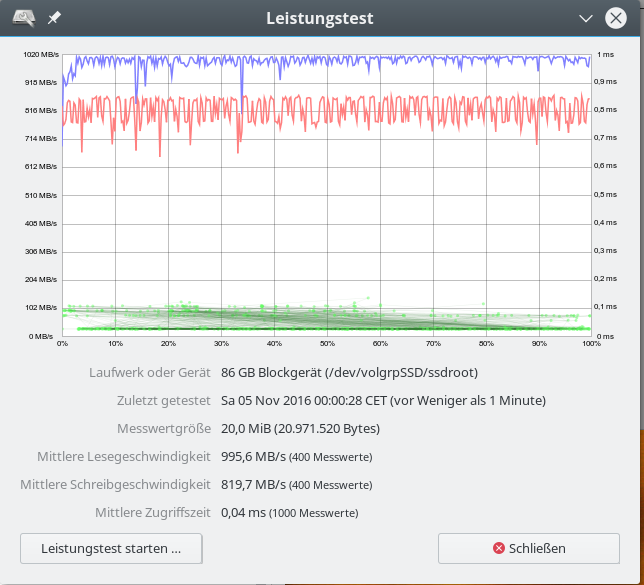
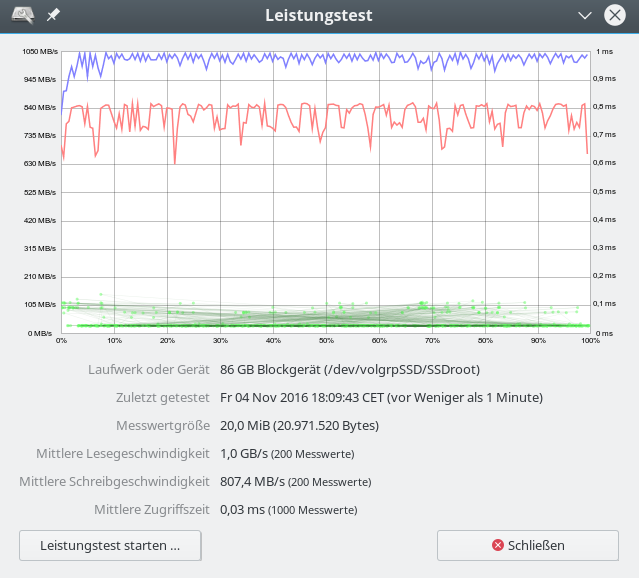
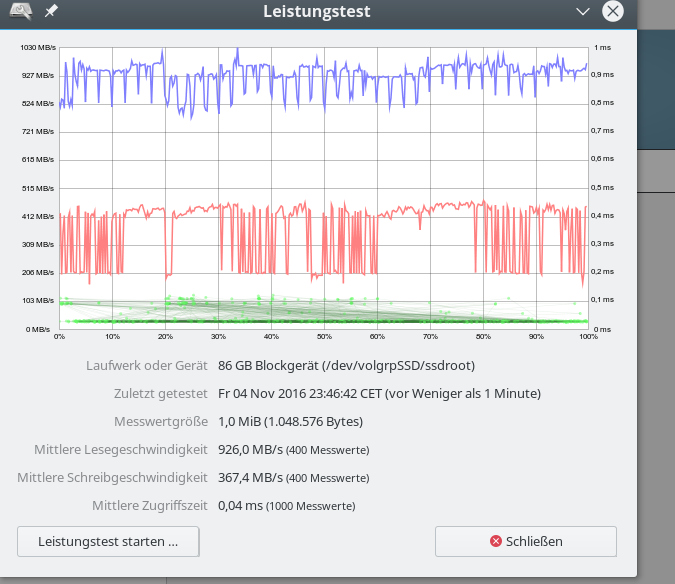
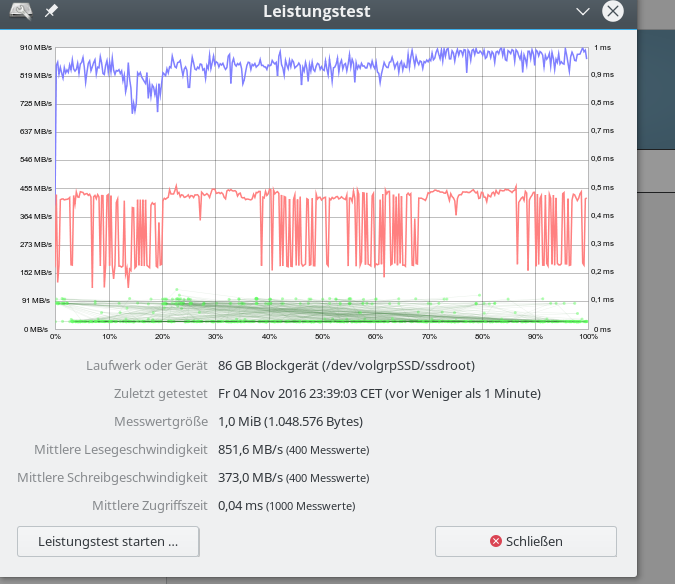
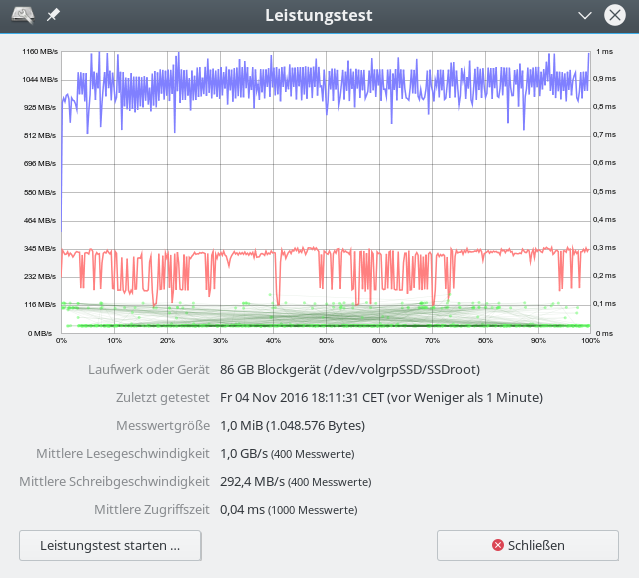
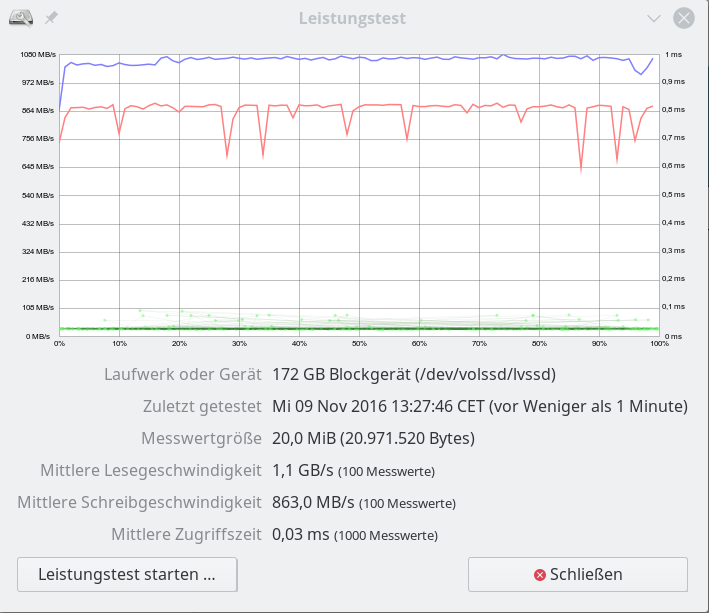
