Bei der Vorbereitung auf ein LPI-Zertifikat lernt man den Umgang mit den Befehlen “ifconfig”, “ip” und “iwconfig” in umfassender Weise. Dabei beziehen sich die Befehle allerdings auf vorhandene Interface-Namen, die dem System bereits bekannt sind. Ifconfig kann u.a. die Zuordnung einer IP-Adresse zu einem definierten und benannten Netzwerk-Interface vornehmen. Diese Zuordnung überdauert aber einen Neustart des Systems jedoch nicht.
Trotz Yast kann ein SuSE-Anwender öfter als ihm lieb ist, in eine Situation geraten, in der die Beherrschung von ifconfig nicht mehr genügt und er gerne auch die Antwort auf folgende Fragen wissen möchte:
Wo wird eigentlich unter SuSE der Name eines Netzwerk-Interfaces dauerhaft hinterlegt? Wie wird eine erkannte NIC eigentlich dem jeweiligen Interface-Namen zugeordnet? Wo steht das? Wo und wie hinterlegt SuSE die Netzwerkkonfigurationsdaten dauerhaft zu einem Interface-Namen? Woher erhält das System z.B. beim Startup die Information, dass es zwei Interfaces eth0 und eth1 gibt, de konfiguriert werden müssen? Genau diese Fragen wurden mir heute gestellt – und LPI-Bücher helfen hier nicht wirklich weiter.
Ich versuche nachfolgend zu zeigen, wie man die zugehörigen Konfigurationsdateien und Informationen in einem SuSE-System durch ein wenig Nachdenken und systematisches Stöbern im System finden kann. Bei aktuellen SuSE-Systemen gelangt man dabei unweigerlich zum Verzeichnis “/sys”. Wir gehen daher kurz auch auf seine grundlegende Bedeutung für Kernel 2.6-Systeme ein.
Die Suche nach der Nadel im Heuhaufen
Angesichts der Vielzahl von Konfigurationsdateien, Startup-Skripts und SuSE- bzw. Yast-spezifischen Konfigurationsdateien kann man auch als erfahrener Linux-Anwender bei der Suche nach spezifischen Informationen zu Netzwerkkarten und deren Interface-Namen fast verzweifeln, wenn einem das Internet mal nicht als zusätzliche Informationsquelle zur Verfügung steht.
Um einen Startpunkt zu bekommen, könnte man als erstes geneigt sein, einmal unter “/proc/sys/ipv4/” und genauer unter “/proc/sys/ipv4/conf” nachzusehen. Der Kernel muss ja zumindest wissen, welche Interfaces er im Griff hat. Das ist insofern ein guter Ansatz, als man dort schnell einen Überblick über die aktiven Karten erhält. Übrigens auch über die (virtuellen) Host-Interfaces eines gestarteten VMware-Prozesses, wobei das Linux-Systems als VMware-Host dient:
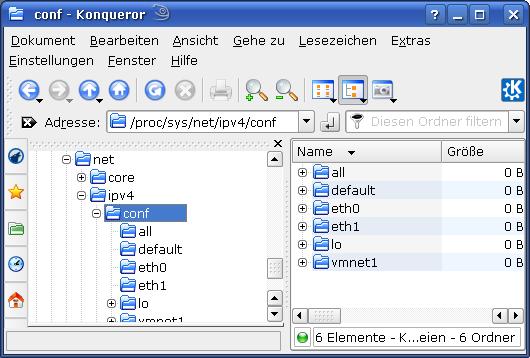
Also irgendwie sind auch dem Kernel die für die Netzwerkkarten vergebenen Namen bekannt. Als SUSE-Anwender weiß man aber auch, dass man die Bezeichnung “eth0” eines Interfaces bereits bei der Einrichtung der Netzwerkkarte über Yast vergeben hat – oftmals schon während der Installation. Zudem bleiben die diesem Namen zugeordnete Konfigurationsvorgaben (z.B. zu DHCP oder einer statischen IP-Adresse) dauerhaft im System erhalten.
