Im letzten Artikel dieser kleinen Serie zur Asus Sonar D2X
Asus Xonar D2X unter Linux / Opensuse 13.1 – II
hatte ich festgestellt,
- dass Soundsignale neben der Digital-Analog Umwandlung nicht modifiziert werden und vom User nur hinsichtlich der Kanal-Lautstärke direkt beeinflusst werden können,
- dass die Karte deshalb nur in Grenzen regelbar ist. So fehlen Möglichkeiten zur systemweiten Bass/Höhen-Regelung und die Varianten eines Stereo-Upmix auf mehr als 2 Kanäle sind begrenzt. So kann man über einen entsprechende Schalter nur auf 4.0 oder 6.0 Sound hochmixen. Ein Upmix auf 5.1 oder 7.1 Sound ist jedoch nicht direkt möglich.
- dass ein Regler zur globalen Lautstärkeregelung, der das Lautstärkeverhältnis der Kanäle zueinander nicht verändert, fehlt.
Hinsichtlich der Klangeigenschaften und der Bass/Höhen-Verteilung müssen unter KDE player-spezifische “Equalizer” helfen, wie sie z.B. Clementine und Amarok zur Verfügung stellen (zumindest bei Einsatz des Gstreamer-Backends für Phonon).
Bzgl. eines weitergehenden Stereo-Upmixes und des fehlenden Reglers müssen wir auf die sehr weitgehenden Konfigurationsmöglichkeiten von ALSA zurückgreifen. Dazu brauchen wir kein Pulse-Audio! ALSA erlaubt dabei eine userspezifische Einstellung über eine Datei “~/.asoundrc“.
Upmix von 2.0-Stereo-Sound auf 5.1-Kanal-Sound (oder 7.1-Kanal-Sound) mittels ALSA und einer “~/.asoundrc”-Datei
Ich definiere und erläutere nachfolgend der Reihe nach die erforderlichen Abschnitte einer Datei “~/.asoundrc“, die unsere D2X-Karte dazu bringt, z.B. zusammen mit den Playern Clementine und Amarok unter KDE folgendes zu tun:
- Ergänzung von Kmix um einen Regler zur Lautstärkenänderung über alle Kanäle hinweg, wobei das Lautstärekverhältnis zwischen den Kanälen gleich bleibt.
- Upmix des Outputs von Stereo-Audio-Quellen zu einem 5.1 (bzw. 7.1) Sound.
Ich zeige dabei zunächst nur eine simple, aber wirkungsvolle Methode, die das generische ALSA Device “surround 5.1” und die Asus Sonar D2X als 6 Kanal-Gerät benutzt. Das ist für Leute interessant, die nur 5.1 Lautsprecher-Sets zur Verfügung haben. Aus dem unten Ausgeführten ergibt sich der 7.1-Fall (mittels “surround71”) jedoch ganz zwanglos.
Wer bzgl. ALSA und der “~/.asoundrc”-Datei kein Hintergrundswissen mitbringt, dem seien folgende Artikel empfohlen:
http://www.volkerschatz.com/noise/alsa.html
http://www.alsa-project.org/main/index.php/Asoundrc
Dort findet man einige grundsätzliche Erläuterungen. Für Entwickler erschließen sich danach ein paar Begrifflichkeiten ggf. auch über
http://www.alsa-project.org/alsa-doc/alsa-lib/pcm_plugins.html
Identifiziere die richtige Nummer der Soundkarte
Bevor wir die Datei “~/.asoundr” editieren, benötigen wir ein paar Informationen zu den vom System und ALSA erkannten Soundkarten. Hat man nämlich mehrere Soundkarten installiert, so ist die Nummer der Karte für die weitere ALSA-Konfiguration entscheidend.
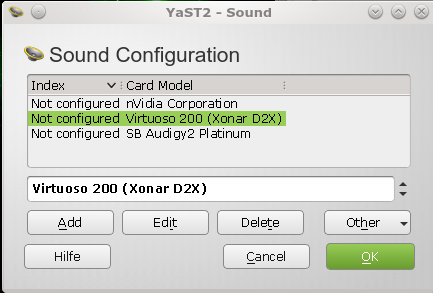
Diesbezügliche Informationen erhalten wir z.B. YaST. Auf ALSA-Ebene geht dies direkter mit Hilfe des Kommandos “aplay -l“. (Hinweis: Das Paket “alsatools” sollte auf dem System installiert sein). Bei mir sieht das Ergebnis dieses Kommandos im Moment so aus:
