
Seit Jahren arbeite ich unter Eclipse fast gewohnheitsmäßig mit SVN (Subversive Plugin und Polarion Connectoren) als Versionsverwaltungstool. Eine Frage, die mich dabei seit längerem verfolgt, ist:
Ist für Freiberufler wie mich, und damit in vielen Fällen für mobile Einzelkämpfer, trotz aller SVN-Affinität ein Wechsel auf Git sinnvoll? Woran kann man den Bedarf dingfest machen?
Steht ein Entwicklungsprojekt in einem überregional verteilten Team an, so setzen ja bereits viele andere Entwickler auch Git ein. Dann ist der Einsatz natürlich auch für mich unumgänglich. In der Situation befand ich mich aber noch nicht – deswegen habe ich eine ernsthafte Auseinandersetzung bislang auch immer wieder verschoben. Nun belasten mich ein paar Defizite von SVN aber zumindest für Entwicklungsaufgaben so, das ich das Thema wieder aufgreife.
Betrachten wir also mal eine sehr viel einfachere Situation als eine Entwicklung in einem verteilten Team. Nehmen wir an, das ich alleine etwas für einen Kunden entwickeln muss, aber den Kunden regelmäßig an einem anderen Ort (u.U. im Ausland) aufsuchen muss. Oder nehmen wir an, dass während der Entwicklungsarbeiten auch aus anderen gründen längere Abwesenheiten vom Arbeitsplatz-PC erforderlich sind, und in der Zwischenzeit am Laptop weitergearbeitet werden muss. Und gehen wir weiter von einer Situation aus, in der im Vor- und Nachfeld von Reisen der Status veränderter Projekt-Dateien regelmäßig versioniert und auf einfache Weise zwischen Arbeitsplatz-PC daheim und einem Laptop abgeglichen werden muss:
- Bewege ich mich zum Kunden, muss ich Dateien, die sich auf aktuell laufende Entwicklungsprojekte beziehen und an denen ich zuvor an meinem Arbeitsplatz gearbeitet habe, von meinem PC auf einfache automatisierte Weise auf einen Laptop transferieren. Dabei möchte ich aus entwicklungstechnischen Gründen (und in Beratungsprojekten z.B. zu Belegzwecken) immer die gesamte bisherige Versionshistorie der Dateien mit mir führen.
- Natürlich möchte ich answchließend zur Kontrolle weiterer Änderungen, die während der Reise anfallen, auf dem Laptop gerne ein lokales Versionsmanagement betreiben. Das gilt vor allem bei längerer Abwesenheit vom Heim/Firmenstandort. Und die während der Reise erreichten Zwischenstände möchte ich schon aus Backup-Gründen mit einem Repository im Internet abgleichen.
- Und natürlich sollen die auf dem Laptop erarbeiteten Ergebnisse nach dem Ende der Reise wieder in ein dortiges zentrales Repository des Haus-/Firmennetzes eingespielt werden. Von da dann wenn möglich auch weiter in ein lokales Repository auf meinem Arbeitsplatz-PC ..
Hier besteht also schon für einen Einzelkämpfer der Bedarf nach einer lokalen und einer zentraler Versionsverfolgung. Das bedingt zwangsläufig den Abgleich zwischen lokalen und zentralen Repositories zu sinnvoll gewählten Zeitpunkten. Will man solche Szenarien mit SVN abbilden steht man vor einem kleinen Dilemma, das erhebliche Klimmzüge erfordert.
SVN ist dafür gedacht, dass man sich mit einem (!) zentralen Server abgleicht. Der muss deshalb auch kontinuierlich erreichbar sein. Nun habe ich (gerade bei etwas längeren Auslandsaufenthalten) aber nicht immer eine Internetverbindung zur Verfügung. In einer solchen Situation bräuchte ich dann zwingend eine lokale Versionsverwaltung auf meinem Laptop, dessen Repository später mit Repositories mehrerer Server abgeglichen werden soll und muss. Das ist unter SVN wirklich ein Rezept für ein gediegenes Kuddelmuddel.
