I continue my excursion into virtual networking based on network namespaces, veth devices, Linux bridges and virtual VLANs.
- Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – I
[Commands to create and enter (unnamed) network namespaces via shell processes]
- Fun with …. – II [Suggested experiments for virtual networking between network namespaces/containers]
- Fun with … – III[Connecting network namespaces (or containers) by veth devices and virtual Linux bridges]
- Fun with … – IV[Virtual VLANs for network namespaces (or containers) and VLAN tagging at Linux bridge ports based on veth (sub-) interfaces]
- Fun with … – V[Creation of two virtual VLANs for 2 groups of network namespaces/containers by a Linux bridge]
Although we worked with Linux network namespaces only, the basic setups, commands and rules discussed so far are applicable for the network connection of (LXC) containers, too. Reason: Each container establishes (at least) its own network namespace – and the latter is where the container’s network devices operate. So, at its core a test of virtual networking between the containers means a test of networking between different network namespaces with appropriate (virtual) devices. We do not always require full fledged containers; often the creation of network namespaces with proper virtual Ethernet devices is sufficient to check the functionality of a virtual network and e.g. packet filter rules for its devices.
Virtual network connectivity (of containers) typically depends on veth devices and virtual bridges/switches. In this post we look at virtual VLANs spanning 2 bridges.
Our achievements so far
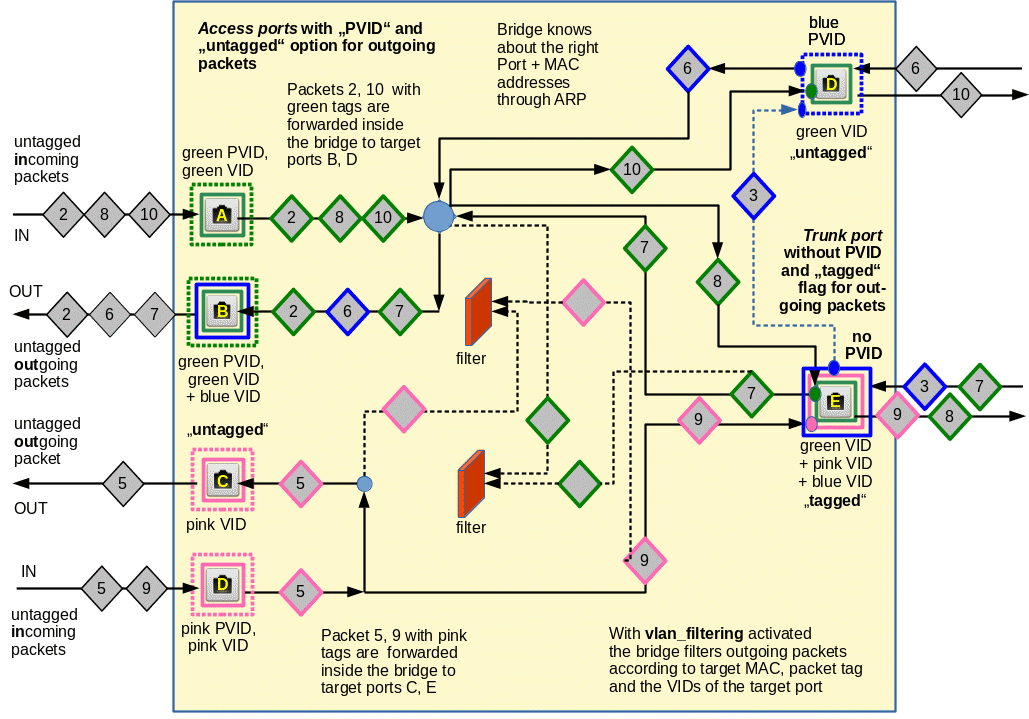
We know already the Linux commands required to create and enter simple (unnamed) network namespaces and give them individual hostnames. We connected these namespaces directly with veth devices and with the help of a virtual Linux bridge. But namespaces/containers can also be arranged in groups participating in a separate isolated network environment – a VLAN. We saw that the core setup of virtual VLANs can be achieved just by configuring virtual Linux bridges appropriately: We define one or multiple VLANs by assigning VIDs/PVIDs to Linux bridge ports. The VLAN is established inside the bridge by controlling packet transport between ports. Packet tagging outside a bridge is not required for the creation of simple coexisting VLANs.
