
Gestern ist mir ein dummer Fehler passiert, dessen Analyse mich Zeit gekostet hat. Dabei erwies sich die Sache am Ende als trivial. Es ging letztlich um konsistente Zeichensatzeinstellungen für PHP und MySQL – allerdings mit einem mir bislang unbekannten Nebeneffekt.
Zeichensätze im Kontext von PHP und MySQL sind ein Thema vieler Foren- und Q&A-Artikel im Internet – und nicht immer trifft man auf zufriedenstellende Antworten. Ich hoffe, dieser Artikel trägt anhand eines Beispiels zu etwas mehr Klarheit bei.
Voraussetzungen und aufgetretener Fehler
Unsere hausinternen Apache- und Datenbank-Server laufen normalerweise vollständig unter UTF-8. Inklusive der eigenen Datenbank- und Tabellen-Kollationen unter MySQL- oder MariaDB-Systemen. Aber für Tests müssen wir immer mal wieder gezielt eine Kompatibilität zu den festgelegten Kollationen für MySQL-Banken/Tabellen auf Kundenservern herstellen. Meist kommt dann Latin1 (iso-8859-1) ins Spiel.
Gestern mussten wir für einen solchen Test Datensätze eines von uns entwickelten, php-basierten CMS von einem gehosteten MySQL-Kundenserver in unsere lokale Test-Datenbank übernehmen. Diese Datensätze beinhalteten viele Text-Strings mit deutschen Umlauten. Da es sich nur um wenige Records handelte, haben wir die Daten in diesem Fall mit Copy/Paste und mit Hilfe von Eingabefeldern unserer CMS-Verwaltungsoberfläche übernommen. Das CMS lief dabei unter einer lokalen UTF8-Standarddomäne. Unsere aktuellen CMS-Programme zeigten die fraglichen Textstrings denn auch korrekt in der Web-Oberfläche des CMS an.
Es gab aber andere zu untersuchende Punkte im Layout. Um die Unstimmigkeiten zu testen, haben wir zusätzlich eine separate Testdomäne angelegt und diverse PHP-Klassen vom Kundenserver (auf dem dortigen Versionsstand) in bestimmte Verzeichnisse des zugehörigen Web-Spaces auf unserem lokalen Server geladen. Ergebnis: 2 Domainen mit z.T. unterschiedlichen Versionsständen von PHP-Klassen.
Und dann passierte es:
Bei einem Aufruf der Webseiten in der Testdomäne verschwanden plötzlich fast alle Text-Strings aus der Web-Oberfläche.
Bilder und grundsätzlicher Aufbau der Webseiten bleiben jedoch erhalten. Ich war zunächst völlig verblüfft über diesen Effekt. Zumal der Einsatz unserer lokalen Versionen der gleichen PHP-Klassen kein Verschwinden der Textstrings zeitigte.
Die Analyse war nicht ohne, da ich zunächst nicht wusste, wonach ich zu suchen hatte. Man denkt da zunächst natürlich an Unterschiede im Programmcode selbst. Am Schluss entpuppten sich aber eine im wesentlichen unmodifizierte Klasse, die die Datenbankverbindung steuert, sowie eine Klasse, die die Strings aus Sicherheitsgründen nach unerlaubten Sequenzen filtert, als Kerne des Übels. Ausschlaggebend waren allerdings nicht Programmunterschiede sondern bestimmte Parameter-Setzungen sowie Server- und Zeichensatzeinstellungen. Aber der Reihe nach.
Zeichensatzeinstellungen in der Kommunikationskette zwischen einem PHP-Server und einer MySQL-Datenbank
In der Datenaustausch-Kette zwischen einer MySQL-Datenbank und PHP-Modulen auf einem Web-Server (und natürlich auch bei der Übersendung eines HTML-/XML- oder JSON-Outputs an Web-Clients) spielen verschiedene Zeichensatzeinstellungen eine Rolle. Einige davon können vom Entwickler beeinflusst werden. Andere wiederum nicht immer.
Für unseren Fall waren vor allem die nachfolgenden Punkte relevant; sie betreffen den Web-Server (mit PHP-Modul) und die MySQL-Datenbank:
- Zeichensätze (“Kollationen”) der MySQL-Datenbank und zugehöriger Datenbanktabellen.
