
Bei meinen aktuellen Systemumzügen auf Opensuse 13.2 bekam ich erneut ein Problemchen mit SVN. Diesmal von Eclipse aus. Aber die Schuld für das Problem kann ich keineswegs SuSE anlasten, sondern nur Konsequenzen aus meinem eigenen Tun. Die Ursache meiner Schwierigkeiten war zwar eine triviale – aber vielleicht lernt ja auch der eine oder andere Leser was von meinem Fehler.
Voraussetzungen
Voraussetzung 1 – lokale Repositories, Zugriff über einen lokalen SVN-Server
Auf einem Entwicklungssystem unter OS 13.1 hatte ich aus Performancegründen irgendwann mal den Zugriff auf neu angelegte lokale SVN-Repositories von einfachem File-Zugriff (file://) auf Zugriff über das native SVN-Protokoll (svn:// bzw. svn+ssh://) umgestellt. Zu den verschiedenen Zugriffsverfahren (unter Eclipse) siehe:
https://eclipse.org/subversive/documentation/gettingStarted/aboutSubversive/protocols.php
Ermöglicht wurde die Umstellung durch Einrichtung eines lokalen SVN-Servers mit entsprechender Konfiguration der Zugriffsrechte im “conf”-Unterverzeichnis des neuen Repository-Verzeichnisses.
Nun wird natürlich die Frage kommen: Warum arbeitet der Typ in seinem Netzwerk mit einem lokalen Repository? Noch dazu mit einem lokalen Server?
Antwort 1: Ich arbeite nur partiell mit einem lokalen Repository. Es gibt Release-Branches, deren Dateien auf ein weiteres Projekt verlinkt sind. Der SVN-External Mechanismus sorgt dann dafür, dass mit Hilfe des anderen Projektes Submits in ein zentrales Repository (im eigenen Netzwerk oder auf Servern im Internet) vorgenommen werden können. So kann ich in Kooperation mit meinem lokalen Repository meine eigenen Entwicklungsschritte in schnellen Zyklen vorantreiben. Das Mergen in ein Release-Repository erfolgt dann nach Absprache über den (verlinken) Branch und das zweite Projekt. Das geht immer dann besonders gut und einfach, wenn die Zuständigkeiten für bestimmte Codebereiche und auch Klassen klar getrennt sind. Ein solches Branching ist für sich schon interessant; dieser Artikel fokussiert aber auf ein bestimmtes Probleme des Zugriffs auf lokale Repositories der Entwicklungsmaschine und eben nicht auf zentral verwaltete Repositories.
Antwort 2: Geschwindigkeit und Flexibilität. Der Zugriff über einen lokalen Server ist unter Eclipse bei umfassenden CheckIns z.T. deutlich schneller als der File-basierte Zugriff (zumindest auf hinreichend leistungsstarken Multiprozessor-Maschinen). Flexibilität: Ist ein SVN-Server erstmal vorhanden, kann er bei Bedarf auch anderen Usern im Netz (oder auf virtuellen Maschinen derselben Workstation) zur Verfügung gestellt werden.
Voraussetzung 2:
Meine gesamten Entwicklungsdateien, SVN-Repositories, Domainverzeichnisse für lokale Webserver liegen auf meinen Entwicklungssystemen auf speziellen, von den Betriebssystem-Partitionen unabhängigen Partitionen – sie seien nachfolgend “Entwicklungspartitionen” genant. Dies gibt mir bei Bedarf die Möglichkeit, von verschiedenen Systeminstallationen aus (z.B. Debian, OS 13.1 oder eben einem mal testweise installierten OS 13.2), die auf anderen Partitionen der Workstation liegen, in ähnlicher auf diese Entwicklungsdateien zuzugreifen. Dazu werden die Entwicklungspartitionen auf Standardverzeichnis-Pfade im jeweils gestarteten Betriebssystem gemountet. Das ganze erleichtert z.B. Test der Tauglichkeit neuer Distributions-Versionen oder einen systematischen stufenweisen Umzug zu einer neu installierten Distribution.
Man beachte, dass diese Möglichkeit zum wechselseitigen Arbeiten am gleichen Eclipse-Projekt von verschiedenen Systemen aus sehr ähnlich ist zum wechselseitigen Arbeiten am gleichen
Projekt auf 2 getrennten Computern, deren Entwicklungsinhalte z.B. über “unison/rsync” systematisch synchronisiert werden. Ich selbst synchronisiere meine sämtlichen projektbezogenen Entwicklungsverzeichnisse, SVN-Verzeichnisse, zugehörige Domaindateien eines lokalen Apache-Testservers (und auch Eclipse selbst) oft zwischen meiner Workstation und einem Laptop, wenn ich mich auf eine längere Reise begeben muss.
