Wegen diverser Nachfragen: Hier ein paar kurze Hinweise zur Statusüberprüfung eines 3ware-Raid-Systems unter Linux und Informationen zum Rebuild eines Platten-Arrays, nachdem eine der Platten ausgefallen ist.
Ich beschränke mich nachfolgend auf die Situation eines Raid 1- Verbundes aus 2 gespiegeltem Platten ohne Hot-Swap-Umgebung.
Zunächst ist interessant, wie man überhaupt erkennt, dass ein Problem vorliegt.
Achte bereits beim Booten des Systems auf Störmeldungen
Bzgl. der Statusüberprüfung eines Raid-Systems möchte ich zunächst auf die 3ware BIOS-Meldungen beim Hochfahren eines Systems hinweisen. Dies betrifft vielleicht weniger Server in Dauerbetrieb; es ist aber dennoch ein interessanter Punkt für Arbeitsstationen. Mir ist selbst schon passiert, dass sich mal ein Kabel gelöst hatte und dass eine Platte im Verbund nicht zur Verfügung stand. Merkt man dies bereits beim Hochfahren und bevor neue Daten auf die noch verfügbare Platte des Arrays geschrieben wurden, so umgeht man ein zeitintensives Rebuild des gesamten Systems.
Ein Array wird beim Booten als “Degraded” gemeldet. Was tun ?
Eine Störungsmeldung wird beim Booten rechts neben der Auflistung der vorhandenen 3ware-Raid-Arrays angezeigt.
Ein ausgefallenes und nicht mehr Fault-tolerantes Raid-Array wird in den BIOS-Status-Meldungen es als “Degraded” beschrieben. Die betroffene defekte oder ggf. abgetrennte Platte erhält im Fehlerfall das Attribut “not in use”.
Je nach Bios-Einstellungen stellt der Controller das defekte Array immer noch als “Exportable” für das darauf enthaltene Betriebssystem zur Verfügung. Solange nicht auch die zweite Platte ausfällt, ist das auch kein Problem.
Ist ein Raid-Array nicht in Ordnung, so sollte man als erstes alle Kabelverbindungen prüfen. Gibt sich das Problem dann, so hat man Glück gehabt.
War die Platte jedoch bereits in der vorhergehenden laufenden Sitzung ausgefallen, so ist ein “Rebuild” des Arrays unvermeidbar – weil bereits Daten im nicht gespiegelten Zustand auf die noch verfügbare Platte geschrieben wurden. Die Platten sind dann also in keinem Fall mehr in einem konsistenten Zustand. Geht man mit ‘Alt-3’ in das Bedienungsmenü des Controllers (3ware-Bios-Manger, 3BM), so erhält man auch eine entsprechende Meldung zur Notwendigkeit des “Rebuilds”.
Bei einem “Rebuild” baut der Controller auf einer neu eingebauten Austausch-Platte ( oder auf der alten Platte, falls nur ein Kabeldefekt zum Ausfall führte ) die Spiegelinformationen von Grund auf neu auf – und zwar auf Basis der noch laufenden Platten des Arrays. Das gilt neben Raid 1 auch für Raid5 oder Raid10 – Systeme.
In einem produktiven Umfeld ist es fast unmöglich, sich nach dem Ausfall zuerst um die Ursachen des Plattendefekts im Detail zu kümmern. Ich persönlich nehme in einem solchen Fall lieber gleich eine Austauschplatte, checke und sichere (!) die Kabelverbindungen und untersuche erst im Nachhinein und in Ruhe, ob und welche Schäden die ausgefallene Platte aufweist. Dann kann man immer noch entscheiden, ob man die wieder einsetzen kann und will.
