
Welcome back to this mini-series of posts on how we can search words in a vocabulary with the help of a few 3-char-grams. The sought words should fulfill the condition that they fit two or three selected 3-char-grams at certain positions of a given string-token:
Pandas dataframe, German vocabulary – select words by matching a few 3-char-grams – I
Pandas dataframe, German vocabulary – select words by matching a few 3-char-grams – II
In the first post we looked at general properties of a representative German vocabulary with respect to the distribution of 3-char-gram against their position in words. In my last post we learned from some experiments that we should use 3-char-grams with some positional distance between them. This will reduce the number of matching vocabulary words to a relatively small value – mostly below 10, often even below 5. Such a small number allows for a detailed analysis of the words. The analysis for selecting the best match may, among other more complicated things, involve a character to character comparison with the original string token or a distance measure in some word vector space.
My vocabulary resides in a Pandas dataframe. Pandas is often used as a RAM based data container in the context of text analysis tasks or data preparation for machine learning. In the present article I focus on the CPU-time required to find matching vocabulary words for 100,000 different tokens with the help of two or three selected 3-char-grams. So, this is basically about the CPU-time for requests which put conditions on a few columns of a medium sized Pandas dataframe.
I will distinguish between searches for words with a length ≤ 9 characters and searches for longer words. Whilst processing the data I will also calculate the resulting average number of words in the hit list of matching words.
A simplifying approach
So, our 3-char-grams for comparison are correctly written. In real data analysis experiments for string tokens of a given text collection the situation may be different – just wait for future posts. You may then have to vary the 3-char-gram positions to get a hit list at all. But even for correct 3-grams we already know from previous experiments that the hit list, understandably, often enough contains more than just one word.
For words ≤ 9 letters we use two 3-char-grams, for longer words three 3-char-grams. We process 7 runs in each case. The runs are different
regarding the choice of the 3-char-grams’ positions within the tokens; see the code in the sections below for the differences in the positions.
My selections of the positions of the 3-char-grams within the word follow mainly the strategy of relatively big distances between the 3-char-grams. This strategy was the main result of the last post. We also follow another insight which we got there:
For each token we use the length information, i.e. we work on a pre-defined slice of the dataframe containing only words of the same length as the token. (In the case of real life tokens you may have to vary the length parameters for different search attempts if you have reason to assume that the token is misspelled.)
I perform all test runs on a relatively old i7-6700K CPU.
Predefined slices of the vocabulary for words with a given length
We first create slices for words of a certain length and put the addresses into a dictionary:
# Create vocab slices for all word-lengths
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~--------------
b_exact_len = True
li_min = []
li_df = []
d_df = {}
for i in range(4,57):
li_min.append(i)
len_li = len(li_min)
for i in range(0, len_li-1):
mil = li_min[i]
if b_exact_len:
df_x = dfw_uml.loc[(dfw_uml['len'] == mil)]
df_x = df_x.iloc[:, 2:]
li_df.append(df_x)
key = "df_" + str(mil)
d_df[key] = df_x
else:
mal = li_min[i+1]
df_x = dfw_uml.loc[(dfw_uml['len'] >= mil) & (dfw_uml['len']< mal)]
df_x = df_x.iloc[:, 2:]
li_df.append(df_x)
key = "df_" + str(mil) + str(mal -1)
d_df[key] = df_x
print("Fertig: len(li_df) = ", len(li_df), " : len(d_df) = ", len(d_df))
li_df[12].head(5)
Giving e.g:

Dataframe with words longer than 9 letters
We then create a sub-dataframe containing words with “10 ≤ word-length < 30“. Reason: We know from a previous post that this selection covers most of the longer words in the vocabulary.
#****************************************************** # Reduce the vocab to strings in a certain length range # => Build dfw_short3 for long words and dfw_short2 for short words #****************************************************** # we produce two dfw_short frames: # - one for words with length >= 10 => 3-char-grams # - one for words with length <= 9 => 2-char-grams # Parameters # ~~~~~~~~~~~ min_3_len = 10 max_3_len = 30 min_2_len = 4 max_2_len = 9 mil_3 = min_3_len - 1 mal_3 = max_3_len + 1 max_3_col = max_3_len + 4 dfw_short3 = dfw_uml.loc[(dfw_uml.lower.str.len() > mil_3) & (dfw_uml.lower.str.len() < mal_3)] dfw_short3 = dfw_short3.iloc[:, 2:max_3_col] mil_2 = min_2_len - 1 mal_2 = max_2_len + 1 max_2_col = max_2_len + 4 dfw_short2 = dfw_uml.loc[(dfw_uml.lower.str.len() > mil_2) & (dfw_uml.lower.str.len() < mal_2)] dfw_short2 = dfw_short2.iloc[:, 2:max_2_col] print(len(dfw_short3)) print() dfw_short3.head(8)
This gives us a list of around 2.5 million words (out of 2.7 million) in “dfw_short3”. The columns are “len” (containing the length), lower (containing the lower case version of a word) and columns for 3-char-grams from position 0 to 29:
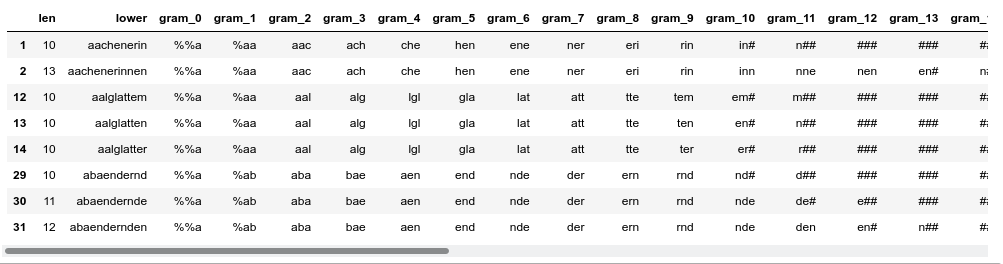
nThe first 3-char-gram residing completely within the word is at column “gram_2”. We have used left- and right-padding 3-char-grams; see a previous post for this point.
The corresponding “dfw_short2” for words with a length below 10 characters is much shorter; it contains around 186000 words only.
