
Linux network namespaces allow for experiments in virtual networks without setting up (virtual) hosts. This includes the study of packet propagation through virtual devices as bridges/switches and between network namespaces. With or without packet filters or firewall rules in place. In the first posts of this series
More fun with veth, network namespaces, VLANs – I – open questions
I have posed a scenario with two L2-segments connected to a common network namespace. Such a scenario appears to be nothing special; we all are used to situations that require routing and forwarding because LAN-segments belong to different IP-subnets.
However, in my scenario all IPs are members of one and the same IP-subnet. An other interesting point is that the assignment of IPs to (virtual) NICs and bridges by the command “ip addr add” causes an automatic setup of elementary routes. We will see that such routes are insufficient to resolve the ambiguities of packet transport from the segment-coupling namespace to the attached segments.
To keep the conditions as plain and simple as possible in our scenario we do not yet mix in VLANs or packet filters or firewalls.
In the 2nd post named above we have already come to some conclusions about the posed scenario and its elements. However, these conclusions were based on theoretical considerations. In this post and in two additional ones we will verify or falsify our preliminary conclusions by performing concrete experiments on a Linux host.
The host I used for the experiments below was a laptop with an Opensuse Leap 15.5 OS, based on packets of SuSE’s enterprise server SLES. The namespaces are set up as unnamed network namespaces. This requires some special commands.
The detailed analysis of the scenario will help us to better understand more complex configurations including virtual VLANs in forthcoming posts. In particular the impact of routes on ARP traffic.
If you notice varying MACs in some images below: You may ignore this safely. It is due to repeating the setup in the course of the experiments. If you have any doubts just repeat the experiments with the help of the commnds provided in the text and in an attachment.
The scenario
The scenario is visualized by the following drawing:
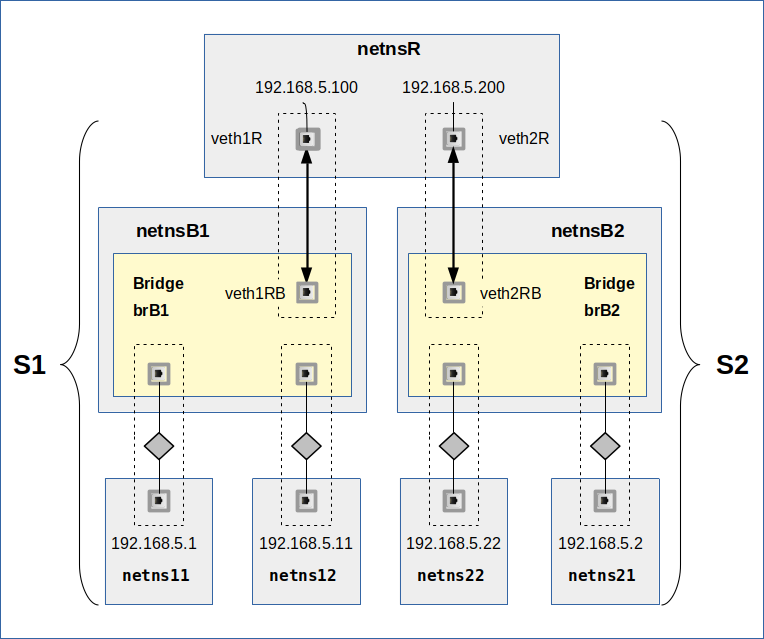
I have already described details in the 2nd post listed above.
How to setup the network namespaces and required devices?
I have discussed all commands required to configure such scenarios with unnamed Linux network namespaces in the first post of another older post series. See
Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – I
If you are new to experiments with unnamed Linux network namespaces please read this post first. Of particular importance are the commands
- unshare …
- nsenter …
- ip link …
- ip address …
I will not discuss details of the chain of commands required for setting up the elements of our scenario. At the end of this post you will find three PDFs with contents you can copy to bash shell scripts. All commands in their given form are meant to be executed by the user root in a safe test environment. I am very confident that readers interested in this post will understand the structure of the commands without further explanation.
Due to the fact that the scripts set and export intermediate variables as environment variables for sub-shells you should run the scripts via the “source“-command if you want these variables to be available in your original shell (probably in a terminal window), too.
The first script (create_netns) will then execute the following commands (you may need to scroll to see all):
#!/bin/bash # Segment 1 unshare --net --uts /bin/bash & export pid_netnsB1=$! unshare --net --uts /bin/bash & export pid_netns11=$! unshare --net --uts /bin/bash & export pid_netns12=$! # Segment 2 unshare --net --uts /bin/bash & export pid_netnsB2=$! unshare --net --uts /bin/bash & export pid_netns21=$! unshare --net --uts /bin/bash & export pid_netns22=$! # Router unshare --net --uts /bin/bash & export pid_netnsR=$! # Assign different hostnames # ~~~~~~~~~~~~~~~~~~~~~~~~~~ nsenter -t $pid_netnsB1 -u hostname netnsB1 nsenter -t $pid_netns11 -u hostname netns11 nsenter -t $pid_netns12 -u hostname netns12 nsenter -t $pid_netnsB2 -u hostname netnsB2 nsenter -t $pid_netns21 -u hostname netns21 nsenter -t $pid_netns22 -u hostname netns22 nsenter -t $pid_netnsR -u hostname netnsR # Assign NICs # ~~~~~~~~~~~~~~~~~~~~~~~~~~ #set up veth devices in netns11, netns12 with connections to netnsB1 ip link add veth11 netns $pid_netns11 type veth peer name veth11B netns $pid_netnsB1 ip link add veth12 netns $pid_netns12 type veth peer name veth12B netns $pid_netnsB1 #set up veth devices in netns21, netns22 with connections to netns2B ip link add veth21 netns $pid_netns21 type veth peer name veth21B netns $pid_netnsB2 ip link add veth22 netns $pid_netns22 type veth peer name veth22B netns $pid_netnsB2 # Conect netnsR to the bridges via 2 veths with end NICs in netnsR ip link add veth1R netns $pid_netnsR type veth peer name veth1RB netns $pid_netnsB1 ip link add veth2R netns $pid_netnsR type veth peer name veth2RB netns $pid_netnsB2 # Assign IPs # ~~~~~~~~~~~~~~~~~~~~~~~~~~ echo "original bash: " $$ echo "<< working in netns11" nsenter -t $pid_netns11 -u -n