
With the last one of the previous posts in this series
- More fun with veth, network namespaces, VLANs – IV – L2-segments, same IP-subnet, ARP and routes
- More fun with veth, network namespaces, VLANs – V – link two L2-segments of the same IP-subnet by a routing network namespace
- More fun with veth, network namespaces, VLANs – VI – veth subdevices for private 802.1q VLANs
we started to look at VLANs based on veths and Linux bridges. I presented multiple options to configure a veth endpoint in a network namespace for enabling communication with other namespaces via tagged Ethernet packets.
We saw that we can potentially start splitting network traffic already from within a multi-homed namespace which is connected to different VLAN-segments. However, a veth endpoint with multiple interfaces also poses a basic ambiguity problem for the direction of both ARP and ICMP requests into the right one of the various attached (V)LAN-segments. From the results of previous experiments we would assume that the Linux kernel solves this problem by following routes.
In this post we will study the most simple VLAN configuration one can think of: We connect two network namespaces directly with a veth based VLAN line. I.e. we use a veth connection to transmit tagged packets along it. As this would be a lit boring, we add some pepper to the scenario by allowing for untagged packets, too.
To achieve this we reduce “option 4” discussed in the last post to a one-armed solution: We allow for only one VLAN interface per veth endpoint (see a sketch of the scenario below). We start a series of experiments with assigning an IP to the veth’s main interface, only. The setting for the source validation kernel parameter rp_filter will be relaxed.
In the experiments of this post we focus on
- some claimed aspects regarding the role of the main trunk interface of a veth endpoint,
- the potential impact of routes on the ARP communication.
- the fact that working ARP does not mean working ICMP for a variety of different reasons.
Regarding the first point we will see that tagged packets just traverse the trunk interfaces on their way from and to the VLAN interface. Regarding route settings we will look at 36 possible variants. We will see that under the given conditions asymmetric route settings may or may not disable communication – already on the ARP level. But even if ARP works and even if we had symmetric routes in the namespaces, ICMP may not function. I will try to isolate the causes of positive and negative results for ARP and ICMP requests.
I recommend that readers who want to perform these experiments on their own to watch the system log in parallel.
A most simple VLAN scenario: Connect two namespaces by a one VLAN-segment based on a veth connection
We define two namespaces netns1 and netns2. We connect them via a veth connection line. Each of the two veth endpoints gets just one VLAN interface. We assign the IP addresses to the main trunk interfaces of the veth endpoints.
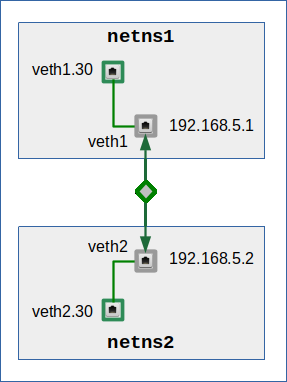
Below netns1 will always be the namespace that sends ARP-requests and in some cases receives an ARP-reply. netns2 instead will be the namespace that potentially receives the ARP-request and in some cases will send an ARP-reply. We use the same sender and receiver roles for the exchange of ICMP for some interesting route settings. ICMP tests the functionality of IP communication for us. I will call the sender of requests also “requestor” and the sender of replies also “responder” below.
My scenario appears to be a very academic one. But already in this simple case
- we have multiple options to set up routes – and the various configuration options (36!) cause different effects regarding ARP,
- we have the alternative to address netns2 from netns1 via tagged or untagged packets
- and despite relaxed source validation we may get “martian sources”.
So, this scenario is not so trivial as it appears on first sight. It comes with many more surprises than one would guess at first sight …
The shell commands to set it up are
Setup commands
#!/bin/bash # Namespace where VLAN "green" starts unshare --net --uts /bin/bash & export pid_netns1=$! # Namespace where VLAN "green" ends unshare --net --uts /bin/bash & export pid_netns2=$! # Assign different hostnames # ~~~~~~~~~~~~~~~~~~~~~~~~~~ nsenter -t $pid_netns1 -u hostname netns1 nsenter -t $pid_netns2 -u hostname netns2 # Assign veth endpoints to namespaces # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #set up veth devices in netns11, netns12 with connections to netnsB1 ip link add veth1 netns $pid_netns1 type veth peer name veth2 netns $pid_netns2 # Add subdevices echo "original bash: " $$ echo "<< working in netns1" nsenter -t $pid_netns1 -u -n ip addr add 192.168.5.1/24 brd 192.168.5.255 dev veth1 nsenter -t $pid_netns1 -u -n ip link add link veth1 name veth1.30 type vlan id 30 nsenter -t $pid_netns1 -u -n ip link add link veth1 name veth1.40 type vlan id 40 #nsenter -t $pid_netns1 -u -n ip addr add 192.168.5.1/24 brd 192.168.5.255 dev veth1.10 nsenter -t $pid_netns1 -u -n ip link set veth1 up nsenter -t $pid_netns1 -u -n ip link set veth1.30 up nsenter -t $pid_netns1 -u -n ip link set veth1.40 down nsenter -t $pid_netns1 -u -n ip link set lo up nsenter -t $pid_netns1 -u -n ip route del 192.168.5.0/24 dev veth1 nsenter -t $pid_netns1 -u -n ip route add 192.168.5.0/24 dev veth1.30 nsenter -t $pid_netns1 -u -n sysctl -w net.ipv6.conf.all.disable_ipv6=1 nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.all.rp_filter=2 #nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.veth1.rp_filter=2 #nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.veth1/30.rp_filter=2 #nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.veth1/40.rp_filter=2 nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.all.forwarding=0 nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.all.arp_accept=0 nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.all.arp_announce=0 nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.all.arp_filter=0 nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.all.arp_ignore=0 nsenter -t $pid_netns1 -u -n sysctl -w net.ipv4.conf.all.arp_notify=0 echo ">> " echo "original bash: " $$ echo "" echo "<< working in netns2" nsenter -t $pid_netns2 -u -n ip addr add 192.168.5.2/24 brd 192.168.5.255 dev veth2 nsenter -t $pid_netns2 -u -n ip link add link veth2 name veth2.30 type vlan id 30 nsenter -t $pid_netns2 -u -n ip link add link veth2 name veth2.40 type vlan id 40 # nsenter -t $pid_netns2 -u -n ip addr add 192.168.5.2/24 brd 192.168.5.255 dev veth2.10 nsenter -t $pid_netns2 -u -n ip link set veth2 up nsenter -t $pid_netns2 -u -n ip link set veth2.30 up nsenter -t $pid_netns2 -u -n ip link set veth2.40 down nsenter -t $pid_netns2 -u -n ip link set lo up nsenter -t $pid_netns2 -u -n ip route del 192.168.5.0/24 dev veth2 nsenter -t $pid_netns2 -u -n ip route add 192.168.5.0/24 dev veth2.30 nsenter -t $pid_netns2 -u -n sysctl -w net.ipv6.conf.all.disable_ipv6=1 nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.all.rp_filter=2 #nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.veth2.rp_filter=2 #nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.veth2/30.rp_filter=2 #nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.veth2/40.rp_filter=2 nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.all.forwarding=0 nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.all.arp_accept=0 nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.all.arp_announce=0 nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.all.arp_filter=0 nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.all.arp_ignore=0 nsenter -t $pid_netns2 -u -n sysctl -w net.ipv4.conf.all.arp_notify=0 echo ">> " echo "original bash: " $$ # Starting konsole windows on KDE desktop # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # Change the terminal emulation for other desktops echo "" echo "<< Starting konsoles to enter namespaces" konsole &>/dev/null --profile "Root Shell" -e "nsenter -t $pid_netns1 -u -n /bin/bash" & echo "Started konsole for netns1 PID $!" export pid_kon_netns1=$! konsole &>/dev/null --profile "Root Shell" -e "nsenter -t $pid_netns2 -u -n /bin/bash" & echo "Started konsole for netns2 PID $!" export pid_kon_netns2=$! echo ">> " echo "original bash: " $$ echo ""
You find the code also in an attached PDF; see the link in the last post-section. Note that some commands already create further veth subdevices, but that we do not activate them. The VID we actively use has the value VID=30.