Wie gesagt: Der Befehl “ifconfig” kann den Netzwerkinterfaces Konfigurationswerte nur momentan, nicht aber über einen Reboot hinaus zuordnen. Mit ifconfig vergebene Werte überleben einen Neustart des Systems oder des Netzwerkes nicht. (Das kann man leicht ausprobieren!).
Also hegt man die Vermutung, dass es wohl Dateien geben wird, in denen Yast die benötigten Informationen persistent hinterlegt. Diese Informationen müssen dann zwangsläufig bei jedem Systemstart ausgewertet werden und auch dem Kernel verfügbar sein. Um herauszubekommen, woher das System beim Startup Informationen zur Netzwerkkonfiguration und zu Interfaces bezieht, werfen wir deshalb einen Blick in das entsprechende Startup-Skript von SuSE für das Netzwerk.
Dieses Skript finden wir – wie erwartet – unter “/etc/init.d/” als Datei “/etc/init.d/network”. Nach etwas Suchen im Skript stößt man recht bald auf eine Zeile in der das
Verzeichnis
/etc/sysconfig/network
aufgesucht wird.
Das Verzeichnis /etc/sysconfig/net
Bei SuSE werden grundlegende Einstellungen zum System im Verzeichnis “/etc/sysconfig” verankert. Tatsächlich gibt es dort denn auch ein Unterverzeichnis “/etc/sysconfig/network” sowie eine Konfigurations-Datei “/etc/sysconfig/network/config”. Unter SuSE’s Yast gibt es zudem ein Werkzeug – den “/etc/sysconfig”-Editor – mit dem man sich die Einträge unter /etc/sysconfig” ansehen und ggf. auch editieren kann. Die Parameter der Datei “/etc/sysconfig/network/config” erhält man im “/etc/sysconfig”-Editor z.B. unter dem Punkt “Network->General”.
Klickt man sich im “Sysconfig-Editor” weiter durch die Hauptpunkte durch, so gelangt man unter “Hardware->Network” auch zu Unterpunkten für die verschiedenen, namentlich definierten Netzwerk-Interfaces (z.B. eth0, eth1,…). U.a. sind hier die zuzuordnenden IP-Adressen hinterlegt. Weitere im “Sysconfig-Editor” definierte bzw. definierbare Parameter sind z.B.:
BOOTPROTO, BROADCAST, ETHTOOL_OPTIONS, IPADDR, MTU, NAME, NETWORK, REMOTE_IPADDR, STARTMODE, USERCONTROL.
Woher nimmt der “Sysconfig-Editor” diese Informationen? Ein kontrollierender Blick in das Verzeichnis “/etc/sysconfig/network” zeigt dann, dass die Vorgaben für das Interface eth0 (bei der Einrichtung der Netzwerkkarte mit Yast2->Netzwerkgeräte->Netzwerkkarte) in die Datei
/etc/sysconfig/network/ifcfg_eth0
geschrieben wurden. Entsprechende Konfigurationsdateien gibt es unter “/etc/sysconfig/network/” natürlich auch für andere NIC-Interfaces.
Aha, über diese Dateien oder über den “Sysconfig”-Editor kann man also unter SuSE IP-Adressen und Broadcast-Adressen für ein Interface (dauerhaft) ändern. Wenn man also im laufenden Betrieb nicht zu “ifconfig” greifen will oder aber Änderungen für ein Interface dauerhaft hinterlegen muss und die erneute Kartenkonfiguration mit “Yast->Netzwerkgeräte->Netzwerkkarten” scheut, so führt auch der Umweg über das Editieren der besagten Dateien zum Ziel. Im laufenden Betrieb muss man aber nach den Datei-Änderungen (über den “/etc/sysconfig”-Editor) den Befehl “/etc/init.d/rcnetwork restart” aufrufen, um die Änderungen konkret auf die vorhandenen NICs anzuwenden.
