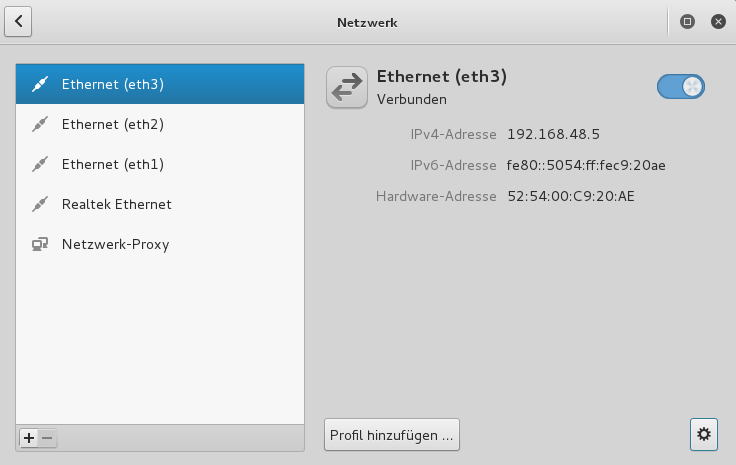
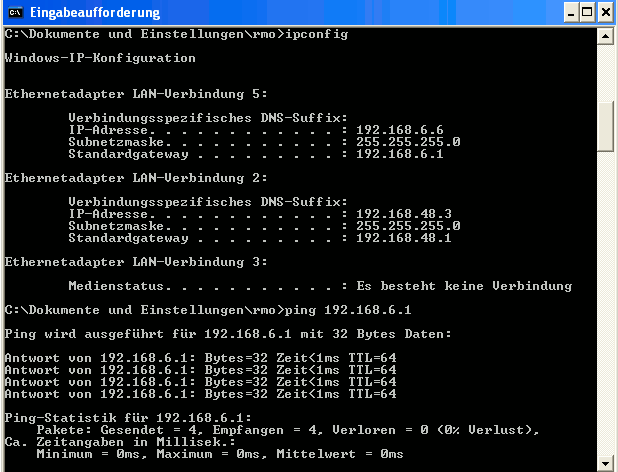
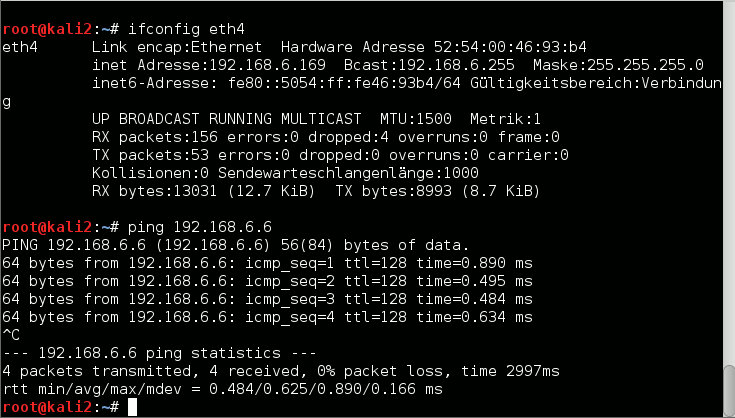
Diese Artikelserie befasst sich mit der Möglichkeit, hohe Monitor-Auflösungen auch beim Arbeiten mit Linux-Gastsystemen unter einem KVM/QEMU-Hypervisor zu nutzen. Dabei sollen das Spice-Protokoll und ein QXL-Device als virtuelle Grafikkarte des Gastsystems genutzt werden.
Wenn man mit einem virtualisierten System arbeitet, kann der Zugriff auf dessen Desktop entweder am KVM-Host selbst oder aber von einem Remote-System aus erfolgen. Bis auf weiteres konzentrieren wir uns auf das erstere Szenario, d.h. wir greifen unter einem Desktop des KVM-Hostes auf den Desktop des Gastes zu. Wir betrachten also den Fall mehrerer am Host selbst angeschlossener, hochauflösender Monitore, auf dem die Desktop-Umgebung des virtualisierten Gastsystems in einem oder mehreren Fenstern dargestellt werden soll. In einem solchen Szenario ist der durch Netzwerkprotokolle entstehende zusätzliche Komplexitätsgrad irrelevant.
Ausgangspunkt unserer Überlegungen des ersten Artikels war die Feststellung, dass nicht immer alle Möglichkeiten der physikalischen Monitore automatisch und richtig erkannt werden. Und selbst wenn das geschehen sollte, wird die Information nicht unbedingt korrekt an das Gastsystem weitergegeben. Dies gilt u.a. für externe Monitore. Dann ist Handarbeit angesagt. Besondere Vorkehrungen sind i.d.R. auch erforderlich, wenn man ggf. mehrere virtuelle Monitore eines Gastsystems nutzen und auf die physikalischen Schirme des Hosts verteilen will.
Im letzten Beitrag
KVM/qemu mit QXL – hohe Auflösungen und virtuelle Monitore im Gastsystem definieren und nutzen – I
hatte ich das Universaltool xrandr zur Konfiguration von Auflösung und Orientierung von Bildschirmen unter X-Window vorgestellt und bereits auf einem exemplarischen KVM-Host (Laptop mit Opensuse) eingesetzt. Danach hatten wir uns dem mittels “virt-manager” und QEMU virtualisierten Gastsystem zugewandt und uns ein wenig damit befasst, wie denn eine virtuelle Grafikkarte vom Typ QXL aussieht und wie man den dortigen Video RAM für hohe Auflösungen konfiguriert.
Wir gehen nun auf die Frage ein, welche Vorkehrungen im Gastsystems noch erforderlich sind, um einen oder mehrere hochauflösende virtuelle Monitore performant nutzen zu können. Abschließend wenden wir dann “xrandr” im Gastsystem an.
