In meinem ersten Artikel über die die Asus Xonar D2X unter Linux
Asus Xonar D2X unter Linux / Opensuse 13.1 – I
hatte ich – etwas oberflächlich und subjektiv – ein paar Aspekte dieser Karte mit denen konkurrierender Karten von Creative verglichen. Nun wenden wir uns folgenden Fragen zu:
- der Inbetriebnahme der Karte unter Opensuse/KDE über YaST2
- Wie präsentiert sich die Karte unter KDE – im speziellen unter KMix ?
Bei all dem, was ich nachfolgend darstelle, gilt: Pulseaudio ist natürlich vollständig deaktiviert :-).
Sonst erhält man unter KDE nicht den direkten Zugriff auf die dargestellten Features. Zudem produziert eine Trennung der Soundkanal-Regler unter “pavucontrol” von Pulseaudio für avanciertere Karten faktisch nur Mist. Und wer will schon anfangen, an den schwer zu verstehenden Pulseaudio-Systemdateien herumzufrickeln ?
Ich verlasse mich da lieber auf ALSA und seine (halbwegs) verständlichen Konfigurationsmöglichkeiten – das Leben ist einfach zu kurz, als dass ich mich als normaler End User mit einer fehlerhaften bis nicht funktionierenden und z.T. völlig überzogenen Abstraktionsschicht des Soundsystems namens Pulseaudio herumschlagen möchte. Das Teil hat mich schon zu viele Nerven gekostet … weg damit.
Unter Opensuse 13.1 deaktiviert man Pulseaudio am einfachsten über
YaST2 > Hardware > Sound > Other > PulseAudio Configuration
und durch Betätigen der dortigen Checkbox. Ansonsten findet man Anregungen zur Deaktivierung unter
http://www.beastwithin.org/blogs/wolfheadofselfrepair/2013/07/pulseaudio-insidious-linux-malware
Im Linux-System sollte man für den ordnungsgemäßen Soundbetrieb ferner die erforderlichen Module von ALSA und der “gstreamer”-Software aus einem der einschlägigen Repositories (SuSE Update, Packman, SuSE Multimedia Libs) konsistent installiert haben, z.B.von
- http://download.opensuse.org/update/13.1/
- http://download.opensuse.org/repositories/multimedia:/libs/openSUSE_13.1/
- http://ftp.gwdg.de/pub/linux/packman/suse/openSUSE_13.1/
Bei einer Standardinstallation von Opensuse 13.1 sind die minimal erforderlichen Alsa und Gstreamer-Module schon installiert. Es lohnt sich jedoch, sich mal in anderen als den Opensuse Basis-Repositories nach Erweiterungen umzusehen.
“Gstreamer” wird als Backend für KDE’s Soundabstraktionsschicht “Phonon” eingesetzt. Phonon nutzt letztlich wiederum ALSA – soweit installiert. Das Gstreamer Backend funktioniert übrigens nach meiner Erfahrung inzwischen sehr viel besser als noch vor ca. 2 Jahren, als es unter KDE das “xine”-Backend für Phonon dauerhaft ersetzte. Für mich ein Muster-Beispiel für einen nach einer Übergangszeit wirklich gelungenen Ersatz einer wichtigen Opensource-Komponente durch einen andere.
Grundinstallation der Xonar D2X unter OS 13.1
Voraussetzung für das folgende ist natürlich eine abgeschlossene Installation der Hardware – also der Soundkarte in einem frein PCIe-X1 slot. Man achte dabei auf ein eventuelles boardspezifisches “lane und bandwidth sharing” mit anderen Slots.
Die Inbetriebnahme der Xonar D2X unter Opensuse 13.1 ist relativ simpel. Unter KDE 4 führt man die Basisinstallation z.B. mit Hilfe von
YaST2 > Hardware > Sound
durch.
Man wählt dann die Soundkarte Virtuoso 200 (Xonar D2X) aus der Liste
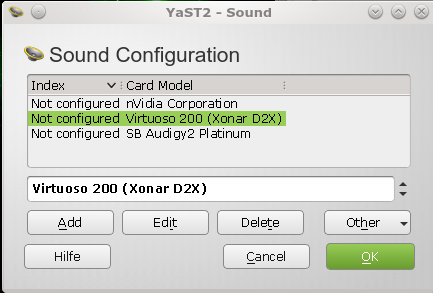
aus, drückt dann auf den “Edit-Button” und bestätigt die nachfolgenden Dialoge. Die Soundkarte wird nach dem Verlassen des Konfigurations-Dialogs dann auch direkt als reines Alsa Device gestartet. Benötigt werden für den reibungslosen Betrieb der Asus D2X unter KDE zumindest die Kernelmodule
“snd_virtuoso”, “snd”, “sndcore”, “snd_oxygen_lib”, “snd_pcm”, “snd_page_alloc”, “snd_timer”.
