
Virtual bridges must be treated with care when security aspects get important. I stumbled into an unexpected kind of potential security topic when I experimented with a combination of KVM and VMware Workstation on one and the same Linux host. I admit that the studied scenario was a very special and academic one, but it really gave me an idea about the threat that some programs may change important and security relevant bridge parameters on a Linux system in the background – and you as an admin may only become aware of the change and its security consequences indirectly.
The scenario starts with a virtual Linux bridge “br0” (created with “brctl”). This Linux bridge gets an IP-address and uses an assigned physical NIC for direct bridging to a physical LAN. You may want to read my previous blog article
Opensuse – manuelles Anlegen von Bridge to LAN Devices (br0, br1, …) für KVM Hosts
for more information about this type of direct bridging.
In our scenario the Linux brigde itself then gets enslaved as an ethernet capable device by a VMware bridge. See also: Opensuse/Linux – KVM, VMware WS – 3 virtuelle Brücken zwischen den Welten (see the detailed description of “Lösungsansatz 2”).
Under which circumstances may such a complicated arrangement be interesting or necessary?
Direct attachment of virtualization guests to physical networks
A Linux host-system for virtualization may contain KVM guests as well as VMware Workstation [WS] guests. A simple way to attach a virtual guest to some physical LAN of the Linux host (without routing) is to directly “bridge” a physical device of the host – as e.g. “enp8s0” – and then attach the guest to the virtual bridge. Related methods are available both for KVM and VMware. (We do not look at routing models for the communication of virtual guests with physical networks in this article).
However, on a host, on which you started working with KVM before you began using VMware, you may already have bridged the physical device with a standard Linux bridge “br0” before you began/begin with the implementation of VMware guests.
Opensuse, e.g., automatically sets up Linux bridges for all physical NICs when you configure the host for virtualization with YaST2. Or you yourself may have configured the Linux bridge and attached both the physical device and virtual “tap”-devices via the “brctl” and the “tunctl” commands. Setting up KVM guests via virt-manager also may have resulted in the attachment of further virtual NIC (tap-) devices to the bridge.
The following sketch gives you an idea about a corresponding scenario:
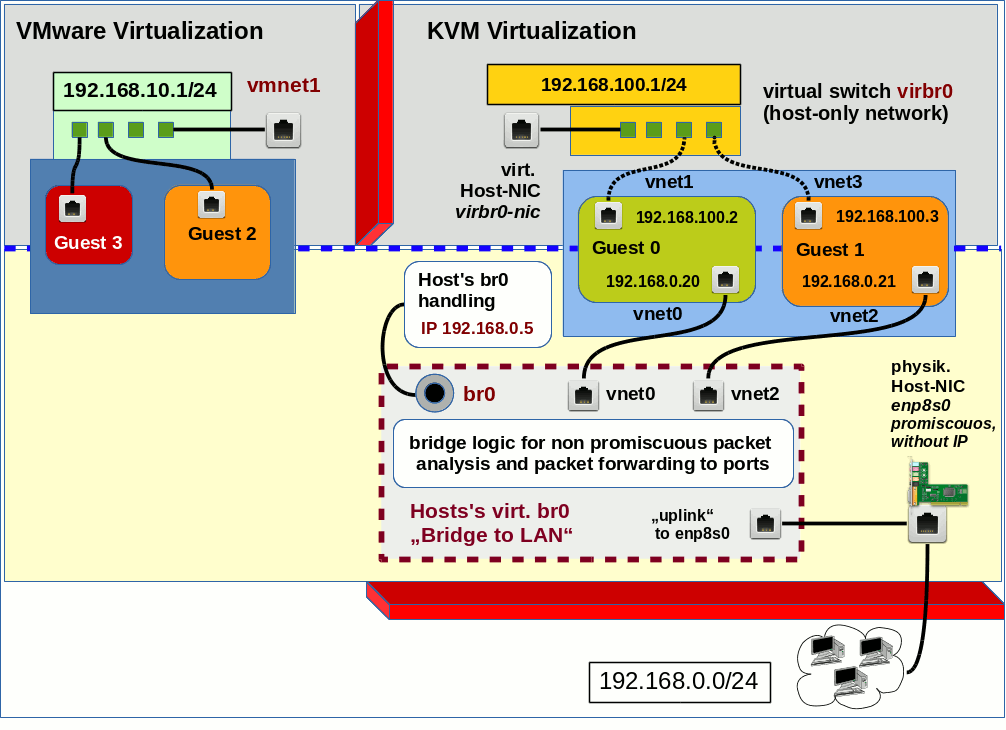
Ignore for a moment the upper parts and the displayed private virtual networks there. In the lower part you recognize our Linux host’s “direct bridge to LAN” in grey color with a red stitched border line. I have indicated some ports in order to visualize the association with assigned (named) virtual and physical network devices.