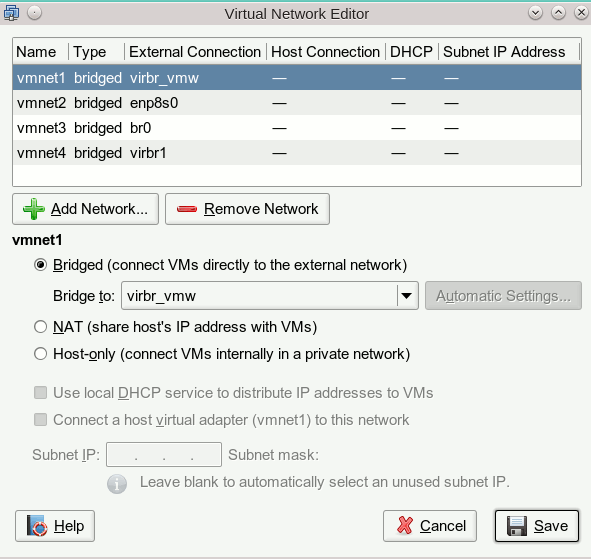
Zusammenspiel benötigter Komponenten
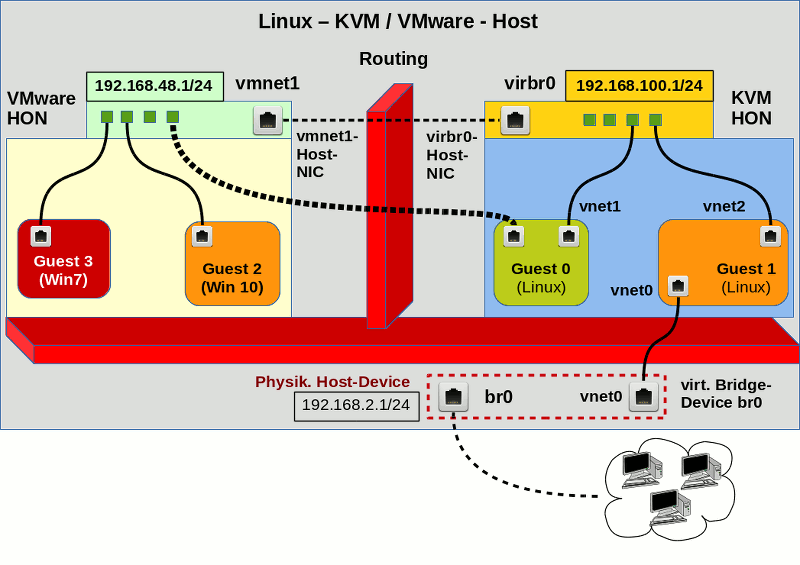
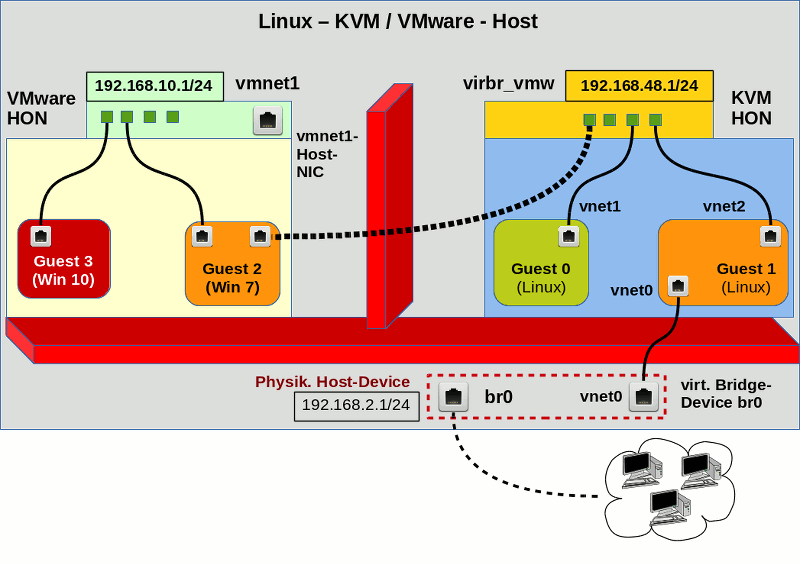
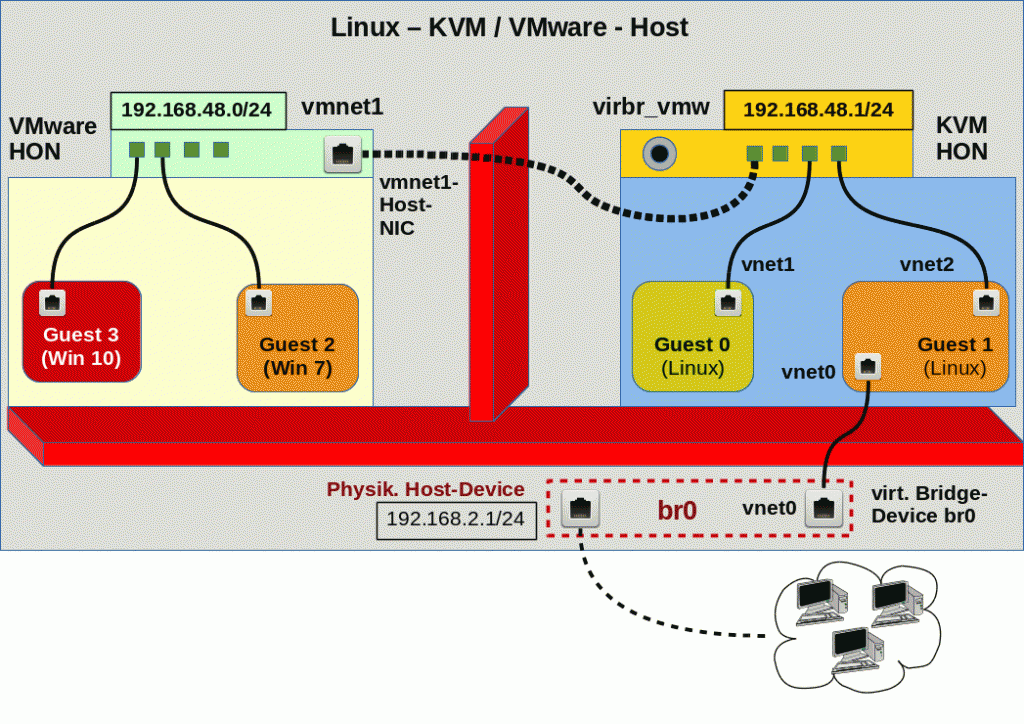
Wie greifen eigentlich die in unserem Szenario benötigten Komponenten Spice, virt-manager, libvirt, Qemu, QXL ineinander? Ich habe mal versucht, das in einer Skizze zu verdeutlichen:
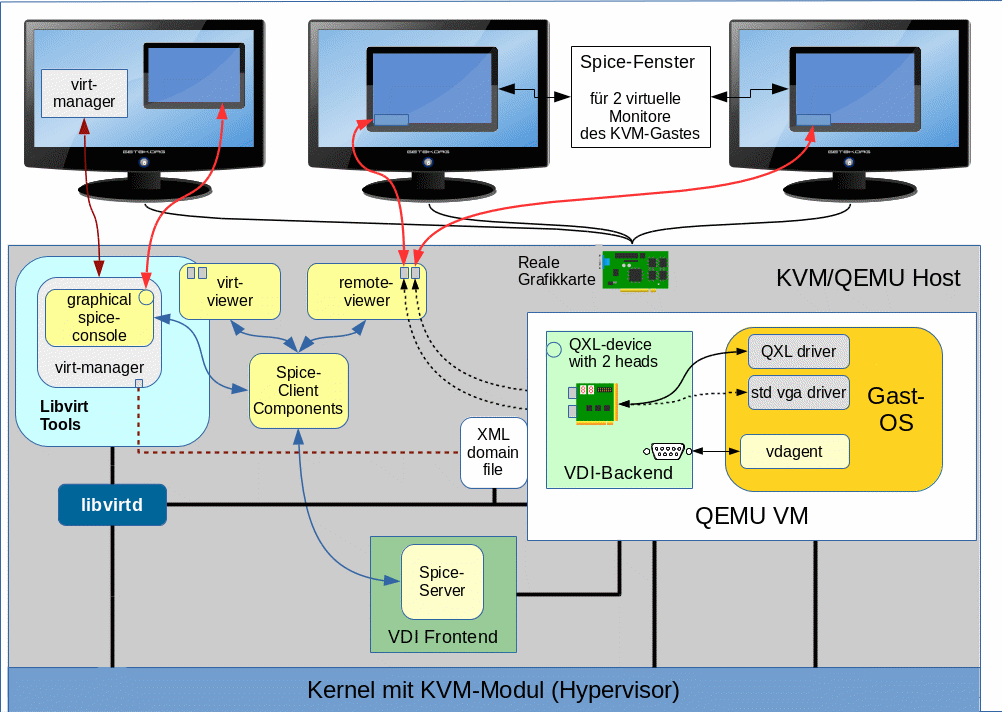
Die Skizze stellt die Situation für einen Virtualisierungshost dar, an dem 3 physikalische Monitore angeschlossen sind. Ein auf diesem KVM-Host angemeldeter User greift mittels Spice-Clients auf das dort installierte Gastsystem zu. (Das ist ein typisches Szenario für Entwickler-Laptops oder Linux-Workstations, in dem man mittels Virtualisierung Eigenschaften eines Zielsystems darstellt.) Das Gast-OS läuft in einer virtualisierten Umgebung, die durch QEMU im Zusammenspiel mit KVM bereitgestellt wird; das virtualisierte System (also der “Gast”) wurde in der Skizze als QEMU VM (Virtual Machine) bezeichnet.
