
In my last article
Importing large csv files with PHP into a MySQL MyISAM table
I talked a little about my first positive experience with using the “LOAD DATA INFILE …” SQL statement in PHP programs to load csv files with millions of records. Some reader asked me whether the import period behaves linearly with the number of records. Actually, I am not completely sure. The reader has to wait for some more experiments on my side. Right now we are preparing tests for 1, 2, 5 and 10 million line csv files for a certain project I am involved in.
So far, we have passed tests with sequences of 1, 2 and 5 million line (= record) files. For those our results look pretty linear:
- For 1 million records we needed ca. 7,5 seconds to import them into a MySQL MyISAM table (with index building).
- For 2 million records we needed ca. 15 seconds.
- For 5 million records we needed ca. 38 seconds.
The csv data files were originally 32 MB, 64 MB and 165 MB big. We transferred them as compressed zip-files to the server (size reduction by a factor of 4 in our case).
Addendum, 19.09.2014, regarding the absolute numbers for the import time:
I should have mentioned that the absolute numbers for loading times are a bit large. The reason for this is that some indices are defined on the table and that the index trees are built up during the loading process. Actually, one can load our 5 million records in below 6 seconds if no indices are defined on the table. Furthermore, one should separate index building completely from the loading process. Building the index in one step after all data have been loaded may take significantly less time than building it during the loading process – especially if non-unique indices are involved. See a forthcoming article
MySQL: LOAD DATA INFILE, csv-files and index creation for big data tables
about this interesting topic.
Furthermore, the measured time intervals included the following main actions
- jQuery/PHP: transfer of a zip file from a control web page to the server via Ajax in a local network
- PHP: saving of the transferred on a special directory on the server
- PHP: unzipping the file there
- PHP/MySQL: selecting information from control tables (control parameter)
- PHP: checking present status of several target tables by various selects (select for certain consistency numbers not only from the filled table)
- PHP/jQuery: return of an Ajax message to the browser confirming the successful file transfer to the server
- jQuery/PHP: automatic start of a new Ajax transaction from the client with control parameters for the import and subsequent checks
- PHP/MySQL: truncation of existing import table and dropping of views
- PHP/MySQL: importing the data by a “LOAD DATA INFILE … ” SQL statement issued by the PHP program
- PHP/MySQL: creating (3) views
- PHP/MySQL: checking present status of several target tables by various selects (consistency numbers)
- PHP/jQuery: Return of an Ajax message to the client – confirming the successful import and delivering consistency data