The bridge “br0” plays a double role: On one side it provides all the logic for packet forwarding to its target ports; on the other side it delivers the packets meant for the host itself to the Linux-kernel as if the bridge were a normal ethernet device. This is not done via an additional tap device of the host but directly. To indicate the difference “br0” is not sketched as a port.
The virtual and
physical devices are also visible e.g. in the output of CLI commands like “ifconfig”, “ip” or “wicked” with listing options as soon as the guest systems are started. The command “brctl show br0” would in addition inform you what devices are enslaved (via virtual ports) by the bridge “br0”.
Note that the physical device has to operate in the so called “promiscuous mode” in this scenario and gets no IP-address.
Bridging the Linux bridge by VMware
Under such conditions VMware still offers you an option to bridge the physical device “enp8s0” – but after some tests you will find out that you are not able to transmit anything across the NIC “enp8s0” – because it is already enslaved by your Linux bridge … Now, you may think : Let us create an additional Linux TAP-device on the host, add it to bridge “br0” and then set up a VMware network bridged to the new tap device. However, I never succeeded with bridging from VMware directly to a Linux tap device. (If you know how to do this, send me an email …).
There are 2 other possibilities for directly connecting your VMware guests (without routing) to the LAN. One is to “bridge the Linux bridge br0” – by administrative means of VMware WS. The other requires a direct connection of the VMware switch via its Host Interface to the Linux-bridge with the spanning tree protocol enabled. We only look at the solution based on “bridging the bridge” in this article.
We achieve a cascaded bridge configuration in which the VMware switch enslaves a Linux bridge via VMwares “Virtual network editor”:
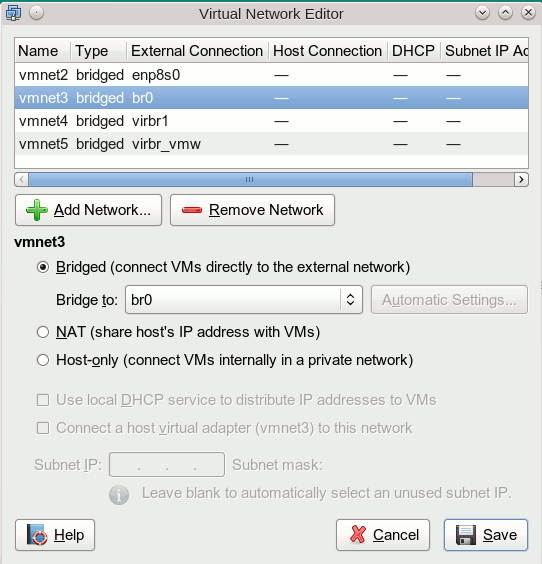
Such a solution is working quite well. The KVM guests can communicate with the physical LAN as well as with the VMware guests as long as all guests NICs are configured to be part of the same network segment. And the VMware guests reach the physical LAN as well as the KVM guests.