In the code for the two namespaces you find statements which set values of certain kernel parameters. For this post rp_filter is relevant.
Side remark: Note, that due to defaults in your Linux distribution the value for a specific interface, e.g. in /proc/sys/net/ipv4/conf/veth1/rp_filter, may still be rp_filter=1. So, if you wanted to experiment with rp_filter=0, which we don’t, then you would have to set the values for all interfaces separately. The reason is a maximum value policy for rp_filter.
Our setup defines routes which go through interface veth1.30 in netns1, and through interface veth2.30 in netns2. We will change the route definitions below to cover all in all 36 (!) configuration alternatives.
Note: Interface bound routes have a high priority for the kernel. Another important rule that counts in our context is the rule of “longest prefix matching”. The latter will become important for configurations where different routes via different interfaces match the target IP.
An important kernel parameter for ARP traffic
There is one kernel parameter which, in combination with route settings, has a significant impact on ARP traffic: rp_filter. I quote from the documentation at kernel.org:
rp_filter - INTEGER
0 - No source validation.
1 - Strict mode as defined in RFC3704 Strict Reverse Path
Each incoming packet is tested against the FIB and if the interface
is not the best reverse path the packet check will fail.
By default failed packets are discarded.
2 - Loose mode as defined in RFC3704 Loose Reverse Path
Each incoming packet's source address is also tested against the FIB
and if the source address is not reachable via any interface
the packet check will fail.
Current recommended practice in RFC3704 is to enable strict mode
to prevent IP spoofing from DDos attacks. If using asymmetric routing
or other complicated routing, then loose mode is recommended.
The max value from conf/{all,interface}/rp_filter is used
when doing source validation on the {interface}.
Default value is 0. Note that some distributions enable it
in startup scripts.
On a freshly installed Opensuse Leap or Red Hat system this parameter is set to rp_filter=1. For our experiments below we use the relaxed variant
rp_filter=2 .
Following the transfer of tagged and untagged packets along a VLAN connection with tcpdump
We use the tcpdump command to follow the exchange of Ethernet packets between network namespaces. We would like to see the VLAN-tags whenever tagged packets pass an interface. A command to achieve this for a certain interface, e.g. veth1.30, is
netns1:~ # tcpdump -n -i veth1.30 -e vlan or not vlan
However, this command does not print out the interface name. The following command sequence would give us all interesting packets on both endpoint-interfaces
netns1:~ # tcpdump -n -i veth1.30 -e vlan or not vlan & tcpdump -n -vvv -i veth1 -e vlan or not vlan &
but the printout would not tell us which interface was passed or used by the packets. Unfortunately, we cannot use “-i any” option because the lo-device will lead to an error.
A simple workaround is to use a separate terminal window for each interface. See the outputs below. As the timestamp is provided we can reconstruct the successive order by which the packets passed the various interfaces. If this is too much work for you just use “-i any -e” and trust in the sequence of information without seeing the VID-tag everywhere.
A good question is: Where would we expect to see tagged packets?
Well, remember my drawings of veth endpoints with VLAN interfaces in the previous post: The VLAN interface of a veth endpoint de-tags packets coming from the main interface and sends untagged packets on egress to its surroundings (here: the namespace). So, if this is correct, tcpdump will only show untagged packets at VLAN interfaces. But we should see tagged packets passing the central main (trunk) interfaces of the veth endpoints, i.e. at veth1 and veth2.
Experiments
We now change route settings and check whether ARP-requests are answered or not. I just show you the full output for four configuration examples and route settings. The results for other configurations will be summarized in a kind of table. For some specific examples where ARP requests get a reply we will show that ICMP may nevertheless fail. (To give GPT a chance to read the output, I do not use real screenshots, but copied plain text from the terminals.)
Experiment 1: VLAN configuration with routes enforcing the use of the VLAN interfaces in both namespaces
In this example we use the routes as defined in the setup. These routes tell the kernel to take the VLAN interface when to address the other namespace.
Exp. 1 – start conditions in netns1 and netns2
netns1:~ # arp
netns1:~ # route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1.30
netns1:~ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: veth1@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 7a:60:37:6d:ef:5d brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.5.1/24 brd 192.168.5.255 scope global veth1
valid_lft forever preferred_lft forever
3: veth1.30@veth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 7a:60:37:6d:ef:5d brd ff:ff:ff:ff:ff:ff
4: veth1.40@veth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 7a:60:37:6d:ef:5d brd ff:ff:ff:ff:ff:ff
netns2:~ # arp
netns2:~ # route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 veth2.30
netns2:~ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: veth2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 5e:06:55:80:5d:50 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.5.2/24 brd 192.168.5.255 scope global veth2
valid_lft forever preferred_lft forever
3: veth2.30@veth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 5e:06:55:80:5d:50 brd ff:ff:ff:ff:ff:ff
4: veth2.40@veth2: <BROADCAST,MULTICAST> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 5e:06:55:80:5d:50 brd ff:ff:ff:ff:ff:ff
As in the last post we find that the MAC of a veth endpoint is shared by its trunk interface and the VLAN interfaces. Contributing to the ambiguity which interface to choose for packet emission to a destination IP.
Exp. 1 – details of all route tables
As some entries will become important in other experiments let us get the full picture of the route tables in the namespaces. Please note which interfaces are registered for broadcasts:
Exp. 1 – route tables of netns1
netns1:~ # ip route show table all 192.168.5.0/24 dev veth1.30 scope link local 127.0.0.0/8 dev lo table local proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo table local proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo table local proto kernel scope link src 127.0.0.1 local 192.168.5.1 dev veth1 table local proto kernel scope host src 192.168.5.1 broadcast 192.168.5.255 dev veth1 table local proto kernel scope link src 192.168.5.1
Route tables in netns2
netns2:~ # ip route show table all 192.168.5.0/24 dev veth2.30 scope link local 127.0.0.0/8 dev lo table local proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo table local proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo table local proto kernel scope link src 127.0.0.1 local 192.168.5.2 dev veth2 table local proto kernel scope host src 192.168.5.2 broadcast 192.168.5.255 dev veth2 table local proto kernel scope link src 192.168.5.2
ARP traffic
Will these settings affect ARP traffic? To test this we first execute an arping command without specifying an interface. Afterward we create an ARP-request explicitly via interface veth1.
