Im vorhergehenden Artikel dieses Blogs
Opensuse – manuelles Anlegen von Bridge to LAN Devices (br0, br1, …) für KVM Hosts
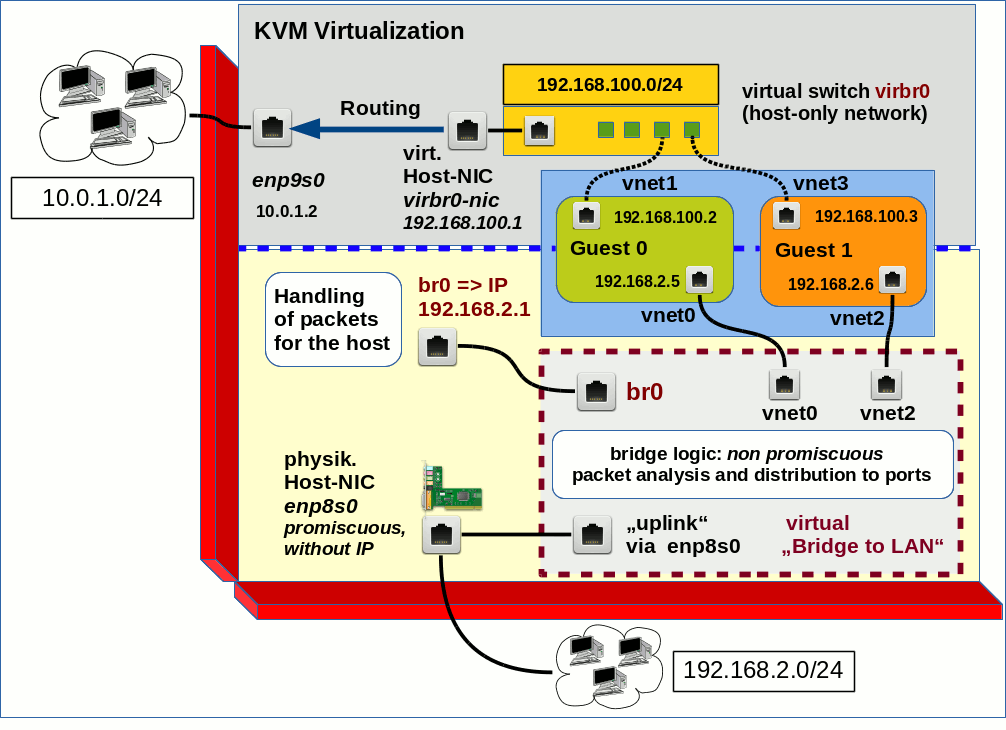
hatte ich 2 Arten der Anbindung eines KVM-Gastsystems an die physikalische Umwelt des KVM-Hostes diskutiert. Ich hatte angemerkt, dass es unter KVM/libvirt neben einem direkten Bridging zu einer physikalischen Host-NIC natürlich auch die Möglichkeit gibt, KVM-Gäste an ein sog. “Host-Only-Network” [HON] anzubinden. Intern wird dieses Netzwerk durch eine virtuelle Bridge repräsentiert. Soll man aus dem HON heraus mit der physikalischen Umwelt (LAN) kommunizieren, muss man auf dem KVM-Host Routing zwischen einer bereitgestellten virtuellen Host-NIC der Bridge zu einer physikalischen NIC des Hostes ermöglichen. Letztere leitet die Pakete dann ins LAN.
Unterlässt man das Routing (und/oder filtert man Pakete aus dem HON) auf dem Host, so befinden sich Gastsystem und Host in einem isolierten virtuellen Netz, aus dem nach außen ohne weitere Vorkehrungen nicht kommuniziert werden kann. Dem isolierten Netz können natürlich weitere Gäste beitreten.
Wegen der Nachfrage einer Leserin, zeige ich nachfolgend kurz die Anlage eines virtuellen Host-Only-Netzwerks unter KVM mittels “virt-manager”. Ich setze voraus, dass der “libvirtd”-Daemon läuft.
