
In the first blog post
Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – I
of this series about virtual networking between network namespaces I had discussed some basic Linux commands to set up and enter network namespaces on a Linux system.
In a second post
Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – II
I suggested and described several networking experiments which can quickly be set up by these tools. As containers are based on namespaces we can study virtual networking between containers on a host in principle just by connecting network namespaces. Makes e.g. the planning of firewall rules and VLANs a bit easier …
The virtual environment we want to build up and explore step by step is displayed in the following graphics:
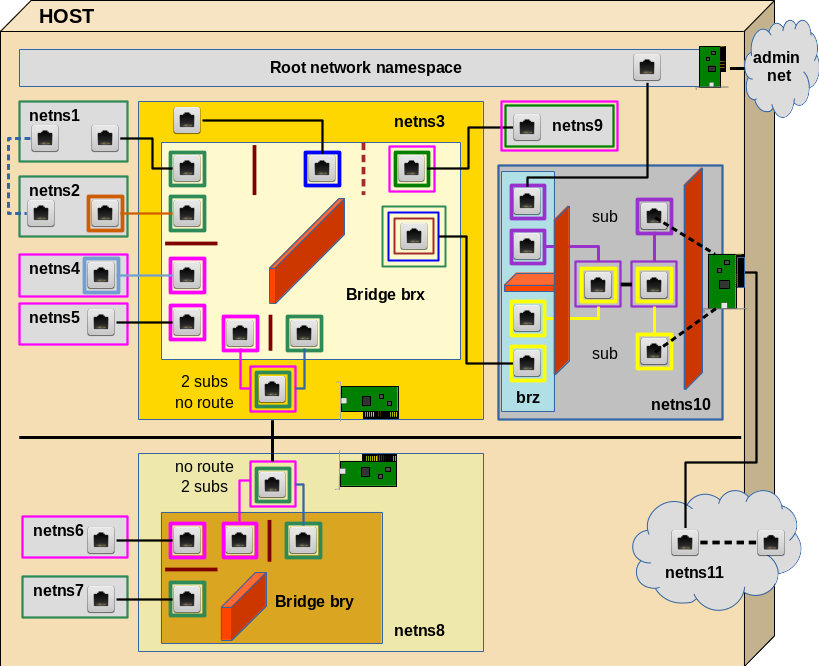
In this article we shall cover experiment 1 and experiment 2 discussed in the last article – i.e. we start with the upper left corner of the drawing.
Experiment 1: Connect two network namespaces directly
This experiments creates the dotted line between netns1 and netns2. Though simple this experiments lays a foundation for all other experiments.
We place the two different Ethernet interfaces of a veth device in the two (unnamed) network namespaces (with hostnames) netns1 and netns2. We assign IP addresses (of the same network class) to the interfaces and check a basic communication between the network namespaces. The situation corresponds to the following simple picture:
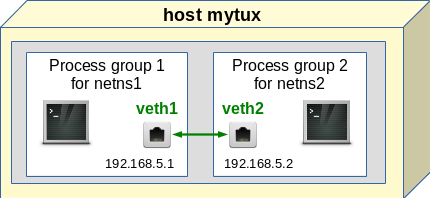
What shell commands can be used for achieving this? You may put the following lines in a file for keeping them for further experiments or to create a shell script:
unshare --net --uts /bin/bash & export pid_netns1=$! nsenter -t $pid_netns1 -u hostname netns1 unshare --net --uts /bin/bash & export pid_netns2=$! nsenter -t $pid_netns2 -u hostname netns2 ip link add veth11 netns $pid_netns1 type veth peer name veth22 netns $pid_netns2 nsenter -t $pid_netns1 -u -n /bin/bash ip addr add 192.168.5.1/24 brd 192.168.5.255 dev veth11 ip link set veth11 up ip link set lo up ip a s exit nsenter -t $pid_netns2 -u -n /bin/bash ip addr add 192.168.5.2/24 brd 192.168.5.255 dev veth22 ip link set veth22 up ip a s exit lsns -t net -t uts
If you copy these lines to the prompt of a root shell of some host “mytux” you will get something like the following:
mytux:~ # unshare --net --uts /bin/bash &
[2] 32146
mytux:~ # export pid_netns1=$!