Unter Git ist das nach ersten Literaturstudien dagegen gut zu beherrschen. Git erlaubt das sichere Arbeiten mit einem lokalen und zentralen Repositories. In dieser Miniserie von Blog-Posts möchte ich deshalb für Interessierte
und Einsteiger, die Git unter Eclipse betreiben wollen, erste einfache Schritte beschreiben,
- wie man lokale Repositorys mit Eclipse-Mitteln auf einem PC und auf einem Laptop aufsetzt,
- wie man Repositories “cloned” und Clones zum Einrichten von Server-Repositories verwendet,
- wie man ein lokales Repository dann mit einem ein zentralen Repository im Haus- oder Firmennetz verbindet
- und gleichzeitig ein weiteres Repository im Internet als Backup- und Refernz-Repository benutzen kann.
Ich lasse dabei ein komplexes lokales und zentrales Feature- oder Release-Branching völlig außen vor. Um Release- und Feature-Branching kümmere ich mich evtl. in späteren Blog-Artikeln. Hier geht es nur um die Unterstützung eines quasi-sequentiellen Arbeitens an verschiedenen Geräten in folgendem Sinne:
Schritte eines Wunschszenarios für mobile Einzelkämpfer
- Entwicklung-/Dateiänderungen am Arbeitsplatz-PC. Versionierung mit Hilfe eines lokalen Repositorys auf dem PC
- => regelmäßiger Abgleich des Entwicklungsstandes auf dem PC mit einem zentralen Server-Repository im Hausnetz und einem zentralen Repository im Internet
- => Vorbereitung einer Reise: Abgleich des zentralen Server-Repositories mit dem lokalen Repositories eines Laptops
- => mobiles Arbeiten am Laptop und Versionsverwaltung mit einem dortigen lokalen Repository
- =>Abgleich neuer Versionsstände auf dem Laptop mit einem zentralen Repository im Internet
- => Rückkehr ins Firmennetz und Abgleich des Laptop-Repositories mit dem zentralen Git-Repository auf einem zuständigen Server des LANs
- => Abgleich zwischen Server-Repository und Arbeitsplatz-Repository
- => Arbeiten mit dem lokalen Repository am Arbeitsplatz und erneut Abgleich mit beiden Server-Repositories
- => Abgleich mit Laptop in Vorbereitung einer neuen Reise.
- Aufgabe 1: Erstellen eines lokalen Repositories auf dem PC.
- Aufgabe 2: Klärung: Wo liegt der “Working Tree”? Welchen Verzeichnisbaum zeigt Eclipse?
- Aufgabe 3: Einbringen des Inhalts des Projektverzeichnisbaums in den Master-Branch des lokalen Repositories. Initiales Commit.
- Aufgabe 4: Durchführung von Änderungen im Verzeichnisbaum des Projekts und Testen nachfolgender “Commits”. Blick auf die Git-Versionshistorie auf dem PC. Identifizierung des HEAD-Commmits bzw. -Knotens.
- Aufgabe 5: Erstellen eines zentralen Repositories auf einem Server im LAN. Hierzu werden wir unser lokales PC-Repository aus Aufgabe 1 in einer bestimmten Weise “klonen”. Der Clone wird dann auf dem Server in zugänglicher Weise platziert.
- Aufgabe 6: Anbinden des zentralen Repositories an das lokale PC-Repository. (Verkopplung der Master-Branches). Klärung der Frage, ob man ein lokales Commit auf dem PC mit einem gleichzeitigen Push zum Server verbinden kann.
- Aufgabe 7: testweises Überführen von neuen Änderungen, die wir auf dem PC am Projekt vornehmen werden, in den Master-Branch des Git-Server-Repositories.
- Aufgabe 8: Erzeugen eines passenden Projektes in einem geeigneten Eclipse-Workspace des Laptops. Klonen des Server-Repositorys und Bereitstellen auf dem Laptop. Verbinden mit dem Projekt. Hier stellt sich u.a. die Frage: Kann man diese Schritte unter Eclipse nicht irgendwie miteinander verbinden?
- Aufgabe 9: Transfer von neuen Commits, die wir auf dem PC vornehmen, über das zwischengeschaltete Server-Repository in das lokale Repository des Laptops. Also: Commit auf dem PC, Push zum Server und Pull-Operation auf dem Laptop.
- Aufgabe 10: Durchführung von Änderungen und entsprechenden Commits auf dem Laptop. Blick auf die Versionshistorie des Laptops.
- Aufgabe 11: Transfer von Änderungen auf dem Laptop über den zentralen LAN-Server auf den Arbeitsplatz-PC.