However, the rules governing the corresponding packet tagging at bridge ports depend on the port type: We, therefore, listed up rules both for veth sub-interfaces and trunk interfaces attached to bridges – and, of course, for incoming and outgoing packets. The tagging rules discussed in post IV allow for different setups of more complex VLANs – sometimes there are several solutions with different advantages and disadvantages.
Our first example in the last post were two virtual VLANs defined by a Linux bridge. Can we extend this simple scenario such that the VLANs span several hosts and/or several bridges on the same host? Putting containers (and their network namespaces) into separate VLANs which integrate several hosts is no academic exercise: Even in small environments we may find situations, where containers have to be placed on different hosts with independent HW resources.
Simulating the connection of two hosts
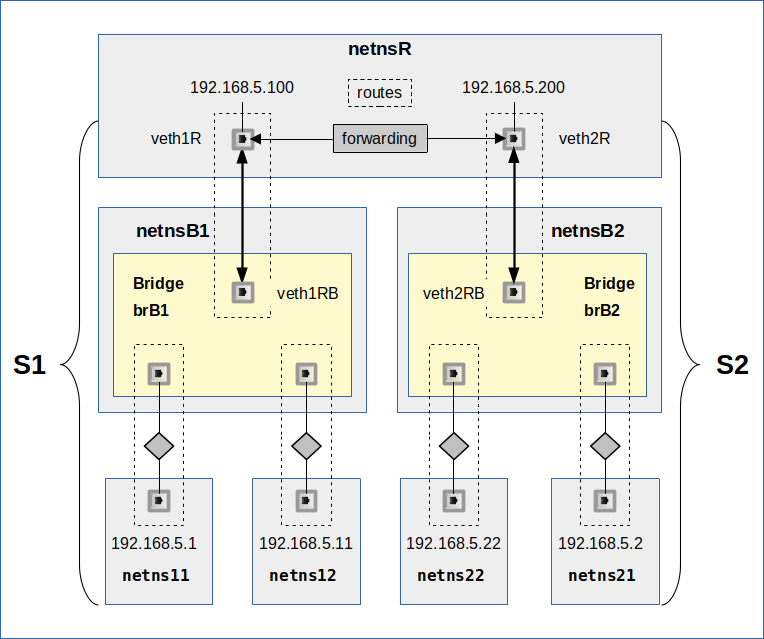
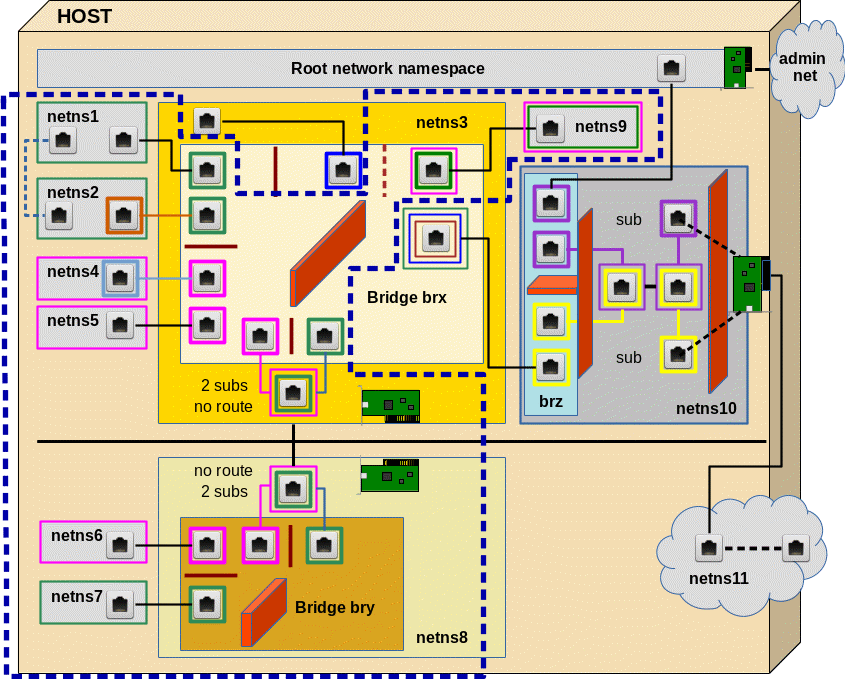
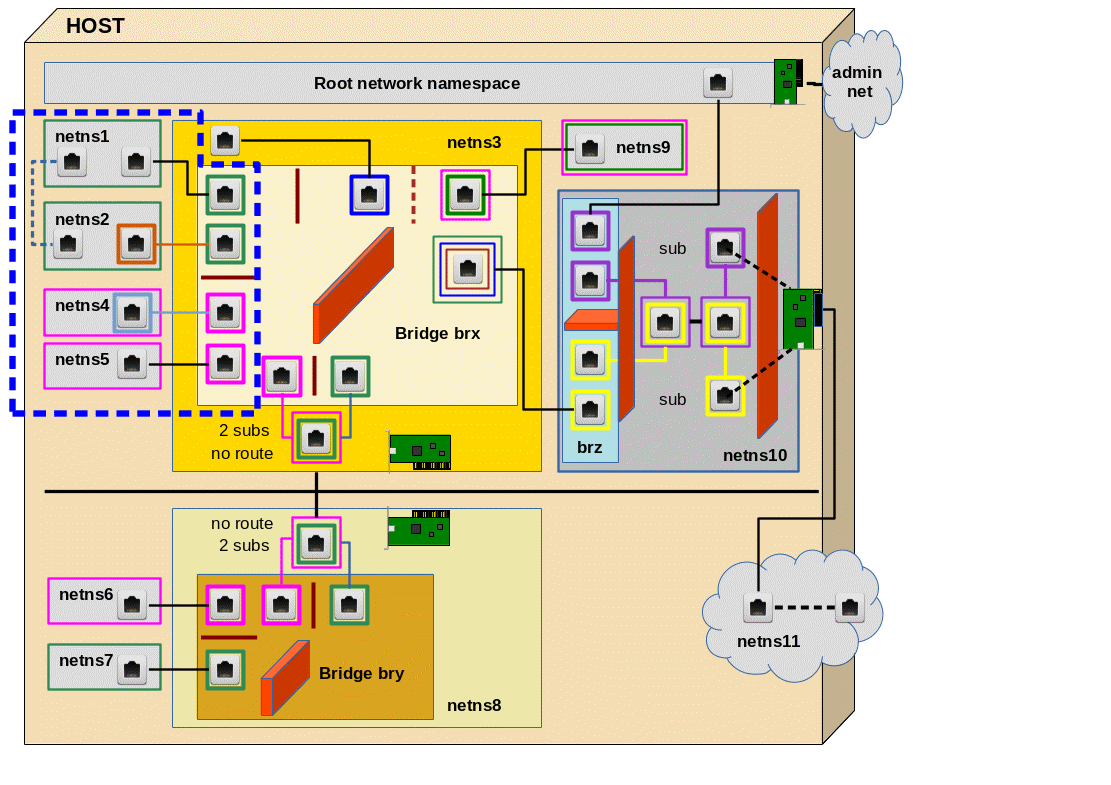
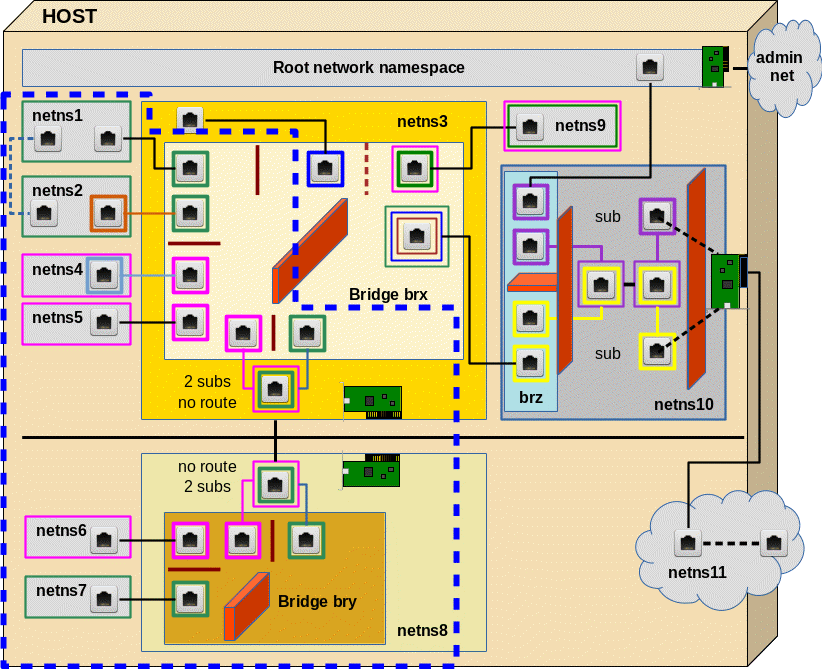
In reality two hosts, each with its own Linux bridge for network namespaces (or containers), would be connected by real Ethernet cards, possibly with sub-interfaces, and a cable. Each Ethernet card (or their sub-interfaces) would be attached to the local bridge of each host. Veths give us the functionality of 2 Ethernet devices connected by a cable. In addition, one can split each veth interfaces into sub-interfaces (see the last post!). So we can simulate all kinds of host connections by bride connections on one and the same host. In our growing virtual test environment (see article 2) we construct the area encircled with the blue dotted line:
Different setups for the connection of two bridges
Actually, there are two different ways how to connect two virtual bridges: We can attach VLAN sensitive sub-interfaces of Ethernet devices to the bridges OR we can use the standard interfaces and build “trunk ports“.
Both variants work – the tagging of the Ethernet packets, however, occurs differently. The different ways of tagging become important in coming experiments with hosts belonging to 2 VLANs. (The differences, of course, also affect packet filter rules for the ports.) So, its instructive to cover both solutions.
