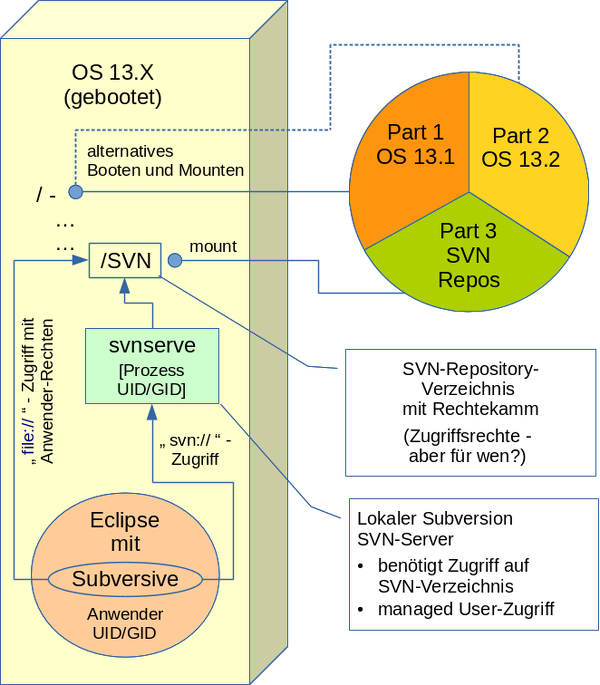
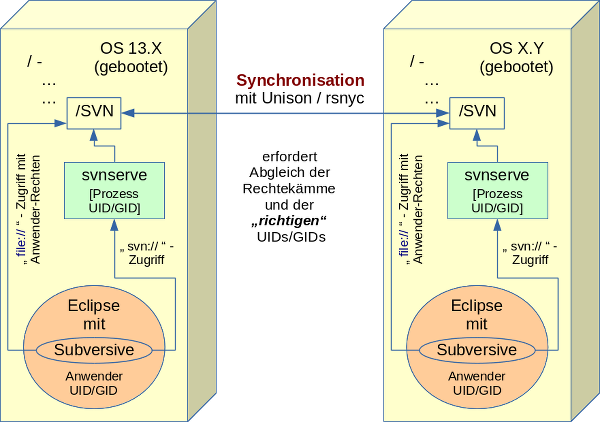
Freunde von uns wissen, dass wir in Sachen Sicherheit individuell analysieren und beraten. Und wir sind dabei sehr zurückhaltend mit pauschalen Rezepten. In einem Blog Artikel zu sicherheitsrelevanten Themen zu starten, beinhaltet daher viele Risiken. Ausschlaggebend für diesen Artikel war die für uns doch etwas schockierende Erfahrung, wie gering auch unter Linux-Freunden die Bereitschaft ist, sich über die Grenzen des eigenen PCs hinaus mit dem Thema Sicherheit des eigenen Netzwerkes zu befassen.
Auch Linux-Freunde haben aber Heimnetzwerke und greifen bzgl. ihrer Internetanbindung auf irgendwelche kommerziellen Router zurück (z.B. von der Telekom, von D-Link, Netgear oder AVM). Etliche dieser Router haben integrierte elementare Firewall-Funktionalitäten auf der Ebene von Paketfiltern mit Stateful Inspection [SI].
Viele Menschen – auch Linuxer – vertrauen die Sicherheit Ihrer PCs, Laptops und mobiler Geräte im Heimnetzwerk dem Schutz durch solche Router an. Aber spätestens nachdem man sich im Internet ein wenig über faktisch aufgetretene Sicherheitsprobleme mit solchen Produkten und/oder entsprechende Begründungen für erforderliche Firmware-Upgrades eingelesen hat, schwindet das Vertrauen in die herstellerabhängigen Technologie ein wenig. Der eine oder andere mag auch – nicht ganz zu Unrecht – fürchten, dass gerade ein Massenware-Produkt kommerzieller DSL-Router-Hersteller ein Objekt ausgiebiger Hacking-Forschungsprojekte von bösen Zeitgenossen und anderen interessierten Datensammlern sein dürfte.