Siehe die Liste der geladenen Kernelmodule weiter unten. Diejenigen, die mit Midi operieren wollen (extra “Board” im Lieferumfang) sollten (vermutlich) auch die Module “snd_mpu401_uart”,”snd_rawmidi”, “snd_seq_device” und “snd_seq” zum Einsatz bringen.
YaST startet je nach erkannter HW diese Module. Sind in einem System mehrere Soundkarten im Spiel erweitert sich die Modulliste entsprechend. Hat man mehrere Soundkarten aktiv, so kann man mit Hilfe von
YaST2 > Hardware > Sound > Other > Set as the primary card
eine der vorhandenen Karten auswählen und als primäre auswählen. Ein anderer direkter Weg zur Soundkarten-Priorisierung wird im nächsten Artikel dieser Serie angesprochen. Ich will auf die Grundkonfiguration mehrerer gleichzeitig aktiver Karten unter KDE und ALSA hier aber nicht weiter eingehen.
Nach der YaST-Installation sehen die KDE-Systemeinstellungen wie folgt aus:
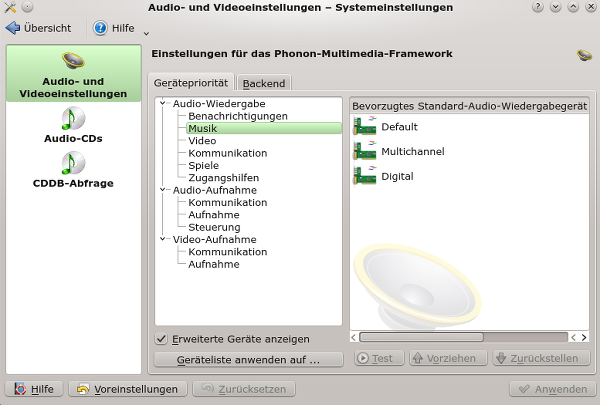
Ich empfehle, das System nun komplett neu zu starten. KDE4 und Phonon reagieren nämlich auf die neu vorhandene Karte und stellen dann unter KDE’s “Systemeinstellungen > Hardware > Multimedia” mehr als die puren Alsa Standard Devices dar. Nach dem Neustart ergibt sich auf meinem System unter KDE etwa folgendes Bild (ohne Option erweiterte Geräte):