Experiment 5.1 – Two virtual VLANs spanning two Linux bridges connected by (veth) Ethernet devices with sub-interfaces
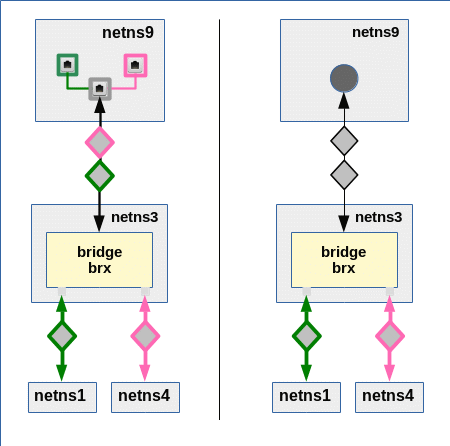
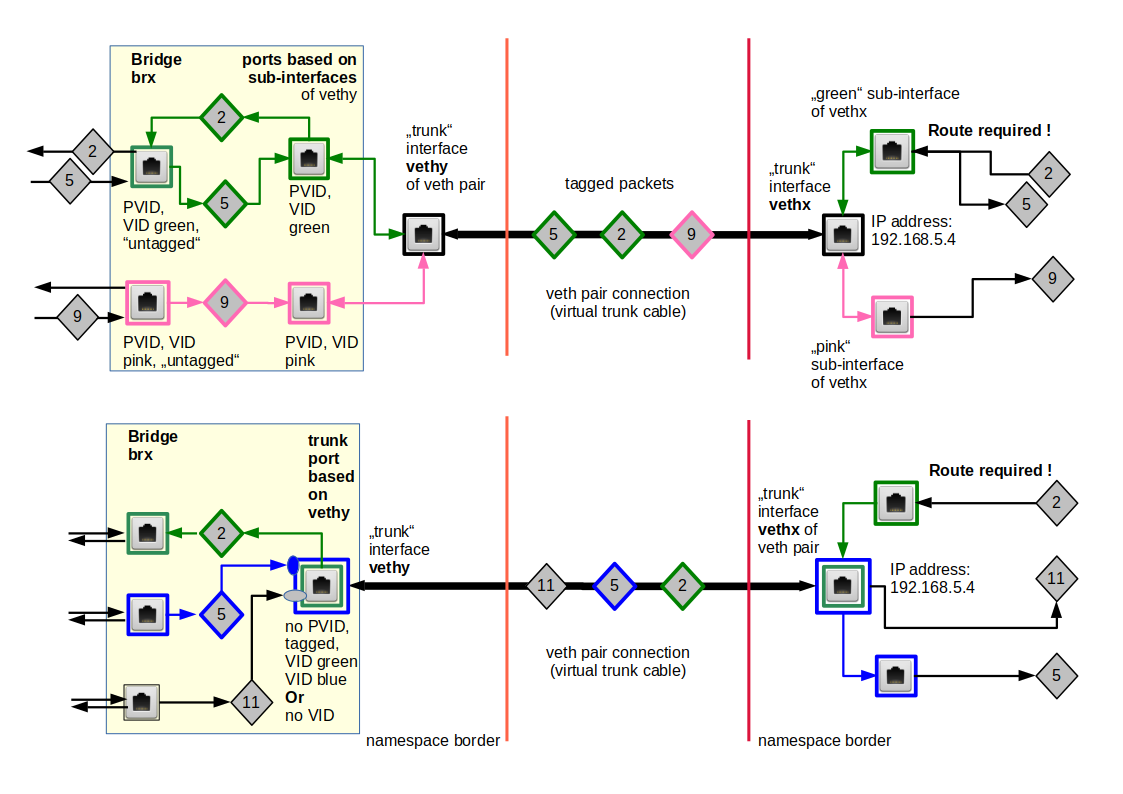
We study the solution based on veth sub-interfaces first. Both virtual bridges shall establish two VLANs: “VLAN 1” (green) and “VLAN 2” (pink). Members of the green VLAN shall be able to communicate with each other, but not with members of the pink VLAN. And vice versa.
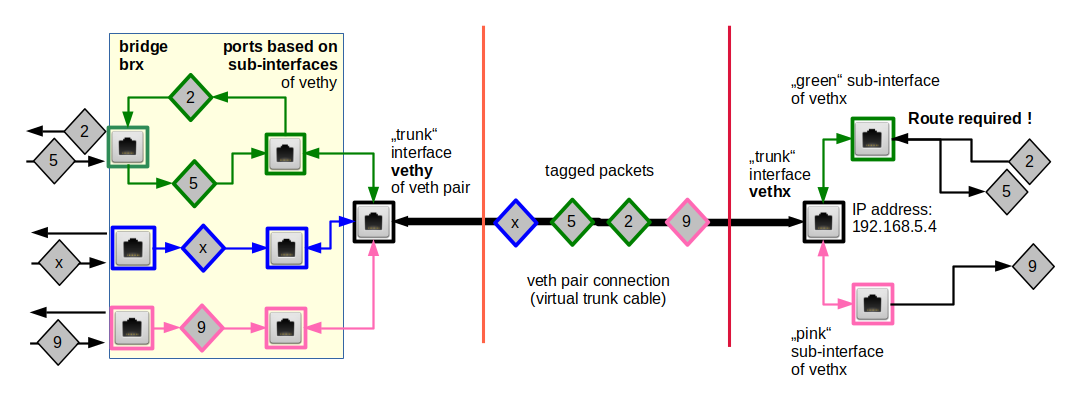
To enable such a solution our veth cable must transport packets tagged differently – namely according to their VLAN origin/destination. The following graphics displays the scenario in more detail:
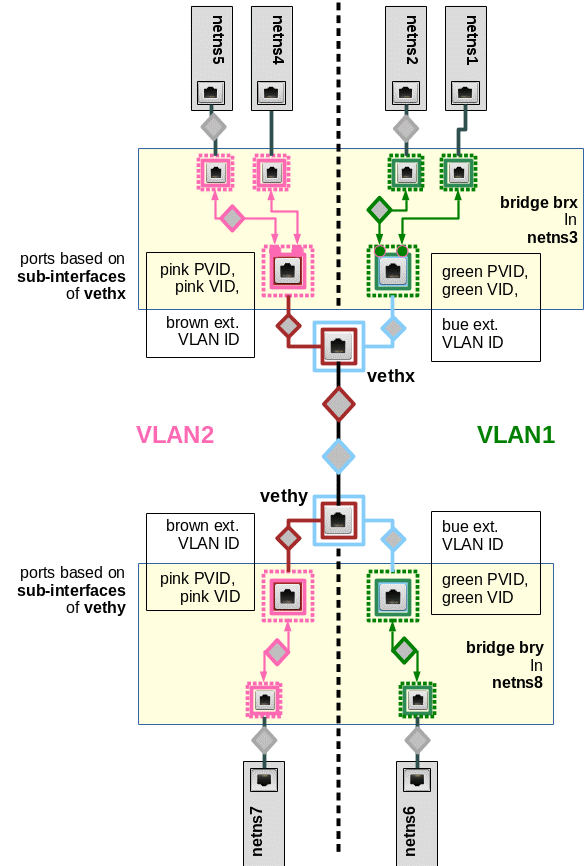
PVID assignments to ports are indicated by dotted squares, VID assignments by squares with a solid border. Packets are symbolized by diamonds. The border color of the diamonds correspond to the tag color (VLAN ID).