Man ruft als root “virt-manager” auf und geht im Übersichtsfenster auf “Edit >> Connection Details” und dort auf den Reiter “Virtual Networks”. Dort findet man unter der Übersichtsliste zu bereits vorhandenen Netzwerken, einen Button mit einem “+” Symbol zum Anlegen eines neuen Netzwerks. Ich zeige nachfolgend die Dialogsequenz:
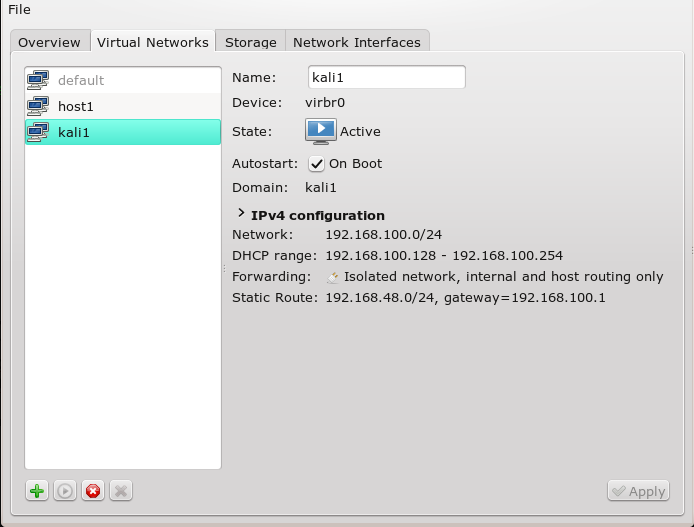
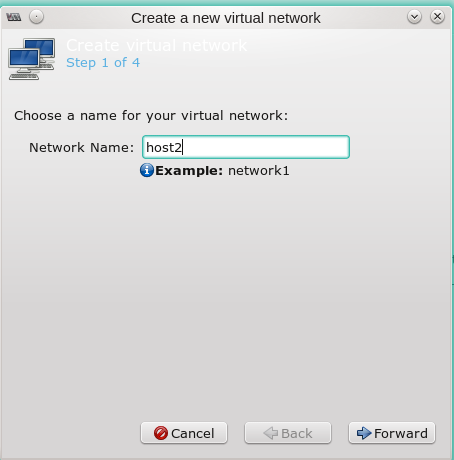
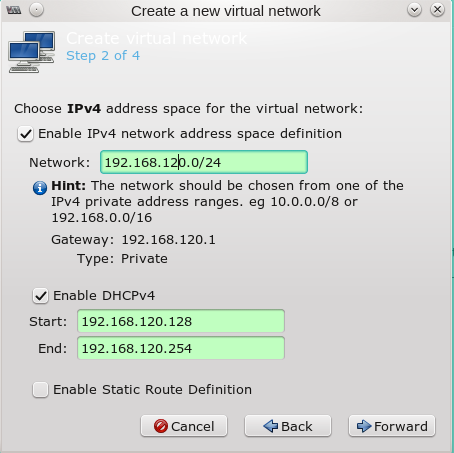
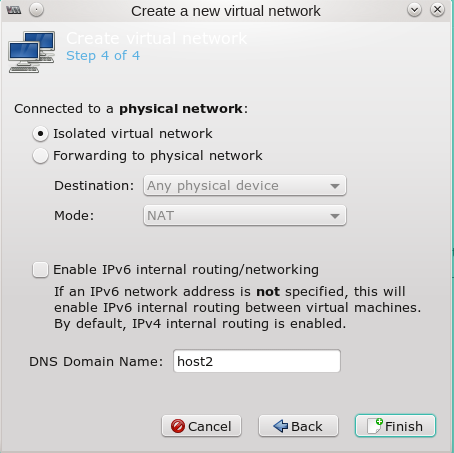
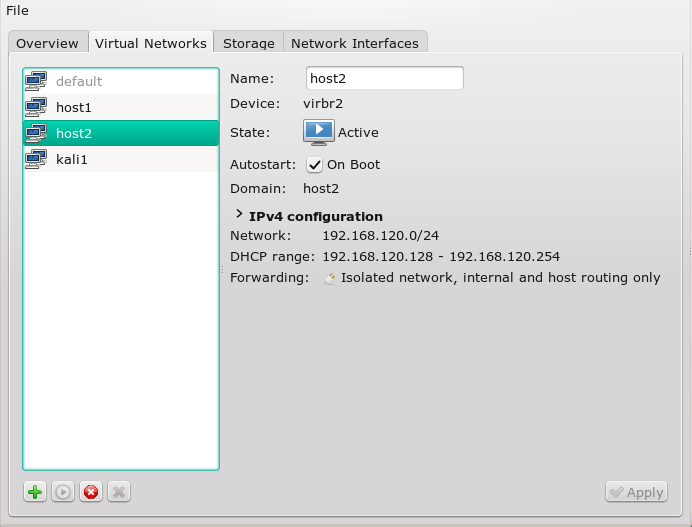
Die Bridge und eine zugehörige Host-NIC tauchen dann auch in der Liste der vorhandenen Netzwerk-Devices auf. Unter Opensuse zeigt das Komamndo “wicked show all” dann etwa ein virbr-Device (virtual bridge – im Beispiel ein “virbr2”):
virbr2 device-unconfigured
link: #73, state device-up, mtu 1500
type: bridge
addr: ipv4 192.168.120.1/24
virbr2-nic device-unconfigured
link: #74, state down, mtu 1500, master virbr2
type: tap, hwaddr 52:54:00:c9:bd:24
Das neue Netzwerk findet sich dann auch in Form einer XML-Netzwerk-Konfigurations-Datei unter “/etc/libvirt/qemu/networks/host2.xml” wieder:
<!--
WARNING: THIS IS AN AUTO-GENERATED FILE. CHANGES TO IT ARE LIKELY TO BE