ip addr add 192.168.5.1/24 brd 192.168.5.255 dev veth11 nsenter -t $pid_netns11 -u -n ip link set veth11 up nsenter -t $pid_netns11 -u -n ip link set lo up nsenter -t $pid_netns11 -u -n ip a echo ">> " echo "original bash: " $$ echo "" echo "<< working in netns12" nsenter -t $pid_netns12 -u -n ip addr add 192.168.5.11/24 brd 192.168.5.255 dev veth12 nsenter -t $pid_netns12 -u -n ip link set veth12 up nsenter -t $pid_netns12 -u -n ip link set lo up nsenter -t $pid_netns12 -u -n ip a echo ">> " echo "original bash: " $$ echo "" echo "<< working in netns21" nsenter -t $pid_netns21 -u -n ip addr add 192.168.5.2/24 brd 192.168.5.255 dev veth21 nsenter -t $pid_netns21 -u -n ip link set veth21 up nsenter -t $pid_netns21 -u -n ip link set lo up nsenter -t $pid_netns21 -u -n ip a echo ">> " echo "original bash: " $$ echo "" echo "<< working in netns22" nsenter -t $pid_netns22 -u -n ip addr add 192.168.5.22/24 brd 192.168.5.255 dev veth22 nsenter -t $pid_netns22 -u -n ip link set veth22 up nsenter -t $pid_netns22 -u -n ip link set lo up nsenter -t $pid_netns22 -u -n ip a echo ">> " echo "original bash: " $$ echo "" echo "<< working in netnsR" nsenter -t $pid_netnsR -u -n ip addr add 192.168.5.100/24 brd 192.168.5.255 dev veth1R nsenter -t $pid_netnsR -u -n ip link set veth1R up nsenter -t $pid_netnsR -u -n ip addr add 192.168.5.200/24 brd 192.168.5.255 dev veth2R nsenter -t $pid_netnsR -u -n ip link set veth2R up nsenter -t $pid_netnsR -u -n ip link set lo up nsenter -t $pid_netnsR -u -n ip a # The extended part which overwrites automatically set rules echo "Changing routes" nsenter -t $pid_netnsR -u -n ip route del 192.168.5.0/24 dev veth1R nsenter -t $pid_netnsR -u -n ip route del 192.168.5.0/24 dev veth2R nsenter -t $pid_netnsR -u -n ip route add 192.168.5.1 via 192.168.5.100 dev veth1R nsenter -t $pid_netnsR -u -n ip route add 192.168.5.11 via 192.168.5.100 dev veth1R nsenter -t $pid_netnsR -u -n ip route add 192.168.5.2 via 192.168.5.200 dev veth2R nsenter -t $pid_netnsR -u -n ip route add 192.168.5.22 via 192.168.5.200 dev veth2R nsenter -t $pid_netnsR -u -n route echo ">> " echo "original bash: " $$ echo "" # Setting up the bridges # ~~~~~~~~~~~~~~~~~~~~~~ # Bridge B1 echo "<< working in netnsB1" nsenter -t $pid_netnsB1 -u -n brctl addbr br1 nsenter -t $pid_netnsB1 -u -n ip link set br1 up nsenter -t $pid_netnsB1 -u -n ip link set veth11B up nsenter -t $pid_netnsB1 -u -n ip link set veth12B up nsenter -t $pid_netnsB1 -u -n ip link set veth1RB up nsenter -t $pid_netnsB1 -u -n ip link set lo up nsenter -t $pid_netnsB1 -u -n brctl addif br1 veth11B nsenter -t $pid_netnsB1 -u -n brctl addif br1 veth12B nsenter -t $pid_netnsB1 -u -n brctl addif br1 veth1RB nsenter -t $pid_netnsB1 -u -n ip a echo ">> " echo "original bash: " $$ echo "" # Bridge B2 echo "<< working in netnsB2" nsenter -t $pid_netnsB2 -u -n brctl addbr br2 nsenter -t $pid_netnsB2 -u -n ip link set br2 up nsenter -t $pid_netnsB2 -u -n ip link set veth21B up nsenter -t $pid_netnsB2 -u -n ip link set veth22B up nsenter -t $pid_netnsB2 -u -n ip link set veth2RB up nsenter -t $pid_netnsB2 -u -n ip link set lo up nsenter -t $pid_netnsB2 -u -n brctl addif br2 veth21B nsenter -t $pid_netnsB2 -u -n brctl addif br2 veth22B nsenter -t $pid_netnsB2 -u -n brctl addif br2 veth2RB nsenter -t $pid_netnsB2 -u -n ip a echo ">> " echo "original bash: " $$ echo "" # Starting konsole windows on KDE desktop # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # Change the terminal emulation for other desktops echo "<< Starting konsoles to enter namespaces" konsole &>/dev/null --profile "Root Shell" -e "nsenter -t $pid_netns11 -u -n /bin/bash" & echo "Started konsole for netns11 PID $!" export pid_kon_netns11=$! konsole &>/dev/null --profile "Root Shell" -e "nsenter -t $pid_netns12 -u -n /bin/bash" & echo "Started konsole for netns12 PID $!" export pid_kon_netns12=$! konsole &>/dev/null --profile "Root Shell" -e "nsenter -t $pid_netns21 -u -n /bin/bash" & echo "Started konsole for netns21 PID $!" export pid_kon_netns21=$! konsole &>/dev/null --profile "Root Shell" -e "nsenter -t $pid_netns22 -u -n /bin/bash" & echo "Started konsole for netns22 PID $!" export pid_kon_netns22=$! konsole &>/dev/null --profile "Root Shell" -e "nsenter -t $pid_netnsR -u -n /bin/bash" & echo "Started konsole for netnsR PID $!" export pid_kon_netnsR=$! echo ">> " echo "original bash: " $$ echo ""
Though there are many commands they are rather simple and straightforward.
Regarding the last 5 commands starting “konsole”-terminal windows, please note:
These commands were intended for a KDE-desktop and I have my own “Root Profile” for KDE konsole-windows. Users of Gnome and other desktops may have to replace these lines with commands for other terminal emulations and/or other profiles. Or start terminal windows manually and afterward access the namespaces via the nsenter-command.
The first script is named “create_netns”. It creates all required namespaces and virtual network devices. The script “create_netns_routes” extends the commands by setting reasonable routes (see below). It is intended for further experiments in other posts. The third script “kill_netns” will destroy all processes and related namespaces for us if and when executed in the original shell (using the “source”-command again).
