Hinweis:
Der nachfolgende Artikel wurde am 21.02.2017 vollständig überarbeitet – ein von mir am 20.02.2017 als Problem dargestelltes Verhalten der “Susefirewall2” im Zusammenspiel mit “libvirtd” halte ich nun für korrekt und angemessen. Ich konnte das am gestrigen Abend in einem Anfall von geistiger Umnachtung nur nicht sofort richtig einordnen. Aber auch aus der eigenen Vergesslichkeit kann man ja was lernen ….
Ich habe gestern probeweise einen KVM-Gast (Kali) unter Opensuse Leap 42.3 installiert. Das von der KVM-Instanz zu nutzende virtuelle Netzwerk namens “deb” hatte ich mit Hilfe von “virt-manager” als “Isolated network, internal and host routing only” aufgesetzt. In diesem Fall für ein C-Netz 192.168.10.0/24.
Die korrespondierende Definitionsdatei “/etc/libvirt/networks/deb.xml” sieht dann wie folgt aus
mytux:/etc/libvirt/qemu/networks # cat deb.xml
<!--
WARNING: THIS IS AN AUTO-GENERATED FILE. CHANGES TO IT ARE LIKELY TO BE
OVERWRITTEN AND LOST. Changes to this xml configuration should be made using:
virsh net-edit kali
or other application using the libvirt API.
-->
<network>
<name>deb</name>
<uuid>8a344aae-20c0-436b-b2a6-daf4d1d10e90</uuid>
<bridge name='virbr3' stp='on' delay='0'/>
<mac address='52:54:00:bf:4f:73'/>
<domain name='kali'/>
<ip address='192.168.10.1' netmask='255.255.255.0'>
<dhcp>
<range start='192.168.10.10' end='192.168.50.254'/>
</dhcp>
</ip>
</network>
Für jemanden, der sich mit virtuellen Netzwerken auskennt, erscheint an dieser Stelle klar, dass auf dem Host eine virtuelle Bridge (in meinem Fall “virbr3”) implementiert wird, die eine IP-Adresse auf dem Host erhält (192.168.10.1; Device virbr3-nic). Virtuelle KVM Gast-Maschinen, die das eben definierte virtuelle Netz nutzen, erhalten dann je ein virtuelles Netzwerk-Device (vnetx, x=0,1,2 …), welches an die Bridge angebunden wird. Ebenso klar ist, dass das neue Netzwerk ohne IP-Forwarding auf dem Host nur den Host selbst erreichen wird.
Im laufenden Betrieb meines KVM-Gastes sieht das dann auf dem Host so aus:
mytux:/etc/sysconfig # brctl show virbr3
bridge name bridge id STP enabled interfaces
virbr3 8000.525400026902 yes virbr3-nic
vnet0
In meinem Fall sollte die virtuelle Maschine über einen Gateway-Rechner des realen Netzwerks (z.B. 192.168.90.0/24) ins Internet dürfen. Auf dem KVM-Host selbst hatte ich entsprechende Routes angelegt und das IP-Forwarding aktiviert. In Firewall-Regeln auf dem KVM-Host wie dem Gateway wurde der Paket-Transport zwischen den Netzwerken zunächst vollständig zugelassen.
Eine interessante Frage ist nun: Reicht das erstmal? Oder aber: Ist das virtuelle Netzwerk wirklich “isoliert”?
Meine Erwartung aus früheren Installationen war: Nein – sobald das Forwarding auf dem KVM-Host aktiviert ist, erreicht das Gastsystem den Gateway und auch das Internet.
Auf einem KVM-Host nutze ich normalerweise ein IPtables-Paketfilter-Setup (Skript) mit selbst definierten Regeln. Diese Regeln werden über eine systemd-Unit nach dem Starten von libvirtd über ein Skript geladen. Dabei werden alle evtl. bereits existierenden Regeln verworfen und ersetzt.
Ein Test ergab: Mit meinen eigenen selektiven “Iptables”-Regeln funktionierte das Forwarding auf dem KVM-Host anstandslos. Erlaubte Web-Server im Internet konnten vom KVM-Gast problemfrei angesprochen
werden.
Meine KVM-Maschine soll später allerdings auf einem Host zum Einsatz kommen, auf dem eine Susefirewall2 läuft. Deswegen deaktivierte ich in einem weiteren Test mal mein eigenes Firewall-Skript und griff auf die “Susefirewall2” zurück. Die hatte ich über Einträge in der Datei “/etc/sysconfig/SuSEfirewall2” so konfiguriert, dass ein Fowarding/Routing zwischen den betroffenen Netzen erlaubt wurde; relevant hierfür ist die Zeile:
FW_FORWARD="192.168.90.0/24,192.168.10.0/24 192.168.10.0/24,192.168.90.0/24"
Nach einem Neustart des Hosts rieb ich mir dann aber zunächst die Augen:
Pings der virtuellen Maschine in Richtung Gateway und umgekehrt erreichten nicht ihr Ziel.
