As a scientist you have to learn and accept that our perception of the world and of the rules governing it may reflect more of our genetically designed and socially acquired prejudices than reality. Scientist go through a long training to mistrust our prejudices. They instead try to understand reality on a deeper level of experimental tests combined with the building of theories and verifiable predictions. On this background I want to discuss a specific aspect in the presently heated debate about the alleged dangers of A(G)I. An aspect which I think is at least in parts misunderstood and not grasped at its full extend.
A typical argument in the discussion, which is used to underline a critical view on AI, is: “AI as e.g. in the form of GPT4 makes things up. Therefore, we cannot trust it and therefore it can be dangerous.” I do not disagree. But the direction of the critics misses one important point: Are we humans actually better?
I would clearly say: Not so much as we like to believe. We still have a big advantage in comparison with AI: As we are embedded into the physical world and interact with it we can make clever experiments to explore underlying patterns of cause and action – and thus go beyond the detection of correlations. We also can test our ideas in conversations with others and in confrontation with their experiences. Not only in science, but in daily social interaction. However, to assume that we humans do not confabulate is a big mistake. Actually, the fact that large language models (and other models of AI) often “hallucinate” makes them more similar to human beings than many of newspaper journalists are willing to discuss in their interviews with AI celebrities.
Illustration: “Hallucinations” of a convolutional network trained on number patterns when confronted with an image of roses
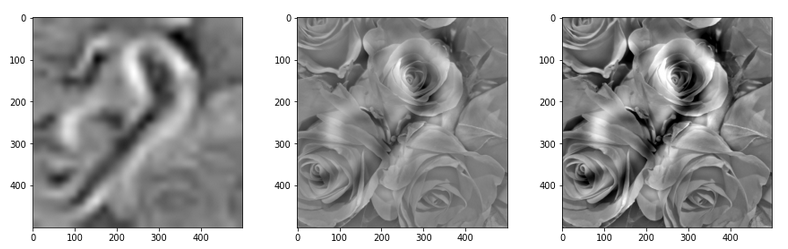
Experiments in neurosciences and psychology indicate that we human beings probably confabulate almost all the time. At least much more often than we think. Our brain re-constructs our perception of the world according to plausibility criteria trained end developed both during evolution of mankind and during our personal life. And the brain presents us manipulated stories to give us a coherent and seemingly consistent view upon our interactions with reality and the respective time-line added to our memories.
You do not believe in a confabulation of our brain? Well, I do not want to bore you with links to a whole bunch of respective literature published during the last 3 decades on this subject. Sometimes simple things make the basic argument clear. One of these examples is an image that got viral on social media some years ago. I stumbled across it yesterday when I read an interview of the Quanta Magazine with the neuroscientist Anil Seth about the “nature of consciousness”. And I had a funny evening afterward with my wife due to this picture. We had a completely different perception of it and its displayed colors.
The image is “The dress” of Cecilia Bleasdale. You find it in the named and very informative interview of the Quanta Magazine. You also find it on Wikipedia. I refrain from showing it, as there may be legal right issues. The image displays a skirt.
A lot of people see it as an almost white skirt with golden stripes. Others see it as a blue skirt with almost black stripes. Personally, I see it as a lighter, but clearly blue skirt with darker bronze/golden stripes. But more interesting: My wife and I totally disagreed.
We disagreed on the colors both yesterday night and this morning – under different light conditions and looking at the image on different computer screens. Today we also looked at hex codes of the colors: I had to admit that the red, green, blue mixture in total indicates much darker stripes than I perceive them. But still the dominant red/green combination gives a clear indication of something of a darker gold. The blue areas of the skirt are undisputed between me and my wife, although I seemingly perceive it in a lighter shading than my wife.
