
Ein neues Test-System bietet eine gute Gelegenheit, neue Technologie unter Linux auszuprobieren. In diesem Fall einen SSD-Raid-Verbund. So etwas mache ich natürlich nicht nur zum Vergnügen. Mein eigentliches Ziel ist es, Berechnungen eines Kunden, die auf Daten einer oder mehrerer MySQL-Datenbanken mit Tabellen mit bis 20 Millionen Datensätzen zurückgreifen, für die HW eines kleineren Standalone-Servers zu optimieren. Dabei sollen die Raid-Arrays auf ein bestimmtes Lastverhalten und andere Faktoren hin optimiert werden. Ich habe dabei doch ein paar Überraschungen erlebt.
Bzgl. SSDs hat sich in den letzten Jahren ja viel getan; die aktuellen SSDs sind schneller, die preislich erschwingliche Kapazität ist deutlich größer geworden. Am wichtigsten ist aber, dass sich die Haltbarkeit verbessert hat. Das ist für kleinere Unternehmen durchaus ein Punkt. Der Austausch von mehreren SSDs kostet ja nicht nur Geld, sondern auch Betriebsausfallzeiten und ggf. Aufwände externer Administratoren.
Diese Artikelserie ist für Leute gedacht, die sich dem Einsatz von SSD-Arrays im privaten Bereich oder aber in kleinen Unternehmen annähern wollen – und dabei sicher über einige grundlegende Fragen stolpern. Wir betrachten also SSD-Raid-Arrays in Linux-Workstations oder kleineren Linux-Servern. Dabei fassen wir auch den Einsatz von SATA3-Onboard-Controllern ins Auge – für Intel Chipsätze wie den Z170, dessen Sunrise-Point-Controller und Intels zugehörige, sog. “iRST”-Technologie.
In einem Linux-Blog ist vor allem auch der Einsatz von Linux-SW-Raid-Arrays von Interesse. Viele der in den kommenden Artikeln getroffenen Feststellungen zu Linux-SW-Raids gelten dabei ganz unabhängig von der Anlagengröße oder dem verwendeten SATA/SAS-Controller.
Raid mit SSDs – ein facettenreiches Thema
Warum will man überhaupt SSD-Raid-Arrays einsetzen? Typische Motive sind: Eine Verbesserung der Ausfallsicherheit und Performanceverbesserungen über das Leistungsvermögen einer einzelnen SSD hinaus.
Nach meiner Meinung sollte man diese Punkte jedoch gut hinterfragen, bevor man unbedarft Geld in die Beschaffung mehrerer SSDs steckt. Im Besonderen sollte man nicht auf Werbeversprechen, die mit sequentiellen Lese- und Schreibraten argumentieren, hereinfallen. Ferner gibt es (nicht nur unter Linux) einige weitere Punkte zu beachten:
- Kann man für kleinere Server Mainboard-Sata-Controller nutzen? Oder ist ein Griff zu HW-Controllern schon aus Performancegründen unumgänglich?
- Bietet der Einsatz spezieller Technologie (wie etwa Intels iRST; s.u.) für einfache Mainboard SATA3-Controller Vorteile gegenüber nativen SW-Raid-Verfahren unter Linux?
- Will man das System aus einem Raid-Array heraus booten? Geht das überhaupt?
- Wie sieht es mit dem Verschleiß der SSDs aus? Hat die Art des Raid-Systems darauf einen Einfluss? Lässt sich der fstrim-Befehl für Partitionen auf Raid-Arrays absetzen?
- Von welchen Faktoren und Konfigurationsparametern hängt die Performance eines Linux-SW-Raid-Arrays ab?
- Kann man den Standardeinstellungen vertrauen, die manche Linux-Installer für die Konfiguration von Raid-Arrays anbieten?