So, actually it is a bit difficult to
extract the real required time for the file import by “LOAD DATA” from this bunch of very different activities. However, the whole sequence should behave approximately linearly if everything works correctly. (If you wonder why we have this two fold Ajax transaction structure – wait for more articles in this blog to come.)
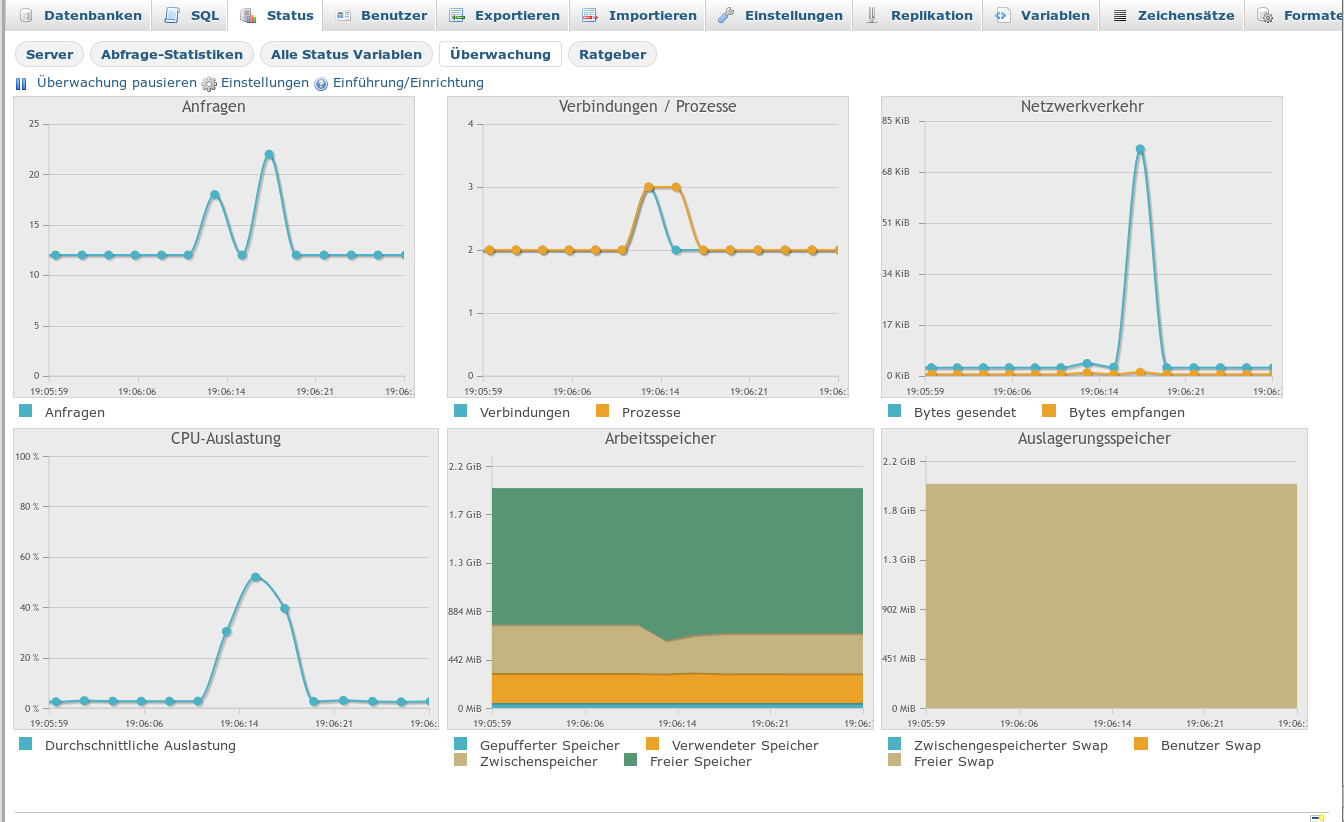
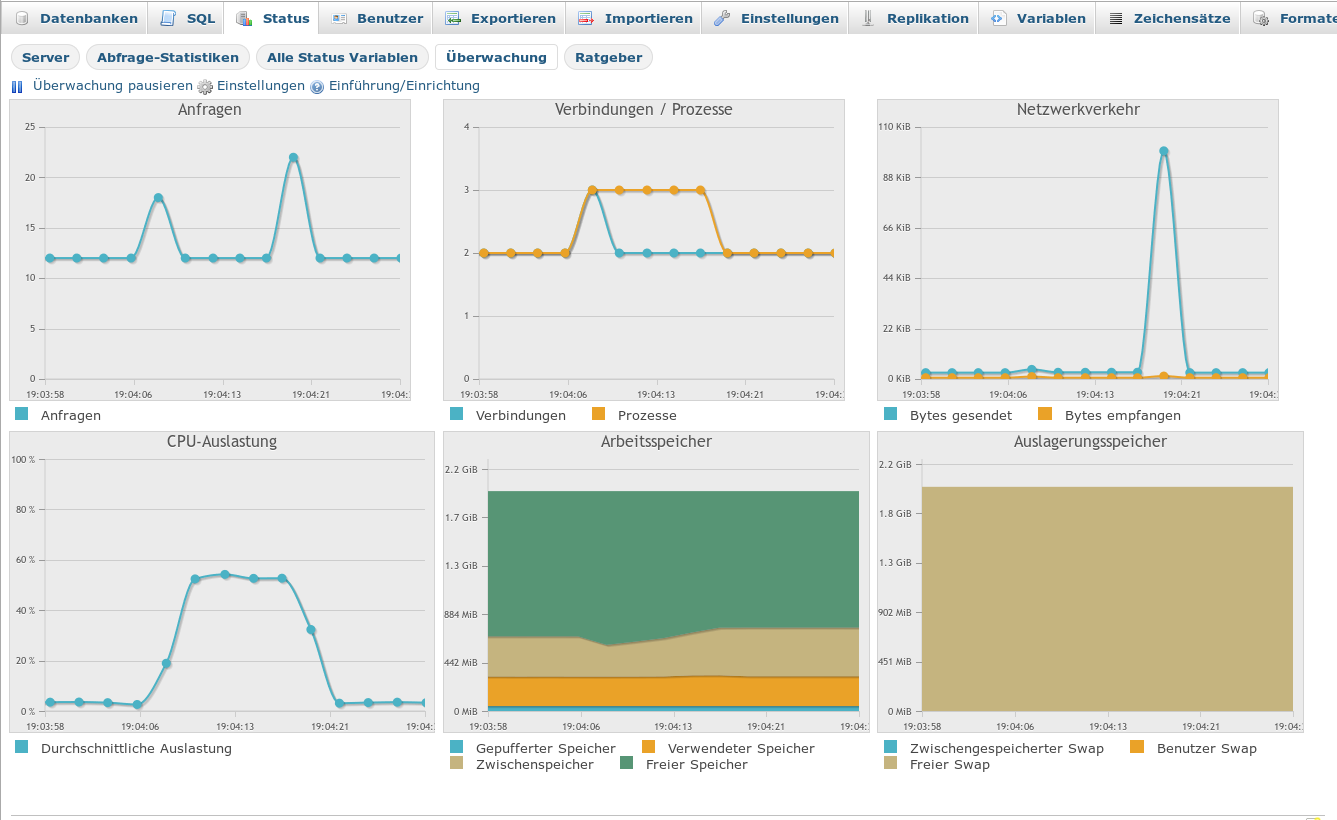
The rather linear behavior for our 1 to 2 million files is also confirmed by the following graphs
Graph for 1 million records
Graph for 2 million records
Graph for 5 million records
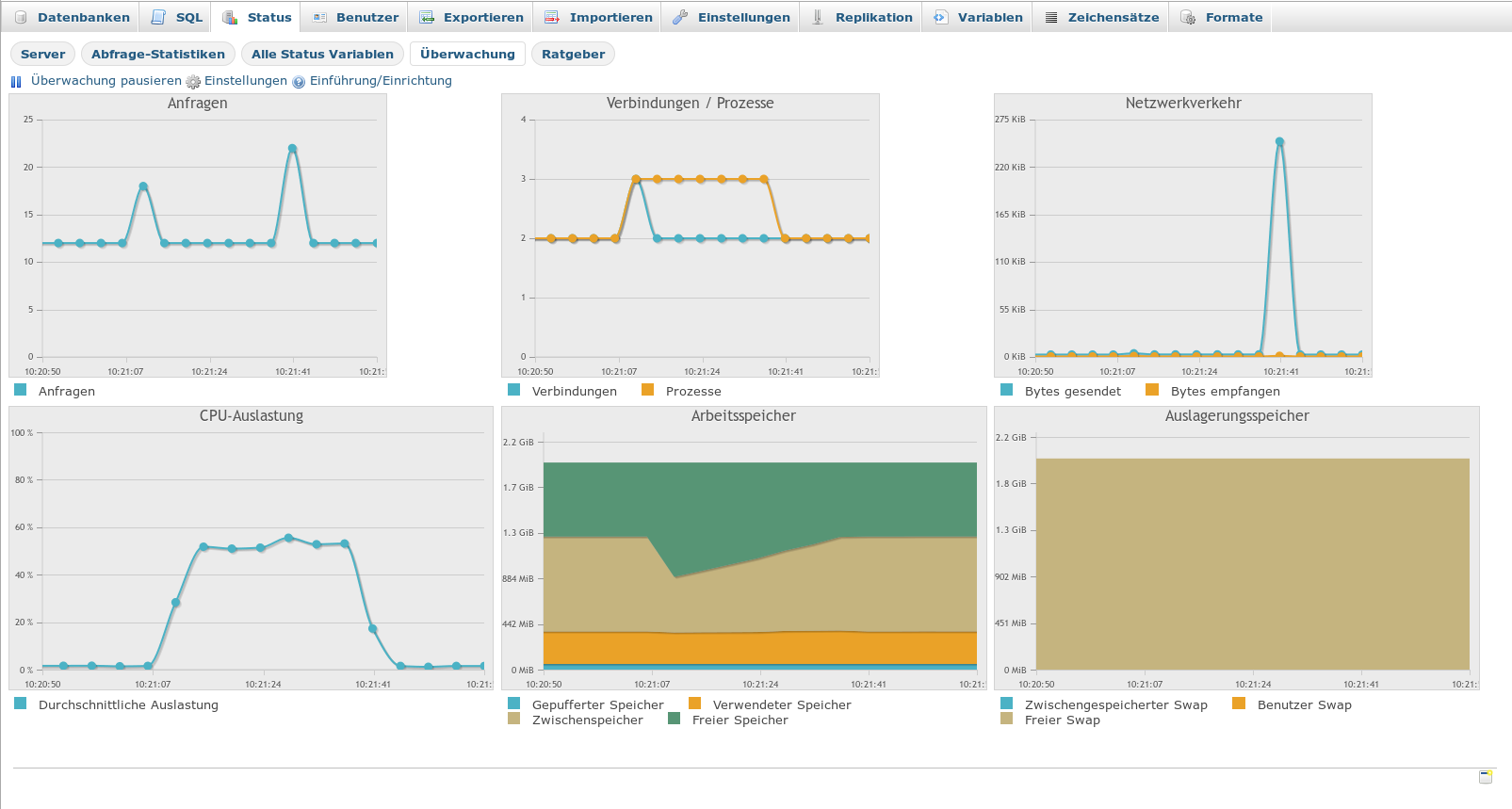
You can see the two fold SELECT structure resulting form the action sequence described above.
Please, note the systematic rise of intermediately used memory from around 700 MByte up to 1.3 GByte! I conclude that the linear behavior is valid only as long as the system has enough free RAM to deal with the data.
I shall supplement more measurement data when we deal with larger files. Our hope is that we can confirm a more or less linear behavior also for larger import files with more records (provided that we supply our virtualized server system with sufficient RAM). However, you can never be sure – when the files get really huge some other memory limitations somewhere on the server (by system or service configuration parameters) may reduce the loading performance drastically. We shall see …