Als Linuxer weiß man dann, dass man sich mit Bordmitteln und ein wenig HW ein Plus an Sicherheit schaffen können müsste. Wie aber den Einstieg finden?
Motive für eine sicherheitsorientierte Auseinandersetzung mit dem Heimnetzwerk
In der heutigen Welt braucht es gar nicht mal Hrn. Snowden oder eine Paranoia, um sich z.B. als Familienvater mit der Sicherheit im Heimnetzwerk auseinanderzusetzen. Es reichen einfache Überlegungen wie :
Wie gehe ich eigentlich mit den ganzen Mobile-Geräten meiner Kinder um? Und jenen von Gästen? Darf eigentlich ein Smartphone mein teures NAS-System mit vielen Services und all meinen Dokumenten und Photos zugreifen?
Wer in seinem IT-Leben zudem mal ganz real mit Viren und Trojanern konfrontiert war und wer sich mal Logs einer Firewall eines im Internet exponierten Systems angesehen hat, ahnt zumindest, dass das Netz nicht wirklich dein Freund ist. So auch ein (ambitionierter) Linux-Fan und Freund von uns, dessen Kinder inzwischen ihr eigenes (hoffentlich betreutes) IT-Leben auf PCs, Tablet PCs und Smartphones leben. Die Kids sollen sich aber natürlich nicht auf den Rechnern der Eltern, die z.T. ja auch zuhause professionell genutzt werden, tummeln. Das Gleiche gilt natürlich auch für die elektronischen Begleiter von Gästen. Es gehört inzwischen ja (leider !) zum guten Ton, dass fast jedermann bei Besuchen auf das hauseigene WLAN Zugriff bekommt. Leider können die Folgen solcher Freizügigkeit schlimm sein …
Der erste Schritt – Netzwerk-Segmentierung
Wie kann man also als Linux-Anhänger sein Heimnetzwerk mit relativ geringen Investitionsmittel und “etwas” Gehirnschmalz sicherer machen? Darüber hatte ich mit unserem Bekannten einige z.T. heftige Diskussionen. Auffällig war dabei für mich, wie wenig eigentlich auch Linux-affine Menschen im privaten Bereich über ihre Netzwerk-Gestaltung nachdenken oder nachdenken wollen. Da kommen dann in mehrfacher Hinsicht falsche und auch irrelevante Argumente wie : Virenschutz braucht man ja nicht auf Linux-Systemen! Die Lageeinschätzung ändert sich meist erst dann, wenn man mal (u.a.) visualisiert,
- welche Verbindungen die liebgewonnen smarten elektronischen Begleiter z.T. ungefragt aus dem eigenen Netz heraus zu Servern im Internet (und
in anderen Ländern mit anderen Gesetzen) aufmachen,
- welche Broadcasts und Multicast-Pakete im Netz herumschwirren und nach Antworten suchen und sie möglicherweise auch von einem Linux-System bekommen
- und welchem Ansturm der DSL-Router von außen so ausgesetzt ist.
Schöne Aha-Effekte erhält man auch, wenn man das Ergebnis von Scans mit “nmap/zenmap” graphisch aufbereitet darstellt oder einen gezielten (und vom Hausherrn erlaubten) Angriff mittels Metasploit auf einen Windows-PC demonstriert.
Neben dem Risiko, das von WLAN-Gästen ausgeht, kann man natürlich auch diskutieren, dass und wie ein Windows-Rootkit beginnen kann, die Netzwerk-Umgebung samt den offenen Ports auf den Linux-Systemen auszuforschen. Mit nachfolgenden Konsequenzen …
Plötzlich tritt dann die gefürchtete Komplexität der zu planenden Punkte wieder in relatives Gleichgewicht mit den erkannten Risiken. Z.B. Risiken durch den Windows-Laptop des Freundes des Tochter, auf dem ja “nur” im Internet gespielt oder gechattet wird. [Oder im Betriebsnetz: Risiken durch den netten externen Berater, der sich selbstverständlich an das Firmennetz ankoppeln darf.]