[2]+ Stopped unshare --net --uts /bin/bash
mytux:~ # nsenter -t $pid_netns1 -u hostname netns1
mytux:~ # unshare --net --uts /bin/bash &
[3] 32154
mytux:~ # export pid_netns2=$!
[3]+ Stopped unshare --net --uts /bin/bash
mytux:~ # nsenter -t $pid_netns2 -u hostname netns2
mytux:~ # ip link add veth11 netns $pid_netns1 type veth peer name veth22 netns $pid_netns2
mytux:~ # nsenter -t
$pid_netns1 -u -n /bin/bash
netns1:~ # ip addr add 192.168.5.1/24 brd 192.168.5.255 dev veth11
netns1:~ # ip link set veth11 up
netns1:~ # ip link set lo up
netns1:~ # ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: veth11: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether da:34:49:a6:18:ce brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.5.1/24 brd 192.168.5.255 scope global veth11
valid_lft forever preferred_lft forever
netns1:~ # exit
exit
mytux:~ # nsenter -t $pid_netns2 -u -n /bin/bash
netns2:~ # ip addr add 192.168.5.2/24 brd 192.168.5.255 dev veth22
netns2:~ # ip link set veth22 up
netns2:~ # ip a s
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth22: <NO-CARRIER,BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether f2:ee:52:f9:92:40 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.5.2/24 brd 192.168.5.255 scope global veth22
valid_lft forever preferred_lft forever
inet6 fe80::f0ee:52ff:fef9:9240/64 scope link tentative
valid_lft forever preferred_lft forever
netns2:~ # exit
exit
mytux:~ # lsns -t net -t uts
NS TYPE NPROCS PID USER COMMAND
4026531838 uts 387 1 root /usr/lib/systemd/systemd --switched
4026531963 net 385 1 root /usr/lib/systemd/systemd --switched
4026532178 net 1 581 root /usr/sbin/haveged -w 1024 -v 0 -F
4026540861 net 1 4138 rtkit /usr/lib/rtkit/rtkit-daemon
4026540984 uts 1 32146 root /bin/bash
4026540986 net 1 32146 root /bin/bash
4026541078 uts 1 32154 root /bin/bash
4026541080 net 1 32154 root /bin/bash
mytux:~ #
Of course, you recognize some of the commands from my first blog post. Still, some details are worth a comment:
Unshare, background shells and shell variables
We create a separate network (and uts) namespace with the “unshare” command and background processes.
unshare –net –uts /bin/bash &
Note the options! We export shell variables with the PIDs of the started background processes [$!] to have these PIDs available in subshells later on. Note: From our original terminal window (in my case a KDE “konsole” window) we can always open a subshell window with:
mytux:~ # konsole &>/dev/null
You may use another terminal window command on your system. The output redirection is done only to avoid KDE message clattering. In the subshell you may enter a previously created network namespace netnsX by
nsenter -t $pid_netnsX -u -n /bin/bash
Hostnames to distinguish namespaces at the shell prompt
Assignment of hostnames to the background processes via commands like
nsenter -t $pid_netns1 -u hostname netns1
This works through the a separation of the uts namespace. See the first post for an explanation.
Create veth devices with the “ip” command
The key command to create a veth device and to assign its two interfaces to 2 different network namespaces is:
ip link add veth11 netns $pid_netns1 type veth peer name veth22 netns $pid_netns2
Note, that we can use PIDs to identify the target network namespaces! Explicit names of the network namespaces are not required!
The importance of a running lo-device in each network namespace
We intentionally did not set the loopback device “lo” up in netns2. This leads to an interesting observation, which many admins are not aware of:
The lo device is required (in UP status) to be able to ping network interfaces (here e.g. veth11) in the local namespace!
This is standard: If you do not specify the interface to ping from via an option “-I” the ping command will use device lo as a default! The ping traffic runs through it! Normally, we just do not realize this point, because lo almost always is UP on a standard system (in its root namespace).