A function to get a hit list of words matching two or three 3-char-grams
For our experiment I use the following (quick and dirty) function get_fit_words_3_grams() to select the right slice of the vocabulary and perform the search for words matching three 3-char-grams of longer string tokens:
def get_fit_words_3_grams(dfw, len_w, j, pos_l=-1, pos_m=-1, pos_r=-1, b_std_pos = True):
# dfw: source df for tokens)
# j: row position of token in dfw (not index-label)
b_analysis = False
try:
dfw
except NameError:
print("dfw not defined ")
# get token length
#len_w = dfw.iat[j,0]
#word = dfw.iat[j, 1]
# get the right slice of the vocabulary with words corresponding to the length
df_name = "df_" + str(len_w)
df_ = d_df[df_name]
if b_std_pos:
j_l = 2
j_m = math.floor(len_w/2)+1
j_r = len_w - 1
j_rm = j_m + 2
else:
if pos_l==-1 or pos_m == -1 or pos_r == -1 or pos_m >= pos_r:
print("one or all of the positions is not defined or pos_m >= pos_r")
sys.exit()
j_l = pos_l
j_m = pos_m
j_r = pos_r
if pos_m >= len_w+1 or pos_r >= len_w+2:
print("Positions exceed defined positions of 3-char-grams for the token (len= ", len_w, ")")
sys.exit()
col_l = 'gram_' + str(j_l); val_l = dfw.iat[j, j_l+2]
col_m = 'gram_' + str(j_m); val_m = dfw.iat[j, j_m+2]
col_r = 'gram_' + str(j_r); val_r = dfw.iat[j, j_r+2]
#print(len_w, ":", word, ":", j_l, ":", j_m, ":", j_r, ":", val_l, ":", val_m, ":", val_r )
li_ind = df_.index[ (df_[col_r]==val_r)
#& (df_[col_rm]==val_rm)
& (df_[col_m]==val_m)
& (df_[col_l]==val_l)
].to_list()
if b_analysis:
leng_li = len(li_ind)
if leng_li >90:
print("!!!!")
for m in range(0, leng_li):
print(df_.loc[li_ind[m], 'lower'])
print("!!!!")
#print(word, ":", leng_li, ":", len_w, ":", j_l, ":", j_m, ":", j_r, ":", val_l, ":", val_m, ":", val_r)
return len(li_ind), len_w
For “b_std_pos == True” all 3-char-grams reside completely within the word with a maximum distance to each other.
An analogous function “get_fit_words_2_grams(dfw, len_w, j, pos_l=-1, pos_r=-1, b_std_pos = True)” basically does the same but for a chosen left and a right positioned 3-char-gram, only. The latter function is to be applied for words with a length ≤ 9.
Function to perform the test runs
A quick and dirty function to perform the planned different test runs is
# Check for 100,000 words, how long the index list is for conditions on three 3-gram_cols or two 3-grams
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#Three 3-char-grams or two 3-char-grams?
b_3 = True
# parameter
num_w = 100000
#num_w = 50000
n_start = 0
n_end = n_start + num_w
# run type
b_random = True
pos_type = 0
#pos_type = 1
#pos_type = 2
#pos_type = 3
#pos_type = 4
#pos_type = 5
#pos_type = 6
#pos_type = 7
if b_3:
len_
dfw = len(dfw_short3)
else:
len_dfw = len(dfw_short2)
print("len dfw_short2 = ", len_dfw)
if b_random:
random.seed()
li_ind_w = random.sample(range(0, len_dfw), num_w)
else:
li_ind_w = list(range(n_start, n_end, 1))
#print(li_ind_w)
if n_start+num_w > len_dfw:
print("Error: wrong choice of params ")
sys.exit
ay_inter_lilen = np.zeros((num_w,), dtype=np.int16)
ay_inter_wolen = np.zeros((num_w,), dtype=np.int16)
v_start_time = time.perf_counter()
n = 0
for i in range(0, num_w):
ind = li_ind_w[i]
if b_3:
leng_w = dfw_short3.iat[ind,0]
else:
leng_w = dfw_short2.iat[ind,0]
#print(ind, leng_w)
# adapt pos_l, pos_m, pos_r
# ************************
if pos_type == 1:
pos_l = 3
pos_m = math.floor(leng_w/2)+1
pos_r = leng_w - 1
elif pos_type == 2:
pos_l = 2
pos_m = math.floor(leng_w/2)+1
pos_r = leng_w - 2
elif pos_type == 3:
pos_l = 4
pos_m = math.floor(leng_w/2)+2
pos_r = leng_w - 1
elif pos_type == 4:
pos_l = 2
pos_m = math.floor(leng_w/2)
pos_r = leng_w - 3
elif pos_type == 5:
pos_l = 5
pos_m = math.floor(leng_w/2)+2
pos_r = leng_w - 1
elif pos_type == 6:
pos_l = 2
pos_m = math.floor(leng_w/2)
pos_r = leng_w - 4
elif pos_type == 7:
pos_l = 3
pos_m = math.floor(leng_w/2)
pos_r = leng_w - 2
# 3-gram check
if b_3:
if pos_type == 0:
leng, lenw = get_fit_words_3_grams(dfw_short3, leng_w, ind, 0, 0, 0, True)
else:
leng, lenw = get_fit_words_3_grams(dfw_short3, leng_w, ind, pos_l, pos_m, pos_r, False)
else:
if pos_type == 0:
leng, lenw = get_fit_words_2_grams(dfw_short2, leng_w, ind, 0, 0, True)
else:
leng, lenw = get_fit_words_2_grams(dfw_short2, leng_w, ind, pos_l, pos_r, False)
ay_inter_lilen[n] = leng
ay_inter_wolen[n] = lenw
#print (leng)
n += 1
v_end_time = time.perf_counter()
cpu_time = v_end_time - v_start_time
num_tokens = len(ay_inter_lilen)
mean_hits = ay_inter_lilen.mean()
max_hits = ay_inter_lilen.max()
if b_random:
print("cpu : ", "{:.2f}".format(cpu_time), " :: tokens =", num_tokens,
" :: mean =", "{:.2f}".format(mean_hits), ":: max =", "{:.2f}".format(max_hits) )
else:
print("n_start =", n_start, " :: cpu : ", "{:.2f}".format(cpu_time), ":: tokens =", num_tokens,
":: mean =", "{:.2f}".format(mean_hits), ":: max =", "{:.2f}".format(max_hits) )
print()
print(ay_inter_lilen)
Test runs for words with a length ≥ 10 and three 3-char-grams
Pandas runs per default on just one CPU core. Typical run times are around 76 secs depending a bit on the background load on my Linux PC. Outputs for 3 consecutive runs for “b_random = True” runs and different “pos_type”-values and are
“b_random = True” and “pos_type = 0”
cpu : 75.82 :: tokens = 100000 :: mean = 1.25 :: max = 91.00 cpu : 75.40 :: tokens = 100000 :: mean = 1.25 :: max = 91.00 cpu : 75.43 :: tokens = 100000 :: mean = 1.25 :: max = 91.00
The average value “mean” for the length of the hit list is quite small. But there obviously are a few tokens for which the hit list is quite long (max-value > 90). We shall see below that the surprisingly large value of the maximum is only due to words in two specific regions of the vocabulary.