This is a simple example of how our brain obviously tells us our own individual stories about reality. There are many other and much more complex examples. One of the most disputed one is the question of whether we really control our intentional behavior and related decisions at a period around the decision making. A whole line of experiments indicates that our brain only confabulates afterward that we were in control. Our awareness of decisions made under certain circumstances appears to be established some hundred milliseconds after our brain actually triggered our actions. This does not exclude that we may have a chance of control on longer timescales and by (re-) training and changing our decision making processes. But on short timescales our brain decides and simply acts. And this is good so. Because it enables us to react fast in critical situations. A handball player or a sword fencer does not have much time to reflect his or her actions; sportsmen and sportswomen very often rely on trained automatisms.
What can we be sure about regarding our perceptions? Well, physical reality is something different than what we perceive via the reaction of our nerve system (including the brain) to interactions with objects around our bodies and resulting stimuli. Or brain constructs a coherent perception of reality with the help of all our senses. The resulting imagination helps us to survive in our surroundings by permanently extrapolating and predicting relatively stable conditions and evolution of other objects around us. But a large part of that perception is imagination and our brain’s story telling. As physics and neuroscience has shown: We often have a faulty imagination of reality. On a fundamental level, but often enough also on the level of judging visual or acoustic information. Its one of the reasons why criminal prosecutors must be careful with the statements of eye-witnesses.
Accepting this allows for a different perspective on our human way of thinking and perceiving: Its not really me who is thinking. IT, the brain – a neural network – is doing it. IT works and produces imaginations I can live with. And the “I” is an embedded entity of my imagination of reality. Note that I am not disputing a free will with this. This is yet another and more complex discussion.
Now let us apply this skeptical view on human perception onto today’s AI. GPT without doubt makes things up. It confabulates on the background of already biased information used during training. It is not yet able to check its statements via interactions with the physical world and experiments. But a combination of transformer technology, GAN-technology and Reinforcement Learning will create new and much more capable AI-systems soon. Already now interactions with simulated “worlds” are a major part of the ongoing research.
In such a context the confabulations of AI-systems make them more human than we may think and like. Let us face it: Confabulation is an expected side aspect on our path to future AGI-systems. It is not a failure. Confabulation is a feature we know very well from us human beings. And as with manipulative human beings we have to be very careful with whatever an AI produces as output. But fortunately enough AI-systems do not yet have an access to physical means to turn their confabulations into action.
This thought, in my opinion, should gain more weight in the discussion about the AI development to come. We should much more often ask ourselves whether we as human beings fulfill the criteria for a conscious intelligent system really so much better than these new kinds of information analyzing networks. I underline: I do not at all think that GPT is some self-conscious system. But the present progress is only a small step at an early stage of the development of capable AI. Upon this all leading experts agree. And we should be careful to give AI systems access to physical means and resources.
Not only do researchers see more and more emergent abilities of large language networks aside those capabilities the networks were trained for. But even some of the negative properties as confabulation indicate “human”-like sides of the networks. And there are overall similarities between humans and some types of AI networks regarding the basic learning of languages. See a respective link given below. These are signs of a development we all should not underestimate.
I recommend to read an interview with Geoffrey Hinton (the prize-winning father of back-propagation algorithms as the base of neural network optimization). He emphasizes the aspect of confabulation as something very noteworthy. Furthermore he claims that some capabilities of today’s AI networks already surpass those of human beings. One of these capabilities is obvious: During a relatively short training period much more raw knowledge than a human could process on a similar time scale gets integrated into the network’s optimization and calibration. Another point is the high flexibility of pre-trained models. In addition we have not yet heard about any experience with multiple GPT instances in a generative interaction and information exchange. But this is a likely direction of future experiments which may accelerate the development of something like an AGI. I give a link to an article of MIT Technology Review with Geoffrey Hinton below.
Links and articles
https://www.quantamagazine.org/ what-is-the-nature-of-consciousness-20230531/
https://slate.com/ technology/ 2017/04/ heres-why-people-saw-the-dress-differently.html
https://www.theguardian.com/ science/ head-quarters/ 2015/feb/27/ the-dress-blue-black-white-gold-vision-psychology-colour-constancy
https://www.technologyreview.com/ 2023/05/02/ 1072528/ geoffrey-hinton-google-why-scared-ai/
https://www.quantamagazine.org/ some-neural-networks-learn-language-like-humans-20230522/