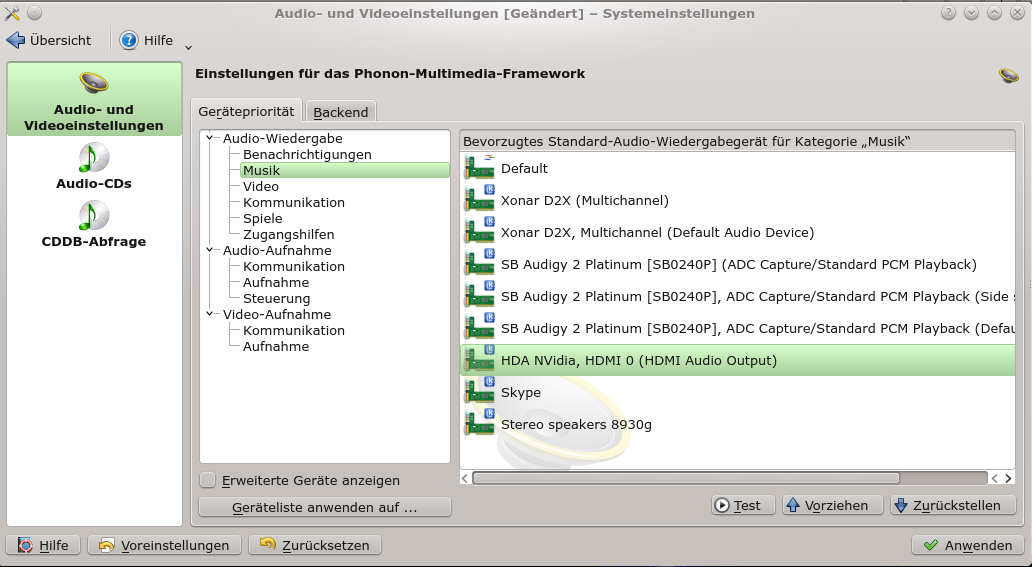
Mit der aktivierten Option “Erweiterte Geräte” erhalte ich auf meinem System folgende lange Liste:
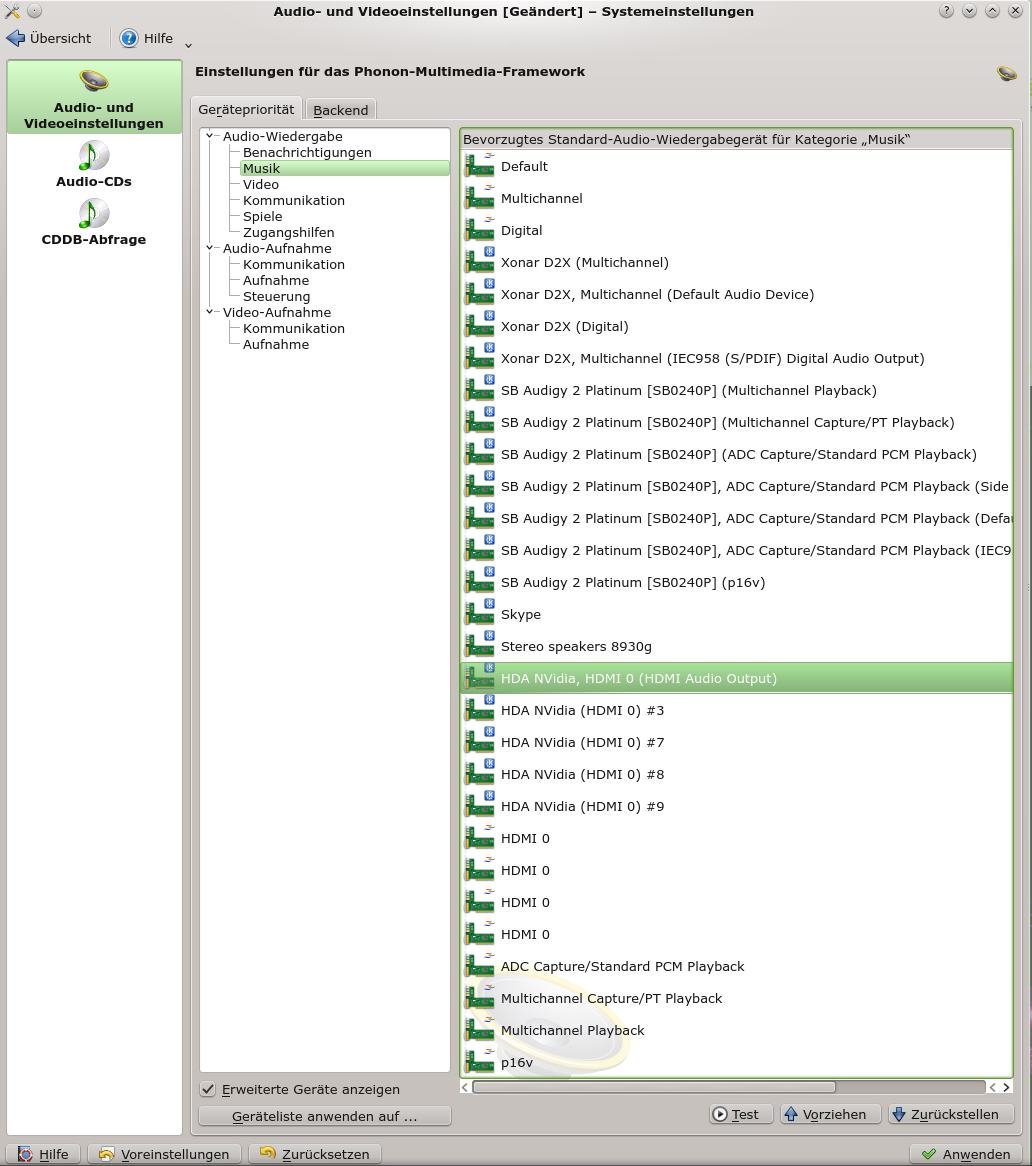
Sie ist in meinem Fall so komplex, weil ich drei Karten im System installiert habe und diese alle in der Vergangenheit auch erfolgreich getestet habe. Systemd, udev und KDE vergessen das offenbar nicht so ohne weiteres, selbst wenn unter YaST die Module für die anderen Karten im Moment gar nicht aktiviert erscheinen (s. Bild oben). Die erforderlichen Kernel-Module werden von systemd über udev beim Systemstart trotzdem geladen:
mytux:~ # lsmod | grep snd
snd_hda_codec_hdmi 45213 4
snd_virtuoso 45131 2
snd_oxygen_lib 45235 1 snd_virtuoso
snd_mpu401_uart 14169 1 snd_oxygen_lib
snd_emu10k1 169303 2
snd_hda_intel 48171 2
snd_rawmidi 34523 2 snd_mpu401_uart,snd_emu10k1
snd_ac97_codec 138428 1 snd_emu10k1
snd_hda_codec 205080 2 snd_hda_codec_hdmi,snd_hda_intel
ac97_bus 12730 1 snd_ac97_codec
snd_pcm 110211 6 snd_hda_codec_hdmi,snd_oxygen_lib,<br>snd_emu10k1,snd_hda_intel,<br>snd_ac97_
codec,snd_hda_codec
snd_util_mem 14117 1 snd_emu10k1
snd_hwdep 13602 2 snd_emu10k1,snd_hda_codec
snd_seq 69752 0