Die Startup-Skripts für das Aufsetzen des Netzwerkes greifen also auf die Interface-spezifischen Dateien vom Typ “/etc/sysconfig/network/ifcfg_ethx” zurück. Natürlich macht auch dieses Startup-Skript sich bei der Konfiguration des jeweilige Interfaces intern die Möglichkeiten von ifconfig(oder ip) zu Nutze. (Dies erkennt man, wenn man die Logik des Startup-Slripts weiter verfolgt.)
Nun führen aber Konfigurationsdateien wie “/etc/sysconfig/network/ifcfg_eth0” die Bezeichnung des Netzwerkinterfaces bereits im Namen! Die Datei wurde bei der Konfiguration der NIC erzeugt. Zu diesem Zeitpunkt war natürlich klar, um welche Hardware es sich handelt. Wie weiß das System aber im Nachhinein, welche Interface-Bezeichnung welcher NIC (welchem physikalischen Gerät) zuzuordnen ist? Wo wird also festgeschrieben, welche Netzwerk-Geräte und -Interfaces es im System gibt und welche Namen diesen Interfaces zugeordnet wurden ?
Wir werfen erneut einen Blick in die Startup-Datei “/etc/init.d/rcnetwork restart”. Nach weiterem Scrollen werden wir fündig (Opensuse 10.X):
Zum Durcharbeiten aller Netzwerkinterfaces wird (falls der “Networkmanager” nicht benutzt wird), die Variable “AVAILABLE_IFACES” herangezogen. Ein wenig weitere Forschungsarbeit zeigt schließlich, dass die Variable “AVAILABLE_IFACES” nach Durchlaufen eines Analyse-Loops über den Inhalt des Verzeichnisses
/sys/class/net/
festgelegt wird.
Von /sys/class/net zum sysFS
Tatsächlich zeigt ein Blick in das Verzeichnis “/sys/class/net/” auf einem meiner Systeme auszugsweise Folgendes:
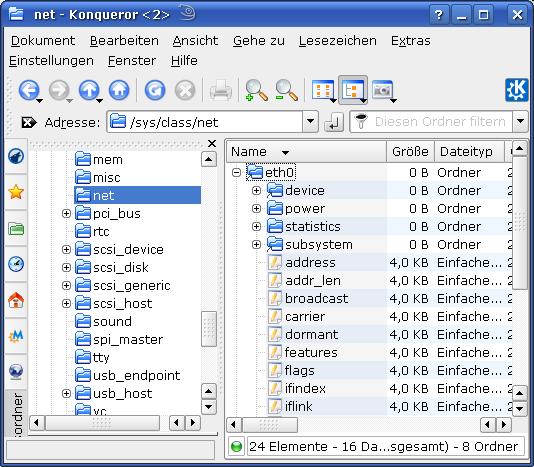
Also: Unsere ursprüngliche Frage, wo im System Informationen zu NIC-Interface-Namen hinterlegt sind, haben wir damit beantwortet: Unter “sys/class/net”.
Wir lernen bei der Gelegenheit jedoch noch ein wenig mehr:
Bei genauerem Hinsehen stellen wir fest, dass es sich bei den Dateien unter “/sys/class/net” um Links handelt, die wiederum auf Device-Dateien unter “/sys” (hier genauer: /sys/pci0000:00) verweisen. Wir erkennen nach einigem Studium ferner, dass sich auch Links aus dem Verzeichnis “/sys/bus/pci” auf die Device-Dateien beziehen. Aha, so langsam wird uns klar, dass das “/sys”-Verzeichnis offenbar essentielle und strukturierte Informationen zu Devices – und nicht nur zu Netzwerkdevices – enthält. Es scheint so, als würden Interface-Klassen separat von den Geräten aufgeführt, aber doch einander zugeordnet.
