Im letzten Beitrag dieser Serie zu SSD-Raid-Arrays unter Linux
SSD Raid Arrays unter Linux – III – SW- Raid vs. Intel-RST-Raid – Performance?
hatte ich mich mit der Frage auseinandergesetzt, ob ein SSD-Raid-Array an einem Intel-Raid-Controller typischer aktueller Mainboards als iRST-Array oder nicht besser gleich als natives Linux-SW-Raid-Array erstellt werden sollte.
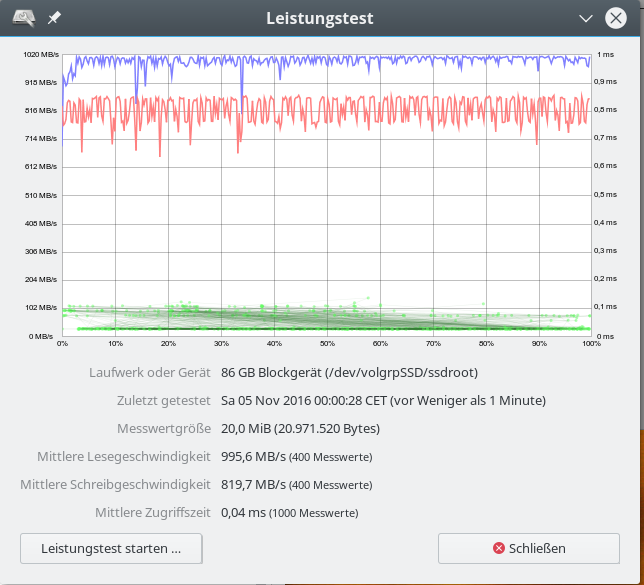
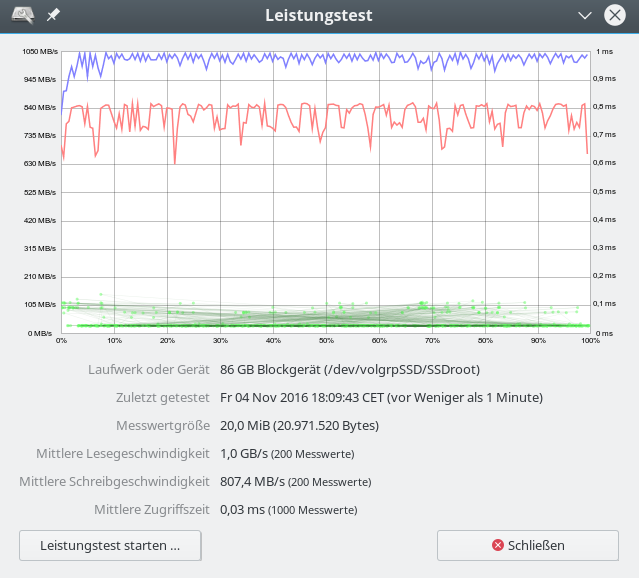