- Aufgabe 12: Klonen des LAN-Server-Repositories und Verschieben des Clones auf einen Server im Internet. Ankopplung an die Git-Versionsverwaltung unter Eclipse auf dem PC.
- Aufgabe 13: Testen von gezielten Push-Vorgängen vom PC und vom Laptop zum Repository auf dem Internet-Server. Klärung der Frage, ob wir unter Eclipse mit einem Commit zwei parallel Pushvorgänge zu den verschiedenen Server-Repositories im LAN und im Internet anstoßen können.
- Aufgabe 14: Testweiser Pull eines per Laptop erzeugten Versionsstandes vom Internet-Repository auf den PC. Anschließend Push vom Laptop zum Repository auf dem LAN-Server (!) und nachfolgender erneuter Pull desselben Versionsstandes durch den PC auch vom LAN-Server. Wird die Identität der Versionsstände erkannt?
Das ist ein denkbar einfaches Szenario, dass sich mit Hilfe einer IDE wie Eclipse nachbilden lassen sollte. Zur Vorbereitung benötigen wir jedoch einige generell Git-Begrifflichkeiten. Daher greife ich nachfolgend die Arbeitsschritte nochmal aus Eclipse-Perspektive auf und führe dabei gleichzeitig ein paar zentrale Begriffe aus der Git-Welt ein, an die man sich sowieso gewöhnen muss, wenn man ein Git-Plugin unter Eclipse einsetzen will.
Wir leiten aus der Neubeschreibung der obigen Arbeitsschritte unseres Wunschszenarios nebenbei Aufgaben ab, deren Lösung später zu einer systematischen Abbildung der gewünschten Prozesse unter Eclipse führen wird.
Das Wunschszenario in Git-Begriffen
Zur Vertiefung betrachten wir folgende Skizze:

Bin ich im firmeneigenen Netz arbeite ich normalerweise auf einer Linux-Workstation. Dort ist etwa “Eclipse Neon 3” mit dem Git-Plugin (Egit) installiert. Die Entwicklungsarbeit ist in Form von (Eclipse-) “Projekten” organisiert, zu denen jeweils ein Dateibaum gehört. In meinem Fall tummeln sich dort typischerweise PHP-, HTML,-, CSS-, Javascript- und auch mal Python-Dateien.
Für unser Beispielszenario ziehen wir später die Dateien eines konkreten Eclipse-Projektes namens “alien1” heran. Die zugehörigen Dateien liegen dabei unter 4 Haupt-Verzeichnissen: includes, admin, interpreters,
uploads. Das Projekt wurde in einem Eclipse-“Workspace” namens “ecl_alienx” platziert. Die genannten 4 Verzeichnisse sind im Beispiel deshalb unter einem Verzeichnis “/projekte/ecl_alienx/alien1” zu finden.
Man könnte nun darüber streiten, ob die Aufbewahrung der Programm-Dateien innerhalb des Eclipse-Workspaces sinnvoll ist. Wir unterlassen diese Diskussion aber, da wir die Verzeichnislokation im Rahmen des Git-Einsatzes sowieso ändern werden.
Was wollen wir nun im Detail erreichen?
Zur Versionsverwaltung möchte ich in unserem Wunsch-Szenario zunächst ein lokales Git-Repository auf dem Arebitsplatz-PC benutzen, bis ich der Meinung bin, dass erreichte Zwischenergebnisse auch auf einem zentralen (Git-) Repository eines Servers im Haus-/Firmen-Netz zur Verfügung gestellt werden sollten. Ggf. für den Zugriff durch andere Nutzer/Tester, aber auch für zentrale Backups.
Lokal checke ich eine erreichte neue (Zwischen-) Version zunächst als sogenannten “Commit” in das Git-Repository meiner Workstation ein. Manchmal muss man in der SW-Entwicklung von einer bestimmten Version aus unterschiedliche, und für eine Weile divergierende Wege zu neuen Versionen gehen. Man erhält dann “Verzweigungen” der Versionsstände; wie in SVN auch bezeichnet man diese Zweige in Git als “Branches“. Branches können zum Beispiel als Feature- oder Release-Branches angelegt werden zur experimentellen Entwicklung von Features in einem separaten Zweig bzw. zur Konsolidierung eingefrorener Versionsstände angelegt werden. Andee Branches mögen etwa auch einer Continuous Integration dienen. Zu und zwischen Branches – also definierten Abzweigungen in der Versionshistorie – möchte man ggf. wechseln. Unter Git spricht man hierbei (abweichend von anderen Versionsverwaltungssystemen) von sog. Checkouts. Warum wird später klarer werden. Würde man z.B. vom Master-Branch zu einem anderen Branch namens “Branch2″ wechseln, so würde Branch2” zum sog. “aktiven Branch” des Repositories werden.