Das trieb mich gestern zunächst in die Verzweiflung. Nach einem Abschalten von IPtables und nach einem testweisen Laden eigener Regeln lief nämlich alles wieder wie erwartet. Ein nachfolgender Start der Susefirewall2 blockierte dagegen erneut die Verbindung des KVM-Gastes zum Gateway. Das virtuelle Netzwerk wurde durch die Susefirewall2 faktisch isoliert.
Ein detailiertes Verfolgen der Pakete mit Wireshark zeigte dann, dass das Forwarding auf dem Host nicht funktionierte, sondern zu Reject-Meldungen der Art “icmp-port-unreachable” führte. Ein erster Blick in die generierten Firewall-Regeln brachte gestern Abend zunächst keine sinnvollen Erkenntnisse, da zu komplex.
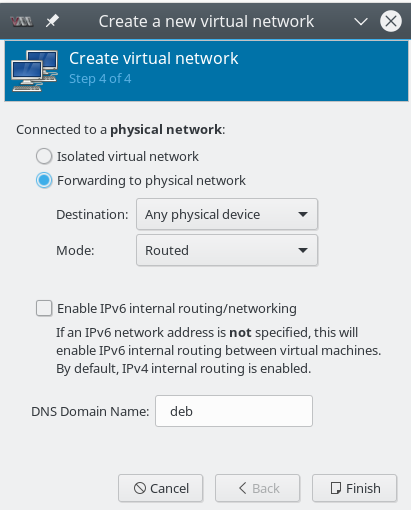
In meiner Not versuchte ich das virtuelle Netzwerk mit “virt-manager” neu anzulegen. Dabei erreicht man zwischenzeitlich die Seite 4 des Setup-Dialogs:

Wegen meines Problems entschied ich mich diesmal testweise für ein nicht-isoliertes Netzwerk – sondern für ein “Routed network”:
Danach: Neustart von libvirtd mittels “systemctl restart libvirtd” und Neustarten der Susefirewall2 über YaST:
Und, oh Wunder: Danach lief die Verbindung meines KVM-Hostes ins Internet!
Die Botschaft dieses Experiments war also, dass die Susefirewall2 Einstellungen des Isolationslevels für virtuelle Netzes, die mit virt-manager/libvirt definiert wurden, aufgreift!
Heute früh wurde mir beim Aufwachen dann klar, was ich gestern beim Testen übersehen (besser:vergessen) hatte: Das Gespann “virt-manager/libvirt” generiert im Zuge der Generierung virtueller Netzwerke selbst IPtables-Regeln zur Umsetzung der verschiedenen Isolationsniveaus:
Legt man ein (virtuelles) “Isolated network” an, stoppt man danach die Susefirewall und startet man anschließend “libvirtd” neu, so zeigt das Kommando “iptables -S” folgenden Output:
mytux:/etc/sysconfig # iptables -S
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
.....
-A INPUT -i virbr3 -p udp
-m udp --dport 53 -j ACCEPT
-A INPUT -i virbr3 -p tcp -m tcp --dport 53 -j ACCEPT
-A INPUT -i virbr3 -p udp -m udp --dport 67 -j ACCEPT
-A INPUT -i virbr3 -p tcp -m tcp --dport 67 -j ACCEPT
...
-A FORWARD -i virbr3 -o virbr3 -j ACCEPT
-A FORWARD -o virbr3 -j REJECT --reject-with icmp-port-unreachable
-A FORWARD -i virbr3 -j REJECT --reject-with icmp-port-unreachable
..
-A OUTPUT -o virbr3 -p udp -m udp --dport 68 -j ACCEPT
Hier geht also nichts – außer innerhalb des virtuellen Netzwerks, das über die Bridge “virbr3” verköpert wird.
Definiert man dagegen ein “Routed network”, so ergibt sich ein anderer, freundlicherer Regelsatz:
mytux:/etc/sysconfig # iptables -S
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
-A INPUT -i virbr3 -p udp -m udp --dport 53 -j ACCEPT
-A INPUT -i virbr3 -p tcp -m tcp --dport 53 -j ACCEPT
-A INPUT -i virbr3 -p udp -m udp --dport 67 -j ACCEPT
-A INPUT -i virbr3 -p tcp -m tcp --dport 67 -j ACCEPT
...