Die Spice-Komponenten sind gelblich dargestellt. “virt-viewer” und “remote-viewer” sind verschiedene Spice-Clients, die mit dem Spice-Server kommunizieren können. Diese Clients ermöglichen die Darstellung des grafischen Outputs des Gastsystems in einem Fenster. Ähnliches leistet auch die in “virt-
manager” integrierte “grafische Spice-Konsole“.
Ich habe versucht, in der Skizze anzudeuten, dass der Spice-Client “remote-viewer” ganz unabhängig von libvirt-Komponenten funktioniert (s. hierzu etwa Red Hat Virtualization Guide für RHEL 6, Kap. 17.2 .
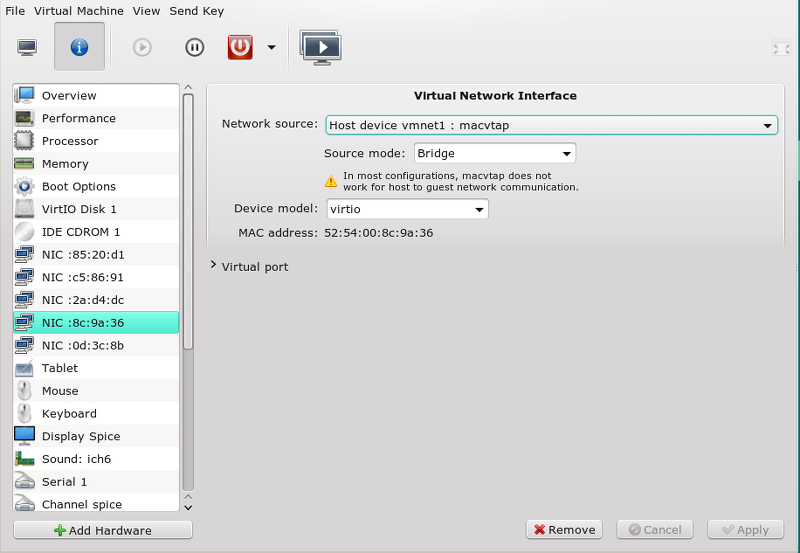
Eine Skizze zur genaueren Struktur des QXL-Devices der QEMU VM mit bis zu vier “heads” für vier virtuelle Monitore von Linux-Gastsystemen hatte ich bereits im vorhergehenden Artikel geliefert. In der hiesigen Skizze habe ich die Situation für 2 “heads” angedeutet; 2 virtuelle Monitore des Gastes werden auf zwei physikalischen Monitoren in Spice-Client-Fenstern angezeigt.