Let us execute the first script “create_netns” in a terminal window for root via
source YOUR_PATH_TO_create_netns
The result should look similar to
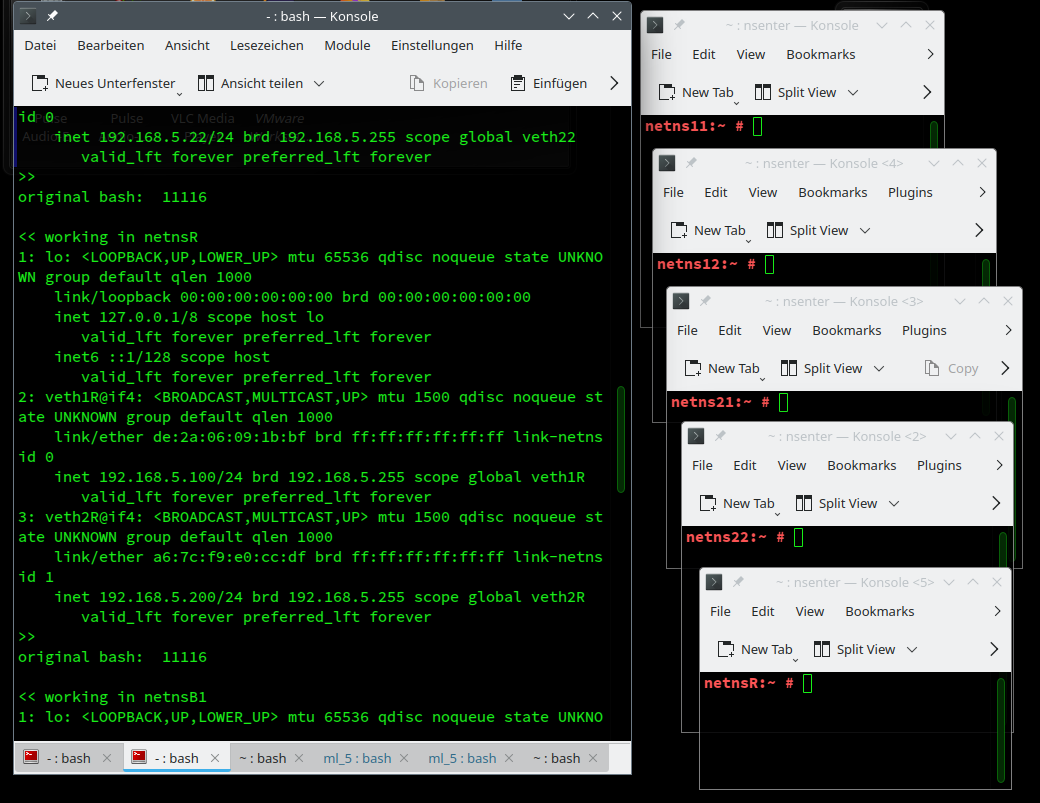
The screenshot shows only a part of the output in the main window. On my KDE desktop I got 5 terminal windows where certain namespaces have already be entered. Note that these namespaces are not only (unnamd) network namespaces, but also uts namespaces; they have got individual hostnames. This is reflected in the prompts. So we know exactly in which namespace we work despite the fact that we have not given them (namespace-) names.
Now we are well equipped to perform some experiments by executing commands in the various network namespaces.
Experiment 1: ICMP communication from S1 to IPs in S1 and S2
An important precondition for all experiments in this post is:
We neither enable forwarding nor Proxy ARP in the coupling network namespace “netnsR”.
One basic expectation derived in the last post was: netns12 should be able to communicate with netns11 (and vice versa). However, we were unsure whether communication with netnsR could be established, due to some uncertainties there. Another expectation was: Without activated forwarding a communication of netns12 with netns21 and netns22 should not be possible under any circumstances.
We test basic communication abilities via pings, i.e. ICMP commands. I just show you the results for netns12 as an example for a non-coupling, single-homed namespace of S1.
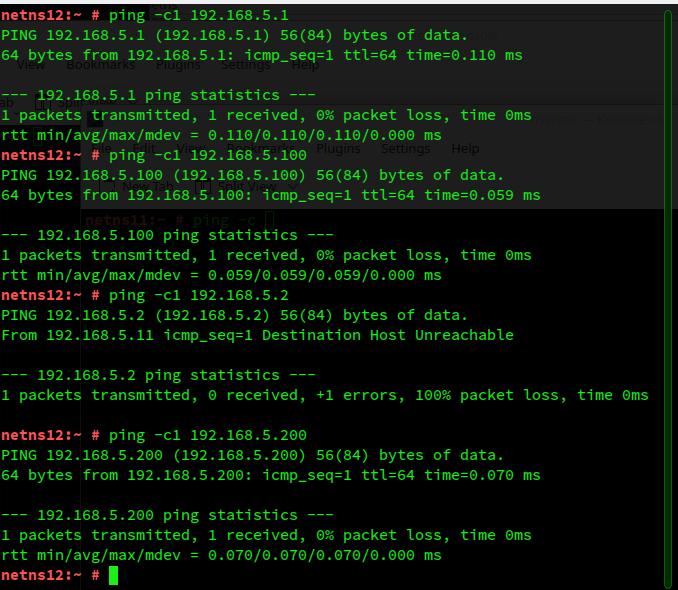
The first good result is:
netns12 can communicate with netns11 over the bridge br1. As expected.
Secondly, we see that communication from netns12 (and netns11) to the border-NIC of S1, located in netnsR, is possible. The border-NIC of S1 is a veth-endpoint named “veth1R”, which got the IP 192.168.5.100.
But, interestingly, we also get ICMP answers from “veth2R” (192.168.5.200), i.e. from the border-NIC of S2. This has to be explained. But, actually, referring to our line of thought in the previous post the really crucial and open question is:
Why did we get an answer from netnsR at all as there should be some uncertainty about packet paths in netnsR?
We will answer this question below.
Thirdly, as expected, no communication from S1 beyond netnsR to (inner) NICs in segment S2 appears to be possible.
Symmetry regarding the reaction to equivalent ICMP-requests in and from segment S1 and S2?
Is the reaction to equivalent ICMP-commands symmetric, when the requests are sent by namespaces of S2, e.g. by netns22? What would you expect? At least our setup commands appeared to be fully symmetric with respect to the elements of S1 and S2 …
Well, the somewhat surprising answer is:
Under the given conditions the reaction is NOT symmetric regarding ICMP commands issued in S1-namespaces in comparison to S2-namespaces!
Let us look at ping requests sent from netns22:
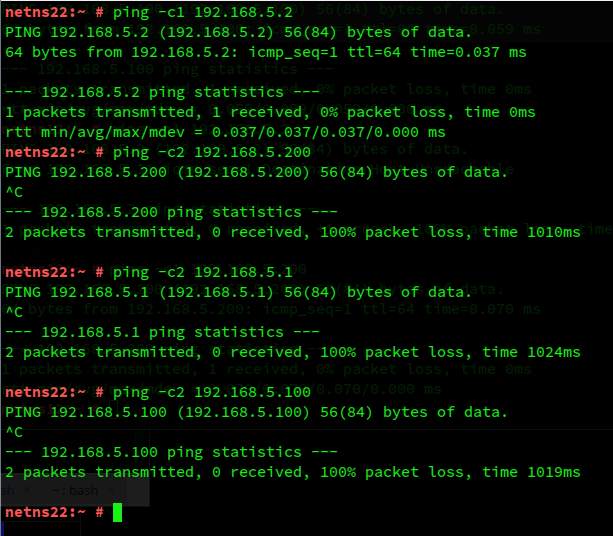
We get no replies from the border-NICs of S2 and S1 located in netnsR. In contrast to what we saw in netns12.
Actually, symmetry is not even given when we send pings from netnsR into the two segments:
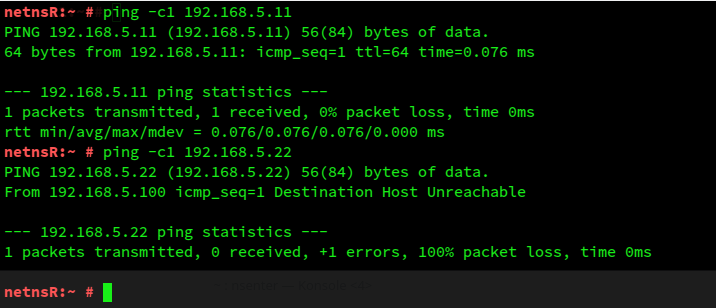
Isn’t it funny?! How do we explain these results?