Aus meiner Sicht ist (trotz des Protests unseres Bekannten) eine ordentliche Segmentierung des Heimnetzwerks ein erster wichtiger Schritt in Richtung organisierter Verbesserung von Sicherheit. Wieso muss hinter einem DSL-Router eigentlich jedes am WLAN angemeldete (Android-) oder Windows-Gerät jeden PC, jedes NAS-System oder gar Server im heimischen Netz sehen können? Persönlich orientiere ich mich bei Sec-Themen immer an der folgenden Reihenfolge von Fragen:
- Wer darf denn überhaupt mit wem ?
- Mit welcher Netzwerkanbindung? Auf welchem Kanal/Port und mit welchem Protokoll?
- Welche Kriterien muss die Nutzlast der Kommunikation ggf. erfüllen?
- Was muss ich dann tun, um das einzelne System gegenüber spezifischen, z.T. betriebssystem- und applikationsspezifischen Bedrohungen und gegenüber Malware abzusichern?
Warum in dieser (diskutierbaren) Reihenfolge? Schlicht und einfach: Ein kompromittiertes System darf zumindest nicht “kampflos” zum Risiko für andere Systeme werden.
In dieser Artikelserie geht es mir lediglich um Punkt 1. Dabei habe ich jedoch fast ein schlechtes Gewissen – denn Sicherheit umfasst auch und gerade im heterogenen Heimnetzwerk wahrlich mehr als Netzwerk-Segmentierung. Aber irgendwo muss ja auch der ambitionierte Linux-Heimwerker anfangen …
Vielleicht ist der folgende Überblick über den entstehenden Segmentierungsansatz bei unserem Bekannten ja auch für andere interessant. Ein Anwendungsfall könnten z.B. Heimnetzwerke von Freiberuflern oder Ärzten, Psychologen und Rechtsanwälten sein, die auch zu Hause Ihrer Arbeit nachgehen und für deren Patientendaten schon wegen einschlägiger Datenschutzrichtlinien ein hoher Schutzbedarf besteht.
Ich gehe in zwei Artikeln dieser kleinen Serie wie gesagt nur auf eine mögliche, grundsätzliche Netzsegmentierung ein. Alles weitere würde uns dann in die Detail-Konfiguration einiger Netzwerkdienste (wie etwa DHCP, DNS und ggf. Samba) und vor allem aber das Aufsetzen hinreichender iptables-Regeln führen. Ich kann entsprechende Details leider schlecht in einem Blog diskutieren. Das Gleiche gilt für IDS-Verfahren. Wer daran ernsthaft interessiert ist, mag – wie unser Bekannter – ein kleines Projektchen mit mir aufsetzen. Ich gehe hier auch nicht auf Anonymisierungsverfahren bzgl. des Surfens im Internet ein. Das mag enttäuschend für den einen oder anderen Leser sein, aber meine verfügbare Zeit für den Blog ist schlicht und einfach begrenzt.
(Alte) HW für ein zusätzliches Gateway-System mit Firewall aktivieren
Als Linuxfreund zieht man
ggf. eine betagte PC-Kiste aus der Versenkung und überlegt sich, den anderen Systemen im Heimnetzwerk (wie PCs, Laptops u.a.) mit Hilfe dieses Geräts noch eine Linux-Firewall als zusätzliche Barriere im Umgang mit dem Internet zu spendieren. Die Kosten für ein bis zwei zusätzliche Netzwerkkarten sind ja relativ gering. Hat man noch ein wenig mehr Geld, so kann man auch auf den Gedanken kommen, neben dem WLAN, das auf heutigen DSL-Routern mit angeboten wird, ein weiteres WLAN zu etablieren, auf das z.B. Gäste keinen Zugriff erhalten. Dazu braucht es dann einen separaten WPA2-gesicherten WLAN-Router oder besser WLAN-Access-Point.
