Bei der Wahl einer Virtualisierungsumgebung auf einem Linux-Host spielen viele Faktoren eine Rolle. Kosten, Anzahl der Gäste, Ressourcenbelastung des Hosts, Verfügbarkeit von Monitoring- und Admin-Umgebungen – aber auch die Kompatibilität mit den zu implementierenden Gastsystemen. Ich betrachte in diesem Artikel ausschließlich Linux-Arbeitsplatzsysteme als Virtualisierungshosts – also Desktops oder Laptops. Auf solchen Systemen verfolge ich dabei andere Interessen als auf Hosts für Server-Gast-Systeme:
In meinem Desktop-Umfeld spielen Windows-Gastsysteme für Entwicklungs- und für Penetrationstetsts neben Mehrzweck-Linux-Systemen wie Debian oder Kali2 eine Rolle. Ich benötige nur wenige und rudimentär ausgestattete Gäste. Die durchschnittliche Belastung des Virtualisierungs-Hosts ist somit relativ gering. Die Kosten sollen möglichst klein sein, die administrativen Möglichkeiten ausreichend, d.h. ohne Luxus. Für alle Gastsysteme gilt aber, dass die emulierte grafische Oberfläche hinreichend flüssig bedienbar sein muss.
Für die Windows-Desktops verwende ich deshalb eine VMware-Workstation-Umgebung, da mir diese Virtualisierungs-Plattform erfahrungsgemäß gut handhabbare Windows-Gastsysteme inkl. einer schnellen grafischen Oberfläche liefert. Zur Not auch mit 3D-Grafik-Unterstützung. Linux-Gäste fahre ich dagegen unter der KVM/Qemu-Virtualisierungsinfrastruktur – durch virtio-Treiber, Spice und Video XQL ist dort die grafische Nutzeroberfläche (inzwischen) hinreichend schnell (wenn z.Z. auch noch ohne 3D-Support). Libvirt/virt-manager liefern für KVM ausreichende und bequeme Möglichkeiten der Administration.
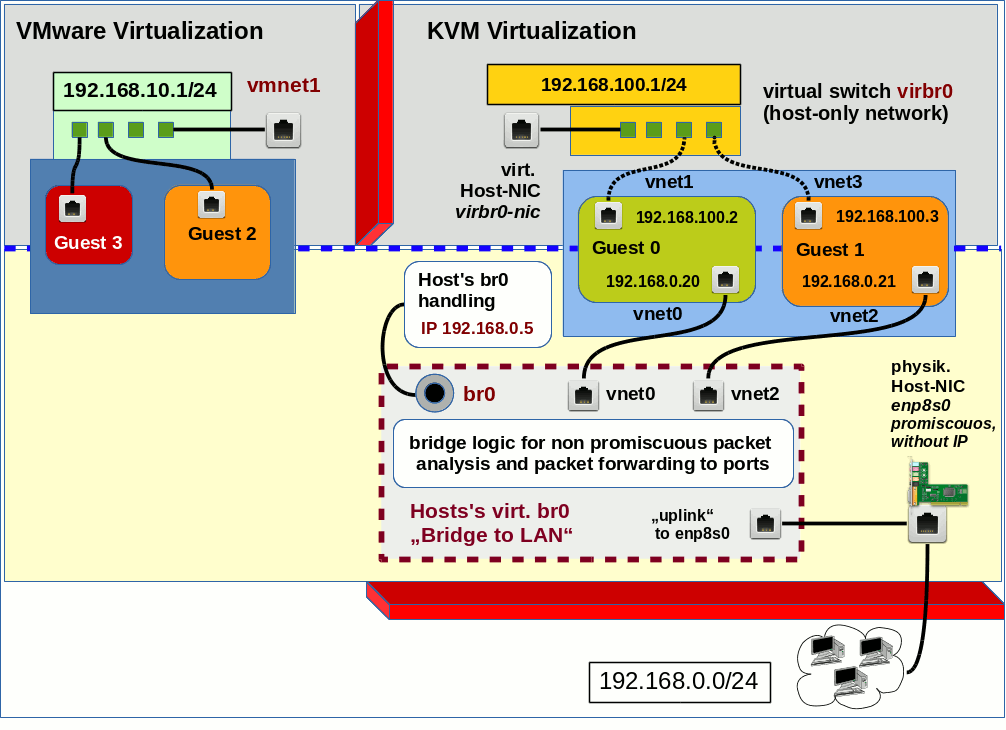
Mixt man – wie ich – zwei unterschiedliche Virtualisierungsumgebungen auf ein und demselben Host, so entstehen neue Begehrlichkeiten. Das gilt im Besonderen für die Konfiguration eines Pentest-Labors und die schnelle Abänderung der Netzwerk-Konfiguration. Für Penetrationstests isoliert man die Gäste i.d.R. in privaten Netzwerken. Diese werden jeweils durch eine virtuelle Bridge repräsentiert – mit oder ggf. auch mal ohne Host-NIC, um auch den Host an das jeweilige Netzwerk anbinden zu können. Ein direktes Bridging zu physikalischen Devices des Hosts bringt dagegen je nach Testsituation zu viele Gefahren für den Hosts selbst und dessen LAN-Umgebung mit sich.
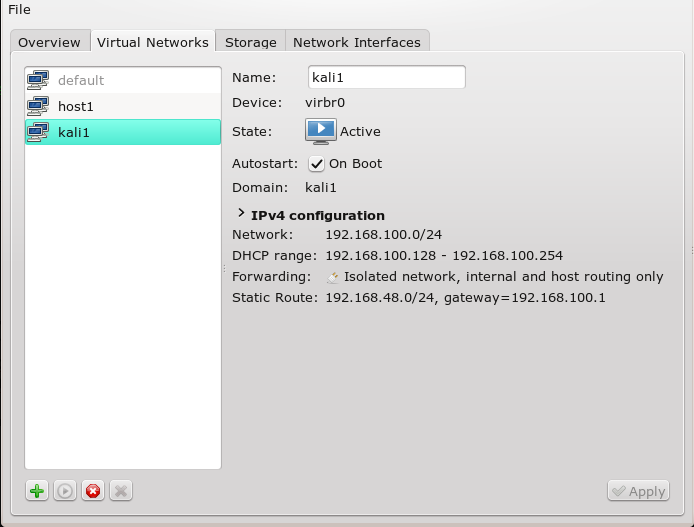
“Host-Only-Netzwerke” [HON] kann man sowohl unter VMware WS als auch unter KVM realisieren. Jedes Host-Only-Netzwerk definiert ein bestimmtes Netzwerksegment, dem die jeweiligen Gastsysteme und ggf. der Host über spezielle virtuelle NICs zugeordnet werden.
In vorliegenden Artikel will ich auf die Frage eingehen, ob und wie man
- Gäste einer “KVM”-Umgebung an eine Host-Only-Bridge Bridge einer VMware WS-Umgebung
- und/oder umgekehrt Gäste einer “VMware WS”-Umgebung an eine Host-Only-Bridge Bridge einer KVM-Umgebung
anbinden kann. Natürlich könnte man immer über den Host zwischen den Netzwerksegmenten der Virtualisierungsumgebungen routen. Das ist sicher die schnellste Art der Kopplung. Mich interessieren in diesem Artikel aber Möglichkeiten, die ohne Routing auskommen. Ich meine also Szenarien, in denen die Gastsysteme der beiden Virtualisierungsumgebungen Teil eines logischen Netzwerk-Segmentes (auf Layer 3) werden.
Es geht also um eine Art “Cross”-Bridging” für bestimmte Gäste der unterschiedlichen Virtualisierungsumgebungen. Ich stelle hierfür nachfolgend drei verschiedene Lösungen vor. Eine vierte Lösung – eine elegante Spielart der dritten Lösung – wird im kommenden Artikel Fun with veth devices, Linux virtual bridges, KVM, VMware – attach the host and connect bridges via veth
vorgestellt.
Stattet man die Gastsysteme mit nur einer NIC aus, welche über die Verwaltungstools der jeweiligen Virtualisierungsinfrastruktur an die dort beheimatete virtuelle Bridge angebunden wird, so können die Gastsysteme des Segments der einen Virtualisierungsumgebung mit den Gastsystemen des Segments der jeweils anderen Virtualisierungsumgebung nur dann kommunizieren, wenn Routing über den Host und dessen Paketfilter zugelassen wird. Damit sind unter Penetrationstest-Bedingungen aber erneut Sicherheitsrisiken (“packet leackage” ins physikalische Netz) verbunden.
Umgekehrt gilt: Auch ohne Paketfilter erzwingen die Standardeinstellungen der Router/Forwarding-Funktionalität eines Linux-Systems Einschränkungen – u.a. werden IP-gespoofte Pakete, mit Ursprungsadressen im jeweils anderen Segment, nicht vom Linux-Kernel des Hosts weitergeleitet. Unter diesen Bedingungen kann im Rahmen von Penetrationstests dann z.B. ein NMAP Idle-Scan von einem Linux-System im KVM-Segment über ein “idle” Windows-System zu einem Windows-Target im VMware-Segment nicht durchgespielt werden.
Grundsätzlich ist meine Anforderung die, dass man auf die Vorteile der jeweiligen Virtualisierungsumgebung für die Gast-Einrichtung nicht verzichten will, unter bestimmten Bedingungen aber eine direkte – d.h. routing-freie – Anbindung eines Gastsystems an das Host-Only-Netzwerksegment der jeweils anderen Virtualisierungsumgebung nutzen möchte – über eine entsprechende konfigurierte (ggf. zusätzliche) virtuelle NIC.
Ich wollte das schon länger mal aus Prinzip ausprobieren – einfach um zu sehen, ob und wie das ggf. geht. Durch Aktivierung/Deaktivierung von NICs und zugehörigen Profilen will ich für ein Gastsystem schnell zwischen Szenarien mit Routing und ggf. zwischengeschalteten Paketfiltern einerseits und direkter Segment-Anbindung andererseits umschalten können.
