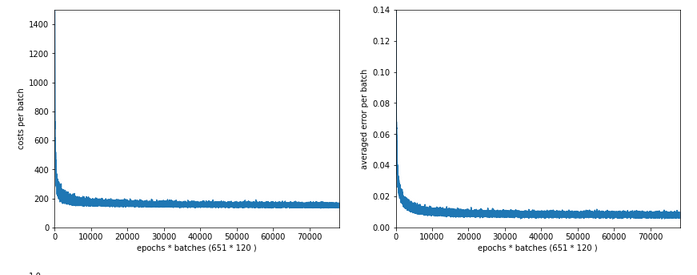
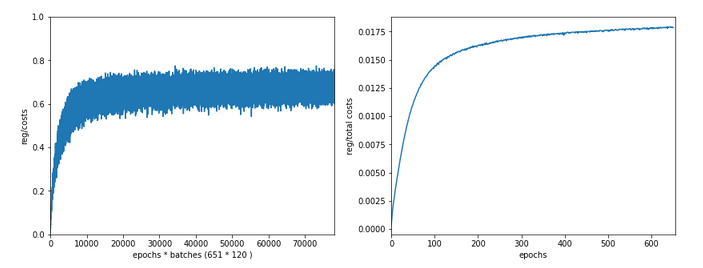
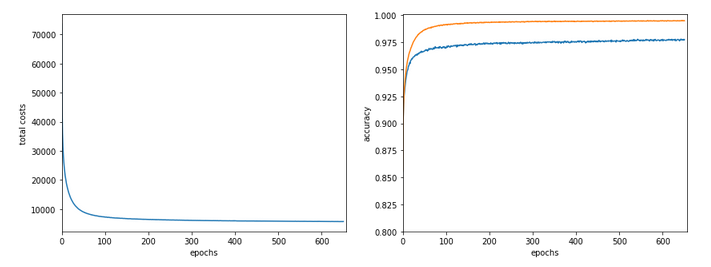
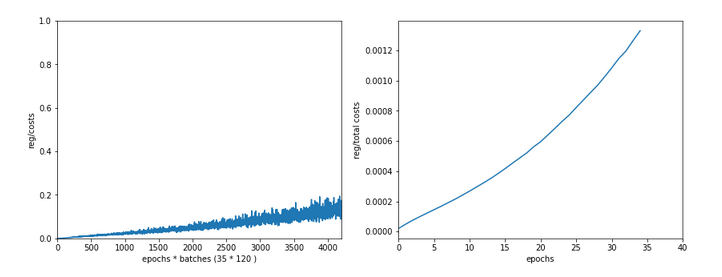
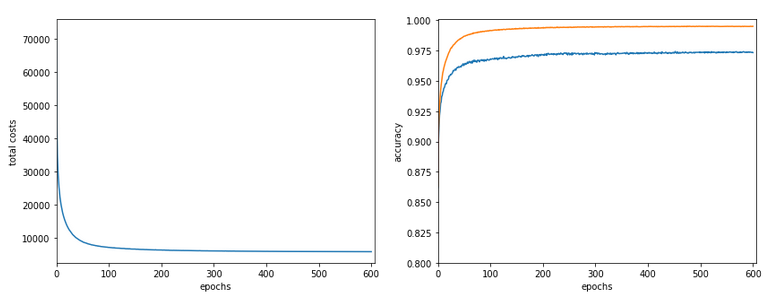
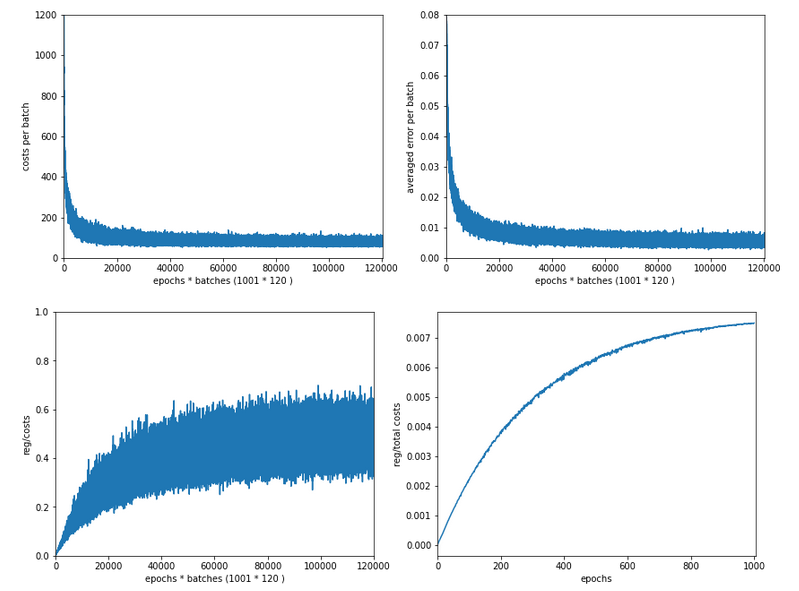
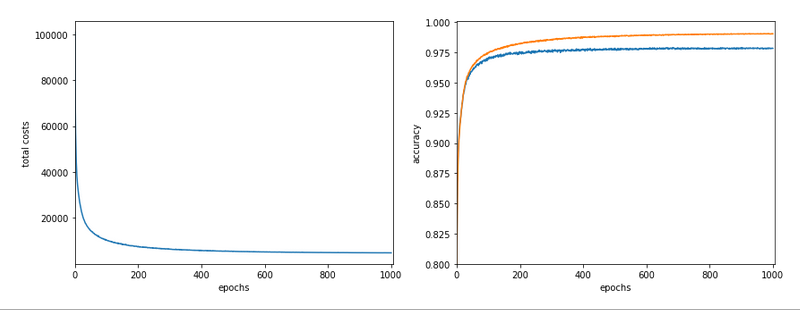
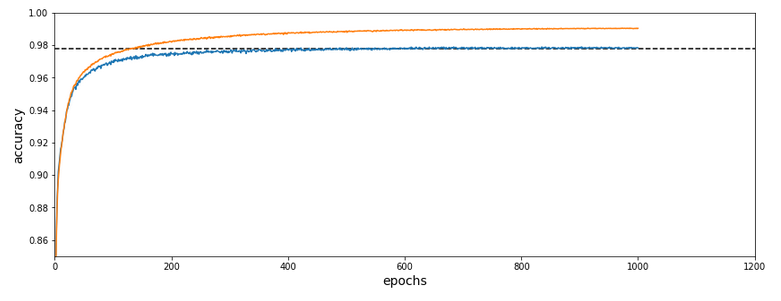
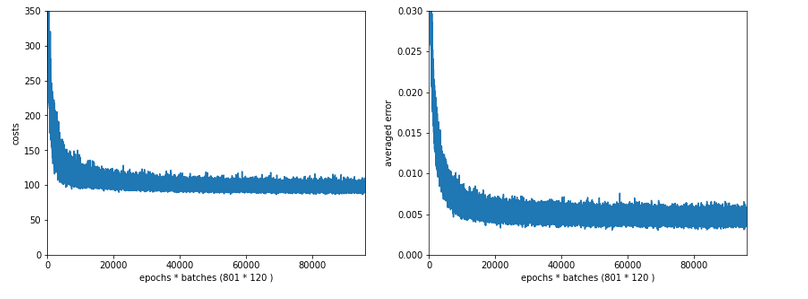
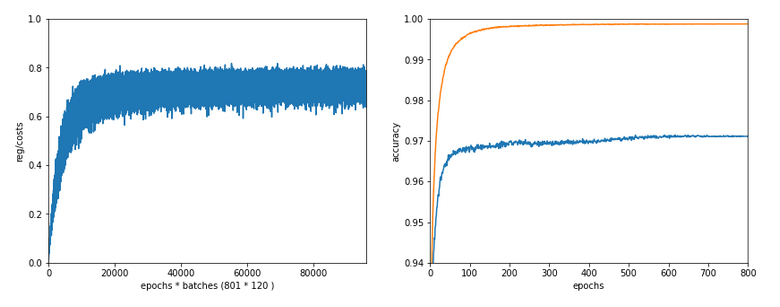
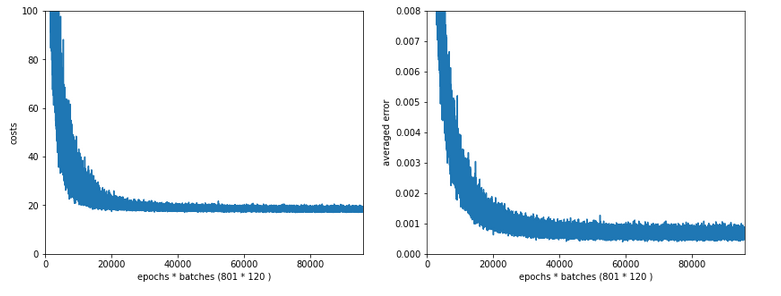
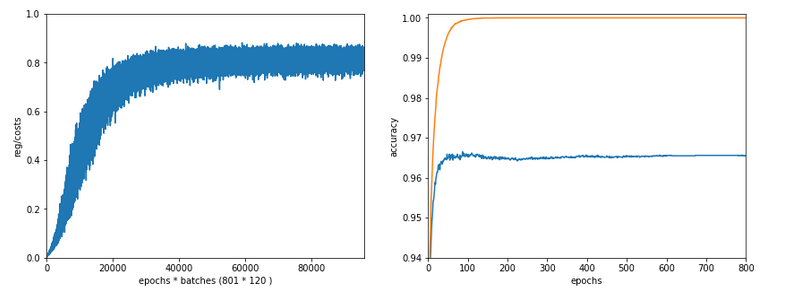
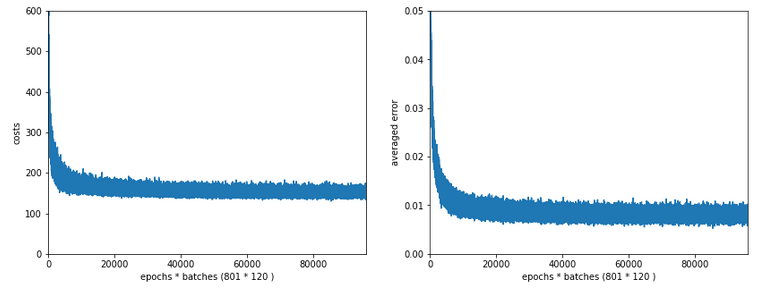
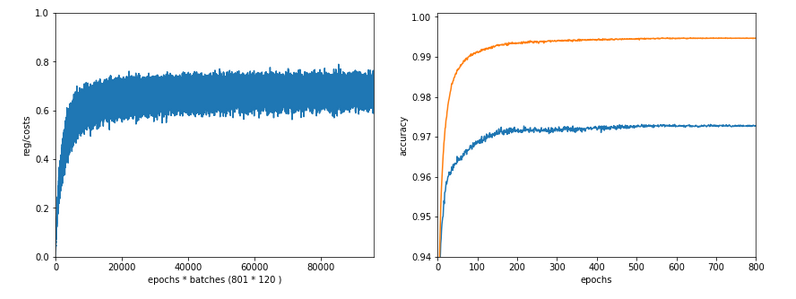
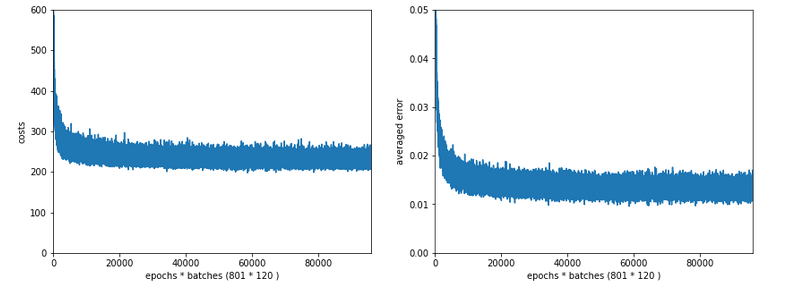
