Ich sag’s mal gleich vorweg:
Leap 42.1 gehört aus meiner Sicht nicht zu den Opensuse Versionen, die sich auf einem Desktop-System auf Anhieb problemfrei installieren und danach ohne weiteres auf persönliche Bedürfnisse hin umkonfigurieren lassen.
Diese Aussage bezieht sich vor allem auf die auf DVDs ausgelieferte Version bzw. auf die Download-Version von Anfang Januar 2016. Die war und ist aus meiner Sicht eher ein kleines Desaster und keineswegs Werbung für das Leap-Projekt im Sinne einer stabilen Linux-Version für einen KDE-Desktop.
Viele der Probleme hatten und haben allerdings wohl mit KDE 5 zu tun – und können daher nicht unbedingt Opensuse angelastet werden. Auf meinem Testsystem sind auch OS 13.2 und OS 13.1 installiert und konnten seit geraumer Zeit produktiv und stabil genutzt werden. Die im Januar noch regelmäßig festgestellten Abstürze und Instabilitäten unter OS Leap 42.1 mit KDE5 sind daher nicht auf die Hardware zurückzuführen.
Die Stabilität des gesamten Leap-Systems hat sich inzwischen – nach zahlreichen Paketupdates und auch Repository-Wechseln – allerdings deutlich verbessert. Man kann inzwischen mit Leap 42.1 produktiv arbeiten – Ende Januar hätte ich diesen Satz so noch nicht ausgesprochen. Hier ein erster Erfahrungsbericht.
Grundsätzlich würde ich jedem, der über einen Wechsel nachdenkt, empfehlen, ein stabil laufendes Opensuse 13.2 auf keinen Fall aufzugeben oder upzugraden. Der von mir selbst regelmäßig gewählte Ansatz, ein neues Opensuse-Release (speziell mit einer grundlegend neuen KDE-Version) zunächst in einer separaten Partition als das aktuell produktive Desktop-System zu installieren und auszuprobieren, erscheint mir gerade im Fall von Leap 42.1 der absolut richtige zu sein. Es gibt immer noch Dinge, die mich ab und zu veranlassen, wieder OS 13.2 zu benutzen.
Neuerungen unter Leap 42.1, wie etwa der Mix aus KDE4 und KDE5 sowie der sog. Hybrid-Ansatz als Mischung aus stabilem Unterbau auf Basis des aktuellen SLES 12 Servers und einem relativ aktuellem Desktop, sind bereits in vielen Reviews beschrieben worden. Ich möchte diesbezüglich daher nur auf einige Artikel verweisen:
https://kofler.info/opensuse-leap-42-1/
http://www.heise.de/open/artikel/OpenSuse-Leap-42-1-Der-Nachfolger-von-OpenSuse-2877560.html
http://ordinatechnic.com/distros/distro-reviews/opensuse/opensuse-leap-421-review
https://www.curius.de/blog/13-linux/40-opensuse-leap-42-1-im-test
http://www.unixmen.com/review-opensuse-42-1-leap/
http://www.theregister.co.uk/2015/10/20/opensuse_leap_opensuse_leap_adoption/?page=1
https://www.youtube.com/watch?v=hkf4l6fIMo4
Persönlich überzeugt mich SuSE’s Hybrid-Ansatz noch nicht völlig. Da wir in unserer kleinen Firma Opensuse aber auch als Server-Plattform einsetzen, erhoffe ich mir – nach einer Phase noch zu findender Stabilität auf der Desktop-Seite – doch langfristig einen einheitlicheren Verwaltungsaufwand für Entwicklungssysteme (mit einigen Serverkomponenten) einerseits und für die von uns genutzten reinen Server- und Virtualisierungsplattformen andererseits. Die größten Probleme mit aktuellem System sehe ich eindeutig auf Seiten von KDE 5 – genauer Plasma 5.
Persönlich bekam ich anfänglich fast einen Schock als ich das “Breeze Look&Feel” für KDE 5 vor Augen hatte. Das erinnerte mich doch zu stark an MS Oberflächen. Aber inzwischen habe ich mich daran gewöhnt; zumal man sich doch viele Eigenschaften des Plasma5-Desktops so zurecht biegen kann, dass die Ähnlichkeit zu Windows am Ende recht weitgehend verschwindet.