Das Ganze ist aber auch unter dem Aspekt interessant, dass ein direktes “cascaded” oder “nested” Bridging von Linux-Bridges nicht möglich ist. So stellt sich u.a. die Frage: Wie bekommt man eine VMware Bridge an eine Linux-Bridge angeschlossen?
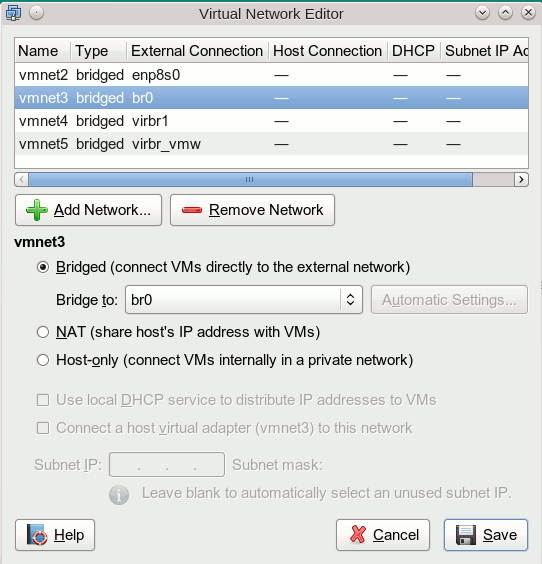
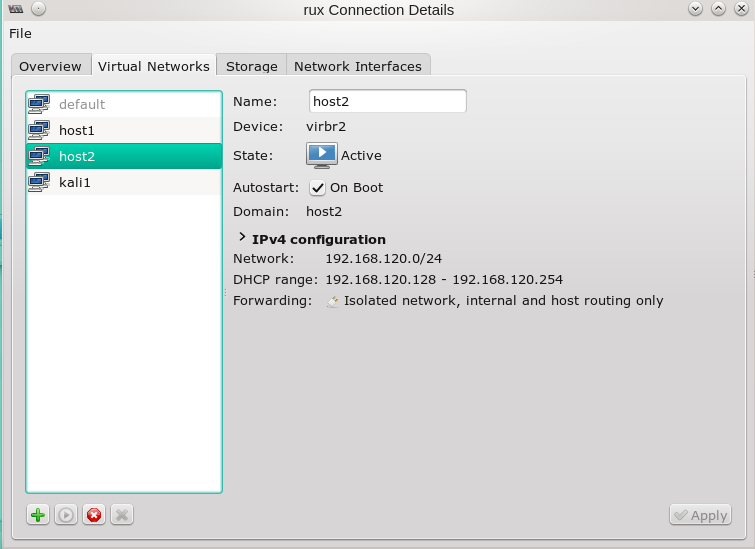
In der “VMware WS”-Umgebung nutzt man zur Konfiguration virtueller Netzwerke/virtueller Bridges als User root den “Virtual Network Editor” (s. Abbdg.), unter KVM den “Virtual Machine Manager” (virt-manager > “Edit” >> “Connection Details” >> “Virtual Networks”) und/oder eine Kombination aus “brctl”- und “ip” bzw. “tunctl”-Kommandos.
VMware Virtual Network Editor [VNE]
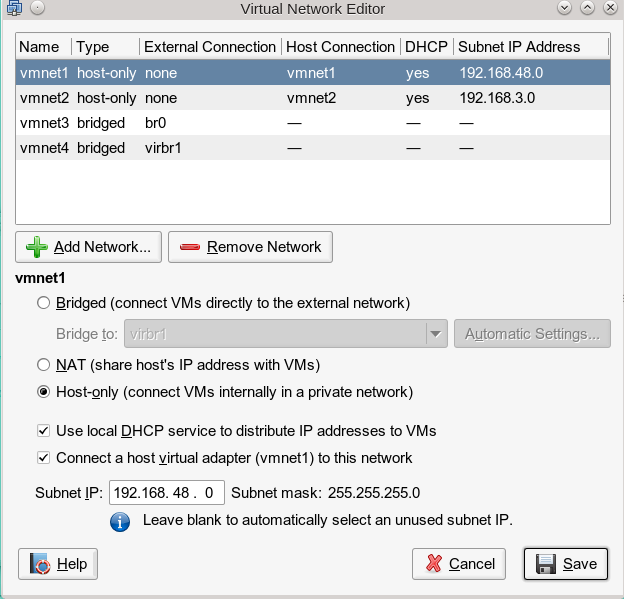
KVM Virtual Machine Manager => Virtual Networks
CLI-Kommandos: brctl/tunctl/ip
Wir kommen auf die praktische Anwendung dieser Kommandos weiter unten zurück. (Siehe aber auch: Opensuse – manuelles Anlegen von Bridge to LAN Devices (br0, br1, …) für KVM Hosts.) Festzuhalten bleibt zunächst, dass ein mittels “tunctl” erzeugtes virtuelles “tap”-Device (Layer 2 Ethernet Device) nur genau einer Linux-Bridge zugeordnet werden kann. Ein Kaskadieren von Bridges (= direktes Einhängen einer Linux-Bridge in eine andere) ist wie gesagt auch nicht möglich.
Ein paar Anmerkungen zum VMware VNE:
nVermutlich reichen die Konfigurationsmöglichkeiten der VMware WS nicht an die der großen VMware Vitualisierungsumgebungen heran – hinreichend sind sie aber. So kann man u.a. Host-Only-Netzwerke (Bridges) mit oder ohne NAT erzeugen. Bei der Erzeugung eines VMware Host-Only-Segments wird automatisch eine Host-NIC für die erzeugte Bridge mit erzeugt. Diese Host-NIC für das VMware Host-Only-Netz erscheint dann – obwohl virtuell – als Ethernet-Device des Hostes.
vmnet1 device-unconfigured
link: #11, state up, mtu 1500
type: ethernet, hwaddr 00:50:56:c0:00:01
addr: ipv4 192.168.48.1/24
vmnet2 device-unconfigured
link: #12, state up, mtu 1500
type: ethernet, hwaddr 00:50:56:c0:00:02
addr: ipv4 192.168.3.1/24
Das ist insofern bemerkenswert, als es in einem entscheidenden Punkt anders aussieht als bei den “tap”- und Bridge-Devices, die man (z.B. mit virt-manager) zu virtuellen “vibr”-Bridges in der KVM-Welt erzeugt:
Der Typ des virtuellen VMware Devices ist “ethernet”! Nicht “bridge” oder “tap”.
Die VMware-Umgebung bietet auch ein direktes Bridging zu physikalischen Host-NICs an. Erzeugt man virtuelle Devices unter Linux und verfolgt, was sich dann auf der VMware-Seite tut, so sieht man: Die VMware Umgebung erkennt neue Netzwerk-Devices (wie erzeugte virtuelle Linux-Bridges und Linux Tap-Devices) und bietet (zumindest theoretisch) ein direktes Bridging auch zu diesen virtuellen Devices an.
Wie bringt man nun mit diesem Rüstzeug die unterschiedlichen Virtualisierungs-Welten bzw. ihre Gastsysteme auf einem Linux-Desktop-System zusammen? Welche Möglichkeiten gibt es?
Im ersten Lösungsansatz möchte ich versuchen, ausgewählte KVM-Gäste der Linux-Bridge direkt an das virtuelle VMware-Netz anzubinden. Das soll vom Effekt her ungefähr so aussehen:
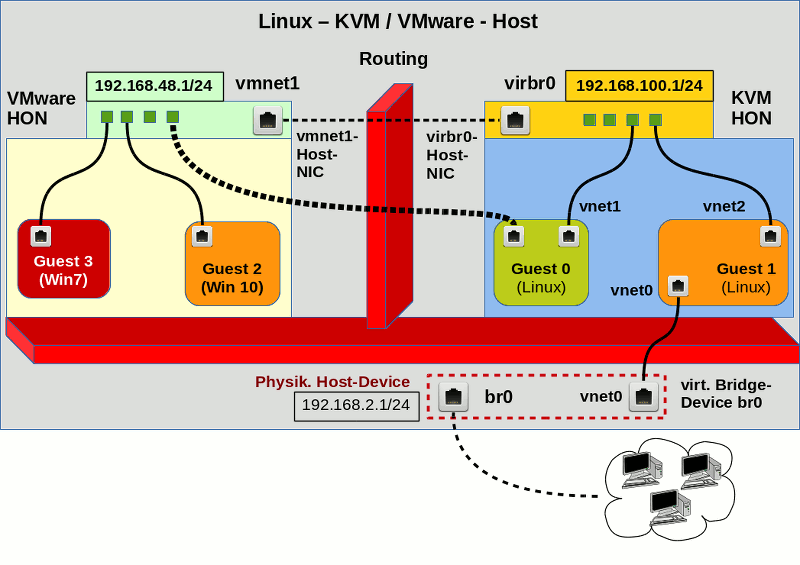
Im Zentrum des Interesses steht “Guest0” im KVM-Bereich. Das eine Interface (vnet1) dieses Gastes ist regulär an die Linux-Bridge “virbr0” angebunden. Von dort könnte über den Host ins VMware-Netz geroutet werden. Das wollen wir aber vermeiden und statt dessen über ein weiteres Interface die nahtlose Anbindung von Guest0 an das virtuelle Netz “vmnet1” auf der VMware-Seite erreichen – unter Umgehung irgendwelcher Paketfilter des Hostes. Siehe die gestrichelte Linie. Auch wenn wir das nicht direkt in der dargestellten Form verwirklichen können, so soll doch zumindest der effektive Datentransport der Logik dieses Bildes entsprechen.