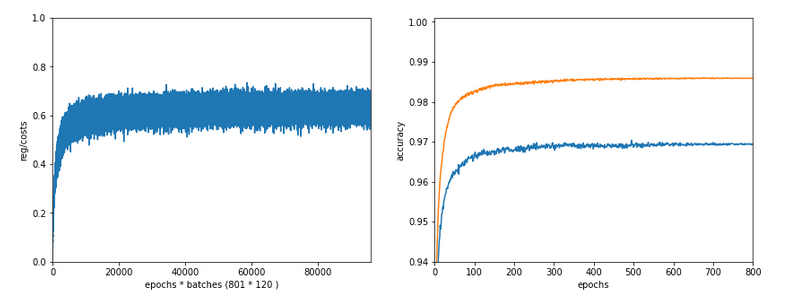
In the last articles of this series
MLP, Numpy, TF2 – performance issues – Step II – bias neurons, F- or C- contiguous arrays and performance
MLP, Numpy, TF2 – performance issues – Step I – float32, reduction of back propagation
we looked at the FW-propagation of the MLP code which I discussed in another article series. We found that the treatment of bias neurons in the input layer was technically inefficient due to a collision of C- and F-contiguous arrays. By circumventing the problem we could accelerate the FW-propagation of big batches (as the complete training or test data set) by more than a factor of 2.
In this article I want to turn to the BW propagation and do some analysis regarding CPU consumption there. We will find a simple (and stupid) calculation step there which we shall replace. This will give us another 15% to 22% performance improvement in comparison to what we have reached in the last article for MNIST data:
- 9.6 secs for 35 epochs and a batch-size of 500
- and 8.7 secs for a batch-size of 20000.
Present CPU time relation between the FW- and the BW-propagation
The central training of mini-batches is performed by the method “_handle_mini_batch()”.
