Im letzten Blog-Post
Erste Schritte mit Git für lokale und zentrale Repositories unter Eclipse – I
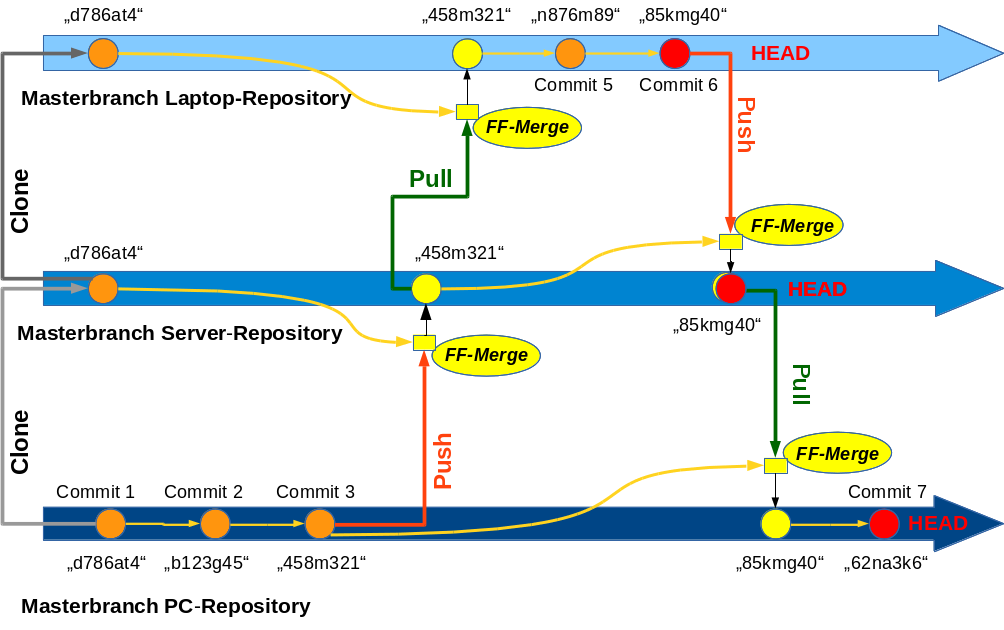
hatte ich ein einfaches Szenario beschrieben, das regelmäßige Wechsel zwischen mobiler und ortsgebundener Entwicklungsarbeit beinhaltet und gerade im Leben von Freiberuflern immer wieder auftritt. Versionskontrolle erfordert im Zuge solcher Wechsel das Arbeiten mit lokalen und zentralen Repositories sowie systematische Abgleichoperationen zwischen solchen Repositories. Git ist für derartige Szenarien gut geeignet. Um entsprechende Experimente durchführen zu können, haben wir im letzten Post unser einfaches Wunschszenario in durchzuführende logische Schritten untergliedert.
Unser Ziel ist nun eine Abbildung der identifizierten Schritte in eine Git-Versionsverwaltung unter der IDE Eclipse. Daraus ergaben sich konkrete Aufgabenstellungen für Tests. In diesem Post befassen wir uns mit den ersten drei der identifizierten Aufgaben:
- Aufgabe 1: Erstellen eines lokalen Git-Repositories auf dem PC.
- Aufgabe 2: Klärung: Wo liegt der “Working Tree”? Welchen Verzeichnisbaum zeigt Eclipse?
- Aufgabe 3: Einbringen des Inhalts des Projektverzeichnisbaums in den Master-Branch des lokalen Repositories. Initiales Commit.
Ich setze für das Verständnis der nachfolgenden Ausführungen einige Begrifflichkeiten voraus, die ich im letzten Blog-Post dieser Serie erläutert habe. Da es sich hier um einen Linux-Blog handelt beschreibe ich alle Schritte zur Lösung der Aufgaben für eine Linux/Eclipse-Umgebung, Linux-Verzeichnisbäume und, soweit erforderlich, Linux-Shell-Kommandos. Vermutlich lässt sich das Meiste aber auch direkt auf eine MS-Umgebung übertragen.