snd_timer 29423 3 snd_emu10k1,snd_pcm,snd_seq
snd_seq_device 14497 3 snd_emu10k1,snd_rawmidi,snd_seq
snd 87417 26 snd_hda_codec_hdmi,snd_virtuoso,<br>snd_oxygen_lib,snd_mpu401_uart,snd_emu10k1,<br>snd_hda_intel,snd_rawmidi,snd_ac97_codec,<br>snd_hda_codec,snd_pcm,snd_hwdep,<br>snd_seq,snd_timer,snd_seq_device
soundcore 15047 1 snd
snd_page_alloc 18710 3 snd_emu10k1,snd_hda_intel,snd_pcm
mytux:~ #
Mir ist unklar, ob das eine Inkonsistent zwischen YaST, der sonstigen SuSE-Soundkonfiguration, den systemd- oder udev-Einstellungen darstellt. Vermutlich erkennt udev die onboard Karte sowie die Audigy automatisch und lädt unter systemd die zugehörigen Treiber. Ich habe das im Moment nicht weiter untersucht. Blacklisten wollte ich die Module auch nicht, da ich bisher keine negativen Effekte der geladenen Kernelmodule feststellen konnte. Alsa kann jedenfalls auch auf die anderen Karten zugreifen.
Verfügbare Regler der D2X unter Kmix – Vergleich mit einer Audigy 2
Ich hatte im ersten Beitrag bereits festgestellt, dass eine Asus D2X eher etwas für Puristen ist, die einfach nur guten Sound hören wollen. Dieser Eindruck bestätigt sich im Vergleich zu Creative Karten beim Angebot an einstellbaren Kanälen und Features.