Arbeitet man sich in die Thematik ein, so merkt man schnell, dass das Thema “SSD-Arrays” eine Wissenschaft für sich ist. Und dann stößt man z.T. auch auf wirklich widersprüchliche Hinweise im Internet:
Das schlimmste Beispiel sind Artikel zur sog. Chunk-Size eines Arrays. Da werden von Administratoren mal möglichst große Chunk-Sizes im Bereich von 2 MB empfohlen, während andere möglichst kleine “Chunk Size”-Größen zwischen 8 und 32 KB empfehlen. Jeweils natürlich mit unterschiedlichen Begründungen, die vom Leser
selten zur Deckung gebracht werden können. Es kommt dann die Frage auf, ob die jeweiligen Autoren nicht implizite Annahmen bzgl. bestimmter Lastprofilen gemacht haben …
Ich habe nun mehrere Tage mit eigenen Tests und Informationsbeschaffung verbracht – erst jetzt hat sich ein Vorgehensmodell herauskristallisiert. Ich werde mir dabei aus guten Gründen Reserven für weitere datenbankspezifische Experimente offen lassen. Inzwischen habe ich immerhin einige Erkenntnisse gewonnen, die auch anderen helfen können, wenigstens ein paar essentielle Fehler und eine unkritische Übernahmen von Empfehlungen zu vermeiden.
Verfügbare Ressourcen auf dem neuen Test-System
Mein neues Testsystem hat folgende Ressourcen:
i6700K-CPU, 64 GB RAM, 4 Raid10 HDDs mit HW-Controller, 1 rel. teure SSD 850 Pro, 4 relativ kostengünstige SSDs 850 EVO.
Das Z170-Mainboard weist einen onboard Intel Z170-SATA3-Controller (Sunrise Point) auf, der mit Intel Rapid Storage Technologie [iRST] betrieben werden kann. Es handelt sich dabei um eine Lösung von Intel, die eine (Vor-) Konfiguration von Raid-Platten-Verbänden bereits im BIOS zulässt. Ich spreche in den kommenden Artikeln kurz vom “iRST-Controller”, wenn denn iRST im BIOS aktiviert ist.
Was ist das vorläufige Zwischenergebnis nach etlichen Tests?
Um den Leser einen Vorgeschmack zu geben, hier ein paar vorläufige Entscheidungen:
- Ich habe eine klare Entscheidung für Linux-SW-Raid getroffen und gegen den Einsatz von iRST getroffen. Weniger aus Performance-Gründen, als vor allem aus Gründen der Flexibilität. Auf iRST werde ich ganz verzichten; die Platten werden BIOS-seitig im reinen AHCI-Modus angesprochen.
- Es werden hauptsächlich Raid-10-Arrays und keine Raid-5-Arrays zum Einsatz kommen. Dies ist eine fundamental wichtige Entscheidung! Sie ist primär dadurch motiviert, die SSDs zu schonen. Raid 10 ist hinsichtlich Plattenplatz teuer – aber das erscheint mir im Vergleich zur Plattenabnutzung nach meinen bisherigen Erfahrungen ein relativ kleiner Preis zu sein.
- Ich werde das Betriebssystem (OS Suse 42.2 und alternativ Debian) nicht auf einer Partition des Raid-Systems selbst aufsetzen – und wenn doch, dann nur zu Testzwecken, aber nicht zum produktiven Arbeiten.
- Ich werde die Raid-Erstellung nicht halbautomatisch über YaST, sondern manuell vornehmen. Hierfür gibt es einen guten Grund, den ich in einem kommenden Artikel erläutern werde.
- Bzgl. des Partition-Alignments werde ich dagegen nach vielen manuellen Checks Opensuses’ YaST bzgl. dessen Alignment-Algorithmen vertrauen.
- Insgesamt werde ich auf den SSDs ca. 12% Plattenplatz ungenutzt lassen. Das ist teuer, aber bzgl. des Verschleißes eine Vorsichtsmaßnahme.
- LVM wird zum Einsatz kommen; die logischen Volumes werden mit guten Reserven bzgl. des eigentlichen Platzbedarfes angelegt.
- Ich werde mir die Option für mehr als 2 Raid Arrays auf ein und demselben Plattenverbund offen lassen. Für echte Hochperformance-Aufgaben werde ich kleine Raid-5-Arrays weiter austesten.
- Für weitere intensivere Applikations- und Datenbanktests werde ich mindestens 2 Raid-Arrays mit ganz unterschiedlichen Raid Chunk Sizes, nämlich 512KB bzw. 32KB verwenden. Die Chunk Size hat sich als ein essentieller Parameter für eine gute Performance erwiesen.