Jeder Commit entspricht grafisch gesehen einem “Knoten” eines Branches (s. die Skizze weiter unten); ein Knoten symbolisiert einen bestimmte Versionsstand des Branches (also eine eindeutigen Kombination aus definierten Versionsständen aller für die Versionsverwaltung erfassten Dateien). Ein Knoten in einem Branch entspricht also genau besehen nicht nur dem punktuellen Commit, der zu seiner Erzeugung führte, sondern im Kern der ganzen Historie aller vorangegangenen Commits auf den erfassten Dateien – ausgehend von einem initialen Commit. Die Rückkehr zu einem älteren Versionsstand (Knoten) in einem Branch nennt man unter Git einen sog. “Reset“.
Für Aktionen wie Commits, eine Historienverfolgung, Branching, Checkouts, Resets etc. sollte im Grunde gar kein Server erforderlich sein; ich will mit meiner lokalen Versionsverwaltung und dem zugehörigen Repository wenn nötig auch einen ganze Weile völlig autonom arbeiten können ohne irgendwelche Kollegen zu belästigen.
So weit so gut. Nun eine Einschränkung:
In unserem Szenario konzentrieren wir uns weitgehend auf sukzessive voranschreitende Versionen – oder “Knoten” – in genau einem Branch jedes eingesetzten Repositories. Der ursprünglich erzeugte, erste und native Branch eines jeden Repositories ist dessen sog. Master-Branch. Wir beschäftigen uns in dieser Blog-Post-Serie also primär mit dem Abgleich zwischen den “Master”-Branches verschiedener Repositories. Wir lassen dabei für unser Wunschszenario die gewollte Erzeugung von Branches (Entwicklungszweigen) und das Wechseln zu einem anderen als dem “Master”-Branch weitgehend außen vor.
Die Verzeichnisstruktur, in der die Dateien eines Eclipse-Projektes organisiert werden, muss sich in einem geeigneten Äquivalent im Rahmen der
Repository-Verwaltung widerspiegeln. Ein solches Äquivalent ist der sog. “Working Tree” eines Repositories. Wir werden sehen, dass auch der Working Tree eine Verzeichnisstruktur darstellt; diese entspricht ferner einer Momentaufnahme eines definierten Knotens auf dem “aktuellen Branch”; in unserem Beispiel also auf dem Master-Branch. Achtung: Checkouts und Resets führen zu Veränderungen der Inhalte von Dateien im “Working Tree”.
Typischerweise kann es sich ein Versionsverwaltungssystem aber nicht leisten, unterschiedliche und vollständige Varianten aller Dateiinhalte in normaler Dateiform aufzubewahren, um die Historie zu erfassen. Git arbeitet hier (wie andere System auch) inkrementell und verwahrt Differenzen zwischen Dateizuständen; zudem wird komprimiert: Im Ergebnis entstehen so Blobs einer Art Objekt-Datenbank. Die Objekte wiederum lassen sich eindeutig identifizieren und werden definierten Zustandsknoten von Branches (und damit auch Commits) zugeordnet. Eine eindeutige Identifizierung sowohl von Objekten als auch Commits (Knoten) wird in Git über Hashes ermöglicht, zwischen denen dann Relationen hergestellt werden. Weitere Details der Objektorganisation sind in unserem Kontext unwichtig.
Der Working Tree stellt eine Momentaufnahme eines ausgewählten Knotens dar – in der Regel des letzten, also des jüngsten Knotens einer Branch-Historie. Dieser Knoten wird auch als HEAD des Branches bezeichnet.