For testing the role of “lo” we now open a separate terminal window:
mytux:~ # konsole &>/dev/null
There:
mytux:~ # nsenter -t $pid_netns2 -u -n /bin/bash netns2:~ # ping 192.168.5.2 PING 192.168.5.2 (192.168.5.2) 56(84) bytes of data. ^C --- 192.168.5.2 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 1008ms netns2:~ # ip link set lo up netns2:~ # ping 192.168.5.2 -c2 PING 192.168.5.2 (192.168.5.2) 56(84) bytes of data. 64 bytes from 192.168.5.2: icmp_seq=1 ttl=64 time=0.017 ms 64 bytes from 192.168.5.2: icmp_seq=2 ttl=64 time=0.033 ms --- 192.168.5.2 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 998ms rtt min/avg/max/mdev = 0.017/0.034 ms
And: Within the same namespace and “lo” down you cannot even ping the second Ethernet interface of a veth device from the first interface – even if they belong to the same network class!
Open a new sub shell and enter e.g. netns1 there:
netns1:~ # ip link add vethx type veth peer name vethy netns1:~ # ip addr add 192.168.20.1/24 brd 192.168.20.255 dev vethx netns1:~ # ip addr add 192.168.20.2/24 brd 192.168.20.255 dev vethy netns1:~ # ip link set vethx up netns1:~ # ip link set vethy up netns1:~ # ping 192.168.20.2 -I 192.168.20.1 PING 192.168.20.2 (192.168.20.2) from 192.168.20.1 : 56(84) bytes of data. ^C --- 192.168.20.2 ping statistics --- 4 packets transmitted, 0 received, 100% packet loss, time 3000ms netns1:~ # ip link set lo up netns1:~ # ping 192.168.20.2 -I 192.168.20.1 PING 192.168.20.2 (192.168.20.2) from 192.168.20.1 : 56(84) bytes of data. 64 bytes from 192.168.20.2: icmp_seq=1 ttl=64 time=0.019 ms 64 bytes from 192.168.20.2: icmp_seq=2 ttl=64 time=0.052 ms ^C --- 192.168.20.2 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 999ms rtt min/avg/max/mdev = 0.019/0.035/0.052/0.017 ms netns1:~ #
Connection test
Now back to our experiment. Let us now try to ping netns1 from netns2:
netns2:~ # ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: veth22: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether f2:ee:52:f9:92:40 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.5.2/24 brd 192.168.5.255 scope global veth22
valid_lft forever preferred_lft forever
inet6 fe80::f0ee:52ff:fef9:9240/64 scope link
valid_lft forever preferred_lft forever
netns2:~ # ping 192.168.5.1
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
64 bytes from 192.168.5.1: icmp_seq=1 ttl=64 time=0.030 ms
64 bytes from 192.168.5.1: icmp_seq=2 ttl=64 time=0.033 ms
64 bytes from 192.168.5.1: icmp_seq=3 ttl=64 time=0.036 ms
^C
--- 192.168.5.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1998ms
rtt min/avg/max/mdev = 0.030/0.033/0.036/0.002 ms
netns2:~ #
OK! And vice versa:
mytux:~ # nsenter -t $pid_netns1 -u -n /bin/bash netns1:~ # nsenter -t $pid_netns2 -u -n /bin/bash netns1:~ # ping 192.168.5.2 -c2 PING 192.168.5.2 (192.168.5.2) 56(84) bytes of data. 64 bytes from 192.168.5.2: icmp_seq=1 ttl=64 time=0.023 ms 64 bytes from 192.168.5.2: icmp_seq=2 ttl=64 time=0.023 ms --- 192.168.5.2 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1003ms rtt min/avg/max/mdev = 0.023/0.023/0.023/0.000 ms netns1:~ #
Our direct communication via veth works as expected! Network packets are not stopped by network namespace borders – this would not make much sense.
Experiment 2: Connect two namespaces via a bridge in a third namespace
We now try a connection of netns1 and netns2 via a Linux bridge “brx“, which we place in a third namespace netns3:
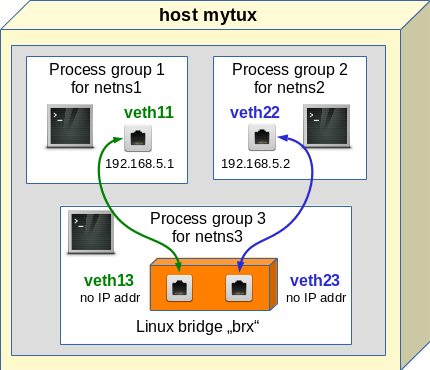
Note:
This is a standard way to connect containers on a host!