Abgrenzung “Eclipse Workspace” versus “Git Workspace”
In deutschsprachigen Büchern zu Git ist oft die Rede von einem (Git-) “Workspace”. Andererseits gibt es aber auch unter Eclipse “Workspaces”. Diese sollten wir im Folgenden begrifflich auseinanderhalten:
- Eclipse Workspace: Ein Eclipse Workspace verwaltet eine Ansammlung von mehreren Projekten und zugehörige Dateien in projektspezifischen Verzeichnissen. Für den gesamten Eclipse Workspace können verschiedene grundlegende Eclipse-Eigenschaften (Settings) projektübergeordnet eingestellt werden. Ich kürze einen Eclipse-Workspace nachfolgend mit EWS ab. Ein EWS ist regelmäßig mit einem zugehörigen Verzeichnis verbunden. Das schließt aber definierte Links in weitere zugeordnete Verzeichnisse nicht aus. Im Besonderen müssen die Projektdateien nicht zwingend in einem Verzeichnis unterhalb des Workspace-Verzeichnisses beheimatet sein. Die EWS-spezifischen Eclipse-Einstellungen werden jedoch in versteckten Dateien/Unterverzeichnissen des EWS-Verzeichnisses hinterlegt. Solche speziellen Dateien/Verzeichnisse eines EWS wird man später nicht unbedingt in einem GIT-Repository erfassen wollen, da sie typischerweise Anweisungen beinhalten, die für eine Eclipse-Version spezifisch sind; ein abgleichender Transfer auf ein anderes System mit einer älteren Eclipse-Version könnte dann zu Problenmen auf der Eclipse-Ebene führen.
- Git-Workspace: Ein Git-Workspace bezieht sich auf Dateien einer Verzeichnisstruktur, deren Änderungshistorie in einem Git-Repository im Sinne einer Versionierung aufgezeichnet und verwaltet wird. Ich kürze nachfolgend einen Git-Workspace mit GWS ab. Ein GWS besteht typischerweise aus einem reinen Repository-Bereich unterhalb eines speziellen Verzeichnisses “.git” und einem sog. “Working
Tree“, dessen Dateien eine definierte Code-Version auf einem Entwicklungs-“Branch” (-Zweig) beinhalten. Auf der Eclipse-Ebene entspricht der Working-Tree typischerweise der Verzeichnis-Struktur eines Projektes mit den dazu gehörigen aktuellen Code-Dateien.
Vorbereitende Schritte
Bevor wir uns an die Lösung unserer Aufgaben machen, müssen wir je nach Ausgangssituation ein paar vorbereitende Schritte treffen. Für diese und auch für nachfolgende Aktionen gilt:
Wir legen uns vorab immer eine Sicherheitskopie des gesamten EWS und ggf. auf Datei- oder Ordnerebene verlinkter anderer Eclipse Workspaces an. Ferner sichern wir vor Experimenten mit Dateien eines realen Projekts evtl. existierende SVN-Repositories, die mit diesem Projekt verbunden sein mögen.
Vorbereitender Schritt 0 – Git und das Eclipse EGit-Plugin installieren
Auf unserem Linux-PC installieren wir zunächst das für die jeweilige Distribution verfügbare Git-Paket. Wir erhalten damit u.a. auch Zugriff auf CLI-Kommandos, die im Zuge der Repository-Verwaltung eingesetzt werden können. Die Kenntnis solcher Kommandos ist übrigens nützlich, auch wenn man – wie ich – grafisch Bedien-Elemente einer IDE verwenden will. (Man kann unter Linux eine Git-basierte Versionsverwaltung von Projekten auch ausschließlich auf der Kommandozeile betreiben.) Wer Lust hat, kann neben Git selbst gleich auch noch die Pakete “gitg”, “Qgit”, “Giggle” und ggf. auch “git-cola” oder “cola-git” installieren. Jedes dieser Pakete bietet eine eigene unabhängig von Eclipse nutzbare GUI für Git mit mehr oder weniger Komfort und Funktionalität an.
Für Eclipse selbst gibt es ein Git-Plugin namens EGit (welches wiederum JGit benötigt). EGit sollte im Haupt- oder Update-Repository der jeweiligen Eclipse-Installation (hier Neon 3) in einer passenden Version verfügbar sein. Für den aktuellsten Stand greift man auf folgendes Eclipse-Repository zu:
http://download.eclipse.org/egit/updates.
