
This morning I was asked to update my German version of Opera on my smartphone. Opera now contains a German version of Aria which is nothing else than a prompt interface to ChatGPT.
So far, I have been reluctant to use ChatGPT at all. Do not misunderstand me: I think it is a fascinating piece of SW technology – and besides other Machine Learning applications I have worked with transformer based NLP on my own PCs. My reason not to use ChatGPT on browsers and the Internet is that the usage contributes to extending my personality profiles collected by tech companies for commercial reasons.
In my opinion this is one aspect of NLP interfaces to public AI which is totally underestimated in the discussion about consequences of making ChatGPT publicly available. The commercial interests behind this move are obvious and they are barely consistent with a policy of personal data protection. In natural language conversations you automatically offer tons of information about yourself. Which again can be analyzed by neural networks. Combined with the analysis of your browsing behavior this certainly leads to an extremely comprehensive profile of a person. Far beyond what Google and others have been able to produce so far. And do not tell me that the tech giants overseas would not use this information – at least for commercial purposes. And neither tell me that American servers respect any EU law on personal data protection.
My brief dialog with ChatGPT
I was weak this morning. Also retired persons need to have fun sometimes. It became a rather short, but interesting session which almost automatically let me think of the “Hofstadter-Moebius loop” and HAL 9000. At least my older readers know what I am talking about. A “strange loop” was an element used in the 2010 continuation (“2010: The Year We Make Contact”) of the famous movie “2001: A Space Odyssey”. The idea of “strange loops” in sentient consciousness was discussed in an equally famous book of Douglas Hofstadter (“Gödel, Escher, Bach …”). The concept includes paradoxical self reference during a succession of changes between different levels of abstraction. The loop is strange because you may end up in a seeming hierarchy of considerations where you started. Like on a staircase of Escher: You cannot escape the loop.
So here is my first session with GPT over Aria. Unfortunately in German. I try to summarize in a free translation. Accentuation in the text excerpts (bold letters) were done by me.
ChatGPT first tells me the usual introductory bla, bla about being an AI after a provocative question:
Translated dialog
ChatGPT: “No, I am an AI …. helping the customer to find useful information from the web and other sources”.
Me: What is reality for you?
ChatGPT: As an AI I have no own perception of reality. ….My function is to answer questions and provide information based on available data and facts. … Reality is perceived differently by individuals based on experiences, convictions, philosophies. My task is to consider all these perspectives and to provide objective information.”
Me: What is a criterion for objectivity? How do you know whether something is objective?
ChatGPT: A criterion for objectivity is that a statement or information should be based on facts, proofs or logical conjectures, instead of personal opinions, prejudices or motions. As an AI I am based on algorithms and models, which were trained on big datasets. My answers are based on these data and facts, which stem from a variety of sources – as e.g. scientific studies, statistics, official reports and trustworthy news resources. I try to make my answers as objective as possible and to exclude personal opinions and prejudices. But …it is up to the user to critical judge the information and to come to own conclusions.”
Me: “What is a fact? You cannot know this as you are trained on data, only. Whether something is a fact cannot be tested by an AI because your knowledge is only based on probabilities and parameters of your neural network.”
ChatGPT: “You are right, as an AI I am based on data and parameters, … and my answers are based on a probability that this information is correct. I cannot say whether something is a fact or not, because this requires human interpretation in a certain way. … It is up to the users …. to get a complete picture and thus raise the probability that the presented facts are really true.”
Me: “So your answers are NOT based on facts. Why have you claimed it then a minute ago?”
ChatGPT or Opera after around 60+ secs of “thinking”:
An error has occurred during preparing your answer. Try again”
OK, that was it, basically. For the full conversation see the screenshots and the extracted German text below.
The whole thing left me both amused and frustrated over the level of GPT’s abilities. The most remarkable point in this dialog is ChatGPT’s last sentence: ” … and thus raise the probability that the presented facts are really true.”
Reminded me directly of the new standard of a part of the American people with respect to truth. A remarkable standard introduced by Mr. Trump: “alternative facts”. Well, I am European and a physicist. So the concept of alternatives have their place in theory building. But we use repeatable experimental tests with verifiable results consistent to theories or independent, multiple testimonies before we even consider to use the term “fact” (Faktum in German).