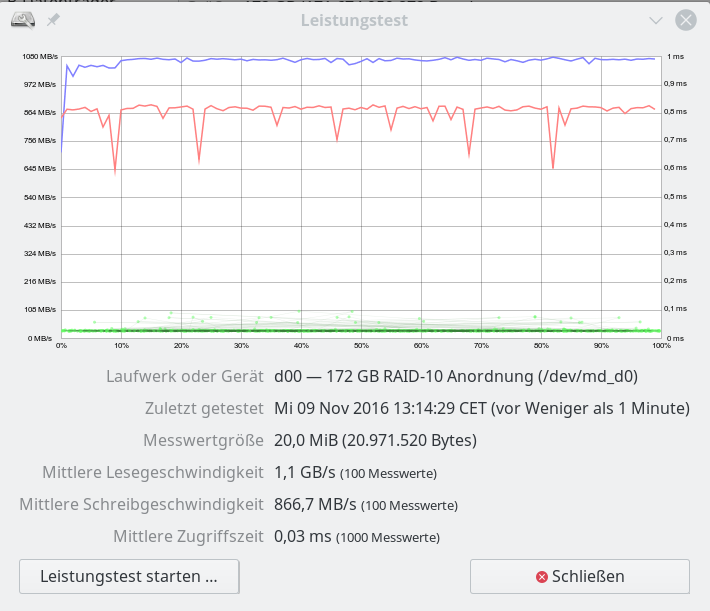
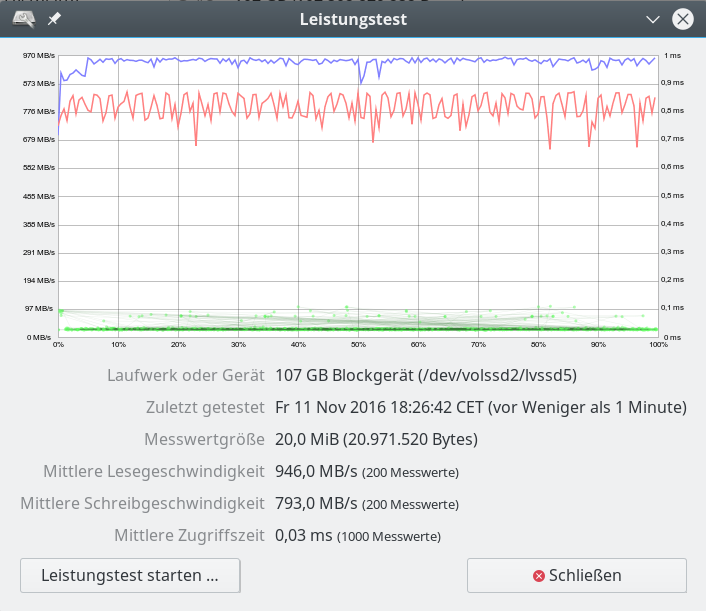
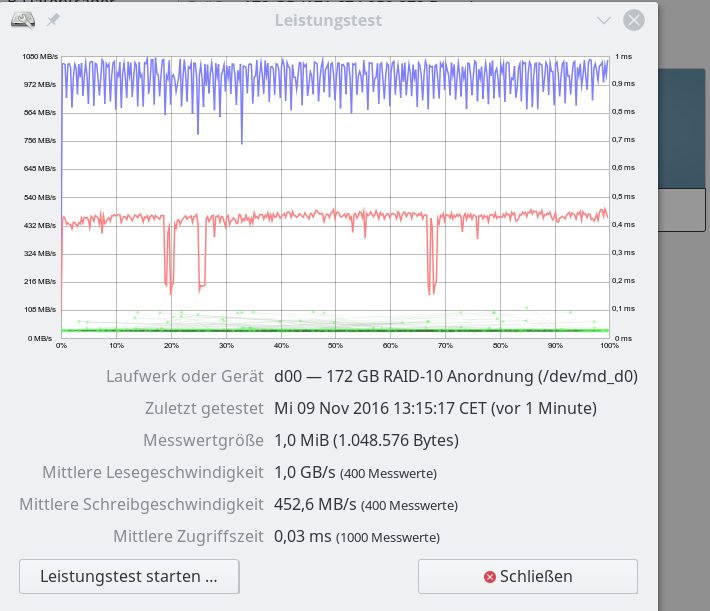
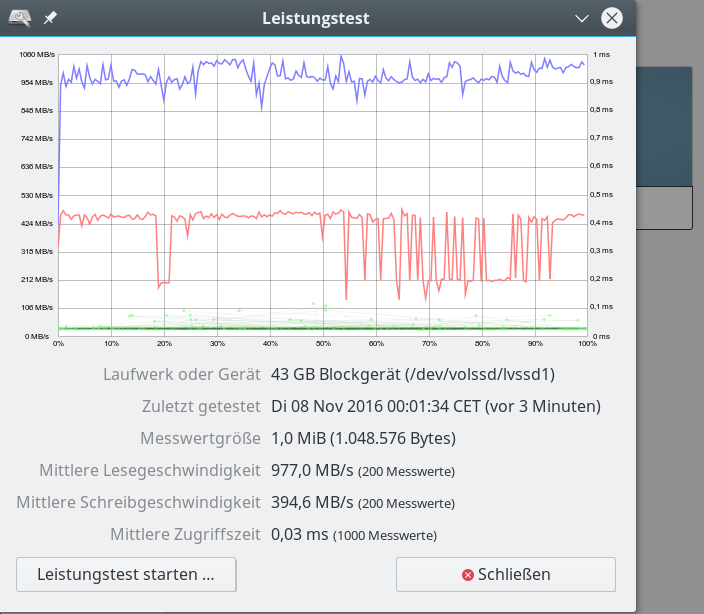
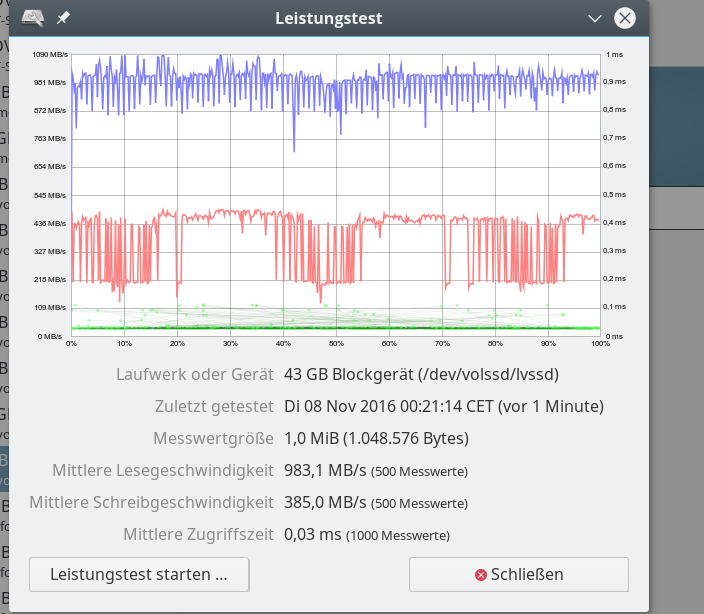
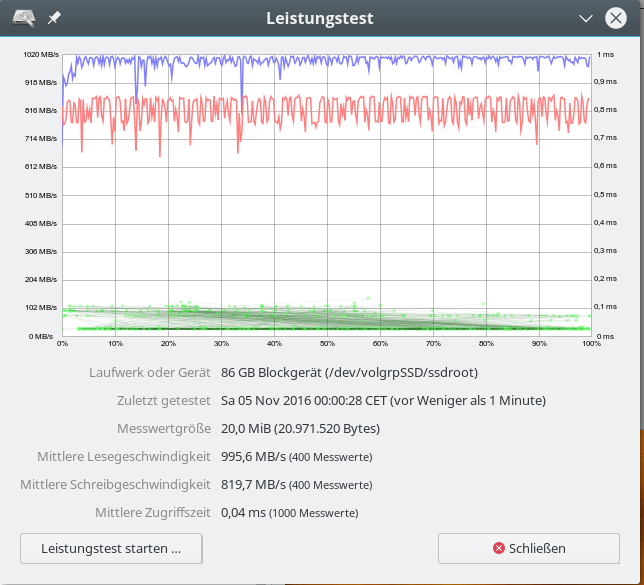
Im letzten Beitrag dieser Serie zu SSD-Raid-Arrays unter Linux
SSD Raid Arrays unter Linux – IV – OS und Daten auf demselben Raid-Array?
hatte ich mich mit der Frage auseinandergesetzt, ob wir eigentlich das Betriebssystem [OS] nicht auch auf einem Raid-Array unterbringen können oder sollten, das für hochperformante Datenzugriffe von Anwendungen vorgesehen ist. Ich habe dafür zwar wenig übrig; aber dennoch kann es Umstände geben, in denen man das Betriebssystem in einem (ggf. separaten) Raid-Array installieren muss oder will.