Der VMware WS VNE bietet eine direkte Anbindung virtueller “tap”-Devices von VMware Gästen an die vmnet1-Bridge leider nicht an. Das einzige Element von “vmnet1”, das auf der Linux-Seite für evtl. Manipulationen zur Verfügung steht, ist die zugehörige virtuelle Host-NIC gleichen Namens. Was können wir damit aus Sicht eines KVM-Gastes tun?
KVM unterstützt seit einigen Jahren die Nutzung physikalischer Ethernet Devices durch Gastsysteme in Form sog. virtueller “macvtap”-Bridge-Devices. Zur Einführung siehe
http://virt.kernelnewbies.org/MacVTap
Ein weiterer sehr lesenswerter Artikel hat mein Verständnis beträchtlich erhöht:
https://seravo.fi/2012/virtualized-bridged-networking-with-macvtap
Der folgende
Artikel zeigt, wie man macvtap Devices in einer mit “libvirt” verwalteten Umgebung manuell über entsprechende Einträge in XML-Konfigurationsdateien einbindet.
Weitere interessante Artikel zu macvtap-Devices sind:
https://wiki.math.cmu.edu/iki/wiki/tips/20140303-kvm-macvtap.html
http://www.furorteutonicus.eu/2013/08/04/enabling-host-guest-networking-with-kvm-macvlan-and-macvtap/
Man beachte, dass alle genannten Artikel auf physikalische Devices als sog. “lower devices” einer “macvtap”-Bridge Bezug nehmen. Kann man evtl. auch virtuelle VMware-Devices in einer macvtap-Bridge nutzen?
Die Vermutung liegt nahe, dass aus Sicht des Linux-Kernels lediglich relevant ist, dass ein entsprechender “device node” mit zugeordneten Treibern und einem unterstützten Ethernet Stack vorhanden ist. VMware hat hier ganze Arbeit geleistet:
Die virtuellen Host-NICs für die virtuellen VMware Host-Only-Netze erscheinen unter “ifconfig” als vollwertige Ethernet Devices (s.o.). Unter dem Verzeichnis “/dev/” findet man zudem zugehörige Dateien für zeichenorientierte Geräte.
Also: Warum nicht mal ein virtuelles VMware “Ethernet”-Devices in KVM über MacVtap bridgen? Man könnte dann einem KVM-(Linux)-Gast-System eine virtuelle NIC zuordnen, die das Ethernet-Device “vmnet1” über den “macvtap”-Mechanismus nutzt. Wird das virtuelle Device im KVM-Gastsystem danach mit einer IP-Adresse versehen, die zum VMware-Netzwerk-Segment “vmnet1” passt, sollte der KVM-Gast direkt im VMware-Netz erreichbar sein bzw. direkt mit Gästen des VMware-Netzes kommunizieren können.