- Bzgl. der endgültigen Wahl der Chunk Size gibt es gleich mehrere Aspekte zu beachten – u.a. die Art der Last: Random I/O? Kleine Blocksizes? Viele parallele und konkurrierende Prozesse mit Plattenzugriff oder eher
zeitlich getrennte Einzelprozesse mit hohen Last-Peaks? Viele separate Zugriffe? Applikationen mit Threading zur Lastverteilung? Auf einem halbwegs ausgelasteten Fileserver wüsste ich jetzt bereits die richtige Wahl; für unsere spezielle PHP/MySQL-Anwendung sind weitere Tests und ggf. sogar eine stärkere Parallelisierung des SW-Algorithmen für mehrere CPU-Cores erforderlich.
Eine wichtige Sache, die ich auch gelernt habe:
Man kann die potentiellen Probleme nicht allein mit einfachen Testtools wie “hdparm -tT”, “dd” für das Lesen und Schreiben größerer Test-Datenmengen mit unterschiedlichen Blockgrößen oder grafischen Tools wie “gnome-disks” erfassen.
Ein Ergebnis wie
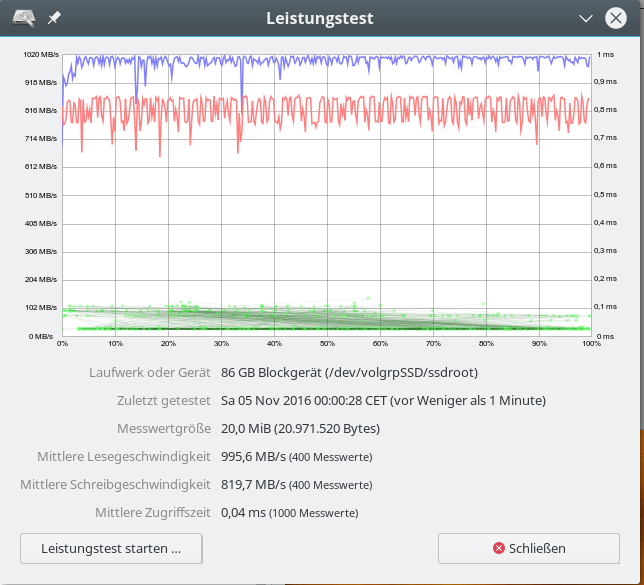
für den iRST ist nicht wirklich aussagekräftig. Tools wie “fio”, die eine differenzierter parametrierte Last erzeugen können, sind wesentlich hilfreicher.
Aber der Reihe nach – in den zunächst kommenden Teilen dieser Miniserie
SSD Raid Arrays unter Linux – II – HW-Controller?
gehe ich zunächst ein wenig auf das Thema HW-Controller ein. Lohnt sich deren Einsatz?
Es folgen dann ein paar Beiträge zum Einsatz von iRST im Vergleich zu nativen SW-Raids.
Danach werde ich mich mit Frage Raid-5 vs. Raid-10 auseinandersetzen. Ein weiterer Artikel zeigt dann, wie man Raid-10-Arrays unter Linux praktisch konfiguriert.
Schließlich werde ich Performance-Daten präsentieren und daraus Schlussfolgerungen bzgl. der Raid-Konfiguration ziehen.
Der eine oder andere praktisch veranlagte Leser wird sich im Gegensatz zu der von mir gewählten Themenfolge vielleicht als erstes auf das Thema einer Anlage und Konfiguration von SW-Raid-Arrays stürzen wollen. Bitte, kein Problem! Ich empfehle vorab eine intensive Auseinandersetzung mit dem “mdadm”-Kommando und seinen Optionen. Siehe zur Einführung etwa
https://raid.wiki.kernel.org/index.php/RAID_setup
https://www.thomas-krenn.com/de/wiki/Software_RAID_mit_MDADM_verwalten
https://www.digitalocean.com/community/tutorials/how-to-create-raid-arrays-with-mdadm-on-ubuntu-16-04
https://linux.die.net/man/8/mdadm
https://doc.opensuse.org/documentation/leap/reference/html/book.opensuse.reference/cha.advdisk.html#sec.yast2.system.raid
Einen kleinen “Kurs” zu mdadm bietet die Seite
https://www.tecmint.com/understanding-raid-setup-in-linux/.