Dennoch vermisse ich ein wenig die Vielzahl von vorgefertigten Designs und Stilen für Bedienelemente, die unter KDE 4 bereits gegeben war. Ich denke aber, das ist nur eine Frage der Zeit …
Dass OS Leap 42.1 zumindest in Teilen auf SLES 12 aufsetzt, wurde wegen der zu erwartenden Stabilität in vielen Reviews gelobt. Desktop-seitig kann ich diesen Eindruck jedenfalls nicht teilen.
Dies liegt wie gesagt vor allem an KDE. Ich habe mir nämlich mal die reinen Serveranteile in Form eines LAMP-Test-Servers und eines KVM-Test-Virtualisierunsghosts, auf den ich Guest-Images aus einem Produktivsystem migriert habe, auch mal separat ohne KDE angesehen. Fazit: Der Server-Unterbau – ohne KDE-Desktop – wirkt grundsolide.
Eine Standard-Installation der Desktop-Pakete aus dem heruntergeladenen ISO Image führte bei mir dagegen früher oder später zu größeren Problemen. Besonders zu nennen sind vor allem anfänglich extrem häufig auftretende Instabilitäten des gesamten KDE 5 Plasma-Desktops und Probleme mit den Abmelde- und Shutdown-Funktionalitäten. Die ersten 4 Versuchstage im Januar waren von folgenden Erfahrungen geprägt:
- Erratische Absturzmeldungen von “konsole”-Fenstern,
- Freezes des Plasma-Desktops (trotz damals aktuellstem Nvidia-Treiber),
- Abstürze des neuen Window-Managers “kwin_x11”
- Ungereimtheiten in der Fensterdarstellung, wenn man als User root Qt5-Anwendungen von der “konsole” aus startete. Es wurde/wird dann nicht erkannt, dass die Applikationen unter einer KDE5-Umgebung laufen. Die resultierende reduzierte Darstellung von Applikationen für den User root (zu kleine Schriften, fehlende Grafiksymbole,etc. …) ist dann mindestens mal ärgerlich. Das ist heute noch so, lässt sich aber umschiffen (s.u.)
- Erhebliche Probleme mit der Sound-Einrichtung – mit und ohne Pulseaudio.
Siehe auch: https://www.curius.de/blog/13-linux/40-opensuse-leap-42-1-im-test.
Nach vielen Updates sowie Repository-Wechseln für Multimedia-Komponenten sowie zwischenzeitlichem Löschen und Neuaufbau des kompletten “~/.config“-Verzeichnisses hat sich das Bild inzwischen aber verbessert. Zumindest Abstürze und Freezes von Plasma treten inzwischen nur noch äußerst selten auf.
KDE5 bietet aber leider noch nicht die Funktionalität, die unter KDE 4.14 gegeben war; einige liebgewonnene Plasmoide sind z.T. noch nicht für KDE5 umgesetzt oder aber es fehlt noch an gewohnten funktionalen Elementen. Ärgerlich ist zudem der z.T. noch häufig vorkommende Mix aus deutschen, englischen und manchmal auch norwegischen Menü-Einträgen in einigen Schlüssel-Applikationen (wie den KDE PIM-Anwendungen) – wie auch im Bereich der KDE-Systemeinstellungen.
Typisch sind auch kleinere Ungereimtheiten wie etwa die, dass grafische Operationen unter KDE5’s Dolphin extrem langsam werden, wenn k3b gleichzeitig CDs rippt, oder Daten zwischen Partitionen kopiert werden, obwohl das System insgesamt weit von einer Auslastung entfernt ist.
Ärgerlich ist auch, dass Symbole im Systemabschnitt der KDE5-Kontroll-Leiste, die nicht speziell für KDE5 entwickelt wurden, keine Funktionalität aufweisen. Sie reagieren auf keine Art von Mausklick. Beispiele sind etwa das “virt-
manager”-Symbol oder auch das Symbol der “Open eCard-Anwendung” für den neuen Personalausweis.
Aus dem Reich des wirklich Üblen erwies sich u.a. das Plasmoid zur Ordneransicht auf dem Desktop. Ich sage einfach: Finger weg davon, wenn man sich Ärger ersparen will. Und wenn man “Ordneransichten” dennoch nutzen und Änderungen an deren Konfiguration und Inhalt vornehmen will, dann sollte man das am Besten ausgehend von einem Dateimanager mittels Kopieren von Einträgen in “~/Schreibtisch” und danach durch Anpassen der Einträge der zugehörigen Datei über einen Editor tun. Funktioniert deutlich besser und fehlerfreier als entsprechende grafische Operationen am Desktop selbst (Stand Ende Januar; habe mir das bisher nicht mehr genauer angesehen, sondern verankere nur noch Einzel-Icons auf der Plasma-Oberfläche).