Um meinem Kali2-Gastsystem in der KVM-Umgebung testweise ein macvtap-Device zuzuordnen benutze ich “virt-manager”. (Ich gehe dabei davon aus, dass der libvirtd-Dämon gestartet wurde, nachdem das virtuelle VMware-Netz angelegt wurde, so dass die “vmnet”-Netzwerk-Devices der KVM-Umgebung mit Sicherheit bekannt sind.)
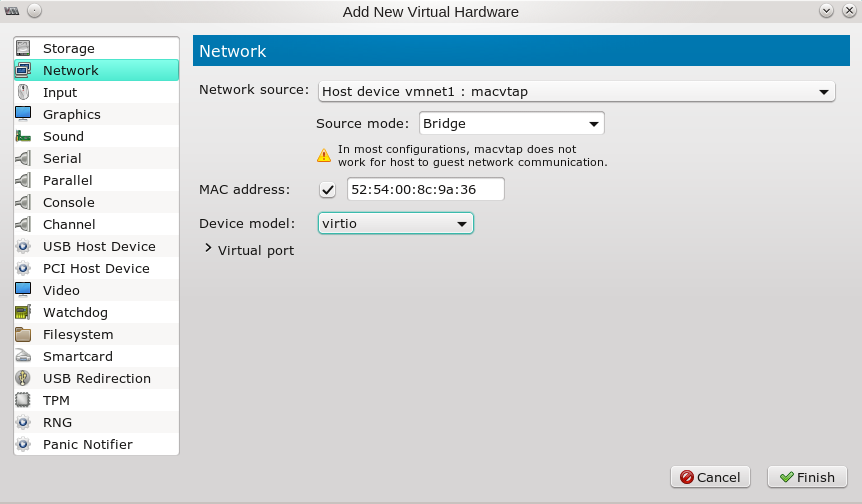
Mit dem Ergebnis:
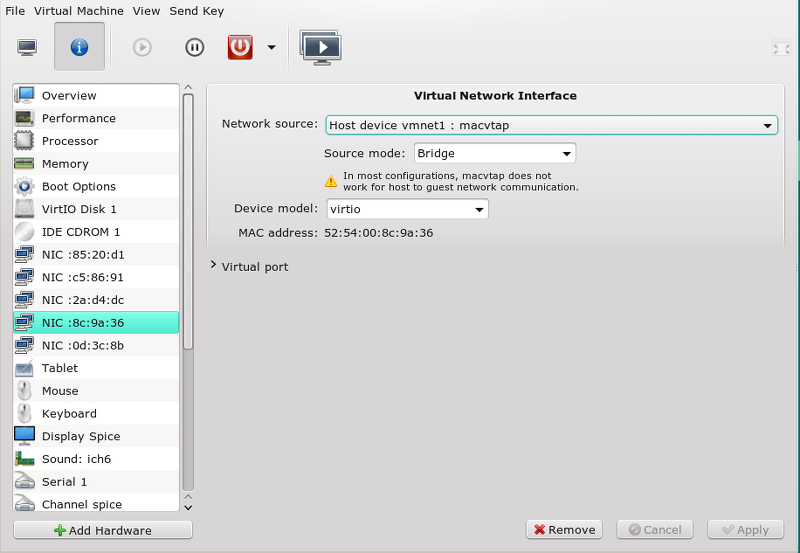
Nun ggf. das Gastsystem nochmal rebooten. Dann die neue virtuelle NIC im Gastsystem konfigurieren – hier in einem Kali2-System:
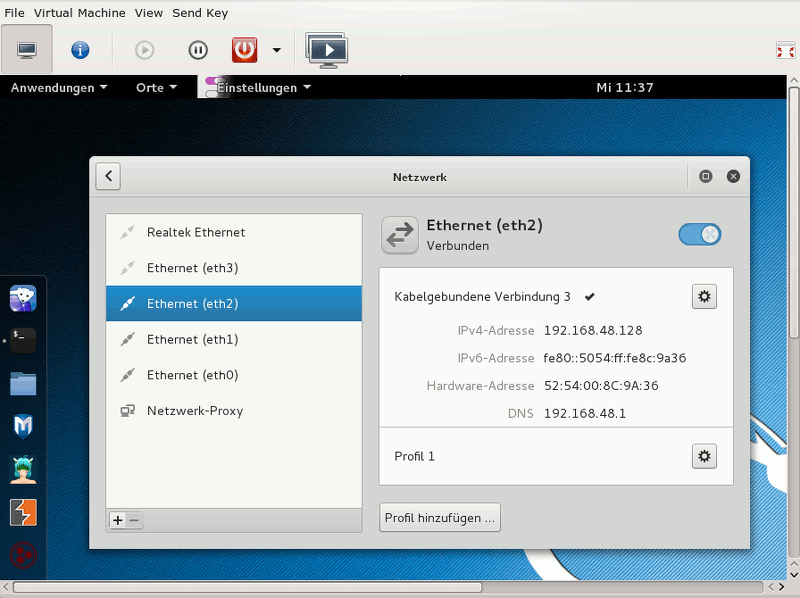
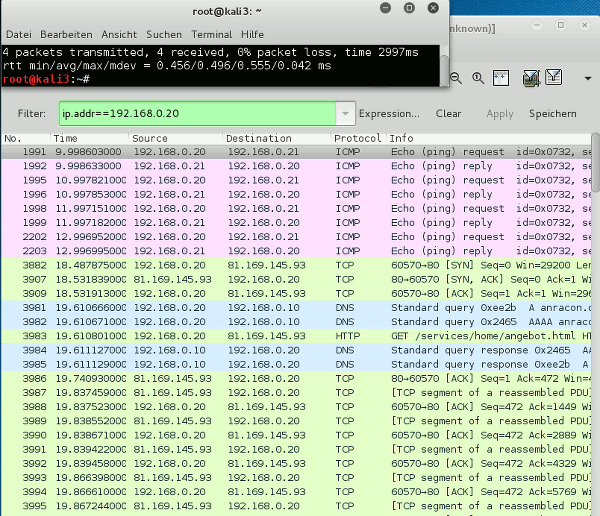
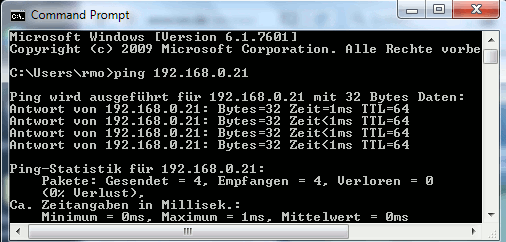
Danach unter VMware WS ein Gastsystem starten. Hier z.B. ein altes XP-System mit einer IP 192.168.48.3. Dann auf beiden Seiten pingen:
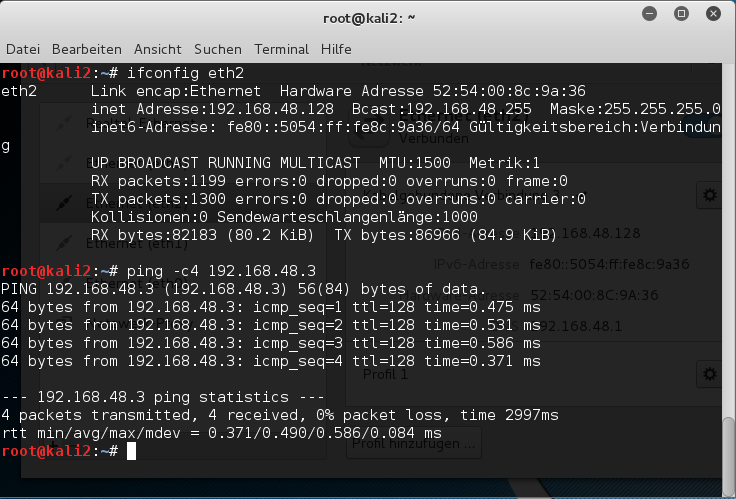
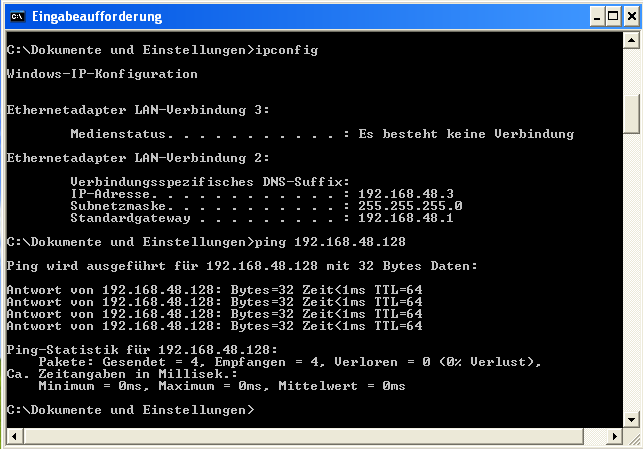
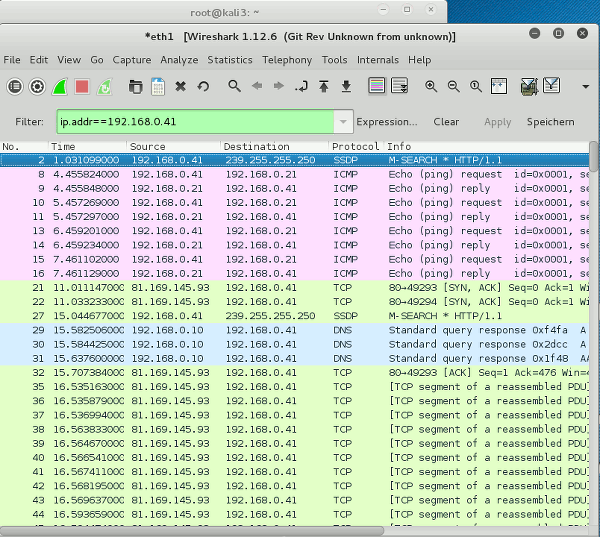
Sieht doch gut aus! Nun auch noch testweise einen nmap-Scan durchführen:
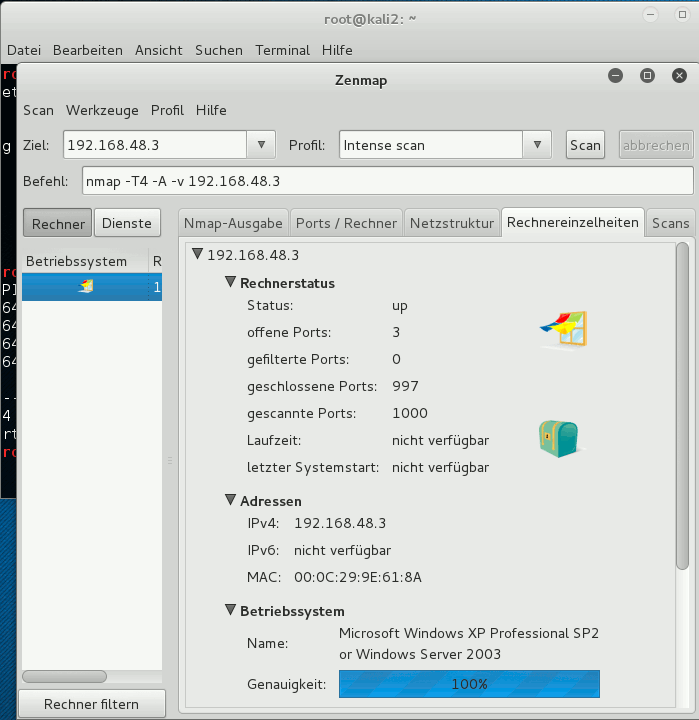
Bestens – Lösungsansatz 1 funktioniert offenbar! Wenn intern auch nicht exakt so, wie im einleitenden Bild dargestellt.
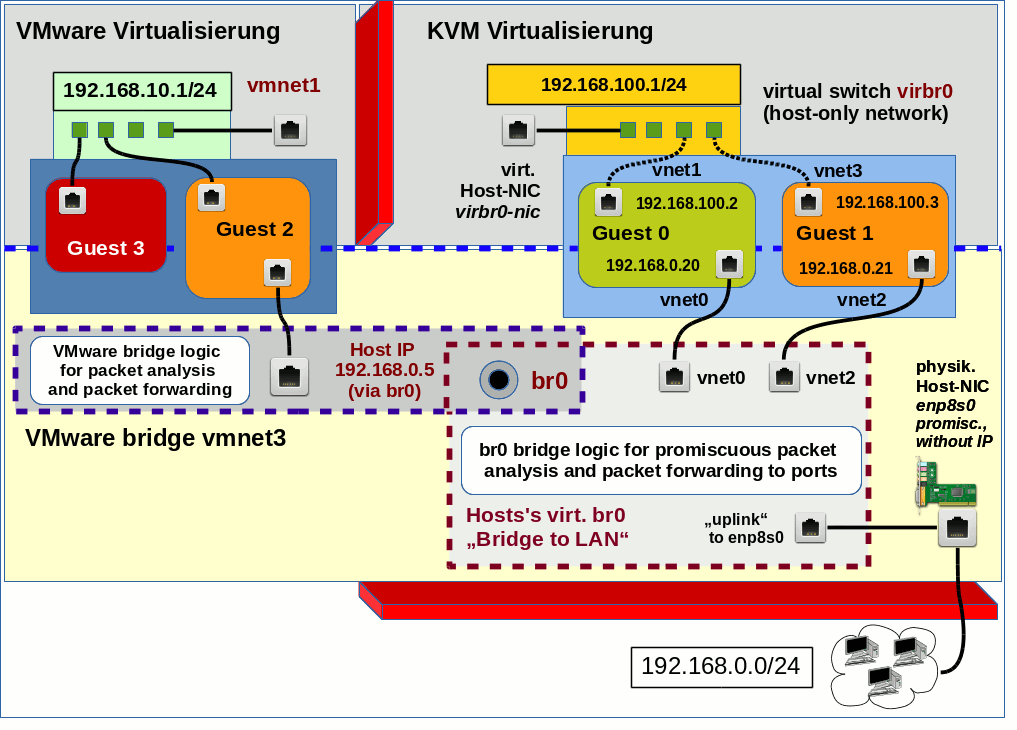
Nun wollen wir uns um den umgekehrten Ansatz kümmern. Ein ausgewählter VMware WS-Gast soll irgendwie an eine Linux-Bridge, die von KVM-Gästen bereits über tap-Devices genutzt wird, angebunden werden. Die nachfolgende Abbildung zeigt, wie man sich das in etwa vorstellen kann.
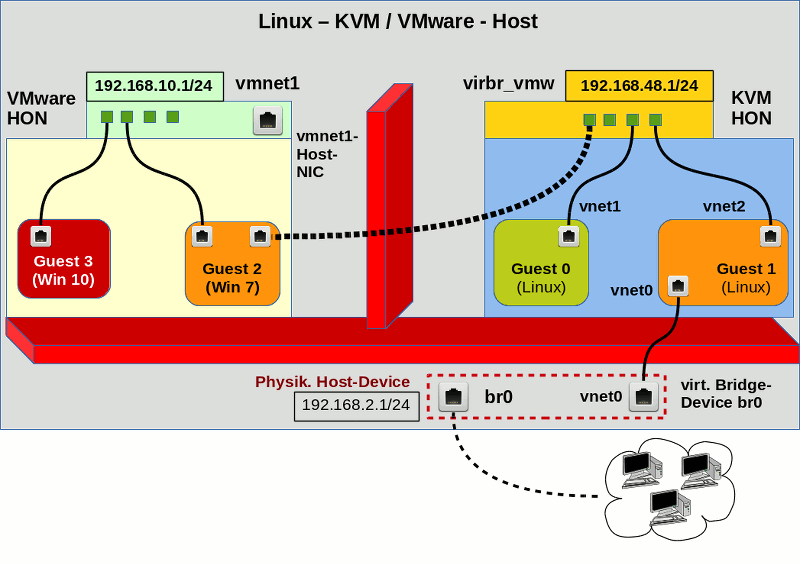
Im Gegensatz zum entsprechenden Bild für den Lösungsansatz 1 haben wir jetzt die Möglichkeit des Routings über den Host ganz ausgeblendet. Zu beachten ist auch, dass das 192.168.48.0/24-Netz sich jetzt auf der rechten Seite befindet. Der Host selbst erhält in unserem Szenario nicht mal eine eigene, and die Bridge angeschlossene virtuelle NIC.