The resulting scenario is displayed in the following sketch:
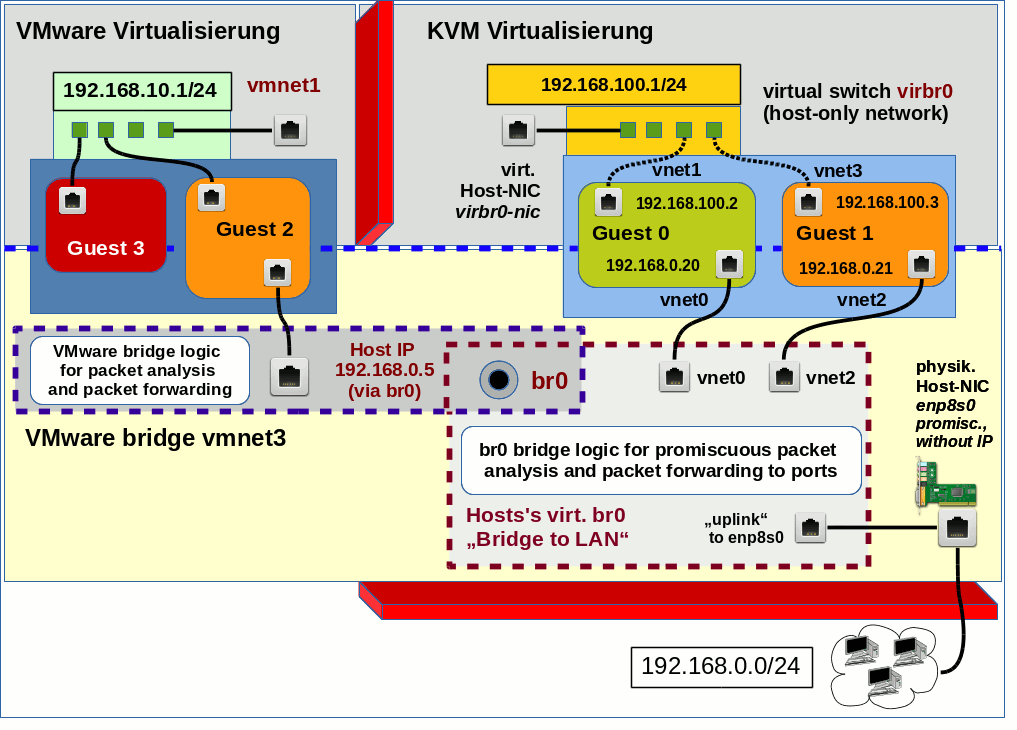
In the lower part you recognize the “cascaded bridging”: The ethernet device corresponding to the bridge “br0” is enslaved by the VMware bridge “vmnet3” in the example. The drawing is only schematic – I do not really know how the “bridging of the bridge” is realized internally.
Interestingly enough the command “brctl” on the Linux side does NOT allow for a similar type of cascaded “bridging of a Linux bridge”. You cannot attach a Linux bridge to a Linux bridge port there.
We shall see that there is a good reason for this (maybe besides additional kernel module aspects and recursive stack handling).
Basic KVM guest “isolation” on a Linux bridge ?
A physical IEEE 802.1D bridge/switch may learn what MAC-addresses are reachable through which port, keep this information in an internal table and forward packets directly between ports without flooding packets to all ports. Is there something similar for virtual Linux bridges? The Linux bridge code implements a subset of the ANSI/IEEE 802.1d standard – see e.g. http://www.linuxfoundation.org/ collaborate/ workgroups/ networking/ bridge#What_does_ a_bridge_do.3F.
So, yes, in a way: There is a so called “ageing” parameter of the bridge. If you set the ageing time to “0” by
brctl setageingtime br0 0
this setting brings the bridge into a “hub” like mode – all accepted packets are sent to all virtual ports – and a privileged user of a KVM guest
may read all packets destined for all guests as well as for the LAN/WAN as soon as he switches the guest’s ethernet device into the “promiscuous mode”.
However, if you set the ageing parameter to a reasonable value like “30” or “40” then the bridge works in a kind of “switch” mode which isolates e.g. KVM guests attached to it against each other. The bridge then keeps track of the MAC adresses attached to its virtual ports and forwards packets accordingly and exclusively (see the man pages of “brctl”). Later on in this article we shall prove this by the means of a packet sniffer. (We assume normal operation here – it is clear that also a virtual bridge can be attacked by methods of ARP-spoofing and/or ARP-flooding).
Now, let us assume a situation with
brctl setageingtime br0 40
and let our Linux bridge be bridged by VMware. If I now asked you whether a KVM guest could listen to the data traffic of a VMware guest to the Internet, what would you answer?
What does “wireshark” tell us about KVM guest isolation without VMware started?