Interessanterweise stürzte/stürzt auch Libreoffice 5 manchmal, wenn auch selten, unvermittelt ab. Das muss jedoch nicht zwingend etwas mit KDE5 oder der GTK-Integration zu tun haben.
In jedem Fall gilt:
Ein Update aller System- und KDE-Pakete sollte nach einer DVD-Installation möglichst unverzüglich vorgenommen werden. Am besten lässt man die Standard-Update Repositories von Opensuse schon zum Installationszeitpunkt einbinden. Dennoch kommen ggf. immer mal wieder Abstürze des Plasma-Desktops, von konsole-Fenstern oder des Window-Managers “kwin_x11″ vor. Dann sollte man im Besonderen die Dateien und die Unterverzeichnisse des ~/.config”-Verzeichnisses komplett neu aufbauen lassen. (Z.B. durch Umbenennen dieses Verzeichnisses). Danach verliert man zwar etliche der bislang vorgenommenen Desktop-Einstellungen; der resultierende Aufwand war im Vergleich zum Gewinn an Stabilität aber ein geringer Preis …
Durch einen mehrtägigen Mail-Verkehr mit einem Leser dieses Blogs musste ich leider lernen, dass sich Leap 42.1 auf mancher Laptop-HW (etwa auf bestimmten UEFI-basierten Asus-Systemen) nicht zu einer Installation bewegen lässt, bei der am Ende das Grafik-System, Tastatur, WLAN-Komponenten problemfrei laufen würden. Ganz im Gegensatz übrigens zu “Linux Mint 14” – in dessen KDE-Variante. Kein Wunder, dass Linux Mint in Deutschland die populärste Linux-Distribution geworden ist! Dass Opensuse hinsichtlich der HW-Kompatibilität mit Mint nicht mehr mithalten kann, hat mich als alten Opensuse-Anhänger denn doch etwas deprimiert.
Kleine Unterschiede zwischen LEAP 42.1-ISO-Images?
Offenbar gibt es geringfügige Unterschiede in publizierten ISO-Images. Die DVD, die der letzten Easy Linux DVD-Ausgabe beigelegt war, unterscheidet sich in Kleinigkeiten von der des ISO-Images, das man von der opensuse.org-Website herunterladen kann – u.a. durch die Voreinstellung zur Größe der Grub BIOS Partition. Besondere Auswirkungen konnte ich nicht feststellen. Ich habe mich aber dennoch gefragt, was da noch alles unterschiedlich sein mag ….
Ich habe die BTRFS-Diskussion schon seit Opensuse 13.1 ein wenig mitverfolgt. Nach einigen vorläufigen Tests, die ich unter OS 13.2 durchgeführt hatte, sehe ich für meine Systeme keinen einzigen Grund, im Moment von “ext4” wegzugehen.
Ich bin deshalb nicht den Partitionierungsvorschlägen des SuSE-Installers gefolgt, sondern habe die Linux-Partitionen meiner Systeme durchgehend mit dem Filesystem ext4 versehen. Neben dem auch von Herrn Kofler ins Feld geführten Argument, dass BTRFS komplexer als ext4 ist und vom Administrator entsprechend mehr Wissen verlangt, waren für mich folgende Punkte ausschlaggebend:
Bzgl. Snapshots: Ich setze auf den meisten meiner Systeme sowieso LVM (und die zugehörige Snapshot-Funktionalität) ein. Für Snapshots benötige ich BTRFS deshalb nicht.
Bzgl. Performance:
ext4 erscheint mir – zumindest auf SSDs (mit und ohne Raid) – im Schnitt auch für die Systempartition hinreichend schnell zu sein. Für Datenbanksysteme gibt es neben ext4 jedoch deutlich performantere Filesysteme als BTRFS.
Der einzige Serverdienst, der nach meiner Erfahrung wirklich von BTRFS zu profitieren scheint, ist ein NFS- und/oder Samba-Fileserver-Dienst für im Schnitt kleine bis mittlere Dateigrößen.