Die entscheidende Frage ist, ob und wie VMware WS dazu zu bekommen ist, eine Linux-Bridge zu nutzen, die mit “brctl addbr” erzeugt wird. Wer einen genauen Blick auf die ursprüngliche VMware-Netz-Konfiguration meines Testsystems weiter oben wirft, stellt fest, dass VMware offenbar virtuelle Netzwerke mit Zugriff auf eine Linux-Bridge (im Beispiel br0) einrichten kann. Das “br0”-Device ist auf meinem Testsystem eine direkte Linux-Bridge zu einem physikalischen Device. Was aber nichts daran ändert, dass es sich dabei um eine kernel-unterstützte Bridge handelt. Deshalb liegt es nahe, das ganze Spiel mal mit einer Linux-Bridge für ein rein virtuelles Host-Only-Netzwerk zu probieren.
Um Verwerfungen zu vermeiden, fahren wir dazu unseren KVM-Gast runter, entfernen dann das oben eingerichtete MacVtap-Device aus diesem Gast mittels “virt-manager”. Dann wechseln wir als root in den VMware Network Editor und löschen das Netzwerk “vmnet1”. Die entsprechende Host-NIC ist ist danach auch nicht mehr als Character-Device unter Linux vorhanden. In der Konfiguration der VMware-Gäste entfernen wir zur Sicherheit entsprechende Netzwerk-Karten vollständig.
Nun richten wir manuell eine Linux-Bridge namens “virbr_vmw” auf unserem Linux-Host ein:
mytux:/etc/init.d # brctl addbr virbr_vmw
mytux:/etc/init.d # ifconfig virbr_vmw 192.168.48.1 netmask 255.255.255.0 broadcast 192.168.48.255
maytux:/etc/init.d # wicked show all
...
...
virbr_vmw device-unconfigured
link: #47, state up, mtu 1500
type: bridge
addr: ipv4 192.168.48.1/24
...
Wir wechseln dann erneut zu VMwares “Virtual Network Editor”. Hier fügen wir ein neues Netzwerk hinzu. Und zwar im Modus “Bridged” – hierdurch wird für die VMware-Gäste eine Bridge zum Sharen eines Linux-Devices erzeugt. Wir verwenden für das neue virtuelle Netzwerk den inzwischen wieder freigewordenen Namen “vmnet1”:
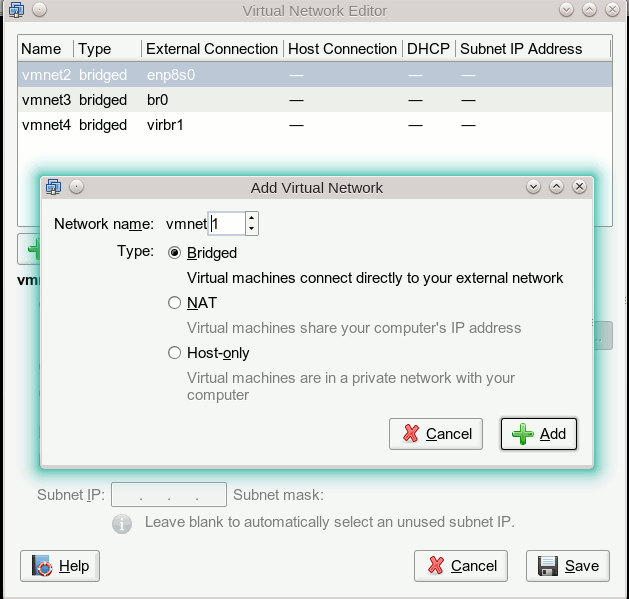
Durch eine VMware-Automatik wird das Netzwerk “vmnet1” dabei vorerst der nächsten freien physikalischen Netzwerkschnittstelle – soweit vorhanden – zugeordnet. In meinem Fall ist das das Device “enp9s0”:
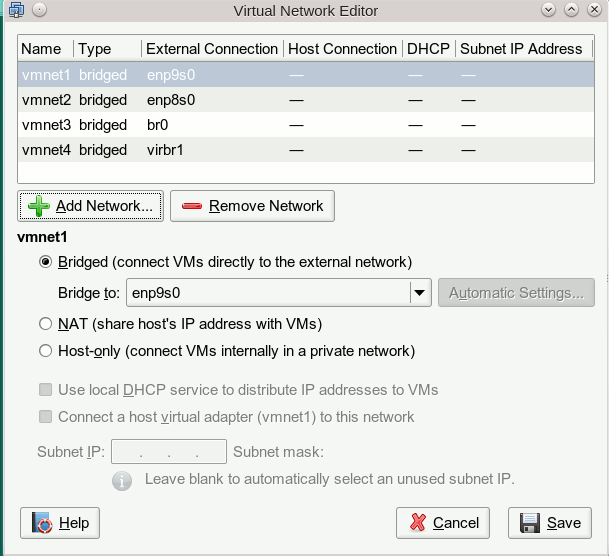
Wir können das aber ändern und wählen über die Combobox vielmehr die neu angelegte Linux-Bridge “virbr_vmw” aus :
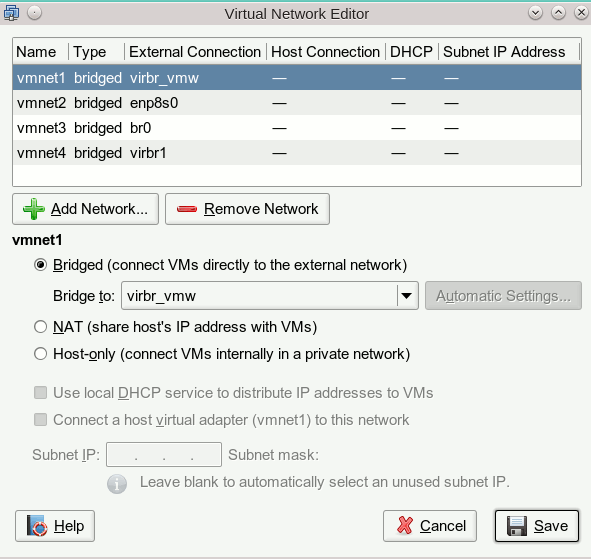
[Sollte die Linux-Bridge noch nicht in der Auswahl angezeigt werden, müssen die VMware-Dienste ggf. runter gefahren und dann über die entsprechen Skripte (/etc/init.d/vmware restart) neu gestartet werden.]
In den Konfigurationseinstellungen eines geeigneten VMware-Gastes legen wir nun ein Netzwerk-Interface zum virtuellen Netz “vmnet1” an. Wir fahren den Gast (in unserem Testfall ein XP-System) anschließend hoch und konfigurieren dort das neue Device mittels der Konfigurationswerkzeuge des VMware-Gastes (hier eines Windows-Systems). Soweit, so gut. Unsere Bridge kann natürlich von unserem Linux-Host aus angepingt werden. Ist unser VMware-Gast aber auch vom Host aus erreichbar?
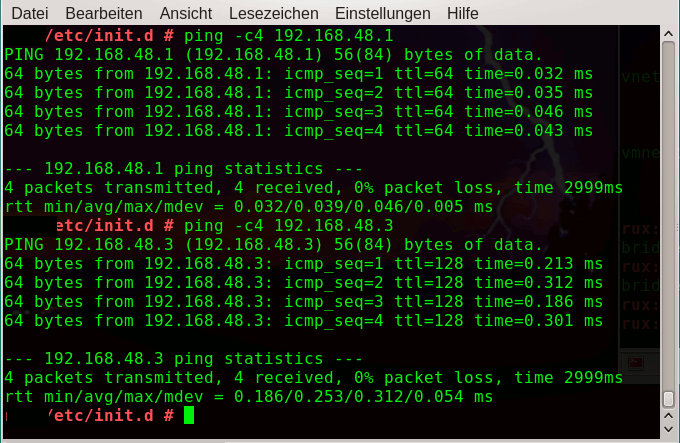
Offenbar ja! Aber wir haben insgesamt noch keine permanente, statische Konfiguration sondern nur eine temporäre erzeugt, die beim nächsten Systemboot verloren gehen würde.
Nun machen wir die ganze Sache auf unserem Opensuse-System permanent. Dazu legen als root unter dem Verzeichnis “/etc/sysconfig/network” eine Datei “ifcfg-virbr_vmw” an – mit folgendem Inhalt:
BOOTPROTO='static'
BRIDGE='yes'
BRIDGE_FORWARDDELAY='0'
BRIDGE_PORTS=''
BRIDGE_STP='off'
BROADCAST=''
DHCLIENT_SET_DEFAULT_ROUTE='yes'
ETHTOOL_OPTIONS=''
IPADDR='192.168.48.1/24'
MTU=''
NETWORK=''
PREFIXLEN='24'
REMOTE_IPADDR=''
STARTMODE='auto'
NAME=''
Im Gegensatz zu einer evtl. schon vorhandenen Bridge “br0” ordnen wir dem Bridge-Device aber keine physikalische NIC des Hostes (wie etwa “enp9s0”) zu!
Hinweis: Debian- oder Red Hat-Anhänger nutzen entsprechende Konfigurationsdateien ihres Systems, die sich teils in anderen Verzeichnissen befinden, einen anderen Namen haben und eine im Detail abweichende Syntax erfordern.
Nun fahren wir alle evtl. noch laufenden virtuellen Maschinen runter und re-booten danach unseren Host. Nach dem Booten sollte man nach Eingabe des Kommandos “ifconfig” in ein Host-Terminal u.a. Folgendes sehen:
virbr_vmw Link encap:Ethernet HWaddr EA:93:44:6E:45:55
inet addr:192.168.48.1 Bcast:192.168.48.255 Mask:255.255.255.0
inet6 addr: fe80::e893:44ff:fe6e:4555/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:132 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:21008 (20.5 Kb)
Wir fahren unseren VMware-Gast wieder hoch und prüfen, ob ein An-Pingen des Hostes möglich ist.