Let us first look at a situation where you have 2 KVM guests and VMware deactivated by
/etc/init.d/vmware stop
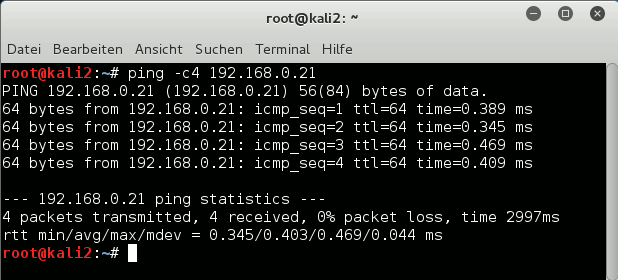
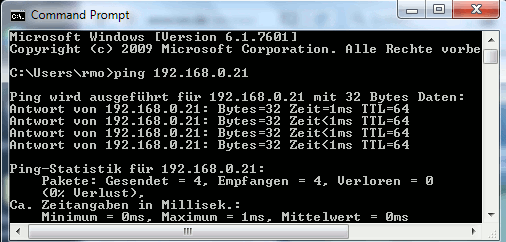
KVM guest 1 [kali2] may have an address of 192.168.0.20 in our test scenario, guest 2 [kali3] gets an address of 192.168.0.21. Both guests are attached to “br0” and can communicate with each other:
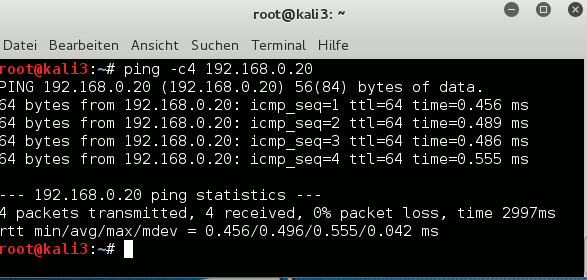
We first set explicitly
brctl setageing br0 30
on the host. Does KVM guest 1 see the network traffic of KVM guest 2 with Internet servers?
To answer this question we start “wireshark” on guest “kali3”, filter for packets of guest “kali2” and first look at ping traffic directly sent to “kali3”:
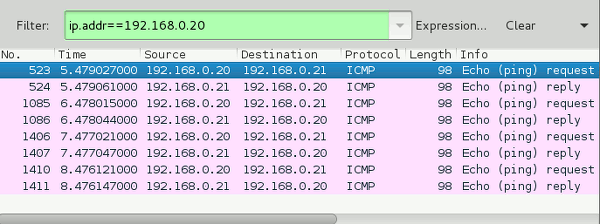
Ok, as expected. Now, if we keep up packet tracking on kali3 and open a web page with “iceweasel” on kali2 we will not see any new packets in the wireshark window. This is the expected result. (Though it can not be displayed as it is difficult to visualize a non-appearance – you have to test it yourself). The Linux virtual bridge works more or less like a switch and directs the internet traffic of kali2 directly and exclusively to the attached “enp8s0”-port for the real ethernet NIC of the host. And incoming packets for kali2 are forwarded directly and exclusively from enp8s0 to the port for the vnet-device used by guest kali2. Thus, no traffic between guest “kali2” and a web server on the Tnternet can be seen on guest “kali3”.
But now let us change the ageing-parameter:
brctl setageing br0 0
and reload our web page on kali2 again:
Then we, indeed, see a full reaction of wireshark on guest kali3:
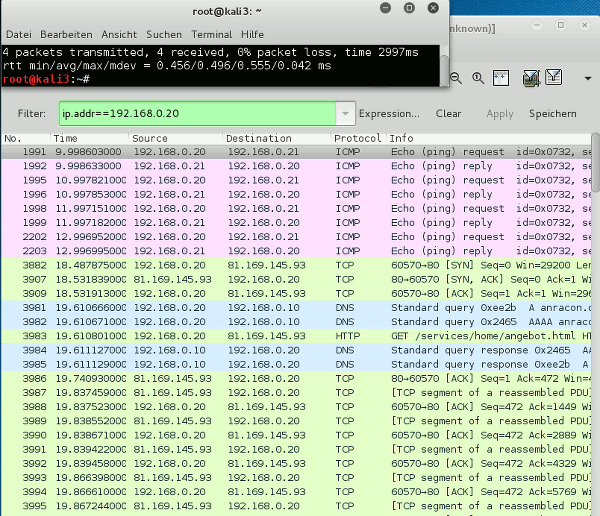
All packets to and from the server are visible! Note that we have not discussed any attack vectors for packet sniffing here. We just discussed effects of special setting for the Linux bridge.