Aber bildet euch selbst eure Meinung; nachfolgend dazu ein paar Artikelhinweise:
https://kofler.info/opensuse-13-2-ausprobiert/
http://www.unixmen.com/review-ext4-vs-btrfs-vs-xfs/
http://www.phoronix.com/scan.php?page=article&item=linux-40-hdd&num=1
http://www.phoronix.com/scan.php?page=article&item=linux-43-ssd&num=1
https://www.diva-portal.org/smash/get/diva2:822493/FULLTEXT01.pdf
http://www.slideshare.net/fuzzycz/postgresql-on-ext4-xfs-btrfs-and-zfs
http://blog.pgaddict.com/posts/friends-dont-let-friends-use-btrfs-for-oltp
http://www.linux-community.de/Internal/Artikel/Print-Artikel/EasyLinux/2015/01/Butter-bei-dat-Dateisystem
http://www.safepark.dk/in-the-news/btrfsunderopensuseleap421-betterharddiskusage
https://forums.opensuse.org/showthread.php/502082-BtrFS-vs-XFS-vs-Ext4/page6?s=ee63ec62915db3e9d5bbaf9cc8b81799
https://wiki.gentoo.org/wiki/Btrfs
https://en.opensuse.org/openSUSE:Snapper_Tutorial
Die Installation auf einem bereits komplexen System mit vielen Partitionen und Raid-Systemen erfordert ggf. eigenhändige Partitionierungsarbeiten. Hier werden diejenigen, die eine Installation über ein DVD-ISO-Image durchführen, ggf. eine Überraschung erleben, wenn mehrere komplexe GPT-basierte Harddisk- und Raid-Konfigurationen mit vielen Partitionen unter LVM ausgelesen und bearbeitet werden müssen. Der ursprüngliche YaST-Partitionierungsassistent, zu dem man während der Installation wechseln kann, reagiert dann unglaublich (!) träge. Ganz im Gegensatz zu einfachen Installationen auf einem Laptop mit nur 2 Standard Partitionen (ohne LVM).
Nach einem umfassenden Rundum-Update der Yast- und anderer Leap-Pakete im Anschluss an die Grundinstallation gibt sich YaST’s “Partitioner” dann allerdings wieder so spritzig, wie man das von Opensuse 13.2 gewohnt war. Das sind halt die typischen Kinderkrankheiten, wie sie bei neuen Opensuse-Releases mit substanziellen Änderungen immer mal wieder auftreten.
Das funktioniert wie gehabt. Je nach Netzkonfiguration und Firewall-Einstellungen ist dafür zu sorgen, dass die DHCP-Zuweisung einer IP-Adresse funktioniert und das System durch evtl. Firewalls nach außen zu SuSE-Servern über HTTP Kontakt aufnehmen darf.
Ich empfehle, nach der Installation einen Dummy-
User einzurichten, dessen KDE- und Desktop-Einstellungen man unverändert lässt. Treten mit KDE 5 unerwartete Probleme auf, sollte man erstes immer mal testen, ob auch der Dummy-User darunter leidet – oder ob zwischenzeitliche, user-spezifische Einstellungsveränderungen zu dem Problem geführt haben. Das war bei mir mehrfach der Fall.
Der während der Installation automatisch konfigurierte Nouveau-Treiber bringt auf der Nvidia-Karte meines Desktop-Systems mit 3 Schirmen alle Boot-Meldungen (im Framebuffer-Modus) und auch den grafischen Anmeldebildschirm von KDE auf allen 3 angeschlossenen Schirmen zur Ansicht.
Das tut der später installierte proprietäre Nvidia-Treiber nicht mehr – der zeigt Boot-Meldungen nur auf genau einem Konsolen-Schirm (in meinem Fall am DVI-Ausgang der Grafikkarte).
Ein paar Hinweise zur nachträglichen Installation des proprietären Nvidia-Treibers:
- Schritt 1: Auf Basis des zunächst automatisch installierten Noveau-Treibers das Erscheinen des KDE-Login-Schirms abwarten. In KDE 5 einloggen. Bei mehreren angeschlossenen Schirmen zunächst eine vernünftige Anordnung der Displays herstellen. Da ist u.a. möglich über KFDE’s “Systemeinstellungen >> Hardware >> Anzeige und Monitor”.
- Schritt 2: Dann den aktuellen Nvidia-Treiber von “nvidia.de” herunterladen. Ausloggen von KDE.
- Schritt 3: Ctrl-Alt-F1, um zur Haupt-Konsole zu wechseln. Dort als User “root” einloggen. Das Kommando “init 3” absetzen, um das X-Window-System zu stoppen.