Ich zeige zunächst das vollständige Kanalbild unter Kmix, das uns KDE und Alsa auf Basis eines über die Jahre sehr hoch entwickelten Kernelmoduls bieten. Ich verwende wegen der großen Anzahl der Kanäle 4 Bilder:
Kmix-Regler der Audigy 2
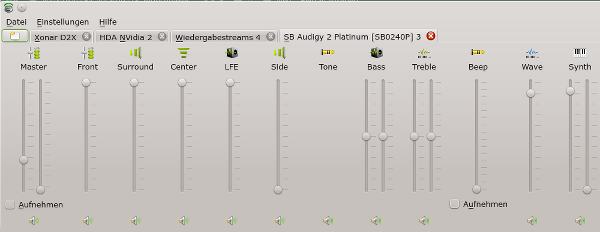
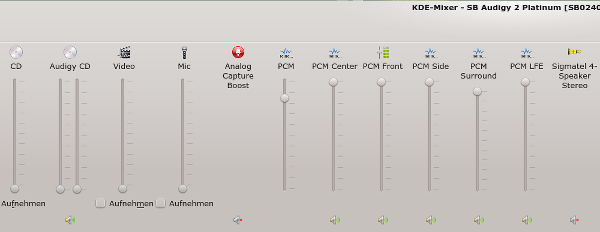

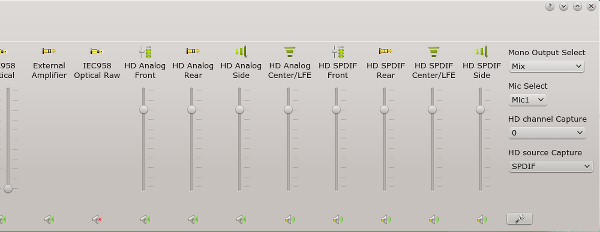
Man ist regelrecht erschlagen von der Vielfalt der Regelungsmöglichkeiten, die in der Regel aber auch funktionieren. Die Audigy 2 ist hier üppigst ausgestattet. (Übrigens: Unter PulseAudio würde man als End User davon leider gar nichts mitbekommen …)
Nun zur Xonar D2X. Sie gibt sich sehr viel bescheidener:
Kmix-Regler der Xonar D2X
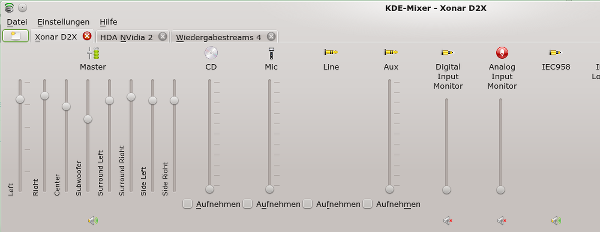
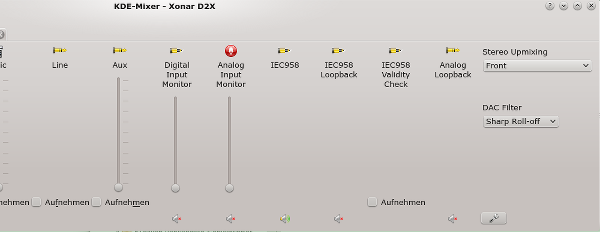
Ob dieser bescheidene Eindruck an Regelbarkeit nun allein am Treiber liegt, vermag ich nicht wirklich zu beurteilen. Die Trennung der Output-Kanäle habe ich hier
übrigens unter KMIX manuell vorgenommen.
Keine Klangregelung
Was sofort ins Auge fällt: Es gibt keine Regler für Höhen und Tiefen. Das hatte ich bereits im ersten Beitrag dieser Serie angesprochen. Auch separate Regler für Synth, Wave und PCM sind nicht vorhanden.
Keine Anhebung des Sounds über alle Kanäle unter Beibehaltung der Lautstärkeverhältnisse zwischen den Kanälen
Alle getrennt erscheinenden Regler für die Output-Kanäle ergeben sich aus der Trennung genau eines Master-Kanals. Man kann den Master nicht im Sinne einer gemeinsamen prozentualen Anhebung aller Kanäle – bei ansonsten unterschiedlichen und gleichbleibenden relativen Niveaus der Kanäle zueinander – separat steuern, wie dies etwa bei der Audigy 2 der Fall ist. Dies ist ein weiterer sehr ärgerlicher Punkt der D2X-Karte unter Linux – denn regelt man in der verkürzten Ansicht des Mixers (etwa beim Klick auf das Symbol im Systemabschnitt der Steuerleiste) den Master, so werden alle Output-Kanäle auf ein- und dasselbe Lautstärke-Niveau gesetzt – auch z.B. der Bass-Lautsprecher. Das verändert dann natürlich das Klangbild insgesamt. Und es ist mühsam, die Verhältnisse der Kanäle wieder nachzuregulieren.
Hier erweist es sich als Vorteil, wenn die betriebene Lutsprecher-Anlage einen externen, unabhängig von der Soundkarte bedienbaren Lautstärkeregler aufweist. Dann stellt man mit Kmix einmal die Lautstärkeverhältnisse zwischen den Kanälen auf dem Linux-PC fest ein und regelt die Gesamtlautstärke nur noch über den externen Regler.