#
''' -- Method to deal with a batch -- '''
def _handle_mini_batch (self, num_batch = 0, num_epoch = 0, b_print_y_vals = False, b_print = False, b_keep_bw_matrices = True):
''' .... '''
# Layer-related lists to be filled with 2-dim Numpy matrices during FW propagation
# ********************************************************************************
li_Z_in_layer = [None] * self._n_total_layers # List of matrices with z-input values for each layer; filled during FW-propagation
li_A_out_layer = li_Z_in_layer.copy() # List of matrices with results of activation/output-functions for each layer; filled during FW-propagation
li_delta_out = li_Z_in_layer.copy() # Matrix with out_delta-values at the outermost layer
li_delta_layer = li_Z_in_layer.copy() # List of the matrices for the BW propagated delta values
li_D_layer = li_Z_in_layer.copy() # List of the derivative matrices D containing partial derivatives of the activation/ouput functions
li_grad_layer = li_Z_in_layer.copy() # List of the matrices with gradient values for weight corrections
# Major steps for the mini-batch during one epoch iteration
# **********************************************************
#ts=time.perf_counter()
# Step 0: List of indices for data records in the present mini-batch
# ******
ay_idx_batch = self._ay_mini_batches[num_batch]
# Step 1: Special preparation of the Z-input to the MLP's input Layer L0
# ******
# ts=time.perf_counter()
# slicing
li_Z_in_layer[0] = self._X_train[ay_idx_batch] # numpy arrays can be indexed by an array of integers
# transposition
#~~~~~~~~~~~~~~
li_Z_in_layer[0] = li_Z_in_layer[0].T
#te=time.perf_counter(); t_batch = te - ts;
#print("\nti - transposed inputbatch =", t_batch)
# Step 2: Call forward propagation method for the present mini-batch of training records
# *******
n #tsa = time.perf_counter()
self._fw_propagation(li_Z_in = li_Z_in_layer, li_A_out = li_A_out_layer)
#tea = time.perf_counter(); ta = tea - tsa; print("ta - FW-propagation", "%10.8f"%ta)
# Step 3: Cost calculation for the mini-batch
# ********
#tsb = time.perf_counter()
ay_y_enc = self._ay_onehot[:, ay_idx_batch]
ay_ANN_out = li_A_out_layer[self._n_total_layers-1]
total_costs_batch, rel_reg_contrib = self._calculate_loss_for_batch(ay_y_enc, ay_ANN_out, b_print = False)
# we add the present cost value to the numpy array
self._ay_costs[num_epoch, num_batch] = total_costs_batch
self._ay_reg_cost_contrib[num_epoch, num_batch] = rel_reg_contrib
#teb = time.perf_counter(); tb = teb - tsb; print("tb - cost calculation", "%10.8f"%tb)
# Step 4: Avg-error for later plotting
# ********
#tsc = time.perf_counter()
# mean "error" values - averaged over all nodes at outermost layer and all data sets of a mini-batch
ay_theta_out = ay_y_enc - ay_ANN_out
ay_theta_avg = np.average(np.abs(ay_theta_out))
self._ay_theta[num_epoch, num_batch] = ay_theta_avg
#tec = time.perf_counter(); tc = tec - tsc; print("tc - error", "%10.8f"%tc)
# Step 5: Perform gradient calculation via back propagation of errors
# *******
#tsd = time.perf_counter()
self._bw_propagation( ay_y_enc = ay_y_enc,
li_Z_in = li_Z_in_layer,
li_A_out = li_A_out_layer,
li_delta_out = li_delta_out,
li_delta = li_delta_layer,
li_D = li_D_layer,
li_grad = li_grad_layer,
b_print = b_print,
b_internal_timing = False
)
#ted = time.perf_counter(); td = ted - tsd; print("td - BW propagation", "%10.8f"%td)
# Step 7: Adjustment of weights
# *******
#tsf = time.perf_counter()
rg_layer=range(0, self._n_total_layers -1)
for N in rg_layer:
delta_w_N = self._learn_rate * li_grad_layer[N]
self._li_w[N] -= ( delta_w_N + (self._mom_rate * self._li_mom[N]) )
# save momentum
self._li_mom[N] = delta_w_N
#tef = time.perf_counter(); tf = tef - tsf; print("tf - weight correction", "%10.8f"%tf)
return None
I took some time measurements there:
ti - transposed inputbatch = 0.0001785 ta - FW-propagation 0.00080975 tb - cost calculation 0.00030705 tc - error 0.00016182 td - BW propagation 0.00112558 tf - weight correction 0.00020079 ti - transposed inputbatch = 0.00018144 ta - FW-propagation 0.00082022 tb - cost calculation 0.00031284 tc - error 0.00016652 td - BW propagation 0.00106464 tf - weight correction 0.00019576
You see that the FW-propagation is a bit faster than the BW-propagation. This is a bit strange as the FW-propagation is dominated meanwhile by a really expensive operation which we cannot accelerate (without choosing a new activation function): The calculation of the sigmoid value for the inputs at layer L1.