- Schritt 4: Zum Verzeichnis mit dem heruntergeladenen Nvidia-Treiber wechseln. Dann:
mytux:~ # bash NVidia-Linux-x86_64-352.63.run
Sich durch die verschiedenen Meldungen durchklicken. Bestätigen der Anlage eines Files unter “/etc/modprobe.d” (!). Danach alles bestätigen => alle Error-Meldungen akzeptieren. Das nvidia-Treibermodul ist und wird wegen der Fehler nicht geladen, wie man über ein “lsmod | grep nvidia” sehen kann. Nun nicht booten; das führt nämlich auch nicht zu einem Laden des nvidia-Kernel-Moduls im nächsten Boot-Prozess.
- Schritt 5: Statt dessen init 5 => Einloggen => Schirmreihenfolge noch OK => root-terminal => Dolphin starten => hunderte Fehlermeldungen auf der Konsole tapfer ignorieren.
- Schritt 6: Unter “dolphin” die Datei “/etc/modprobe.de/nvidia-installer-disable-nouveau.conf” suchen und mit kwrite öffnen. Parallel die Datei “/etc/modprobe.de/50-blacklist.conf” öffnen.
- Schritt 7: Den Inhalt von “/etc/modprobe.de/nvidia-installer-disable-nouveau.conf”, nämlich
# generated by nvidia-installer
blacklist nouveau
options nouveau modeset=0
mit Hilfe von z.B. kwrite an das Ende der Datei “/etc/modprobe.de/50-blacklist.conf” kopieren. Erst diese Aktion stellt sicher, dass das nouveau-Modul beim nächsten Bootvorgang nicht mehr geladen wird. Die vom Nvidia-Installer bereitgestellte Datei “/etc/modprobe.de/nvidia-installer-disable-nouveau.conf” wird von systemd nicht ausgelesen.
- Schritt 8: Die modifizierte Datei “/etc/modprobe.de/50-blacklist.conf” speichern und kwrite schließen.
- Schritt 9: In einem Terminalfenster meldet man sich dann erneut als User root an und setzt den Befehl
mytux:~ # mkinitrd
ab. Fehlermeldungen am Ende erneut tapfer ignorieren.
- Schritt 10: Alle Fenster schließen =>
Neustart-Button (blau) im Startmenü
- Schritt 11: Der erneute Boot-Prozess endet dann ggf. in der Hauptkonsole. Falls der KDE-Login-Schirm aufgrund des geladenen langsamen nv-treibers angezeigt werden sollte: Ctrl-Alt-F1 => als User root einloggen => Kommando “init 3”.
- Schritt 12: Nvidia-Treiber erneut installieren – das sollte nun anstandslos funktionieren.
- Schritt 13: System neu starten (init 6). Nun sollte der grafische KDE-Login-Schirm erscheinen.
Es ist zudem sinnvoll, eine ggf. vorhandene Mehrfach-Schirm-Kombination in der Datei “/etc/X11/xorg.conf” zu verankern. Das sieht in meinem Fall etwa so aus:
# nvidia-xconfig: X configuration file generated by nvidia-xconfig
# nvidia-xconfig: version 352.79 (buildmeister@swio-display-x64-rhel04-15) Wed Jan 13 17:02:24 PST 2016
# nvidia-settings: X configuration file generated by nvidia-settings
# nvidia-settings: version 352.30 (buildmeister@swio-display-x64-rhel04-18) Tue Jul 21 19:35:20 PDT 2015
# 14.01.2016: Modified by Ralph Moenchmeyer
Section "ServerLayout"
Identifier "Layout0"
Screen 0 "Screen0" 0 0
InputDevice "Keyboard0" "CoreKeyboard"
InputDevice "Mouse0" "CorePointer"
Option "Xinerama" "0"
EndSection
Section "Files"
EndSection
Section "InputDevice"
# generated from data in "/etc/sysconfig/mouse"
Identifier "Mouse0"
Driver "mouse"