Below you see the tcpdump results in netns1 for both requests separated by blank line
Exp. 1 – packet traffic at veth1.30 in netns1
netns1:~ # tcpdump -n -i veth1.30 -e vlan or not vlan 18:17:53.393777 7a:60:37:6d:ef:5d > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28 18:17:53.393818 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype ARP (0x0806), length 42: Reply 192.168.5.2 is-at 5e:06:55:80:5d:50, length 28
Exp. 1 – packet traffic at veth1 in netns1
netns1:~ # tcpdump -n -i veth1 -e vlan or not vlan 18:17:53.393780 7a:60:37:6d:ef:5d > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 30, p 0, ethertype ARP (0x0806), Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28 18:17:53.393818 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype 802.1Q (0x8100), length 46: vlan 30, p 0, ethertype ARP (0x0806), Reply 192.168.5.2 is-at 5e:06:55:80:5d:50, length 28 18:18:19.682015 7a:60:37:6d:ef:5d > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28 18:18:19.682038 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype ARP (0x0806), length 42: Reply 192.168.5.2 is-at 5e:06:55:80:5d:50, length 28
netns2 / veth2
netns2:~ # tcpdump -n -i veth2 -e vlan or not vlan 18:17:53.393783 7a:60:37:6d:ef:5d > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 30, p 0, ethertype ARP (0x0806), Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28 18:17:53.393818 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype 802.1Q (0x8100), length 46: vlan 30, p 0, ethertype ARP (0x0806), Reply 192.168.5.2 is-at 5e:06:55:80:5d:50, length 28 18:18:19.682019 7a:60:37:6d:ef:5d > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28 18:18:19.682037 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype ARP (0x0806), length 42: Reply 192.168.5.2 is-at 5e:06:55:80:5d:50, length 28
netns2 / veth2.30
netns2:~ # tcpdump -n -i veth2.30 -e vlan or not vlan 18:17:53.393783 7a:60:37:6d:ef:5d > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28 18:17:53.393817 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype ARP (0x0806), length 42: Reply 192.168.5.2 is-at 5e:06:55:80:5d:50, length 28
Exp. 1 – Interpretation:
For the first ARP request the route settings enforce that an untagged broadcast packet moves through veth1.30, gets tagged and then passes veth1 on its way to veth2. At veth2.30 the request is emitted un-tagged into netns2. Afterwards an ARP-reply moves in form of an unicast packet in backward direction with an opposite story of tagging and de-tagging. It eventually arrives at veth1.30.
So, we were absolutely right to draw the points where tagging ad de-tagging occurs in between the VLAN interface and the main interface of a veth endpoint.
The second arping broadcast is emitted directly from veth1, but obviously untagged and gets a reply from veth2. The VLAN interfaces of the veth endpoints do not get involved.
An important question now is: Why did we get an answer at all as no route is defined from 192.168.5.2 to 192.168.5.1 via veth2?
The reason, of course, is that we have relaxed settings for the parameter rp_filter (=2)! Another route to the request’s source is defined – so we send a reply packet via the interface where the request arrived!
ICMP traffic?
From the perspective of netns1 we have got two answered ARP replies and assume that ICMP should work, too. However:
netns1:~ # ping -c1 192.168.5.2 PING 192.168.5.2 (192.168.5.2) 56(84) bytes of data. 64 bytes from 192.168.5.2: icmp_seq=1 ttl=64 time=0.042 ms --- 192.168.5.2 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.042/0.042/0.042/0.000 ms netns1:~ # ping -c1 192.168.5.2 -I veth1 PING 192.168.5.2 (192.168.5.2) from 192.168.5.1 veth1: 56(84) bytes of data. --- 192.168.5.2 ping statistics --- 1 packets transmitted, 0 received, 100% packet loss, time 0ms
Ooops! The second ICMP request remains unanswered! Can you guess why?
I just give you the packet transfer in netns1 for “ping 192.168.5.2 -I veth1”:
Exp. 1 – ICMP packets at veth1 for enforced un-tagged emission
netns1:~ # tcpdump -n -i veth1 -e vlan or not vlan 18:38:47.406287 7a:60:37:6d:ef:5d > 5e:06:55:80:5d:50, ethertype IPv4 (0x0800), length 98: 192.168.5.1 > 192.168.5.2: ICMP echo request, id 13202, seq 1, length 64 18:38:47.406319 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype 802.1Q (0x8100), length 102: vlan 30, p 0, ethertype IPv4 (0x0800), 192.168.5.2 > 192.168.5.1: ICMP echo reply, id 13202, seq 1, length 64 18:38:52.427713 7a:60:37:6d:ef:5d > 5e:06:55:80:5d:50, ethertype ARP (0x0806), length 42: Request who-has 192.168.5.2 tell 192.168.5.1, length 28 18:38:52.427706 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype 802.1Q (0x8100), length 46: vlan 30, p 0, ethertype ARP (0x0806), Request who-has 192.168.5.1 tell 192.168.5.2, length 28 18:38:52.427744 7a:60:37:6d:ef:5d > 5e:06:55:80:5d:50, ethertype 802.1Q (0x8100), length 46: vlan 30, p 0, ethertype ARP (0x0806), Reply 192.168.5.1 is-at 7a:60:37:6d:ef:5d, length 28 18:38:52.427748 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype ARP (0x0806), length 42: Reply 192.168.5.2 is-at 5e:06:55:80:5d:50, length 28
Exp. 1 – ICMP packets at veth1.30 for enforced un-tagged emission
netns1:~ # tcpdump -n -i veth1.30 -e vlan or not vlan 18:38:47.406319 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype IPv4 (0x0800), length 98: 192.168.5.2 > 192.168.5.1: ICMP echo reply, id 13202, seq 1, length 64 18:38:52.427706 5e:06:55:80:5d:50 > 7a:60:37:6d:ef:5d, ethertype ARP (0x0806), length 42: Request who-has 192.168.5.1 tell 192.168.5.2, length 28 18:38:52.427743 7a:60:37:6d:ef:5d > 5e:06:55:80:5d:50, ethertype ARP (0x0806), length 42: Reply 192.168.5.1 is-at 7a:60:37:6d:ef:5d, length 28
So, our ICMP request actually got a reply – but at the wrong interface! The kernel suppresses the reply as an unsolicited one. The reply over veth2.30 to veth1.30 obviously depended on the route settings in netns2! This is not too surprising as we expect IP traffic to follow routes.
Note that we do not get any messages regarding “martin sources” in the system log in our first test case. We will later understand that this has two reasons: Symmetric routes and the fact that veth2 is registered for potential broadcasts from 192.168.5.0/24 in the routing tables of netns2.
Exp. 1 – eventual ARP-cache in netns2
Eventually, we find two entries in each of the ARP cache tables:
netns2:~ # arp Address HWtype HWaddress Flags Mask Iface 192.168.5.1 ether 7a:60:37:6d:ef:5d C veth2 192.168.5.1 ether 7a:60:37:6d:ef:5d C veth2.30
Exp. 1 – eventual ARP-cache in netns1
netns2:~ # arp Address HWtype HWaddress Flags Mask Iface 192.168.5.2 ether 5e:06:55:80:5d:50 C veth1 192.168.5.2 ether 5e:06:55:80:5d:50 C veth1.30
Note that the entries in the ARP cache table of netns1 result from ARP-requests from netns2 in the course of the last ICMP requests, and not due to ARP-replies. We know already from previous posts that replies to ARP-requests which were sent from user-space are regarded as unsolicited by the kernel – and therefore do not lead to entries in the ARP cache table.
Experiment 1 – summary:
All in all this experiment showed that tagged ARP-request packets were transferred along our VLAN connection when we just create a request without specifying an interface. This is a first indication that an ARP-request packet follows a defined route if no other criterion is available to resolve the basic ambiguity concerning available veth interfaces.
When we explicitly specify interface veth1 for ARP-request creation then we see that an untagged broadcast packet is created. In netns2 veth2 reacts to this request and answers with an untagged reply packet. The ARP-request in this case never reaches interface veth2.30.