Die nachfolgend dargestellte Problematik lässt sich also auf das wechselseitige Fortführen der Eclipse-Entwicklungsarbeit an zwei laufend synchronisierten Systemen direkt übertragen. Wir erfassen somit über das nachfolgend geschilderte Problem zwei unterschiedliche Zugriffssituationen:
- Den (sequentiellen) wechselnden Zugriff von 2 Betriebssysteminstallationen auf ein und derselben Workstation aus auf ein und dasselbe Repository auf einer separaten Partition. Das geht im Normalfall natürlich nur über Reboots; zu einer Zeit ist genau ein Betriebssystem aktiv, unter dem dann die Partition mit den Repositories gemountet wird. [Ich habe in der täglichen Praxis aber natürlich durchaus auch Situationen mit parallel gestarteten virtuellen Maschinen auf ein und derselben Workstation. Das entspricht dann aber eher der künstlich geschaffenen Situation des parallelen Arbeitens zweier Entwickler auf dem gleichen Repository; diese Situation erfordert aber eigentlich fast zwingend die Einrichtung eines zentralen SVN-Servers auf irgendeiner der gestarteten Maschinen-Instanzen. Ich betrachte den Sonderfall mehrerer gestarteter virtueller Maschinen (auf einer Workstation), die ggf. und idiotischerweise dieselbe Partition mit SVN-Repository mounten, nicht weiter.]
- von je einem Betriebssystem auf 2 unterschiedlichen Computern aus auf jeweils lokale Repositories, die aber systematisch und regelmäßig zwischen den Maschinen synchronisiert werden.
Das aufgetretene Problem
Auf der erwähnten Entwicklungs-Workstation habe ich Opensuse 13.2 (in einer separaten Partition) neu neben einem laufenden und benutzten Opensuse 13.1 installiert. Ich habe unter Opensuse 13.2 natürlich die gleichen Entwickler-User eingerichtet (identische UID, GID) wie unter OS 13.1.
Nun wollte ich bestimmte Verzeichnisse, die SVN-Repositories enthalten, eben von einer dritten (“Entwicklungs-“) Partition mounten und dann von einem bereits umgezogenen Eclipse über dessen SVN-Connectoren in gewohnter Weise auf die Repositories zugreifen.
Da ich die aktuellen Eclipse-Einstellungen unter OS 13.1 nach OS13.2 übernommen hatte, musste dafür auf dem OS13.2-System auch ein lokaler SVN-Server laufen. (Zumindest für die Repositories, auf die der Zugriff über den SVN-Server eingestellt war). Die nachfolgende Skizze verdeutlicht die Situation:
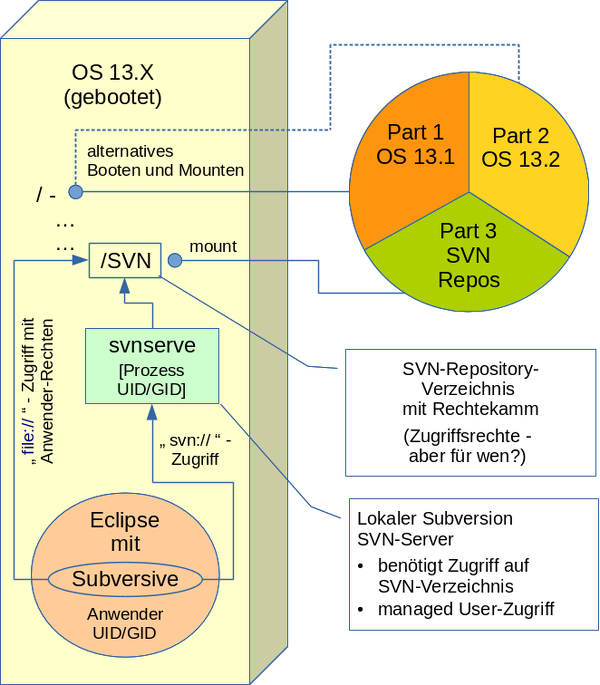
Nachdem ich den SVN-Server-Prozess (svnserve) endlich mit Hilfe einer selbst erzeugten sysconfig-Datei für “svnserve” [s. https://linux-blog.anracom.com/2015/01/16/opensuse-13-2-subversion-sysconfig-file-svnserve-fehlt/ unter OS 13.2 zum Laufen gebracht hatte, schlug allerdings der Zugriff von Eclipse aus (unter OS 13.2) fehl :
svn: E204900: Can’t open file …… txn-current-lock’: Permission denied
Zunächst dachte ich aufgrund einer oberflächlichen Interpretation der Fehlermeldung, dass der unter Eclipse angegebene User (unter OS13.2) nicht zu den Einstellungen im “conf”-Unterverzeichnis des von mir angesprochenen Repository-
Verzeichnisses passen würde. Oder das Password sei falsch, oder … Also stellte ich die Zugriffserlaubnis in der “authz”-Datei des Repositories mal testweise so um, dass jedermann “rw”-Zugriff auf das Repository haben konnte. Das änderte an der obigen Fehlermeldung des Eclipse-Connectors jedoch gar nichts.