Anmerkungen zur Client-Server-Struktur
Aus der Skizze geht die Client/Server-Struktur der Komponenten nicht so recht hervor, da im dargestellten Fall ja alles auf dem Virtualisierungshost abläuft. Aber sowohl Spice als auch libvirt/qemu sind netzwerkfähig und somit als Client/Server-Systeme ausgelegt. Der “Spice-Server” wie auch der Dämon “libvirtd” sind dabei immer auf dem Virtualisierungs-Server (also dem KVM-Host) zu installieren. Zur Konfiguration der Protokoll-Einstellungen auf einem Linux-Remote-System, von dem aus die Spice-Clients “Spice Console des virt-managers” bzw. der stand-alone Spice-Client “remote-viewer” über ein Netz mit ihren Gegenparts auf dem Virtualisierungshost kommunizieren sollen, siehe
https://www.spice-space.org/spice-user-manual.html
bzw.
https://libvirt.org/docs.html
https://wiki.ubuntuusers.de/virt-manager/.
Virtualization-Administration-Guide von Red Hat für RHEL 6
Im virt-manager bietet der Punkt “File” > Add new connection” Felder zur Konfiguration einer Verbindung an. Spice kann über SSH getunnelt werden; für virt-manager wird eh’ qemu+ssh angeboten.
Wie einleitend festgestellt, werden uns in dieser Artikelserie zunächst mit einer Konfiguration, wie sie auf der Skizze dargestellt ist, begnügen. Spezielle Netzwerk-Einstellungen entfallen dann.
QXL-Treiber und spice-vdagent
Auf der rechten Seite der obigen Skizze erkennt man das virtuelle QXL-Device. Die Skizze deutet hier an, dass im Betriebssystem [OS] des Gastes zwei Komponenten erforderlich sind, um die notwendige Unterstützung zu liefern – ein Treiber und ein sogenannter “spice-vdagent”. Wir müssen uns nun mit deren Bereitstellung im Gastsystem befassen. Es gilt:
- Der qxl-Treiber ist, wie Video-Treiber für reale Karten auch, ein drm-fähiges Kernelmodul. “drm” steht dabei für “direct rendering manager”; https://de.wikipedia.org/ wiki/ Direct_Rendering_Manager).
- Der spice-vdagent wird dagegen als Dämon bereitgestellt und ist als Service zu aktivieren.
Versionsabhängigkeiten und Test-Setup
Leider muss ich vor weiteren Details vorausschicken, dass sowohl das Laden des qxl-Kernel-Moduls als auch die faktische Wirkungsweise von qxl-Treiber und spice-vdagent stark von der Art/Version des Linux-Gastsystems, dessen Kernel und zu allem Überfluss auch noch von der dortigen Desktop-Version abhängen. Ich nehme als Beispiel mal Debian 8 “Jessie”:
Unter dem ursprünglichen Kernel 3.16 von Jessie lässt sich das qxl-Modul nicht ohne weiteres laden. Es verlangt einen mir
unbekannten Parameter. In Installationen, die Debian-Backport-Pakete nutzen, wird ab Kernelversion 4.2 das qxl-Modul dagegen automatisch geladen. Ferner hat das Laden des qxl-Moduls – je nach Kernelversion und Desktop-Version unterschiedliche Auswirkungen auf automatische Auflösungsanpassungen. Ich komme darauf in einem weiteren Artikel zurück.
Wer die nachfolgend beschriebenen Punkte in einer konsistenten Weise nachvollziehen will, sollte bzgl. der Gastsysteme deshalb auf ein aktuelles Debian 9 (“Stretch”) (mit Gnome, KDE 5) oder aber ein Kali 2017 (mit Gnome) zurückgreifen. Diese Systeme bilden im Moment aus meiner Sicht den Sollzustand am besten ab.
Wählt man dagegen Opensuse Leap 42.2, so bitte mit Gnome. Mit debian-8-basierten Systemen, neueren Kernel-Versionen, unterschiedlichen libvirt/spice-Versionen aus Backport Repositories sowie mit dem offiziellen Plasma5-KDE5/KDE4-Mix unter Opensuse 42.1/42.2 kann es dagegen abweichende Resultate geben. “Red Hat”-Gastsysteme habe ich bislang nicht getestet.
Test-Setup
- KVM-Gast: Debian 9 “Stretch” (mit Gnome und KDE5) / Kali2017 (Gnome). Virtuelles Grafik-Device: QXL mit maximaler ram/vram-Bestückung.
- KVM-Host: Linux-Systeme mit Opensuse Leap 42.2 und dem dortigen KDE5/Plasma5/KDE4-Mix; darunter auch der im letzten Artikel angesprochene Laptop mit einem externen HDMI-Schirm.
- Grafischer Spice-Client für einen virtuellen Monitor: die “grafische Spice Konsole”, die in virt-manager integriert ist.
- Grafischer Spice-Client für mehrere virtuelle Monitore: “remote-viewer” (muss ggf. über das Paket “virt-viewer” nachinstalliert werden).
Bereitstellung QXL-Treiber im Gastsystem
Die Kapazitäten und die Performance einer Grafikkarte können nur mit einem geeigneten Treiber vollständig genutzt werden. Das ist für virtuelle Grafik-Devices wie das QXL-Device nicht anders.
Für einen KVM-Gast kann man in einem Spice-Client in jedem Fall Auflösungen bis zu 1024×768 erreichbar – auch wenn der device-spezifische QXL-Treiber im Gastystem gar nicht installiert ist. (Dies wird durch einen Fallback auf einen “standard vga”-Treiber bzw. ein VESA Framebuffer-Device ermöglicht.) Will man dagegen mit höheren Auflösungen arbeiten, so kann dies ggf. auch ohne QXL-Treiber funktonieren; allein aus Performancegründen lohnt es sich aber zu überprüfen, ob der QXL-Treiber im Gastsystem geladen ist:
root@deb11:~# lsmod | grep -iE "(video|qxl|drm)" qxl 69632 3 ttm 98304 1 qxl drm_kms_helper 155648 1 qxl drm 360448 6 qxl,ttm,drm_kms_helper
Falls das nicht der Fall sein sollte, muss man ggf. SW-Pakete nachinstallieren. Das Kernelmodul wird unter Debian über das Paket “xserver-xorg-video-qxl” bereitgestellt; unter Opensuse ist dagegen das Paket “xf86-video-qxl” erforderlich. (Zudem sollte “qemu-vgabios” installiert sein).