Another important message is, however: If we set symmetric routes such that VLAN interfaces are used with priority, then ICMP requests enforced to be sent from the trunk interface will not receive a reply at the trunk interface.
Experiment 2: VLAN configuration with route in the requestor namespace changed to the trunk interface
We want to show that ARP-requests follow the definition of a route. We, therefore, restart the setup configuration from scratch; so do not wonder about changed MACs. Then we change the route in netns1 to point to the trunk interface veth1:
netns1:~ # ip route del 192.168.5.0/24 dev veth1.30 netns1:~ # ip route add 192.168.5.0/24 dev veth1 netns1:~ # route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1 netns1:~ # arp netns1:~ #
If this route setting had any effect on ARP-requests, we would expect that an arping command without specified interface leads to the creation and emission of an untagged Ethernet broadcast by interface veth1. Well, let us see …
Exp. 2 – netns1 – arping
The ARP-request is indeed sent via veth1 and we receive a reply:
netns1:~ # arping -c1 192.168.5.2 ARPING 192.168.5.2 from 192.168.5.1 veth1 Unicast reply from 192.168.5.2 [F2:DA:1A:73:D0:31] 0.571ms Sent 1 probes (1 broadcast(s)) Received 1 response(s)
Exp. 2 – veth1.30 – no ARP packets
We see indeed no packets at veth1.30:
netns1:~ # tcpdump -n -i veth1.30 -e vlan or not vlan
Exp. 2 – veth1 – untagged ARP packets
At veth1 and veth2 we observe untagged packets, only:
netns1:~ # tcpdump -n -i veth1 -e vlan or not vlan 09:40:22.474860 7a:bb:7f:8d:05:59 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28 09:40:22.474903 f2:da:1a:73:d0:31 > 7a:bb:7f:8d:05:59, ethertype ARP (0x0806), length 42: Reply 192.168.5.2 is-at f2:da:1a:73:d0:31, length 28
Exp. 2 – veth1 – untagged ARP packets
netns2:~ # tcpdump -n -i veth2 -e vlan or not vlan 09:40:22.474863 7a:bb:7f:8d:05:59 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28 09:40:22.474902 f2:da:1a:73:d0:31 > 7a:bb:7f:8d:05:59, ethertype ARP (0x0806), length 42: Reply 192.168.5.2 is-at f2:da:1a:73:d0:31, length 28
Without output you will believe me that veth2.30 is not reached by the request. I omit the output for an enforced request via veth1 because it would be just the same.
Experiment 2 – Interpretation:
ARP sends the request according to the set route, i.e. directly via veth1. As veth1 can only create untagged packets we get an untagged broadcast. veth2 afterward creates and sends an ARP-reply. It does so despite an existing deviating route because of the setting rp_filter=2.
Exp. 2 – ICMP traffic?
From the results of “Experiment 1” we expect ICMP to fail. And indeed:
netns1:~ # ping -c1 192.168.5.2 PING 192.168.5.2 (192.168.5.2) 56(84) bytes of data. --- 192.168.5.2 ping statistics --- 1 packets transmitted, 0 received, 100% packet loss, time 0ms
The reason is just the same as before: The reply is sent via veth2.30 to veth1.30, due to the route settings in netns2. There is one difference, however: The system log warns about a “martian source”, namely 192.168.5.2. This martian is obviously detected when a packet arriving at veth1.30 was analyzed:
2024-04-26T10:09:23.167119+02:00 mytux kernel: [ 4708.622935][ C4] IPv4: martian source 192.168.5.1 from 192.168.5.2, on dev veth1.30 2024-04-26T10:09:23.167126+02:00 mytux kernel: [ 4708.622938][ C4] ll header: 00000000: ff ff ff ff ff ff f2 da 1a 73 d0 31 08 06 2024-04-26T10:09:24.176133+02:00 mytux kernel: [ 4709.627973][ C4] IPv4: martian source 192.168.5.1 from 192.168.5.2, on dev veth1.30 2024-04-26T10:09:24.176154+02:00 mytux kernel: [ 4709.627983][ C4] ll header: 00000000: ff ff ff ff ff ff f2 da 1a 73 d0 31 08 06 2024-04-26T10:09:25.204122+02:00 mytux kernel: [ 4710.655936][ C4] IPv4: martian source 192.168.5.1 from 192.168.5.2, on dev veth1.30 2024-04-26T10:09:25.204142+02:00 mytux kernel: [ 4710.655946][ C4] ll header: 00000000: ff ff ff ff ff ff f2 da 1a 73 d0 31 08 06
Can you guess why? An answer is given in a special section below. Whenever the kernel detects a “martian source” it drops a packet as this does not match the IP and NIC configurations.
Experiment 2 – Summary: Experiment 2 confirmed that ARP-requests follow defined routes to the destination IP. As long as the kernel sees no martion sources and if rp_filter=2, ARP-requests will be answered via the veth interface where the request eventually arrived. Despite working ARP, ICMP may nevertheless fail. This happens when due to route priorities the ICMP-reply is sent along a different path than the request, such that the reply packet arrives at a different interface than the one used for the request in the requestor namespace. The kernel may regard the source of an unexpected arriving reply packets even as a “martian source”.
Experiment 3: VLAN configuration with route in the target namespace changed to the veth’s trunk interface
We now look at the impact of an asymmetric route setting. I.e., we set a general route to 192.168.5.0/24 via veth2 in our target namespace netns2:
Routes in netns2
netns2:~ # ip route del 192.168.5.0/24 netns2:~ # ip route add 192.168.5.0/24 dev veth2 netns2:~ # ip route show table all 192.168.5.0/24 dev veth2 scope link local 127.0.0.0/8 dev lo table local proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo table local proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo table local proto kernel scope link src 127.0.0.1 local 192.168.5.2 dev veth2 table local proto kernel scope host src 192.168.5.2 broadcast 192.168.5.255 dev veth2 table local proto kernel scope link src 192.168.5.2 netns2:~ #
In netns1 we leave the original settings from the setup:
Routes in netns1
netns1:~ # ip route show table all 192.168.5.0/24 dev veth1.30 scope link local 127.0.0.0/8 dev lo table local proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo table local proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo table local proto kernel scope link src 127.0.0.1 local 192.168.5.1 dev veth1 table local proto kernel scope host src 192.168.5.1 broadcast 192.168.5.255 dev veth1 table local proto kernel scope link src 192.168.5.1
You certainly guess now what will happen. We do not get an ARP-reply!
netns1:~ # arping -c1 192.168.5.2 ARPING 192.168.5.2 from 192.168.5.1 veth1.30 Sent 1 probes (1 broadcast(s)) Received 0 response(s)
In netns2 we see the expected tagged packet coming from veth1.30 passing veth2 and arriving at veth2.30:
netns2:~ # tcpdump -n -i veth2 -e vlan or not vlan 11:03:25.333628 ce:a4:45:61:5a:d7 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 30, p 0, ethertype ARP (0x0806), Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28
netns2:~ # tcpdump -n -i veth2.30 -e vlan or not vlan 11:03:25.333628 ce:a4:45:61:5a:d7 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.168.5.2 (ff:ff:ff:ff:ff:ff) tell 192.168.5.1, length 28
But no reply is generated. A look at the system protocol reveals a martian source:
2024-04-26T11:03:25.336126+02:00 mytux kernel: [ 2466.341045][ C6] IPv4: martian source 192.168.5.2 from 192.168.5.1, on dev veth2.30 2024-04-26T11:03:25.336149+02:00 mytux kernel: [ 2466.341057][ C6] ll header: 00000000: ff ff ff ff ff ff ce a4 45 61 5a d7 08 06
We need not investigate ICMP in detail. It will fail, too.
netns1:~ # ping -c1 192.168.5.2 PING 192.168.5.2 (192.168.5.2) 56(84) bytes of data. From 192.168.5.1 icmp_seq=1 Destination Host Unreachable --- 192.168.5.2 ping statistics --- 1 packets transmitted, 0 received, +1 errors, 100% packet loss, time 0ms
So, in combination with rp_filter-settings routes even have an impact on whether ARP-replies are created or not.