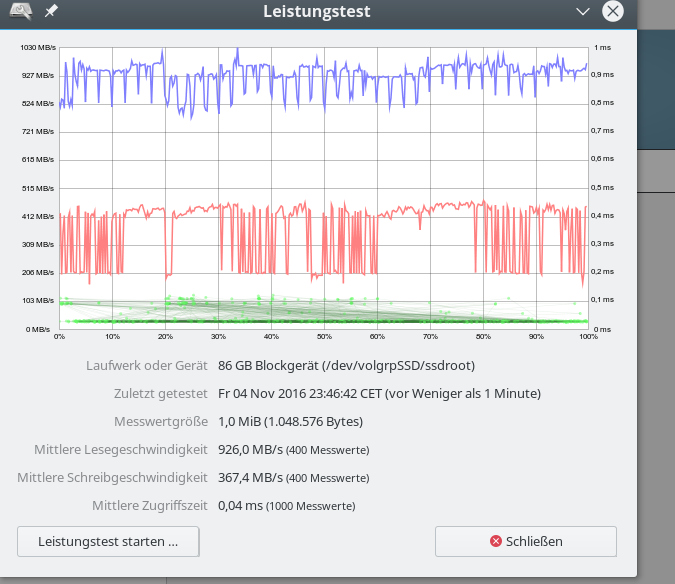
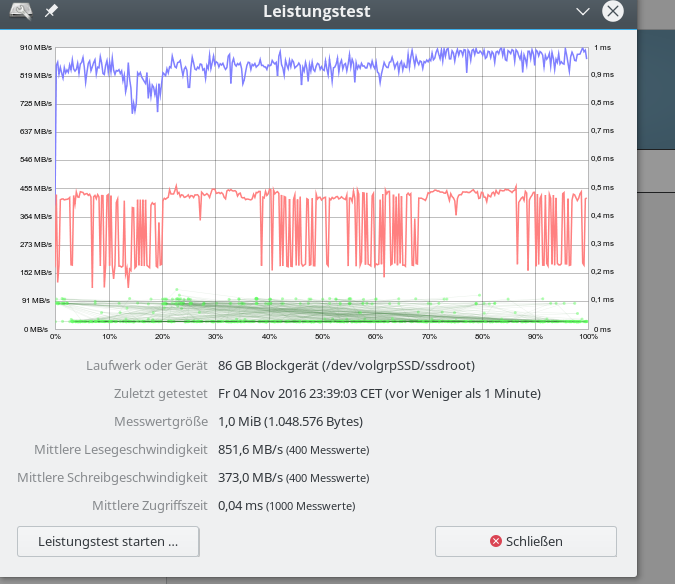
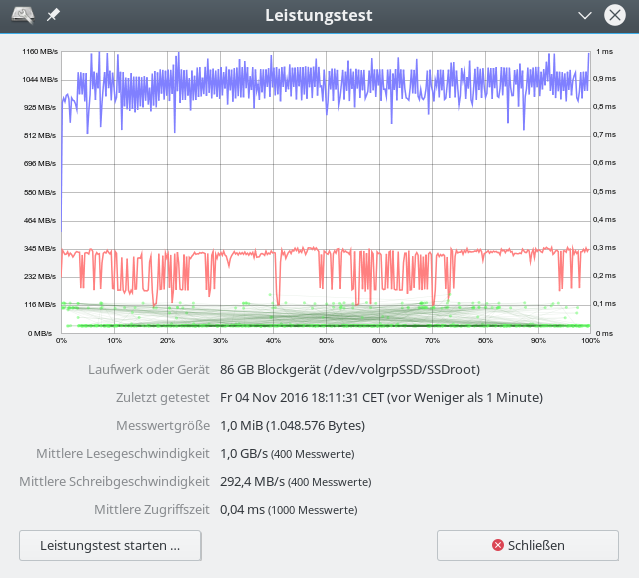
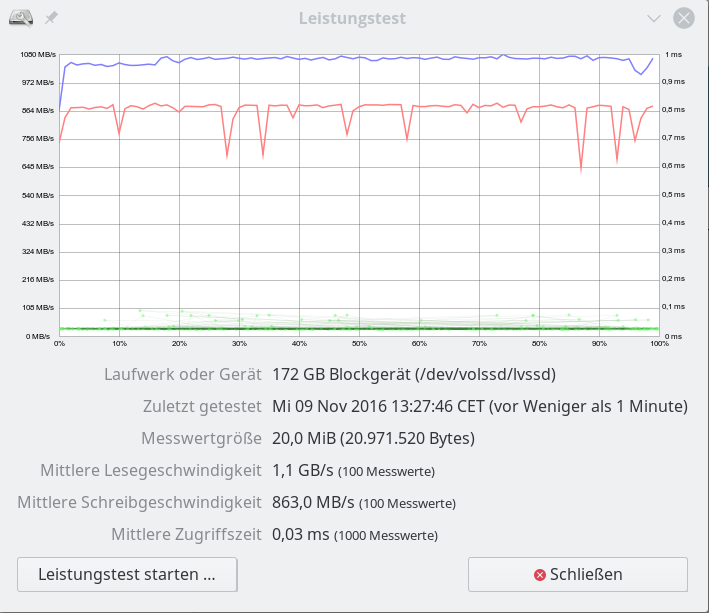
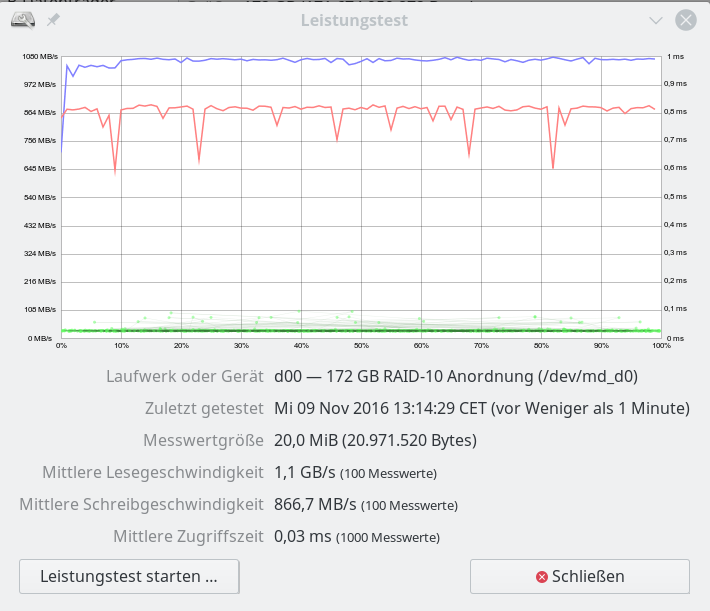
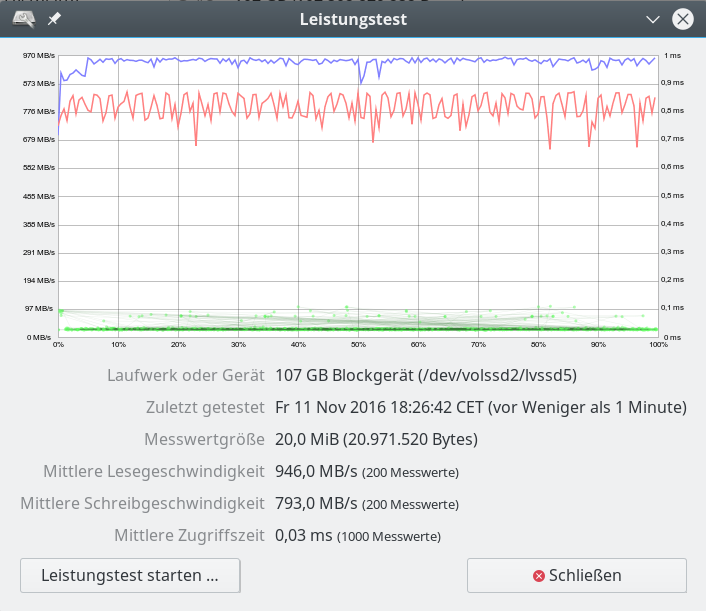
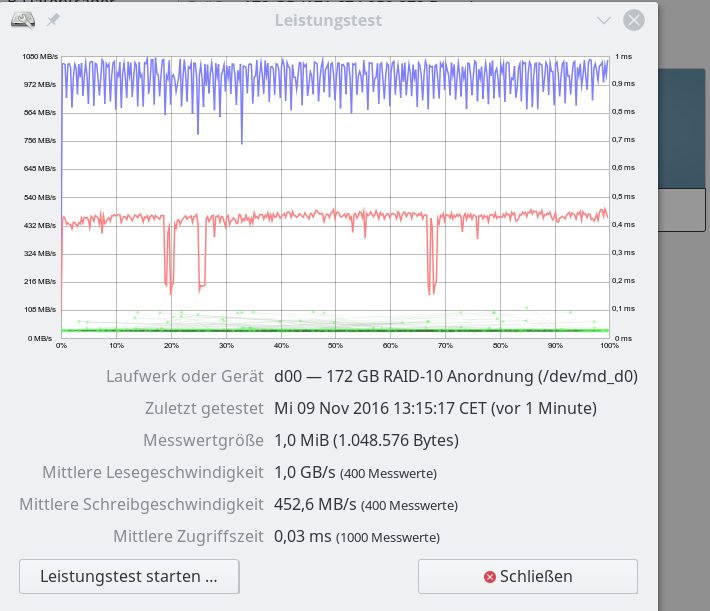
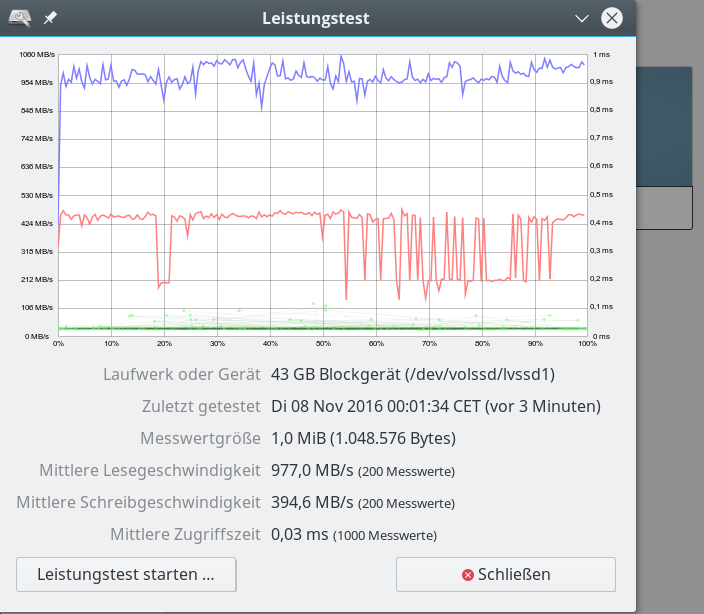
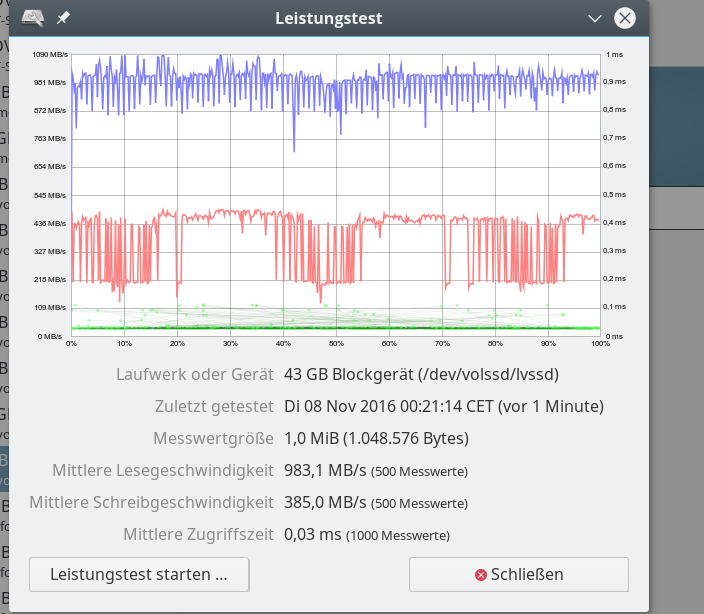
iRST bedeutet Intel Rapid Storage Technologie; wir hatten diese Technologie im letzten Artikel genauer beleuchtet. Aus Performance-Tests für sequentielle Read- oder Write-Zugriffe haben sich dabei keine Anhaltspunkte ergeben, die zwingend für den Einsatz der iRST-Technologie sprechen würden:
Ein natives Linux-SW-Raids mit dem gleichen Onboard-Controller im AHCI-Modus (!) liefert eine vergleichbare oder höhere Performance!
Nun könnte man aber noch Sorgen bzgl. der Boot-Unterstützung haben. Einige Leute werden ja mit dem Gedanken spielen, das Linux-Betriebssystem [OS] selbst auf dem zu konfigurierenden Raid-Array zu installieren.
Ich möchte diesen Wunsch nachfolgend zunächst kritisch hinterfragen, da die Platzierung des OS auf einem ggf. hoch belasteten Raid-Array zumindest einen zusätzlichen Komplexitätsgrad erzeugt. Im nächsten Blog-Beitrag sehe ich mir dann die Boot-Unterstützung genauer an.
Motive für die Installation des Betriebssystem auf einem Raid-Array?
