My present post series on veth devices and Linux network namespaces continues articles I have written in 2017 about virtual networking and veth based connections. The last two posts of the present series
- More fun with veth, network namespaces, VLANs – IV – L2-segments, same IP-subnet, ARP and routes
- More fun with veth, network namespaces, VLANs – V – link two L2-segments of the same IP-subnet by a routing network namespace
were a kind of excursion: We studied the effects of routes on ARP-requests in network namespaces where two or more L2-segments of a LAN terminated – with all IPs in both L2-segments belonging to one and the same IP subnet. So far, the considered segments in this series were standard L2-segments, not VLAN segments.
Despite being instructive, scenarios with multiple standard L2-segments attached to a namespace (or virtualized host) are a bit academic. However, when you replace the virtual L2-segments by private virtual VLAN segments we come to more relevant network configurations. A namespace or a virtualized host with multiple attached VLAN segments is not academic. Even without forwarding and even if the namespace got just one IP. We speak of a virtual “multi-homed” namespace (or virtualized host) connected to multiple VLAN segments.
What could be relevant examples?
- Think of a virtual host that administers other guest systems in various private VLANs of a virtualization server! To achieve this we need routes in the multi-homed host, but no forwarding.
- On the other side think of a namespace/host where multiple VLANs terminate and where groups of LAN segments must be connected to each other or to the outer world. In this case we would combine private VLANs with forwarding; the namespace would become a classic router for virtual hosts loacted in different VLANs.
The configuration of virtual private VLAN scenarios based on Linux veth and bridge devices is our eventual objective. In forthcoming posts we will consider virtual VLANs realized with the help of veth subdevices. Such VLANs follow the IEEE 802.1q standard for the Link layer. And regarding VLAN-aware bridges we may refer to RFC5517. A Linux (virtual) bridge fulfills almost all of the requirements of this RFC.
This very limited set of tools gives us a choice between many basic options of setting up a complex VLAN landscape. Different options to configure Linux bridge ports and/or VLAN aware veth endpoints in namespaces extends the spectrum of decisions to be made. An arangement of multiple cascading bridges may define a complex hierarchcal topology. But there are other factors, too. Understanding the influence of routes and of Linux kernel parameters on the path and propagation of ARP and ICMP requests in virtual LANs with VLANs and multi-homed namespaces (or hosts) can become crucial regarding both functionality and weak points of different solutions.
In this post we start with briefly discussing different basic options of VLAN creation. We then look closer at configuration variants for veth VLAN aware interfaces inside a namespace. The results will prepares us for two very simple VLAN scenarios that will help us to investigate the impact of routes and kernel parameters in the next two posts. In later posts I will turn to the port configuration of Linux bridges for complex VLAN solutions.
Private VLANs and veth endpoints
We speak of private VLANs because we want to separate packet traffic between different groups of hosts within a LAN-segment – on the Link layer. This requires that the packets get marked and processed according to these marks. In a 802.1q compliant VLAN the packets get VLAN tags, which identify a VLAN ID [VID] in special data sections of Ethernet packets. By analyzing these tags by and in VLAN aware devices we can filter packets and thus subdivide the original LAN segment into different VLAN-segments. Private VLAN segments form a Link layer broadcast domain (here: Ethernet broadcast domain) of their own.
The drawing below shows tagged packets (diamond like shape) moving along one and the same veth connection line. The colors represent a certain VID.
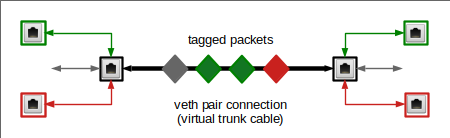
We see some VLAN aware network devices on both sides. They send and receive packets with certain tags only. A veth endpoint can be supplemented with such VLAN aware subdevices. The device in the middle may instead handle untagged packets only. But we could also have something like this:
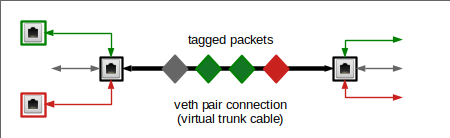
Here on the right side a typical “trunk interface” transports all kinds of tagged and untagged packets into a target space – which could be a namespace or the inner part of a bridge. We will see that such a trunk interface is realized by a standard veth endpoint.
Basic VLAN variants based on veths and Linux bridges
Linux bridge ports for attached VLAN aware or unaware devices can be configured in various ways to tag or de-tag packets. Via VID-related filters the bridge can establish and control allowed or disallowed connections between its ports, all on the Link layer. Based on veths and Linux bridges there are four basic ways to set up to (virtual) VLAN solutions:
- We can completely rely on the tagging and traffic separation abilities of Linux bridges. All namespaces and hosts would be connected to the bridge via veth lines and devices that transport untagged packets, only. The bridge then defines the VLANs of a LAN-segment.
- We can start with VLAN separation already in the multi-homed namespace/host via VLAN aware sub-devices of veth endpoints and connect respective VLAN-aware devices or a trunk device of a veth peer device to the bridge. These options require different settings on bridge ports.
- We can combine approaches (1) and (2).
- We can connect different namespaces directly via VLAN aware veth peer devices.