Asymmetry due to insufficient routing rules in the coupling network namespace
To derive an explanation for our findings above, we must have a closer look at netnsR. Let us first try to find out whether routes exist in netnsR:
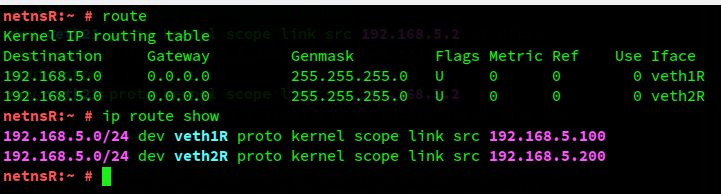
Ooops, two routes to one and the same IP-subnet (note the same network mask)! But via different network interfaces (NICs)! Where do these rules come from – as we have not explicitly set them?
Well, the “ip addr add ” command tries to make life easier for admins to set up standard hosts. A default route is automatically created for a device to which we assign an IP and a netmask. In our case this happened twice in netnsR for 2 different devices which we, on purpose and in contrast to standard situations, put into the same IP-subnet.
Note that the difference between the automatically created routes concerns the routing interface, only!
This is exactly what I called an “ambiguity” regarding the choice of packet paths in netnsR in the previous post! When netnsR wants to communicate with IPs in either segment it must make a choice which of the available network interfaces to use.
Side remark: If you have read my older posts of 2016 on such topics you may remember that we stumbled across a similar kind of ambiguity when we terminated two virtual VLANs by veth-subdevices in one and the same namespace. So, the present experiments also deliver explanations for some of the results we saw in older posts about virtual VLANs.
Which of the two rules for routing in netnsR is taken seriously by the Linux kernel?
Well, it just picks the first one of our two equivalent rules that match the destination IP. This fully explains the asymmetry we saw in our experiments above.
Addendum, 21.0.2024: A reader has asked me to be more specific regarding the selection of a route by the Linux kernel. Well, in our specific case the kernel will pick the first of the rules matching the destination IP. Both rules are on an equal level regarding netmask restrictions. In general, however, the kernel would pick the most specific route for a destination IP. I.e., the one with the broadest and most specific network mask. If we had an additional route for a specific IP and a most specific mask in the sense of e.g. 192.168.2.22/32 then I think the respective route would be taken. But in our scenario the automatically created routes cause a real ambiguity – also for the kernel.
Regarding the border-NICs:
That we got a reply to an ICMP-request for veth2R (192.168.5.200) is due to the fact that netnsR knows about both NICs as its own ones. From the perspective of “netnsR” it has two IP addresses, for which it is responsible in case of requests. And, because the route for replies to requests coming from the IP-subnet 192.168.5.0/24 is clear, it also provides ICMP reply packets into segment S1. But not into S2. (For ARP see below).
Is this a security issue? Well, we could argue that requests to the border-NICs end up in the same namespace, anyway. So, no harm done by replies. Personally, I regard this point much more critical. By some more tests and analysis (out of the scope of this post) a hacker which invaded S1 could learn that veth2R indeed is an interface to some LAN-segments he/she did not know about yet. So, we could ask: Why should netnsR deliver more information than absolute necessary, in particular as we have not enabled forwarding?
Experiment 2: Monitoring of ARP-table entries
ICMP works on the IP layer. How did netnsR get the right MAC-address which it needs to reply to a request coming from a NIC in S1? We assume by ARP requests … Does the asymmetry we saw on the ICMP level also have an impact on ARP in netnsR? And if so, how?
Let us erase everything we have created so far (by running the script “kill_netns”) and set up the namespaces from scratch again. And let us watch the ARP table of netnsR. Just after creation of the namespaces we find:
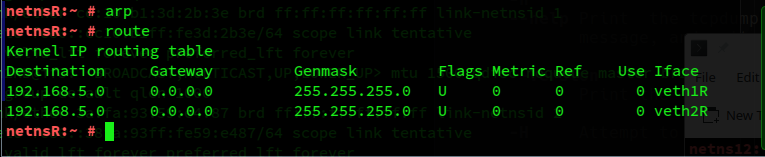
The ARP-table is empty and we have our 2 routes, of which only the first one is used. Now we repeat what we have done in netns12 before (in experiment 1) and afterward look at the ARP-table again:

So far, netnsR has obviously only learned something about the IP-MAC-relation regarding netns12, i.e. regarding 192.168.5.11.
Why not something about 192.168.5.2, which was addressed by requests, too? Well, probably because the ARP was neither forwarded by any magic to S2 nor answered. Or: If ARP requests had been sent they obviously went the wrong direction. Due to the selected route?
If the route really were the reason then a layer 3 rule would have an impact on a layer 2 protocol … This definitely asks for a closer look at what happens in netnsR. We will do this with the help of tcpdump; see below.
But first, let us repeat the ICMP requests which we have sent before from netns22 to other IPs. Afterward we get the following information in netnsR:
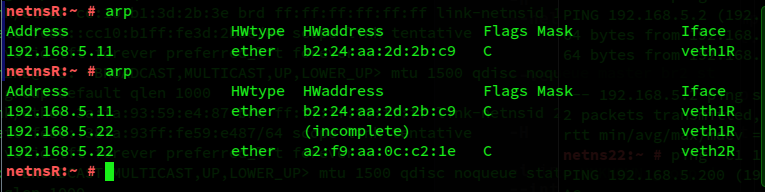
You notice the confusion for netns22, i.e. 192.168.5.22?
The first entry for 192.168.5.22 stems from the first ping request having reached netnsR from netns22. The second from ARP actions in the wake of this ICMP requests. netnsR tried to verify the MAC of 192.168.5.22, but apparently it turned to device vethR1 to generate the necessary Ethernet broadcasts, according to the selected routing rule. Of course, netnsR got no answer from there.
Note that the ARP-table includes information about an interface behind which the IP and its MAC is assumed to be located. This information is correct in the sense that netns22 is not located behind veth1R.
For the MAC of 192.168.5.22 the table defines veth2R as a possible interface. But this ARP information clearly is in conflict with the selected route for subnet 192.168.5.0/24. The route tells netnsR that it instead should use interface veth1R to address any IP in this IP-subnet. But for this interface it had and has no valid MAC of 192.168.5.22!
Intermediate result:
We have managed to create unclear and conflicting information in netnsR – without having set any routes or ARP-entries explicitly.
To cross-check the impact of the conflicts (with asymmetric preference of S1), let us look at the ARP-table in netns12:
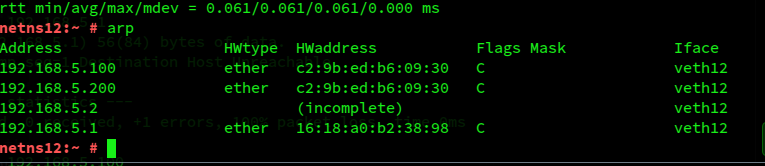
And after a ping request from netns12 to 192.168.5.22?