The next section for “pos_type = 1” shows a better behavior:
“b_random = True” and “pos_type = 1”
n
cpu : 75.23 :: tokens = 100000 :: mean = 1.18 :: max = 27.00 cpu : 76.39 :: tokens = 100000 :: mean = 1.18 :: max = 24.00 cpu : 75.95 :: tokens = 100000 :: mean = 1.17 :: max = 27.00
The next position variation again suffers from words in the same regions of the vocabulary where we got problems already for pos_type = 0:
“b_random = True” and “pos_type = 2”
cpu : 75.07 :: tokens = 100000 :: mean = 1.28 :: max = 52.00 cpu : 75.57 :: tokens = 100000 :: mean = 1.28 :: max = 52.00 cpu : 75.78 :: tokens = 100000 :: mean = 1.28 :: max = 52.00
The next positional variation shows a much lower max-value; the mean value is convincing:
“b_random = True” and “pos_type = 3”
cpu : 74.70 :: tokens = 100000 :: mean = 1.21 :: max = 23.00 cpu : 74.78 :: tokens = 100000 :: mean = 1.22 :: max = 23.00 cpu : 74.48 :: tokens = 100000 :: mean = 1.22 :: max = 24.00
“b_random = True” and “pos_type = 4”
cpu : 75.18 :: tokens = 100000 :: mean = 1.27 :: max = 52.00 cpu : 75.45 :: tokens = 100000 :: mean = 1.26 :: max = 52.00 cpu : 74.65 :: tokens = 100000 :: mean = 1.27 :: max = 52.00
For “pos_type = 5” we get again worse results for the average values:
“b_random = True” and “pos_type = 5”
cpu : 74.21 :: tokens = 100000 :: mean = 1.70 :: max = 49.00 cpu : 74.95 :: tokens = 100000 :: mean = 1.71 :: max = 49.00 cpu : 74.28 :: tokens = 100000 :: mean = 1.70 :: max = 49.00
“b_random = True” and “pos_type = 6”
cpu : 74.21 :: tokens = 100000 :: mean = 1.49 :: max = 31.00 cpu : 74.16 :: tokens = 100000 :: mean = 1.49 :: max = 28.00 cpu : 74.21 :: tokens = 100000 :: mean = 1.50 :: max = 31.00
“b_random = True” and “pos_type = 7”
cpu : 75.02 :: tokens = 100000 :: mean = 1.28 :: max = 34.00 cpu : 74.19 :: tokens = 100000 :: mean = 1.28 :: max = 34.00 cpu : 73.56 :: tokens = 100000 :: mean = 1.28 :: max = 34.00
The data for the mean number of matching words are overall consistent with our general considerations and observations in the previous post of this article series. The CPU-times are very reasonable – even if we had to perform 5 different 3-char-gram requests per token we could do this within 6,5 to 7 minutes.
A bit worrying is the result for the maximum of the hit-list length. The next section will show that the max-values above stem from some words in two distinct sections of the vocabulary.
Data for certain regions of the vocabulary
It is always reasonable to look a bit closer at different regions of the vocabulary. Therefore, we repeat some runs – but this time not for random data, but for 100,000 tokens following a certain start-position in the alphabetically sorted vocabulary:
“b_random = False” and “pos_type = 0” and num_w = 50,000
n_start = 0 :: tokens = 50000 :: mean = 1.10 :: max = 10 n_start = 50000 :: tokens = 50000 :: mean = 1.15 :: max = 14 n_start = 100000 :: tokens = 50000 :: mean = 1.46 :: max = 26 n_start = 150000 :: tokens = 50000 :: mean = 1.25 :: max = 26 n_start = 200000 :: tokens = 50000 :: mean = 1.30 :: max = 14 n_start = 250000 :: tokens = 50000 :: mean = 1.15 :: max = 20 n_start = 300000 :: tokens = 50000 :: mean = 1.10 :: max = 13 n_start = 350000 :: tokens = 50000 :: mean = 1.07 :: max = 6 n_start = 400000 :: tokens = 50000 :: mean = 1.11 :: max = 12 n_start = 450000 :: tokens = 50000 :: mean = 1.28 :: max = 14 n_start = 500000 :: tokens = 50000 :: mean = 1.38 :: max = 20 n_start = 550000 :: tokens = 50000 :: mean = 1.12 :: max = 15 n_start = 600000 :: tokens = 50000 :: mean = 1. 11 :: max = 11 n_start = 650000 :: tokens = 50000 :: mean = 1.18 :: max = 16 n_start = 700000 :: tokens = 50000 :: mean = 1.12 :: max = 17 n_start = 750000 :: tokens = 50000 :: mean = 1.20 :: max = 19 n_start = 800000 :: tokens = 50000 :: mean = 1.32 :: max = 21 n_start = 850000 :: tokens = 50000 :: mean = 1.13 :: max = 13 n_start = 900000 :: tokens = 50000 :: mean = 1.11 :: max = 9 n_start = 950000 :: tokens = 50000 :: mean = 1.15 :: max = 14 n_start = 1000000 :: tokens = 50000 :: mean = 1.21 :: max = 25 n_start = 1050000 :: tokens = 50000 :: mean = 1.08 :: max = 7 n_start = 1100000 :: tokens = 50000 :: mean = 1.08 :: max = 10 n_start = 1150000 :: tokens = 50000 :: mean = 1.32 :: max = 20 n_start = 1200000 :: tokens = 50000 :: mean = 1.14 :: max = 18 n_start = 1250000 :: tokens = 50000 :: mean = 1.15 :: max = 14 n_start = 1300000 :: tokens = 50000 :: mean = 1.10 :: max = 12 n_start = 1350000 :: tokens = 50000 :: mean = 1.14 :: max = 13 n_start = 1400000 :: tokens = 50000 :: mean = 1.09 :: max = 11 n_start = 1450000 :: tokens = 50000 :: mean = 1.12 :: max = 12 n_start = 1500000 :: tokens = 50000 :: mean = 1.15 :: max = 33 n_start = 1550000 :: tokens = 50000 :: mean = 1.15 :: max = 19 n_start = 1600000 :: tokens = 50000 :: mean = 1.27 :: max = 28 n_start = 1650000 :: tokens = 50000 :: mean = 1.10 :: max = 11 n_start = 1700000 :: tokens = 50000 :: mean = 1.13 :: max = 15 n_start = 1750000 :: tokens = 50000 :: mean = 1.23 :: max = 57 n_start = 1800000 :: tokens = 50000 :: mean = 1.79 :: max = 57 n_start = 1850000 :: tokens = 50000 :: mean = 1.44 :: max = 57 n_start = 1900000 :: tokens = 50000 :: mean = 1.17 :: max = 20 n_start = 1950000 :: tokens = 50000 :: mean = 1.24 :: max = 19 n_start = 2000000 :: tokens = 50000 :: mean = 1.31 :: max = 19 n_start = 2050000 :: tokens = 50000 :: mean = 1.08 :: max = 19 n_start = 2100000 :: tokens = 50000 :: mean = 1.12 :: max = 17 n_start = 2150000 :: tokens = 50000 :: mean = 1.24 :: max = 27 n_start = 2200000 :: tokens = 50000 :: mean = 2.39 :: max = 91 n_start = 2250000 :: tokens = 50000 :: mean = 2.76 :: max = 91 n_start = 2300000 :: tokens = 50000 :: mean = 1.14 :: max = 10 n_start = 2350000 :: tokens = 50000 :: mean = 1.17 :: max = 12 n_start = 2400000 :: tokens = 50000 :: mean = 1.18 :: max = 21 n_start = 2450000 :: tokens = 50000 :: mean = 1.16 :: max = 24
These data are pretty consistent with the random approach. We see that there are some intervals were the hit list gets bigger – but on average not bigger than 3.