Before you scratch your head now: We provoked these situations. Our route settings deserve a critical analysis. But we learn a lot from our provoked failures.
Experiment 4: VLAN configuration with fuully symmetric rules for tagged and untagged packets
Let us see whether we can improve our situation by switching to option 5 discussed in the last post. This means two things: We assign the same IP-address to all interfaces of the veth endpoints. And: We define routes for tagged and un-tagged packets.
netns1:~ # ip addr add 192.168.5.1/24 dev veth1.30 netns1:~ # ip route del 192.168.5.0/24 netns1:~ # route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1.30 netns1:~ # ip route del 192.168.5.0/24 netns1:~ # route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface netns1:~ # ip route add 192.168.5.0/24 dev veth1 netns1:~ # ip route add 192.168.5.2/32 dev veth1.30 netns1:~ # ip route show table all 192.168.5.0/24 dev veth1 scope link 192.168.5.2 dev veth1.30 scope link local 127.0.0.0/8 dev lo table local proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo table local proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo table local proto kernel scope link src 127.0.0.1 local 192.168.5.1 dev veth1 table local proto kernel scope host src 192.168.5.1 local 192.168.5.1 dev veth1.30 table local proto kernel scope host src 192.168.5.1 broadcast 192.168.5.255 dev veth1 table local proto kernel scope link src 192.168.5.1 broadcast 192.168.5.255 dev veth1.30 table local proto kernel scope link src 192.168.5.1 netns1:~ #
We perform analogous steps in netns2:
netns2:~ # ip route show table all 192.168.5.0/24 dev veth2 scope link 192.168.5.1 dev veth2.30 scope link local 127.0.0.0/8 dev lo table local proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo table local proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo table local proto kernel scope link src 127.0.0.1 local 192.168.5.2 dev veth2 table local proto kernel scope host src 192.168.5.2 local 192.168.5.2 dev veth2.30 table local proto kernel scope host src 192.168.5.2 broadcast 192.168.5.255 dev veth2 table local proto kernel scope link src 192.168.5.2 broadcast 192.168.5.255 dev veth2.30 table local proto kernel scope link src 192.168.5.2 netns2:~ #
Fully symmetric routes and the VLAN interfaces are now registered to receive broadcasts. And this configuration appears to open up for an option to send ntagged packets, too, via vet1 – if we wanted to. Really?
netns1:~ # arping -c1 192.168.5.2 ARPING 192.168.5.2 from 192.168.5.1 veth1.30 Unicast reply from 192.168.5.2 [4A:A0:58:62:5F:47] 0.551ms Sent 1 probes (1 broadcast(s)) Received 1 response(s) netns1:~ # arping -c1 192.168.5.2 -I veth1 ARPING 192.168.5.2 from 192.168.5.1 veth1 Unicast reply from 192.168.5.2 [4A:A0:58:62:5F:47] 0.557ms Sent 1 probes (1 broadcast(s)) Received 1 response(s) netns1:~ # ping -c1 192.168.5.2 PING 192.168.5.2 (192.168.5.2) 56(84) bytes of data. 64 bytes from 192.168.5.2: icmp_seq=1 ttl=64 time=0.077 ms --- 192.168.5.2 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.077/0.077/0.077/0.000 ms netns1:~ # ping -c1 192.168.5.2 -I veth1 PING 192.168.5.2 (192.168.5.2) from 192.168.5.1 veth1: 56(84) bytes of data. --- 192.168.5.2 ping statistics --- 1 packets transmitted, 0 received, 100% packet loss, time 0ms
Well, on the ARP-level everything is OK. And during none of the arpings and pings we get warnings about “martians”. But ICMP fails again. I am sure you know by now why this happens.
Intermediate conclusion
Our simple setup has confronted us with a complicated set of dependencies for veth endpoints with VLAN interfaces – both on the levels of the ARP and the IP/ICMP protocols:
- Routes play an important role in multihomed namespaces for the path of ARP- and ICMP-requests by determining the interface for broadcast emission.
- If an ARP-request arrives at an interface for which a direct route back to the requestor is defined, an ARP-reply is sent backward via this particular interface.
- rp_filter=2 allows for ARP-replies along the interface where the ARP-request arrived, even if the prioritized route to the requestor in the answering namespace points to a different interface. But this requires that the reply packet is not evaluated to stem from a “martian source”.
- Despite rp_filter=2, the Linux kernel may drop ARP-requests at the destination IP if route settings in combination with the general interface setup (without IP) let the kernel evaluate the source of the ARP-request as “martian”.
- ICMP may fail despite received ARP-replies
- either due to routes leading the ARP-reply along another route to a different interface than where the ARP-reply was generated
- and/or due to an evaluation of the reply packet as coming from a “martian source” by the kernel in the receiving namespace.
I hope that my readers who have asked many questions regarding the impact of routes on ARP get the feeling that we are up to approaching solid ground. But we understand that source evaluation for packets and respective kernel parameter settings must be taken into account in parallel to come to a proper understanding.
36 alternatives for route configurations in the namespaces connected by a VLAN
I have shown the 4 examples above in detail to come to some important conclusions. However, we cannot go through the remaining 32 configuration alternatives this way. Instead I introduce a notation which allows me to indicate the route settings and to summarize the results:
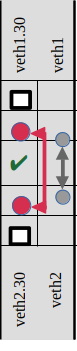

The two columns for each experiment correspond to the VLAN interfaces (left column) and the trunk interfaces (right column). The grey second arrow always corresponds to the enforced ARP-request via veth1:
netns1:~ # arping -c1 192.168.5.2 -e -I veth1
Full squares indicate a distinctive route setting via a target interface. For the red one in netns1 e.g. by
netns1:~ # ip route add 192.168.5.2/32 dev veth1.30
For the grey one by
netns1:~ # ip route add 192.168.5.2/32 dev veth1
With analogous definitions in netns2.