So let us look into the BW-propagation; the code for it is momentarily:
''' -- Method to handle error BW propagation for a mini-batch --'''
def _bw_propagation(self,
ay_y_enc, li_Z_in, li_A_out,
li_delta_out, li_delta, li_D, li_
grad,
b_print = True, b_internal_timing = False):
# List initialization: All parameter lists or arrays are filled or to be filled by layer operations
# Note: the lists li_Z_in, li_A_out were already filled by _fw_propagation() for the present batch
# Initiate BW propagation - provide delta-matrices for outermost layer
# ***********************
tsa = time.perf_counter()
# Input Z at outermost layer E (4 layers -> layer 3)
ay_Z_E = li_Z_in[self._n_total_layers-1]
# Output A at outermost layer E (was calculated by output function)
ay_A_E = li_A_out[self._n_total_layers-1]
# Calculate D-matrix (derivative of output function) at outmost the layer - presently only D_sigmoid
ay_D_E = self._calculate_D_E(ay_Z_E=ay_Z_E, b_print=b_print )
#ay_D_E = ay_A_E * (1.0 - ay_A_E)
# Get the 2 delta matrices for the outermost layer (only layer E has 2 delta-matrices)
ay_delta_E, ay_delta_out_E = self._calculate_delta_E(ay_y_enc=ay_y_enc, ay_A_E=ay_A_E, ay_D_E=ay_D_E, b_print=b_print)
# add the matrices to their lists ; li_delta_out gets only one element
idxE = self._n_total_layers - 1
li_delta_out[idxE] = ay_delta_out_E # this happens only once
li_delta[idxE] = ay_delta_E
li_D[idxE] = ay_D_E
li_grad[idxE] = None # On the outermost layer there is no gradient !
tea = time.perf_counter(); ta = tea - tsa; print("\nta-bp", "%10.8f"%ta)
# Loop over all layers in reverse direction
# ******************************************
# index range of target layers N in BW direction (starting with E-1 => 4 layers -> layer 2))
range_N_bw_layer = reversed(range(0, self._n_total_layers-1)) # must be -1 as the last element is not taken
# loop over layers
tsb = time.perf_counter()
for N in range_N_bw_layer:
# Back Propagation operations between layers N+1 and N
# *******************************************************
# this method handles the special treatment of bias nodes in Z_in, too
tsib = time.perf_counter()
ay_delta_N, ay_D_N, ay_grad_N = self._bw_prop_Np1_to_N( N=N, li_Z_in=li_Z_in, li_A_out=li_A_out, li_delta=li_delta, b_print=False )
teib = time.perf_counter(); tib = teib - tsib; print("N = ", N, " tib-bp", "%10.8f"%tib)
# add matrices to their lists
#tsic = time.perf_counter()
li_delta[N] = ay_delta_N
li_D[N] = ay_D_N
li_grad[N]= ay_grad_N
#teic = time.perf_counter(); tic = teic - tsic; print("\nN = ", N, " tic = ", "%10.8f"%tic)
teb = time.perf_counter(); tb = teb - tsb; print("tb-bp", "%10.8f"%tb)
return
Typical timing results are:
ta-bp 0.00007112 N = 2 tib-bp 0.00025399 N = 1 tib-bp 0.00051683 N = 0 tib-bp 0.00035941 tb-bp 0.00126436 ta-bp 0.00007492 N = 2 tib-bp 0.00027644 N = 1 tib-bp 0.00090043 N = 0 tib-bp 0.00036728 tb-bp 0.00168378
We see that the CPU consumption of “_bw_prop_Np1_to_N()” should be analyzed in detail. It is relatively time consuming at every layer, but especially at layer L1. (The list adds are insignificant.)
What does this method presently look like?
''' -- Method to calculate the BW-propagated delta-matrix and the gradient matrix to/for layer N '''
def _bw_prop_Np1_to_N(self, N, li_Z_in, li_A_out, li_delta, b_print=False):
'''
BW-
error-propagation between layer N+1 and N
Version 1.5 - partially accelerated
Inputs:
li_Z_in: List of input Z-matrices on all layers - values were calculated during FW-propagation
li_A_out: List of output A-matrices - values were calculated during FW-propagation
li_delta: List of delta-matrices - values for outermost ölayer E to layer N+1 should exist
Returns:
ay_delta_N - delta-matrix of layer N (required in subsequent steps)
ay_D_N - derivative matrix for the activation function on layer N
ay_grad_N - matrix with gradient elements of the cost fnction with respect to the weights on layer N
'''
# Prepare required quantities - and add bias neuron to ay_Z_in
# ****************************
# Weight matrix meddling between layers N and N+1
ay_W_N = self._li_w[N]
# delta-matrix of layer N+1
ay_delta_Np1 = li_delta[N+1]
# fetch output value saved during FW propagation
ay_A_N = li_A_out[N]
# Optimization V1.5 !
if N > 0:
#ts=time.perf_counter()
ay_Z_N = li_Z_in[N]