Also, falls kein “Hot-Swap” vorhanden: Rechner runterfahren, Platte austauschen und beim Booten erneut in das 3BM BIOS-Management-Systems des 3ware-Controllers gehen. An den Fehlermeldungen ändert sich durch den Plattenaustausch übrigens nichts. Dann das Rebuild-Verfahren durch Auswahl des Arrays (Pfeiltasten oder Tab-Taste und Enter im 3BM) und Bedienung der entsprechenden Menüpunkte (Button “Maintain Unit” -> “Rebuild”) einleiten. F8 drücken und dann das vorhandene (oder ein anderes; s.u.) Linux-System booten.
Der Rebuild-Vorgang findet nun im Hintergrund des laufenden
Betriebssystems und evtl. über mehrere Stunden hinweg statt. Hierzu erhält man übrigens in den Hinweis-Texten des 3BM Menüs keine Information – der Prozess beeinträchtigt die Systemperformance u.U. in so geringem Maße, dass man davon fast nichts merkt. Das verwirrt Anfänger regelmäßig und man braucht tatsächlich Zusatztools, um etwas über den Status der Restaurierung zu erfahren.
Sicherungen nicht vergessen
Je nach Umgebung und verfügbaren Tools sollte man in die Reparaturarbeiten eine außerplanmäßige Sicherung einplanen. Ist auch die zweite Platte nicht mehr die jüngste, zählt evtl. jede Minute.
Ich habe aus diesem Grund immer zwei gespiegelte Raid-Systeme am Laufen. Auf beiden steht mir jeweils ein bootfähiges Linux-System zur Verfügung. Um die Schreibbelastung während der Restaurierung auf dem defekten Array so gering wie möglich zu halten, boote ich meist das System auf dem anderen Raid-Verbund und führe eine Sicherung der Partitionen des defekten Arrays durch, die ich der Reihe nach mounte. Sicherung und Restaurierung behindern sich gegenseitig – aber ohne Sicherung finde ich das Risiko nach einem Plattenausfall zu hoch.
Hat man nicht den Luxus eines Ersatz-Operativsystems, so meine ich, dass man noch während der Restaurierung mit der Sicherung unverzichtbarer Daten im laufenden System auf externe Medien beginnen sollte. Hierüber kann man sich aber vielleicht streiten.
Statusinformationen zu den 3ware Raid-Systemen im laufenden Betrieb
Spätestens im Fall der Restaurierung eines Raid-Arrays möchte man über den Stand des Rebuilds im laufenden Betrieb informiert werden.
Aber auch sonst liegt es ja nahe, unter Linux immer mal wieder Informationen zu den Raid-Arrays oder Platten anzufragen. (Bzgl. des “Smart”-Tools zur Überwachung des Zustands einzelner Platten an einem 3ware-Controller siehe einen früheren Blogbeitrag.)
Im laufenden Betrieb kann man mit folgenden Tools von 3ware einen Blick auf den Zustand des Raid-Systems werfen:
- tw_cli (Command Line Interface)
- 3DM2 (Daemon mit Java und Browser – Interface)
Beide Tools kann man sich von der 3ware-Website (www.3ware.com) herunterladen und problemlos nach dem Entpacken der Tar-Dateien installieren.
Im Fall von 3DM2 durchläuft man dabei eine Installationsroutine, die die notwendigen Dinge abfragt. Alle notwendigen Informationen zur Installation findet man auf den 3ware Dokumentations-Seiten. Die Tar-Verzeichnisse enthalten zudem umfängliche Info-Dateien im HTML-Format. 3DM2 installiert übrigens auch “tw_cli” mit. Die 3DM2- Installation landet standardmäßig im Verzeichnis “/opt/AMCC“.
Alle Einstellungen von 3DM2 kann man später auch über entsprechende Menüpunkte vornehmen oder verändern.
Zugriff auf 3DM2, Anfangspasswörter und Konfiguration für Benachrichtigungen
Den Zugriff auf die Oberfläche von 3DM2 erhält man bei Standardeinstellungen über einen Browser und die Adresse
https://localhost:888
– also über Port 888.