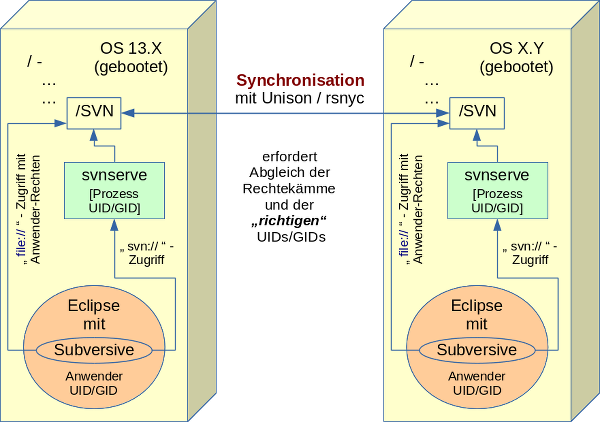
Ein ganz analoges Problem kann sich
- nach einem rsync-Abgleich der Repository-Verzeichnisse mit einem anderen Computersystem
- und dem anschließenden Versuch, auf dem 2-ten System auf das Repository, zuzugreifen,
ergeben. Siehe die nachfolgende Skizze.
Problem-Ursache
Kein Problem bei SVN-Filezugriff
Solange man unter Eclipse lokal auf einem Entwicklungssystem z.B. über das Subversion-Plugin lediglich einen File-Zugriff auf die angelegten lokalen SVN-Repositories festgelegt hat, bereiten Systemumzüge oder auch maschinenübergreifende Synchronisierungsverfahren z.B. mit “unison/rsync” selten Probleme – es genügt dann, die User Accounts der Entwickler mit identischen UIDs, GIDs im neu installierten oder dem zu synchronisierenden System anzulegen. Haben die betroffenen User auf beiden Systemen hinreichende Zugriffsrechte auf die Repository-Verzeichnisse und -Files, so funktioniert nach einem Umzug bzw. nach einer Synchronisation beim Zugriff auf das alte bzw. das synchronisierte Repository alles wie gewohnt. Legt man die Repositories über Eclipse selbst an, so sorgt das SVN-Plugin (bei file-Zugriff) bereits für die korrekte Rechtevergabe. (Bei Synchronisationsverfahren müssen lediglcih die Zugriffsberechtigungen lediglich 1:1 übertragen werden und dieselben Entwickler-UIDs auf beiden Systemen vorhanden sein).
Zugriff und Zugriffserfordernisse über lokalen SVN-Server und das svn-Protokoll
Läuft jedoch lokal (oder auf einem Synchronisationssystem) ein SVN-Server und soll Eclipse über ihn auf (einigen) Repositories operieren, so muss natürlich der lokale SVN-Server-Prozess selbst lesend und/oder schreibend auf die Repository-Verzeichnisse, deren Konfigurationsdateien sowie die Datenbankfiles des Repositories zugreifen können. (Bei einem reinen File-Zugriff genügen dagegen – wie gesagt – die Rechte des Users). Auf einem Server sind daher alle Repository-Verzeichnisse normalerweise dem svn-Systemuser und seiner Gruppe zugeordnet (und natürlich nicht irgendwelchen Entwicklern – der Entwicklerzugriff wird vielmehr nicht auf Filesystem-Ebene sondern über Rechtesetzungen in den “conf”-Dateien der Repositories geregelt).
Leider hatte ich bei der Installation des OS 13.2-Systems aber die Vergabe von UIDs und GIDs an System Accounts nicht hinreichend beachtet (oft bleibt SuSE ja bei Standard System-Usern – soweit möglich – bei den gleichen UIDs). Meine Nachlässigkeit rächte sich. Was war geschehen?
Auf der ursprünglich unter OS 13.1 genutzten Partition waren natürlich die Verzeichnisse und Dateien des SVN-Repositories unter dem dortigen SVN-Server mit Zugriffsrechten für den dortigen User “svn” und die dortige Gruppe “svn” angelegt worden. Aber wer sagt denn, dass in einem separat und neu installierten OS13.2-System der “svn”-Account bzw. die svn-Gruppe die gleich UID bzw. GID wie auf meinem alten OS13.1-System erhält? Niemand ! Ein kurzer Check zeigte:
Die zu dem svn-User bzw. der svn-Gruppe gehörigen UID.GID waren auf meiner 13.1-Installation (die eine längere Upgrade-Geschichte hinter sich hat) “482.480” – unter der frischen OS13.2-Installation jedoch “483.482”.