Intermediate result: Setting the ageing-parameter
on a linux bridge helps to isolate the KVM guests against each other.
Can we see an Internet communication of a VMware guest on a KVM guest?
We now reset the ageing parameter of the bridge and start the daemons for VMware WS on our Opensuse host:
mytux:~ # brctl setageing br0 30 mytux:~ # /etc/init.d/vmware start Starting VMware services: Virtual machine monitor done Virtual machine communication interface done VM communication interface socket family done Blocking file system done Virtual ethernet done VMware Authentication Daemon done Shared Memory Available done mytux:~ #
Then we start a VMware guest with a reasonably configured IP address of 192.168.0.41 within our LAN segment:
Then we load a web page on the VMware guest and have a parallel view at a reasonably filtered wireshark output on KVM guest “kali3”:
Wireshark:
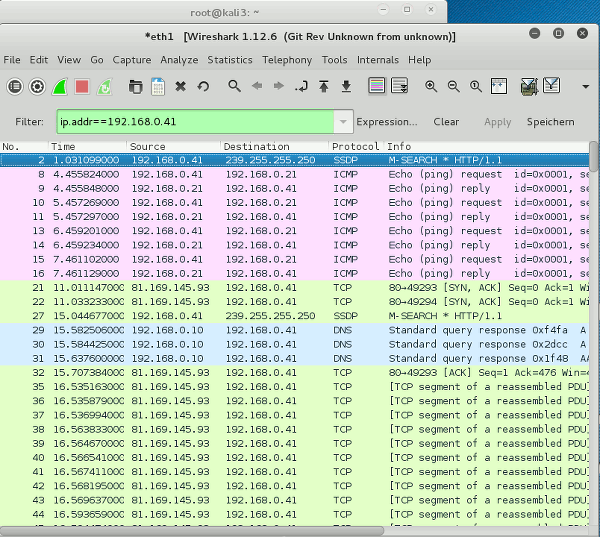
Hey, we can see – almost – everything! A closer look reveals that we only capture ACK and data packets from the Internet server (and other sources, which is not visible in our picture) but not packages from the VMware guest to the Internet server or other target servers.
Still and remarkably, we can capture all packets directed towards our VMware windows guest on a KVM guest. Despite an ageing parameter > 0 on the bridge “br0”!
Guest isolation in our scenario is obviously broken! To be able to follow TCP-packets and thereby be able to decode the respective data streams fetched from a server to a distinct virtualization guest from other virtualization guests is not something any admin wants to see on a virtualization host! This at least indicates a potential for resulting security problems!
So, how did this unexpected “sniffing” become possible?
Bridges and the promiscuous mode of an attached physical device
What does a virtual layer 2 Linux bridge with an attached (physical) device to a LAN do? It uses this special device to send packets from virtualization guests to the LAN and further into the Internet – and vice versa it receives packets from the Internet/LAN sent to the multiple attached guests or the host. Destination IP addresses are resolved to MAC-addresses via the ARP-protocol. A received packet is then transferred to the specific target guest attached at the bridge’s virtual ports. If the ageing parameter is set > 0 the bridge remembers the MAC-address/port association and works like a switch – and thus realizes the basic guest isolation discussed above.
Let us have a look at the Linux bridge of our host :
mytux:/proc/net # brctl show br0
bridge name bridge id STP enabled interfaces
br0 8000.1c6f653dfd1e no enp8s0
vnet0
vnet4
The physical device “enp8s0” is attached. The additional network interfaces “vnet0”, “venet4” devices are tun-devices assigned to our 2 virtual KVM guests “kali2” and “kali3”.
There is a very basic requirement for the bridge to be able to distribute packets coming from the LAN to their guest targets: The special physical device – here “enp8s0” – must be put into the “promiscuous mode”. This is required for the device to be able to receive and handle packets for multiple and different MAC- and associated IP-addresses.