In einer solchen Situation könnte man größere Sorgen bzgl. der Boot-Unterstützung bekommen. Im Besonderen, wenn man vor hat, Linux-SW-Raids zu nutzen. Das Thema beim Booten ist ja immer:
Wer oder was findet eigentlich das Kernel-Image und eine ggf. notwendige Informationen zu einem initramfs, wenn das alles auf Partitionen eines Raid-Arrays liegt? Ggf. auch noch unter einem LVM-Layer versteckt? Der Kernel jedenfalls nicht – der ist zu diesem Zeitpunkt ja noch nicht geladen. Und wenn er geladen wäre, müsste er mit dem jeweiligen Raid-Verbund umgehen können. Dazu braucht er Treiber, sprich Kernel-Module, die er aus dem initramfs auslesen müsste. Wer aber stellt im Bootvorgang die “initram” auf Basis von File-Informationen bereit, die selbst auf einem Raid-Array liegen?
Braucht es da nicht schon irgendwelche magischen Kenntnisse des BIOS über das Raid-Layout? Und im Fall von Intel-Sata-Controllern, die in Mainboard-Chipsätze integriert sind: Braucht man dann nicht zwingend iRST-Technologie ? Und einen Layer in einem System mit (U)EFI-BIOS, der das Raid-Layout der Platten am Intel-Raid-Controller kennt?
Das sind berechtige Fragen. Evtl. Sorgen sind jedoch unbegründet.
Grub2 ist intelligent – dieser Bootmanager kann mit Linux-SW-Raid-Arrays, dortigen Partitionen und auch LVM umgehen
Grub2 ist in den letzten Jahren so ertüchtigt worden, dass dieser Boot-Manager nicht nur mit verschiedenen Partionierungs-und Filesystem-Schemata, sondern auch mit verschiedenen Varianten von Linux-SW-Raids und auch mit LVM/LVM2 umgehen kann. Dass es dafür letztlich kein Hexenwerk benötigt, mag man daran erkennen, dass unter Linux sowohl Raid- als auch LVM-Informationen im Superblock der beteiligten Partitionen auf den einzelnen miteinander verkoppelten Platten bzw. Partitionen hinterlegt werden.
Auf Basis der dortigen Imformationen kann Grub2 die angelegte (komplexe und sich ggf. über mehrere Platten erstreckende Filesystemstruktur aufdröseln, von dort ein Kernel-Image laden und ein initramfs bereitstellen.
Ferner ist Grub2 ist in seiner EFI-Variante natürlich auch in der Lage, Boot-Informationen in EFI-Partitionen zu lesen bzw. über den Grub-Installer Boot-Informationen in EFI-Partitionen zu schreiben und auch den EFI-Bootmanager mit Informationen zur Boot-Reihenfolge und mit entsprechenden Zieladressen zu versorgen.
https://www.gnu.org/software/grub/manual/grub.html
https://wiki.gentoo.org/wiki/GRUB2/AdvancedStorage
Ist der Einsatz von iRST auf einem UEFI-System notwendig, damit Grub2 ein Linux-System aus einer Partition eines Linux-SW-Raid-Arrays oder eines imsm-Raid-Arrays booten kann?
Die Antwort ist: Mit Grub2 kann man Linux-Betriebsysteme auf einem UEFI-System von beiden Raid-Varianten (SW-Raid und von iRST-imsm-Volumes) booten. Der Einsatz von Intels iRST-Technologie ist jedenfalls nicht erforderlich! Mann kann auch von Linux-SW-Arrays booten!