With these notations we get the following results
(for kernel parameter rp_filter=2 !!):
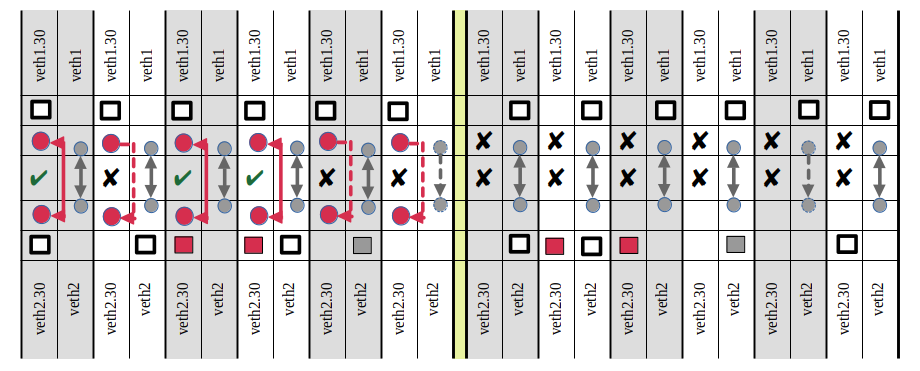
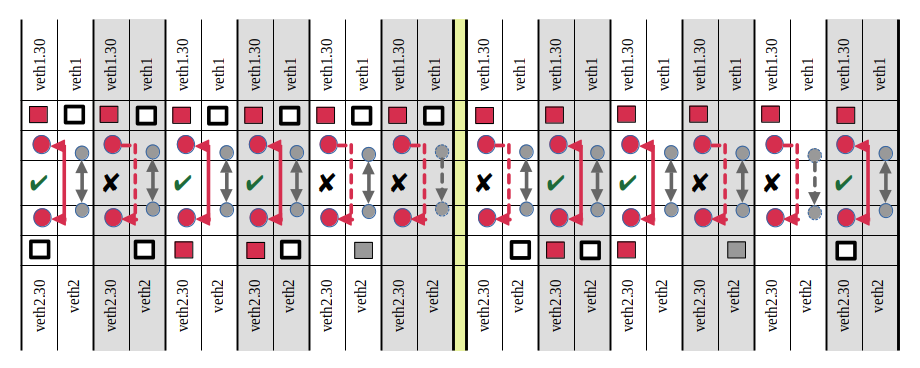
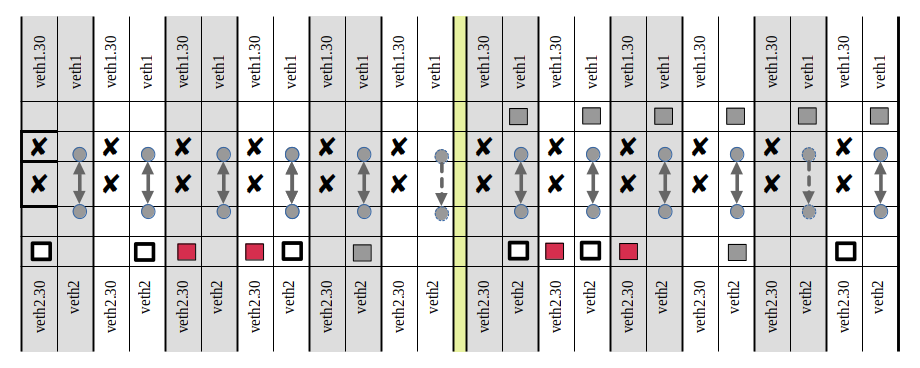
If you apply all what we learned in experiments 1 to 4, all of these results should make sense.
In depth analysis of failing ICMP and IP traffic – despite answered ARP-requests
We have seen that with the default setup and rp_filter=2 an ARP requests send from netns1 via the trunk interface will get a reply. But even if ARP seems to work from the perspective of the requestor, this does not mean that IP-traffic is operational between the namespaces. According to our experiments we can assume that there are three possible reasons for an ICMP failure:
- The receiver of the ICMP-request may regard the sender as a martian source from which it does not expect broadcasts.
- The receiver of the ICMP-request sends an ARP-request to the ICMP-requestor, which the requestor may regard as a martian source.
- The receiver of the ICMP-request may answer via a different (V)LAN interface and connection than the ones the requestor used.
The third point clearly would have to do with asymmetric route settings and/or particular route priorities in the requestor and the receiver namepaces. The first two points are not completely clear, yet, but so far just observations. We check them out in more detail with two experiments.
Martian responder – despite valid routes at the receiver of the request
We kill the namespaces of our previous experiments and start our setup script again and modify the route settings as follows:
netns1:~ # route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1.30 netns1:~ # ip route del 192.168.5.0/24 netns1:~ # ip route add 192.168.5.0/24 dev veth1 netns1:~ # route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1
An ARP-request via the tagging interface veth1.30 is answered because we have a respective prioritized reverse route defined in netns2 via veth2.30.
netns1:~ # arping -c1 192.168.5.2 -I veth1.30 ARPING 192.168.5.2 from 192.168.5.1 veth1.30 Unicast reply from 192.168.5.2 [42:B1:7F:6B:15:22] 0.553ms Sent 1 probes (1 broadcast(s)) Received 1 response(s)
After this request netns2 has an ARP cache table entry showing that 192.168.5.1 can be reached via veth2.30. So what about an ICMP-request? netns2, obviously, has a valid route for a reply!
netns1:~ # ping -c1 192.168.5.2 -I veth1.30 ping: Warning: source address might be selected on device other than: veth1.30 PING 192.168.5.2 (192.168.5.2) from 192.168.5.1 veth1.30: 56(84) bytes of data. --- 192.168.5.2 ping statistics --- 1 packets transmitted, 0 received, 100% packet loss, time 0ms
Oops, failing! Despite the fact the routes point in the right direction. And tcpdump shows that an ICMP-reply from netns2 actually arrived in netns1 at veth1.30:
netns1:~ # tcpdump -n -i any -e 10:27:35.012302 veth1.30 Out ifindex 3 0a:c4:37:a9:dd:52 ethertype IPv4 (0x0800), length 104: 192.168.5.1 > 192.168.5.2: ICMP echo request, id 2407, seq 1, length 64 10:27:35.012303 veth1 Out ifindex 2 0a:c4:37:a9:dd:52 ethertype IPv4 (0x0800), length 104: 192.168.5.1 > 192.168.5.2: ICMP echo request, id 2407, seq 1, length 64 10:27:35.012314 veth1 In ifindex 2 42:b1:7f:6b:15:22 ethertype IPv4 (0x0800), length 104: 192.168.5.2 > 192.168.5.1: ICMP echo reply, id 2407, seq 1, length 64 10:27:35.012314 veth1.30 In ifindex 3 42:b1:7f:6b:15:22 ethertype IPv4 (0x0800), length 104: 192.168.5.2 > 192.168.5.1: ICMP echo reply, id 2407, seq 1, length 64 10:27:40.020102 veth1.30 Out ifindex 3 0a:c4:37:a9:dd:52 ethertype ARP (0x0806), length 48: Request who-has 192.168.5.2 tell 192.168.5.1, length 28 10:27:40.020104 veth1 Out ifindex 2 0a:c4:37:a9:dd:52 ethertype ARP (0x0806), length 48: Request who-has 192.168.5.2 tell 192.168.5.1, length 28 10:27:40.020090 veth1 In ifindex 2 42:b1:7f:6b:15:22 ethertype ARP (0x0806), length 48: Request who-has 192.168.5.1 tell 192.168.5.2, length 28 10:27:40.020090 veth1.30 In ifindex 3 42:b1:7f:6b:15:22 ethertype ARP (0x0806), length 48: Request who-has 192.168.5.1 tell 192.168.5.2, length 28 10:27:40.020148 veth1 In ifindex 2 42:b1:7f:6b:15:22 ethertype ARP (0x0806), length 48: Reply 192.168.5.2 is-at 42:b1:7f:6b:15:22, length 28 10:27:40.020148 veth1.30 In ifindex 3 42:b1:7f:6b:15:22 ethertype ARP (0x0806), length 48: Reply 192.168.5.2 is-at 42:b1:7f:6b:15:22, length 28 10:27:41.044161 veth1 In ifindex 2 42:b1:7f:6b:15:22 ethertype ARP (0x0806), length 48: Request who-has 192.168.5.1 tell 192.168.5.2, length 28 10:27:41.044161 veth1.30 In ifindex 3 42:b1:7f:6b:15:22 ethertype ARP (0x0806), length 48: Request who-has 192.168.5.1 tell 192.168.5.2, length 28 10:27:42.072024 veth1 In ifindex 2 42:b1:7f:6b:15:22 ethertype ARP (0x0806), length 48: Request who-has 192.168.5.1 tell 192.168.5.2, length 28 10:27:42.072024 veth1.30 In ifindex 3 42:b1:7f:6b:15:22 ethertype ARP (0x0806), length 48: Request who-has 192.168.5.1 tell 192.168.5.2, length 28
Also later incoming ARP-requests from netns2 are discarded and not answered by netns1. At the same time we get warnings about “martian sources” – nameley with respect to 192.168.5.2 – in the system’s logs!