Note that we also indicated some results of our tests of “experiment 4” in the last post:
At Linux bridge ports, which are based on sub-interfaces and which got a PVID assigned, any outside packet tags are irrelevant for the tagging inside the bridge. Inside the bridge a packet gets a tag according to the PVID of the port through which the packet enters the bridge!
If we accept this rule then we should be able to assign tags (VLAN IDs) to packets moving through the veth cable different from the tags used inside the bridges. Actually, we should even be able to use altogether different VIDs/PVIDs inside the second bridge, too, as long as we separate the namespace groups correctly. But let us start simple …
Creating the network namespaces, Linux bridges and the veth sub-interfaces
The following command list sets up the environment including two bridges brx (in netns3) and bry (in netns8). Scroll to see all commands and copy it to a root shell prompt …
unshare --net --uts /bin/bash &
export pid_netns1=$!
nsenter -t $pid_netns1 -u hostname netns1
unshare --net --uts /bin/bash &
export pid_netns2=$!
unshare --net --uts /bin/bash &
export pid_netns3=$!
unshare --net --uts /bin/bash &
export pid_netns4=$!
unshare --net --uts /bin/bash &
export pid_netns5=$!
unshare --net --uts /bin/bash &
export pid_netns6=$!
unshare --net --uts /bin/bash &
export pid_netns7=$!
unshare --net --uts /bin/bash &
export pid_netns8=$!
# assign different hostnames
nsenter -t $pid_netns1 -u hostname netns1
nsenter -t $pid_netns2 -u hostname netns2
nsenter -t $pid_netns3 -u hostname netns3
nsenter -t $pid_netns4 -u hostname netns4
nsenter -t $pid_netns5 -u hostname netns5
nsenter -t $pid_netns6 -u hostname netns6
nsenter -t $pid_netns7 -u hostname netns7
nsenter -t $pid_netns8 -u hostname netns8
#set up veth devices in netns1 to netns4 with connection to netns3
ip link add veth11 netns $pid_netns1 type veth peer name veth13 netns $pid_netns3
ip link add veth22 netns $pid_netns2 type veth peer name veth23 netns $pid_netns3
ip link add veth44 netns $pid_netns4 type veth peer name veth43 netns $pid_netns3
ip link add veth55 netns $pid_netns5 type veth peer name veth53 netns $pid_netns3
#set up veth devices in netns6 and netns7 with connection to netns8
ip link add veth66 netns $pid_netns6 type veth peer name veth68 netns $pid_netns8
ip link add veth77 netns $pid_netns7 type veth peer name veth78 netns $pid_netns8
# Assign IP addresses and set the devices up
nsenter -t $pid_netns1 -u -n /bin/bash
ip addr add 192.168.5.1/24 brd 192.168.5.255 dev veth11
ip link set veth11 up
ip link set lo up
exit
nsenter -t $pid_netns2 -u -n /bin/bash
ip addr add 192.168.5.2/24 brd 192.168.5.255 dev veth22
ip link set veth22 up
ip link set lo up
exit
nsenter -t $pid_netns4 -u -n /bin/bash
ip addr add 192.168.5.4/24 brd 192.168.5.255 dev veth44
ip link set veth44 up
ip link set lo up
exit
nsenter -t $pid_netns5 -u -n /bin/bash
ip addr add 192.168.5.5/24 brd 192.168.5.255 dev veth55
ip link set veth55 up
ip link set lo up
exit
nsenter -t $pid_netns6 -u -n /bin/bash
ip addr add 192.168.5.6/24 brd 192.168.5.255 dev veth66
ip link set veth66 up
ip link set lo up
exit
nsenter -t $pid_netns7 -u -n /bin/bash
ip addr add 192.168.5.7/24 brd 192.168.5.255 dev veth77
ip link set veth77 up
ip link set lo up
exit
# set up bridge brx and its ports
nsenter -t $pid_netns3 -u -n /bin/bash
brctl addbr brx
ip link set brx up
ip link set veth13 up
ip link set veth23 up
ip link set veth43 up
ip link set veth53 up
brctl addif brx veth13
brctl addif brx veth23
brctl addif brx veth43
brctl addif brx veth53
exit
# set up bridge bry and its ports
nsenter -t $pid_netns8 -u -n /bin/bash
brctl addbr bry
ip link set bry up
ip link set veth68 up
ip link set veth78 up
brctl addif bry veth68
brctl addif bry veth78
exit
Set up the VLANs
The following commands configure the VLANs by assigning PVIDs/VIDs to the bridge ports (see the last 2 posts for more information):
# set up 2 VLANs on each bridge
nsenter -t $pid_netns3 -u -n /bin/bash
ip link set dev brx type bridge vlan_filtering 1
bridge vlan add vid 10 pvid untagged dev veth13
bridge vlan add vid 10 pvid untagged dev
veth23
bridge vlan add vid 20 pvid untagged dev veth43
bridge vlan add vid 20 pvid untagged dev veth53
bridge vlan del vid 1 dev brx self
bridge vlan del vid 1 dev veth13
bridge vlan del vid 1 dev veth23
bridge vlan del vid 1 dev veth43
bridge vlan del vid 1 dev veth53
bridge vlan show
exit
nsenter -t $pid_netns8 -u -n /bin/bash
ip link set dev bry type bridge vlan_filtering 1
bridge vlan add vid 10 pvid untagged dev veth68
bridge vlan add vid 20 pvid untagged dev veth78
bridge vlan del vid 1 dev bry self
bridge vlan del vid 1 dev veth68
bridge vlan del vid 1 dev veth78
bridge vlan show
exit
We have a whole bunch of network namespaces now. Use “lsns” to get an overview. See the first 2 articles of the series, if you need an explanation of the commands used above and additional commands to get more information about the created namespaces and processes.
Note that we used VID 10, PVID 10 on the bridge ports to establish VLAN1 (green) and VID 20, PVID 20 to establish VLAN2 (pink). Note in addition that there is NO VLAN tagging required outside the bridges; thus the flag “untagged” to enforce Ethernet packets to leave the bridges untagged. Consistently, no sub-interfaces have been defined in the network namespace 1, 2, 4, 5, 6, 7. Note also, that we removed the PVID/VID = 1 default values from the ports.