U.a. unter Opensuse Leap 42.2 lädt das Gastsystem den QXL-Treiber dann aber immer noch nicht zwingend automatisch. Das Modul ist in solchen Fällen also von Hand über “modprobe qxl” zu laden; den X-Server muss man dann neu starten. Ferner muss man sich darum kümmern, in welcher Weise man in seinem (Gast-) Betriebssystem dafür sorgen kann, dass Kernelmodule bereits beim Booten geladen werden:
Automatisches Laden des qxl-Kernelmoduls unter Opensuse Leap
Unter Opensuse kann man etwa “dracut -f” oder “mkinit” bemühen, nachdem man einer Datei “/etc/dracut.conf.d/01-dist.conf” einen Eintrag
force_drivers+=”qxl”
hinterlassen hat. Dabei wird das initramfs bemüht.
Alternativ und soweit systemd aktiv ist:
Im Verzeichnis “/etc/modules-load.d/” eine Datei “qxl.conf” anlegen und dort einfach “qxl” eintragen.
Als weitere Möglichkeit, die ich aber nicht getestet habe, legt man unter “/etc/X11/xorg.conf.d/50-device.conf” einen Eintrag der Form
Section "Device" Identifier "device0" Driver "qxl" EndSection
an.
Automatisches Laden des qxl-Kernelmoduls unter Debian
Unter Debian-Systemen nimmt man dagegen einfach einen Eintrag in der Datei “etc/modules” vor. Debian 9 lädt das qxl-Modul aber eh’ schon automatisch, wenn es erkennt, dass es unter KVM/QEMU virtualisiert läuft und ein QXL-Device vorhanden ist .
OS-unabhängig über einen systemd-Service
Persönlich finde ich eigentlich ein kleines eigenes Skript, das man mit einer Service-Datei (qxl.service) versieht, am besten. Dort kann man nämlich z.B. über “lspci” vorab analysieren, ob überhaupt ein QXL Device zur Verfügung steht. Ich gehe auf diese Lösung aus Platzgründen aber nicht weiter ein.
Für alle Varianten gilt: Der Treiber sollte jedenfalls geladen sein, bevor der X- oder Wayland-Server gestartet wurde.
Bedeutung und Aktivierung des spice-vdagent
Der sog. “spice-vdagent” hat/hatte mehrere wichtige Aufgaben; ich stelle sie mal nach meinem Verständnis dar:
- Kommunikations- und Event-Support: Der vdagent triggert und optimiert die Kommunikation zwischen dem Gast OS über den Spice-Server mit dem (remote) Spice-Client auf dem KVM-Host oder auf einem Remote-Host. U.a. werden Mouse-Positionen zwischen KVM-Gastsystem und Host abgeglichen und interpretiert – das ermöglicht u.a. ein nahtloses Verlassen von Spice-Fenstern auf dem Host.
- Copy/Paste: Der vdagent ermöglicht beidseitiges Copy/Paste zwischen Applikationen des (Remote-) Host-Systems, auf dem das Spice-Fenster zur Ansicht des Gast-Desktops läuft, und Applikationen des KVM-Gast-Systems.
- Multi-Monitor-Support: Er unterstützt im Zusammenspiel mit dem qxl-Treiber Gast-Systeme mit mehreren virtuellen Monitoren, deren Output in mehreren Spice-Remote-Viewer-Fenstern dargestellt werden kann. U.a. übernimmt er dabei das korrekte Mouse-Handling auf der Gast- wie der (Remote-) Host-Seite.
- Auflösungsanpassung: Er ermöglichte eine automatische Anpassung der Auflösung des Gast-Desktops an die gewählte Größe des Spice-Client-Fensters auf dem (Remote-) Host.
Hinweis: Das wird in aktuelleren Linux-Systemen aber wohl anders gemacht; s. hierzu den nächsten Artikel. - File-Transfer: Freigabe eines Zugriff des Gastsystems auf bestimmte Verzeichnisse des (Remote-) Hostes; File-Transfer mittels Drag & Drop
Man sieht: Der spice-vdagent hat etwa solche Aufgaben wie die “VMmware-Tools”, die in einem VMware-Gastsystem zu installieren sind.
Einen detaillierteren Überblick verschaffen die Web-Seiten https://www.spice-space.org/spice-user-manual.html#agent und https://www.spice-space.org/features.html
Die Platzierung des Agents im KVM-Gast und in der Kommunikationsstruktur entnimmt man der Skizze auf der Seite https://www.spice-space.org/index.html.
Die Nutzung des spice-vdagent erfordert bestimmte Voraussetzungen:
Vorbereitung der QEMU VM auf dem KVM-Host
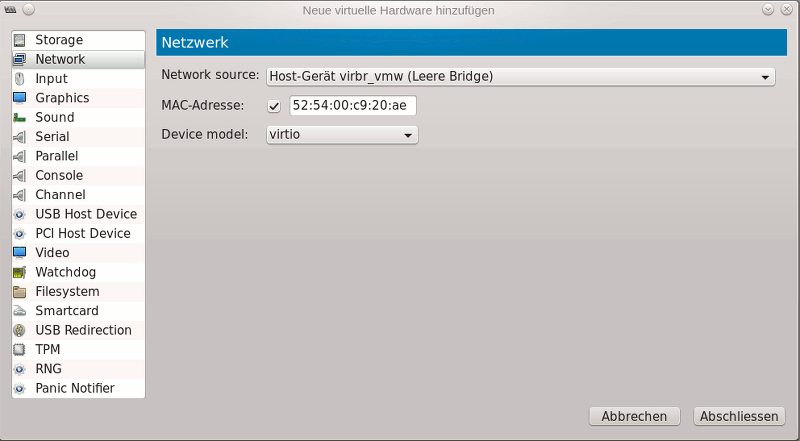
Der Einsatz des spice-vdagents erfordert bestimmte Features der virtuellen Maschine und zugehörige Startoptionen für die QEMU VM. So muss ein bestimmtes Serial-Device vorhanden sein (s. die Skizze oben) und ein Kommunikationskanal für den Spice-Agent reserviert werden (https://wiki.archlinux.org/ index.php/ QEMU#SPICE). Man kann sich einige händische Arbeit durch das Anlegen der virtuellen Maschinen (“Domänen” im QEMU-Slang) mittels “virt-manager” ersparen:
“virt-manager” gibt die notwendigen Features automatisch vor und konfiguriert die zugehörigen QEMU-Optionen für den Start der virtuellen Maschine.