# !!! Add intermediate row (for bias) to Z_N !!!
ay_Z_N = self._add_bias_neuron_to_layer(ay_Z_N, 'row')
#te=time.perf_counter(); t1 = te - ts; print("\nBW t1 = ", t1, " N = ", N)
# Derivative matrix for the activation function (with extra bias node row)
# ********************
# can only be calculated now as we need the z-values
#ts=time.perf_counter()
ay_D_N = self._calculate_D_N(ay_Z_N)
#te=time.perf_counter(); t2 = te - ts; print("\nBW t2 = ", t2, " N = ", N)
# Propagate delta
# **************
# intermediate delta
# ~~~~~~~~~~~~~~~~~~
#ts=time.perf_counter()
ay_delta_w_N = ay_W_N.T.dot(ay_delta_Np1)
#te=time.perf_counter(); t3 = te - ts; print("\nBW t3 = ", t3)
# final delta
# ~~~~~~~~~~~
#ts=time.perf_counter()
ay_delta_N = ay_delta_w_N * ay_D_N
# Orig reduce dimension again
# ****************************
ay_delta_N = ay_delta_N[1:, :]
#te=time.perf_counter(); t4 = te - ts; print("\nBW t4 = ", t4)
else:
ay_delta_N = None
ay_D_N = None
# Calculate gradient
# ********************
#ts=time.perf_counter()
ay_grad_N = np.dot(ay_delta_Np1, ay_A_N.T)
#te=time.perf_counter(); t5 = te - ts; print("\nBW t5 = ", t5)
# regularize gradient (!!!! without adding bias nodes in the L1, L2 sums)
#ts=time.perf_counter()
if self._lambda2_reg > 0:
ay_grad_N[:, 1:] += self._li_w[N][:, 1:] * self._lambda2_reg
if self._lambda1_reg > 0:
ay_grad_N[:, 1:] += np.sign(self._li_w[N][:, 1:]) * self._lambda1_reg
#te=time.perf_counter(); t6 = te - ts; print("\nBW t6 = ", t6)
return ay_delta_N, ay_D_N, ay_grad_N
Timing data for a batch-size of 500 are:
N = 2 BW t1 = 0.0001169009999557602 N = 2 BW t2 = 0.00035331499998392246 N = 2 BW t3 = 0.00018078099992635543 BW t4 = 0.00010234199999104021 BW t5 = 9.928200006470433e-05 BW t6 = 2.4267000071631628e-05 N = 2 tib-bp 0.00124414 N = 1 BW t1 = 0.0004323499999827618 N = 1 BW t2 = 0. 000781415999881574 N = 1 BW t3 = 4.2077999978573644e-05 BW t4 = 0.00022921000004316738 BW t5 = 9.376399998473062e-05 BW t6 = 0.00012183700005152787 N = 1 tib-bp 0.00216281 N = 0 BW t5 = 0.0004289769999559212 BW t6 = 0.00015404999999191205 N = 0 tib-bp 0.00075249 .... N = 2 BW t1 = 0.00012802800006284087 N = 2 BW t2 = 0.00034988200013685855 N = 2 BW t3 = 0.0001854429999639251 BW t4 = 0.00010359299994888715 BW t5 = 0.00010210400000687514 BW t6 = 2.4010999823076418e-05 N = 2 tib-bp 0.00125854 N = 1 BW t1 = 0.0004407169999467442 N = 1 BW t2 = 0.0007845899999665562 N = 1 BW t3 = 0.00025684100000944454 BW t4 = 0.00012409999999363208 BW t5 = 0.00010345399982725212 BW t6 = 0.00012994100006835652 N = 1 tib-bp 0.00221321 N = 0 BW t5 = 0.00044504700008474174 BW t6 = 0.00016473000005134963 N = 0 tib-bp 0.00071442 .... N = 2 BW t1 = 0.000292730999944979 N = 2 BW t2 = 0.001102525000078458 N = 2 BW t3 = 2.9429999813146424e-05 BW t4 = 8.547999868824263e-06 BW t5 = 3.554099998837046e-05 BW t6 = 2.5041999833774753e-05 N = 2 tib-bp 0.00178565 N = 1 BW t1 = 3.143399999316898e-05 N = 1 BW t2 = 0.0006720640001276479 N = 1 BW t3 = 5.4785999964224175e-05 BW t4 = 9.756200006449944e-05 BW t5 = 0.0001605449999715347 BW t6 = 1.8391000139672542e-05 N = 1 tib-bp 0.00147566 N = 0 BW t5 = 0.0003641810001226986 BW t6 = 6.338999992294703e-05 N = 0 tib-bp 0.00046542
It seems that we should care about t1, t2, t3 for hidden layers and maybe about t5 at layers L1/L0.