2024-04-20T10:27:35.016052+02:00 mytux kernel: [14118.925642][ C2] IPv4: martian source 192.168.5.1 from 192.168.5.2, on dev veth1.30 2024-04-20T10:27:35.016061+02:00 mytux kernel: [14118.925646][ C2] ll header: 00000000: 0a c4 37 a9 dd 52 42 b1 7f 6b 15 22 08 00 2024-04-20T10:27:40.024118+02:00 mytux kernel: [14123.933385][ C2] IPv4: martian source 192.168.5.1 from 192.168.5.2, on dev veth1.30 2024-04-20T10:27:40.024137+02:00 mytux kernel: [14123.933395][ C2] ll header: 00000000: 0a c4 37 a9 dd 52 42 b1 7f 6b 15 22 08 06 2024-04-20T10:27:41.048157+02:00 mytux kernel: [14124.957425][ C2] IPv4: martian source 192.168.5.1 from 192.168.5.2, on dev veth1.30 2024-04-20T10:27:41.048164+02:00 mytux kernel: [14124.957429][ C2] ll header: 00000000: 0a c4 37 a9 dd 52 42 b1 7f 6b 15 22 08 06 2024-04-20T10:27:42.073068+02:00 mytux kernel: [14125.985274][ C2] IPv4: martian source 192.168.5.1 from 192.168.5.2, on dev veth1.30 2024-04-20T10:27:42.073092+02:00 mytux kernel: [14125.985282][ C2] ll header: 00000000: 0a c4 37 a9 dd 52 42 b1 7f 6b 15 22 08 06
Not really funny! Everything went well in netns2. No martian sources there and a fitting route back to netns1. But, bbviously, a source validation for the arriving reply packet is done in netns1, too. Despite rp_filter=2 and a valid route in netns1. The reason for the qualification of the reply’s source as a “martian” becomes clear when we print out the contents of all routing tables:
netns1:~ # ip route show table all 192.168.5.0/24 dev veth1 scope link local 127.0.0.0/8 dev lo table local proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo table local proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo table local proto kernel scope link src 127.0.0.1 local 192.168.5.1 dev veth1 table local proto kernel scope host src 192.168.5.1 broadcast 192.168.5.255 dev veth1 table local proto kernel scope link src 192.168.5.1
Due to our route manipulation and the fact that we never had assigned an IP to veth1.30, the network mask of our network configurration is specified for veth1, only. If this is the reason we should see valid ICMP-replies if we gave veth1.30 the address 192.168.5.1 with the right netmask, too. And indeed:
netns1:~ # ip addr add 192.168.5.1/24 dev veth1.30 netns1:~ # ping -c1 192.168.5.2 -I veth1.30 PING 192.168.5.2 (192.168.5.2) from 192.168.5.1 veth1.30: 56(84) bytes of data. 64 bytes from 192.168.5.2: icmp_seq=1 ttl=64 time=0.047 ms --- 192.168.5.2 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.047/0.047/0.047/0.000 ms
Funny, isn’t it? And no martian source warnings now!
Martian requestor
Now, let us change the route setting in netns2:
netns2:~ # ip route del 192.168.5.0/24 dev veth2.30 netns2:~ # ip route add 192.168.5.0/24 dev veth2
Afterward an ICMP request from netns1 via veth1.30 fails:
netns1:~ # ping -c1 192.168.5.2 -I veth1.30 PING 192.168.5.2 (192.168.5.2) from 192.168.5.1 veth1.30: 56(84) bytes of data. --- 192.168.5.2 ping statistics --- 1 packets transmitted, 0 received, 100% packet loss, time 0ms
With martian warnings again – but this time concerning 192.168.5.1:
2024-04-20T11:07:54.949279+02:00 mytux kernel: [16538.831379][ C6] IPv4: martian source 192.168.5.2 from 192.168.5.1, on dev veth2.30 2024-04-20T11:07:54.949295+02:00 mytux kernel: [16538.831387][ C6] ll header: 00000000: ff ff ff ff ff ff 0a c4 37 a9 dd 52 08 06 2024-04-20T11:07:55.957462+02:00 mytux kernel: [16539.838303][ C6] IPv4: martian source 192.168.5.2 from 192.168.5.1, on dev veth2.30 2024-04-20T11:07:55.957478+02:00 mytux kernel: [16539.838311][ C6] ll header: 00000000: ff ff ff ff ff ff 0a c4 37 a9 dd 52 08 06 2024-04-20T11:07:56.982192+02:00 mytux kernel: [16540.862226][ C6] IPv4: martian source 192.168.5.2 from 192.168.5.1, on dev veth2.30 2024-04-20T11:07:56.982207+02:00 mytux kernel: [16540.862233][ C6] ll header: 00000000: ff ff ff ff ff ff 0a c4 37 a9 dd 52 08 06
Even ARP requests do not work – because already the respective broadcast packets are qualified as martians .
netns1:~ # arping -c1 192.168.5.2 -I veth1.30 ARPING 192.168.5.2 from 192.168.5.1 veth1.30 Sent 1 probes (1 broadcast(s)) Received 0 response(s)
Conflicting routes – ICMP replies are sent along a different route than the requests and arrive at wrong interfaces
Let us now add address 192.168.5.2 also to veth2.30. Then an ARP-request will get a reply – for the reasons named above.
netns1:~ # arping -c1 192.168.5.2 -I veth1.30 ARPING 192.168.5.2 from 192.168.5.1 veth1.30 Unicast reply from 192.168.5.2 [42:B1:7F:6B:15:22] 0.552ms Sent 1 probes (1 broadcast(s)) Received 1 response(s)
However, the ICMP request fails:
netns1:~ # ping -c1 192.168.5.2 -I veth1.30 PING 192.168.5.2 (192.168.5.2) from 192.168.5.1 veth1.30: 56(84) bytes of data. --- 192.168.5.2 ping statistics --- 1 packets transmitted, 0 received, 100% packet loss, time 0ms
The reason is that the reply – due to route settings in netns2 is sent via veth2 and thus arrives at veth1 and not veth1.30, where the request originated.