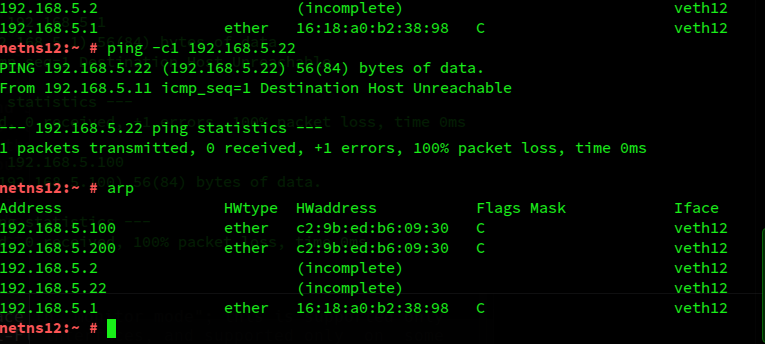
As expected! No host in S2 returned a reply. netsR does not provide any information it may have about segments behind other border-NICs; in our case no information about S2-devices behind veth2R is delivered to S1-devices behind veth1R.
Tcpdump for more information
So far, we have just used the ping-command to analyze some traffic. But we know that pings trigger ARP-requests. To follow the traffic of all packets we need a packet sniffer. On the command line tcpdump and tshark are convenient tools. Both tools depend on the libpcap1-library. I use tcpdump below.
A warning for Opensuse users: Sometimes there are incompatibilities between “libpcap1” and another useful package “iputils”. Among other things the latter contains support for the “arping” command. I experienced problems with the analysis of arp packets on veth devices. If you experience such problems try to pick libcap1 and iputils from the same repository.
Experiment 3: tcpdump in netnsR to monitor ICMP/ARP requests
Let us look closer into what happens at netnsR. To watch network traffic and to be able to execute commands in parallel in netnsR, we open a new additional terminal window and access netnsR a second time.
In the new window to netnsR we then execute a suitable tcpdump command:

(The “-i any” option works on Linux hosts from kernel 2.2 onward; I am not sure whether it is available on other systems).
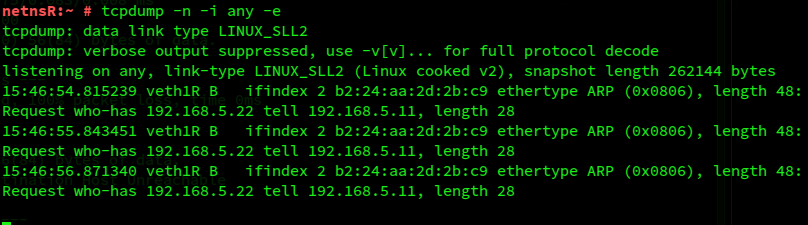
Now we move to the terminal for netns12 and ping two times for 192.168.5.22 again. Obviously, netnsR receives resulting ARP requests of netns12 for 192.168.5.22 (as precursors to creating an Ethernet-packet with the ICMP-payload), but does, of course, not reply to them:
But what happens if we directly ping from netnsR to netns22? So, in the first terminal for netnsR:
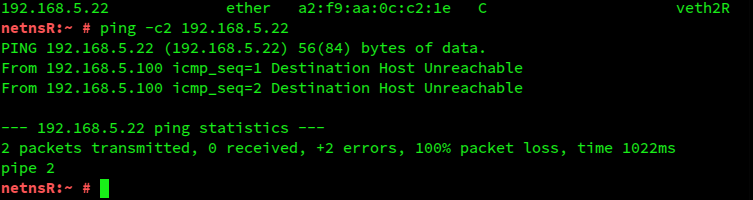
And at the same time in the second where tcpdump monitors (look at the lower part after the first blank line):
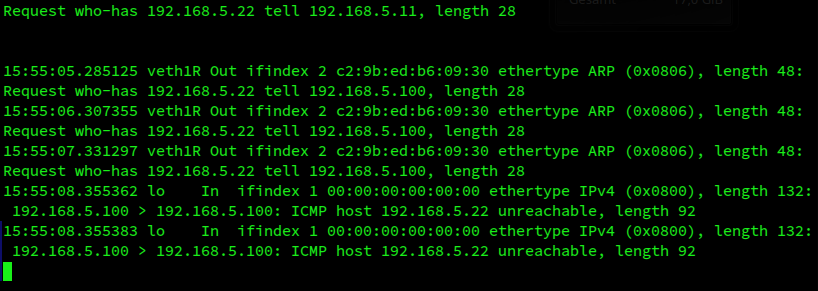
We, again, see a clear sign of the confusion in netnsR!
Remember: netnsR already knows a MAC for 192.168.5.22 from previous ARP requests sent by netns22. But the interface information in the ARP table is in conflict with the selected route to 192.168.5.0/24. Therefore, netnsR, obviously tries to get a reply for a new clarifying ARP request – to become able to create the Ethernet packet with the ICMP request with the help of the right one of the two available interfaces. However, it sends the request to the network behind veth1R! From where it gets no reply and as a consequence the ICMP-request remains unanswered.
One more indication that the automatically defined routes have an impact on the direction of ARP requests when multiple NICs (with segements behind) are available. The explanation would be:
To create Ethernet packets with a payload of higher layer packets the networking components controlling netnsR must get a yet unknown MAC-address or clarify information about an unclear MAC-address. Unclear information may include conflicting interface information saved in the ARP and routing tables!
Therefore netnsR emits ARP requests, i.e. respective Ethernet broadcast packets, via one of the NIC interfaces available. (Respective electromagnetic broadcast waves have to be generated in the respective and presumably right L2-segment.) To chose the (presumably) right interface netnsR seemingly uses available route information about the location of the relevant IP-subnet. It would probably also use more fine-grained information if it were available – which is not the case in our scenario, yet. But as we have seen the first of the two automatically created routes to the network 192.168.50/24 was selected to be the relevant route. This resulted in an asymmetric preference of segment S1. (If we had assigned an IP to veth2R before veth1R, then S2 would have been preferred. Try it out by yourself!)
This is not really surprising. ARP main purpose is to support higher protocols. But ARP’s range is limited to L2-segments. So a decision on the higher protocol level (here ICMP) must be taken in which segment to create the ARP request broadcasts. And this decision is based on routes.
Which are insufficient in or case.
To get an improved picture and a confirmation for our interpretation let us ping again from netns22 for 192.168.5.100:
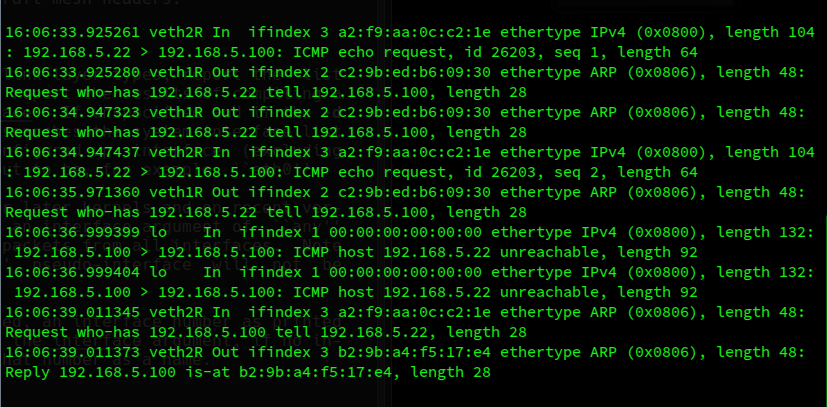
The following interpretation is plausible, in my opinion:
The Ethernet packet with the payload of the ICMP request for 192.168.5.100 from S2 arrives at netnsR via interface veth2R. The ICMP packet is extracted from the Ethernet packet and afterward treated logically. netnsR identifies that it has the requested IP and that it must send an ICMP reply to 192.168.5.22 – again encapsulated in an Ethernet packet which has to be created in the right L2-segment.
netnsR then tries to find out which MAC to use to create an Ethernet packet with the help of the right one of the available interfaces. Now, the mentioned conflict comes up. Remember that netnsR already has an information about the MAC of 192.168.5.22 in netns22. However, the interface conflicts with the selected route. The resulting ARP request (broadcast) to resolve the problem, however, is emitted into S1 via veth1R. Due to the defined route …
Yet, one more experiment to support our ideas: Let us eliminate the route which associated 192.168.5.0/24 with veth1R.