**** Liste der Hardware-Geräte (PLAYBACK) **** Karte 0: Audigy2 [SB Audigy 2 Platinum [SB0240P]], Gerät 0: emu10k1 [ADC Capture/Standard PCM Playback] Sub-Geräte: 32/32 Sub-Gerät #0: subdevice #0 Sub-Gerät #1: subdevice #1 Sub-Gerät #2: subdevice #2 Sub-Gerät #3: subdevice #3 Sub-Gerät #4: subdevice #4 Sub-Gerät #5: subdevice #5 Sub-Gerät #6: subdevice #6 Sub-Gerät #7: subdevice #7 Sub-Gerät #8: subdevice #8 Sub-Gerät #9: subdevice #9 Sub-Gerät #10: subdevice #10 Sub-Gerät #11: subdevice #11 Sub-Gerät #12: subdevice #12 Sub-Gerät #13: subdevice #13 Sub-Gerät #14: subdevice #14 Sub-Gerät #15: subdevice #15 Sub-Gerät #16: subdevice #16 Sub-Gerät #17: subdevice #17 Sub-Gerät #18: subdevice #18 Sub-Gerät #19: subdevice #19 Sub-Gerät #20: subdevice #20 Sub-Gerät #21: subdevice #21 Sub-Gerät #22: subdevice #22 Sub-Gerät #23: subdevice #23 Sub-Gerät #24: subdevice #24 Sub-Gerät #25: subdevice #25 Sub-Gerät #26: subdevice #26 Sub-Gerät #27: subdevice #27 Sub-Gerät #28: subdevice #28 Sub-Gerät #29: subdevice #29 Sub-Gerät #30: subdevice #30 Sub-Gerät #31: subdevice #31 Karte 0: Audigy2 [SB Audigy 2 Platinum [SB0240P]], Gerät 2: emu10k1 efx [Multichannel Capture/PT Playback] Sub-Geräte: 8/8 Sub-Gerät #0: subdevice #0 Sub-Gerät #1: subdevice #1 Sub-Gerät #2: subdevice #2 Sub-Gerät #3: subdevice #3 Sub-Gerät #4: subdevice #4 Sub-Gerät #5: subdevice #5 Sub-Gerät #6: subdevice #6 Sub-Gerät #7: subdevice #7 Karte 0: Audigy2 [SB Audigy 2 Platinum [SB0240P]], Gerät 3: emu10k1 [Multichannel Playback] Sub-Geräte: 1/1 Sub-Gerät #0: subdevice #0 Karte 0: Audigy2 [SB Audigy 2 Platinum [SB0240P]], Gerät 4: p16v [p16v] Sub-Geräte: 1/1 Sub-Gerät #0: subdevice #0 Karte 1: D2X [Xonar D2X], Gerät 0: Multichannel [Multichannel] Sub-Geräte: 0/1 Sub-Gerät #0: subdevice #0 Karte 1: D2X [Xonar D2X], Gerät 1: Digital [Digital] Sub-Geräte: 1/1 Sub-Gerät #0: subdevice #0 Karte 2: NVidia [HDA NVidia], Gerät 3: HDMI 0 [HDMI 0] Sub-Geräte: 1/1 Sub-Gerät #0: subdevice #0 Karte 2: NVidia [HDA NVidia], Gerät 7: HDMI 1 [HDMI 1] Sub-Geräte: 1/1 Sub-Gerät #0: subdevice #0 Karte 2: NVidia [HDA NVidia], Gerät 8: HDMI 2 [HDMI 2] Sub-Geräte: 1/1 Sub-Gerät #0: subdevice #0 Karte 2: NVidia [HDA NVidia], Gerät 9: HDMI 3 [HDMI 3] Sub-Geräte: 1/1 Sub-Gerät #0: subdevice #0
Hier sieht man, dass die D2X als Karte 1 erkannt wurde. Weitere Geräte sind eine alte, liebgewonnene Audigy 2 und eine Onboard-Karte. Man erkennt ferner, dass jede Karte (im Besonderen abwer die Audigy-Karte) eine Reihe untergeordneter Geräte mit weiteren “Sub Devices” beherbergen. Die D2X erscheint mit ihren 2 “Geräten” unter Linux eher als eine sehr schlanke Karte.
Auf einem System mit genau nur einer Soundkarte wäre die Soundkarten-Nummer im Gegensatz zum obigen Befund “0” gewesen.
Weitere Kommandos, die die Reihenfolge der Karten unter einem Linux-System und zugehörige Module anzeigen, sind:
cat /proc/asound/cards
mytux:~ # cat /proc/asound/cards
0 [D2X ]: AV200 - Xonar D2X
Asus Virtuoso 200 at 0x7e00, irq 16
1 [Audigy2 ]: Audigy2 - SB Audigy 2 Platinum [SB0240P]
SB Audigy 2 Platinum [SB0240P] (rev.4, serial:0x10021102) at 0x8f00, irq 16
2 [NVidia ]: HDA-Intel - HDA NVidia
HDA NVidia at 0xfaffc000 irq 17
cat /proc/asound/modules
mytux:~ # cat /proc/asound/modules 0 snd_virtuoso 1 snd_emu10k1 2 snd_hda_intel
An letzterer Ausgabe erkennt man übrigens auch, dass das für die Asus Xonar D2X geladene Kernelmodul den Namen “snd_virtuoso” trägt. Dieser Befund ist natürlich
konsistent zu der von uns in
Asus Xonar D2X unter Linux / Opensuse 13.1 – II
per YaST vorgenommenen Sound-Karten-Konfiguration.
Bei Bedarf die Reihenfolge der Soundkarten ändern
Dass die eigentlich bevorzugte Xonar D2X-Karte in meinem System nicht als Karte “0” definiert ist, mag dem einen oder anderen Leser suspekt vorkommen. Nicht ganz zu Unrecht:
Bei dem heutigen Mischmasch aus Phonon, einer definierten Reihenfolge aus Phonon-Devices, diversen Phonon-Backends, Resten von Pulse-Audio und ALSA kann die eine oder andere KDE- oder Gnome-Applikation von sich aus schon mal als Default die Karte “0” (oder untergeordnete Geräte) ansprechen; dann müssen da natürlich auch Lautsprecher angeschlossen sein, damit man überhaupt was zu hören bekommt.