Das Aufsetzen des Betriebssystems auf einem reinen Linux-SW-Raid-Array ist nur geringfügig komplizierter als auf einem im BIOS
vorkonfigurierten iRST-Array. Allerdings sind ein paar Regeln zu beachten:
- Die efi-boot-Partition selbst darf nicht Bestandteil einer Linux-LVM– oder mdadm-Raid-Gruppe an Partitionen werden. Das erscheint logisch: Grub2 oder Linux müssen schon da sein, um LVM oder mdadm-Raids auswerten zu können. Das Grub2-Modul “grubx64.efi” wird ja aber gerade auf der EFI-Partition für den EFI-Bootmanager hinterlegt und von dort geladen.
- Die efi-Boot-Partition darf nicht Bestandteil des reinen SW-Raid-Arrays sein. Es gilt eine analoge Begründung wie beim vorherigen Punkt.
- Eine “initram” mit einem initramfs mit den notwendigen Treibermodulen für den Kernel ist erforderlich. Aber das wird von den meisten Linux-Installern sowieso im Zuge der Erstinstallation ordentlich prepariert.
Das bedeutet in der Praxis, dass ihr die EFI-Partition entweder auf eine separate SSD oder HDD Platte legen müsst, die nicht am vorgesehenen SSD-Raid-Verbund beteiligt ist. Oder aber: Ihr legt auf jeder der SSD-Platten, deren größere Roh-Partitionen man später in SW-Raid-Arrays unter mdadm einbinden will, zunächst eine kleine, ca. 170 MB umfassende Partition an; eine dieser Partitionen wird im Installationsvorgang bereits mit FAT formatiert und erhält dann die richtigen EFI-Einträge udn EFI-Module. Die anderen 170MB-Partitionen werden später per “”dd”-Kommando als Clones dieser ersten EFI-Partition mit Inhalten versorgt.
Keine dieser kleinen EFI-Partitionen auf den SSDs wird aber an den anzulegenden SW-Raid-Arrays beteiligt.
Grundsätzliches Vorgehen im Zuge der OS-Installation am Beispiel Opensuse
Auf einem laufenden Linux-System legt man SW-Raid-Arrays mittels mdadm-Befehlen auf der Kommandozeile an. Es lohnt sich jedenfalls, sich mit diesem Linux Raid-Tool und seinen Optionen auseinanderzusetzen. Wir gehen auf mdadm ganz konkret in einem späteren Blog-Beitrag ein. Eine etwas weniger mächtige Möglichkeit zur Anlage von SW-Raid-Arrays ergibt sich unter Opensuse aber z.B. auch der über den “YaST-Partitioner”; der kommt ja auch während einer Standardinstallation um Tragen.
Man beginnt bei der Installation zunächst mit der Anlage einer EFI-System-Partition [ESP] – z.B. unter “/dev/sda1”. Diese wird dann mit FAT formatiert. Unter Opensuse bietet der Installer über YaST-Module aber auch
- eine grafisch unterstützte Konfiguration von mdadm-SW-Raid-Arrays aus verschiedenen unformatierten (Raid-)Roh-Partitionen unterschiedlicher HDDs/SSDs an,
- und eine automatische Konfiguration des Grub2-Bootloaders unter Einbeziehung einer EFI-Partition an.
Partitionierungs- und mdadm-Befehle können während der Installation aber auch an einer Konsole (Wechsel etwa mit Ctrl-Alt-F2) abgesetzt werden. Das ist zu einer genaueren Parametrierung als mit YaST ggf. nötig. Der YaST-Partitioner bietet nämlich leider nicht alle für die Performance relevanten Raid-Konfigurationsmöglichkeiten als Optionen an! Eine Erstellung der Raid-Arrays über mdadm-befehle empfiehlt sich also unmittelbar vor Verwendung des YaST-Partitioners.
Der YaST-Partitioner erkennt dann die bereitgestellten Raid-Arrays und erlaubt deren weitere Bearbeitung.
Angelegte mdadm-SW-Arrays werden dann entweder direkt für bestimmte Filesysteme formatiert oder aber über LVM in Logical Volumes unterteilt und dann formatiert; geeignete Partitionen werden im Zuge der Plattenkonfiguration dann dem “/”- wie dem “/boot”-Verzeichnis zugeordnet und dort gemountet.