Option "Protocol" "IMPS/2"
Option "Device" "/dev/input/mice"
Option "Emulate3Buttons" "yes"
Option "ZAxisMapping" "4 5"
EndSection
Section "InputDevice"
# generated from default
Identifier "Keyboard0"
Driver "kbd"
EndSection
Section "Monitor"
Identifier "Monitor0"
VendorName "Unknown"
ModelName "Ancor Communications Inc PB248"
HorizSync 30.0 - 83.0
VertRefresh 50.0 - 61.0
Option "DPMS" "false"
EndSection
Section "Device"
# Addendum RMO https://bugs.kde.org/show_bug.cgi?id=322060
Identifier "Device0"
Driver "nvidia"
VendorName "NVIDIA Corporation"
BoardName "GeForce GTX 960"
EndSection
Section "Screen"
# Removed Option "metamodes" "DVI-I-1: 1920x1200_60 +0+0, DVI-D-0: 1920x1200_60 +1920+0"
# Removed Option "MultiGPU" "On"
Identifier "Screen0"
Device "Device0"
Monitor "Monitor0"
DefaultDepth 24
Option "Stereo" "0"
Option "nvidiaXineramaInfoOrder" "DFP-0"
Option "metamodes" "DP-4: nvidia-auto-select +0+0, DP-0: nvidia-auto-select +2560+0, DVI-I-1: nvidia-auto-select +5120+0"
Option "SLI" "Off"
Option "MultiGPU" "Off"
Option "BaseMosaic" "Off"
Option "TripleBuffer" "True"
SubSection "Display"
Depth 24
EndSubSection
EndSection
Die Anweisungen im Screen-Bereich sorgen dafür, dass der Treiber beim Starten des X-Window-Systems die Zuordnung der verschiedenen Schirme zu den Grafikkarten-Ports korrekt umsetzt. Danach erscheint die KDE-Login-Oberfläche schließlich auf allen drei Schirmen.
Achtung: Ich rede hier über ein Desktop-System. Eine Nvidia-Installation auf Laptops mit Optimus-Technologie erfordert andere Schritte. Siehe z.B.:
Bumblebee
auf Laptops mit Opensuse 13.1 / 13.2
Ich habe das dort beschriebene Verfahren allerdings noch nicht mit Leap 42.1 ausprobiert.
Ist der nvidia-Treiber erstmal installiert, so findet man die Konfigurationsanwendung “nvidia-settings” im neuen Startmenü übrigens unter dem Punkt “Einstellungen”.
Im Falle von Mehrschirm-Arbeitsplätzen sollte man abschließend prüfen, dass die Schirmanordnungen und die schirmbezogenen Einstellungen unter “nvidia-settings” mit jenen unter KDE’s “Systemeinstellungen => Anzeige und Monitor” sind. (Anfang Januar war das nämlich nicht unbedingt der Fall).
Zur leidigen Sound-Konfiguration unter Linux mag ich mich schon fast nicht mehr äußern. Wie immer verweigere ich “pulseaudio” (das mit Mehrkanalkarten bis heute nicht vernünftig bzw. nicht fehlerfrei umgehen kann) für den normalen Gebrauch des Desktops die Dienstaufnahme. Das Abschalten von Pulseaudio ermöglicht unter Opensuse auf einfache Weise eine entsprechende Option unter YaST.
Während mir aber unter KDE 4.14 nach einem Neustart unter “Systemeinstellungen => Mulitimedia” für meine 3 Soundkarten eine ganze Phalanx von funktionstüchtigen Alsa-fähigen Geräten unter den Phonon-Einstellungen angezeigt wurde/wird, ist dies bei Opensuse Leap 42.1 mit KDE 5 nicht der Fall.
Das ist durchaus ein Problem: Durch diesen “Fehler” (?) fallen dann auch Änderungen an der Priorität der Devices und ein einfacher Tests unter den Tisch. Solche Dinge treiben mich als Anwender zu Verzweiflungsausbrüchen.