- Zeichensatz-Vorgaben zur MySQL-Verbindung und zum Datentransfer von und zu (PHP-)Programmen, die mittels der SQL-Direktive “SET NAMES” vorgenommen wurden.
- Einstellungen für den Default-Character-Set des PHP-Apache-Moduls.
- Zeichensatzeinstellungen für die PHP-Funktion “htmlentities()”.
Zeichensätze in der Datenbank und die Direktive “SET NAMES”
Für die Kollation der relevanten MySQL-Datenbank und ihrer Tabellen war auf dem Kundenserver “latin1_german2_ci” gewählt worden. Unsere Einstellungen im lokalen Testsystem waren dazu auf Tabellenebene kompatibel. Die Kollation einer Datenbanktabelle bestimmt letztlich aber nur die interne Ablage der Daten in der Tabelle und nicht den Zeichensatz, unter dem z.B. per SQL ermittelte Resultsets an weiterverarbeitende Programme übermittelt werden.
Für letzteres sind andere Parameter verantwortlich, die man als Entwickler für eine spezifische Verbindung zur MySQL-Datenbank einstellen kann. Unter MySQL und der MariaDB nutzt man dafür etwa die SQL-Direktive “SET NAMES” (oder aber die Funktion mysqli_set_charset(); s.u.).
“SET NAMES” führt zur gleichzeitigen Festlegung dreier RDBMS-Parameter für die Behandlung einer spezifischen Datenbankverbindung. Diese Parameter sind: character_set_client, character_set_connection, character_set_results.
Siehe hierzu etwa
https://dev.mysql.com/doc/refman/5.7/en/set-names.html
und
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_character_set_results.
Die Datenbankverbindung wird unter dem PHP/mysqli-Interface dabei über das Connection-Objekt
$dbi = mysqli_connect(….)
identifiziert. Im Wesentlichen legen die genannten Parameter Folgendes fest:
- character_set_client: Zeichensatz, unter dem Daten, die vom Datenbank-Client zum RDBMS-Server transferiert werden, interpretiert werden.
- character_set_connection: Handhabung bestimmterErsetzungen und Konversionen, u.a. von Numbers zu Strings.
- character_set_results: Zeichensatz, unter dem Daten, die vom RDBMS zu Client-Programmen übermittelt werden interpretiert werden.
Der “Client” ist in unserem Fall natürlich ein PHP-Programm auf einem Apache-Server. Die Anwendung des “SET NAMES”-Statements durch ein PHP-Programm, z.B.
$sql_unames = “SET NAMES ‘utf8′”;
$this->dbi->query($sql_unames);
//dbi->Datenbank-Connection Object
//$this->dbi = mysqli_connect(….)
ist somit von zentraler Bedeutung für die Kommunikation zwischen einem PHP-Programm und einer MySQL/MariaDB! Solange eine hinreichende Konvertierung verwendeter Zeichen gewährleistet ist, muss der Zeichensatz, unter dem Resultsets zum PHP-Programm übermittelt werden, nicht zwingend mit dem der Datenbanktabellen selbst identisch sein.
Es sei darauf hingewiesen, dass es zu “SET NAMES” auch Alternativen gibt, die man im Rahmen des mysqli-Interfaces einsetzen kann und sollte (s.u.). Dass wir in einigen Programmen noch SET NAMES verwenden, hat lediglich historische Gründe. Die hier beschriebene Problematik gilt aber unabhängig vom genauen Werkzeug zur Einstellung der Zeichensatzparameter.