Afterward, the only remaining route indicates the opposite: 192.168.5.0/24 is now assumed to be behind veth2R, i.e. in segment S2. So, let us ping again for 192.168.5.100 from netns22:
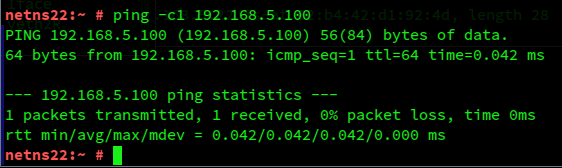
Hey, we got a reply! And what does tcpdump in netnsR tell us:
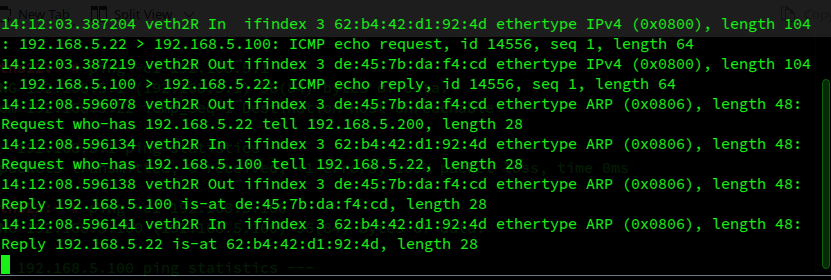
Now all required information in netnsR is consistent – at least regarding a reply to the received ICMP request. netnsR already has the right information about the MAC of 192.168.5.22 in netns22 and the route also shows that veth2R is the correct interface to direct the ICMP reply to. So, the reply is directly created and sent through the interface veth2R. Which, accidentally, is the right one this time.
Ok, so much about the separation of layers. It is an illusion that the path an ARP request takes cannot be influenced by rules on higher layers. True enough, ARP uses Ethernet broadcasts on layer 2. But, obviously, routing rules defined on a higher protocol layer (IP layer) have an impact on the interface chosen to create and emit at least some ARP request packets. And thereby a certain path among alternatives is determined. I would say that this is natural as the nature of ARP’s purpose is to support higher protocols – and thus reaches in a sense beyond that of layer 2.
Addendum, 23.04.2024, after an intense discussion with a reader:
The following question turns up: If the interface used by netnsR to create ARP requests in the wake of higher protocol requests is determined by routes, what about ARP replies? Good question, which touches the formal assignment of ARP to the Link layer. I will try to answer it in my next post.
Intermediate results
Let us widen our view a bit. We all know that ARP information is transient by its very nature. IP-MAC-relations may change with good reason. Routes, therefore, provide a more solid ground regarding the direction and NIC of TCP/IP-packets. Border-NICs of LAN-segments play an important role in this context in network namespaces with multiple NICs. To create encapsulating Ethernet packets with TCP/IP payload,
- MAC-addresses of destination IPs have to be determined and ARP-requests must, therefore, be created in the presumably right L2-segment,
- the right network interface among the available ones must be chosen in order to emit/send ARP request packets and Ethernet packets with higher protocol payload into the right L2-segment.
Again: A route’s information about an interface to use normally is more trustworthy than interface information provided by entries in the ARP-table.
What have we learned about consequences?
Standard network configurations have LAN-segments belonging to different IP-subnets. As soon as we deviate from such a layout, automatically created routes may lead to conflicts regarding interface definitions of entries in the ARP-table in comparison to entries in the routing table of a namespace or host that contains multiple endpoints of L2-segments.
In our case, with the IPs of two segments belonging to one and the same IP-subnet, a selection between automatically created routes (with equal netmasks regarding the IP destination) caused an asymmetry in the handling of packets with respect to the two L2-segments which were attached to a common network namespace (or host).
We saw that ARP-requests, which were send out ahead or after an ICMP request and which had the purpose to get missing MACs, were directed to a particular segment among to possible ones. Namely to the segment behind the interface defined by the selected matching route entry for the target IP in the routing table. This led in our case to (basically wrong) messages about “unreachable hosts”. We could well say this is the consequence of an insufficient configuration of our network on the IP-level.
Lessons learned:
- It is the primary task of the admin to avoid conflicting rules during the setup even of seemingly simple network configurations as ours. Automatically created routes have to be checked, always. They may match your configuration’s purpose or they may not … And selection effects in case of ambiguities must be taken into account.
- ARP supports higher level protocols by sending request broadcasts on layer 2. But in case of multiple available interfaces to different L2-segments the interface used to emit the broadcasts into one of the segments depends on route definitions – and in case of ambiguities on the selected route. So, in this paticular sense rules regarding higher layers can have an impact on the path of ARP packets.
Experiment 4: Replace the automatically defined routes by suitable ones
What can we do? What is a first step to allow for a regular communication from netnsR to either S1 or S2? What must be done to achieve a symmetry in the reaction of our network to requests from either L2-segment? And a symmetry in the reply-pattern when netnsR sends requests into either segment?
The answer obviously is: Define reasonable, unique routes for target IPs.
However, a the standard guiding rule on the level of IP-subnets, namely
“Routes have to be defined clearly and uniquely regarding IP-subnets”,
can not be applied in our special case – as long as we do not want to define a narrower network mask than 255.255.255.0. I.e. if we do not want to define a smaller subnet (longer CIDR) and separate the L2-segments on this level.
Our simple way out is to define routes to individual target IPs and not to whole subnets. Such rules can always be added to a router’s table. In our case the number of routes is small. If there were many NIC-devices in each of the available segments, we would create the required rules by scripts.
The following commands, which we enter in one of the terminal for netnsR, will help us:
ip route del 192.168.5.0/24 dev veth1R ip route del 192.168.5.0/24 dev veth2R ip route add 192.168.5.1 via 192.168.5.100 dev veth1R ip route add 192.168.5.11 via 192.168.5.100 dev veth1R ip route add 192.168.5.2 via 192.168.5.200 dev veth2R ip route add 192.168.5.22 via 192.168.5.200 dev veth2R
If we wanted to add the commands also to the script for creating our scenario hen we would use
nsenter -t $pid_netnsR -u -n ip route del 192.168.5.0/24 dev veth1R nsenter -t $pid_netnsR -u -n ip route del 192.168.5.0/24 dev veth2R nsenter -t $pid_netnsR -u -n ip route add 192.168.5.1 via 192.168.5.100 dev veth1R nsenter -t $pid_netnsR -u -n ip route add 192.168.5.11 via 192.168.5.100 dev veth1R nsenter -t $pid_netnsR -u -n ip route add 192.168.5.2 via 192.168.5.200 dev veth2R nsenter -t $pid_netnsR -u -n ip route add 192.168.5.22 via 192.168.5.200 dev veth2R
See the script “create_netns_routes”.