However, we learn something important here:
In all segments of the vocabulary there are some relatively few words for which our recipe of distanced 3-car-grams nevertheless leads to long hit lists.
This is also reflected by the data for other positional distributions of the 3-char-grams:
“b_random = False” and “pos_type = 1” and num_w = 50,000
n_start = 0 :: tokens = 50000 :: mean = 1.08 :: max = 10 n_start = 50000 :: tokens = 50000 :: mean = 1.14 :: max = 14 n_start = 100000 :: tokens = 50000 :: mean = 1.16 :: max = 13 n_start = 150000 :: tokens = 50000 :: mean = 1.17 :: max = 16 n_start = 200000 :: tokens = 50000 :: mean = 1.24 :: max = 15 n_start = 250000 :: tokens = 50000 :: mean = 1.15 :: max = 20 n_start = 300000 :: tokens = 50000 :: mean = 1.12 :: max = 12 n_start = 350000 :: tokens = 50000 :: mean = 1.13 :: max = 13 n_start = 400000 :: tokens = 50000 :: mean = 1.13 :: max = 18 n_start = 450000 :: tokens = 50000 :: mean = 1.12 :: max = 10 n_start = 500000 :: tokens = 50000 :: mean = 1.20 :: max = 18 n_start = 550000 :: tokens = 50000 :: mean = 1.15 :: max = 19 n_start = 600000 :: tokens = 50000 :: mean = 1.13 :: max = 14 n_start = 650000 :: tokens = 50000 :: mean = 1.17 :: max = 18 n_start = 700000 :: tokens = 50000 :: mean = 1.15 :: max = 12 n_start = 750000 :: tokens = 50000 :: mean = 1.20 :: max = 16 n_start = 800000 :: tokens = 50000 :: mean = 1.30 :: max = 21 n_start = 850000 :: tokens = 50000 :: mean = 1.13 :: max = 13 n_start = 900000 :: tokens = 50000 :: mean = 1.14 :: max = 13 n_start = 950000 :: tokens = 50000 :: mean = 1.16 :: max = 14 n_start = 1000000 :: tokens = 50000 :: mean = 1.22 :: max = 25 n_start = 1050000 :: tokens = 50000 :: mean = 1.12 :: max = 14 n_start = 1100000 :: tokens = 50000 :: mean = 1.11 :: max = 12 n_start = 1150000 :: tokens = 50000 :: mean = 1.24 :: max = 16 n_start = 1200000 :: tokens = 50000 :: mean = 1.14 :: max = 18 n_start = 1250000 :: tokens = 50000 :: mean = 1.25 :: max = 15 n_start = 1300000 :: tokens = 50000 :: mean = 1.16 :: max = 15 n_start = 1350000 :: tokens = 50000 :: mean = 1.17 :: max = 14 n_start = 1400000 :: tokens = 50000 :: mean = 1.10 :: max = 10 n_start = 1450000 :: tokens = 50000 :: mean = 1.16 :: max = 21 n_start = 1500000 :: tokens = 50000 :: mean = 1.18 :: max = 33 n_start = 1550000 :: tokens = 50000 :: mean = 1.17 :: max = 20 n_start = 1600000 :: tokens = 50000 :: mean = 1.15 :: max = 14 n_start = 1650000 :: tokens = 50000 :: mean = 1.16 :: max = 12 n_start = 1700000 :: tokens = 50000 :: mean = 1.17 :: max = 15 n_start = 1750000 :: tokens = 50000 :: mean = 1.16 :: max = 12 n_start = 1800000 :: tokens = 50000 :: mean = 1.20 :: max = 14 n_start = 1850000 :: tokens = 50000 :: mean = 1.17 :: max = 13 n_start = 1900000 :: tokens = 50000 :: mean = 1.17 :: max = 20 n_start = 1950000 :: tokens = 50000 :: mean = 1.07 :: max = 11 n_start = 2000000 :: tokens = 50000 :: mean = 1.13 :: max = 15 n_start = 2050000 :: tokens = 50000 :: mean = 1.10 :: max = 8 n_start = 2100000 :: tokens = 50000 :: mean = 1.15 :: max = 17 n_start = 2150000 :: tokens = 50000 :: mean = 1.27 :: max = 27 n_start = 2200000 :: tokens = 50000 :: mean = 1.47 :: max = 24 n_start = 2250000 :: tokens = 50000 :: mean = 1.34 :: max = 22 n_start = 2300000 :: tokens = 50000 :: mean = 1.18 :: max = 12 n_start = 2350000 :: tokens = 50000 :: mean = 1.19 :: max = 14 n_start = 2400000 :: tokens = 50000 :: mean = 1.25 :: max = 21 n_start = 2450000 :: tokens = 50000 :: mean = 1.17 :: max = 25
“b_random = False” and “pos_type = 2” and num_w = 50,000
n_start = 0 :: tokens = 50000 :: mean = 1.25 :: max = 11 n_start = 50000 :: tokens = 50000 :: mean = 1.25 :: max = 8 n_start = 100000 :: tokens = 50000 :: mean = 1.50 :: max = 18 n_start = 150000 :: tokens = 50000 :: mean = 1.25 :: max = 18 n_start = 200000 :: tokens = 50000 :: mean = 1.36 :: max = 15 n_start = 250000 :: tokens = 50000 :: mean = 1.19 :: max = 13 n_start = 300000 :: tokens = 50000 :: mean = 1.15 :: max = 7 n_start = 350000 :: tokens = 50000 :: mean = 1.15 :: max = 6 n_start = 400000 :: tokens = 50000 :: mean = 1.18 :: max = 9 n_start = 450000 :: tokens = 50000 :: mean = 1.36 :: max = 15 n_start = 500000 :: tokens = 50000 :: mean = 1.39 :: max = 14 n_start = 550000 :: tokens = 50000 :: mean = 1.20 :: max = 15 n_start = 600000 :: tokens = 50000 :: mean = 1.16 :: max = 6 n_start = 650000 :: tokens = 50000 :: mean = 1.21 :: max = 8 n_start = 700000 :: tokens = 50000 :: mean = 1.18 :: max = 8 n_start = 750000 :: tokens = 50000 :: mean = 1.27 :: max = 12 n_start = 800000 :: tokens = 50000 :: mean = 1.32 :: max = 13 n_start = 850000 :: tokens = 50000 :: mean = 1.18 :: max = 8 n_start = 900000 :: tokens = 50000 :: mean = 1.17 :: max = 8 n_start = 950000 :: tokens = 50000 :: mean = 1.25 :: max = 10 n_start = 1000000 :: tokens = 50000 :: mean = 1.22 :: max = 11 n_start = 1050000 :: tokens = 50000 :: mean = 1.15 :: max = 8 n_start = 1100000 :: tokens = 50000 :: mean = 1.15 :: max = 6 r n_start = 1150000 :: tokens = 50000 :: mean = 1.29 :: max = 15 n_start = 1200000 :: tokens = 50000 :: mean = 1.17 :: max = 7 n_start = 1250000 :: tokens = 50000 :: mean = 1.17 :: max = 8 n_start = 1300000 :: tokens = 50000 :: mean = 1.16 :: max = 9 n_start = 1350000 :: tokens = 50000 :: mean = 1.18 :: max = 8 n_start = 1400000 :: tokens = 50000 :: mean = 1.17 :: max = 8 n_start = 1450000 :: tokens = 50000 :: mean = 1.17 :: max = 7 n_start = 1500000 :: tokens = 50000 :: mean = 1.17 :: max = 9 n_start = 1550000 :: tokens = 50000 :: mean = 1.17 :: max = 7 n_start = 1600000 :: tokens = 50000 :: mean = 1.31 :: max = 24 n_start = 1650000 :: tokens = 50000 :: mean = 1.18 :: max = 9 n_start = 1700000 :: tokens = 50000 :: mean = 1.17 :: max = 13 n_start = 1750000 :: tokens = 50000 :: mean = 1.26 :: max = 21 n_start = 1800000 :: tokens = 50000 :: mean = 1.70 :: max = 21 n_start = 1850000 :: tokens = 50000 :: mean = 1.43 :: max = 21 n_start = 1900000 :: tokens = 50000 :: mean = 1.19 :: max = 10 n_start = 1950000 :: tokens = 50000 :: mean = 1.30 :: max = 11 n_start = 2000000 :: tokens = 50000 :: mean = 1.33 :: max = 11 n_start = 2050000 :: tokens = 50000 :: mean = 1.16 :: max = 8 n_start = 2100000 :: tokens = 50000 :: mean = 1.17 :: max = 9 n_start = 2150000 :: tokens = 50000 :: mean = 1.41 :: max = 20 n_start = 2200000 :: tokens = 50000 :: mean = 2.08 :: max = 52 n_start = 2250000 :: tokens = 50000 :: mean = 2.27 :: max = 52 n_start = 2300000 :: tokens = 50000 :: mean = 1.21 :: max = 11 n_start = 2350000 :: tokens = 50000 :: mean = 1.21 :: max = 10 n_start = 2400000 :: tokens = 50000 :: mean = 1.21 :: max = 9 n_start = 2450000 :: tokens = 50000 :: mean = 1.30 :: max = 18
“b_random = False” and “pos_type = 3” and num_w = 50,000
n_start = 0 :: tokens = 50000 :: mean = 1.23 :: max = 23 n_start = 50000 :: tokens = 50000 :: mean = 1.25 :: max = 17 n_start = 100000 :: tokens = 50000 :: mean = 1.16 :: max = 17 n_start = 150000 :: tokens = 50000 :: mean = 1.22 :: max = 15 n_start = 200000 :: tokens = 50000 :: mean = 1.22 :: max = 17 n_start = 250000 :: tokens = 50000 :: mean = 1.18 :: max = 11 n_start = 300000 :: tokens = 50000 :: mean = 1.27 :: max = 23 n_start = 350000 :: tokens = 50000 :: mean = 1.29 :: max = 23 n_start = 400000 :: tokens = 50000 :: mean = 1.14 :: max = 11 n_start = 450000 :: tokens = 50000 :: mean = 1.18 :: max = 17 n_start = 500000 :: tokens = 50000 :: mean = 1.16 :: max = 15 n_start = 550000 :: tokens = 50000 :: mean = 1.26 :: max = 17 n_start = 600000 :: tokens = 50000 :: mean = 1.20 :: max = 13 n_start = 650000 :: tokens = 50000 :: mean = 1.10 :: max = 9 n_start = 700000 :: tokens = 50000 :: mean = 1.20 :: max = 17 n_start = 750000 :: tokens = 50000 :: mean = 1.17 :: max = 17 n_start = 800000 :: tokens = 50000 :: mean = 1.28 :: max = 19 n_start = 850000 :: tokens = 50000 :: mean = 1.15 :: max = 15 n_start = 900000 :: tokens = 50000 :: mean = 1.19 :: max = 11 n_start = 950000 :: tokens = 50000 :: mean = 1.19 :: max = 13 n_start = 1000000 :: tokens = 50000 :: mean = 1.24 :: max = 24 n_start = 1050000 :: tokens = 50000 :: mean = 1.17 :: max = 10 n_start = 1100000 :: tokens = 50000 :: mean = 1.29 :: max = 23 n_start = 1150000 :: tokens = 50000 :: mean = 1.18 :: max = 13 n_start = 1200000 :: tokens = 50000 :: mean = 1.18 :: max = 16 n_start = 1250000 :: tokens = 50000 :: mean = 1.38 :: max = 23 n_start = 1300000 :: tokens = 50000 :: mean = 1.30 :: max = 23 n_start = 1350000 :: tokens = 50000 :: mean = 1.21 :: max = 15 n_start = 1400000 :: tokens = 50000 :: mean = 1.21 :: max = 23 n_start = 1450000 :: tokens = 50000 :: mean = 1.23 :: max = 12 n_start = 1500000 :: tokens = 50000 :: mean = 1.21 :: max = 13 n_start = 1550000 :: tokens = 50000 :: mean = 1.22 :: max = 12 n_start = 1600000 :: tokens = 50000 :: mean = 1.12 :: max = 13 n_start = 1650000 :: tokens = 50000 :: mean = 1.27 :: max = 16 n_start = 1700000 :: tokens = 50000 :: mean = 1.23 :: max = 15 n_start = 1750000 :: tokens = 50000 :: mean = 1.26 :: max = 11 n_start = 1800000 :: tokens = 50000 :: mean = 1.08 :: max = 7 n_start = 1850000 :: tokens = 50000 :: mean = 1.11 :: max = 12 n_start = 1900000 :: tokens = 50000 :: mean = 1.26 :: max = 23 n_start = 1950000 :: tokens = 50000 :: mean = 1.06 :: max = 9 n_start = 2000000 :: tokens = 50000 :: mean = 1.11 :: max = 15 n_start = 2050000 :: tokens = 50000 :: mean = 1.16 :: max = 16 n_start = 2100000 :: tokens = 50000 :: mean = 1.17 :: max = 13 n_start = 2150000 :: tokens = 50000 :: mean = 1.33 :: max = 16 n_start = 2200000 :: tokens = 50000 :: mean = 1.29 :: max = 24 n_start = 2250000 :: tokens = 50000 :: mean = 1.20 :: max = 17 n_start = 2300000 :: tokens = 50000 :: mean = 1.35 :: max = 17 n_start = 2350000 :: tokens = 50000 :: mean = 1.25 :: max = 12 n_start = 2400000 :: tokens = 50000 :: mean = 1.26 :: max = 16 n_start = 2450000 :: tokens = 50000 :: mean = 1.29 :: max = 13
“b_random = False” and “pos_type = 4” and num_w = 50,000