Die ersten Ziele, die wir unter Eclipse erreichen müssen, sind demnach folgende:
Zu geeigneten Zeitpunkten möchte ich den aktuellen Stand meiner Dateien auch auf einem zentralen Git-Server (z.B. im Firmen-LAN) bereitstellen. Entsprechende Operation werden als “Push“-Operationen bezeichnet. Ziel (“Target”) eines Pushes ist also ein Branch aus einem anderen (Target-) Repository – hier also im Repository des Servers. Ein Pushvorgang erzeugt dort einen neuen Knoten.
Andere bzw. auch ich selbst können später vom Server-Repository den dort festgehaltenen Entwicklungsstand auf andere Geräte (z.B. einen Laptop) und dortige lokale Repositories überführen. Dazu führen sie dann sog. Pull- oder Fetch-Operationen durch, mit denen der Versionsstand eines definierten Branches auf dem Server abgefragt und in das lokale Repository überführt und dort integriert wird. Auf den Unterschied zwischen Pull und Fetch gehe ich an passender Stelle in einem späteren Post dieser Serie kurz ein.
In unserem Szenario “pullen” wir typischerweise den letzten Stand vom Master-Branch des Server-Repositories. Das Target eines Pulls ist also der aktuelle Branch in dem lokalen Repository, von dem aus ich auf ein anderes Repository als Quelle von Veränderungen zugreife. Der Pull erzeugt einen neuen Knoten in meinem lokalen Branch. In unserem Szenario finden Pulls normalerweise auf dem Laptop und später auch auf dem Arbeitsplatz-PC statt. Server-Repositories protokollieren in unserem Szenarion dagegen neue Versionsstände als Ergebnis von Push-Vorgängen zum einem dortigen Branch – bei uns dem Master-Branch des jeweiligen Server-Repositories.
Sowohl bei einer Push- bzw. Pull-Operationen finden (automatisch) Merge-Prozesse mit dem Stand des betroffenen Branches auf dem Target-Repository statt. In unserem Szenario wird ein erster Push-Prozess also z.B. den Stand einer Datei (oder mehrerer Dateien) des Master-Branches auf einem lokalen PC-Repository mit dem Stand der entsprechenden Datei(en) (bzw. ihrer Objekte) im Master-Branch des Server-Repositorys zusammenführen. Das PC-Repository verändert sich dabei nicht; der neue Knoten entsteht auf dem Server. [Hat man Push/Pull-Vorgänge zwischen definierten Master-Branches unterschiedlicher Repositories verstanden, so sind spätere, komplexere Operationen zwischen anderen lokalen und zentralen Repository-Branches (als den Master-Branches) relativ einfach zu beherrschen.]
Beim Zusammenführen unterschiedlicher Dateiänderungen in einem Merge können ggf. Konflikte auftreten; diese müssen dann ggf. manuell aufgelöst werden. Das erfordert ggf. detaillierte Vergleiche der in den unterschiedlichen Branches/Repositories vor dem Merge durchgeführten Änderungen. Wir werden aber sehen:
Arbeitet man als Einzelperson phasenweise entweder ausschließlich auf dem Arbeitsplatz oder in einer anderen Phase ausschließlich auf dem Laptop und gleicht bei einem Übergang zwischen diesen Arbeitsphasen die jeweiligen lokalen Repositories mit einem zentralen Server-Repository in der oben angegebenen Schrittfolge ab, so treten Konflikte in der Regel nicht auf. In diesen Fällen kann Git die notwendigen Merges automatisch und auf einfache Weise erledigen. Man spricht dann auch von Fast-Forward-Merges (FF-Merges).
Bei FF-Merges sind eigentlich nur neue Knoten in einem Branch zu erzeugen und Referenzen zu bereits bekannten Objekten aufzubauen. Letztere müssen möglicherweise zwischen Repositories kopiert werden; aber echte neue Objekte zu neuen Datenstrukturen sind nicht zu erzeugen. Es liegt dann kein Merge-Commit wie im Falle echter Zusammenführungen mehrer unterschiedlicher Änderungen in den Quell- und Target-Branches vor.
Die Situation wird in folgender Skizze dargestellt. Wir sehen sukzessiv erstellte Knoten in den Master-Branches dreier Repositories. Echte Commits, bei denen Datenveränderungen vorgenommen wurden, sind als solche bezeichnet und durchnummeriert. Zu jedem Knoten findet man die ersten alphanumerischen Zeichen eines zugehörigen eindeutigen Hashes. In jedem Branch ist der führende Head-Knoten durch eine rote Füllung angedeutet.