OVERWRITTEN AND LOST. Changes to this xml configuration should be made using:
virsh net-edit host2
or other application using the libvirt API.
-->
<network>
<name>host2&
lt;/name>
<uuid>f47c2d04-b1d6-48bf-a6dc-a643d28b38d3</uuid>
<bridge name='virbr2' stp='on' delay='0'/>
<mac address='52:54:00:c9:bd:24'/>
<domain name='host2'/>
<ip address='192.168.120.1' netmask='255.255.255.0'>
<dhcp>
<range start='192.168.120.128' end='192.168.120.254'/>
</dhcp>
</ip>
</network>
Will man eine solche Host-Only-Bridge von einem KVM-Gast aus nutzen, so muss man für diesen Gast ein entsprechendes “Netzwerk”-Device (NIC) anlegen, das der Bridge zugeordnet wird. “virt-manager” bietet auch hierfür entsprechende grafische Dialoge an. Ich gehe davon aus, dass eine virtuelle Maschine (z.B. namens “kali2”) bereits existiert. Man öffnet deren Konfigurations-Oberfläche durch Doppelklick auf den entsprechenden Eintrag in der Liste aller KVM-Instanzen unter “virt-manager”. Im sich öffnenden Fenster klickt man weiter auf den Button mit dem “i”-Symbol:
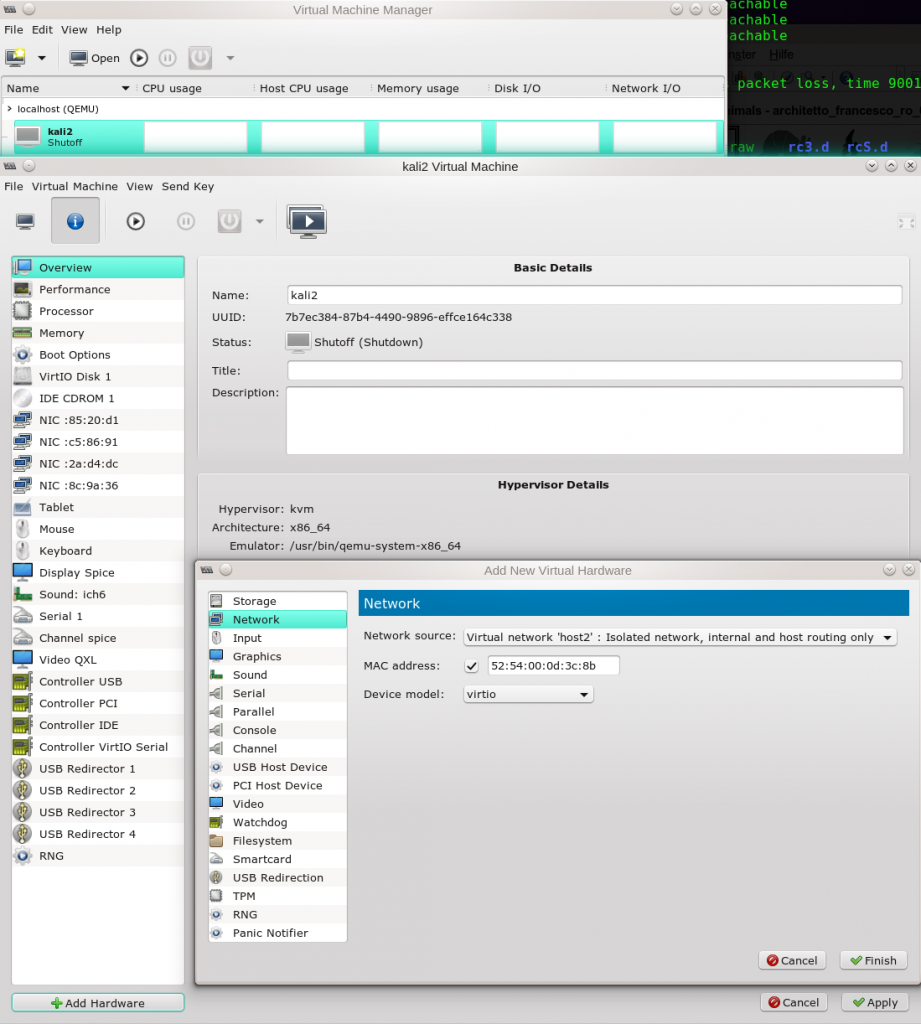
Danach taucht das Device auch in der XML-Konfigurationsdatei für den Gast auf – in meinem Beispiel etwa für einen Kali-Gast mit der Datei “/etc/libvirt/qemu/kali.xml” – ich zeige nur den relevanten Ausschnitt:
<interface type='network'>
<mac address='52:54:00:0d:3c:8b'/>
<source network='host2'/>
<model type='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x0d' function='0x0'/>
</interface>
Danach muss man den Gast neu starten und in ihm natürlich das neu aufgetauchte Netzwerk-Interface manuell konfigurieren – falls man nicht auf DHCP setzt und/oder besondere Einstellungen benötigt. Man merke sich hierzu die MAC-Adresse, um bei mehreren NICs nicht den Überblick zu verlieren! Man achte auch auf das Default-Gateway, wenn Routing über den Host gewünscht ist.
Achtung: Das neue virtuelle Netzwerk des Gastes ist mit “ifconfig”, “ip” oder “wicked” Kommandos erst als ein “vnetN“-Device sichtbar, wenn der Gast gestartet und aktiv ist. Das “N” steht dabei für eine fortlaufende Nummer, die vom System (libvirt) vergeben wird. Z.B. taucht unter “wicked show all” dann ggf. ein Device “vnet3” auf:
virbr2 device-unconfigured
link: #73, state device-up, mtu 1500
type: bridge
addr: ipv4 192.168.120.1/24
virbr2-nic device-unconfigured
link: #74, state down, mtu 1500, master virbr2
type: tap, hwaddr 52:54:00:c9:bd:24
...