Maßnahmen im Gast-OS
Der spice-vdagent ist als systemd-Service ausgelegt und kann als solcher im KVM-Gastsystem enabled (über den nächsten Reboot hinaus) und gestartet werden.
root@guest:~# systemctl enable spice-vdagentd.service root@guest:~# systemctl start spice-vdagentd.service
(Nachtrag 22.02.2018: Natürlich muss man den Agent erstmal installieren; hierzu nutzt man das Paket-Management des Gastsystems; unter Debian mittels “apt-get install spice-vdagent”. Um nach dem “Enablen” des zugehörigen Service z.B. Copy/Paste in beide (!) Richtungen zwischen Spiece-Konsole und der Umgebung ausführen zu können, muss man zudem die virtuelle Maschine und deren Konsole neu starten.)
Damit haben wir alles erledigt, was zur Performance-Optimierung, einer vernünftigen Mouse-Steuerung etc. notwendig war.
Einsatz von xrandr für unerkannte Auflösungsmodes im Gastsystem
Wir kommen nun wieder auf unser Laptop-Problem mit einer unerkannten Auflösung von 2560x1440_44Hz aus dem letzten Artikel zurück. Dort hatten wir bereits beschrieben, wie man den KVM-Host vorbereitet und die dort bislang unerkannte Auflösung auf einem externen HDMI1-Monitor mittels xrandr aktiviert. Wird dann die für den Host-Desktop bereitgestellte Auflösung auch auf dem Gastsystem automatisch erkannt?
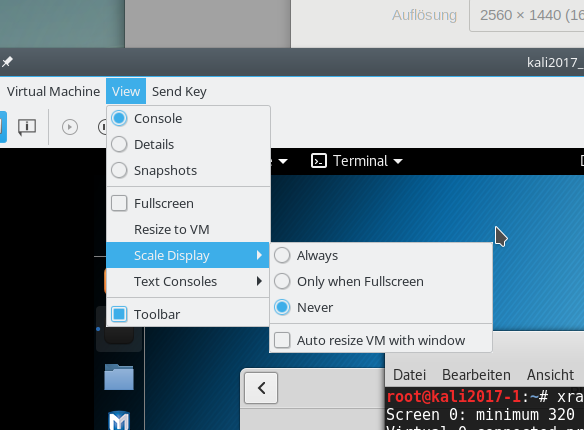
Wir starten über “virt-manager” z.B. einen “Kali2017”-Gast und betrachten ihn über die grafische Spice-Konsole des virt-managers auf dem HDMI-Monitor; dabei unterbinden wir zunächst eine automatische Skalierung der Gastauflösung (darauf kommen wir später zurück):
Leider bieten dann weder ein Kali2017- noch ein Debian-Stretch-Gast die maximal mögliche Auflösung an:
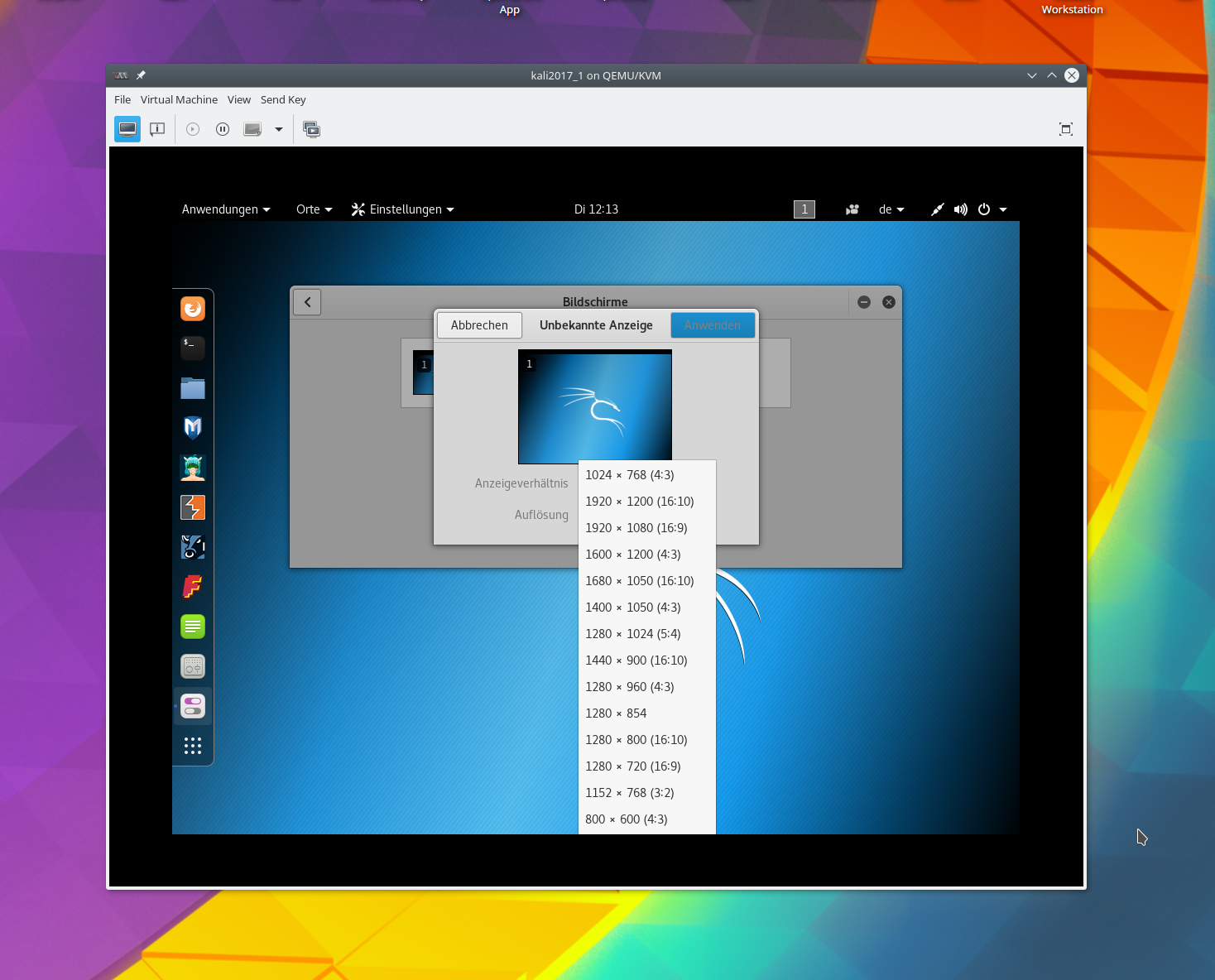
Der Einsatz des QXL-Treibers und des vdagents hat in dieser Hinsicht also nichts verbessert. Dass beide SW-Komponenten samt QXL-Device im Gastsystem vorhanden sind, belegt folgender Output:
root@kali2017-1:~# lsmod | grep qxl
qxl 69632 3
ttm 98304 1 qxl
drm_kms_helper 155648 1 qxl
drm 360448 6 qxl,ttm,drm_kms_helper
root@kali2017-1:~#
root@kali2017-1:~# systemctl status spice-vdagentd.service
● spice-vdagentd.service - Agent daemon for Spice guests
Loaded: loaded (/lib/systemd/system/spice-vdagentd.service; enabled; vendor p
Active: active (running) since Thu 2017-07-13 09:49:54 CEST; 5min ago
Process: 397 ExecStart=/usr/sbin/spice-vdagentd $SPICE_VDAGENTD_EXTRA_ARGS (co
Process: 390 ExecStartPre=/bin/rm -f /var/run/spice-vdagentd/spice-vdagent-soc
Main PID: 427 (spice-vdagentd)