Typische Motive für die Installation des Betriebssystems auf einer Partition des SSD-Raid-Arrays könnten sein:
Verbesserung der Ausfallsicherheit und potentieller Performance-Gewinn
Raid-10- oder Raid-5-Arrays können ja die Lese- und Schreibperformance eines Raid-Verbundes deutlich über die einer einzelnen SSD hinaustreiben! Bei angeblich guter Sicherheit gegenüber dem Ausfall einer einzelnen der beteiligten Platten! Warum das nicht nur für Datenzugriffe von Spezialanwendungen sondern gleich auch für normale operationale Lese- und Schreibzugriffe das Betriebssystems mit nutzen?
Aus meiner Sicht gilt jedoch :
Es gibt mehr gute Gründe gegen die Installation des OS auf einem Raid-Array für die Daten von Anwendungen als dafür. Auf gewöhnlichen Systemen empfiehlt sich eher eine Installation des OS auf einer separaten SSD. Auf Hochperformance-Systemen würde ich das OS zumindest auf einem anderen Array als einem High-Performance-Array für datenintensive Anwendungen anlegen.
Ich führe dafür nachfolgend ein paar Argumente an. Als Voraussetzung nehme ich ein Einsatz-Szenario an, in dem vor allem Datenzugriffe spezieller Anwendungen durch ein Raid-10- oder ein Raid-5-Array beschleunigt werden sollen. Das Raid-Array mit den zugehörigen Daten sei dabei einer regelmäßig hohen Belastung ausgesetzt. Wir nennen es nachfolgend “Last-Array”.
Das ist zwar eine spezielles Szenario; einige der angeführten Argumente sind jedoch auch in anderen Szenarien valide. Das gewählte Szenario zeigt zumindest auf, dass man über die Sinnhaftigkeit einer OS-Installation auf einem für Last ausgelegten Raid-Array nachdenken sollte.
Verbesserung der Ausfallsicherheit?
Aus meiner Sicht gilt ganz grundsätzlich:
Keine einzige Raid-Variante entbindet von regelmäßigen Backups!
Das liegt auf der Hand und ist für Zweifler so oft im Internet begründet worden, dass ich hier auf weitere Ausführungen verzichte.
Zu berücksichtigen ist ferner, dass die Wahrscheinlichkeit, dass gleich belastete SSDs in einem Raid-1/10/5-Verbund etwa gleichzeitig ausfallen werden, ziemlich hoch ist. Auf einem Raid-1, einem Raid-10- oder Raid-5-System darf genau nur eine Platte ausfallen. (Dass es bei Raid-10
Situationen gibt, in denen auch das noch verkraftbar ist, ändert nichts am Grundargument.) Da die Platten in solchen Raid-Verbünden einem in etwa gleichen Verschleiß ausgesetzt sind, wird auch ihr Lebensende etwa zum gleichen Zeitpunkt eintreffen – ggf. stirbt die zweite Platte noch während eines langwierigen Rekonstruktionsvorgangs. Bei einem nicht mehr rekonstruierbaren Raid-System muss man dann aber aber in jedem Fall auf Backups zurückgreifen können.
Ein Szenario mit dem OS auf einer separaten SSD oder einem separaten SSD-Array plus Backups ist demgegenüber also nicht unsicherer. Es reduziert aber die Komplexität und beinhaltet auch eine Lastentkopplung.
Komplexitätsreduktion und Lastentkopplung
Liegen das OS und das Root-Verzeichnis auf einer vom Last-Array separaten SSD bzw. auf einem separaten SSD-Array, so werden die Ausfallmöglichkeiten des Last-Arrays von denen der OS-SSD entkoppelt.
Zudem kommt es zu einer Entkopplung der Last und damit des Verschleißes: Ein hoher Verschleiß der SSDs des Last-Arrays für High-Performance-Anwendungen schlägt sich nicht 1 zu 1 auf die SSD oder das separate SSD-Array des OS nieder. Und ggf. vice versa.
Zudem werden die Strukturen einfacher und flexibler, auch wenn das zunächst nicht den Anschein hat: Nicht ohne Grund mountet man von Haus aus Datenpartitionen oder spezielle Anwendungspartitionen auf bestimmte Zweige des Verzeichnisbaums. Das ermöglicht separate Backups und im Fall von System-Upgrades bleibt die Datenhaltung völlig außen vor. Man denke etwa an Datenbank-Daten, imap-Daten, die Partitionen virtualisierter Systeme etc., die man ggf. auf dem Last-Array platziert hat.