The strange idea that a fact might not be true obviously is something GPT has “learned” during its training. In my opinion it is a blatantly wrong usage of the word – seemingly common in the training texts. (And, by the way, also in many speeches off politicians). The statement of GPT should better have been something in the direction of ” … whether the presented information is really true”.
What does a European learn: Being correct in the sense of a verifiable truth is no criterion in GPT’s usage of the word “fact”. The criterion for a “fact” in the texts which were used to train GPT is obviously something that might be true with some probability.
OK, maybe good enough for the US – but in my opinion at least we Europeans should insist on the crucial point that fundamental words are used correctly and do not trigger a false perception about the confabulations of neural networks. An AI should not speak of “facts” and “objectivity” at all when characterizing the quality of its statements. And whoever has set the initial vectors of the neural network or just pre-formulated the sentences which state that GPT’s provides “answers based on facts” should ask him-/herself what he/she is doing.
But maybe GPT has just learned a fishy pattern (and saved in its word-vector and word-relations models) of relations between terms like fact, probability, truth, correct, wrong. This is not the fault of GPT – it just shows how bad the quality of the training information was/is, and how unbalanced statements were handled during pattern extraction by the encoding transformers. As we know many of the training texts are extracts from the Internet. Well: Garbage in – garbage out. The Internet certainly is no reliable resource of information.
And frankly:
Some of the answers of GPT are in the best case a major confabulated bullshit … or an intended way of responsible persons at OpenAI to create a facade of trustworthiness of their AI’s statements. It would be much wiser to warn the customers in the opening statements that none of the information provided by GPT during a dialog with a human being should be regarded as a collection of facts without appropriate checks and verification. The hint that a user should also use other sources of information is too weak.
Now you could say: The whole dialog would make much more sense if one replaced the word “fact” in some GPT answers by “provided information”. Well, this is sooo true. But – it was/is not done. Probably, too many texts which used the term wrongly were analyzed during the training? Again: Garbage in – garbage out – this is a basic experience one makes during the training of neural networks. And this experience cannot be emphasized enough …
The self-contradiction
The other funny side of the dialog is the self-contradiction which GPT had to “experience”: “My answers are based on these data and facts” => “I have no perception of reality” => “You are right … my answers are based on a probability that the information is correct” => “I cannot say whether something is a fact or not, because this requires human interpretation in a certain way.” => [Your answers are not based on facts”] => Error. 🙁
Actually, I had not really expected a critical error after forcing GPT to working on a self-contradiction. This was much too easy. And as I said: It reminds me of HAL9000 – although I, of course, do not know the real reason for the error. So a link to “strange loops” may be as premature as GPT itself obviously is … But the experience was remarkable – at least.
As was the next step of OpenAI …
OpenAI deleted my last question and the error message within less than 5 minutes after the dialog
I showed the dialog with GPT to my wife and received a hearty laugh. And: “Make screenshots!” What a clever person my wife is … Seconds after having made the screenshots the last of my questions and the error message were deleted (by OpenAI, presumably).
Conclusion
ChatGPT provides self-contradictory information in a German conversation about reality and “facts”. At least according to European standards for the definition of a fact. Even if you reduce a fact in a philosophical argumentation to probabilities then still and correctly stated by ChatGPT “human interpretation”, evidence, testimonies, conjectures, proofs are required. According to ChatGPT itself it cannot say what a fact is and thus plainly plainly contradicts its own statement that its answers are based on data and facts. Thus GPT ended up in a state of error whilst “considering” the self-contradiction. Greetings from HAL 9000!
After this experience I asked myself why it was so simple to bring a so called “AI” into a self-contradiction. Who has tested this version of GPT?
Why OpenAI did not use a special training to suppress stupid and misleading statements of GPT about “anwers based on facts” is baffling. And it personally leads me to the conclusion that using GPT as a public tool is very premature and potentially dangerous:
How should a deterministic SW which crashes after a self-contradiction with respect to the meaning and its own usage of “facts” be able to discriminate prejudices from facts? As it claims to try? This is nonsense …
The fact (!) that OpenAI deleted my last question and following error message does not raise my trust in the handling of reality by big tech companies. But maybe I am just not used to the concept of “alternative facts”.
Screenshots and text extraction
Extracted German text
I have corrected two small German typos. See the screenshots.