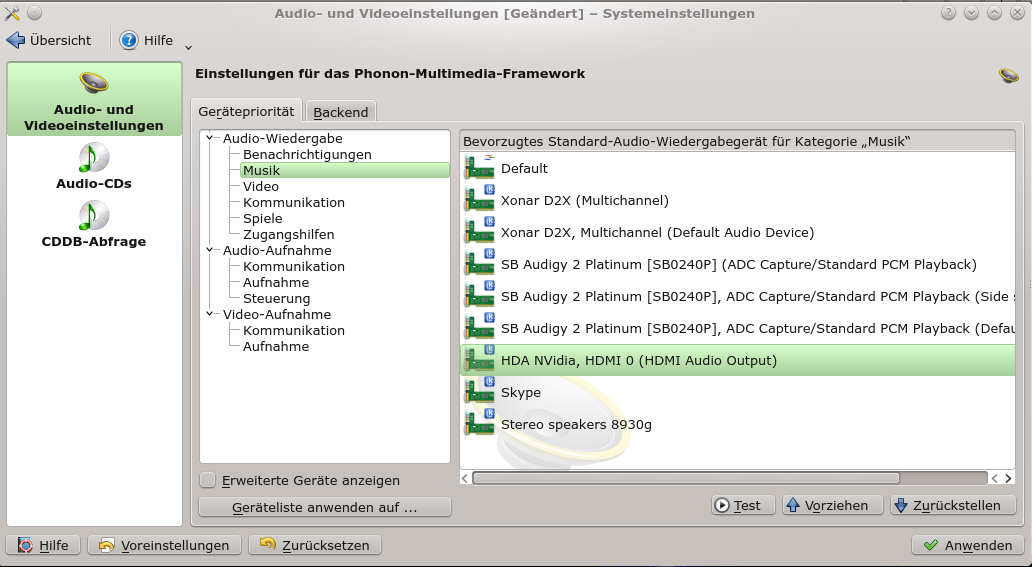
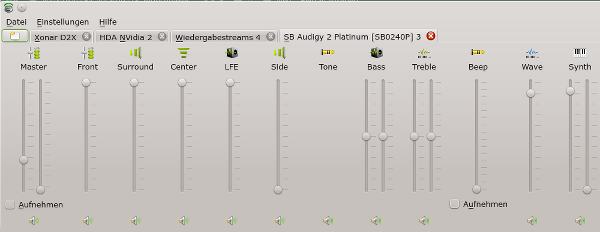
Hinzu kommt ein seltsamer Mix aus erkannten reinen ALSA-Devices (mit kleinem ALSA-Logo) und Phonon/KDE-Devices (versehen mit einem kleinen KDE-Logo) in den KDE-weiten “Multimedia (= Phonon)-Einstellungen (s. die Abbildung weiter unten). Auch wenn man die Reihenfolge der bevorzugten Devices dort so definiert, das die ALSA-Devices ganz oben stehen, wird das nicht zwingend von jeder Applikation beachtet. Manche Applikationen erlauben zudem eine spezifische eigene Auswahl des Sound-Gerätes. Wer nicht an jeder Soundkarte Lautsprecher angeschlossen hat und auf Probleme mit Applikationen stößt, der möge die D2X zur Sicherheit also als Karte “0” definieren und die weiter unten folgenden HW-Angaben in der “~/.asoundrc” entsprechend anpassen.
Leicht gesagt – aber wie ändert man eigentlich die Reihenfolge der erkannten Soundkarten im System?
Unter Opensuse kann die Reihenfolge der Karten am einfachsten mit “YaST >> Sound” beeinflusst werden. Unter anderen Systemen ist es u.U. etwas schwieriger. Letztlich läuft die Sache auf Einstellungen in einer sound-spezifischen Datei unter dem Verzeichnis “/etc/modprobe.d/” hinaus. Übersichtliche Hinweise zu Ubuntu findet man hier:
http://wiki.ubuntuusers.de/Soundkarten_konfigurieren
Siehe dort den Abschnitt “Reihenfolge (Priorität) von Soundkarten Ändern”. Die dort beschriebenen Einstellungen gelten vermutlich auch für andere Debian-basierte Systeme; sie verdeutlichen in jedem Fall das Prinzip.
Unter Opensuse 13.1 heißt die zu modifizierende Datei dagegen “/etc/modprobe.d/50-sound.conf”. Sie sieht in meinem Fall so aus:
options snd slots=snd-emu10k1,snd-virtuoso # Cw4d.j3r564qQSgF:Virtuoso 200 (Xonar D2X) alias snd-card-1 snd-virtuoso # cuhJ.vIcU+IM+7DC:SB Audigy2 Platinum alias snd-card-0 snd-emu10k1
Für eine Reihenfolge, bei der die D2X an erster Stelle kommt, müsste der Inhalt wie folgt abgeändert werden:
options snd slots=snd-virtuoso,snd-emu10k1 # cuhJ.vIcU+IM+7DC:SB Audigy2 Platinum alias snd-card-1 snd-emu10k1 # Cw4d.j3r564qQSgF:Virtuoso 200 (Xonar D2X) alias snd-card-0 snd-virtuoso
Nach einem Reboot ist dann die in dieser Datei definierte Reihenfolge gültig. Nebenbei: Die seltsamen Buchstaben-Zahlen-Kombinationen für die Karten stammen aus “udev” und dort hinterlegten Infos.
Beziehung der Soundkarten-Nummer zu ALSA-Definitionen
Wie die Nummer der Karte und ihrer Subdevices in ALSA-Kennungen eingehen, die in einer “.asoundrc” verwendet werden können, erfährt man hier
http://www.alsa-project.org/main/index.php/Asoundrc
In diesem Artikel kann man auch nachlesen, was sog. “Plugin” PCM Devices sind. Derartige PCM Devices (vom Type “plug”) werden wir weiter unten in einer hierarchischen Abfolge definieren und miteinander kombinieren. Vereinfacht gilt:
PCM Devices (bestimmter verschiedener Typen, u.a. “plug”) können sich unter ALSA jeweils ein sogenanntes “Slave Device” zunutze machen und den Sound an dieses Device gemäß vorgegebener Einstellungen weiterleiten. Das Ganze kann über mehrere Ebenen hinweg erfolgen.