...
vnet3 device-unconfigured
link: #17, state up, mtu 1500, master virbr2
type: tap, hwaddr fe:54:00:0d:3c:8b
Man beachte, dass sowohl die Host-Nic, als auch das Device des Gastes “tap”-Devices sind. Allg. Infos zu tap-devices finden sich hier:
https://www.kernel.org/doc/Documentation/networking/tuntap.txt
https://de.wikipedia.org/wiki/TUN/TAP
Hinweise für Leser, die die Konfiguration lieber manuell und über die Kommandozeile durchführen mögen
Wie man eine virtuelle Bridge auf dem KVM-Host mittels des “brctl”-Kommandos einrichtet, benennt und wie man ihr “tap”-Devices zuordnet, habe ich im Prinzip bereits früher am Beispiel einer direkten Bridge zu einem physikalischen Device beschrieben:
Opensuse – manuelles Anlegen von Bridge to LAN Devices (br0, br1, …) für KVM Hosts
Siehe aber auch hier:
http://www.linux-kvm.org/page/Networking#Configuring_Guest_Networking – Abschnitt (Private Network)
“tap”-Devices kann man manuell und temporär über das Kommando “tunctl” auf dem Host erzeugen.
Siehe etwa :
http://unix.stackexchange.com/questions/86720/can-i-create-a-virtual-ethernet-interface-named-eth0
http://serverfault.com/questions/347895/creating-tun-tap-devices-on-linux
http://www.naturalborncoder.com/virtualization/2014/10/17/understanding-tun-tap-interfaces/
http://blog.elastocloud.org/2015/07/qemukvm-bridged-network-with-tap.html
Die Zuordnung von “tap”-Devices zu einer virtuellen Linux-Bridge erfolgt über das “brctl addif”-Kommando. Nun fehlt also nur noch eine Methode, um einmal erzeugte “tap”-Devices in die Konfiguration eines Gastes einzubinden.
Ich kenne einige Leute, die starten ihre virtuellen Maschinen lieber eigenhändig und über Scripts statt über virt-manager. Dann kann die Netzwerk-Konfiguration des Gastsystems in Form passender Optionsparameter des Kommandos “qemu-system-x86_64” (mit weiteren Optionen für KVM-Unterstützung; s.u.) oder des Kommandos “qemu-kvm” zum Starten eines KVM-Gastes geschehen. Eine Übersicht über diese Möglichkeit findet man hier:
http://qemu-buch.de/de/index.php?title=QEMU-KVM-Buch/_Netzwerkoptionen/_Virtuelle_Netzwerke_konfigurieren
In abgekürzter Form auch hier :
https://bbs.archlinux.org/viewtopic.php?pid=1148335#p1148335
https://bbs.archlinux.org/viewtopic.php?pid=1424044#p1424044
Eine weitere Alternative ist hier beschrieben (s. den Abschnitt zu “Private Networking”):
http://www.linux-kvm.org/page/Networking#Configuring_Guest_Networking
Übrigens: “qemu-kvm” ist auf aktuellen Linux-Systemen meist nur ein kleines Shell-Script-Kommando, dass “qemu-system-x86_64” mit KVM-Hardware-Unterstützungsoptionen aufruft! Siehe zum Unterschied zw. “qemu-system-x86_64” und “qemu-kvm” etwa
http://www.linux-kvm.com/content/qemu-kvm-or-qemu-system-x8664%EF%BC%9F).
Die Optionen des “qemu-kvm”-Kommandos sind z.B. hier beschrieben:
https://www.suse.com/documentation/sles11/book_kvm/data/cha_qemu_running_gen_opts.html
Eine Zusammenfassung zu tap-Devices und verschiedenen Bridging-Varianten gibt auch
https://www.suse.com/documentation/sles11/book_kvm/data/cha_qemu_running_networking.html
Will man die Tools von “libvirt/virt-manager” zum Starten der virtuellen Maschine benutzen, dann kann die “manuelle” Definition von virtuellen NICs für einen KVM-Gastes aber auch mittels des “virsh edit”-Kommandos zur Manipulation des XML-Files für die
Gastkonfiguration durchgeführt werden.
Siehe:
http://serverfault.com/questions/665440/set-up-network-interfaces-in-ubuntu-for-kvm-virtual-machine
In einigen Situationen kann es auch erforderlich sein, den Gast im laufenden Betrieb um ein Netzwerkinterface zu einem neu definierten virtuellen Netz zu erweitern. Informationen hierzu findet man hier:
http://www.linuxwave.info/2014/12/hot-attach-and-hot-detach-network.html
https://kashyapc.fedorapeople.org/virt/add-network-card-in-guest.txt