The deletion of the original routes leads to:
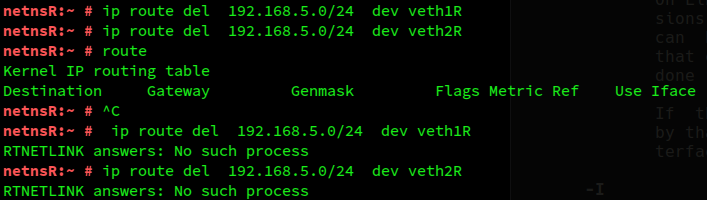
Then we add the routes to our individual IPs of netns11, netns12, netns21, netns22:
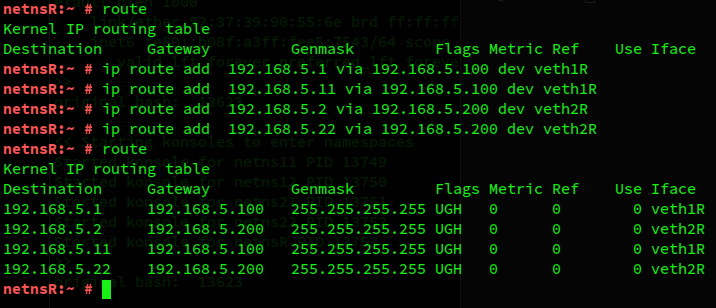
Note the variation in the interfaces!
Symmetry in the network’s reactions to ICMP requests after route corrections!
Let us first test the reaction to requests for border NICs in netnsR and for NICs located in the other segment. First we look at requests send from netns12 in S1 for IPs in netnsR and segment S2:
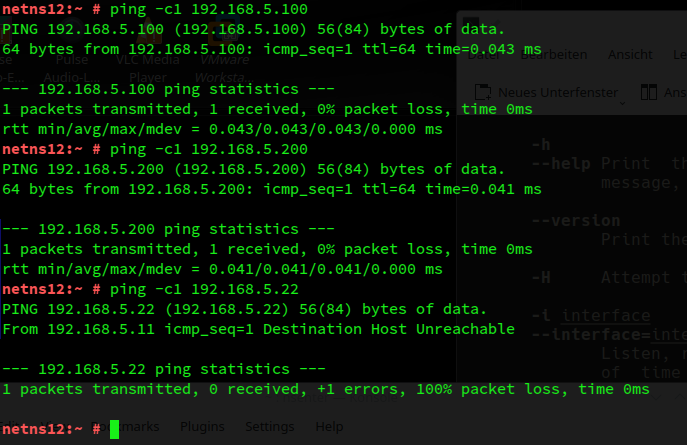
And at the same time in netnsR:
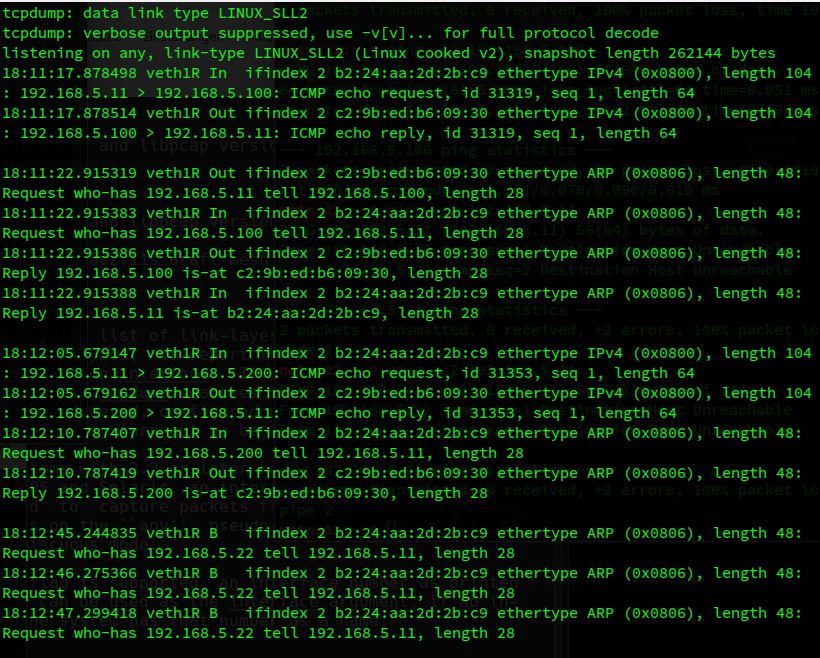
What we see here that ICMP and ARP requests for IPs in segment S2 are not forwarded. Related ARP requests from netns12 remain unanswered. Legitimate ARP replies, which netnsR can answer, are, however, directed to the requesting netns12 via device veth1R.
So the new routes do the right thing for requests from S1.
Now, we execute equivalent symmetric requests in netns22 located in S2. After our changes to the routes in netnsR we do expect a valid reply to ICMP requests regarding both 192.168.5.200 and 192.168.5.100:
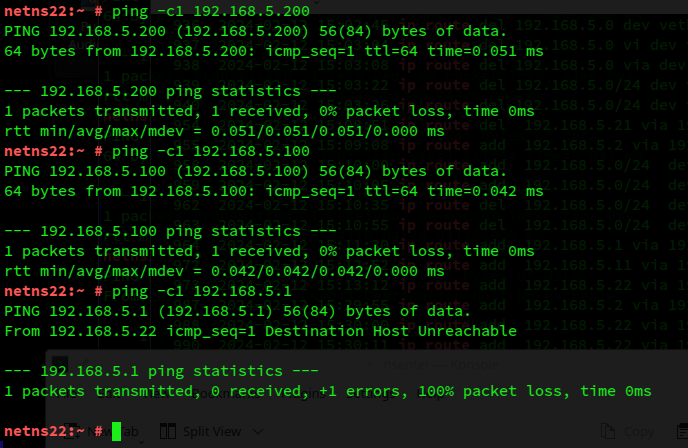
In contrast to what we found above we now get the expected replies. Routes and ARP-entries refer to the same interfaces. And tcpdump tells us the following about netnsR:
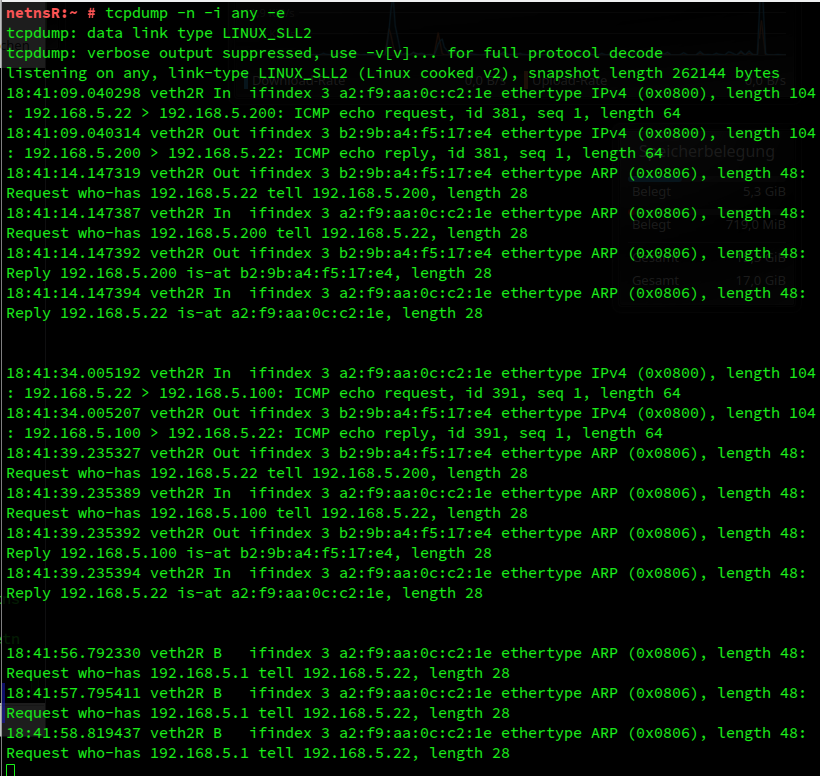
ICMP and ARP requests for IPs in segment S1 are not forwarded. Related ARP requests remain unanswered. Legitimate ARP replies are created by netnsR and send to the requesting netns22 via device veth2R.