Definition eines Full Duplex Devices als Ziel des Upmixes
Wir beginnen nun mit dem Editieren der Datei ~/.asoundrc. In einem ersten Abschnitt legen wir ein Full Duplex Device (Plugin) namens “dmix51” fest, das wir mit unser Hardware verknüpfen. Zu “Full Duplex” siehe z.B.:
http://www.ehow.com/how_7763496_check-sound-card-fullduplex.html.
Der Typ (= “type”), den man bei der Konfiguration eines solchen Full-Duplex-Devices angeben muss, ist “asym”. Siehe http://alsa.opensrc.org/Asym. Plugins vom Typ “asym” bestehen aus zwei Komponenten, die definiert werden müssen – einer “playback”– und einer “capture”-Komponente. Am wichtigsten für unsere Zwecke ist im Moment die “playback”-Komponente. Zu dieser legen wir diverse Eigenschaften fest, während wir bei der “capture”-Komponente lediglich auf die vorhandene Hardware verweisen.
Das “playback”-Plugin ist wiederum vom Typ “dmix”. Siehe hierzu:
http://alsa.opensrc.org/Dmix.
Wichtig ist, dass ALSA für solche definierten Devices mehrere Soundstreams aus unterschiedlichen Quellen direkt miteinander mixen, also störungsfrei überlagern kann. Dafür braucht man Pulseaudio überhaupt nicht. So ist es dann z.B. möglich, parallel Sound von Clementine und von Amarok oder anderen Quellen abspielen zu lassen. Unter Kmix lassen sich diese Quellen dann zudem gegeneinander von der Lautstärke her abmischen.
Sog. “ipc”-Daten regeln die Zugriffsmöglichkeiten. Siehe hierzu: http://www.alsa-project.org/alsa-doc/alsa-lib/pcm_plugins.html und dort den Abschnitt zu “dmix”.
pcm.dmix51 {
type asym
playback.pcm {
type dmix
ipc_key 6789123
ipc_perm 0660
ipc_gid audio
slave {
# 6 channels entsprechen surround51, 8 surround71
channels 6
pcm {
#format S32_LE
format S16_LE
#rate 44100
rate 48000
type hw
card 1
device 0
subdevice 0
}
period_size 1024
buffer_size 16384
}
}
capture.pcm "hw:1"
}
ctl.dmix51 {
type hw
card 1
}
Der Name “dmix51” ist willkürlich gewählt und deutet an, dass wir hier 6 Kanäle voraussetzen und nutzen wollen. Festgelegt wird Letzteres über das “channels”-Statement im inkludierten “slave” :
channels 6
Schließt man eine 7.1-Anlage an die Xonar D2X an, so nutzt man natürlich ein analog definiertes Device “dmix71” mit “channels 8”. Eine Darstellung des länglichen Codes für ein “dmix71” hierfür habe ich mir aus Platz- und Wiederholungsgründen erspart.
Innerhalb der “playback”-Komponente wird ein Slave PCM Device vom Typ “hw” (Hardware) definiert. Bzgl. der angegebenen Alternativen zu den Sampling-Parametern für die gemixten Streams und auch zum Buffering muss man ein wenig experimentieren – u.a. um stockenden Sound oder “Crackling” zu vermeiden. Siehe etwa die Kommentare in einer analogen Definition in
https://dl.dropboxusercontent.com/u/18371907/asoundrc.
Die Definition des Control Devices “ctl.dmix51” am Ende haben wir zur Sicherheit vorgenommen. Programme wie “Jack” benötigen diese Festlegung gegebenenfalls.
Ok,
nun haben wir ein “dmix”-PCM Device, das auf unsere Karte verweist und das in der Lage ist, eingehende Streams aus unterschiedlichen Quellen zu einem Stream zu resamplen.
Kette aus Default und Slave-Devices in der “~/.asoundrc”
Applikationen wie Clementine nutzen ohne weitere detaillierte Konfiguration ein ALSA Default Device. Amarok wertet zudem die KDE-Einstellungen zum Phonon Standard Device aus. Das von uns nun vorgegebene ALSA Default Device sollte nach Abwickeln einer Kette von hierarchischen Slave Device Definitionen letztich zu dem vorgesehenen HW-Device führen. Dies erreichen wir nachfolgend, indem wir die Slave-Kette am Ende zu unserem bereits definierten “dmix51” PCM Device führen.
pcm.!default {
type softvol
slave.pcm "simple51"
# slave.pcm "simple71"
# slave.pcm "ctrl51"
control {
name "SW master"
card 1
}
hint {
show on
description "ALSA_DEFAULT"
}
}
# speaker-test -D simple51 -c 2 -t wav
pcm.simple51 {
type plug
slave.pcm "surround51"
slave.channels 6
route_policy duplicate
}
pcm.simple71 {
type plug
slave.pcm "surround71"
slave.channels 8
route_policy duplicate
}
pcm.!surround20 {
type plug
slave.pcm "dmix51"
# slave.pcm "dmix71"
}
pcm.!surround40 {
type plug
slave.pcm "dmix51"
# slave.pcm "dmix71"
}
pcm.!surround51 {
type plug
slave.pcm "dmix51"
# slave.pcm "dmix71"
}
pcm.!surround71 {
type plug
slave.pcm "dmix71"
}
# speaker-test -D ctrl51 -c 2 -t wav
pcm.ctrl51 {
type plug
slave.pcm "surround51"
slave.channels 6
type route
ttable.0.0 1
ttable.1.1 1
ttable.0.2 1
ttable.1.3 1
ttable.0.4 0.5
ttable.1.4 0.5
ttable.0.5 0.5
ttable.1.5 0.5
}
pcm.wine {
type plug
# Output directly, for performance
#slave.pcm "hw:0"
slave.pcm "surround20"
}
Hinweis: “#” leitet einen Kommentar ein.