Hinweis: Die Anfangspasswörter für 3DM2 sind für User und Administrator “3ware”. Die 3DM2 Accounts haben übrigens nichts mit den normalen Linux-User-Accounts zu tun!
Ich habe mir 3DM2 so konfiguriert, dass ich per Mail über Probleme des 3ware-Controllers informiert werde. Dazu beantwortet man am besten schon die entsprechenden Fragen zum entsprechenden Mailserver und zum Mailaccount während der Installation. Später kann man das Benachrichtigungsverhalten unter dem Menüpunkt “3DM2-Settings” einstellen.
So ausgerüstet bekommt man den Ausfall einer Platte in einem Raid-Verbund im laufenden Betrieb automatisch mit.
Informationen
zu den 3ware-Raidsystemen mit tw_cli
Mit tw_cli kann man sich als root praktisch alle Statusinformationen zum Raidverbund anzeigen lassen und Maintenance-Maßnahmen einleiten.
Nach dem Starten von tw_cli landet man an einem eigenen Prompt. Dort lässt man sich zunächst mit “show” die Kurzbezeichnung “cX” des Controllers anzeigen und erhält anschließend mit
“/cX show”, in meinem Fall mit “/c6 show”
mehr Informationen. “X” steht dabei für die Nummer – in meinem Fall eine 6.
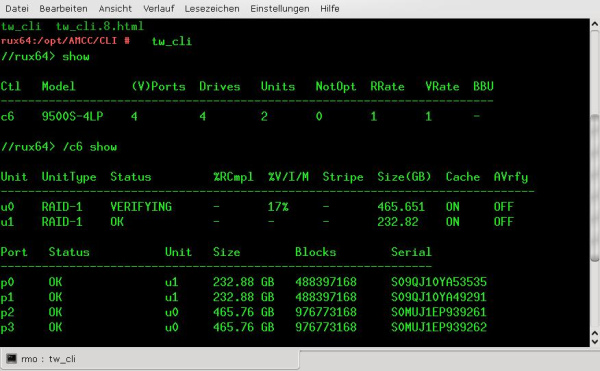
U.a. erhält man hier Informationen zum Status eines “Rebuild-Prozesses”.
Erste Informationen mit 3DM2
Unter 3DM2 sieht die Statusinformation wie folgt aus
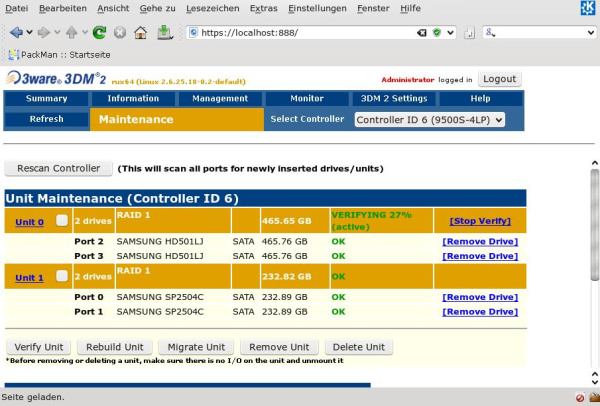
Hier habe ich die Seite “Management->Maintenance” aufgerufen. Man erkennt auch hier den aktuellen Stand eines “Rebuild-Prozesses”.
Für weitere Informationen und mögliche Kommandos zu beiden Tools sei auf die umfängliche Information verwiesen, die unter “/opt/AMCC/Documentation” mit installiert wird.
Plattenausfall im laufenden Betrieb
Das Vorgehen nach einem Plattenausfall im laufenden Betrieb ist übrigens das gleiche wie oben beschrieben: Hat man kein “Hot-Swap” so muss man das System ordentlich herunterfahren, Platte austauschen und den Rebuild nach dem erneuten Booten über 3BM oder die anderen Tools (3DM2 und tw_cli) starten.