How can we see that the “enp8s0”-device on my test KVM host really is in a promiscuous state? Good question: Actually and as far as I know, this is a bit more difficult than you may expect. Most standard tools you may want to use –
ifconfig, ip, “netstat -i” – fail to show the change if done in the background by bridge tools. However, a clear indication in my opinion is delivered by
mytux:/proc/net # cat /sys/class/net/enp8s0/flags 0x1303
Watch the 3rd position! If I understand the settings corrrectly, I would assume that anything bigger than 1 there indicates that the IFF_PROMISC flag of a structure describing NIC properties is set – and this means promiscuous mode. It is interesting to see what happens if you remove the physical interface from the bridge
mytux:/proc/net # brctl delif br0 enp8s0 mytux:/proc/net # cat /sys/class/net/enp8s0/flags 0x1003 mytux:/proc/net # brctl addif br0 enp8s0 mytux:/proc/net # cat /sys/class/net/enp8s0/flags 0x1303 mytux:/proc/net # cat /sys/class/net/enp9s0/flags 0x1003 mytux:/proc/net # cat /sys/class/net/vnet0/flags 0x1303 mytux:/proc/net # cat /sys/class/net/vnet4/flags 0x1303 mytux:/proc/net #
The promiscuous mode is obviously switched on by the “brctl addif”-action. As a comparison see the setting for the physical ethernet device “enp9s0” not connected to the bridge. (By the way: all interfaces attached to the bridge are in the same promiscuous mode as “enp8s0”. That does not help much for sniffing if the bridge works in a switch-like mode).
Another way of monitoring the promiscuous state of a physical ethernet device in virtual bridge scenarios is to follow the and analyze the output of systemd’s “journalctl”:
mytux:~ # brctl delif br0 enp8s0 mytux:~ # brctl addif br0 enp8s0
The parallel output of “journalctl -f” is:
... .Jan 12 15:21:59 rux kernel: device enp8s0 left promiscuous mode Jan 12 15:21:59 rux kernel: br0: port 1(enp8s0) entered disabled state .... .... Jan 12 15:22:10 mytux kernel: IPv4: martian source 192.168.0.255 from 192.168.0.200, on dev enp8s0 .... .... Jan 12 15:22:13 mytux kernel: device enp8s0 entered promiscuous mode Jan 12 15:22:13 mytux kernel: br0: port 1(enp8s0) entered forwarding state Jan 12 15:22:13 mytux kernel: br0: port 1(enp8s0) entered forwarding state ...
Promiscuous or non promiscuous state of the Linux bride itself?
An interesting question is: In which state is our bridge – better the ethernet device it also represents (besides its port forwarding logic)? With stopped vmware-services? Let us see :
mytux:~ # /etc/init.d/vmware stop .... mytux:~ # cat /sys/class/net/br0/flags 0x1003
Obviously not in promiscuous mode. However, the bridge itself can work with ethernet packets addressed to it. In our configuration the bridge itself got an IP-address – associated with the
host:
mytux:~ # wicked show br0 enp8s0 vnet0 vnet4
enp8s0 enslaved
link: #2, state up, mtu 1500, master br0
type: ethernet, hwaddr 1c:6f:65:3d:fd:1e
config: compat:/etc/sysconfig/network/ifcfg-enp8s0
br0 up
link: #5, state up, mtu 1500
type: bridge
config: compat:/etc/sysconfig/network/ifcfg-br0
addr: ipv4 192.168.0.19/24
route: ipv4 default via 192.168.0.200
vnet4 device-unconfigured
link: #14, state up, mtu 1500, master br0
type: tap, hwaddr fe:54:00:27:4e:0a
vnet0 device-unconfigured
link: #18, state up, mtu 1500, master br0
type: tap, hwaddr fe:54:00:85:20:d1
mytux:~ #
This means that the bridge “br0” also acts like a normal non promiscuous NIC for packets addressed to the host. As the bridge itself is not in promiscuous mode it will NOT handle packets not addressed to any of its attached ports (and associated MAC-addresses) and just throw them away. The attached ports – and even the host itself (br0) – thus would not see any packets not addressed to them. Note: That the virtual bridge can separate the traffic between its promiscuous ports and thereby isolate them with “ageing > 0” is a reasonable but additional internal feature.
What impact has VMware’s “bridging the bridge” on br0 ?