Was passiert hier ? Zunächst gilt:
- “surround51” ist eines der generischen ALSA Devices – siehe http://alsa.opensrc.org/SurroundSound.
- Das Ausrufezeichen vor den PCM Plugin-Namen leitet eine neue Device Definition mit (ggf.) Parameterüberschreibung ein. Siehe http://www.volkerschatz.com/noise/alsa.html und dort den Abschnitt über “Advanced configuration file features”.
Mit diesem Wissen ausgestattet, besprechen wir nun einzelne Abschnitte.
Definition des Default Devices als “softvol” Device mit kanalübergreifendem Lautstärkeregler
Wir definieren im ersten Block also das PCM Standard (=Default) Device “pcm.!default” neu und zwar so, dass es offenbar vom Typ “softvol” sein soll. Letzteres bedeutet, dass ein “volume”-Regler (also Lautstärkeregler) auf SW-Basis eingeführt und einer HW-Einheit zugeordnet wird. Siehe hierzu: http://alsa.opensrc.org/Softvol.
Der über “control” für unsere Soundkarte 1 definierte Regler steht dann z.B. in Mixer-GUIs wie “kmix” oder “alsamix” als verwendbarer Regler zur Verfügung. Warum wollen wir einen solchen Regler? Weil die Kanal-Splittung des Standard-Master-Reglers der D2X alle Kanäle auf das gleiche Volumen hebt, sobald er betätigt wird. Wir möchten aber einen (zusätzlichen) Regler, der nach einem Split des Master auf einzelnen Kanäle das relative Lautstärkeverhältnis der Kanäle zueinander aufrecht erhält. Genau dies wird der von uns definierte Regler leisten. Wir haben ihn deshalb als “SW Master” bezeichnet.
Unser “pcm.!default”-
Device bindet aber auch ein Slave Device vom Typ “plug” ein, nämlich “pcm.simple51”, dessen Eigenschaften wir in einem weiteren, entsprechenden Abschnitt definiert haben. Will man eine 7.1-Konfiguration, so ist die Zeile
slave.pcm “simple51”
auszukommentieren und durch die im Moment kommentierte Zeile mit
slave.pcm “simple71”
zu ersetzen.
Upmix über ein zwischengeschobenes Plugin, das Stereo-Eingangskanäle nach Upmix an das generische Device “surround51” bzw. “surround71” weiterleitet
Das PCM Device “simple51” benutzt als Slave das (redefinierte) “Surround51”-Plugin und gibt dafür vor,
- dass 6 Kanäle benutzt werden sollen und
- dass eine Kanal-Duplikation vorgenommen werden soll.
Letzteres drückt sich in dem “route_policy”-Statement aus:
route_policy duplicate
Hinweise zur Bedeutung des Parameters “route_policy” und den verschiedenen dafür vergebbaren Werten findet man in http://alsa.opensrc.org/Asoundrc (Abschnitt “Plugins”).
Die Einstellung “duplicate” führt zu einer automatischen Generierung von sog. “ttable”-Einstellungen, die den Upmix der ersten beiden Kanäle auf alle folgenden in einer einfachen, vordefinierten Lautstärkebalance vornehmen.
“ttable”-Vorgaben legen fest, welcher vorhandene Kanal durch ALSA in welcher Form (z.B. mit welcher Lautstärke) auf einen anderen Kanal abgebildet werden soll. Wie man die “ttable”-Einstellungen in der “~/.asoundrc” bei Bedarf explizit ändern kann, beschreibe ich kurz weiter unten. Zwingend ist eine eigene “ttable”-Abmischung über die “.asoundrc” aber nicht erforderlich, da wir ja zum relativen Lautstärke-Mix der D2X-Kanäle auch unsere Regler unter Kmix (oder einer anderen Mixer-GUI) zur Verfügung haben.
Im 7.1 Fall hätte unser “pcm.!default” in natürlich analoger Weise auf das angegebene “pcm.simple71” verwiesen und Letzteres wiederum auf das ebenfalls angegebene “pcm.!surround71”.
Redefinition des generischen “surround51”- bzw. “surround71” Devices
Wohin verweist dann das redefinierte “surround51”-Plugin? Natürlich auf unser “dmix51” Device, das an unsere Soundkarte gebunden wurde und 6 Kanäle bereitstellt. (Im 7.1-Fall verweist “pcm.!surround71” natürlich auf ein vorzudefinierendes “dmix71”).
Insgesamt hat unsere “~/.asoundrc” also folgende Device-Kette etabliert:
pcm!default => pcm.simple51 (Upmix) => pcm.!surround51 => pcm.dmix51
Siehe zum hier gewählten Vorgehen für den Default-Upmix auch :
http://forums.bodhilinux.com/index.php?/topic/2493-how-to-51-surround-sound-with-alsa/
http://www.gentoo-wiki.info/HOWTO_Surround_Sound
https://wiki.archlinux.org/index.php/Advanced_Linux_Sound_Architecture/Example_Configurations
Warum ein zwischengeschobenes Plugin “pcm.simple51” bzw. “pcm.simple71” für den Upmix?
Der aufmerksame Leser wird fragen, warum das Plugin “simple51” (bzw. “simple71”) überhaupt dazwischen geschoben werden muss. Der einfache Grund dafür ist, dass wir unser 6 Kanal-“dmix51”-Gerät (bzw. unser 8 Kanal “dmix71 Gerät) ja auch ohne Upmix von expliziten Mehrkanal-Sound-Quellen unseres PCs nutzen lassen wollen, für die gar kein 2.0=>5.1 Upmix nötig ist und die von Haus aus z.B. das generische “surround51”-Device ansprechen. Beispiel hierfür
wären etwa Video-Player.