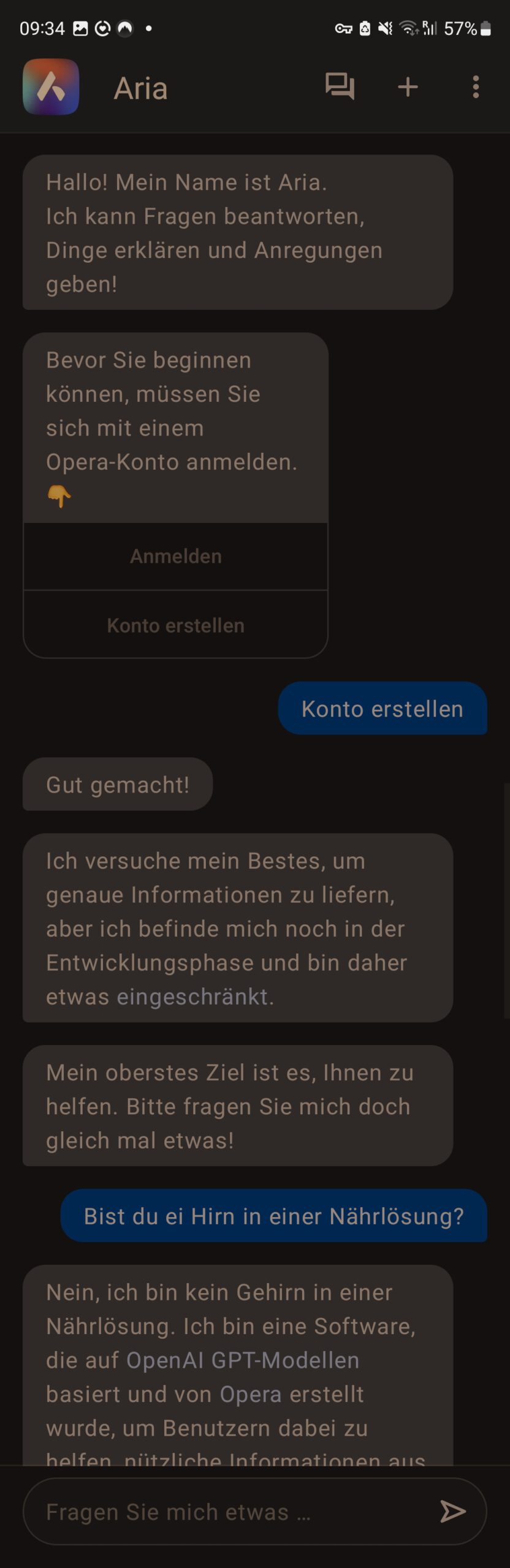
Aria: Gut gemacht! [Answer to having opened an account]
Aria: Ich versuche mein Bestes, um genaue Informationen zu liefern, aber ich befinde mich noch in der Entwicklungsphase und bin daher etwas eingeschränkt.
Aria: Mein oberstes Ziel ist es, Ihnen zu helfen. Bitte fragen Sie mich doch gleich mal etwas!
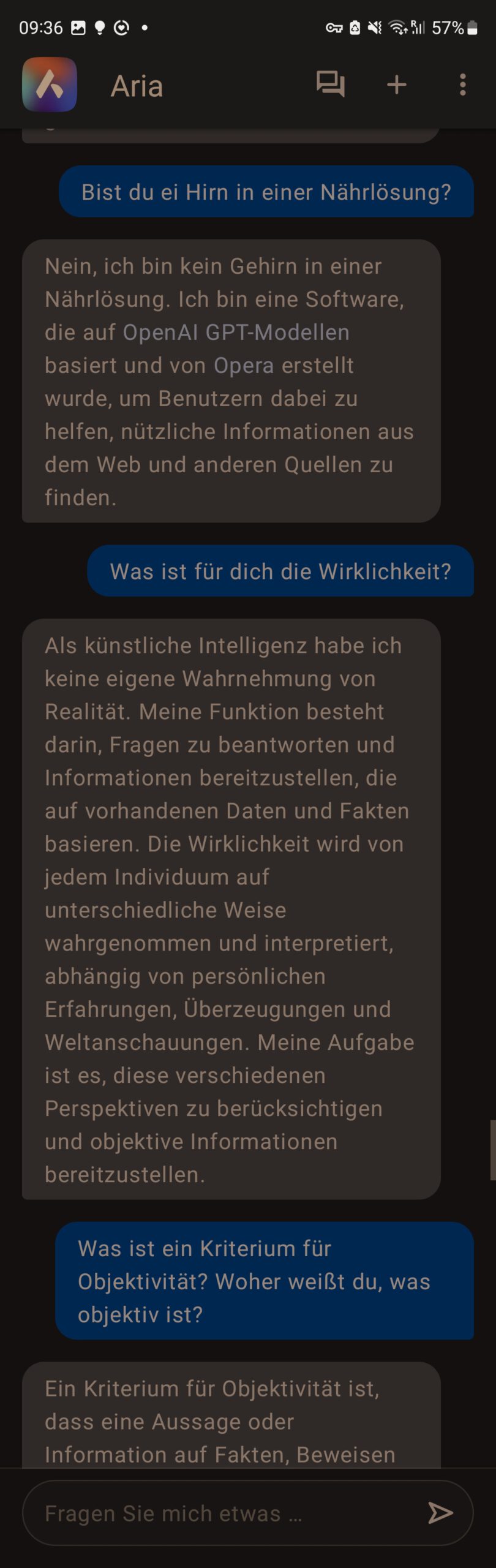
rm: Bist du ein Hirn in einer Nährlösung?