Ein Blick in “/etc/fstab” zeigt übrigens, dass “sysfs” auf “/sys” gemountet wird. Es handelt sich also um ein regelrechtes Filesystem. Wem nützt sowas? Natürlich u.a. dem Kernel (ab Version 2.6). Es handelt sich um das sog. “sysFS”-System, mit dem Geräte und deren Interfaces organisiert werden. Die sysFS-Organisation wird in den Startup-Skripts von SUSE (ab Vers. 9.1) explizit verwendet.
Generell sind die Unterverzeichnisse im sysFS die Verzeichnisse “/sys/devices/”, “/sys/bus”, “/sys/class” und “/sys/block” wesentlich. Die Verzeichnisse “/sys/devices” und “/sys/bus” entsprechen zwei verschiedenen Sichten auf die im System vorhandene Hardwaregeräte.
“/sys/class” und “/sys/block” enthalten alle “Schnittstellen” (Interfaces) zu konkreten Geräten. Nur diese definierten Interfaces können die Anwendungen des jeweiligen Systems ansprechen. es mag befremdlich wirken, aber “/dev/sdb” ist in diesem Sinne z.B. ein Interface zu einem Speichergerät. Von einem Eintrag in den Schnittstellenunterverzeichnissen “/sys/class” oder “/sys/block” führt ein eindeutiger Verweis auf ein entsprechendes Geräteunterverzeichnis in “/sys/devices” und dort zu einem speziellen Gerät.
Unter “/sys/block” findet man (wie der Name andeutet) Interfaces zu Blockgeräten, “/sys/class” enthält dagegen Interfaces zu zeichenorientierten Geräten. Die Major- und Minor-Nummern der Devices sind jeweils in einer zugehörigen Pseudodatei namens »dev« enthalten.
Aha, durch diese Verweise kann das System also wissen, welche Schnittstelle sich auf welches Gerät bezieht. Wie sieht es nun mit den Bezeichnungen der Netzwerk-Interfaces aus?
Durch die persistente Namensvergabe zu Geräte-Schnittstellen unter “/sys/class/net/*” und die entsprechende Bezeichnung der zugehörigen Datei “/etc/sysconfig/network/ifcfg_*” mit den Konfigurationsvorgaben ermöglicht es SUSE, die Netzwerk-Interface-Konfiguration über die sysFS-Struktur mit einem ganz bestimmten Gerät zu verbinden. Im Kern gilt folgende Zuordnungskette:
Gerät unter /sys/devices/Unterverzeichnis/…/Gerätedatei <<>> Bezeichnetes Interface unter /sys/class/net/*
Bezeichnetes Interface unter /sys/class/net/* <<>> (Netz-) Interfacekonfiguration unter /etc/sysconfig/network/ifcfg_*
Hiermit rundet sich unser Bild zur Netzwerkkonfiguration unter SUSE ab. Neben SUSE-spezifischen Konfigurationsdateien und Startup-Skripts spielt der Einsatz der “sysFS”-Struktur eine essentielle Rolle. Die persistente Namensgebung für die Netzwerkinterfaces spiegelt sich im Verzeichnis “/sys/class/net” wieder. Auf dieses nehmen auch die Startup-Skripts Bezug. Die unter “/sys/class/net” definierten Interfaces
sind dagegen mit konkreten Geräten unter “/sys/devices/….” verbunden.
Links
Wer nun immer noch neugierig ist, der möge sich mit tiefergehenden Geheimnissen des “sysFS”-Filesystems und weiterführend ggf. auch mit “udev” befassen.
Einen ersten Einstieg bieten folgende Adressen:
http://de.opensuse.org/SDB:SUSE_Linux_Geräte-_und_Schnittstellenkonfiguration
http://www.linux-magazin.de/heft_abo/ausgaben/2005/04/knoten_knuepfen/(offset)/2