Fällt das Last-Array aus oder degradiert, ist nicht das OS betroffen. Fällt dagegen die SSD des OS aus, kann man das Array sofort wieder auf das Rootverzeichnis eines OS auf einer Ersatz-SSD mounten.
Die Rekonstruktion eines Raid-Arrays erfordert ein laufendes Betriebssystem – eine schnelle Rekonstruktion ein OS auf einer separaten Platte!
Es ergibt sich ein weiterer Punkt, über den man nachdenken sollte:
Hat das Raid-System einen Schaden oder fällt es gar ganz aus, will man trotzdem zeitnah booten können. Die Rekonstruktion eines (SW-) Arrays und das Monitoring dieses Prozesses setzen meist ein laufendes Linux-System voraus. Es ist also durchaus sinnvoll, das OS auf einer separaten SSD oder einem separaten (kleinen) Raid-Array zu halten.
Das Betriebssystem selbst ist bei vernünftiger Partitionierung relativ klein; bei Ausfall der OS-Platte oder -Partition ist es auf einer separaten Ersatzplatte sehr viel schneller rekonstruiert als ein großes Raid-System insgesamt.
Die Rekonstruktion eines defekten degraded Raid-Arrays aus einem auf dem Raid selbst liegenden OS heraus dauert ggf. sehr lange: Eine von Haus aus schlechte Restaurierungs-Performance von z.B. Raid-5-Arrays würde durch den laufenden OS-Betrieb im beschädigten Raid-Verbund noch einmal verschlechtert. Laufende Schreibprozesse aus dem Betriebssystem interferieren mit der Array-Rekonstruktion und können über die heranzuziehenden Paritätsalgorithmen auch nur langsam an das (noch) beschädigte Raid-Array übertragen werden.
Performancegewinn für das Betriebssystem durch RAID?
Linux puffert den normalen Festplattenzugriff so gut, dass man aus meiner Sicht nicht zwingend ein SSD-Array für eine hinreichend gute Basisperformance des Linux-Systems benötigt. Das sieht für spezielle Anwendungen oder etwa einen hochbelasteten Fileservice ggf. anders aus. Für das Kern-OS und seine Platteninteraktionen selbst genügt eine einzelne SSD bei möglichst großem RAM jedoch völlig. Das gilt umso mehr, als gerade bei kleineren Datenpaketen die Raid-Performance je nach Parametrierung sich nur wenig von der perfromance einer SSD abheben mag. Ich werde auf diesen interessanten Punkt in späteren Artikeln zurückkommen.
Beeinträchtigung der Performance eines Last-Raid-Arrays durch ein dort installiertes OS?
Nach meiner bisherigen Erfahrung gilt:
Würde man das OS auf einer Partition eines vorgesehenen (Daten-) Raid-Arrays installieren, so hätte das spürbaren (!) Einfluss auf die Gesamt-Performance dieses Last-Array und dessen Latenz. Random I/O-Prozesse des OS interferieren dann mit denen der Anwendungsprozesse, die man ja eigentlich mit Hilfe des Raid-Systems performanter machen will. Ich habe im Mittel etwa 10% an Performance-Einbußen durch Tests von Arrays mit aktivem OS nachvollziehen können. Für Datenbankanwendungen wie Fileservices, die verschieden konfigurierte Last-Arrays nutzten.
Man sollte das auf seinen eigenen Systemen in jedem Falle überprüfen.
Separates Raid-System für das OS?
Die Frage, ob das OS auf einem (separaten) Raid-System liegen soll, hängt letztlich auch von der Anzahl erstellbarer Raid-Arrays (bzw. im Fall des iRST von der Anzahl separat erstellbarer Container) und damit vom Geldbeutel ab. Ich sehe für eine Installation des OS auf einem Raid-Array, das primär für performanten Daten-I/O bestimmter High-Performance-Anwendungen gedacht ist, keinen überzeugenden Grund. (Es sei denn, man möchte aus irgendwelchen Eitelkeiten heraus extrem schnelle Bootzeiten produzieren.)
Will man das OS aber aus Gründen einer verbesserten Ausfallsicherheit auf einem SSD-Array anlegen, dann bitte auf einem separaten Array (bzw. beim iRST: auf einem Volume eines separaten Containers); dieses Array sollte nicht auch gleichzeitig die Daten geplanter Hochperformance-Anwendungen beherbergen.