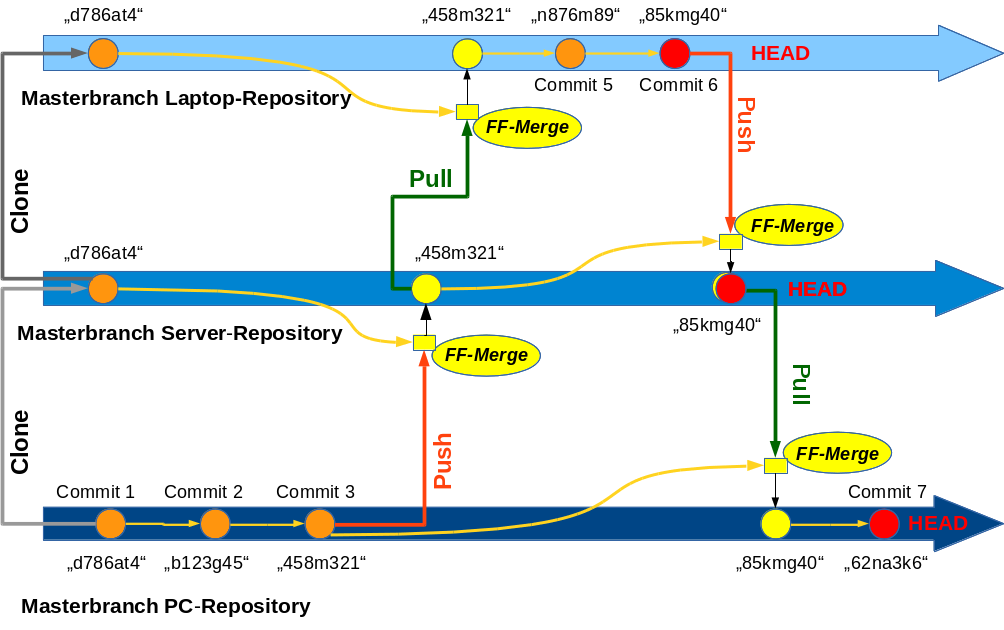
Push und Pull-Aktionen führen in der rein sequentiellen Aktionsabfolge unseres einfachen Szenarios zu unkomplizierten und konfliktfreien FF-Merges, in die wir nicht eingreifen müssen.
Komplizierter wäre das Mergen allerdings dann, wenn die zentralen Versionsstände zu Dateien, an denen man selbst in seinem lokalen Repository arbeitet, während einer Phase auch durch andere von anderen Stellen aus manipuliert werden würden. Das schließen wir für diese Artikelserie aber mal aus. Etwas schwieriger ist auch ein zwischenzeitlicher lokaler “Reset” auf alte Versionen beim Abgleich zwischen den verschiedenen Arbeitsphasen an unterschiedlichen Geräten zu bewältigen. Auch auch das lassen wir hier zunächst außen vor. Ich komme darauf aber in einem späteren Post der Serie zurück.
Der eine oder andere wird sich noch die Frage stellen, wie man denn überhaupt zu einem Repository kommt. Unter Git (und damit auch mit entsprechenden Tools unter Eclipse) ist das sowohl über das gezielte Erzeugen und Initialisieren eines Repositories in einem Projekt-Verzeichnis möglich als auch über das Klonen (also Kopieren) von Repositories. Clones mit bestimmten Eigenschaften
können auch auf Server verschoben und anschließend mit lokalen Repositories verbunden werden. Wir werden uns den Aufbau und das Klonen von Repositories mit Eclipse Tools später genauer ansehen.