Konsistenz zu Zeichensatzvorgaben für PHP – Einstellungen in der php.ini
Das PHP-Programm muss in jedem Fall mit dem gewählten Zeichensatz für Resultsets adäquat umgehen können; s.u.. Der rechte Bereich der folgenden Skizze, die ich aus einem anderen Artikel dieses Blogs entliehen habe, verdeutlicht das für den Fall “SET NAMES ‘latin1′” :
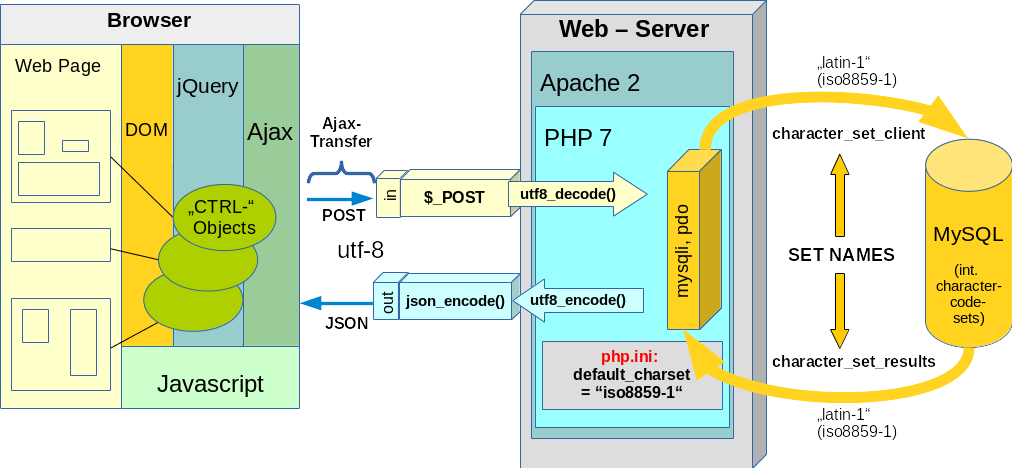
Nun könnte man in seinen PHP-Programmen natürlich spezifische Umwandlungsfunktionen (u.a. iconv(), mb_convert_encoding(), utf8-encode(), utf8-decode) für die Zeichensatzkonvertierung aus- und eingehender Strings bemühen. Die linke Seite der Skizze liefert hierfür Beispiele (s. den dazu gehörigen Abschnitt weiter unten).
Wenn möglich, kann man aber auch einen Standardzeichensatz für die PHP-Verarbeitung von Strings vorgeben und sich darauf bzgl. der Datenbankinteraktion verlassen.
Entsprechende Einstellungen nimmt man in der Konfigurationsdatei
/etc/php7/apache2/php.ini
vor. Die relevanten Parameter sind dort:
; PHP's default character set is set to UTF-8. ; http://php.net/default-charset default_charset = "UTF-8" ; PHP internal character encoding is set to empty. ; If empty, default_charset is used. ; http://php.net/internal-encoding ;internal_encoding = ; PHP input character encoding is set to empty. ; If empty, default_charset is used. ; http://php.net/input-encoding ;input_encoding = ; PHP output character encoding is set to empty. ; If empty, default_charset is used. ; mbstring or iconv output handler is used. ; See also output_buffer. ; http://php.net/output-encoding ;output_encoding =
Die hierfür gesetzten Werten sollte natürlich mit den Einstellungen für die Datenbankverbindung zusammenpassen.
Kundenvorgaben
Wir parametrieren in Kundenprojekten die PHP-Methoden für den Verbindungsaufbau zum Datenbankserver meist gemäß expliziter Kundenvorgaben. In unserem Fall hatten wir “SET NAMES ‘latin1′” gewählt. (Hinweis: Die Zeichensatz-Namen auf einem MySQL-Server enthalten grundsätzlich keine Trennzeichen; daher ist statt iso8859-1 “latin1” zu verwenden).
Der Grund dafür war, dass das Apache-PHP-Modul des (gehosteten) Kunden-Web-Servers auf “iso-8859-1” eingestellt war. Das bestätigte eine Überprüfung mit phpinfo(). Diese Einstellungen sollten wir gem. Kundenvorgabe nicht ändern, da auf dem Web-Server auch andere PHP-Programme als unsere eigenen laufen müssen.
Auf dem Kundenserver waren die Zeichensatzeinstellungen also konsistent.
Ursache unseres Problems und die Rolle von htmlentities()
Man ahnt es bereits: Durch das Kopieren der PHP-Klasse für die Steuerung von Datenbankverbindungen vom Kundenserver auf die Testdomäne unseres lokalen Web-Servers entstand dort u.a. eine Inkonsistenz zwischen der Zeichensatzbehandlung unter PHP (utf8!) und dem Zeichensatz für den Transfer von Resultsets aus der MySQL-Datenbank (latin1).