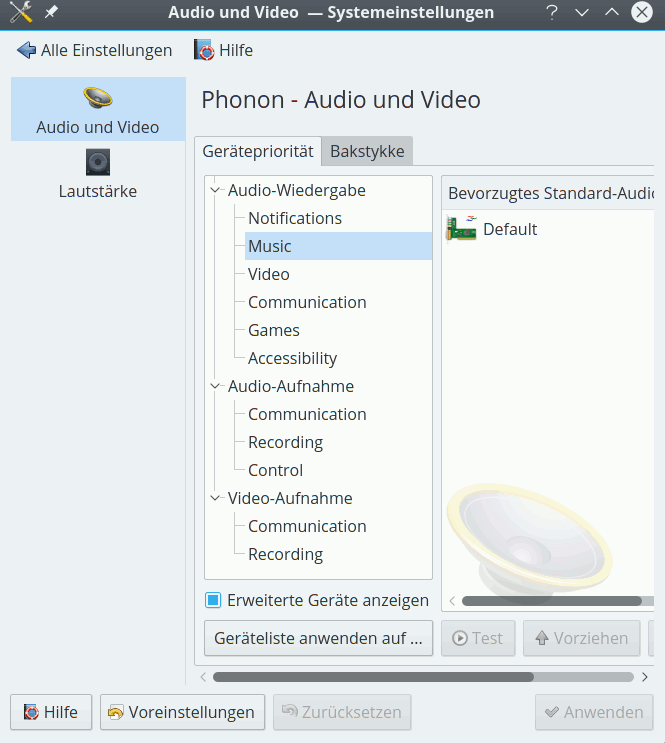
Interessanterweise zeigt aber Amarok 2.8.0, das noch für KDE 4.14.17 entwickelt wurde, unter dem Menüpunkt “Einstellungen > Amarok einrichten => Wiedergabe => Phonon einrichten” alle Alsa-tauglichen Geräte inkl. der selbstdefinierten Alsa-Devices korrekt an!
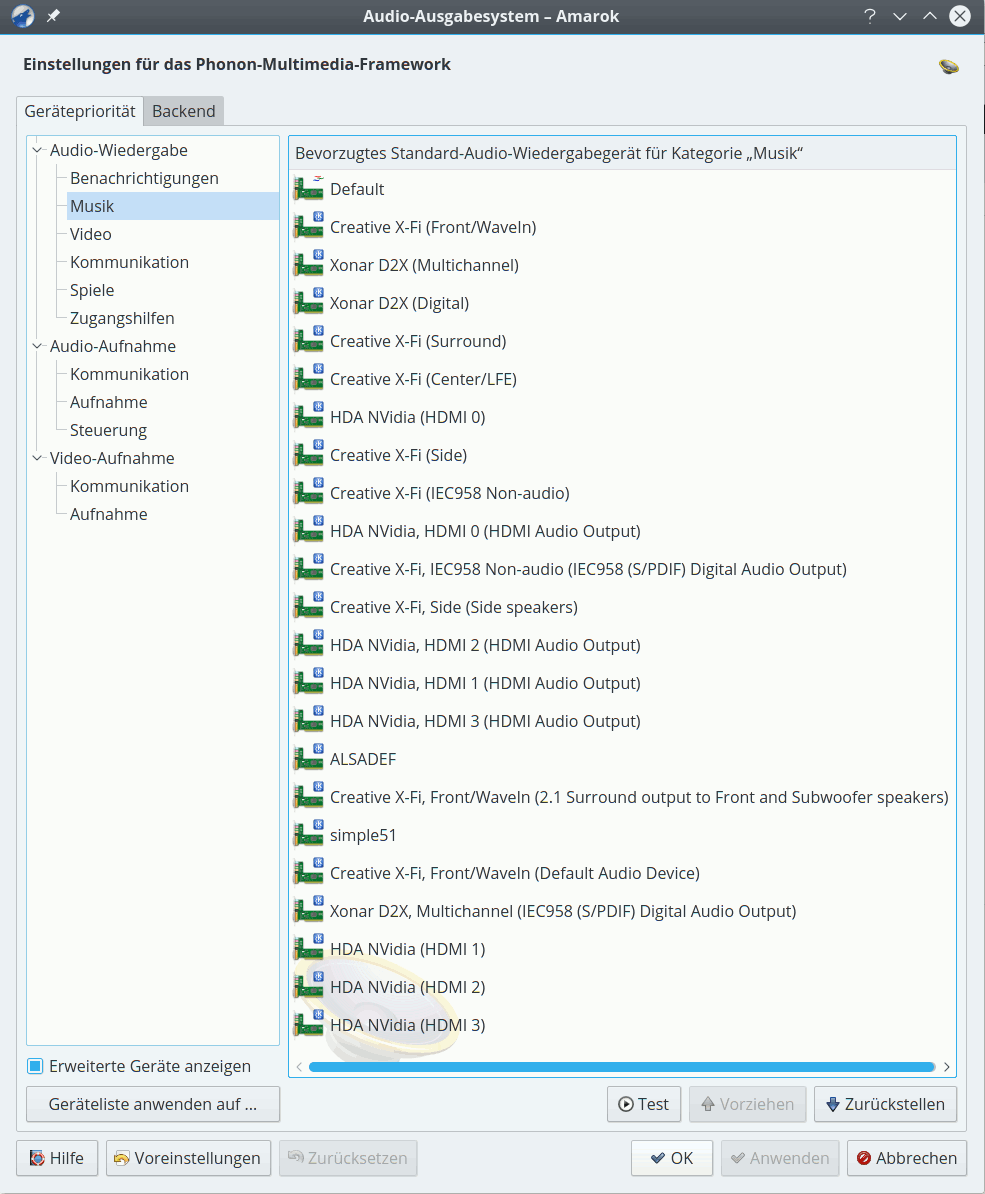
Es liegt also nicht an der Hardware, nicht am Alsa-System, nicht am Gstreamer-Backend, sondern an irgendwelchen Lücken zwischen der Darstellung der Phonon-Konfiguration unter KDE 5 und Alsa. Da ich zumindest für meine XONAR D2X spezielle Alsa-Profile für den Multikanalbetrieb eingerichtet habe, benötige ich eigentlich die Anzeige der darüber definierten eigenen Alsa-Geräte unter KDE5. Daher mein dringender Appell:
Liebe KDE- und/oder Opensuse-Entwickler: Bitte orientiert euch bei der Programmierung der Masken für die Phonon-Einstellungen nicht ausschließlich an den Features eines (nach wie vor unzureichenden) Pulseaudio-Interfaces. Es gibt Leute, die wollen aus guten Gründen mit einem direkt nutzbaren Alsa-Interface (ohne fehlerhafte Pulseaudio-Zwischenschichten) leben!
Denn auch bei aktiviertem Pulseaudio wird neben den üblichen Problemen (plötzliches Springen auf 100% Lautstärke bei Systemnachrichten; die erzwungene gekoppelte Regelung der Lautstärke von verschiedenen Input und Output-Kanälen, massive Fehler in der Mehrkanal-Regelung, dauerndes ungwolltes Resetten der individuiell gesetzten Lautstärke pro Ausgangskanal auf einen gemeinsamen Wert….) nur eine gebündelte Darstellung von Audiooptionen angeboten – aber nicht die gegliederte Darstellung der alsafähigen Subdevices.
Ich hatte alles in allem erhebliche Probleme, unter Opensuse Leap 42.1 meine Xonar D2X neben der Createive XiFi in der Form zum Laufen zu bringen, wie ich das von Opensuse 13.2 gewohnt war. Aber eine Beschreibung der Schritte