Tasks: 1 (limit: 4915)
CGroup: /system.slice/spice-vdagentd.service
└─427 /usr/sbin/spice-vdagentd
root@kali2017-1:~# dmesg | grep drm
[ 2.272876] [drm] Initialized
[ 2.391864] [drm] Device Version 0.0
[ 2.391865] [drm] Compression level 0 log level 0
[ 2.391866] [drm] Currently using mode #0, list at 0x488
[ 2.391866] [drm] 114686 io pages at offset 0x4000000
[ 2.391867] [drm] 67108864 byte draw area at offset 0x0
[ 2.391867] [drm] RAM header offset: 0x1fffe000
[ 2.391868] [drm] rom modes offset 0x488 for 142 modes
[ 2.391916] [drm] qxl: 64M of VRAM memory size
[ 2.391917] [drm] qxl: 511M of IO pages memory ready (VRAM domain)
[ 2.391917] [drm] qxl: 512M of Surface memory size
[ 2.392479] [drm] main mem slot 1 [a0000000,1fffe000]
[ 2.392479] [drm] surface mem slot 2 [c0000000,20000000]
[ 2.392481] [drm] Supports vblank timestamp caching Rev 2 (21.10.2013).
[ 2.392482] [drm] No driver support for vblank timestamp query.
[ 2.392739] [drm] fb mappable at 0xA0000000, size 3145728
[ 2.392740] [drm] fb: depth 24, pitch 4096, width 1024, height 768
[ 2.392772] fbcon: qxldrmfb (fb0) is primary device
[ 2.405136] qxl 0000:00:02.0: fb0: qxldrmfb frame buffer device
[ 2.418839] [drm] Initialized qxl 0.1.0 20120117 for 0000:00:02.0 on minor 0
Hinweis:
Ob der spice-vdagent tatsächlich seinen Job tut, verifiziert man am einfachsten dadurch, indem man Copy/Paste-Übertragungen von Text zwischen Host- und Gast-System ausprobiert.
Einsatz von xrandr
Wir greifen im Gast nun zum gleichen Trick wie auf dem Host. Ein Absetzen des Befehls xrandr zeigt, dass der relevante (virtuelle) Monitor des Gastsystems “Virtual_0” heißt:
root@kali2017-1:~# xrandr Screen 0: minimum 320 x 200, current 1024 x 768, maximum 8192 x 8192 Virtual-0 connected primary 1024x768+0+0 0mm x 0mm 1024x768 59.92*+ 1920x1200 59.88 1920x1080 59.96 1600x1200 59.87 1680x1050 59.95 1400x1050 59.98 1280x1024 59.89 1440x900 59.89 1280x960 59.94 1280x854 59.89 1280x800 59.81 1280x720 59.86 1152x768 59.78 800x600 59.86 848x480 59.66 720x480 59.71 640x480 59.38 Virtual-1 disconnected Virtual-2 disconnected Virtual-3 disconnected
Also:
root@kali2017-1:~# cvt 2560 1440 44 # 2560x1440 43.99 Hz (CVT) hsync: 65.06 kHz; pclk: 222.75 MHz Modeline "2560x1440_44.00" 222.75 2560 2720 2992 3424 1440 1443 1448 1479 -hsync +vsync root@kali2017-1:~# xrandr --newmode 2560x1440_44 222.75 2560 2720 2992 3424 1440 1443 1448 1479 -hsync +vsync root@kali2017-1:~# xrandr --addmode Virtual-0 2560x1440_44 root@kali2017-1:~# xrandr --output Virtual-0 --mode 2560x1440_44