However, for a batch-size of 15000 things look a bit different:
N = 2 BW t1 = 0.0005776280000304723 N = 2 BW t2 = 0.004995969999981753 N = 2 BW t3 = 0.0003165199999557444 BW t4 = 0.0005244750000201748 BW t5 = 0.000518499999998312 BW t6 = 2.2458999978880456e-05 N = 2 tib-bp 0.00736144 N = 1 BW t1 = 0.0010120430000029046 N = 1 BW t2 = 0.010797029000002567 N = 1 BW t3 = 0.0005006920000028003 BW t4 = 0.0008704929999794331 BW t5 = 0.0010805200000163495 BW t6 = 3.0326000000968634e-05 N = 1 tib-bp 0.01463436 N = 0 BW t5 = 0.006987539000022025 BW t6 = 0.00023552499999368592 N = 0 tib-bp 0.00730959 N = 2 BW t1 = 0.0006299790000525718 N = 2 BW t2 = 0.005081416999985322 N = 2 BW t3 = 0.00018547400003399162 BW t4 = 0.0005970070000103078 BW t5 = 0.000564008000026206 BW t6 = 2.3311000006742688e-05 N = 2 tib-bp 0.00737899 N = 1 BW t1 = 0.0009376909999900818 N = 1 BW t2 = 0.010650266999959968 N = 1 BW t3 = 0.0005232729999988806 BW t4 = 0.0009100700000317374 BW t5 = 0.0011237720000281115 BW t6 = 0.00016643800000792908 N = 1 tib-bp 0.01466144 N = 0 BW t5 = 0.006987463000029948 BW t6 = 0.00023978600000873485 N = 0 tib-bp 0.00734308
For big batch-sizes “t2” dominates everything. It seems that we have found another code area which causes the trouble with big batch-sizes which we already observed before!
What operations do the different CPU times stand for?
To keep an overview without looking into the code again, I briefly summarize which operations cause which of the measured time differences:
- “t1” – which contributes for small batch-sizes stands for adding a bias neuron to the input data Z_in at each layer.
- “t2” – which is by far dominant for big batch sizes stands for calculating the derivative of the output/activation function (in our case of the sigmoid function) at the various layers.
- “t3” – which contributes at
some layers stands for a dot()-matrix multiplication with the transposed weight-matrix, - “t4” – covers an element-wise matrix-multiplication,
- “t5” – contributes at the BW-transition from layer L1 to L0 and covers the matrix multiplication there (including the full output matrix with the bias neurons at L0)
Use the output values calculated at each layer during FW-propagation!
Why does the calculation of the derivative of the sigmoid function take so much time? Answer: Because I coded it stupidly! Just look at it:
''' -- Method to calculate the matrix with the derivative values of the output function at outermost layer '''
def _calculate_D_N(self, ay_Z_N, b_print= False):
'''
This method calculates and returns the D-matrix for the outermost layer
The D matrix contains derivatives of the output function with respect to local input "z_j" at outermost nodes.
Returns
------
ay_D_E: Matrix with derivative values of the output function
with respect to local z_j valus at the nodes of the outermost layer E
Note: This is a 2-dim matrix over layer nodes and training samples of the mini-batch
'''
if self._my_out_func == 'sigmoid':
ay_D_E = self._D_sigmoid(ay_Z = ay_Z_N)
else:
print("The derivative for output function " + self._my_out_func + " is not known yet!" )
sys.exit()
return ay_D_E
''' -- method for the derivative of the sigmoid function-- '''
def _D_sigmoid(self, ay_Z):
'''
Derivative of sigmoid function with respect to Z-values
- works via expit element-wise on matrices
Input: Z - Matrix with Input values for the activation function Phi() = sigmoid()
Output: D - Matrix with derivative values
'''
S_Z = self._sigmoid(ay_Z)
return S_Z * (1.0 - S_Z)
We first call an intermediate function which then directs us to the right function for a chosen activation function. Well meant: So far, we use only the sigmoid function, but it could e.g. also be the relu() or tanh()-function. So, we did what we did for the sake of generalization. But we did it badly because of two reasons:
- We did not keep up a function call pattern which we introduced in the FW-propagation.
- The calculation of the derivative is inefficient.
The first point is a minor one: During FW-propagation we called the right (!) activation function, i.e. the one we choose by input parameters to our ANN-object, by an indirect call. Why not do it the same way here? We would avoid an intermediate function call and keep up a pattern. Actually, we prepared the necessary definitions already in the __init__()-function.
The second point is relevant for performance: The derivative function produces the correct results for a given “ay_Z”, but this is totally inefficient in our BW-situation. The code repeats a really expensive operation which we have already performed during FW-propagation: calling sigmoid(ay_Z) to get “A_out”-values per layer then. We even put the A_out-values [=sigmoid(ay_Z_in)] per layer and batch (!) with some foresight into a list in “li_A_out[]” at that point of the code (see the FW-propagation code discussed in the last article).
So, of course, we should use these “A_out”-values now in the BW-steps! No further comment …. you see what we need to do.
Hint: Actually, also other activation functions “act(Z)” like e.g. the “tanh()”-function have derivatives which depend on on “A=act(
Z)”, only. So, we should provide Z and A via an interface to the derivative function and let the respective functions take what it needs.
But, my insight into my own dumbness gets worse.
Eliminate the bias neuron operation!
Why did we need a bias-neuron operation? Answer: We do not need it! It was only introduced due to insufficient cleverness. In the article
I have already indicated that we use the function for adding a row of bias-neurons again only to compensate one deficit: The matrix of the derivative values did not fit the shape of the weight matrix for the required element-wise operations. However, I also said: There probably is an alternative.