Insgesamt fangen die Redefinitionen von “surround20”, “surround40” und eben “surround51” den Upmix ab. Wird eines dieser generischen ALSA-Geräte explizit von einem Player angesprochen, wird es direkt an “dmix51” weitergereicht. (Für 7.1 kommentiert man jeweils die “dmix51”-Zeile und unkommentiert die jeweilige “dmix71”-Zeile).
Nun kommt als Nächstes natürlich die Frage, warum ich die generischen “surround40” und “surround20” nicht auf 5.1 (bzw. 7.1) hochmixe. Gute Frage! Ich lasse das in der Regel bleiben, weil ich dadurch beim Hören direkt erfahre, welche Sound-Applikation die genannten generischen Geräte explizit (also anstelle des ALSA-Default-Devices) anspricht. Ein “40=>51”-Upmix erfordert außerdem spezifischere “ttable”-Einstellungen. “surround40” kommt ferner so gut wie nie vor. Der geneigte Leser kann ja aber bei Lust und Laune zumindest schon mal “surround20” auf “simple51” (bzw. “simple71”) umlenken!
Einstellen des ALSA Default Devices als Phonon Default Device für geeignete Sound-Quellen unter KDE
Bleibt noch ein wichtiger Schritt. Wer hat denn festgelegt, dass KDE oder KDE-Anwendungen – z.B. für Musik – überhaupt das ALSA Default Device nutzen sollen? Bislang niemand ! Deshalb müssen wir das ALSA Default Device explizit an die Spitze der von Phonon erkannten Devices für “Audio=>Musik”-Quellen zu stellen. Dies geschieht über die KDE Systemeinstellungen (aufrufbar über das Kommando “systemsettings”) und dort unter “Hardware=> Multimedia”.
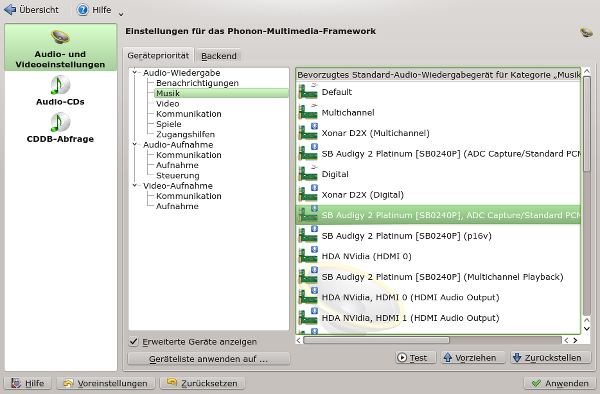
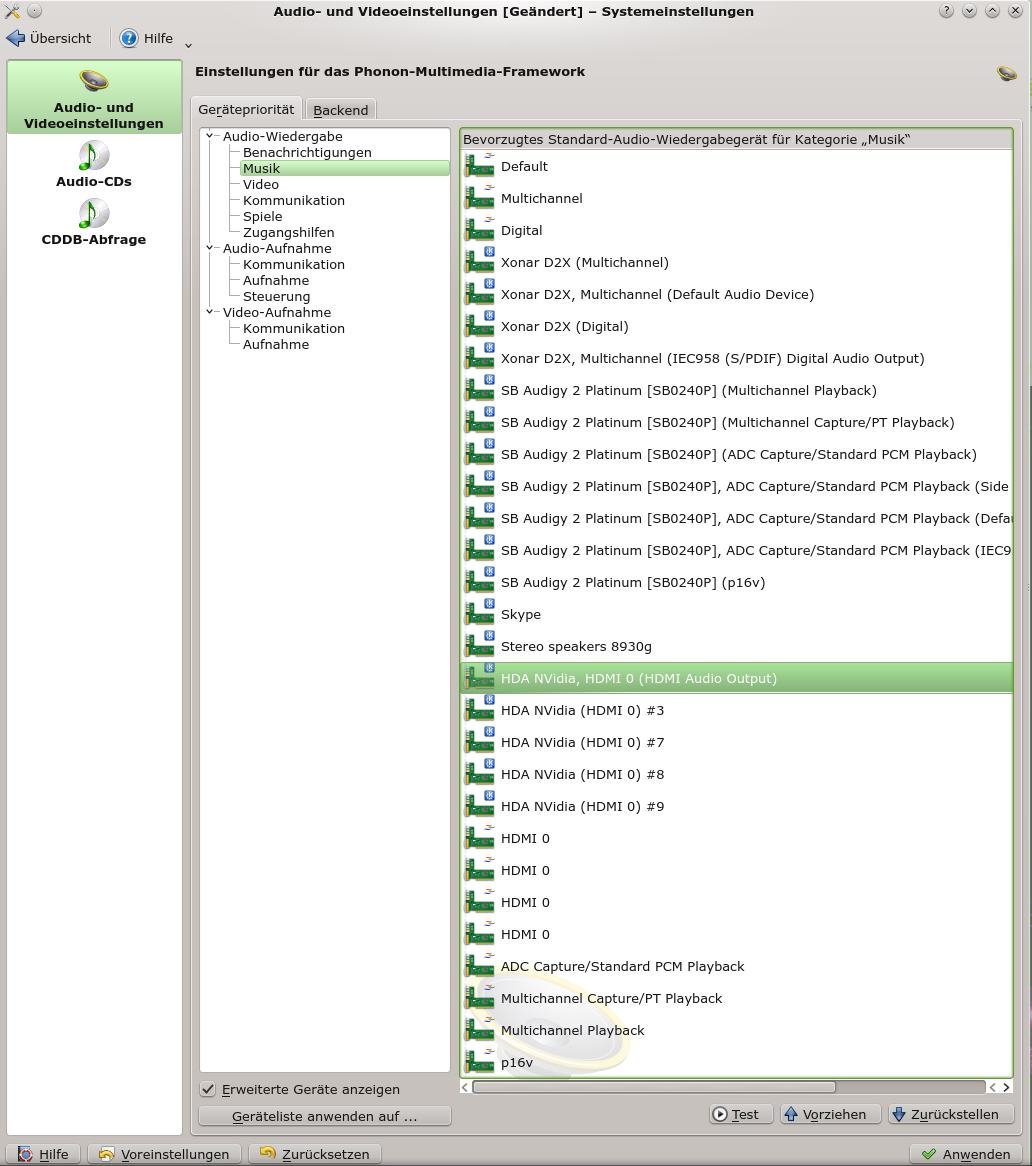
Ergänzung 20.12.2014: Anzeige der ALSA PCM Devices in den Phonon-Einstellungen von KDE
Nachdem ich auf einem meiner Systeme testweise Opensuse 13.2 musste ich feststellen, dass immer weniger erkannte Alsa Devices unter Phonon angezeigt werden. Das bringt uns zu der Frage, wie man eigentlich die in der “~/.asoundrc” definierten PCM Devices in Phonon zur Anzeige bringt. Dies funktioniert für unser redefiniertes Default Device z.B. über die Ergänzung
hint {
show on
description "ALSA_DEFAULT"
}
innerhalb des Definitionsbereichs. Siehe oben. Ich habe den Abschnitt für “pcm.!default” ergänzt. Die “hint”-Ergänzung scheint ein allgemeiner Mechanismus zu sein. Er funktioniert nach ersten Tests z.B. auch für “pcm.simple51”. Das kann jeder Leser mal selbst ausprobieren.
