces with object references that were already known to their TCO object. So, my generator methods referred and used the SGL PWO object and it’s SCHEMA by invoking it with the “$this”-operator:
function someTCOgenerator_method() {
…..
do something with $this->SGL and $this->Schema
….
}
However, in the light of a more general approach this appears to be a too simplistic idea.
If we regard a SLAVE SGL object as a relatively compact entity inside a PWO – as a SLAVE object with its own property and field information SCHEMA – than we see: for a generator method it behaves almost like an independent object different from the MAIN PWO. This situation is comparable to one where the generator method really would be requested to operate on instances a completely different PWO class:
A HTML generator method needs to know the qualities of certain OO properties and associated database field definitions. In our approach with MAIN SGL PWOs comprising composite SLAVE SGL PWO objects each SGL object knows exactly about its associated MAIN or SLAVE Schema object. To work correctly the generator method must get access to this specific SCHEMA. This would in a reasonable application design also be valid for PWO objects representing other, i.e. different types of RWOs.
A (X)HTML generator method can work properly as soon as it knows about
- the SGL object,
- the object property (identified by some name, index or other unique information) to operate on and generate HTML code for,
- the SCHEMA describing the qualities of the object property and related database fields.
This would in
our approach also be given for our SLAVE SGL objects or any PWO as soon as we inject it into our generator method.
Therefore, (X)HTML generator methods of TCOs should be programmed according to the following rules:
- Do not assume that there is only one defined class of PWO SGL objects that the Template Control Object TCO needs to know about and needs to apply it’s generator methods to.
- Instead enable the (X)HTML generator methods of a TCO to be able to work with any kind of PWO and its properties – as long as the PWO provides the appropriate SCHEMA information.
- Inject the SGL [SLAVE] PWO and thereby also its associated [SLAVE] SCHEMA into each TCO generator method:
function someTCOgenerator_method($SGL_ext, …..). - Do not refer to the TCO’s knowledge about a SGL PWO by using the “$this” operator (like “$this->Sgl”) inside a generator method of a TCO; refer all generator action to a local $SGL object reference that points to the injected (!) object $SGL_ext:
$SGL = $SGL_ext.
Also refer to a local $Schema which points to the $SGL->Schema of the injected $SGL object:
$Schema = $Sgl->Schema.
(Remember: Objects are transferred by reference !)
These recipes give us the aspired flexibility to deal with properties both of SLAVE objects and objects of a different PWO class.
The injection is a small but structurally important difference in comparison to the database interaction methods directly incorporated in SGL objects or better their base classes. Here the TCO (!) method must receive the required information – and we gain flexibility when we inject the SGL object into it (plus information identifying the property for which a HTML fragment has to be generated for).
Had I respected the rules above already some time ago it would have saved me much time now. Now, I had to adapt the interfaces of many of my generator methods in my TCO base classes.
Again, I found one experience confirmed:
- In case of doubt do not hesitate to use loose object coupling via injection on general methods which could in principle be applied to more and other objects than the ones the object containing the method knows about at the time of your class design.
- Use injection even if it may look strange when you need to do something like
$this->someTCOgenerator_method($this->KnownObject);
i.e., when you inject something the present object containing the method knows about already.
It will save time afterwards when iterator patterns over other objects have to be used and when you may access the (public) method from outside, too.
Iteration over SLAVE objects
Now, if our (X)HTML-generator methods are prepared for injection of SGL PWO objects, we have no more difficulties to generate HTML fragments required in templates for selected properties of MAIN and SLAVE PWO SGL objects:
We just have to iterate the usage of the generator method for the properties/fields of the MAIN SGL PWO as well as its SLAVE SGL PWOs. By getting the SGL object injected the method also knows about the right SCHEMA to use and provide required detail information for the generation of related HTML code (e.g. for a form element).
Think about a situation in which we want to provide a form with input fields which a user can use to update data for all properties of a certain PWO. We just have to apply generator methods to create the required input field types according to the appropriate SCHEMA informations. For this
- we loop (iterate) over the MAIN and all it’s SLAVE objects,
- identify all properties according to the MAIN or SLAVE SCHEMA
information - and apply the generator method by injecting the relevant property identifier plus the MAIN/SLAVE-SGL object in question.
Mission accomplished.
The principle of iteration over SLAVE objects is actually nothing new to us: We used it already when dealing with the database interaction methods. (It is a basic ingredient of a composite pattern).
If we only want to work on selected properties then we need to know which of the properties is located in which SLAVE PWO and described in which SLAVE SCHEMA. To be able to do so, we should create and use an array
- that collects information about which PWO property belongs to which of the PWOs SLAVE objects
- and which is filled in course of the construction process of a PWO.
Conclusion
When realizing a composite pattern in the form of SLAVE objects (with SLAVE Schemata) to deal with closely associated property groups of complex objects you can apply existing base class methods and iterate over the SLAVE objects to accomplish complete transactions affecting all properties of a structured PWO. This principle can be extended to (X)HTML generator methods of Template Control Objects, if these methods are prepared to receive the SLAVE SGL PWO objects by injection. If we only want to apply generator methods on a bunch of selected properties, we should use an array associating each PWO property with a SLAVE PWO SGL object.