Das letztendliche Zugriffsrecht des “svnserve”-Prozesses richtet sich jedoch nicht nach dem svn-User/Gruppen-Namen sondern natürlich nach dessen UID/GID. Auf der gemeinsam zu nutzenden Partition war der Rechtekamm zur Erzeugungszeit der Repositories selbtsverständlich auf die alte UID/GID-Kombination des svn-Users bzw. der svn-Gruppe ausgelegt worden. Mounted man die Partition dann unter OS 13.2 ist der Zugriff des dortigen svnserve-Prozesses nicht möglich.
Lösungsansätze
Aus dieser Analyse ergaben sich mehrere Lösungsansätze, unter denen man ein wechselseitiges Arbeiten auf dem Entwicklungssystem mal unter OS13.1, mal unter OS13.2 auf demselben Repository einer unabhängigen, jeweils gemounteten Partition erreichen konnte :
- Methode 1: Man geht auf beiden Systemen unter Eclipse/Subversive zurück zum reinen File-Zugriffsverfahren mit anschließender Anpassung der User-Rechte an den Repository-Verzeichnissen/-Dateien. Hierbei kommt dann lediglich die (hoffentlich übereinstimmende) UID/GID des Entwicklers bzw. der Entwicklergruppe zum Tragen.
- Methode 2: Abgleich der UID/GIDs für die “svn”-Accounts auf beiden Systemen – so dass man danach von beiden Systemen aus auch arbeiten kann. Das ist allerdings leichter gesagt als getan: So kann die im alten System benutze UID/GID auf dem neuen System bereits belegt sein. Geht man hingegen in beiden Systemen auf eine neutrale, unbelegte UID/GID, so muss man auf beiden Systemen für die jeweils vorhandenen UID/GIDs alle Dateien suchen lassen, bei denen diese UID/GIDs im Rechtekamm auftauchen und die Rechtekämme danach entsprechend abändern. Das ist zwar befehlstechnisch einfach zu realiseren, kann jedoch aufgrund der Menge der betroffenen Dateien zu einem Problem werden. Hierfür schreibt man sich deshalb am besten ein kleines Script.
- Methode 3: Anlage einer neuen, neutralen Gruppe mit identischer GID auf beiden Systemen, der sowohl der System-User “svn” als auch die Entwickler-Accounts zugeordnet werden. Abänderung der Rechtekämme für alle Repositories auf beiden Systemen so, dass ihnen neue Gruppe zugeordnet wird UND dass diese Gruppe auch Schreibrechte erhält. Das impliziert dann ggf. ein Sicherheitsproblem, wenn man die “conf”-Dateien nicht explizit ausschließt. Zudem muss man das SGID-Bit auf den Repository-Verzeichnissen setzen. Auf privaten Systemen mag das alles noch gehen; nicht aber auf Systemen, die tatsächlich von mehreren Usern benutzt werden.
Methode 3 hat gegenüber einer alleinigen Anwendung der Methode 2 den Vorteil, dass man danach beliebig zwischen den Zugriffsvarianten “file” und “svn” unter Eclipse auf den betroffenen Systemen wechseln kann. Ich selbst bevorzuge aber Methode 2 und werde den erforderlichen frühzeitigen Abgleich der UID/GIDs für die svn-Systemaccounts in Zukunft beherzigen.
Fazit
Beim wechselseitigen Arbeiten von verschiedenen Betriebsystem-Instanzen ein und desselben Computers aus mit lokalen SVN-Repositories einer vom jeweils gebooteten System gemounteten separaten Partition muss man unbedingt auf einen Abgleich der UID/GID des svn-Systemusers bzw. der svn-Systemgruppe unter den jeweiligen Betriebssystemen achten. Zumindest, wenn man jeweils einen lokalen SVN-Server für den Zugriff einsetzt. Diese Regel ist u.a. auch bei der testweisen Installation einer neuen Distributionsversion auf einer eigenen Partition zu berücksichtigen.
Das Gleiche gilt in analoger Weise aber auch für das wechselseitige Arbeiten am gleichen Projekt auf unterschiedlichen Computern, deren SVN-Repositories auf der Dateiebene bei Bedarf synchronisiert werden. Erfolgt auf jedem System der Zugriff auf die
lokalen Repositories über einen (jeweils) lokalen SVN-Server, so ist auf gleiche UIDs/GIDs der svn-System-Accounts zu achten.