11:35:55.095656 veth1.30 Out ifindex 3 0a:c4:37:a9:dd:52 ethertype IPv4 (0x0800), length 104: 192.168.5.1 > 192.168.5.2: ICMP echo request, id 10723, seq 1, length 64 11:35:55.095658 veth1 Out ifindex 2 0a:c4:37:a9:dd:52 ethertype IPv4 (0x0800), length 104: 192.168.5.1 > 192.168.5.2: ICMP echo request, id 10723, seq 1, length 64 11:35:55.095668 veth1 In ifindex 2 42:b1:7f:6b:15:22 ethertype IPv4 (0x0800), length 104: 192.168.5.2 > 192.168.5.1: ICMP echo reply, id 10723, seq 1, length 64 11:36:00.116026 veth1.30 Out ifindex 3 0a:c4:37:a9:dd:52 ethertype ARP (0x0806), length 48: Request who-has 192.168.5.2 tell 192.168.5.1, length 28
Even if we make the routes symmetric, like
netns1:~ # route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1 192.168.5.2 0.0.0.0 255.255.255.255 UH 0 0 0 veth1.30
netns2:~ # route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 veth2 192.168.5.1 0.0.0.0 255.255.255.255 UH 0 0 0 veth2.30
and switched off rp_filter for all interfaces explicitly
netns1:~ # echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter netns1:~ # echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter netns1:~ # echo 0 > /proc/sys/net/ipv4/conf/veth1.30/rp_filter
(and make the analogous settings in netns2), sending an ICMP-request via veth1 would not work for the very same reason: No martians, but the ICMP-reply arrives at the wrong interface. An ARP-request sent via veth1 would however be answered.
Which is in a way good, by the way, as our routes impose that we want to talk via tagged packets between 192.168.5.1 and 192.168.5.2.
rp_filter=2 and valid routes via other interfaces do not prevent checks for martians
Important lessons we take with us from the last experiments are the following:
- The ARP protocol tries to answer an ARP-request via the network interface through which the ARP-request eventually entered the target namespace or host. If a porper route via this particular interface is set a direct reply will be enḿitted.
- If rp_filter is set to rp_filter=2, an ARP-reply may be sent even if this contradicted the local preferred route to the source of the request. But the Linux kernel performs an elementary check before doing this.
- Even if some valid route to the source of an ARP-request exists, the Linux kernel first checks whether the interface, where the request arrived, is registered for traffic from the source network, i.e. if it is registered to receive broadcasts and other packets from the (V)LAN-segment at all. The kernel checks the defined IP and netmask for the interface and a respective entry in the local routing tables whilst doing this. If the network interface is not registered for a traffic in the IP-subnet , the arriving packet may be regarded as coming from a “martian source” and dropped. Only, if the arriving packet is not regarded “martian” then the existence of a valid secondary route to the source may trigger an ARP-reply in case rp_filter=2.
The last point explains the potential problems which I announced for configuration option 4 of VLAN-aware veth endpoints already in my last post.
Avoid misinterpretations
Despite our liberal setting of rp_filter=2, address assignments in combination with some route configurations may cause a failure of ARP-requests in the sense that no reply arrives. One could have misinterpreted this in the way that the kernel somehow manages to avoid un-tagged or wrongly tagged ARP-replies in comparison to the request’s tag. I want to underline this point:
The present results do not support the idea that ARP-replies to tagged requests are denied by the kernel if route settings would imply another tag.
The causes of unreplied ARP- and ICMP-requests are others: A detected “martian source” or a preferred route sending the reply to another network interface than where the request came from.
Note also:
The present results for (V)LAN interfaces of a veth endpoint do not indicate that an ARP-reply might be sent through an interface different from the one where the ARP-reply arrived.
Which is very comforting after all.
A general dilemma regarding VLAN-aware veth endpoints and ICMP
As we saw the whole arrangement leaves us with the somewhat surprising insight that routes indeed have a deep impact on the path which ARP-requests take, but that we may also experience no ARP-reply at all despite liberal settings for rp_filter! This happened
- if and when we had no symmetric route settings
- and if a request receiving interface was not registered with an IP and fitting netmask for traffic from the IP-subnet at all.
We could remedy the ARP “problem” by assigning the same IP address to all interfaces. But then ICMP requests through the trunk interface may still fail due to the asymmetric or deviating preferred routes. In our special situation you could regard this as a kind of positive feature. You cannot talk un-tagged if the routes tell you something different.
But it is not very reasonable to allow for ARP-replies, but make an ICMP-reply via the same interface fail. In my opinion the consequence is:
If you split traffic from and to different VLAN-segments already inside a namespace (or within a virtualized host), you should not follow a policy which allows to use both the trunk interface and VLAN-interfaces. Instead, use VLAN-interfaces, only, set respective routes to the different goups of target hosts and deactivate ARP on the trunk interface. Use a “standard VID” to reach namespaces or hosts that work with untagged packets, only, and know nothing about VLANs.
A working packet flow can be achieved relatively easily via a coupling Linux bridge which does the “translation” between the chosen standard VID and untagged packets to and from communictaion partners outside the VLAN-segments. We come back to this when we attach veths to Linux bridges.
Preventing ARP and IP communication via the trunk interfaces
In our academic example, but also in more realistic cases we may want to prevent an ARP exchange and thus any communication via untagged packet completely. The trunk interface should become an intermediate transfer point for tagged packets, only. This means we can not deactivate it. But there two other methods to deactivate it as a legitimate origin for ARP- and ICMP/IP-packets:
Method 1: Turn ARP off on trunk interfaces.
netns1:~ # ip link set arp off dev veth1
and
netns2:~ # ip link set arp off dev veth2
Method 2: Set all routes via VLAN interfaces and set “rp_filter=1”
The other option in our specific case is to set the kernel parameter rp_filter to rp_filter=1. This enforces a strict analysis of the optimal route for an interface in question. If we have not defined any route through the trunk interfaces (or if such routes would be sub-optimal) arriving packes will be dropped.
Conclusion
Even our exteremely simple configuration came with a basic ambiguity regarding interfaces for the emission of Ethernet packets transporting ARP and ICMP/IP requests and replies. We found that properly defined routes where required to ensure that ARP packets were send into the right VLAN segment. We have tested different route settings to support the Linux kernel in his task of selecting a distinct interface of a VLAN-aware veth endpoint for packet emission.
Our experiments proved that routes have an significant impact on the path of both ARP and ICMP requests emiited from multi-homed namespaces (or virtualized Linux hosts). Routes determine which of the interfaces of a veth endpoint is chosen to send an ARP-request – if the interface is not specified otherwise.
For proper VLAN communication via veth endpoints we must always ensure symmetry in the route settings for the sending and receiving namespaces. Otherwise certain veth configurations may lead to the detection of “martian sources” by the Linux kernel. If we want to represent a namespace with a veth endpoint having multiple interfaces by just one IP, it might be OK to assign this IP to all of the used interfaces – to all VLAN interfaces as well as to the trunk interface.
Certain interface and route settings may block ARP-replies to ARP-requests created in the course of ICMP-traffic – even in combination with a liberal setting of rp_filter=2. This may be due to a first obligatory stage of source evaluation by the kernel – and the detection of martian sources. This may in addition hinder ICMP traffic over an explicitly chosen interface – despite valid alternative routes in the target namespace.
Despite replies to ARP-requests route settings may cause that ICMP-replies are sent via a different route than the one the requests took. Therefore, an ICMP reply may end up at another interface than the one where the request started and therefore ignored. Thus, ARP-replies from a target destination do not guarantee that ICMP and general IP traffic can happen. Therefore, correct route settings is particularly mportant for multi-homed namespaces with multiple VLAN-interfaces.
In general we have alos found that we shoul VLN interfaces only if and when we want to separate VLAN traffic already in a namespace with veth endpoints.
Furthermore, we have seen that we may have to deactivate ARP and IP traffic on the main veth trunk interface to prevent the exchange of untagged packets – and/or to set rp_filter=1.
All results must, however, be verified in other more complex configurations. And for other kernel parameters … The next post extends our simple setting a bit.