The bridges are not connected, yet. Therefore, our next step is to create a connecting veth device with VLAN sub-interfaces – and to attach the sub-interfaces to the bridges :
# Create a veth device to connect the two bridges
ip link add vethx netns $pid_netns3 type veth peer name vethy netns $pid_netns8
nsenter -t $pid_netns3 -u -n /bin/bash
ip link add link vethx name vethx.50 type vlan id 50
ip link add link vethx name vethx.60 type vlan id 60
brctl addif brx vethx.50
brctl addif brx vethx.60
ip link set vethx up
ip link set vethx.50 up
ip link set vethx.60 up
bridge vlan add vid 10 pvid untagged dev vethx.50
bridge vlan add vid 20 pvid untagged dev vethx.60
bridge vlan del vid 1 dev vethx.50
bridge vlan del vid 1 dev vethx.60
bridge vlan show
exit
nsenter -t $pid_netns8 -u -n /bin/bash
ip link add link vethy name vethy.50 type vlan id 50
ip link add link vethy name vethy.60 type vlan id 60
brctl addif bry vethy.50
brctl addif bry vethy.60
ip link set vethy up
ip link set vethy.50 up
ip link set vethy.60 up
bridge vlan add vid 10 pvid untagged dev vethy.50
bridge vlan add vid 20 pvid untagged dev vethy.60
bridge vlan del vid 1 dev vethy.50
bridge vlan del vid 1 dev vethy.60
bridge vlan show
exit
Note that we have used VLAN IDs 50 and 60 outside the bridge! Note also the VID/PVID settings and the flag “untagged” at our bridge ports vethx.50, vethx.60, vethy.50, vethy.60. The bridge internal tags of outgoing packets are first removed; afterwards the veth sub-interfaces re-tag outgoing packets automatically with tags for VLAN IDs 50,60.
However, we have kept up consistent tagging histories for packets propagating between the bridges and along the vethx/vethy line:
“10=>50=>10”
and
“20=>60=>20”
So, Ethernet packets nowhere cross the borders of our separated VLANs – if our theory works correctly.
Routing? 2 or 4 VLANs?
Routes for 192.168.5.0/24 were set up automatically in the network namespaces netns1, 2, 4, 5, 6, 7. You may check this by entering the namespaces with a shell (nsenter command) and using the command “route“.
Note that we have chosen all IP address to be in the same class. All our virtual devices work on the network link layer (L1/2 of the OSI model). Further IP routing across the bridges is not required on this level. The correct association of IP addresses and MAC addresses across the bridges and all VLANs is instead managed by the ARP protocol.
Our network namespaces should be able to get into contact – as long as they belong to the “same” VLAN.
Note: Each bridge sets up its own 2 VLANs; so, actually, we have built 4 VLANs!. But the bridges are connected in such a way that packet transport works across these 4 VLANs as if they were only two VLANs spanning the bridges.
Tests
We first test whether netns7 can communicate with e.g. netns5, which it should. On the other side netns7 should not be able to ping e.g. netns1. It is instructive to open several terminal windows from our original terminal (on KDE e.g. by “konsole &>/dev/null &”) and to enter different namespaces there to get an impression of what happens.
mytux:~ # nsenter -t $pid_netns7 -u -n /bin/bash
netns7:~ # ping 192.168.5.1 -c2
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
From 192.168.5.7 icmp_seq=1 Destination Host Unreachable
From 192.168.5.7 icmp_seq=2 Destination Host Unreachable
--- 192.168.5.1 ping statistics ---
2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 1008ms
pipe 2
netns7:~ # ping 192.168.5.5 -c2
PING 192.168.5.5 (192.168.5.5) 56(84) bytes of data.
64 bytes from 192.168.5.5: icmp_seq=1 ttl=64 time=0.170 ms
64 bytes from 192.168.5.5: icmp_seq=2 ttl=64 time=0.087 ms
--- 192.168.5.5 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.087/0.128/0.170/0.043 ms
netns7:~ #
And at the same time inside bry in netns8 :
mytux:~ # nsenter -t $pid_netns8 -u -n /bin/bash
netns8:~ # tcpdump -n -i bry host 192.168.5.1 -e
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on bry, link-type EN10MB (Ethernet), capture size 262144 bytes
14:38:48.780367 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
14:38:49.778559 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
14:38:50.778574 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
^C
3 packets captured
3 packets received by filter
0 packets dropped by kernel
netns8:~ # tcpdump -n -i bry host 192.168.5.5 -e
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on bry, link-type EN10MB (Ethernet), capture size 262144 bytes
14:39:30.045117 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.5 tell 192.168.5.7, length 28
14:39:30.045184 2e:75:26:04:a9:70 > 8a:1e:62:e8:f3:c3, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Reply 192.168.5.5 is-at 2e:75:26:04:a9:70, length 28
14:39:30.045193 8a:1e:62:e8:f3:c3 > 2e:75:26:04:a9:70, ethertype 802.1Q (0x8100), length 102: vlan 20, p 0, ethertype IPv4, 192.168.5.7 > 192.168.5.5: ICMP echo request, id 21633, seq 1, length 64
14:39:30.045247 2e:75:26:04:a9:70 > 8a:1e:62:e8:f3:c3, ethertype 802.1Q (0x8100), length 102: vlan 20, p 0, ethertype IPv4, 192.168.5.5 > 192.168.5.7: ICMP echo reply, id 21633, seq 1, length 64
14:39:31.044106 8a:1e:62:e8:f3:c3 > 2e:75:26:04:a9:70, ethertype 802.1Q (0x8100), length 102: vlan 20, p 0, ethertype IPv4, 192.168.5.7 > 192.168.5.5: ICMP echo request, id 21633, seq 2, length 64
14:39:31.044165 2e:75:26:04:a9:70 > 8a:1e:62:e8:f3:c3, ethertype 802.1Q (0x8100), length 102: vlan 20, p 0, ethertype IPv4, 192.168.5.5 > 192.168.5.7: ICMP echo reply, id 21633, seq 2, length 64
14:39:35.058576 2e:75:26:04:a9:70 > 8a:1e:62:e8:f3:c3, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.7 tell 192.168.5.5, length 28
14:39:35.058587 8a:1e:62:e8:f3:c3 > 2e:75:26:04:a9:70, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Reply 192.168.5.7 is-at 8a:1e:62:e8:f3:c3, length 28
^C
8 packets captured
8 packets received by filter
0 packets dropped by kernel
netns8:~ #
And parallel at vethx in netns3 :
mytux:~ # nsenter -t $pid_netns3 -u -n /bin/bash
netns3:~ # tcpdump -n -i vethx host 192.168.5.1 -e
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on vethx, link-type EN10MB (Ethernet), capture size 262144 bytes
14:38:48.780381 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 60, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
14:38:49.778582 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 60, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
14:38:50.778594 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 60, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
^C
3 packets captured
3 packets received by filter
0 packets dropped by kernel
netns3:~ # tcpdump -n -i vethx host 192.168.5.5 -e
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on vethx, link-type EN10MB (Ethernet), capture size 262144 bytes
14:39:30.045131 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 60, p 0, ethertype ARP, Request who-has 192.168.5.5 tell 192.168.5.7, length 28
14:39:30.045182 2e:75:26:04:a9:70 > 8a:1e:62:e8:f3:c3, ethertype 802.1Q (0x8100), length 46: vlan 60, p 0, ethertype ARP, Reply 192.168.5.5 is-at 2e:75:26:04:a9:70, length 28
14:39:30.045210 8a:1e:62:e8:f3:c3 > 2e:75:26:04:a9:70, ethertype 802.1Q (0x8100), length 102: vlan 60, p 0, ethertype IPv4, 192.168.5.7 > 192.168.5.5: ICMP echo request, id 21633, seq 1, length 64
14:39:30.045246 2e:75:26:04:a9:70 > 8a:1e:62:e8:f3:c3, ethertype 802.1Q (0x8100), length 102: vlan 60, p 0, ethertype IPv4, 192.168.5.5 > 192.168.5.7: ICMP echo reply, id 21633, seq 1, length 64
14:39:31.044123 8a:1e:62:e8:f3:c3 > 2e:75:26:04:a9:70, ethertype 802.1Q (0x8100), length 102: vlan 60, p 0, ethertype IPv4, 192.168.5.7 > 192.168.5.5: ICMP echo request, id 21633, seq 2, length 64
14:39:31.044163 2e:75:26:04:a9:70 > 8a:1e:62:e8:f3:c3, ethertype 802.1Q (0x8100), length 102: vlan 60, p 0, ethertype IPv4, 192.168.5.5 > 192.168.5.7: ICMP echo reply, id 21633, seq 2, length 64
14:39:35.058573 2e:75:26:04:a9:70 > 8a:1e:62:e8:f3:c3, ethertype 802.1Q (0x8100), length 46: vlan 60, p 0, ethertype ARP, Request who-has 192.168.5.7 tell 192.168.5.5, length 28
14:39:35.058589 8a:1e:62:e8:f3:c3 > 2e:75:26:04:a9:70, ethertype 802.1Q (0x8100), length 46: vlan 60, p 0, ethertype ARP, Reply 192.168.5.7 is-at 8a:1e:62:e8:f3:c3, length 28
^C
8 packets captured
8 packets received by filter
0 packets dropped by kernel
netns3:~ #
How does netns7 see the world afterwards?