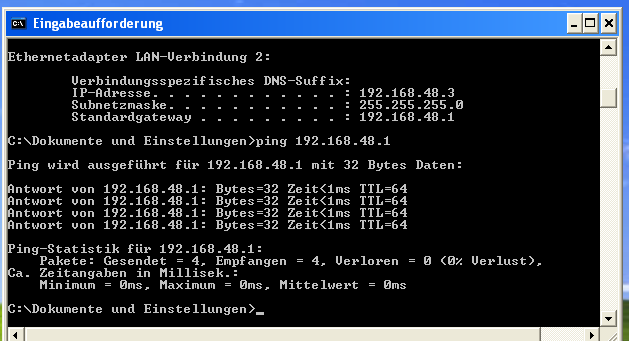
Wenn nicht, so ist noch etwas an der Konfigurationsdatei falsch. Ggf. mit YaST über die dortigen Module zur Netzwerk-Konfiguration prüfen. Zur Sicherheit auch nochmal die Routen auf dem Host und im VMware-Gast kontrollieren.
Nun wenden wir uns unserem KVM-Gast-System zu. Über die Verwaltungsoberfläche von virt-manager fügen wir der Hardware des Gastes ein neues Device hinzu:
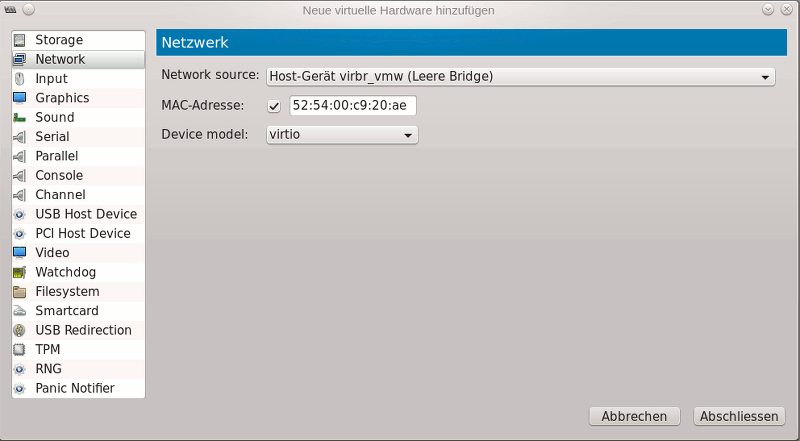
Wir starten danach den KVM-Gast und konfigurieren dort das neue Ethernet-Device mit den Mitteln des Gastsystems (hier mit Kali2/Debian-Einstellungswerkzeugen):
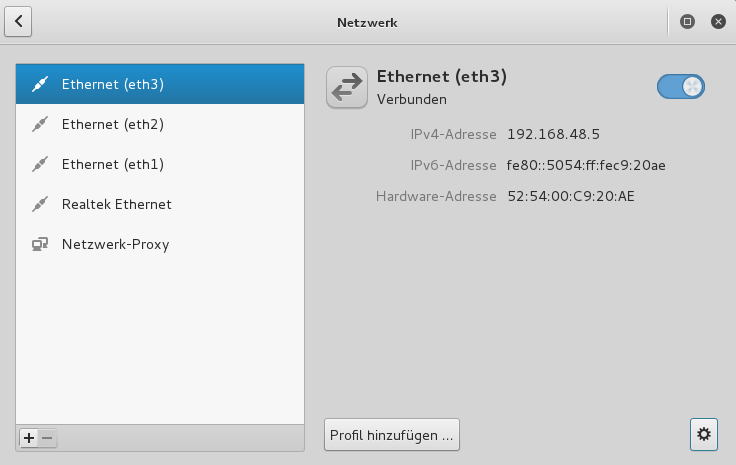
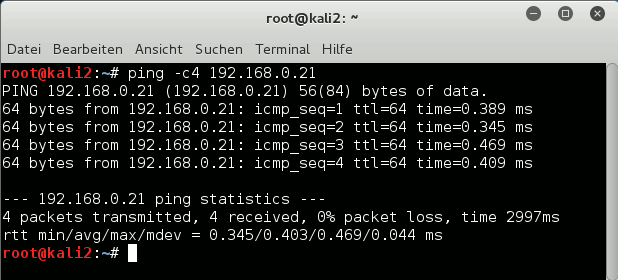
Abschließend testen wir wieder Pings in Richtung Host, VMware-Gast und zurück:
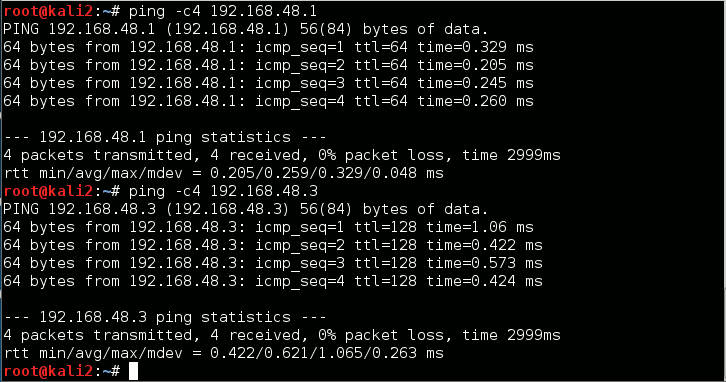
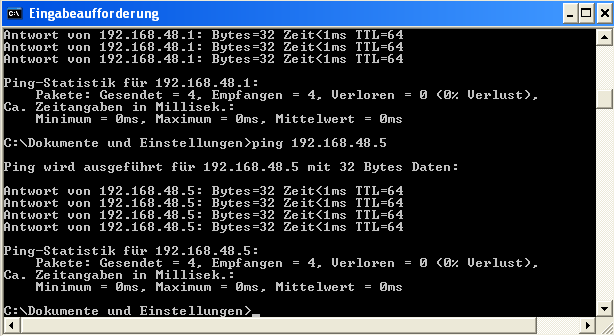
So liebe ich Virtualisierung! Weitere KVM-Gäste benötigen lediglich ein Netzwerk-Interface zur Bridge “virbr_vmw” – und dann stehen auch sie schon in Verbindung zu entsprechend konfigurierten Gästen des VMware-Systems.
Lösungsansatz 1 bot eine Möglichkeit zur direkten Anbindung einzelner KVM-Gäste an das VMware Host-Only-Netzwerk. Es stellt sich die Frage: Geht das nicht auch kollektiv?
Dazu müsste man das von VMware bereitgestellte Ethernet-Device in die Linux-Bridge einbinden. Sprich das Host-Interface des VMware-Switches muss Teil der Linux-Bridge werden. Das entspräche einem Kaskadieren von Bridges. Funktioniert das? Bildlich sähe das dann etwa wie folgt aus:
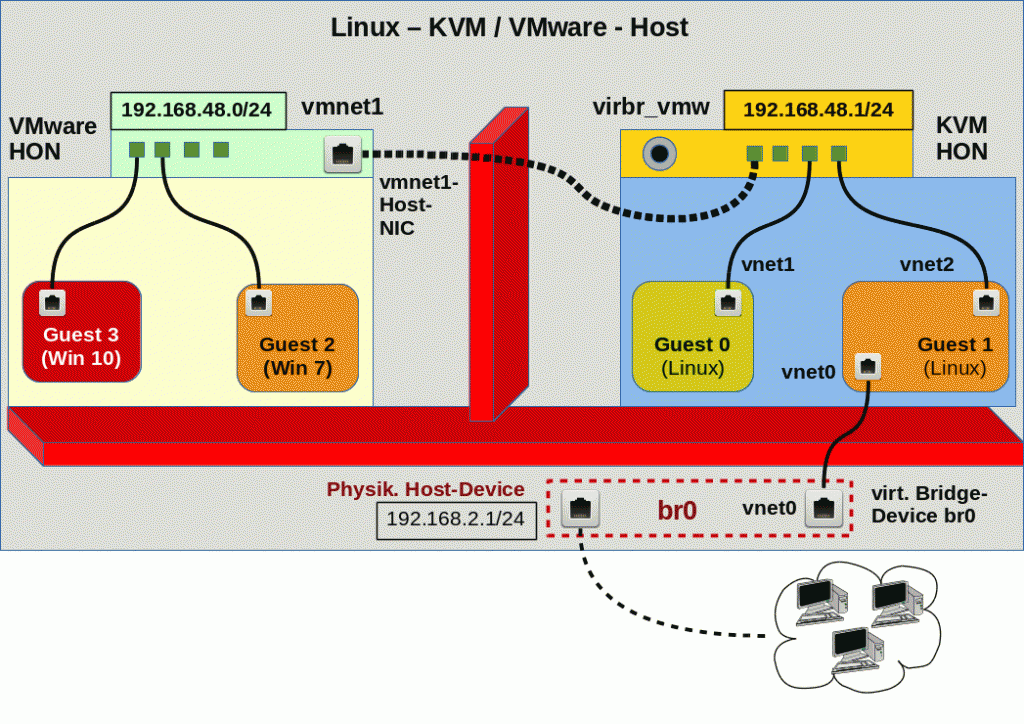
Die erste Frage, die sich einem beim Betrachten stellt, ist: Wie vermeidet man Kollisionen in der Addresszuweisung? DHCP-seitig sollte nach dem Einhängen der des VMware-Devices nur noch genau ein DHCP-Dienst laufen – z.B. der auf der Linux-Seite. Dazu muss beim Einrichten des VMware-Netzwerkes die angebotene DHCP-Funktionalität abgewählt werden.