Netzwerk-Segmentierung
In der Diskussion mit meinem Bekannten entstand dann das folgende Bild seines künftigen Heimnetzwerkes mit einer Reihe von erkennbaren Segmenten:
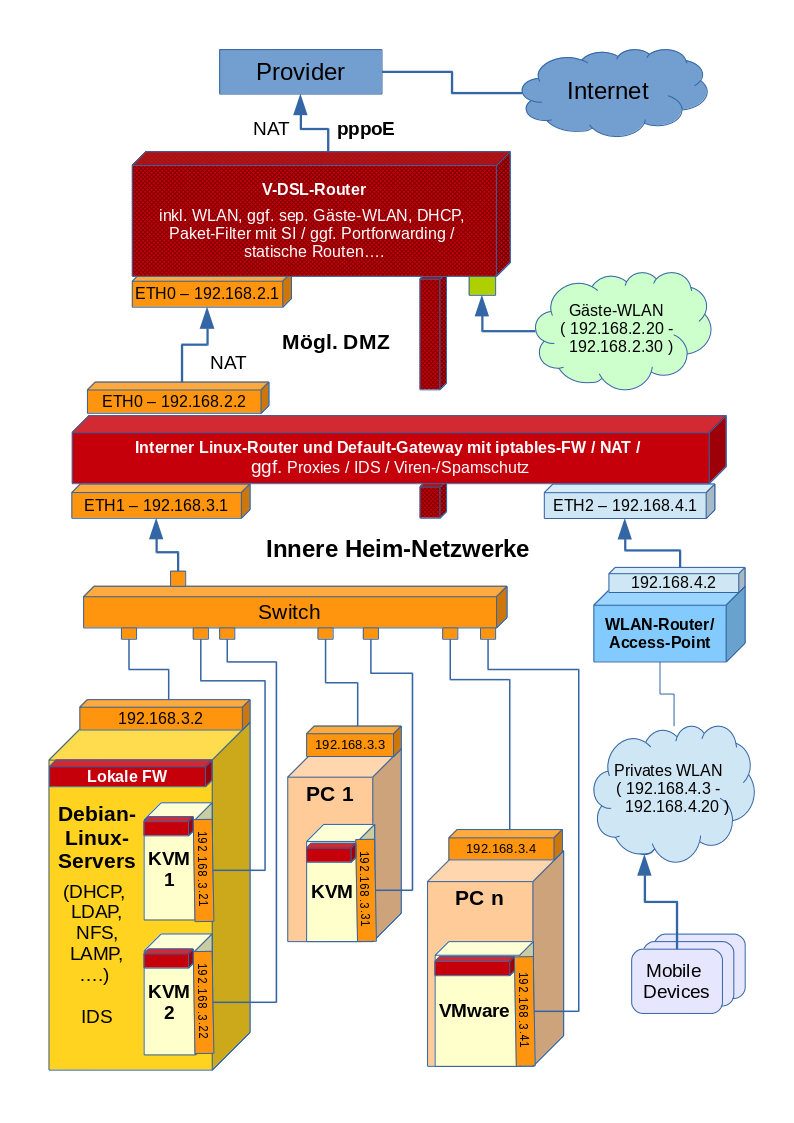
Ich habe das Bild gegenüber der Realität etwas angereichert, um zu verdeutlichen, dass man es in einem z.T. professionell genutzten Heimnetzwerk oder in einer kleinen Firma auch ganz schnell mal mit Systemen zu tun haben kann, die auf Virtualisierungshosts laufen. Der eine Server steht dann stellvertretend für mehrere (spezialisierte) Server und auch die zwei PCs sind nur Stellvertreter für mehr Geräte ihrer Klasse.
Das Ganze ist dann doch schon relativ komplex und nähert sich der Struktur eines kleinen Firmennetzes an. Ich kenne einige kleinere Firmen, für die das Bild strukturell ziemlich ähnlich wäre. Allerdings sind bestimmte Systeme dann durch gewartete Sicherheits-Appliances ersetzt oder ergänzt und zudem spielen VPNs eine große Rolle. Der Linux-Heimwerker kann sich teure Appliances jedoch nicht ohne weiteres leisten.