-A FORWARD -d 192.168.10.0/24 -o virbr3 -j ACCEPT
-A FORWARD -s 192.168.10.0/24 -i virbr3 -j ACCEPT
-A FORWARD -i virbr3 -o virbr3 -j ACCEPT
-A FORWARD -o virbr3 -j REJECT --reject-with icmp-port-unreachable
-A FORWARD -i virbr3 -j REJECT --reject-with icmp-port-unreachable
...
-A OUTPUT -o virbr3 -p udp -m udp --dport 68 -j ACCEPT
Ein nachfolgender Start der Susefirewall2 respektiert nun diese Regeln (trotz Änderung der Default-Policy). Ich zeige nachfolgend nur einige relevante Zeilen für den Fall des “Routed network”, in dem die Kommunikation erlaubt wird:
rux:/etc/sysconfig # iptables -S
-P INPUT DROP
-P FORWARD DROP
-P OUTPUT ACCEPT
-N forward_ext
-N forward_int
-N input_ext
-N input_int
-N reject_func
-A INPUT -i virbr3 -p udp -m udp --dport 53 -j ACCEPT
-A INPUT -i virbr3 -p tcp -m tcp --dport 53 -j ACCEPT
-A INPUT -i virbr3 -p udp -m udp --dport 67 -j ACCEPT
-A INPUT -i virbr3 -p tcp -m tcp --dport 67 -j ACCEPT
...
-A INPUT -i lo -j ACCEPT
-A INPUT -m conntrack --ctstate ESTABLISHED -j ACCEPT
-A INPUT -p icmp -m conntrack --ctstate RELATED -j ACCEPT
...
-A INPUT -j input_ext
-A INPUT -m limit --limit 3/min -j LOG --log-prefix "SFW2-IN-ILL-TARGET " --log-tcp-options --log-ip-options
-A INPUT -j DROP
-A FORWARD -d 192.168.10.0/24 -o virbr3 -j ACCEPT
-A FORWARD -s 192.168.10.0/24 -i virbr3 -j ACCEPT
-A FORWARD -i virbr3 -o virbr3 -j ACCEPT
-A FORWARD -o virbr3 -j REJECT --reject-with icmp-port-unreachable
-A FORWARD -i virbr3 -j REJECT --reject-with icmp-port-unreachable
...
-A FORWARD -p tcp -m tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
-A FORWARD -m physdev --physdev-is-bridged -j ACCEPT
...
-A FORWARD -i virbr3 -j forward_ext
-A FORWARD -i virbr3_nic -j forward_ext
...
-A FORWARD -m limit --limit 3/min -j LOG --log-prefix "SFW2-FWD-ILL-ROUTING " --log-tcp-options --log-ip-options
-A FORWARD -j DROP
-A OUTPUT -o virbr3 -p udp -m udp --dport 68 -j ACCEPT
...
-A OUTPUT -o lo -j ACCEPT
-A forward_ext -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 0 -j ACCEPT
-A forward_ext -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 3 -j ACCEPT
-A forward_ext -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 11 -j ACCEPT
-A forward_ext -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 12 -j ACCEPT
-A forward_ext -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 14 -j ACCEPT
-A forward_ext -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 18 -j ACCEPT
-A forward_ext -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 3/2 -j ACCEPT
-A forward_ext -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 5 -j ACCEPT
-A forward_
ext -s 192.168.90.0/24 -d 192.168.10.0/24 -m limit --limit 3/min -m conntrack --ctstate NEW -j LOG --log-prefix "SFW2-FWDext-ACC-FORW " --log-tcp-options --log-ip-options
-A forward_ext -s 192.168.90.0/24 -d 192.168.10.0/24 -m conntrack --ctstate NEW,RELATED,ESTABLISHED -j ACCEPT
-A forward_ext -s 192.168.10.0/24 -d 192.168.90.0/24 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A forward_ext -s 192.168.10.0/24 -d 192.168.90.0/24 -m limit --limit 3/min -m conntrack --ctstate NEW -j LOG --log-prefix "SFW2-FWDext-ACC-FORW " --log-tcp-options --log-ip-options
-A forward_ext -s 192.168.10.0/24 -d 192.168.90.0/24 -m conntrack --ctstate NEW,RELATED,ESTABLISHED -j ACCEPT
-A forward_ext -s 192.168.90.0/24 -d 192.168.10.0/24 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A forward_ext -m comment --comment "sfw2.insert.pos" -m pkttype ! --pkt-type unicast -j DROP
-A forward_ext -p tcp -m limit --limit 3/min -m tcp --tcp-flags FIN,SYN,RST,ACK SYN -j LOG --log-prefix "SFW2-FWDext-DROP-DEFLT " --log-tcp-options --log-ip-options
-A forward_ext -p icmp -m limit --limit 3/min -j LOG --log-prefix "SFW2-FWDext-DROP-DEFLT " --log-tcp-options --log-ip-options
