During the last two posts of this series
More fun with veth, network namespaces, VLANs – IV – L2-segments, same IP-subnet, ARP and routes
we have studied a Linux network namespace with two attached L2-segments. All IPs were members of one and the same IP-subnet. Forwarding and Proxy ARP had been deactivated in this namespace.
So far, we have understood that routes have a decisive impact on the choice of the destination segment when ICMP- and ARP-requests are sent from a network namespace with multiple NICs – independent of forwarding being enabled or not. Insufficiently detailed routes can lead to problems and asymmetric arrival of replies from the segments – already on the ARP-level!
The obvious impact of routes on ARP-requests in our special scenario has surprised at least some readers, but I think remaining open questions have been answered in detail by the experiments discussed in the preceding post. We can now move on, on sufficiently solid ground.
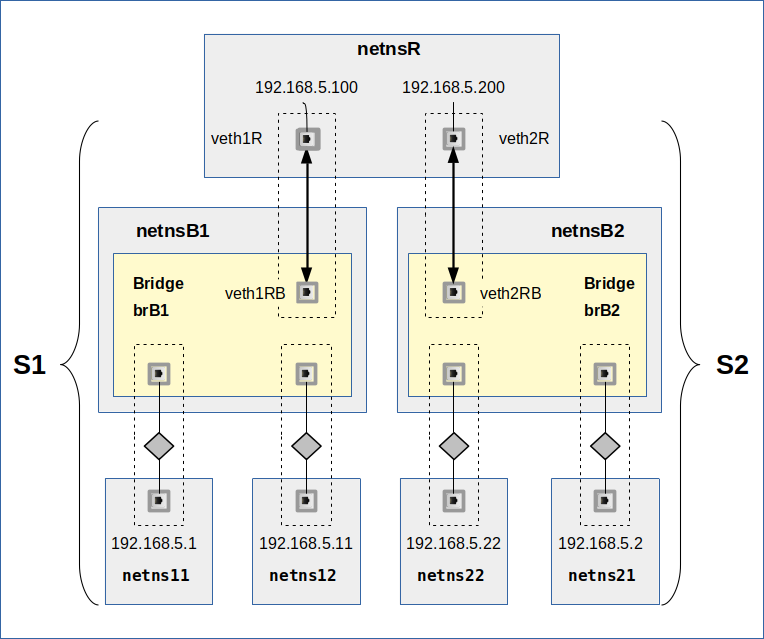
We have also seen that even with detailed routes ARP- and ICMP-traffic paths to and from the L2-segments remain separated in our scenario (see the graphics below). The reason, of course, was that we had deactivated forwarding in the coupling namespace.
In this post we will study what happens when we activate forwarding. We will watch results of experiments both on the ICMP- and the ARP-level. Our objective is to link our otherwise separate L2-segments (with all their IPs in the same IP-subnet) seamlessly by a forwarding network namespace – and thus form some kind of larger segment. And we will test in what way Proxy ARP will help us to achieve this objective.
Not just fun …
Now, you could argue that no reasonable admin would link two virtual segments with IPs in the same IP-subnet by a routing namespace. One would use a virtual bridge. First answer: We perform virtual network experiments here for fun … Second answer: Its not just fun ..
Our eventual objective is the configuration of virtual VLAN configurations and related security measures. Of particular interest are routing namespaces where two tagging VLANs terminate and communicate with a third LAN-segment, the latter leading to an Internet connection. The present experiments with standard segments are only a first step in this direction.
When we imagine a replacement of the standard segments by tagged VLAN segments we already get the impression that we could use a common namespace for the administration of VLANs without accidentally mixing or transferring ICMP- and ARP-traffic between the VLANs. But the results in the last two previous posts also gave us a clear warning to distinguish carefully between routing and forwarding in namespaces.
The modified scenario – linking two L2-segments by a forwarding namespace
Let us have a look at a sketch of our scenario first:
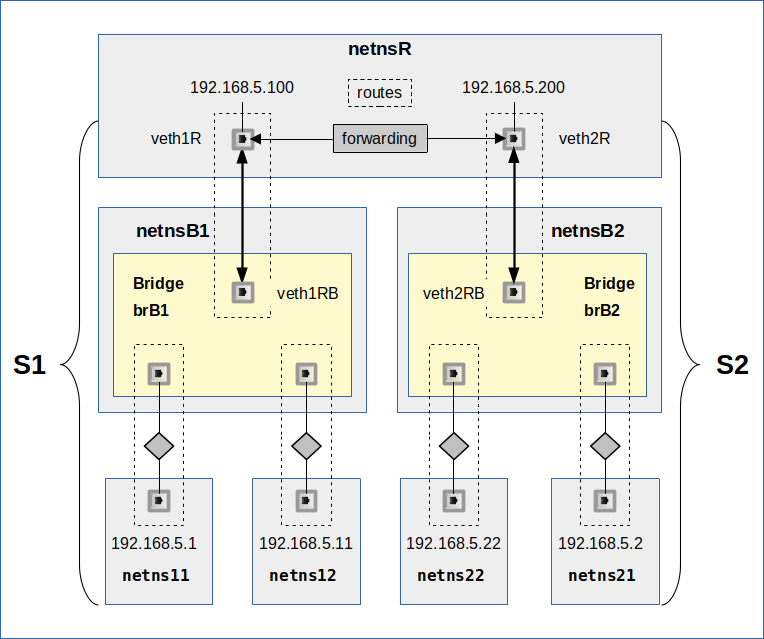
We see our segments S1 and S2 again. All IPs are memebers of 192.168.5.0/24. The segments are attached to a common network namespace netnsR. The difference to previous scenarios in this post series lies in the activated forwarding and the definition of detailed routes in netnsR for the NICs with IPs of the same C-class IP-subnet.
Our experiments below will look at the effect of default gateway definitions and at the requirement of detailed routes in the L2-segments’ namespaces. In addition we will also test in what way enabling Proxy ARP in netnsR can help to achieve seamless segment coupling in an efficient centralized way.