Der andere Punkt ist der, dass man zumindest mit dem “Virtual Machine Manager” ein Problem bekommt, wenn man ein virtuelles Host-Only-Netzwerk anlegen will, dass das gleiche Segment betrifft, aus dessen Adressbereich anderen virtuellen oder physikalischen Devices bereits IP-Adressen zugewiesen wurden. Also legt man als Erstes am besten die Bridge auf der rechten Seite der obigen Abbildung an. Wir benutzen dazu KVM’s virt-manager:
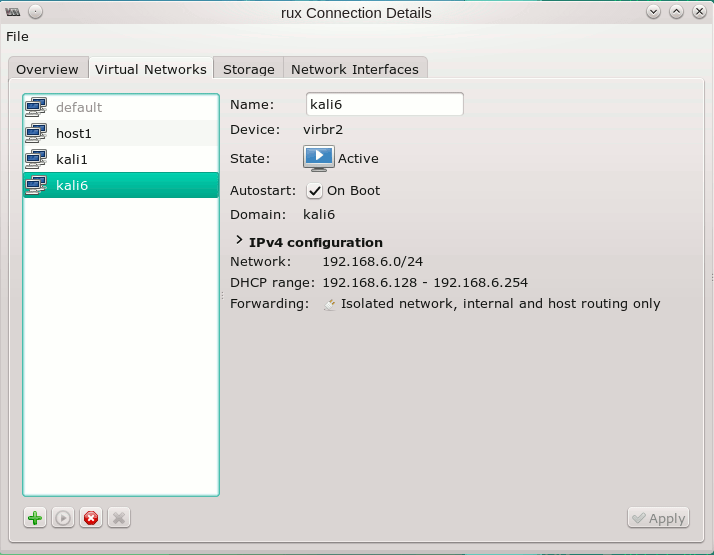
Das Netzwerk taucht in meinem Fall in Form der virtuellen Bridge “virbr2” auf dem Host auf (mit “brtcl show” prüfbar). Nun ordnen wir einem KVM-Gast noch ein entsprechendes virtuelles Device zu:
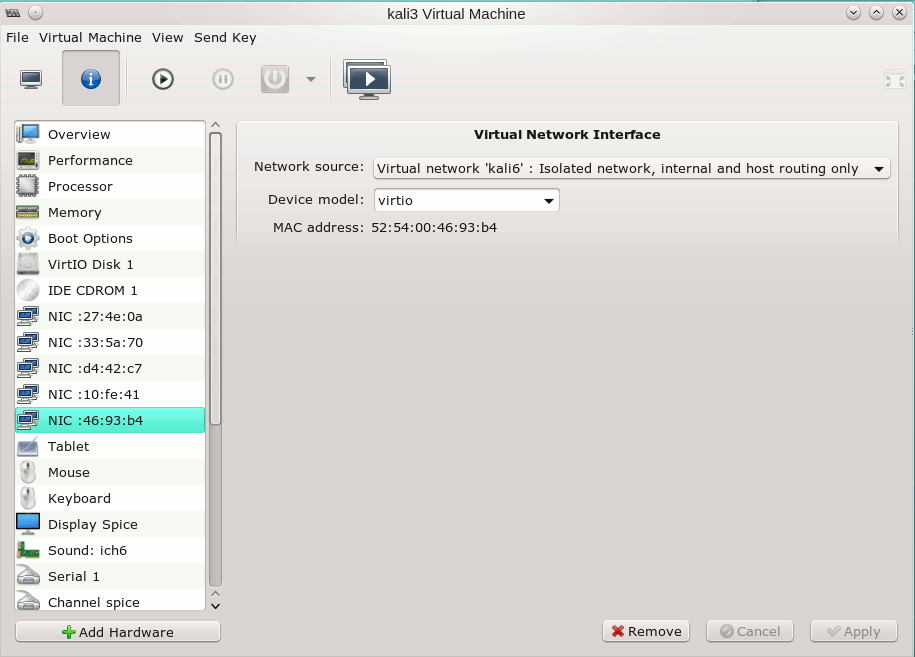
Wir können diesen Gast schon mal starten und die Zuordnung zur Bridge prüfen:
mytux:~ # brctl show virbr2
bridge name bridge id STP enabled interfaces
virbr2 8000.005056c00008 yes virbr2-nic
vnet4
mytux:~ #
OK, jetzt aber zur VMware-Seite. Ein neues virtuelles Netzwerk ist auch im VNE schnell angelegt:
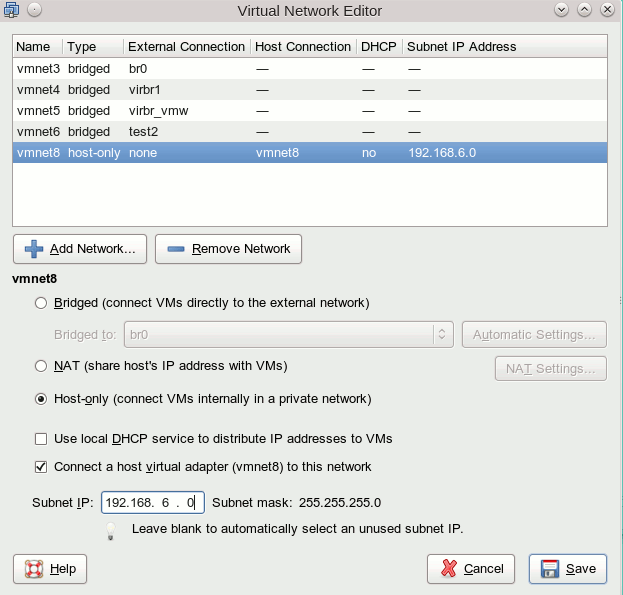
r
(Hinweis: Das ist nicht mehr das standardmäßige vmnet8 Host-Only-Network, das VMware nach einer anfänglichen Installation automatisch konfiguriert, sondern mein eigenes. Ihr könnt zum Testen natürlich auch das vorkonfigurierte verwenden – oder statt der “8” eine andere Nummer wählen).
Leider ist VMware beim Generieren des gleichnamigen Host-Interfaces gnadenlos und überprüft im Gegensatz zu KVM nicht, ob der Adressraum Überschneidungen aufweist:
mytux:~ # ip address show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
...
18: virbr2: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 52:54:00:6b:ab:44 brd ff:ff:ff:ff:ff:ff
inet 192.168.6.1/24 brd 192.168.6.255 scope global virbr2
valid_lft forever preferred_lft forever
19: virbr2-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr2 state DOWN group default qlen 500
link/ether 52:54:00:6b:ab:44 brd ff:ff:ff:ff:ff:ff
20: vmnet8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN group default qlen 1000
link/ether 00:50:56:c0:00:08 brd ff:ff:ff:ff:ff:ff
inet 192.168.6.1/24 brd 192.168.6.255 scope global vmnet8
valid_lft forever preferred_lft forever
inet6 fe80::250:56ff:fec0:8/64 scope link
valid_lft forever preferred_lft forever
mytux:~ #
So gehts natürlich nicht – wir entfernen die IP-Adresse manuell vom VMware-Interface:
mytux:~ # ip addr del 192.168.6.1/24 broadcast 192.168.6.255 dev vmnet8
Nachtrag, 30.01.2016:
Interessanterweise wurde nach einem heutigen Kernelupdate und einer Neukompilation der VMware-Programme der VMware-Dienst “Virtual Ethernet” zur Aktivierung der virtuellen VMware-Netze nicht mehr erfolgreich gestartet, wenn dadurch Überlapps in der IP-Adresse mit irgendeiner gestarteten KVM-Bridge produziert wurden. In einem solchen Fall muss man die VMware Standard-DHCP-Einstellungen für das betroffene virtuelle Netzwerk in der Datei “/etc/vmware/netzwerkname/dhcpd/dhcpd.conf” für das erzeugte Ethernet-Device der Bridge manuell abändern.
Nun kommt ein wichtiger Punkt:
Welche IP ordnen wir dem Interface “vmnet8” statt dessen zu? Erinnern wir uns an Linux-Bridges zu physikalischen Ethernet-Devices (s. etwa: Opensuse – manuelles Anlegen von Bridge to LAN Devices (br0, br1, …) für KVM Hosts):
Dem Ethernet Device (in seiner Funktion als Uplink-Device) darf dort keine IP-Adresse zugeordnet sein! Die richtige Antwort ist auch in diesem Fall: Keine IP-Adresse für das vmnet-Device!