Well, let me make a long story short: The steps behind t1 up to t4 to calculate “ay_delta_N” for the present layer L_N (with N>=1) can be compressed into two relatively simple lines:
ay_delta_w_N = ay_W_N.T.dot(ay_delta_Np1)
ay_delta_N = ay_delta_w_N[1:,:] * ay_A_N[1:,:] * (1.0 – ay_A_N[1:,:]); ay_D_N = None;
No bias back and forth corrections! Instead we use simple slicing to compensate for our weight matrices with a shape covering an extra row of bias node output. No Z-based derivative calculation; no sigmoid(Z)-call. The last statement is only required to support the present output interface. Think it through in detail; the shortcut does not cause any harm.
Code change for tests
Before we bring the code into a new consolidated form with re-coded methods let us see what we gain by just changing the code to the two lines given above in terms of CPU time and performance. Our function “_bw_prop_Np1_to_N()” then gets reduced to the following lines:
''' -- Method to calculate the BW-propagated delta-matrix and the gradient matrix to/for layer N '''
def _bw_prop_Np1_to_N(self, N, li_Z_in, li_A_out, li_delta, b_print=False):
# Weight matrix meddling between layers N and N+1
ay_W_N = self._li_w[N]
ay_delta_Np1 = li_delta[N+1]
# fetch output value saved during FW propagation
ay_A_N = li_A_out[N]
# Optimization from previous version
if N > 0:
#ts=time.perf_counter()
ay_Z_N = li_Z_in[N]
# Propagate delta
# ~~~~~~~~~~~~~~~~~
ay_delta_w_N = ay_W_N.T.dot(ay_delta_Np1)
ay_delta_N = ay_delta_w_N[1:,:] * ay_A_N[1:,:] * (1.0 - ay_A_N[1:,:])
ay_D_N = None;
else:
ay_delta_N = None
ay_D_N = None
# Calculate gradient
# ********************
ay_grad_N = np.dot(ay_delta_Np1, ay_A_N.T)
if self._lambda2_reg > 0:
ay_grad_N[:, 1:] += self._li_w[N][:, 1:] * self._lambda2_reg
if self._lambda1_reg > 0:
ay_grad_N[:, 1:] += np.sign(self._li_w[N][:, 1:]) * self._lambda1_reg
return ay_delta_N, ay_D_N, ay_grad_N
Performance gain
What run times do we get with this setting? We perform our typical test runs over 35 epochs – but this time for two different batch-sizes:
Batch-size = 500
------------------ Starting epoch 35 Time_CPU for epoch 35 0.2169024469985743 Total CPU-time: 7.52385053600301 learning rate = 0.0009994051838157095 total costs of training set = -1.0 rel. reg. contrib. to total costs = -1.0 total costs of last mini_batch = 65.43618 rel. reg. contrib. to batch costs = 0.12302863 mean abs weight at L0 : -10.0 mean abs weight at L1 : -10.0 mean abs weight at L2 : -10.0 avg total error of last mini_batch = 0.00758 presently batch averaged accuracy = 0.99272 ------------------- Total training Time_CPU: 7.5257336139984545
Not bad! We became faster by around 2 secs compared to the results of the last article! This is close to an improvement of 20%.
But what about big batch sizes? Here is the result for a relatively big batch size:
Batch-size = 20000
------------------ Starting epoch 35 Time_CPU for epoch 35 0.2019189490019926 Total CPU-time: 6.716679593999288 learning rate = 9.994051838157101e-05 total costs of training set = -1.0 rel. reg. contrib. to total costs = -1.0 total costs of last mini_batch = 13028.141 rel. reg. contrib. to batch costs = 0.00021923862 mean abs weight at L0 : -10.0 mean abs weight at L1 : -10.0 mean abs weight at L2 : -10.0 avg total error of last mini_batch = 0.04389 presently batch averaged accuracy = 0.95602 ------------------- Total training Time_CPU: 6.716954112998792
Again an acceleration by roughly 2 secs – corresponding to an improvement of 22%!
In both cases I took the best result out of three runs.
Conclusion
Enough for today! We have done a major step with regard to performance optimization also in the BW-propagation. It remains to re-code the derivative calculation in form which uses indirect function calls to remain flexible. I shall give you the code in the next article.
We learned today is that we, of course, should reuse the results of the FW-propagation and that it is indeed a good investment to save the output data per layer in some Python list or other suitable structures during FW-propagation. We also saw again that a sufficiently efficient bias neuron treatment can be achieved by a more efficient solution than provisioned so far.
All in all we have meanwhile gained more than a factor of 6.5 in performance since we started with optimization. Our new standard values are 7.3 secs and 6.8 secs for 35 epochs on MNIST data and batch sizes of 500 and 20000, respectively.
We have reached the order of what Keras and TF2 can deliver on a CPU for big batch sizes. For small batch sizes we are already faster. This indicates that we have done no bad job so far …
In the next article we shall look a bit at the matrix operations and evaluate further optimization options.