Wir können an dieser Stelle jedoch schon mehrere neue Aufgaben festhalten, die wir unter Eclipse lösen müssen:
Wenden wir uns nun unserem Laptop zu. Im Wunschszenario ist beim Wechsel von einer Arbeitsphase am PC auf eine mobile Phase unter alleinigem Einsatz des Laptops zunächst also eine Push-Operation vom PC auf den Server und danach eine Pull-Operation auf dem Laptop erforderlich. Es ergeben sich also folgende weitere Aufgaben:
Danach arbeitet man ausschließlich auf dem Laptop weiter:
Hinweis: Unter Git wäre prinzipiell auch ein direkter Abgleich zwischen den lokalen Repositories des Laptops und des PCs möglich gewesen. Aus verschiedenen Gründen halten wir aber in einem LAN den Weg über ein zentrales Repository für eine deutlich bessere Idee (Stern-Architektur). Ein Grund besteht etwa in Sicherheitsargumenten und einer Zugriffskontrolle: Nicht jedes System soll auf Verzeichnisstrukturen jedes andere im Netz zugreifen können. Die Zugriffsberechtigung auf bestimmte Repository-Daten lässt sich an zentraler Stelle gleich für mehrere Mitarbeiter steuern. Ein weiterer Grund ist die zentrale Zugriffsprotokollierung. Zudem stehen die Arbeitsergebnisse an zentraler Stelle auch für Backups und andere Mitarbeiter zur Verfügung.
Betrachten wir die Situation die sich bei der Rückkehr von einer Reise ergibt. Will man dann ausschließlich auf dem Arbeitsplatz-PC weiterarbeiten, so gilt: Erforderlich ist zuerst eine Push-Operation vom Laptop in Richtung Server-Repository des Firmen-LANs und anschließend eine Pull-Operation am PC, bei der man den aktuellen Stand vom Server-Repository in das lokale Repository des PCs überführt.
Man kann die gesamte Kette “PC => Server => Laptop => Server => PC”, die im Laufe einer Reise abgearbeitet wird, auch an der oben dargestellten Skizze nachvollziehen. Der Weg vom Laptop zum PC ist daher die Umkehrung von Aufgabe 9:
Repository im Internet
Was soll nun in unserem 1-Mann-Szenario der in der Skizze angedeutete weitere Server im Internet ?
Ein Repository kann man auch als spezielle Backup-Datenbank für erzielte Arbeitsergebnisse betrachten. Zentrale Repositories schützen in diesem Sinne gegen lokale Verluste. Tatsächlich ist es mir schon mal passiert, dass eine Laptop-Platte auf einer Reise ihren Geist aufgegeben hat. Manchmal kann man sich dann sogar eine neue Platte beschaffen – und Linux wie Eclipse sind auch schnell installiert. Aber woher bekommt man in einem solchen Fall ein halbwegs aktuelles Repository? Hier hilft ein Server im Internet.
Umgekehrt gilt: Auch ein Totalverlust des Laptops (z.B. durch Diebstahl) ist in der Regel weniger schlimm als der Verlust der auf diesem Gerät erzielten Arbeitsergebnisse. D.h., wir werden das Internet-Repository auch während einer Reise relativ regelmäßig mit den auf dem Laptop erzielten Versionsständen per Push-Abgleich versorgen. Soweit wir eben Zugang zu einer halbwegs vernünftigen Internet-Anbindung haben. Da Git inkrementell und komprimiert sichert, ist die Menge der zu transferierenden Daten dann oft gar nicht so groß, wie man meinen möchte. Natürlich gilt, dass man ein zentrales Repository im Internet auch für andere Zwecke wie die Arbeit in einem verteilten Team nutzen könnte.
Wir benutzen also ein zentrales Git-Repository im Internet (oder mehrere solcher Repositories) als Backup-Instanz. Damit das Repository des Internet-Servers bereits zu Beginn einer Reise ordentlich gefüllt ist, werden wir vom PC aus rechtzeitig entsprechende Push-Aktionen durchführen. Im Sinne einer Backup-Übung sogar relativ regelmäßig. Selbstverständlich müssen unsere Administratoren dafür Sorge tragen, dass der Server und der Kommunikationsweg zum Repository hinreichend gegen Zugriffe anderer geschützt ist. Hier gelten die gleichen Maßnahmen, die man bei jedem anderen Cloud-Service auch treffen würde.
Es ergeben sich folgende abschließende Aufgaben:
Damit genug der Theorie. Wir haben unser Wunschszenario in Git-Begriffen ausgedeutet und uns dabei ein ordentliches Paket an Aufgaben zusammengestellt, das wir soweit möglich und sinnvoll unter Eclipse abarbeiten wollen. Im nächsten Post dieser Serie
Erste Schritte mit Git für lokale und zentrale Repositories unter Eclipse – II
bewegen wir uns dann in die Git-Praxis unter Eclipse und legen dort erstmal ein lokales Repository für unser Beispielprojekt “alien1” an.