Und schon ist unsere gewünschte hohe Auflösung nach ein wenig Flackern im Spice-Fenster aktiv :
root@kali2017-1:~# xrandr --current Screen 0: minimum 320 x 200, current 2560 x 1440, maximum 8192 x 8192 Virtual-0 connected primary 2560x1440+0+0 0mm x 0mm 1024x768 59.92 + 1920x1200 59.88 1920x1080 59.96 1600x1200 59.87 1680x1050 59.95 1400x1050 59.98 1280x1024 59.89 1440x900 59.89 1280x960 59.94 1280x854 59.89 1280x800 59.81 1280x720 59.86 1152x768 59.78 800x600 59.86 848x480 59.66 720x480 59.71 640x480 59.38 2560x1440_44 43.99* Virtual-1 disconnected Virtual-2 disconnected Virtual-3 disconnected
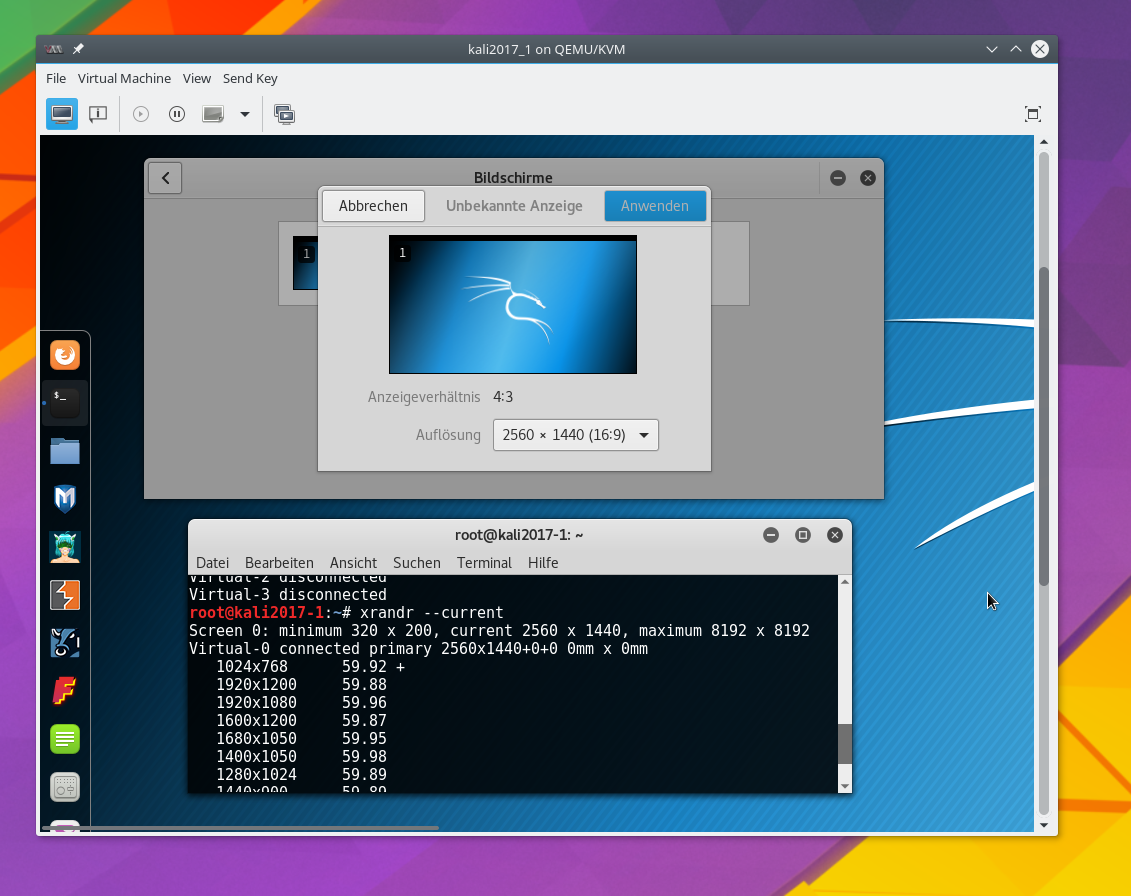
Das im Bildausschnitt erkennbare farbige Hintergrundsbild außerhalb der Spice-Konsole stammt vom KDE-Desktop des Opensuse-Hosts; es wurde für den HDMI-Schirm festgelegt. Man erkennt, dass das Fenster der grafischen Spice-Konsole Scrollbalken anbietet, wenn der aktuelle Fensterrahmen zu klein für die Auflösung des Gast-Desktops ist. Wegen meines GTK-Themes werden die Scrollbalken nur angezeigt, wenn die Maus dem jeweiligen Fensterrand nahe kommt. Deshalb ist im Bild nur der vertikale Balken sichtbar.
Natürlich kann man das Spice-Fenster auf dem externen HDMI-Monitor auch im Vollbild-Modus betreiben. Am einfachsten geht das, indem man die Fenstergröße an die Gastauflösung anpassen lässt; die Spice-Konsole bietet aber unter “View” zudem einen eigenen Menüpunkt zum Wechsel in den Vollbild-Modus an:
Mein HDMI-Schirm mit 2560×1440 zeigt dann folgendes Bild:

Genau das war aber unser erstes Ziel:
Wir können die hohe Auflösung eines physikalischen Host-Monitors, auf dem ein Spice-Client-Fenster im Vollbild-Modus läuft, nun für die Darstellung des Desktops eines unter KVM/QEMU virtualisierten Gastsystems nutzen.
Anzumerken bleibt auch, dass die Spice/QXL-Performance selbst mit der relativ schwachbrüstigen Intel HD4000, die in der Laptop-CPU integriert ist, völlig annehmbar ist. Zu verdanken ist das vor allem dem Einsatz des QXL-Treibers.
Ausblick
Im nächsten Artikel
KVM/qemu mit QXL – hohe Auflösungen und virtuelle Monitore im Gastsystem definieren und nutzen – III
befassen wir uns damit, wie man die mit CVT und xrandr gefundenen bzw. definierten Modes persistent im Gast-System hinterlegt, so dass sie auch einen Boot-Vorgang überstehen. Zudem wollen wir die Auflösung auch für den Display-Manager (etwa gdm3) hinterlegen. Danach wenden wir uns der Frage zu, ob und wie eine automatische Auflösungsanpassung an den Fensterrahmen der Spice-Clients möglich ist.