n_start = 0 :: tokens = 50000 :: mean = 1.25 :: max = 6 n_start = 50000 :: tokens = 50000 :: mean = 1.27 :: max = 9 n_start = 100000 :: tokens = 50000 :: mean = 1.43 :: max = 19 n_start = 150000 :: tokens = 50000 :: mean = 1.22 :: max = 19 n_start = 200000 :: tokens = 50000 :: mean = 1.33 :: max = 12 n_start = 250000 :: tokens = 50000 :: mean = 1.22 :: max = 7 n_start = 300000 :: tokens = 50000 :: mean = 1.17 :: max = 7 n_start = 350000 :: tokens = 50000 :: mean = 1.17 :: max = 8 n_start = 400000 :: tokens = 50000 :: mean = 1.21 :: max = 8 n_start = 450000 :: tokens = 50000 :: mean = 1.32 :: max = 12 n_start = 500000 :: tokens = 50000 :: mean = 1.36 :: max = 14 n_start = 550000 :: tokens = 50000 :: mean = 1.22 :: max = 8 n_start = 600000 :: tokens = 50000 :: mean = 1.18 :: max = 6 n_start = 650000 :: tokens = 50000 :: mean = 1.23 :: max = 8 n_start = 700000 :: tokens = 50000 :: mean = 1.21 :: max = 14 n_start = 750000 :: tokens = 50000 :: mean = 1.29 :: max = 14 n_start = 800000 :: tokens = 50000 :: mean = 1.31 :: max = 13 n_start = 850000 :: tokens = 50000 :: mean = 1.19 :: max = 13 n_start = 900000 :: tokens = 50000 :: mean = 1.17 :: max = 7 n_start = 950000 :: tokens = 50000 :: mean = 1.26 :: max = 8 n_start = 1000000 :: tokens = 50000 :: mean = 1.24 :: max = 11 n_start = 1050000 :: tokens = 50000 :: mean = 1.18 :: max = 9 n_start = 1100000 :: tokens = 50000 :: mean = 1.19 :: max = 7 n_start = 1150000 :: tokens = 50000 :: mean = 1.27 :: max = 10 n_start = 1200000 :: tokens = 50000 :: mean = 1.20 :: max = 7 n_start = 1250000 :: tokens = 50000 :: mean = 1.18 :: max = 13 n_start = 1300000 :: tokens = 50000 :: mean = 1.19 :: max = 9 n_start = 1350000 :: tokens = 50000 :: mean = 1.20 :: max = 9 n_start = 1400000 :: tokens = 50000 :: mean = 1.20 :: max = 8 n_start = 1450000 :: tokens = 50000 :: mean = 1.20 :: max = 9 n_start = 1500000 :: tokens = 50000 :: mean = 1.19 :: max = 14 n_start = 1550000 :: tokens = 50000 :: mean = 1.20 :: max = 11 n_start = 1600000 :: tokens = 50000 :: mean = 1.29 :: max = 11 n_start = 1650000 :: tokens = 50000 :: mean = 1.19 :: max = 6 n_start = 1700000 :: tokens = 50000 :: mean = 1.18 :: max = 8 n_start = 1750000 :: tokens = 50000 :: mean = 1.21 :: max = 22 n_start = 1800000 :: tokens = 50000 :: mean = 1.42 :: max = 33 n_start = 1850000 :: tokens = 50000 :: mean = 1.32 :: max = 33 n_start = 1900000 :: tokens = 50000 :: mean = 1.23 :: max = 15 n_start = 1950000 :: tokens = 50000 :: mean = 1.25 :: max = 9 n_start = 2000000 :: tokens = 50000 :: mean = 1.27 :: max = 10 n_start = 2050000 :: tokens = 50000 :: mean = 1.17 :: max = 10 n_start = 2100000 :: tokens = 50000 :: mean = 1.19 :: max = 9 n_start = 2150000 :: tokens = 50000 :: mean = 1.40 :: max = 16 n_start = 2200000 :: tokens = 50000 :: mean = 1.82 :: max = 52 n_start = 2250000 :: tokens = 50000 :: mean = 1.94 :: max = 52 n_start = 2300000 :: tokens = 50000 :: mean = 1.21 :: max = 9 n_start = 2350000 :: tokens = 50000 :: mean = 1.20 :: max = 7 n_start = 2400000 :: tokens = 50000 :: mean = 1.24 :: max = 7 n_start = 2450000 :: tokens = 50000 :: mean = 1.31 :: max = 16
“b_random = False” and “pos_type = 5” and num_w = 50,000
n_start = 0 :: tokens = 50000 :: mean = 1.73 :: max = 49 n_start = 50000 :: tokens = 50000 :: mean = 1.59 :: max = 49 n_start = 100000 :: tokens = 50000 :: mean = 1.91 :: max = 49 n_start = 150000 :: tokens = 50000 :: mean = 1.99 :: max = 49 n_start = 200000 :: tokens = 50000 :: mean = 1.46 :: max = 44 n_start = 250000 :: tokens = 50000 :: mean = 1.74 :: max = 49 n_start = 300000 :: tokens = 50000 :: mean = 1.94 :: max = 49 n_start = 350000 :: tokens = 50000 :: mean = 2.00 :: max = 49 n_start = 400000 :: tokens = 50000 :: mean = 1.47 :: max = 49 n_start = 450000 :: tokens = 50000 :: mean = 2.04 :: max = 49 n_start = 500000 :: tokens = 50000 :: mean = 1.80 :: max = 49 n_start = 550000 :: tokens = 50000 :: mean = 1.76 :: max = 49 n_start = 600000 :: tokens = 50000 :: mean = 1.83 :: max = 44 n_start = 650000 :: tokens = 50000 :: mean = 1.43 :: max = 44 n_start = 700000 :: tokens = 50000 :: mean = 1.77 :: max = 49 n_start = 750000 :: tokens = 50000 :: mean = 1.43 :: max = 49 n_start = 800000 :: tokens = 50000 :: mean = 1.50 :: max = 32 n_start = 850000 :: tokens = 50000 :: mean = 1.71 :: max = 44 n_start = 900000 :: tokens = 50000 :: mean = 1.68 :: max = 40 n_start = 950000 :: tokens = 50000 :: mean = 1.74 :: max = 49 n_start = 1000000 :: tokens = 50000 :: mean = 1.98 :: max = 49 n_start = 1050000 :: tokens = 50000 :: mean = 1.73 :: max = 40 n_start = 1100000 :: tokens = 50000 :: mean = 1.71 :: max = 30 n_start = 1150000 :: tokens = 50000 :: mean = 1.32 :: max = 30 n_start = 1200000 :: tokens = 50000 :: mean = 1.49 :: max = 49 n_start = 1250000 :: tokens = 50000 :: mean = 1.93 :: max = 40 n_start = 1300000 :: tokens = 50000 :: mean = 1.94 :: max = 49 n_start = 1350000 :: tokens = 50000 :: mean = 1.67 :: max = 44 n_start = 1400000 :: tokens = 50000 :: mean = 1.61 :: max = 37 n_start = 1450000 :: tokens = 50000 :: mean = 1.86 :: max = 49 n_start = 