würde diesen Artikel sprengen.
Auch Amarok funktionierte nach der Grundinstallation zunächst überhaupt nicht – auch nicht mit Ogg Vorbis-Dateien. Man muss sich da durchkämpfen. In jedem Fall sollte man eine Reihe von sound-relatierten Paketen auf die unter den Packman-Repositories und im Opensuse Multimedia Repository angebotenen Versionen umstellen. Vorabtests selbst definierter Alsa-Devices sind zumindest im Moment noch über das Phonon-Interface von Amarok (aus dem Packman Repository) möglich
systemd ist unter Leap 42.1 wegen des SLES12-Unterbaus noch auf einem veralteten Stand (Version 210). So stehen die für bestimmte Zwecke (wie Virtualisierung) nützlichen Möglichkeiten zur permanenten Konfiguration von z.B. “veth”-Devices in der Datei “/etc/systemd/network” unter Leap 42.1 noch nicht zur Verfügung (wohl aber unter Tumbleweed; systemd-Version 225).
Zur Umgehung eines Problems mit YaST auf Mehrschirm-Systemen siehe
Opensuse Leap 42.1 – nerviger YaST Bug
Insgesamt komme ich nach nun 2 Monaten intensiver Alltags- und Entwicklungs-Arbeit unter Leap sowie vielen Einzeltests zur Sound/Video-Einrichtung wie dem Ausprobieren von KVM/VMware-WS unter Opensuse Leap 42.1 zu dem Schluss, dass z.B. Opensuse 13.2 mit KDE 4.14 immer noch stabiler läuft als Leap 42.1 und sogar mehr Funktionalität bietet.
Inzwischen nutze ich Leap 42.1 aber zunehmend produktiv.
Dennoch habe ich mich zeitweise schon gefragt, ob ich mich nicht langsam nach einer anderen Distribution umsehen sollte. Vielleicht wechsle ich auf meine alten Tage sogar zum Gnome-Desktop. Da ich z.Z. öfter mal mit Debian- und Kali-Systemen arbeite, zeichnet sich die Richtung schon ab ….