To conclude we test whether ICMP requests from netnsR to IPs in S1 and S2 are answered in a symmetric way:
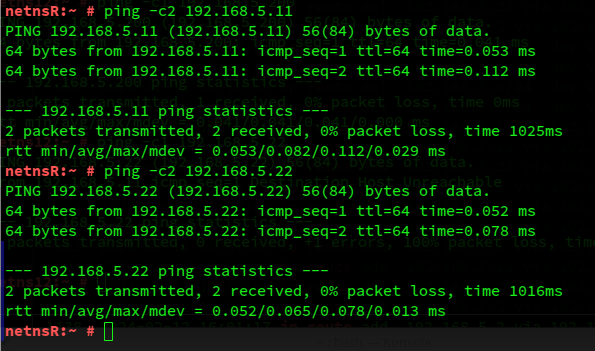
And what happens at netnsR:
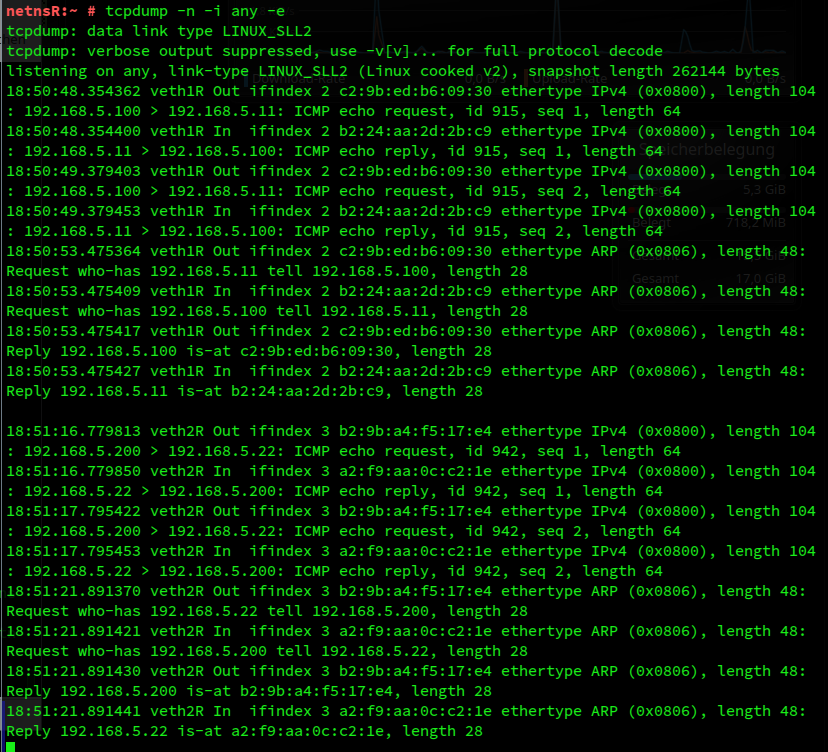
Our more specific routes appear to avoid conflicts regarding interface informtion and lead to unique and correct entries in the ARP tables. We will analyze this and the path of ARP replies further in the next post.
Conclusion
In this post we have had a first closer look on what happens in a network namespace, netnsR, which couples two otherwise separated L2-segments with all IPs in one and the same IP-subnet. No forwarding was activated in netnsR.
We saw that automatically created routes to the IP-subnet in netnsR led to “unreachable hosts”. The first of two created routes (with equal netmasks for the IP destination, but different interfaces) was selected by the Linux kernel to create and send certain ICMP and related ARP request packets via a specific border-device among the two available ones. This led to an asymmetry of the reaction of netnsR to ICMP requests to and from the attached segments and alos to an asymmetry regarding the emission of ARP requests to support ICMP. As a consequence asymmetry also characterized the replies to ICMP requests sent by netnsR into each of the segments.
On a deeper level we saw that a selection of one of the automatically set routes sooner or later led to conflicting entries in the ARP- and the routing table (of netnsR) concerning the information which of the available interfaces should be used.
The setup of routes to individual IPs in both segments via respective valid NIC-interfaces corrected the wrong reactions of netnsR to requests from both L2-segments. ICMP requests from netnsR to IPs into each of the segments were handled and answered symmetrically afterwards.
Regarding security: It was comforting to see that no transfer of any information from namespaces behind the border NIC of one segment occurred to namespaces behind the border-NIC of the other segment. In critical configurations it may nevertheless be important to even hide the border-NICs of a segment from requests of the other segment. We cannot achieve this in our simple scenario, which has no VLANs, without an implementation of packet filer rules.
Route impact without activated forwarding: Another insight is that defined routes can have an impact on the path some packets take in an unusual network configuration – even if no forwarding is activated. This indicates that we should be careful to distinguish between the effects of routes and of activated forwarding. The use of “forwarding” and “routing” as synonyms, which we often find in the context of discussions about routing hosts, blurs the subtle differences. In a forthcoming post we shall analyze what happens in our scenario when we allow for “forwarding” in netnsR.
However, I got questions and comments from two readers regarding the impact of the routes in netnsR on the handling of ARP requests and ARP replies. The focus of the very fruitful and interesting discussion was the formal assignment of ARP to the Link layer. So, I first want to offer some clarification on ARP and routes in the next post:
More fun with veth, network namespaces, VLANs – IV – L2-segments, same IP-subnet, ARP and routes
And thanks to the readers who made me look a bit deeper once again.
PDFs to set up and kill the scenario
create_netns
create_netns_routes
kill_netns