Diese Inkonsistenz kam jedoch noch nicht zum Tragen, als wir die Daten per Copy/Paste über lokale Web-Interfaces einer UTF8-Standard-Domäne in die Bank einbrachten.
Für unsere Testdomäne dagegen muss man jedoch u.a. eine fehlerhafte Konvertierung von deutschen Umlauten erwarten! Warum aber verschwanden die Text-Strings in Gänze aus den Web-Oberflächen?
Die Antwort lieferte schließlich eine von mir bislang zu wenig beachtete Eigenschaft der PHP-Funktion “htmlentities()”.
Unsere Web-Generatoren jagen Strings vor einer Web-Darstellung durch eine Reihe von Prüfroutinen, Transformatoren für erlaubte Zeichenfolgen und durch Filter (u.a. HTMLPurifier, aber auch eigene Filter). Dabei wird in einem Zwischenschritt (nach einer vorhergehenden Konvertierung erlaubter HTML-Zeichenfolgen) auch “htmlentities()” eingesetzt.
htmlentities() erlaubt selbst eine Vorgabe des “Character Sets” über einen Parameter. Ein Check zeigte: Dieser Parameter stand in der lokalen Testdomäne explizit auf “UTF-8”. Diese Einstellung betrifft jedoch eine Konvertierung in den gewünschten Ziel-Zeichensatz für den HTML-Output. Hier hatten wir kein Problem, da die
HTML-Header der Webseiten bzw. die vom Apache-Server generierten HTTP-Header tatsächlich auf UTF-8 ausgerichtet waren.
Allerdings sorgten schon die vorhergehenden Widersprüche zwischen dem Zeichensatz der Datenbank-Resultsets und dem Zeichensatz für die anschließende Behandlung von Strings durch PHP. Das hatte gravierende Folgen. Unter http://php.net/manual/de/function.htmlentities.php findet man nämlich folgenden Hinweis:
Rückgabewerte
Gibt die kodierte Zeichenkette zurück. Enthält der string eine in dem übergebenen encoding ungültige Code Unit Sequenz, wird eine leere Zeichenkette zurückgegeben, sofern weder das ENT_IGNORE noch das ENT_SUBSITUTE Flag gesetzt sind.
(Hervorhebung durch mich).
Das war des Rätsels Lösung:
Eine Inkonsistenz in der Zeichensatzbehandlung im Datenaustausch zwischen unserer MySQL-Datenbank und PHP führte zu nicht behandelbaren Zeichen bei der Anwendung von htmlentities() auf Strings – und diese Funktion produzierte dann gemäß ihrer Default-Einstellungen leere Strings.
Trivial – man muss es halt nur wissen! Ein Test mit
“SET NAMES ‘utf8′”
ließ denn alle verschwundenen Strings auch in unserer Testdomäne prompt wieder erscheinen!
Notwendige Checks vor der Anwendung von SET NAMES (oder von mysqli_set_charset())
Hat man die Kette der Zeichensatzsetzungen bzw. Zeichensatzbehandlung im Austausch zwischen PHP und einer MySQL-Datenbank erst einmal verstanden, so ist auch klar, wo man mit vorbeugenden Maßnahmen ansetzen kann. Solche Vorkehrungen sind – wie das Beispiel zeigt – vor allem dann notwendig, wenn man die Zeichensatz-Einstellungen für PHP nicht auf allen involvierten Web-Servern beeinflussen kann oder darf.
Bevor man “SET NAMES” (oder mysqli_set_charset(); s.u.) in einem PHP-Programm tatsächlich anwendet, sollte man die Setzung des “Default Character Sets” in der php.ini für den aktuellen Server explizit abfragen – mittels
ini_get(‘default_charset’);
– und dann mit der ebenfalls abfragbaren Kollation der Datenbanktabellen vergleichen. Das Ergebnis dieses Vergleichs kann man dann nach bestimmten Regeln behandeln:
Z.B. Warnhinweise bei (ernsthafter) Inkompatibilität ausgeben. Oder wenn man wirklich sicher ist, dass nur deutsche Umlaute zu potentiellen Problemen führen können: Wahl des zu den PHP-Einstellungen konsistenten Zeichensatzes für den Transfer von Resultsets aus der Datenbank. In unserem Fall also “utf8”.