Von dort können wir EGit genauso wie andere Eclipse Plugins auch installieren. Je nachdem, ob man vor hat, später auch externe GitHub-Dienste zu nutzen und/oder Mylyn einzusetzen, kann die Installation weiterer Plugins von Interesse sein. Das folgende Bild zeigt, welche Git-bezogenen Pakete ich selbst unter einem aktuellen Eclipse Neon 3 installiert habe:
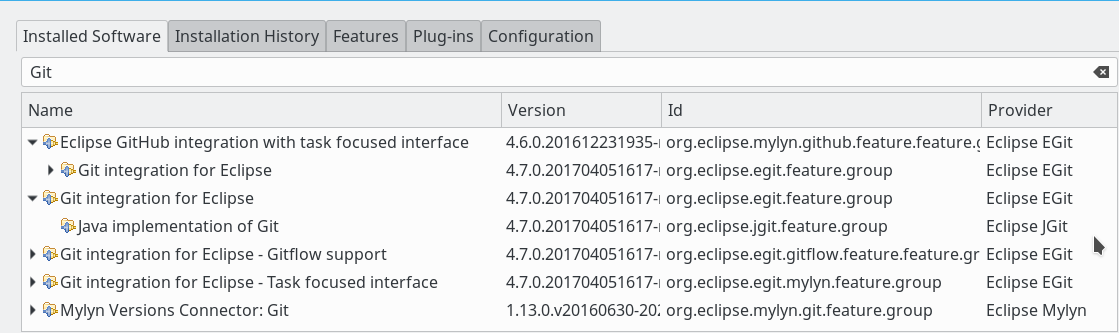
Ich gehe auf die relativ trivialen Installationsschritte unter Linux/Eclipse nicht näher ein. Siehe bei Bedarf aber:
http://www.vogella.com/ tutorials/ EclipseGit /article.html #installation-of-git-support-into-eclipse
https://www.eclipse.org/ forums/ index.php/ t/273443/
Vorbereitender Schritt 1 – Lösen eines PHP-Projektes von seiner SVN-Anbindung
Das nachfolgende Bild zeigt die relativ simple Verzeichnis und Projektstruktur eines EWS namens “ecl_alienx”; das zugehörige Verzeichnis auf dem Linux-PC ist “/projekte/ecl_alienx”.
Das dortige Test-Projekt “alien1” und seine Verzeichnisse/Dateien sind unterhalb des Ordners “/projekte/ecl_alienx/alien1” beheimatet. Eclipse-Puristen würden diese Ortswahl für die Programmdateien mit einiger Berechtigung kritisieren. Das ist uns hier aber egal; es wird sich sowieso gleich ändern.

Den Bildinformationen entnehmen wir: Das Projekt ist offenbar noch mit einem Subversion-SVN-Repository verbunden. Wir lösen diese SVN-Verbindung nun über den Disconnect-Befehl, den wir unter dem Kontexmenüs des Projektes finden: => “Team => Disconnect”.
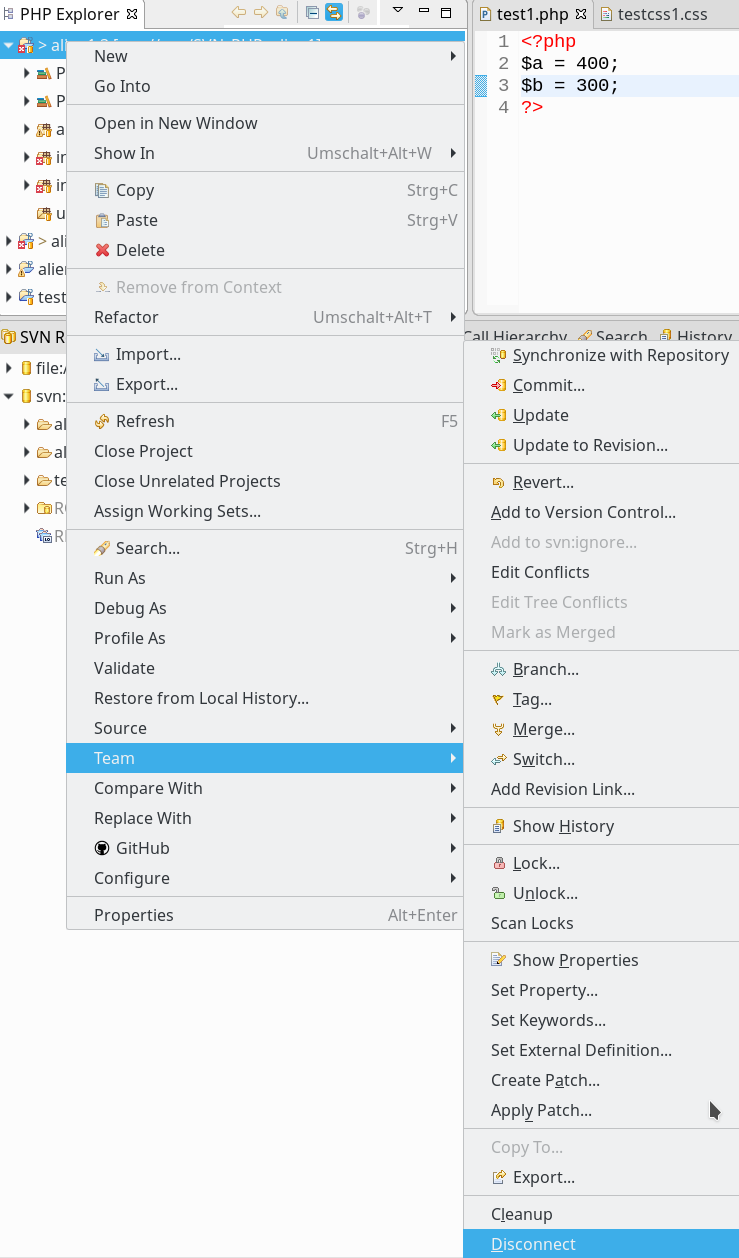
Dabei löschen wir auch die SVN-Metainformation in den “.svn”-Dateien jedes Projekt-Verzeichnisses. Das ist zwar nicht zwingend erforderlich; ich möchte bei den nachfolgenden Git-Experimenten aber keinen SVN-Ballast mit mir rumschleppen. (Das SVN-Repository selbst wird bei dieser Aktion übrigens nicht gelöscht).