1500000 :: tokens = 50000 :: mean = 2.04 :: max = 49 n_start = 1550000 :: tokens = 50000 :: mean = 1.60 :: max = 49 n_start = 1600000 :: tokens = 50000 :: mean = 1.38 :: max = 34 n_start = 1650000 :: tokens = 50000 :: mean = 1.77 :: max = 49 n_start = 1700000 :: tokens = 50000 :: mean = 1.77 :: max = 44 n_start = 1750000 :: tokens = 50000 :: mean = 1.79 :: max = 49 n_start = 1800000 :: tokens = 50000 :: mean = 1.08 :: max = 16 n_start = 1850000 :: tokens = 50000 :: mean = 1.46 :: max = 49 n_start = 1900000 :: tokens = 50000 :: mean = 1.51 :: max = 49 n_start = 1950000 :: tokens = 50000 :: mean = 1.31 :: max = 24 n_start = 2000000 :: tokens = 50000 :: mean = 1.24 :: max = 29 n_start = 2050000 :: tokens = 50000 :: mean = 1.85 :: max = 49 n_start = 2100000 :: tokens = 50000 :: mean = 1.96 :: max = 49 n_start = 2150000 :: tokens = 50000 :: mean = 1.66 :: max = 49 n_start = 2200000 :: tokens = 50000 :: mean = 1.45 :: max = 40 n_start = 2250000 :: tokens = 50000 :: mean = 1.51 :: max = 49 n_start = 2300000 :: tokens = 50000 :: mean = 2.07 :: max = 49 n_start = 2350000 :: tokens = 50000 :: mean = 2.01 :: max = 34 n_start = 2400000 :: tokens = 50000 :: mean = 1.94 :: max = 34 n_start = 2450000 :: tokens = 50000 :: mean = 1.85 :: max = 49
pos_type = 5 shows on average
larger maximum values; this is consistent with relatively high average values for the hit list length.
“b_random = False” and “pos_type = 6” and num_w = 50,000
n_start = 0 :: tokens = 50000 :: mean = 1.38 :: max = 9 n_start = 50000 :: tokens = 50000 :: mean = 1.44 :: max = 22 n_start = 100000 :: tokens = 50000 :: mean = 1.58 :: max = 14 n_start = 150000 :: tokens = 50000 :: mean = 1.41 :: max = 20 n_start = 200000 :: tokens = 50000 :: mean = 1.51 :: max = 16 n_start = 250000 :: tokens = 50000 :: mean = 1.43 :: max = 17 n_start = 300000 :: tokens = 50000 :: mean = 1.41 :: max = 20 n_start = 350000 :: tokens = 50000 :: mean = 1.34 :: max = 17 n_start = 400000 :: tokens = 50000 :: mean = 1.47 :: max = 21 n_start = 450000 :: tokens = 50000 :: mean = 1.56 :: max = 18 n_start = 500000 :: tokens = 50000 :: mean = 1.54 :: max = 21 n_start = 550000 :: tokens = 50000 :: mean = 1.40 :: max = 22 n_start = 600000 :: tokens = 50000 :: mean = 1.41 :: max = 22 n_start = 650000 :: tokens = 50000 :: mean = 1.47 :: max = 21 n_start = 700000 :: tokens = 50000 :: mean = 1.47 :: max = 19 n_start = 750000 :: tokens = 50000 :: mean = 1.51 :: max = 21 n_start = 800000 :: tokens = 50000 :: mean = 1.51 :: max = 17 n_start = 850000 :: tokens = 50000 :: mean = 1.36 :: max = 15 n_start = 900000 :: tokens = 50000 :: mean = 1.39 :: max = 27 n_start = 950000 :: tokens = 50000 :: mean = 1.53 :: max = 22 n_start = 1000000 :: tokens = 50000 :: mean = 1.45 :: max = 22 n_start = 1050000 :: tokens = 50000 :: mean = 1.45 :: max = 16 n_start = 1100000 :: tokens = 50000 :: mean = 1.49 :: max = 31 n_start = 1150000 :: tokens = 50000 :: mean = 1.46 :: max = 31 n_start = 1200000 :: tokens = 50000 :: mean = 1.55 :: max = 20 n_start = 1250000 :: tokens = 50000 :: mean = 1.33 :: max = 14 n_start = 1300000 :: tokens = 50000 :: mean = 1.44 :: max = 27 n_start = 1350000 :: tokens = 50000 :: mean = 1.41 :: max = 16 n_start = 1400000 :: tokens = 50000 :: mean = 1.43 :: max = 19 n_start = 1450000 :: tokens = 50000 :: mean = 1.46 :: max = 20 n_start = 1500000 :: tokens = 50000 :: mean = 1.32 :: max = 15 n_start = 1550000 :: tokens = 50000 :: mean = 1.39 :: max = 18 n_start = 1600000 :: tokens = 50000 :: mean = 1.52 :: max = 20 n_start = 1650000 :: tokens = 50000 :: mean = 1.36 :: max = 17 n_start = 1700000 :: tokens = 50000 :: mean = 1.41 :: max = 17 n_start = 1750000 :: tokens = 50000 :: mean = 1.38 :: max = 19 n_start = 1800000 :: tokens = 50000 :: mean = 1.80 :: max = 20 n_start = 1850000 :: tokens = 50000 :: mean = 1.63 :: max = 25 n_start = 1900000 :: tokens = 50000 :: mean = 1.52 :: max = 21 n_start = 1950000 :: tokens = 50000 :: mean = 1.52 :: max = 22 n_start = 2000000 :: tokens = 50000 :: mean = 1.53 :: max = 25 n_start = 2050000 :: tokens = 50000 :: mean = 1.33 :: max = 14 n_start = 2100000 :: tokens = 50000 :: mean = 1.41 :: max = 23 n_start = 2150000 :: tokens = 50000 :: mean = 1.61 :: max = 19 n_start = 2200000 :: tokens = 50000 :: mean = 2.03 :: max = 28 n_start = 2250000 :: tokens = 50000 :: mean = 2.12 :: max = 28 n_start = 2300000 :: tokens = 50000 :: mean = 1.47 :: max = 26 n_start = 2350000 :: tokens = 50000 :: mean = 1.42 :: max = 21 n_start = 2400000 :: tokens = 50000 :: mean = 1.50 :: max = 21 n_start = 2450000 :: tokens = 50000 :: mean = 1.49 :: max = 22
For pos_type == 0 typical examples for many hits are members of the following word collection. You see the common 3-char-grams at the beginning, in the middle and at the end of the words:
verbindungsbauten, verbindungsfesten, verbindungskanten, verbindungskarten, verbindungskasten, verbindungsketten, verbindungsknoten, verbindungskosten, verbindungsleuten, verbindungslisten, verbindungsmasten, verbindungspisten, verbindungsrouten, verbindungsweiten, verbindungszeiten, verfassungsraeten, verfassungstexten, verfassungswerten, verfolgungslisten, verfolgungsnoeten, verfolgungstexten, verfolgungszeiten, verführungsküsten, vergnügungsbauten, vergnügungsbooten, vergnügungsfesten, vergnügungsgarten, vergnügungsgärten, verguetungskosten, verletzungsnoeten, vermehrungsbauten, vermehrungsbeeten, vermehrungsgarten, vermessungsbooten, vermessungskarten, vermessungsketten, vermessungskosten, vermessungslatten, vermessungsposten, vermessungsseiten, vermietungslisten, verordnungstexten, verpackungskisten, verpackungskosten, verpackungsresten, verpackungstexten, versorgungsbauten, versorgungsbooten, versorgungsgarten, versorgungsgärten, versorgungshütten, versorgungskarten, versorgungsketten, versorgungskisten, versorgungsknoten, versorgungskosten, versorgungslasten, versorgungslisten, versorgungsposten, versorgungsquoten, versorgungsrenten, versorgungsrouten, versorgungszeiten, verteilungseliten, verteilungskarten, verteilungskosten, verteilungslisten, verteilungsposten, verteilungswerten, vertretungskosten, vertretungswerten, vertretungszeiten, vertretungsärzten, verwaltungsbauten, verwaltungseliten, verwaltungskarten, verwaltungsketten, verwaltungsknoten, verwaltungskonten, verwaltungskosten, verwaltungslasten, verwaltungsleuten, verwaltungsposten, verwaltungsraeten, verwaltungstexten, verwaltungsärzten, verwendungszeiten, verwertungseliten, verwertungsketten, verwertungskosten, verwertungsquoten
For pos_type == 5 we get the following example words with many hits:
almbereich, altbereich, armbereich, astbereich, barbereich, baubereich, biobereich, bobbereich, boxbereich, busbereich, bußbereich, dombereich, eckbereich, eisbereich, endbereich, erdbereich, essbereich, fußbereich, gasbereich, genbereich, hofbereich, hubbereich, hutbereich, hörbereich, kurbereich, lötbereich, nahbereich, oelbereich, ohrbereich, ostbereich, radbereich, rotbereich, seebereich, sehbereich, skibereich, subbereich, südbereich, tatbereich, tonbereich, topbereich, torbereich, totbereich, türbereich, vorbereich, webbereich, wegbereich, zoobereich, zugbereich, ökobereich
Intermediate conclusion for tokens longer than 9 letters
From what we found above something like “0 <= pos-type <= 4" and "pos_type =7" are preferable choices for the positions of the 3-char-grams in longer words. But even if we have to vary the positions a bit more, we get on average reasonably short hit lists.
It seems, however, that we must live with relatively long hit lists for some words (mostly compounds at a certain region of the vocabulary).
Test runs for words with a length ≤ 9 and two 3-char-grams
The list of words with less than 10 characters comprises only around 185869 entries. So, the cpu-time required should become smaller.
Here are some result data for runs for words with a length ≤ 9 characters:
“b_random = True” and “pos_type = 0”
cpu : 42.69 :: tokens = 100000 :: mean = 2.07 :: max = 78.00
“b_random = True” and “pos_type = 1”
cpu : 43.76 :: tokens = 100000 :: mean = 1.84 :: max = 40.00
“b_random = True” and “pos_type = 2”
cpu : 43.18 :: tokens = 100000 :: mean = 1.76 :: max = 30.00
“b_random = True” and “pos_type = 3”
cpu : 43.91 :: tokens = 100000 :: mean = 2.66 :: max = 46.00
“b_random = True” and “pos_type = 4”
cpu : 43.64 :: tokens = 100000 :: mean = 2.09 :: max = 30.00
“b_random = True” and “pos_type = 5”
cpu : 44.00 :: tokens = 100000 :: mean = 9.38 :: max = 265.00
“b_random = True” and “pos_type = 6”
cpu : 43.59 :: tokens = 100000 :: mean = 5.71 :: max = 102.00
“b_random = True” and “pos_type = 7”
cpu : 43.50 :: tokens = 100000 :: mean = 2.07 :: max = 30.00
You see that we should not shift the first or the last 3-char-gram to far into the middle of the word. For short tokens such a shift can lead to a full overlap of the 3-char-grams – and this obviously reduces our chances to reduce the list of hits.
Conclusion
In this post we continued our experiments on selecting words from a vocabulary which match some 3-char-grams at different positions of the token. We found the following:
- The measured CPU-times for 100,000 tokens allow for multiple word searches with different positions of two or three 3-char-grams, even on a PC.
- While we, on average, get hit lists of a length below 2 matching words there are always a few compounds which lead to significantly larger hit lists with tenths of words.
- For tokens with a length less than 9 characters, we can work with two 3-char-grams – but we should avoid a too big overlap of the char-grams.
These results give us some hope that we can select a reasonably short list of words from a vocabulary which match parts of misspelled tokens – e.g. with one or sometimes two letters wrongly written. Before we turn to the challenge of correcting such tokens in a new article series we close the present series with yet another post about the effect of multiprocessing on our word selection processes.