Die Crux des Ganzen – Was nützen Segmente ohne Kommunikations- und Filterregeln?
Ehrlich gesagt: wenig. Damit sind wir auch bei dem Punkt, durch den sich auch unser Bekannter in unseren Diskussionen abgeschreckt gefühlt haben dürfte. Wer wie mit wem in dem oben darzustellenden Netzwerk kommunizieren und wer welchen Service nutzen darf, ist zum großen Teil ein Sache sinnvoll und sicher aufgesetzter Paketfilter-Regeln. Hierbei kommt dem Paketfilter auf dem inneren Router-System eine besondere Bedeutung zu. Aber auch einfache, zusätzlich aktivierte “vereinfachte” Firewalls wie etwa die “SuseFirewall2” kann einem auf dem einen oder anderen System innerhalb des inneren Netzwerks schon mal gehöriges Kopfzerbrechen bereiten.
Die Logik ineinandergreifender iptables-Regeln auf verschiedenen Systemen mit speziellen betriebssystem-spezifischen “Personal Firewalls” (z.B. auf Windows-Laptops) kann je nach Situation beliebig komplex werden und ist sicher nicht jedermanns Sache. Das ist keine Abschreckung sondern eine auf Erfahrung gegründete vorsichtige Warnung:
In iptables – und erst Recht das Zusammenspiel von iptables-Regeln mit Firewall-Settings auf anderen Systemen – muss man sich reinknien.
Man kann dabei zudem Fehler machen. Speziell, wenn man bestimmte Linux-, Windows und ggf. Android-Systeme an so schöne Dinge wie File-, Mail und Web-Dienste auf einem zentralen Heimserver ranlassen will. Geht es wirklich um erhöhten Sicherheitsbedarf, so ist das Regelwerk ferner durch Analyse- und Penetrationswerkzeuge einem Belastungstest auszusetzen. Ferner kommt gerade bei Android und Windows Punkt 4 unser obigen Checkliste und die Konfiguration spezieller kommerzieller Produkte zum Tragen. Spätestens dann werden Grenzen für den Hobby-Linux-Bastler erkennbar.
Ich kann und will die iptables-Regeln für die einzelnen Maschinen des nachfolgend skizzierten Netzes nicht im
Rahmen der dieses und des kommenden Blog-Beitrags diskutieren. Das heißt aber nicht, dass man als Linux-Interessierter gleich die Segel streichen müsste. Zu iptables gibt es am Markt sehr gute Bücher. Ferner gibt es graphische Hilfsmittel. Obwohl ich den aktuellen Pflegestatus des SW-Pakets nicht so richtig einschätzen kann, empfinde ich “FWBuilder” nach wie vor als ein Opensource Programm, das den iptables-Einstieg doch sehr erleichtert – auch wenn die generierten Regelsätze manchmal im Internet und in Fachartikeln kritisiert wurden. Die durch FWBuilder generierten Chains und Regeln stellen aus meiner Sicht jedenfalls eine brauchbare Grundlage für evtl. weitergehende Verbesserungsarbeiten dar.
Also -liebe Linux-Heimwerker: Kauft euch ein iptables-Buch, fangt mit FWBuilder an und habt vor allem Spaß an eurem privaten Sicherheitsprojekt !
iptables scripts und systemd?
Nun hat man es wegen “systemd” im Moment leider nicht mehr ganz so leicht, seine mit welchem Tool auch immer erstellten iptables-Regeln beim Systemstart auch zu aktivieren. Deshalb werde ich in einem dritten Beitrag dieser kleinen Serie kurz darauf eingehen, wie man ein iptables-Generator-Skript auf einfach Weise in den systemd-gesteuerten Startablauf einbauen kann.
Im nächsten Beitrag gehe ich zunächst auf die vorgeschlagenen Segmente und Gründe für deren Abtrennung ein. Bis dann!