Da wir schon schon auf der Kommandozeile sind, ordnen wir jetzt unserer Bridge “virbr2” das Device “vmnet8” manuell zu:
mytux:~ # brctl addif virbr2 vmnet8
mytux:~ # brctl show virbr2
bridge name bridge id STP enabled interfaces
virbr2 8000.005056c00008 yes virbr2-nic
vmnet8
vnet4
mytux:~ #
Nun statten wir unseren exemplarischen VMware-Gast noch mit einem passenden Interface aus:
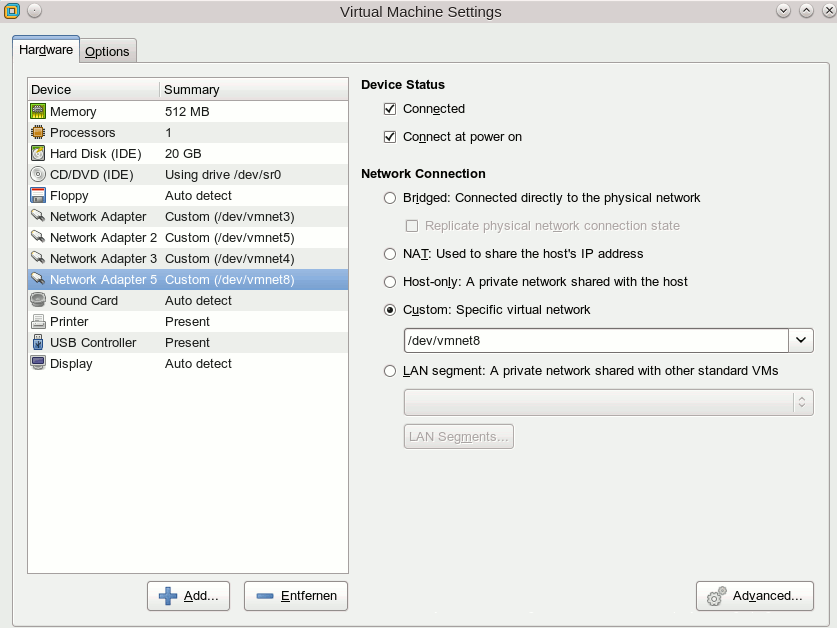
Dann fahren wir den VMware-Gast hoch, konfigurieren unsere neue
Netzwerkschnittstelle dort mit den vorhandenen Tools des Gast-Betriebssystems (hier Windows) manuell und probieren, ob wir den Host erreichen können:
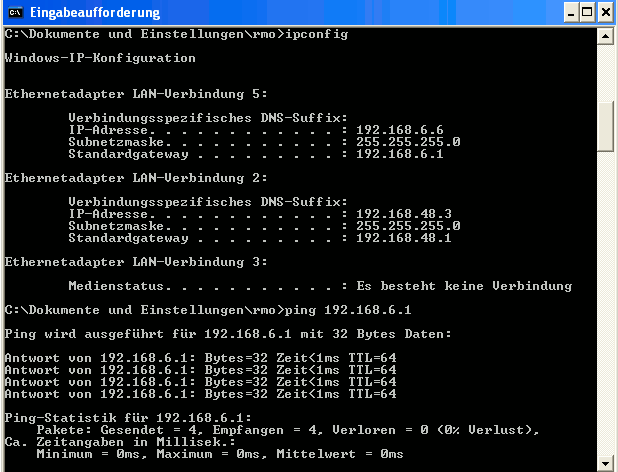
Bestens! Nun zu unserem Linux-KVM-Gast:
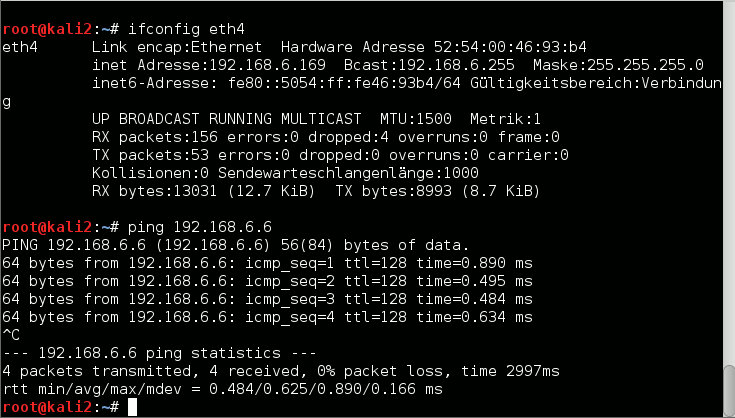
Alles klar! Lösung 3 funktioniert. Der Leser, der das nachbaut, kann ja selbst weitere Tests durchführen.
Lösung 3 erscheint mir persönlich unter den drei hier besprochenen Ansätzen die strukturell klarste zu sein. Sie hat allerdings den Nachteil, dass man sich selbst darum kümmern muss, dass dem VMware Interface (hier “vmnet8”) auch beim nächsten Systemstart die IP-Adresse entzogen wird. Sobald der VMware-Dienst startet, konfiguriert er “vmnet8” ansonsten nämlich wieder mit einer Adresse. Ich habe bislang keine Möglichkeit gefunden, das über die VMware-Netzwerk-Konfigurations-Tools und zugehörige Konfigurationsdateien unter “/etc/vmware” abzustellen.
Auch die Zuordnung des VMware Devices zur Linux-Bridge sollte man am besten selbst vornehmen, um von der Reihenfolge des Starts der diversen Virtualisierungsdienste etwas unabhängiger zu werden. Für die Abarbeitung entsprechender Kommandos erstellt man sich ein kleines Script, dass man mit ein bisschen Geschick auch als eigenen systemd-Service in den systemd-Startup-Vorgang einbinden kann.
Ein anderer Weg zur Realisierung einer Bridge-Kopplung im Geiste von Lösung 3 besteht darin, die VMware Bridge von vornherein als Bridge zu einem im Linux-System angelegten “veth”-Device zu kreieren. Das zweite Interface des veth-Paars wird dann zur Anbindung an die Linux-Bridge eingesetzt. Ehrlich gesagt, ist das dann die Lösung, die ich für die wirklich beste halte. Ich gehe auf den Einsatz von veth-device-Paaren für ein strukturiertes Bridge-Linking ausführlich in einem kommenden Artikel ein (Fun with veth devices, Linux virtual bridges, KVM, VMware – attach the host and connect bridges via veth).
Ein gute Frage! Ohne gezielte Messungen traue ich mich nicht, hierzu Aussagen zu machen. MacVtap bietet z.B. eine leichtgewichtige und auch performante Methode, ein Ethernet-Interface zu nutzen. Die Frage ist allerdings, wie gut das Character-Device, das VMware auf dem Host für ein virtuelles Netz bereitstellt, mit mehreren Kommunikationsströmen zwischen KVM-Gästen und VMware-Gästen, die in Lösung 1 und Lösung 3 gleichzeitig über dieses eine (!) Interface transferiert werden müssen, klarkommt. In Lösung 2 hängt dagegen alles an der unter Linux definierten (und vom Kernel unterstützten) virtuellen Bridge, die gleichzeitig von Gästen aus beiden Virtualisierungs-Umgebungen geteilt wird.
Schwer einzuschätzen …… Bin für Hinweise dankbar. In meinem Mini-Labor für Penetrationstests konnte ich bislang keine signifikanten Unterschiede ausmachen. Werde die Sache aber im Auge behalten …
Standard-Bridges haben aus Security-Sicht einen grundlegenden Nachteil: Sie müssen mindestens über ein angeschlossenes Netzwerk-Interface Pakete für verschiedene IP-Adressen entgegennehmen können. Was bedeutet das eigentlich im Fall unserer zweiten und dritten Lösung für die Sicherheit? Eine sehr gute Frage, die man dann aber auch gleich für die Standardbridge “br0” stellen muss. Hier muss ich den Leser vertrösten. Ich werde mich in kommenden Artikeln mit diesem
Thema etwas intensiver auseinandersetzen. Siehe u.a.:
VMware WS – bridging of Linux bridges and security implications
Für den Augenblick möchte ich allerdings folgende explizite Warnung aussprechen:
Warnung : Das Bridgen einer Bridge – wie in Lösung 2 – ist aus Security-Gesichtspunkten ein gefährliches Spiel. In Pentest-Labors mag so etwas nützlich sein – in Produktivumgebungen sollten beim Admin alle roten Warnleuchten angehen, da die Bridge dann selbst – und nicht nur ein spezielles Uplink-Interface – in den “promiscuous mode” versetzt wird.
Eine Abschottung des Datenverkehrs bestimmter Gastsysteme von und mit externen Systemen gegen ein Mithören durch andere Gäste ist dann nicht mehr garantiert – selbst wenn die Linux-Bridge das im Normalfall leisten würde.
Man muss dann sehr genau wissen, was man tut, und ggf. explizit untersuchen, wie die Linux-Bridge auf die Modifikationen durch erneutes Bridging reagiert.
Was haben wir erreicht? Die von einer “VMware WS” bereitgestellten virtuellen Devices des Hosts erscheinen unter Linux als vollwertige (zeichen-orientierte) Ethernet-Devices. Sie können von einem KVM-Gast z.B. über die Einrichtung eines individuellen MacVtap-Devices genutzt werden. Nach Konfiguration mit IP-Adressen und passenden Routen wird der KVM-Gast dann für alle praktischen Anwendungen Mitglied des VMware-Netzes.
Umgekehrt und alternativ lässt sich eine virtuelle Linux-Bridge, die mit einer IP-Adresse ausgestattet wurde, unter VMware als direkt gebridgtes Ethernet-Device von mehreren VMware-Gästen nutzen. KVM-Gäste werden an die Linux-Bridge mit Standard-Verfahren angebunden. VMware-Gäste, die über das Bridging der Linux-Bridge an selbige Linux-Bridge angeschlossen wurden, kommunizieren direkt mit allen KVM-Gastsystemen.
Beiden Lösungen 1 und 2 ist gemeinsam, dass sie ein bereits virtualisiertes Devices auf einer Metaebene nochmals in virtualisierter Form nutzen. Das allein macht diese Lösungen – wie ich finde – spannend.
Am elegantesten erscheint im Rückblick jedoch Lösung 3 (bzw. Lösung 4) zu sein. Der VMware-Switch wird dabei einfach und ohne IP-Adresse in die Linux-Bridge integriert. Das Vmware-Hostinterface funktioniert dann wie ein Uplink-Device zum VMware-Switch.
Alle beschriebenen Methoden können im Einzelfall jedoch erhebliche Sicherheitsimplikationen nach sich ziehen. Damit werde ich mich in kommenden Artikeln befassen.
Immerhin:
Durch Aktivierung oder Deaktivierung von entsprechend konfigurierten Ethernet-Devices auf KVM- und VMware-Gästen kann man in allen drei dargestellten Fällen schnell zwischen
- einer Konfiguration mit einer über den Host gerouteten Verbindung zum VMware-Netz
- oder einer Konfiguration mit einer direkten Ein-/An-Bindung der Gastsysteme in das jeweils andere Netz ohne Routing
hin- und herschalten.
Das erhöht u.a. die Flexibilität für das Durchspielen verschiedener Penetrationstest-Szenarien in einem virtuellen Test-Labor eines Linux-Hostes beträchtlich. Man kann sich natürlich aber auch etliche Alltags-Szenarien vorstellen, in denen diese Art des Brückenschlags zwischen den Welten nützlich ist. Solange es keine speziellen Sicherheitsanforderungen gibt ….
Viel Spaß nun mit dem Einsatz von Brücken zwischen den Virtualisierungswelten von VMware WS und KVM unter Linux!