Die als EFI-Device mit Modulen auszustattende Partition (z.B. unter /dev/sda1) wird im weiteren Verlauf des Installationsprozesses ausgewählt, mit FAT formatiert und vom
Installer in den UEFI-Boot-Prozess eingebunden; der Grub2-Installer in seiner EFI-Variante schreibt die dafür notwendigen Infos in die ausgewählte EFI-Partition und der System-Installer nordet per “efibootmgr”-Kommando hinter den Kulissen auch das UEFI-Bootsystem richtig ein.
Installer wie YaST sorgen zudem dafür, dass das “initramfs” mit den notwendigen Kernelmodulen für den Umgang mit Raid-Arrays ausgestattet wird.
Warum mehrere EFI-Partitionen?
Der Grund, warum man letztlich mehrere EFI-Partitionen (je eine auf jeder SSD) erzeugt, ist eine Absicherung gegenüber einem Plattenausfall. Man kopiert dazu nach einer Installation die Inhalte der auf “/dev/sda1” angelegten EFI-Partition mittels des Kommandos “dd” auf die vorbereiteten, noch leeren, aber für EFI vorgesehenen 170MB-Partitionen der anderen am Array beteiligten SSDs.
Die meisten UEFI-Systeme erkennen selbständig gültige ESPs; fällt die erste davon aus, wird automatisch die nächste gültige im Bootvorgang herangezogen. Man kann die Reihenfolge der für den Bootvorgang heranzuziehenden ESPs aber auch gezielt vorgeben.
Hinweise darauf, wie man insgesamt zu verfahren hat, liefert etwa der folgende Artikel, der sich von Ubuntu auf andere Linux-Varianten verallgemeinern lässt:
http://askubuntu.com/questions/660023/how-to-install-ubuntu-14-04-64-bit-with-a-dual-boot-raid-1-partition-on-an-uefi
Ein vorkonfiguriertes iRST-Container-Volume würde das Leben bzgl. der EFI-Partition lediglich etwas vereinfachen: Da der iRST-Controller für UEFI-Systeme Boot-Unterstützung (Zwischenschicht) liefert, wird die EFI-Boot-Partition direkt als unabhängige Partition eines definierten “imsm”-Containers vorbereitet.
Hat man alles richtig gemacht, wird man feststellen, dass das EFI/Grub2-Gespann Linux-Betriebssysteme sowohl von reinen Linux-SW-Raid-Arrays als auch von iRST-Arrays bootet. Man hat das vor allem der Fähigkeit von Grub 2 zu verdanken, Files aus Raid- und LVM-Konfigurationen auszulesen.
Wir können somit Linux-Betriebssysteme und auch andere Daten auf einem Linux-SW-Raid-System bereitstellen – aber wir müssen das nicht unbedingt. Wer es dennoch tun will, kann trotzdem regulär booten!
Eine Fallgrube
Allerdings ist das “iRST/efi/grub2”-Geschäft manchmal auch mit unerwarteten Falltüren versehen:
Irrtümliches Löschen einer gültig beschriebenen EFI-Partition
Ein spezieller Fall ist der, dass man im Zuge einer OS-Installation auf einem neuen Raid-Array die Grub-Informationen nicht auf eine spezifische, neu angelegte EFI-Partition hat schreiben lassen – sondern den Grub-Eintrag auf eine bereits existierenden EFI-Partition (auf einer anderen Platte) anlegen ließ. Löscht man später wiederum irrtümlich diese ursprüngliche EFI-Partition, so geht im Bootprozess natürlich gar nichts mehr.
Mir ist das z.B. passiert, als ich das erste Mal mit einer OS-Installation auf einem SW-Raid experimentierte. Vorher lag die bis dahin gültige EFI-Partition auf einer separaten Platte und blöderweiser habe ich diese vorhandene Partition während der Installation anstelle der neu formatierten EFI-Partitionen auf den SSDs ausgewählt. Später habe ich diese Partition aber irrtümlich gelöscht, da ich ja Partitionen auf den SSDs für EFI vorgesehen hatte – aber nicht mit GRUB-Einträgen versehen hatte. Hat man dann keine weitere Partition mit einem gültigen grub-Eintrag mehr, so führt das ins Boot-Nirwana.