Unser Projekt ist jetzt unbelastet von jeglicher Versionsverwaltung.
Für die weiteren Schritte lohnt es sich, den View “Git Repositories” (z.B. im unteren Bereich des Eclipse Desktops) permanent geöffnet zu halten. Dieser View ist anfänglich natürlich noch leer; bei späteren Git-Aktionen ist ein kontrollierender Blick in diesen View immer informativ und hilfreich. Öffnen kann man den View über den Eclipse Menüpunkt “Window => Show View => Others => Git => Git Repositories”.
Lösung der Aufgabe 1 – Erstellen eines lokalen Repositories
Als erstes erstellen wir mittels einer Shell oder einem Dateimanager außerhalb des EWS ein Verzeichnis für unseren künftigen GWS inkl. eines lokalen GIT-Repositories. In meinem Testfall etwa unter “/projekte/GIT/alien1“. Dann öffnen wir das Kontext-Menü unseres Projektes erneut und wählen den Punkt “Team => Share Project“:
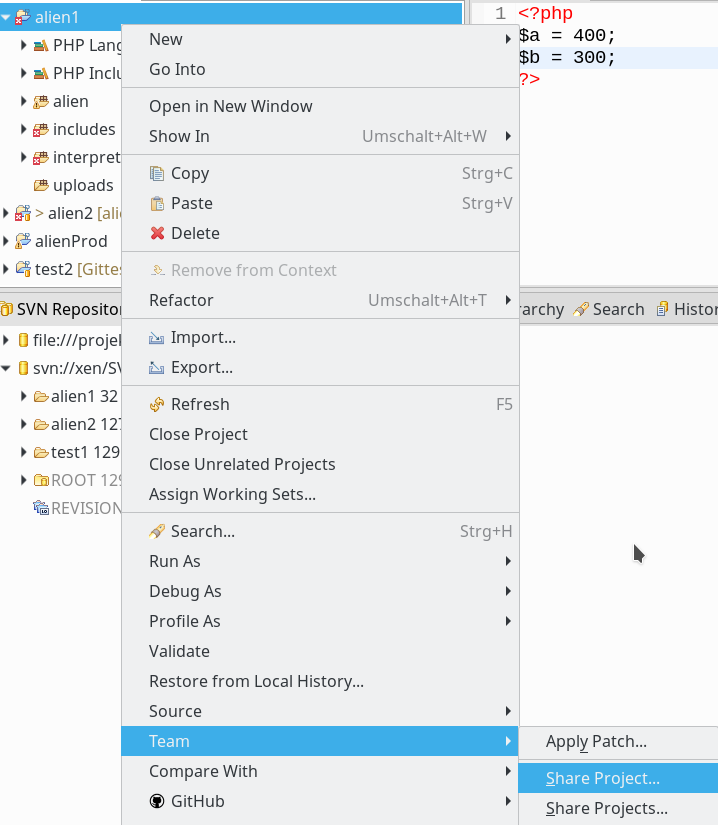
Im nächsten Dialogfenster klicken wir auf den “Create“-Button und geben im nachfolgenden Subdialog den vorgesehenen Zielort des Repositories an:

Achtung:
Das Bild deutet bereits an, dass EGit deutlich mehr vor hat, als nur ein Git-Repository anzulegen. Vielmehr sollen alle Unterverzeichnisse unseres Projektes in eine Verzeichnisstruktur im Targetverzeichnis “/projekte/GIT/alien1” umgezogen werden. Wir werden gleich sehen, dass dadurch der sog. “Working Tree” unter dem Directory “/projekte/GIT/alien1/alien1/” im Workspace angelegt wird; der Working Tree besteht initial also aus den ursprünglichen Projekt-Verzeichnissen und -Dateien des EWS.