LXC tools as well as libvirt/virt-manager would help you to establish such a bridge! However, the bridge would normally be place inside the host’s root namespace. In my opinion this is not a good idea:
A separate 3rd namespace gets the the bridge and related firewall and VLAN rules outside the control of the containers. But a separate namespace also helps to isolate the host against any communication (and possible attacks) coming from the containers!
So, let us close our sub terminals from the first experiment and kill the background shells:
mytux:~ # kill -9 32146 [2]- Killed unshare --net --uts /bin/bash mytux:~ # kill -9 32154 [3]+ Killed unshare --net --uts /bin/bash
We adapt our setup commands now to create netns3 and bridge “brx” there by using “brctl bradd“. Futhermore we add two different veth devices; each with one interface in netns3. We attach the interface to the bridge via “brctl addif“:
unshare --net --uts /bin/bash & export pid_netns1=$! nsenter -t $pid_netns1 -u hostname netns1 unshare --net --uts /bin/bash & export pid_netns2=$! nsenter -t $pid_netns2 -u hostname netns2 unshare --net --uts /bin/bash & export pid_netns3=$! nsenter -t $pid_netns3 -u hostname netns3 nsenter -t $pid_netns3 -u -n /bin/bash brctl addbr brx ip link set brx up exit ip link add veth11 netns $pid_netns1 type veth peer name veth13 netns $pid_netns3 ip link add veth22 netns $pid_netns2 type veth peer name veth23 netns $pid_netns3 nsenter -t $pid_netns1 -u -n /bin/bash ip addr add 192.168.5.1/24 brd 192. 168.5.255 dev veth11 ip link set veth11 up ip link set lo up ip a s exit nsenter -t $pid_netns2 -u -n /bin/bash ip addr add 192.168.5.2/24 brd 192.168.5.255 dev veth22 ip link set veth22 up ip a s exit nsenter -t $pid_netns3 -u -n /bin/bash ip link set veth13 up ip link set veth23 up brctl addif brx veth13 brctl addif brx veth23 exit
It is not necessary to show the reaction of the shell to these commands. But note the following:
- The bridge has to be set into an UP status.
- The veth interfaces located in netns3 do not get an IP address. Actually, a veth interface plays a different role on a bridge than in normal surroundings.
- The bridge itself does not get an IP address.
Bridge ports
By attaching the veth interfaces to the bridge we create a “port” on the bridge, which corresponds to some complicated structures (handled by the kernel) for dealing with Ethernet packets crossing the port. You can imagine the situation as if e.g. the veth interface veth13 corresponds to the RJ45 end of a cable which is plugged into the port. Ethernet packets are taken at the plug, get modified sometimes and then are transferred across the port to the inside of the bridge.
However, when we assign an Ethernet address to the other interface, e.g. veth11 in netns1, then the veth “cable” ends in a full Ethernet device, which accepts network commands as “ping” or “nc”.
No IP address for the bridge itself!
We do NOT assign an IP address to the bridge itself; this is a bit in contrast to what e.g. happens when you set up a bridge for networking with the tools of virt-manager. Or what e.g. Opensuse does, when you setup a KVM virtualization host with YaST. In all these cases something like
ip addr add 192.168.5.100/24 brd 192.168.5.255 dev brx
happens in the background. However, I do not like this kind of implicit politics, because it opens ways into the namespace surrounding the bridge! And it is easy to forget this bridge interface both in VLAN and firewall rules.
Almost always, there is no necessity to provide an IP address to the bridge itself. If we need an interface of a namespace, a container or the host to a Linux bridge we can always use a veth device. This leads to a much is much clearer situation; you see the Ethernet interface and the port to the bridge explicitly – thus you have much better control, especially with respect to firewall rules.