Ähnliches kann auch passieren, wenn parallel auch noch iRST-Container mit einer EFI-Partition vorhanden sind. Hat man die während der Installation eines OS auf neuen SW-Raid-Arrays ausgewählt, und vernichtet anschließend das iRST-Array, so kann man auch nicht mehr booten. Selbst wenn man auf anderen Platten noch gültige Grub-Boot-Einträge haben
sollte, so muss man den SATA-Controller im BIOS zunächst auf den AHCI-Modus umstellen (Storage-Einstellungen), um diese alten gültigen EFI-Boot-Einträge überhaupt finden zu können. Hier wird die iRST-Zwischenschicht offenbar auch mal zum Verhängnis. Ein Grund mehr, von vornherein nicht auf den iRST-Mechanismus zurückzugreifen.
Also: Bevor man Experimente mit der Installation eines Linux OS auf einem iRST-Raid oder auf einem SW-Raid-Array macht, vorab einen gültigen Grub-Boot-Eintrag für ein bereits existierendes Linux OS auf einer anderen Platte erstellen lassen.
Ich lege ach meinen ersten schlechten Erfahrungen vor solchen Experimenten auf irgendeiner unbeteiligten Platte meines Systems immer ein kleines Not-Linux an, dass ich zur Not von einer zugehörigen separaten EFI-Partition booten kann. Diese EFI-Partition rühre ich dann nie mehr ohne Not an. So kommt man wenigstens immer und auch nach Auflösung der experimentell angelegten RAID-Arrays oder Löschung zugehöriger EFI-Partitionen wieder in ein gültiges System. Hinweis: Manchmal muss dazu im EFI-Bootmanager (sprich im UEFI-BIOS die eingetragene Bootreihenfolge ändern).
Ein paar zusammenfassende Ratschläge
Folgende Ratschläge erscheinen mir deshalb bedenkenswert:
- OS-Anlage – wenn möglich – am besten auf einer separaten SSD außerhalb des Raid-Systems.
- Wenn ihr dennoch unbedingt einen Raid-Verbund mit OS auf dem Raid betreibt, so sorgt dafür, dass ihr ein zweites (!) boot- und lauffähiges OS auf einer separaten Platte (außerhalb des Raid-Verbunds) verfügbar habt. Legt auf dieser Platte (außerhalb des Raids) ebenfalls eine funktionierende EFI-Partition an. Schreibt dann vom sekundären OS einen funktionierenden Bootloader-Eintrag in genau diese EFI-Partition.
Kurz gesagt: Sorgt dafür, dass ihr eine gültige EFI-Partition mit gültigen Grub-Einträgen auch außerhalb der am Raid-Array beteiligten Platten habt. Definiert dann die Boot-Prioritäten im BIOS. Viele UEFI-BIOS suchen bei Problemen automatisch die nächste valide efi-Partition. Ansonsten sollte man immer ein gutes Linux-Live-System parat haben. - Vergesst nicht, dass gerade bei SSDs der zunehmende gleichmäßige Verschleiß der Platten im Raid-Verbund die Wahrscheinlichkeit eines parallelen und zeitlich kurz hintereinander getakteten Ausfalls mehrerer Platten erhöht. Macht also von allem regelmäßig Backups. Das erspart einem im Ernstfall viel Ärger.
Ausblick
Ich habe versucht zu verdeutlichen, dass wir mit Grub2 auch auf UEFI-Systemen Linux-Systeme booten können, die auf einem Linux-SW-Raid-Array eingerichtet wurden. Weder aus Gründen der Boot-Unterstützung, noch aus Gründen der Performance (s. die früheren Artikel) ist also ein Rückgriff auf iRST-Technologie erforderlich.
Linux-SW-Raids bieten aber auch noch andere Vorteile – nämlich u.a. eine weitgehenden Flexibilität bei der Anlage verschiedener Raid-Arrays. Das ist das Thema des nächsten Beitrags dieser Serie:
SSD Raid Arrays unter Linux – VI – SW-Raid vs. iRST-Raid – Flexibilität?