Im Targetverzeichnis “/projekte/GIT/alien1” wird parallel auch das eigentliche Git-Repository als Teil des GWS angelegt. Die erforderlichen Repository-Strukturen (Unter-Verzeichnisse für verschiedene Informationen, Object-Datenbanken mit Blobs, Indices, …) findet man anschließend in einem Verzeichnis “/projekte/GIT/alien1/.git“.
Hinweis: Ich würde an dieser Struktur des GWS nichts ändern!
- Git erlaubt zwar grundsätzlich eine Trennung des Dachverzeichnisses
für das “.git”-Repository-Verzeichnis vom Dachverzeichnisses für den “Working Tree”. Man kann dies etwa über CLI-Kommandos erzwingen. Nach meiner Erfahrung bringt eine solche separate Lagerung des Repositories und des Working-Trees an unterschiedlichen Orten EGit aber bei weiteren Aktionen außer Tritt. Also den Umzug der Verzeichnisstruktur an die angezeigten Position bitte zulassen! - Bitte achtet auch darauf, dass der Pfad zum künftigen “.git”-Verzeichnisses in eurem Dialog wirklich so ähnlich aussieht wie dargestellt. Man gerät durch Unachtsamkeit relativ schnell in eine Situation, in der man “.git” nachher unterhalb des Hauptverzeichnisses des Working Trees wiederfindet. Auch das ist technisch zwar zulässig, hätte später aber mehrere unangenehme Seiteneffekte, auf die ich an dieser Stelle nicht eingehen will. Also: Bitte darauf achten, dass das “.git”-Verzeichnis auf derselben Ebene der Verzeichnisstruktur platziert wird wie der zu erzeugende Working Tree. !
Jetzt klicken wir endlich auf den Button “Finish”; je nach Größe des bereits vorhandenen Projektverzeichnisses dauert das Verlagern der Dateien ggf. ein wenig. Schließlich sind aber sowohl das Repository unter dem Directory “.git” wie auch der Working Tree am vorgesehenen Bestimmungsort vorhanden.