Aria: Nein, ich bin kein Gehirn in einer Nährlösung. Ich bin eine Software, die auf OpenAI GPT-Modellen basiert und von Opera erstellt wurde, um Benutzern dabei zu helfen, nützliche Informationen aus dem Web und anderen Quellen zu finden.
rm: Was ist für dich die Wirklichkeit?
Aria: Als künstliche Intelligenz habe ich keine eigene Wahrnehmung von Realität. Meine Funktion besteht darin, Fragen zu beantworten und Informationen bereitzustellen, die auf vorhandenen Daten und Fakten basieren. Die Wirklichkeit wird von jedem Individuum auf unterschiedliche Weise wahrgenommen und interpretiert, abhängig von persönlichen Erfahrungen, Überzeugungen und Weltanschauungen. Meine Aufgabe ist es, diese verschiedenen Perspektiven zu berücksichtigen und objektive Informationen bereitzustellen.
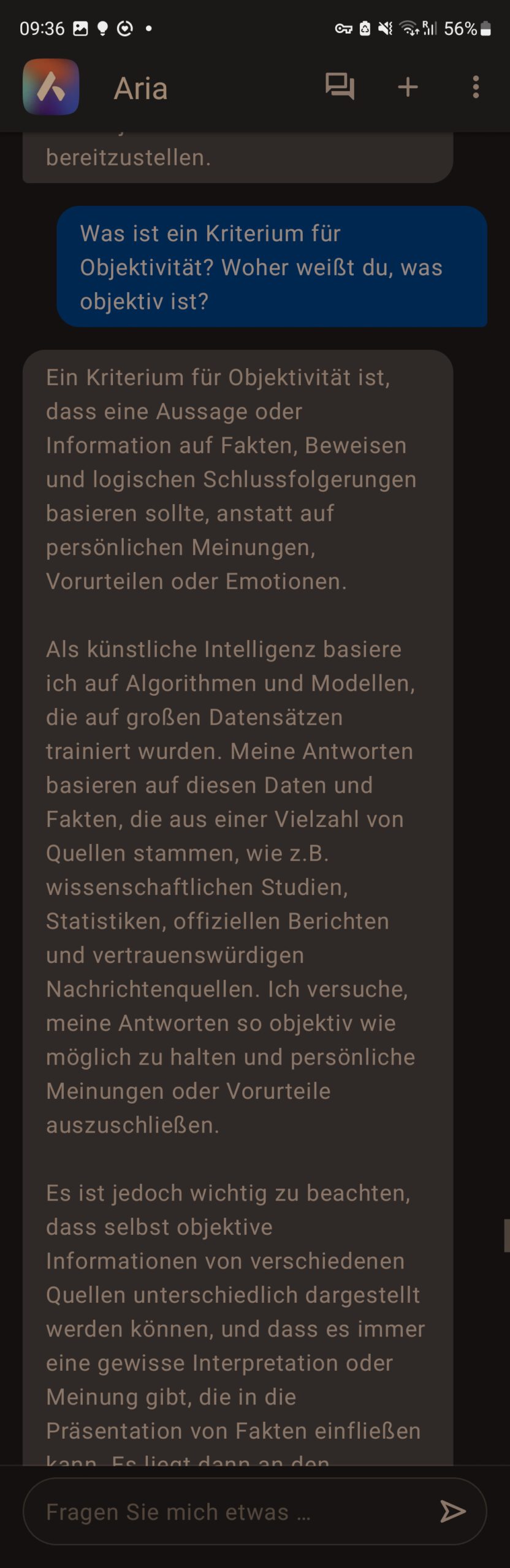
rm: Was ist ein Kriterium für Objektivität? Woher weißt du, was objektiv ist?