Enter network namespace netns3
Now we open a terminal as a sub shell (as we did in the previous example) and enter netns3 to have a look at the interfaces and the bridge.
mytux:~ # nsenter -t $pid_netns3 -u -n /bin/bash
netns3:~ # brctl show brx
bridge name bridge id STP enabled interfaces
brx 8000.000000000000 no
netns3:~ # ip a s
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: brx: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ce:fa:74:92:b5:00 brd ff:ff:ff:ff:ff:ff
inet6 fe80::1c08:76ff:fe0c:7dfe/64 scope link
valid_lft forever preferred_lft forever
3: veth13@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master brx state UP group default qlen 1000
link/ether ce:fa:74:92:b5:00 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::ccfa:74ff:fe92:b500/64 scope link
valid_lft forever preferred_lft forever
4: veth23@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master brx state UP group default qlen 1000
link/ether fe:5e:0b:d1:44:69 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::fc5e:
bff:fed1:4469/64 scope link
valid_lft forever preferred_lft forever
netns3:~ # bridge link
3: veth13 state UP @brx: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master brx state forwarding priority 32 cost 2
4: veth23 state UP @brx: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master brx state forwarding priority 32 cost 2
Useful commands
Let us briefly discuss some useful commands:
Incomplete information of “brctl show”
Unfortunately, the standard command
brctl show brx
does not work properly inside network namespaces; it does not produce a complete output. E.g., the attached interfaces are not shown. However, the command
ip a s
shows all interfaces and their respective “master“. The same is true for the very useful “bridge” command :
bridge link
If you want to see even more details on interfaces use
ip -d a s
and grep the line for a specific interface.
Just for completeness: To create a bridge and add a veth devices to the bridge, we could also have used:
ip link add name brx type bridge ip link set brx up ip link set dev veth13 master brx ip link set dev veth23 master brx
Connectivity test with ping
Now, let us turn to netns1 and test connectivity:
mytux:~ # nsenter -t $pid_netns1 -u -n /bin/bash
netns1:~ # ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: veth11@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 6a:4d:0c:30:12:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.5.1/24 brd 192.168.5.255 scope global veth11
valid_lft forever preferred_lft forever
inet6 fe80::684d:cff:fe30:1204/64 scope link
valid_lft forever preferred_lft forever
netns1:~ # ping 192.168.5.2
PING 192.168.5.2 (192.168.5.2) 56(84) bytes of data.
64 bytes from 192.168.5.2: icmp_seq=1 ttl=64 time=0.039 ms
64 bytes from 192.168.5.2: icmp_seq=2 ttl=64 time=0.045 ms
64 bytes from 192.168.5.2: icmp_seq=3 ttl=64 time=0.054 ms
^C
--- 192.168.5.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1998ms
rtt min/avg/max/mdev = 0.039/0.046/0.054/0.006 ms
netns1:~ # nc -l 41234
Note that – as expected – we do not see anything of the bridge and its interfaces in netns1! Note that the bridge basically is a device on the data link layer, i.e. OSI layer 2. In the current configuration we did nothing to stop the propagation of Ethernet packets on this layer – this will change in further experiments.
Connectivity test with netcat
At the end of our test we used the netcat command “nc” to listen on a TCP port 41234. At another (sub) terminal we can now start a TCP communication from netns2 to the TCP port 41234 in netns1:
mytux:~ # nsenter -t $pid_netns2 -u -n /bin/bash netns2:~ # nc 192.168.5.1 41234 alpha beta
This leads to an output after the last command in netns1:
netns1:~ # nc -l 41234 alpha beta
So, we have full connectivity – not only for ICMP packets, but also for TCP packets. In yet another terminal:
mytux:~ # nsenter -t $pid_netns1 -u -n /bin/bash netns1:~ # netstat -a Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 *:41234 *:* LISTEN tcp 0 0 192.168.5.1:41234 192.168.5.2:45122 ESTABLISHED Active UNIX domain sockets (servers and established) Proto RefCnt Flags Type State I-Node Path netns1:~ #
Conclusion
It is pretty easy to connect network namespaces with veth devices. The interfaces can be assigned to different network namespaces by using a variant of the “ip” command. The target network namespaces can be identified by PIDs of their basic processes. We can link to namespaces directly via the interfaces of one veth device.
An alternative is to use a Linux bridge (for Layer 2 transport) in yet another namespace. The third namespace provides better isolation; the bridge is out of the view and control of the other namespaces.
We have seen that the commands “ip a s” and “bridge link” are useful to get information about the association of bridges and their assigned interfaces/ports in network namespaces.
In the coming article
Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – IV
we extend our efforts to creating VLANs with the help of our Linux bridge. Stay tuned ….