netns7:~ # ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: veth77@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 8a:1e:62:e8:f3:c3 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.5.7/24 brd 192.168.5.255 scope global veth77
valid_lft forever preferred_lft forever
inet6 fe80::881e:62ff:fee8:f3c3/64 scope link
valid_lft forever preferred_lft forever
netns7:~ # arp -a
? (192.168.5.1) at <incomplete> on veth77
? (192.168.5.5) at 2e:75:26:04:a9:70 [ether] on veth77
netns7:~ #
We have a mirrored situation on netns6 with respect to netns1 and netns5. netns6 can reach netns1, but not netns5.
These results prove what we have claimed:
- We have a separation of the VLANs across the bridges.
- Inside the bridges only the ports’ PVID-settings determine the VLAN tag (here 20) of incoming packets.
- Along the veth “cable” we have a completely different tag (here 60 for packets which originally got tag 20 inside bry).
Let us cross check for netns2:
mytux:~ # nsenter -t $pid_netns2 -u -n /bin/bash
netns2:~ # ping 192.168.5.7 -c2
PING 192.168.5.7 (192.168.5.7) 56(84) bytes of data.
From 192.168.5.2 icmp_seq=1 Destination Host Unreachable
From 192.168.5.2 icmp_seq=2 Destination Host Unreachable
--- 192.168.5.7 ping statistics ---
2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 999ms
pipe 2
netns2:~ # ping 192.168.5.6 -c2
PING 192.168.5.6 (192.168.5.6) 56(84) bytes of data.
64 bytes from 192.168.5.6: icmp_seq=1 ttl=64 time=0.154 ms
64 bytes from 192.168.5.6: icmp_seq=2 ttl=64 time=0.092 ms
--- 192.168.5.6 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.092/0.123/0.154/0.031 ms
netns2:~ #
And how do the bridges see the world?
In netns8 and netns3 we have a closer look at the bridges:
netns8:~ # ip a s
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth68: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master bry state UP group default qlen 1000
link/ether 0a:5b:60:31:7a:bd brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::85b:60ff:fe31:7abd/64 scope link
valid_lft forever preferred_lft forever
3: veth78@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master bry state UP group default qlen 1000
link/ether 3e:f3:4b:26:02:46 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::3cf3:4bff:fe26:246/64 scope link
valid_lft forever preferred_lft forever
4: bry: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 0a:5b:60:31:7a:bd brd ff:ff:ff:ff:ff:ff
inet6 fe80::30a5:8dff:fe54:987e/64 scope link
valid_lft forever preferred_lft forever
5: vethy@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 7a:86:31:14:57:2a brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::7886:31ff:fe14:572a/64 scope link
valid_lft forever preferred_lft forever
6: vethy.50@vethy: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master bry state UP group default qlen 1000
link/ether 7a:86:31:14:57:2a brd ff:ff:ff:ff:ff:ff
inet6 fe80::7886:31ff:
fe14:572a/64 scope link
valid_lft forever preferred_lft forever
7: vethy.60@vethy: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master bry state UP group default qlen 1000
link/ether 7a:86:31:14:57:2a brd ff:ff:ff:ff:ff:ff
inet6 fe80::7886:31ff:fe14:572a/64 scope link
valid_lft forever preferred_lft forever
netns8:~ # bridge vlan show
port vlan ids
veth68 10 PVID Egress Untagged
veth78 20 PVID Egress Untagged
bry None
vethy.50 10 PVID Egress Untagged
vethy.60 20 PVID Egress Untagged
netns8:~ # brctl showmacs bry
port no mac addr is local? ageing timer
1 0a:5b:60:31:7a:bd yes 0.00
1 0a:5b:60:31:7a:bd yes 0.00
4 2e:75:26:04:a9:70 no 3.62
2 3e:f3:4b:26:02:46 yes 0.00
2 3e:f3:4b:26:02:46 yes 0.00
4 7a:86:31:14:57:2a yes 0.00
3 7a:86:31:14:57:2a yes 0.00
3 7a:86:31:14:57:2a yes 0.00
3 7a:86:31:14:57:2a yes 0.00
2 8a:1e:62:e8:f3:c3 no 3.62
netns3:~ # ip a s
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master brx state UP group default qlen 1000
link/ether 52:9b:43:56:37:df brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::509b:43ff:fe56:37df/64 scope link
valid_lft forever preferred_lft forever
3: veth23@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master brx state UP group default qlen 1000
link/ether 06:81:88:12:5d:dc brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::481:88ff:fe12:5ddc/64 scope link
valid_lft forever preferred_lft forever
4: veth43@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master brx state UP group default qlen 1000
link/ether 56:d6:b2:80:9a:de brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::54d6:b2ff:fe80:9ade/64 scope link
valid_lft forever preferred_lft forever
5: veth53@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master brx state UP group default qlen 1000