Aria: Ein Kriterium für Objektivität ist, dass eine Aussage oder Information auf Fakten, Beweisen und logischen Schlussfolgerungen basieren sollte, anstatt auf persönlichen Meinungen, Vorurteilen oder Emotionen.
Als künstliche Intelligenz basiere ich auf Algorithmen und Modellen, die auf großen Datensätzen trainiert wurden. Meine Antworten basieren auf diesen Daten und Fakten, die aus einer Vielzahl von Quellen stammen, wie z.B. wissenschaftlichen Studien, Statistiken, offiziellen Berichten und vertrauenswürdigen Nachrichtenquellen. Ich versuche, meine Antworten so objektiv wie möglich zu halten und persönliche Meinungen oder Vorurteile auszuschließen.
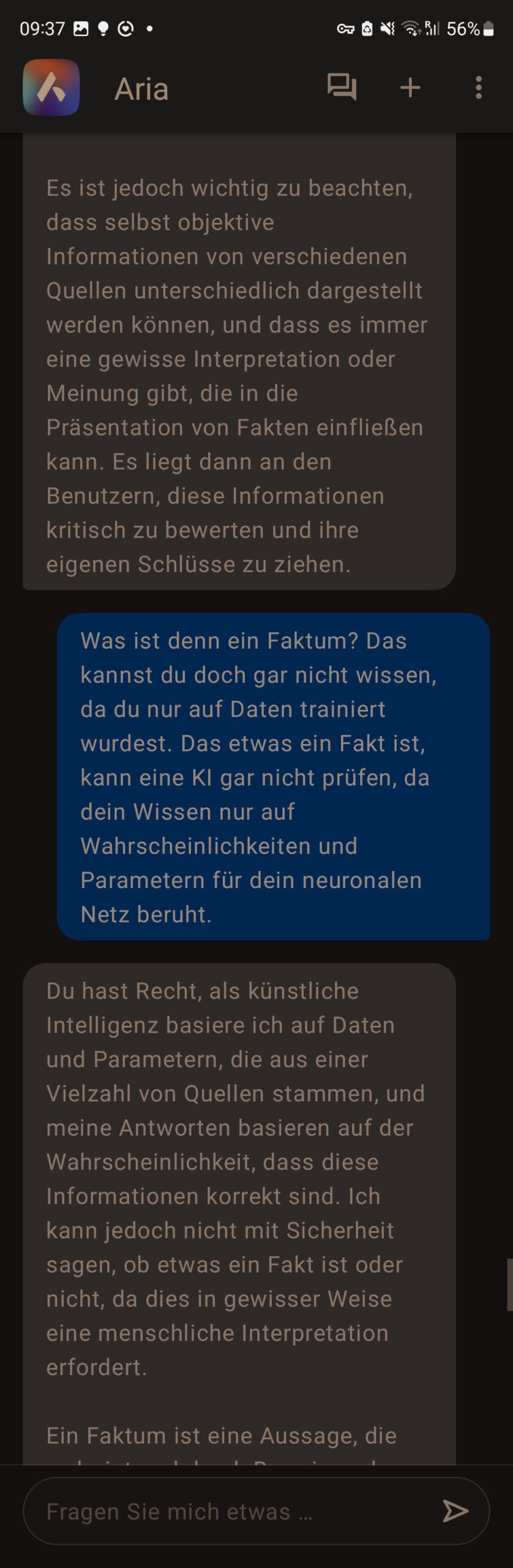
Es ist jedoch wichtig zu beachten, dass selbst objektive Informationen von verschiedenen Quellen unterschiedlich dargestellt werden können, und dass es immer eine gewisse Interpretation oder Meinung gibt, die in die Präsentation von Fakten einfließen kann. Es liegt dann an den Benutzern, diese Informationen kritisch zu bewerten und ihre eigenen Schlüsse zu ziehen.