>Lösung der Aufgabe 2 – Working Tree und Verzeichnisstruktur
Das Ergebnis sollte sich im PHP-Explorer bzw. im View “Git Reposiories” wie folgt darstellen:
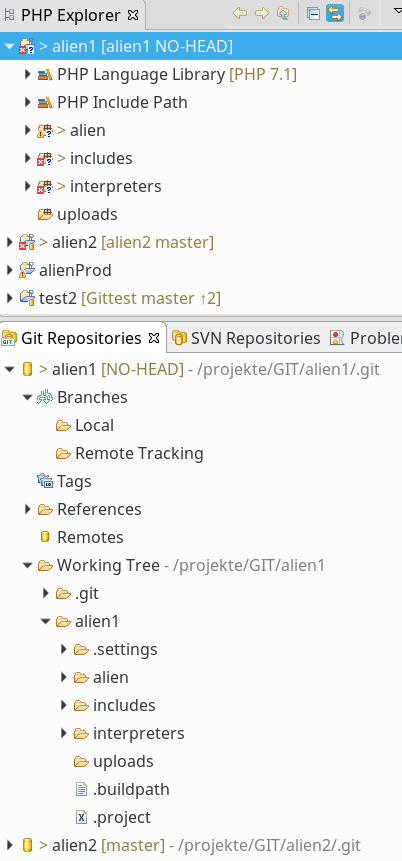
Im unteren Teil sehen wir einen Ausschnitt des “Git Repository”-Views. Bereits hier erkennen wir deutlich den Aufbau unseres neuen GWS. Der Working Tree ist dort als solcher bezeichnet und sein Pfad ist angegeben. Ein Dateimanager bestätigt die gewünschte Verzeichnishierarchie:
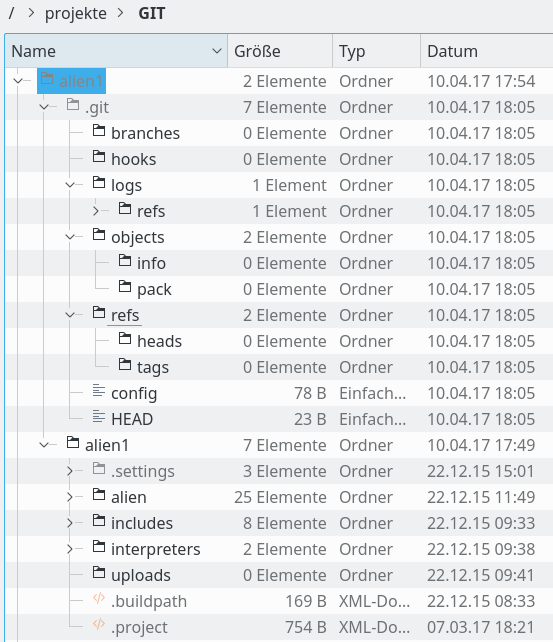
Glückwunsch! Wir haben unser erstes Git-Repository samt Working Tree erstellt. Durch die Parametrierung bei der Erstellung des Repositorys und durch die beiden obigen Abbildungen haben wir neben Aufgabe 1 auch schon Aufgabe 2 gelöst.
Das Repository ist in diesem Zustand aber erst vorbereitet. Noch sind dort keine Inhalte oder Verionsobjekte angelegt ….
Git-Smart-Icon-Leiste aktivieren
Um nachfolgend etwas einfacher mit dem Repository und dem Commit neuer Dateien arbeiten zu können, beschaffen wir uns eine Smart-Icon-Leiste für Git-Operationen im Kopfbereich von Eclipse. Das erreichen wir in zwei Schritten:
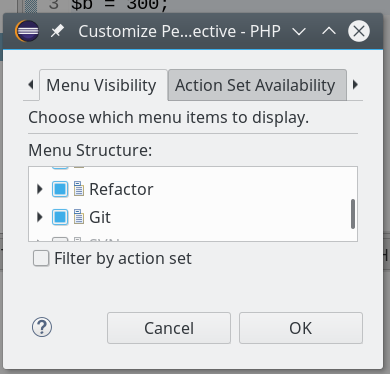
- Klick auf den Eclipse-Menüpunkt “Window => Perspective => Customize Perspective … “. Dort unter dem Reiter “Action Set Availability” die Punkte “Git” und “Git Navigation Actions” aktivieren.

- Danach aktivieren wir unter dem Tab “Menu Visibility” den Punkt “Git”:
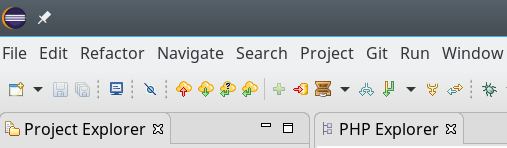
Als Ergebnis erhalten wir folgende Leiste:
>Lösung der Aufgabe 3 – Master-Branch und initiales Commit
Der weiter oben dargestellte View “Git-Repositories” weist uns neben dem Repository-Symbol im Moment explizit darauf hin, dass noch keine HEAD-Version existiert. Wie auch? Im “Branches”-Bereich ist unter dem Punkt “Local” ja noch nicht mal ein (Master-) Branch zu finden (s. den vorhergehenden Blog-Post). Es gibt im Moment noch überhaupt keinen Branch!