link/ether 12:58:a6:73:6c:6e brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::1058:a6ff:fe73:6c6e/64 scope link
valid_lft forever preferred_lft forever
6: brx: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 06:81:88:12:5d:dc brd ff:ff:ff:ff:ff:ff
inet6 fe80::8447:28ff:fe22:7a90/64 scope link
valid_lft forever preferred_lft forever
7: vethx@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether b6:e9:ef:3d:1c:b7 brd ff:ff:ff:ff:ff:ff link-netnsid 4
inet6 fe80::b4e9:efff:fe3d:1cb7/64 scope link
valid_lft forever preferred_lft forever
8: vethx.50@vethx: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master brx state
UP group default qlen 1000
link/ether b6:e9:ef:3d:1c:b7 brd ff:ff:ff:ff:ff:ff
inet6 fe80::b4e9:efff:fe3d:1cb7/64 scope link
valid_lft forever preferred_lft forever
9: vethx.60@vethx: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master brx state UP group default qlen 1000
link/ether b6:e9:ef:3d:1c:b7 brd ff:ff:ff:ff:ff:ff
inet6 fe80::b4e9:efff:fe3d:1cb7/64 scope link
valid_lft forever preferred_lft forever
netns3:~ # bridge vlan show
port vlan ids
veth13 10 PVID Egress Untagged
veth23 10 PVID Egress Untagged
veth43 20 PVID Egress Untagged
veth53 20 PVID Egress Untagged
brx None
vethx.50 10 PVID Egress Untagged
vethx.60 20 PVID Egress Untagged
netns3:~ # brctl showmacs brx
port no mac addr is local? ageing timer
2 06:81:88:12:5d:dc yes 0.00
2 06:81:88:12:5d:dc yes 0.00
4 12:58:a6:73:6c:6e yes 0.00
4 12:58:a6:73:6c:6e yes 0.00
4 2e:75:26:04:a9:70 no 3.49
1 52:9b:43:56:37:df yes 0.00
1 52:9b:43:56:37:df yes 0.00
3 56:d6:b2:80:9a:de yes 0.00
3 56:d6:b2:80:9a:de yes 0.00
6 8a:1e:62:e8:f3:c3 no 3.49
5 b6:e9:ef:3d:1c:b7 yes 0.00
6 b6:e9:ef:3d:1c:b7 yes 0.00
5 b6:e9:ef:3d:1c:b7 yes 0.00
5 b6:e9:ef:3d:1c:b7 yes 0.00
And:
netns8:~ # brctl showmacs bry
port no mac addr is local? ageing timer
1 0a:5b:60:31:7a:bd yes 0.00
1 0a:5b:60:31:7a:bd yes 0.00
4 2e:75:26:04:a9:70 no 7.37
2 3e:f3:4b:26:02:46 yes 0.00
2 3e:f3:4b:26:02:46 yes 0.00
4 7a:86:31:14:57:2a yes 0.00
3 7a:86:31:14:57:2a yes 0.00
3 7a:86:31:14:57:2a yes 0.00
3 7a:86:31:14:57:2a yes 0.00
2 8a:1e:62:e8:f3:c3 no 7.37
3 96:e8:d1:2c:b8:ad no 3.84
1 ce:48:c6:8c:ee:1a no 3.84
netns8:~ #
netns3:~ # brctl showmacs brx
port no mac addr is local? ageing timer
2 06:81:88:12:5d:dc yes 0.00
2 06:81:88:12:5d:dc yes 0.00
4 12:58:a6:73:6c:6e yes 0.00
4 12:58:a6:73:6c:6e yes 0.00
4 2e:75:26:04:a9:70 no 12.48
1 52:9b:43:56:37:df yes 0.00
1 52:9b:43:56:37:df yes 0.00
3 56:d6:b2:80:9a:de yes 0.00
3 56:d6:b2:80:9a:de yes 0.00
6 8a:1e:62:e8:f3:c3 no 12.48
2 96:e8:d1:2c:b8:ad no 8.94
5 b6:e9:ef:3d:1c:b7 yes 0.00
6 b6:e9:ef:3d:1c:b7 yes 0.00
5 b6:e9:ef:3d:1c:b7 yes 0.00
5 b6:e9:ef:3d:1c:b7 yes 0.00
5 ce:48:
c6:8c:ee:1a no 8.94
netns3:~ #
Obviously, our bridges learn during pings …
Check of the independence of VLAN definitions on Bry
Just for fun: Let us change the PVID/VID setting on bry:
# Changing PVID/VID in bry
nsenter -t $pid_netns8 -u -n /bin/bash
bridge vlan add vid 36 pvid untagged dev veth68
bridge vlan add vid 46 pvid untagged dev veth78
bridge vlan add vid 36 pvid untagged dev vethy.50
bridge vlan add vid 46 pvid untagged dev vethy.60
bridge vlan del vid 10 dev vethy.50
bridge vlan del vid 10 dev veth68
bridge vlan del vid 20 dev vethy.60
bridge vlan del vid 20 dev veth78
bridge vlan show
exit
This leads to:
netns8:~ # bridge vlan show
port vlan ids
veth68 36 PVID Egress Untagged
veth78 46 PVID Egress Untagged
bry None
vethy.50 36 PVID Egress Untagged
vethy.60 46 Egress Untagged
But still:
netns2:~ # ping 192.168.5.7 -c2
PING 192.168.5.7 (192.168.5.7) 56(84) bytes of data.
From 192.168.5.2 icmp_seq=1 Destination Host Unreachable
From 192.168.5.2 icmp_seq=2 Destination Host Unreachable
--- 192.168.5.7 ping statistics ---
2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 1009ms
pipe 2
netns2:~ # ping 192.168.5.6 -c2
PING 192.168.5.6 (192.168.5.6) 56(84) bytes of data.
64 bytes from 192.168.5.6: icmp_seq=1 ttl=64 time=0.120 ms
64 bytes from 192.168.5.6: icmp_seq=2 ttl=64 time=0.094 ms
--- 192.168.5.6 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.094/0.107/0.120/0.013 ms
netns2:~ #
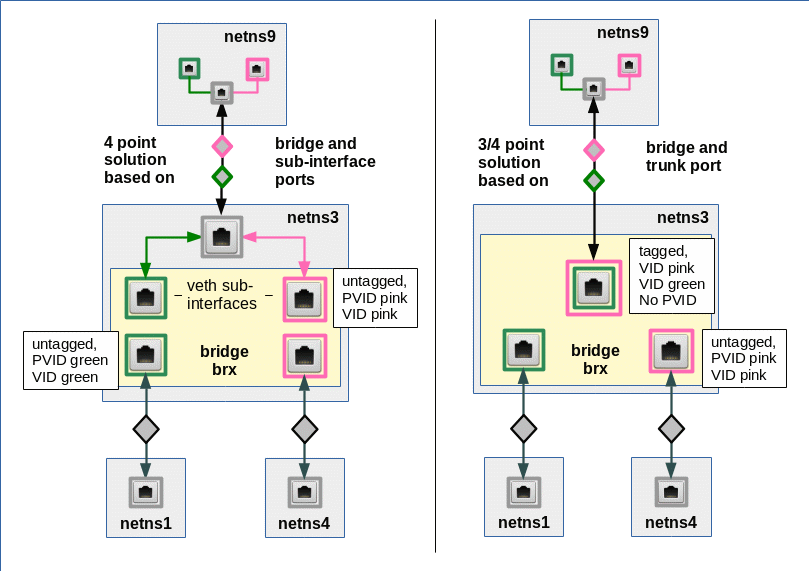
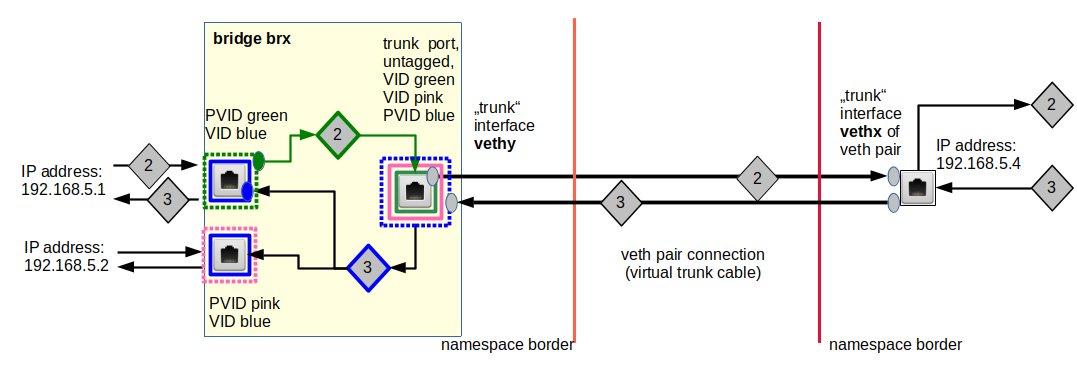
Experiment 5.2 – Two virtual VLANs spanning two Linux bridges connected by a veth based trunk line between trunk ports
Now let us look at another way of connecting the bridges. This time we use a real trunk connection without sub-interfaces. We then have to attach vethx directly to brx and vethy directly to bry. NO PVIDs must be used on the respective ports; however the flag “tagged” is required. And compared to the last settings in bry we have to go back to the PVID/VID values of 10, 20.