Zeit für eine Zwischenbilanz. Rein auf Basis des mageren Erscheinungsbildes unter Kmix kommt man zu folgender Aussage:
Die Asus D2X entpuppt sich (unter Linux) tatsächlich als Karte, die digitalen Input
- in analoge Signale umwandelt und dann unmodifiziert an die analogen Output-Kanäle weiterreicht oder
- unmodifiziert an einen optischen Digitalausgang durchreicht.
Wir sprechen im Kern also über einen hochwertigen Digital-Analog-Wandler.
Eine digitale und durch den Anwender in Grenzen regelbare Manipulation des eingehenden Sound-Signals wie durch den Soundprozessor der Audigy2 findet entweder von Haus aus nicht statt oder ist eben über die aktuellen Linux-Treiber zumindest nicht zugänglich und/oder regelbar. Die Karte hinterlässt hinsichtlich der Features unter Linux einen wirklich sehr puristisch Eindruck – wie schon gesagt.
Angesichts des Preises der Karte fängt es hier an, doch etwas ärgerlich zu werden …. Ich finde, dass dieser Befund für manch einen ein sehr guter Grund sein kann, die Finger von der Karte zu lassen. Ich möchte es nochmals betonen: Die Karte lohnt sich nicht für einen Linux-Anwender, der gelegentlich neben der Arbeit am PC mal Musik hören will, und der dennoch vielfältige Einstellmöglichkeiten erwartet.
Dieser vorläufige Befund hat aber noch eine weitere Auswirkung (s. nächste Abschnitt).
Einschränkung der Xonar D2X : 2-Kanal-Stereo-Output für Stereo-Input – Spiegelung des Sounds durch Mixer-Schalter nur eingeschränkt möglich
Ohne weitere Schritte gilt:
2 Stereo Kanäle in – 2 Stereo Kanäle out. Wieso sollte man eigentlich mehr erwarten? Nun, von sämtlichen bisher betriebenen Audigy- oder X-Fi-Karten war ich es gewohnt, dass Stereo-Input durch den Soundprozessor automatisch auf andere analoge Output-Kanäle als “Front Left” und “Front Right” vervielfältig bzw. gespiegelt wurde. Natürlich wurden dabei auch ein Center-Speaker und eine Bass-Speaker angemessen berücksichtigt. Bzgl. des Tiefton-Kanals wurde der Sound angeblich sogar frequenzabhängig zugewiesen. Das kann man bei der Xonar D2X für reine ogg-vorbis-, flac-, wav-, mp3-Musik-Player (Amarok, Clementine, Banshee etc.) in einer Standardeinrichtung weitgehend vergessen. Es ist auf einfache
Weise keine umfassende Sound-Verteilung auf 5.1 oder 7.1 Speaker-Systeme möglich …. Kanal für Kanal wird durchgereicht.
Bei Mehrkanal-Input wie z.B. von einem Video-Player wie MPLAYER gilt dann aber auch: da schleift auch die Xonar D2X den Sound kanalgetreu durch. Hier erhält man also echten Mehrkanal-Ton, wenn der Film einen solchen aufwies.
Nun könnte man bzgl. der reinen Stereo-Musikwiedergabe theoretisch mit der Einschränkung des 2-Kanal-Outputs leben, aber mich persönlich hat das erstmal frustriert. Schließlich habe ich – wie im letzten Abschnitt erwähnt – eine eine kleine billige Mehrkanal-Anlage an meinem Linux-System hängen. Und manchmal hätte man gerne – speziell bei SW-Entwicklungsarbeiten – eine Rundum-Beschallung.
Was also tun? Ein erste einfache Einstellmöglichkeit liefert die Karte doch ! Auf den Kmix-Bildern weiter oben erkennt man bei genauerem Hinsehen einen Schalter für einen “Stereo-Upmix”. Aber nicht zu früh gefreut: Dieser Schalter erlaubt zwar eine Spiegelung
Front Left => Rear Left (und ggf. => Side Left)
Front Right => Rear Right (und ggf. => Side Right)
Ein vorhandener Centre Speaker und ein Bass Speaker bleiben dabei aber leider außen vor.
Linux wäre nicht Linux, wenn es hierfür nicht eine Lösung gäbe. Und dazu müssen wir im nächsten Beitrag
Asus Xonar D2X unter Linux / Opensuse 13.1 – III – Alsa Upmix 2.0 auf 5.1
ein klein wenig an einer persönlichen Alsa-Konfiguration basteln.