Unbestritten ist: Ein separates Raid-10-System mit ggf. hochwertigen Enterprise SSDs ist ein guter Ort für das OS eines Hochperformance-Systems – wenn man denn das dafür nötige Kleingeld hat.
Rücksichtnahme auf Lastprofile!
Ein Raid-System für ein OS erfordert aus Performancegründen ggf. eine andere Parametrierung als ein Last-Array für die Daten von Anwendungen mit einer ganz bestimmten Zugriffs-Charakteristik. Ein Lastprofil, das laufend durch kurze einzelne aufeinander folgende I/O-Spikes für kurze Datenblöcke (< 64KB) gekennzeichnet ist (OS oder bestimmte DB-Anwendungen), ist anders zu bewerten als ein Lastprofil, bei dem viele Jobs parallel große Datenpakete (> 1 MB) auf und von einem Raid-System befördern müssen (Fileserver) oder gar ein Profil, auf dem große Videodateien (> n x 10MB) sequentiell verarbeitet werden.
Entsprechend unterschiedlich sollten zugehörige Raid-Systeme konfiguriert werden. Ich komme darauf in weiteren Artikeln zurück. Auch dieser Punkt spricht für die Trennung des Last-Arrays von Arrays für das OS.
Lösungsansatz: Wie gehe ich persönlich vor?
Sieht man einmal von puren Performance ab, so ist aus den obigen Gründen in vielen Fällen ein Vorgehen sinnvoll, bei dem das OS samt Root-Filesystem auf einer vom Raid-Verband unabhängigen SSD liegt und das Last-Array auf ein Spezialverzeichnis gemountet wird. Zudem ist für eine hinreichende RAM-Ausstattung des Systems zu sorgen. Zu finanzieren ist ferner eine Ersatz-SSD.
Für dieses Vorgehen gilt:
- Es reduziert Komplexität im Bootvorgang.
- Es kann durch Einsatz einer weiteren Ersatz-SSD, die mit einer boot- udn laufenden OS-Installation versehen wird, gegen Ausfälle der OS-SSD abgesichert werden. Die Ersatz-SSD kann gegen Verschleiß weitgehend geschont werden; sie muss erst im Notfall mit einem aktuellen OS-Abbild aus einer Sicherung, die z.B. täglich auf konventionellen Medien (HDD) hinterlegt wurde, versehen werden. Ein solcher Transfer dauert heutzutage nur wenige Minuten. Tipp am Rande: Die Identifikation der OS-Platten im Boot-Loader in diesem Szenario eher konventionell, also neutral und nicht über eindeutige Device-IDs, vornehmen.
- Eine
eintretende Degradierung des Last-Arrays durch einen SSD-Ausfall betrifft nicht die Operabilität anderer Systembestandteile. Mit einem “degraded SSD-Spezial-Array” kann man sich dann kontrolliert von einem immer noch funktionierenden separaten OS aus befassen. - Die SSD für das OS sollte aber Enterprise-Qualität haben und seitens des Herstellers gegen schnellen Verschleiß gewappnet sein.
Käme es auf Geld nicht an, würde ich auf manchen Systemen dem OS und der Root-Partition ein eigenes Raid-10-Array spendieren.
Ausblick
OK – man hat schon gemerkt: Ich halte nicht viel davon, das OS auf einem Raid-Array für die Daten von Hoch-Performance-Anwendungen unterzubringen. Aber manch einer hat entweder so viel Geld, dass er sich ein separates, dediziertes SSD-Raid-Array für das Betriebssystem leisten kann. Oder manch einer ist aus anderen Gründen gzwungen, das OS im einzigen vorhandenen SSD-Raid-Array zu installieren (z.B. auf einem Laptop). dann stellt sich die Frage:
Wird das Booten eines OS in einem Linux-SW-Raid-Array überhaupt unterstützt? Oder ist man hier beim Einsatz von Mainboards mit Intel Chipsatz auf iRST angewiesen?
Darum dreht sich der nächste Artikel dieser Serie:
SSD Raid Arrays unter Linux – V – SW-Raid vs. iRST-Raid – Bootunterstützung?