Den Hinweis auf “hint” habe ich (gut versteckt) in einem der Abschnitte von
https://intern.radiotux.de/Dmix
gefunden. Siehe auch
http://wiki.ubuntuusers.de/.asoundrc
In beiden Fällen nach “phonon” suchen.
Findet man also aus irgendwelchen Gründen das Alsa Default Device nicht unter den Phonon-Geräten, dei unter den KDE Multimedia-Einstellungen gezeigt werden, so kann man eine Anzeige unseres selbst definierten PCM Devices über “hint” veranlassen, dann in den Phonon-Einstellungen testen und in der Priorität ganz nach oben schieben.
Ähnliche Einstellungen für das von Phonon zu priorisierende Gerät nimmt man für die Punkte “Benachrichtigungen”, “Kommunikation” und “Zugangshilfen” vor.
Für “Audio=>Video”- Quellen wird man dagegen direkt eines der erkannten Multichannel-Geräte auswählen. Da wir u.a. das “surround71” Device nicht umgelenkt haben, können wir (bei entsprechender Anzahl an angeschlossenen Lautsprechern) dann auch vollen 7.1-Kanal-Sound erhalten. Bei Spielen wird man normalerweise auch ein Multichannel-Gerät und nicht das “ALSA-Default Device” verwenden. Für Spiele mit reinem Stereo kann man ja bei Bedarf umschalten.
Bezieht man Phonon mit ein, so sieht unsere
eigentliche Geräte-Kette also wie folgt aus:
KDE => Phonon => Musik => ALSA Default Device => Redefiniertes ALSA Default Device per ~/.asoundrc == pcm!default => pcm.simple51 (Upmix) => pcm.!surround51 => pcm.dmix51 => D2X, genutzt als 6-Kanal-Gerät
Eigentlich gar nicht so komplex. Phonon gibt uns an dieser Stelle einfach weitere Freiheitsgrade.
Damit unsere Einstellungen in der “~/.asoundrc” nun in Gänze wirksam werden müssen wir uns von KDE abmelden und uns danach wieder einloggen. Ein Reboot (oder einfacher ein Neustart des Soundsystems) ist nur nötig, wenn wir die Reihenfolge von Soundkarten vertauscht haben sollten.
Resultierende erweiterte Darstellung unter Kmix
Haben wir alles richtig gemacht, so ergibt sich etwa folgendes Bild unter Kmix :

Der rechte Bereich der Mixer-GUI wurde abgeschnitten. Man erkennt unschwer unseren SW-Lautstärkeregler “SW Master”, der nun kanalübergreifend funktioniert.
Wir testen das Ganze etwa mit Clementine und spielen ein paar Soundtracks ab. Unter “Werkzeuge >> Einstellungen >> Wiedergabe” sollte als Ausgabe-Plugin “Audio sink (ALSA)” festgelegt sein:

Leider erfolgte in meinem Fall die globale Lautstärke-Regelung über den rechten der 2 zu “SW Master” angebotenen Regler, der eigentlich für Aufnahmen gedacht ist. Ich habe noch nicht herausgefunden, wie ich das switchen kann – aber man muss es ja nur wissen.
Man kann nun über “Einstellungen > Hauptkanal auswählen” unseren Regler “SW Master” auswählen. Er wird dann künftig angezeigt, wenn wir auf das “Kmix”-Symbol im Systemsteuerungsabschnitt der KDE-Kontroll-Leiste klicken:

Damit ist (zumindest für das ALSA Default Device eines unserer Ziele für eine bessere Nutzung der Xonar D2X – nämlich die kanalübergreifende Lautstärkeregelung – erreicht.
5.1 Surround Sound und Verkabelung – ein Hinweis
Meine Standard-Lautsprecheranlage am Arbeitsplatz ist von Creative und hat ein 5.1-Anschluss-Kabel für die Soundkarte. Am Anlagenanschluss wird jedoch auch ein Kabel für die Side-Kanäle abgeführt; das System ist intern 7.1-Upmix-fähig. Ein wenig schwachsinnig; aber sehr günstig erstanden 🙂 .