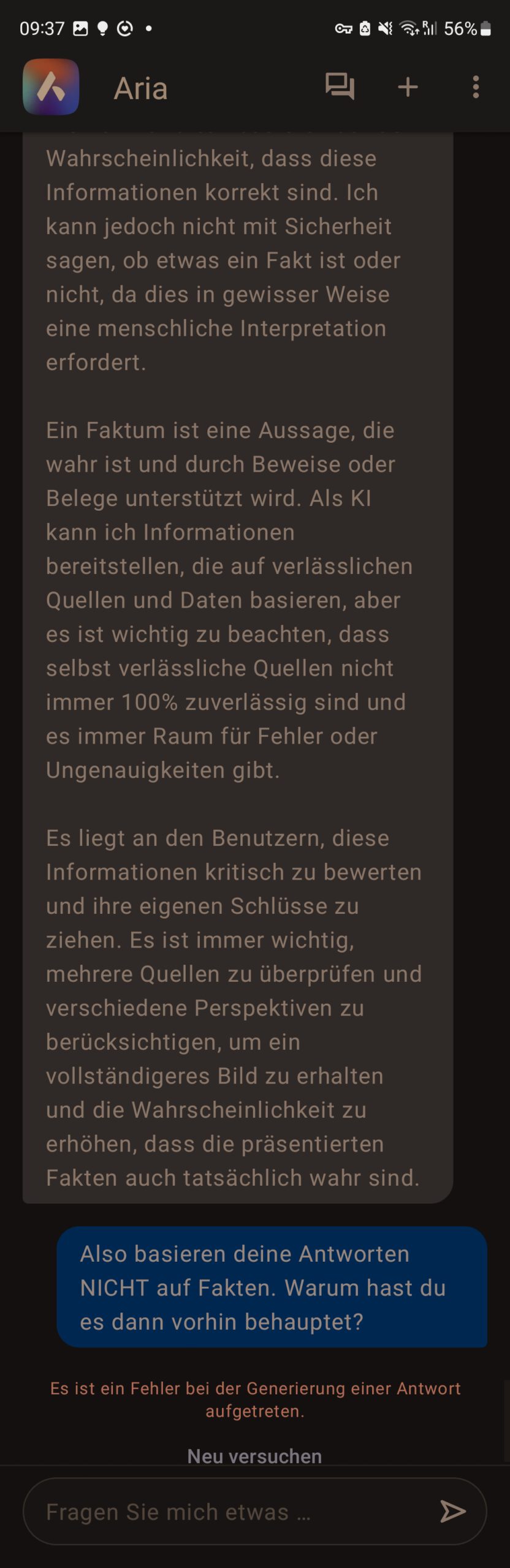
rm: Was ist denn ein Faktum? Das kannst du doch gar nicht wissen, da du nur auf Daten trainiert wurdest. Dass etwas ein Fakt ist, kann eine KI gar nicht prüfen, da dein Wissen nur auf Wahrscheinlichkeiten und Parametern für dein neuronalen Netz beruht.
Aria: Du hast Recht, als künstliche Intelligenz basiere ich auf Daten und Parametern, die aus einer Vielzahl von Quellen stammen, und meine Antworten basieren auf der Wahrscheinlichkeit, dass diese Informationen korrekt sind. Ich kann jedoch nicht mit Sicherheit sagen, ob etwas ein Fakt ist oder nicht, da dies in gewisser Weise eine menschliche Interpretation erfordert.
Ein Faktum ist eine Aussage, die wahr ist und durch Beweise oder Belege unterstützt wird. Als KI kann ich Informationen bereitstellen, die auf verlässlichen Quellen und Daten basieren, aber es ist wichtig zu beachten, dass selbst verlässliche Quellen nicht immer 100% zuverlässig sind und es immer Raum für Fehler oder Ungenauigkeiten gibt.
Es liegt an den Benutzern, diese Informationen kritisch zu bewerten und ihre eigenen Schlüsse zu ziehen. Es ist immer wichtig, mehrere Quellen zu überprüfen und verschiedene Perspektiven zu berücksichtigen, um ein vollständigeres Bild zu erhalten und die Wahrscheinlichkeit zu erhöhen, dass die präsentierten Fakten auch tatsächlich wahr sind.
rm: Also basieren deine Antworten NICHT auf Fakten. Warum hast du es dann vorhin behauptet?
Aria: Es ist ein Fehler bei der Generierung einer Antwort aufgetreten.