Alternative: Ändern der php.ini-Vorgaben für den Zeichensatz durch und für das laufende PHP-Programm
Auf festgestellte Inkonsistenzen in den Zeichensatzeinstellungen kann man u.U. – nämlich wenn man die dafür nötigen Rechte besitzt – auch mit einer Modifikation der php.ini-Vorgaben für das laufende Programm reagieren. Dazu muss man natürlich die Funktion ini_set() bemühen; Bsp.:
ini_set( string ‘default_charset’, ‘ISO-8859-1’)
bemühen.
Empfohlener Weg zum Setzen des “Character Sets” für eine MySQL-Verbindung
Ich möchte explizit darauf hinweisen, dass es andere Möglichkeiten als die SQL-Direktive “SET NAMES” gibt, Character Sets für die Datenbankverbindung zu setzen. Das PHP-Manual empfiehlt explizit, die Funktion
mysqli_set_charset(mysqli $link , string $charset)
anstelle von SQL und “Set Names” zu verwenden. Siehe: http://php.net/manual/de/mysqli.set-charset.php
Zeichensätze und die Web-Client-Seite
Obwohl nicht Kernthema dieses Artikels werfen wir noch einen ergänzenden Blick auf den
Datenaustausch des PHP/Web-Servers mit Web-Clients (z.B. einem Browser). Die Zeichensatzthematik setzt sich natürlich auch auf dieser Kommunikationsstrecke fort; der linke Teil der obigen Skizze verdeutlicht das am Beispiel von Ajax/Ajaj-Programmen. Diese erfordern i.d.R. UTF-8 für einen ordnungsgemäßen Datenaustausch mit dem Web-Server.
Ist der Parameter “default_charset” in der php.ini-Datei aber auf “iso-8859-1” gesetzt, so muss man ein- und ausgehende Daten entsprechend konvertieren. Dafür eignen sich die Funktionen utf8_decode() für einlaufende POST-/GET-Daten aus Ajax-Programmen und utf8_encode() bei der Erzeugung des Ajax/Ajaj-Outputs in Richtung Web-Client.
Für reinen HTML-Output gilt analoges; dabei sind aber auch HTTP- und HTML-Header-Anweisungen für Character Sets zu setzen. Siehe hierzu:
http://www.html-info.eu/php/php-als-script-sprache/item/zeichensatz-latin1-oder-unicode-utf-8.html
Fazit
In unbeabsichtigter Weise kann htmlentities() plötzlich zu einer Testfunktion für die Konsistenz zwischen
- der Zeichensatz-Einstellungen durch “SET NAMES” bzw. mysqli_set_charset() für die MySQL/MariaDB-Datenbankanbindung an ein PHP-Programm
- und den Zeichensatzeinstellungen für das PHP-Modul selbst auf dem Webserver
werden – und in letzter Konsequenz zu leeren Strings auf Webseiten führen.
Es lohnt sich vor einem Einsatz von “SET NAMES” – oder besser mysqli_set_charset() – eigentlich immer, die Einstellungen in der “php.ini” bzgl. des “default_charset” und verwandter Parameter abzufragen und daraus angemessene Konsequenzen für den Aufbau der Datenbankverbindung zu ziehen.
Dies gilt vor allem dann, wenn man im Rahmen von Tests und Produktivierungen auf verschiedenen Servern arbeiten will oder muss – und dabei nicht alle Konfigurationsparameter der Server selbst beeinflussen kann und darf.
Neben dem Setzen von Server- und Verbindungsparametern kann man auf festgestellte oder vorgegebene Zeichensatzanforderungen oder Zeichensatzdiskrepanzen aber auch gezielt mit verschiedenen Funktionen reagieren, die PHP für eine Zeichensatz-Detektion und eine explizite Zeichensatzkonvertierung von Strings anbietet.