-A forward_ext -p udp -m limit --limit 3/min -m conntrack --ctstate NEW -j LOG --log-prefix "SFW2-FWDext-DROP-DEFLT " --log-tcp-options --log-ip-options
-A forward_ext -j DROP
-A forward_int -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 0 -j ACCEPT
-A forward_int -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 3 -j ACCEPT
-A forward_int -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 11 -j ACCEPT
-A forward_int -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 12 -j ACCEPT
-A forward_int -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 14 -j ACCEPT
-A forward_int -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 18 -j ACCEPT
-A forward_int -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 3/2 -j ACCEPT
-A forward_int -p icmp -m conntrack --ctstate RELATED,ESTABLISHED -m icmp --icmp-type 5 -j ACCEPT
-A forward_int -s 192.168.0.0/24 -d 192.168.10.0/24 -m limit --limit 3/min -m conntrack --ctstate NEW -j LOG --log-prefix "SFW2-FWDint-ACC-FORW " --log-tcp-options --log-ip-options
-A forward_int -s 192.168.90.0/24 -d 192.168.10.0/24 -m conntrack --ctstate NEW,RELATED,ESTABLISHED -j ACCEPT
-A forward_int -s 192.168.10.0/24 -d 192.168.90.0/24 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A forward_int -s 192.168.10.0/24 -d 192.168.90.0/24 -m limit --limit 3/min -m conntrack --ctstate NEW -j LOG --log-prefix "SFW2-FWDint-ACC-FORW " --log-tcp-options --log-ip-options
-A forward_int -s 192.168.10.0/24 -d 192.168.90.0/24 -m conntrack --ctstate NEW,RELATED,ESTABLISHED -j ACCEPT
-A forward_int -s 192.168.90.0/24 -d 192.168.10.0/24 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A forward_int -m comment --comment "sfw2.insert.pos" -m pkttype ! --pkt-type unicast -j DROP
-A forward_int -p tcp -m limit --limit 3/min -m tcp --tcp-flags FIN,SYN,RST,ACK SYN -j LOG --log-prefix "SFW2-FWDint-DROP-DEFLT " --log-tcp-options --log-ip-options
-A forward_int -p icmp -m limit --limit 3/min -j LOG --log-prefix "SFW2-FWDint-DROP-DEFLT " --log-tcp-options --log-ip-options
-A forward_int -p udp -m limit --limit 3/min -m conntrack --ctstate NEW -j LOG --log-prefix "SFW2-FWDint-DROP-DEFLT " --log-tcp-options --log-ip-options
-A forward_int -j reject_func
-A input_ext -p udp -m pkttype --pkt-type broadcast -m udp --dport 5353 -j ACCEPT
..
-A input_ext -m pkttype --pkt-type broadcast -j DROP
...
-A input_ext -s 192.168.10.0/24 -m limit --limit 3/min -m conntrack --ctstate NEW -j LOG --log-prefix "SFW2-INext-ACC-TRUST " --log-tcp-options --log-ip-options
-A input_ext -s 192.168.10.0/24 -m conntrack --ctstate NEW,RELATED,ESTABLISHED -j ACCEPT
...
-A input_ext -j DROP
-A input_int -j ACCEPT
-A reject_
func -p tcp -j REJECT --reject-with tcp-reset
-A reject_func -p udp -j REJECT --reject-with icmp-port-unreachable
-A reject_func -j REJECT --reject-with icmp-proto-unreachable
Damit lässt sich mein Befund von gestern Abend ganz einfach erklären:
Mein eigener Regelsatz löschte zunächst alle vordefinierten Regeln von “libvirt” und erlaubte das Forwarding über den Gateway in jedem Fall. Im Falle eines Starts der Susefirewall2 und eines “Isolated network” respektiert die Susefirewall2 die blockierenden Regeln, die über “virt-manager/libvirt” für das virtuelle Netzwerk vorgegeben wurden. Dito im positiven Fall des “Routed network”.
Merke:
Die “Susefirewall2” setzt die IPtables-Regeln von “virt-manager/libvirtd” für virtuelle Netzwerke nicht außer Kraft!
So simpel; man muss sich halt nur daran erinnern. Nachdem nun das Grundsätzliche geklärt ist, kann ich endlich spezifischere, engmaschigere IPtables-Regeln mit der Susefirewall2 für den eigentlichen Zielhost meiner virtuellen Maschine festlegen. In meinem eigenen Netz nutze ich dagegen lieber weiterhin meine eigenen Firewall-Skripte … und vergesse hoffentlich nicht mehr, welche grundsätzlichen Unterschiede das im Vergleich zur Susefirewall2 nach sich zieht und warum.