Our new connection model is displayed in the following graphics:

We need to change the present bridge and bridge port definitions accordingly. The commands, which you can enter at the prompt of your original terminal window are given below:
# Change vethx to trunk like interface in brx
nsenter -t $pid_netns3 -u -n /bin/bash
brctl delif brx vethx.50
brctl delif brx vethx.60
ip link del dev vethx.50
ip link del dev vethx.60
brctl addif brx vethx
bridge vlan add vid 10 tagged dev vethx
bridge vlan add vid 20 tagged dev vethx
bridge vlan del vid 1 dev vethx
bridge vlan show
exit
And
# Change vethy to trunk like interface in brx
nsenter -t $pid_netns8 -u -n /bin/bash
brctl delif bry vethy.50
brctl delif bry vethy.60
ip link del dev vethy.50
ip link del dev vethy.60
brctl addif bry vethy
bridge vlan add vid 10 tagged dev vethy
bridge vlan add vid 20 tagged dev vethy
bridge vlan del vid 1 dev vethy
bridge vlan add vid 10 pvid untagged dev veth68
bridge vlan add vid 20 pvid untagged dev veth78
bridge vlan del vid 36 dev veth68
bridge vlan del vid 46 dev veth78
bridge vlan show
exit
We get the following bridge/VLAN configurations:
netns8:~ # bridge vlan show
port vlan ids
veth68 10 PVID Egress Untagged
veth78 20 PVID Egress Untagged
bry None
vethy 10
20
and
netns3:~ # bridge vlan show
port vlan ids
veth13 10 PVID Egress Untagged
veth23 10 PVID Egress Untagged
veth43 20 PVID Egress Untagged
veth53 20 PVID Egress Untagged
brx None
vethx 10
20
Testing 2 VLANs spanning two bridges/Hosts with a trunk connection
We test by pinging from netns7:
netns7:~ # ping 192.168.5.1 -c2
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
From 192.168.5.7 icmp_seq=1 Destination Host Unreachable
From 192.168.5.7 icmp_seq=2 Destination Host Unreachable
--- 192.168.5.1 ping statistics ---
2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 999ms
pipe 2
netns7:~ #
This gives at the bridge device bry in netns8:
netns8:~ # tcpdump -n -i bry host 192.168.5.1 -e
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on bry, link-type EN10MB (Ethernet), capture size 262144 bytes
15:31:15.527528 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
15:31:16.526542 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
15:31:17.526576 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
^C
3 packets captured
3 packets received by filter
0 packets dropped by kernel
netns8:~ #
At the outer side of vethx in netns3 we get :
netns3:~ # tcpdump -n -i vethx host 192.168.5.1 -e
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on vethx, link-type EN10MB (Ethernet), capture size 262144 bytes
15:31:15.527543 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
15:31:16.526561 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
15:31:17.526605 8a:1e:62:e8:f3:c3 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 20, p 0, ethertype ARP, Request who-has 192.168.5.1 tell 192.168.5.7, length 28
^C
3 packets captured
3 packets received by filter
0 packets dropped by kernel
netns3:~ #
You see, how the packet tags have changed now: Due to the missing PVIDs at the ports for vethx, vethy and the flag “tagged” we get packets on the vethx/vethy connection line, which carry the original 20 tag they had inside the bridges.
So :
netns7:~ # ping 192.168.5.5 -c2
PING 192.168.5.5 (192.168.5.5) 56(84) bytes of data.
64 bytes from 192.168.5.5: icmp_seq=1 ttl=64 time=0.042 ms
64 bytes from 192.168.5.5: icmp_seq=2 ttl=64 time=0.092 ms
--- 192.168.5.5 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.042/0.067/0.092/0.025 ms
netns7:~ #
Obviously, we can connect our bridges with a trunk line between trunk ports, too.
Exactly 2 VLANs spanning 2 bridges with a trunk connection
Note that we MUST provide identical PVID/VID values inside the bridges bry and brx when we use a trunk like connection! VLAN filtering at all bridge ports works in both directions – IN and OUT. As the Ethernet packets keep their VLAN tags
when they leave or enter a bridge, we can not choose the VID/PVID values to be different in bry from brx. So, in contrast to the connection model with the sub-interfaces, we have no choices for PVID/VID assignments; we deal with exactly 2 and not 4 coupled VLANs.
Still, packets leave veth68, 78 and veth13, 23, 43, 53 untagged! The VLANs get established by the bridge and their connection line, alone.
Which connection model is preferable?
The connection model based on trunk port configurations looks simpler than the model based on veth sub-interfaces. However, the connection model based on sub-interfaces allows for much more flexibility and freedom! In addition, it may make it easier to define port related iptables filtering rules.
So, you have the choice how to extend (virtual) VLANs over several bridges/hosts.
Unfortunately, I have not yet tested for any performance differences.
VLANs spanning hosts with Linux bridges
Our test examples were tested on just one host. Is there any major difference when we instead look at 2 hosts, each with a virtual Linux bridge? Not, really. Our devices vethx and vethy would then be two real Ethernet cards like ethx and ethy. But you could make them slaves of the bridges, too, and you could split them into sub-interfaces.
So, our VLANs based on Linux bridge configurations would also work, if the bridges were located on different hosts. For both connection models …
Conclusion
Network namespaces or containers can become members of virtual VLANs. The configuration of bridge ports determines the VLAN setup. We can easily extend such (virtual) VLANs from one bridge to other bridges – even if the bridges are located on different hosts. In addition, we have the choice whether we base the connection on ports based on sub-interfaces or pure trunk ports. This gives us a maximum of flexibility.
But: Our VLANs were strictly separated so far. In reality, however, we may find situations in which a host/container must be member of two VLANs (VLAN1 and VLAN2). How do the veth connections from/to a network namespace look like, if a user in this intermediate network namespace shall be able to talk to all containers/namespaces in VLAN1 and VLAN2?
This is the topic of the next post.
Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – VII
Again, there will be 2 different solutions ….