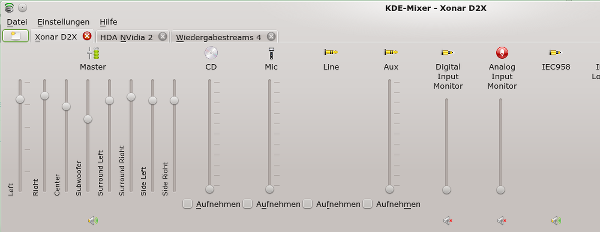
Ich weiss nicht, ob es an dieser seltsamen Kombination liegt, aber die Regelung der 5.1-Kanäle funktioniert nur dann richtig, wenn man die Kabel bei Draufsicht in folgender Reihenfolge in die Analog-Ausgänge der D2X steckt – dabei blicke ich von hinten auf die Karte :
- Grün (Creative-Front) – auf grünen Ausgang der Karte (D2X – Front)
- Schwarz (Creative-Rear) – auf den orangen Ausgang der Karte (D2X-Side)
- Orange (Creative-Center/Subwoofer) – auf den weißen Ausgang der Karte (D2X – Center/Subwoofer)
Das Stecken des schwarzen Kables ist nicht konsistent zur D2X-Beschreibung – funktioniert aber mit den angegebenen Einstellungen in der “~/.asoundrc”. Hier ist die Kanalnummerierung des ALSA-Treibers wohl etwas neben der Intention von Asus. Oder die im Internet verfügbare Beschreibung zur D2X stimmt nicht. Na ja, stört
mich nicht.
Sollte jemand mit einer 5.1-Anlage an der D2X-Probleme mit den Lautsprechern und/oder deren Regelung haben, so sollte er in jedem Fall mal die angegebene Stecker-Reihenfolge ausprobieren.
Übrigens: Bei einem 7.1-Upmix und einem physikalischen 5.1-Abgriff relativiert sich das Ganze dann sowieso.
Ich habe den Befund aber als Hinweis darauf genommen, dass es beim Ansehen von Filmen mit Surround Sound wichtig sein kann, die Lautsprecher-Reihenfolge zu prüfen. Hierzu dann bitte das Progrämmchen “speaker-test” einsetzen. Für 5.1 und unseren einfachen Upmix über “surround51” in der Form:
speaker-test -c 6 -D surround51 -t wav
Natürlich kann man mit
speaker-test -c 6 -D simple51 -t wav
auch unser “simple51” PCM testen.
Ein paar Worte zum Kopfhörer-Anschluss
Es gibt ja bei der D2X keine Möglichkeit, einen Ausgang auf das Frontpanel des PCs zu legen. Kopfhörer muss man also normalerweise (zumindest ohne Elektronik-Bastelei) hinten an der Karte an den Stereo-Ausgang (grün) legen.
Ich habe Gott sei Dank am flexiblen Lautstärkeregler der Lautsprecher-Anlage auch einen Kopfhörerausgang, so dass ich den Kopfhörer nicht hinten in einen der analogen Ausgänge der Karte selbst einstöpseln muss.
Aber auch dem, der das nicht haben sollte, hilft ggf. unser ALSA-Upmix: Bei einem 7.1-Upmix per ALSA und einem physikalischen 5.1-Abgriff wäre auch noch ein Ausgang frei, den man für die Kopfhörer benutzen könnte – auch permanent. Für diesen Ausgang muss man dann aber die Lautstärken-Regelung im Griff haben. Also nach Kopfhörer-Benutzung zur Sicherheit auf 0 stellen.
Direkte Beeinflussung der Signalstärke bei der Kanalzuordnung im Upmix durch ttable-Anweisungen
Der aufmerksame Leser wird sich gewundert haben, dass das oben angegebene PCM Device “pcm.ctrl51” unerwähnt blieb. Ich gehe darauf kurz ein. Um “pcm.ctrl51” zu nutzen, muss man “simple51” als Slave in der “pcm.!default”-Definition auskommentieren und den Kommentar aus der Zeile mit
slave.pcm “ctrl51”
entfernen.
Der Abschnitt zu “pcm.ctrl51” enthält den bekannten Slave “surround51” und explizite “ttable”-Definitionen. Wie z.B.:
#front
ttable.0.0 1.0
ttable.1.1 1.0
#rear left
ttable.0.2 1.0
#rear right
ttable.1.3 1.0
#center
ttable.0.4 0.5
ttable.1.4 0.5
#bass
ttable.0.5 0.2
ttable.1.5 0.2
Man erkennt, wie die die Input-Kanäle “0” und “1” (links auf den ersten Punkt in jeder Zeile folgend) auf die 6 Output-Kanäle “0” bis “5” des Slaves verteilt werden. Die Werte ganz rechts in jeder ttable-Zeile geben (lineare elektronische) Signalstärkenverhältnisse an, die der User nun selbst anpassen kann, statt sich auf die “route_policy” von “simple51” zu verlassen. Die weitere Lautstärke-Regelung jedes Kanals auf diesem Grundmix durch die Regler von Kmix bleibt natürlich unbenommen.
Weitere Informationen hierzu findet ihr unter
http://drona.csa.iisc.ernet.in/~uday/alsamch.shtml
Analoge Einstellungen für einen 7.1-Upmix sollten für den Leser kein Problem mehr darstellen.
Viel Spaß nun mit der Nutzung der Xonar D2X, der vereinfachten, kanalübergreifenden Lautstärke-Regelung und dem vorgenommenen 2.0=>5.1 bzw. 2.0=>7.1 “Surround”-Upmix!
Wenn ich Zeit finden sollte, gehe ich einem weiteren Artikel auf weitere Einstellungen zum Upmix und ggf. auch auf die Einbindung von “alsaequ” ein. Wird aber mit Sicherheit ein wenig dauern …