However, “br0” becomes a part of a VMware bridge in our scenario – just like “enp8s0” became a part of the linux bridge “br0”. This happens in our case as soon as we start a virtual VMware machine inside the user interface of VMware WS. Thinking a bit makes it clear that the VMware bridge – independent of how it is realized internally – must put the device “br0″ (receiving external data form the LAN) into the promiscuous mode”. And really:
mytux:/sys/class/net # cat /sys/class/net/br0/flags 0x1103 mytux:/sys/class/net #
This means that the bridge now also accepts packets sent from the Internet/LAN to the VMware guests attached to the VMware bridge realized by a device “vmnet3”, which can be found under the “/dev”-directory. These packets arriving over “enp8s0” first pass the bridge “br0” before they are by some VMware magic picked up sat the output side of the Linux bridge and transmitted/forwarded to the VMware bridge.
But, obviously the Linux program responsible for the handling of packets reaching the bridge “br0” via “enp8s0” and the further internal distribution of such packets kicks in first (or in parallel) and gets a problem as it now receives packets which cannot be directed to any of its known ports.
Now, we speculate a bit: What does a standard physical 802.1D switch typically do when it gets packets addressed to it – but cannot identify the port to which it should transfer the packet? It just distributes or floods it to all of its ports!
And hey – here we have found a very plausible reason for our the fact that we can read incoming traffic to our VMware guest from all KVM guests!
Addendum 29.01.2016:
Since Kernel 3.1 options can be set for controlling and stopping the flooding of packets for unknown target MACs to specific ports of a Linux bridge. See e.g.:
http://events.linuxfoundation.org/ sites/ events/ files/ slides/ LinuxConJapan2014 _makita_0.pdf
The respective command would be :
echo 0 > /sys/class/net/
It would have to be used on all tap ports (for the KVM guests) on the Linux bridge. Such a procedure may
deliver a solution to the problem described above. I have tested it, yet.
Conclusion
Although our scenario is a bit special we have learned some interesting things:
- Bridging a Linux bridge as if it were a normal ethernet device from other virtualization environments is a dangerous game and should be avoided on productive virtualization hosts!
- A Linux bridge may be set into promiscuous mode by background programs – and you may have to follow and analyze flag entries in special files for a network device under “/sys/class/net/” or “journalctl” entries” to get notice of the change! Actually, on a productive system one should monitor these sources for status changes of network devices.
- A Linux bridge in promiscuous mode may react like a 802.1D device and flood its ports with packets for which it has not learned MAC adresses yet – this obviously has security and performance implications – especially when the flooding becomes a permanent action as in our scenario.
- Due to points 2 and 3 the status of a Linux bridge to a physical ethernet device of a host must be monitored with care.
Regarding VMware and KVM/Linux-Bridges – what are possible alternatives for “linking” the virtual bridges of both sides to each other and enable communication between all attached guests?
One simple answer is routing (via the virtualization host). But are there also solutions without routing?
From what we have learned a scenario in which the virtual VMware switch is directly attached to a Linux bridge port seems to be preferable in comparison to “bridging the bridge”. Port specific MAC addresses for the traffic could then be learned by the Linux bridge – and we would get a basic guest isolation. Such a solution would be a variation of what I have described as “Lösung 3” in a previous article about “bridges between KVM and VMware”:
KVM, VMware WS – 3 virtuelle Brücken zwischen den Welten
However, in contrast to “Lösung 3” described there we would require a Linux bridge with activated STP protocol – because 2 ethernet devices would be enslaved by the Linux bridge. Whether such a scenario is really more secure, we may study in another article of this blog.
Links
https://books.google.de/books?id=MRChaUQr0Q0C&pg= PA301&dq= bridge+ethernet+promiscuous+mode&hl= de&sa=X&redir_esc=y#v=onepage&q=bridge%20 ethernet%20 promiscuous%20mode&f=false
See especially pages 301 – 304
http://www.linuxfoundation.org/ collaborate/ workgroups/ networking/ bridge# What_does_a_ bridge_do.3F
See especially the paragraph “Why is it worse than a switch?”
Promiscuous mode analysis
https://www.kernel.org/ doc/ Documentation/ ABI/ testing/ sysfs-class-net
http://grokbase.com/ t/ centos/ centos/ 1023xtt5fd/ how-to-find-out-promiscuous-mode
https://lists.centos.org/ pipermail/ centos/ 2010-February/ 090269.html
Wrong info via “netstat -i ”
http://serverfault.com/ questions/ 453213/ why-is-my-ethernet-interface-in-promiscuous-mode