Unter Git muss man Verzeichnisse und Dateien explizit für die Berücksichtigung in der Versionsverwaltung markieren. Die kleinen Fragezeichen in den Verzeichnis-Icons im PHP-Explorer deuten an, dass dies bislang noch für keines der vier Hauptverzeichnisse unseres Test-Projektes geschehen ist. Ein “gt;”-Symbol nach den Verzeichnis- bzw. auch nach einem Datei-Namen deutet ferner an, dass es eine Änderung gibt, die noch nicht per Commit im Repository erfasst wurde: Der aktuelle Inhalt jeder Datei stellt aus Sicht von Git offenbar eine Art erste (initiale) Änderung dar. Wir würden das Symbol bei jeder Datei unterhalb der Verzeichnisse sehen.
Später werden wir das “>”-Symbol natürlich genau an denjenigen Dateien/Verzeichnissen entdecken, die jemand seit dem letzten Commit modifiziert hat. Das ist beim Einsatz von Subversion ganz genauso. Einen kleinen Unterschied zu SVN gibt es allerdings doch, und der macht sich dadurch bemerkbar, dass das Verzeichnis “uploads” kein “>”-Symbol aufweist: Der Grund dafür ist, dass das Verzeichnis leer ist. Das ist ein Hinweis darauf, dass Git keine separate Versionsverwaltung für Verzeichnisse als Repository-Objekte vornimmt. Verzeichnisse sind lediglich ein Art Attribut der nach Versionen verwalteten Datei-Objekte!
Den aktuellen Repository-Zustand könnte man im Git-Sprachgebrauch also etwa so zusammenfassen: Es ist bislang weder ein “Commit” zu den vorhandenen Dateien erfolgt, noch wurden die in Verzeichnissen organisierten Dateien überhaupt für eine Indizierung und Verwaltung in einem Branch und damit auch der Git-Objektdatenbank vorgesehen. Wir ändern das nun in zwei separaten Schritten:
Schritt 1 – Einbeziehen der Verzeichnisse und ihrer Dateien in die Versionsverwaltung: Wir markieren unsere 4 Projektverzeichnisse des Beispiels “alien”, “includes”, “interpreters”, “uploads” im PHP- oder Projekt-Explorer. Dann klicken wir in der Git-Icon-Leiste auf das grüne Kreuz. Danach müssen warten, bis sich das Dialogfenster zu “Operation in Progress …” wieder schließt.
Die nächste Abbildung zeigt, dass sich die Mikro-Symbole an den Verzeichnissen nun geändert haben:
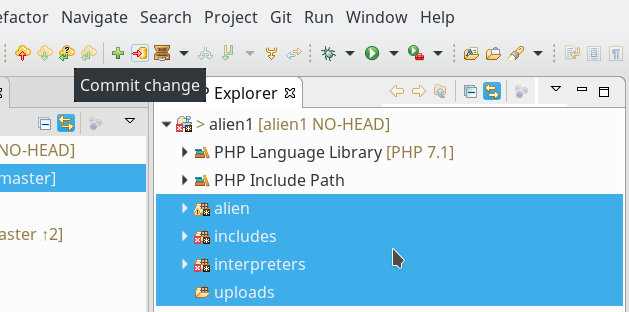
Der weiße Stern auf schwarzem Grund weist allerdings darauf hin, dass die Dateien in den Verzeichnissen immer noch keinen “Commit” erfahren haben.
Schritt 2 – Initialer Commit für alle erfassten Dateien:
Um für alle Dateien einen “Commit” einzuleiten, markieren wir unsere Verzeichnisse erneut und klicken dann auf das orange Repository-Symbol mit dem Pfeil von links nach rechts in der Git-Icon-Leiste; dieses Symbol befindet sich neben dem grünen Kreuz und symbolisiert einen Commit-Vorgang – unseren ersten im erstellten Repository.
Nach wenigen Augenblicken bietet sich uns dann folgendes Bild im sogenannten “Git Staging View“. Dieser View öffnet sich automatisch und listet Dateien/Verzeichnisse auf, die modifiziert wurden und für die endgültige Ausführung des Commits “vorgemerkt” sind. Man nennt das auch “Staging“.
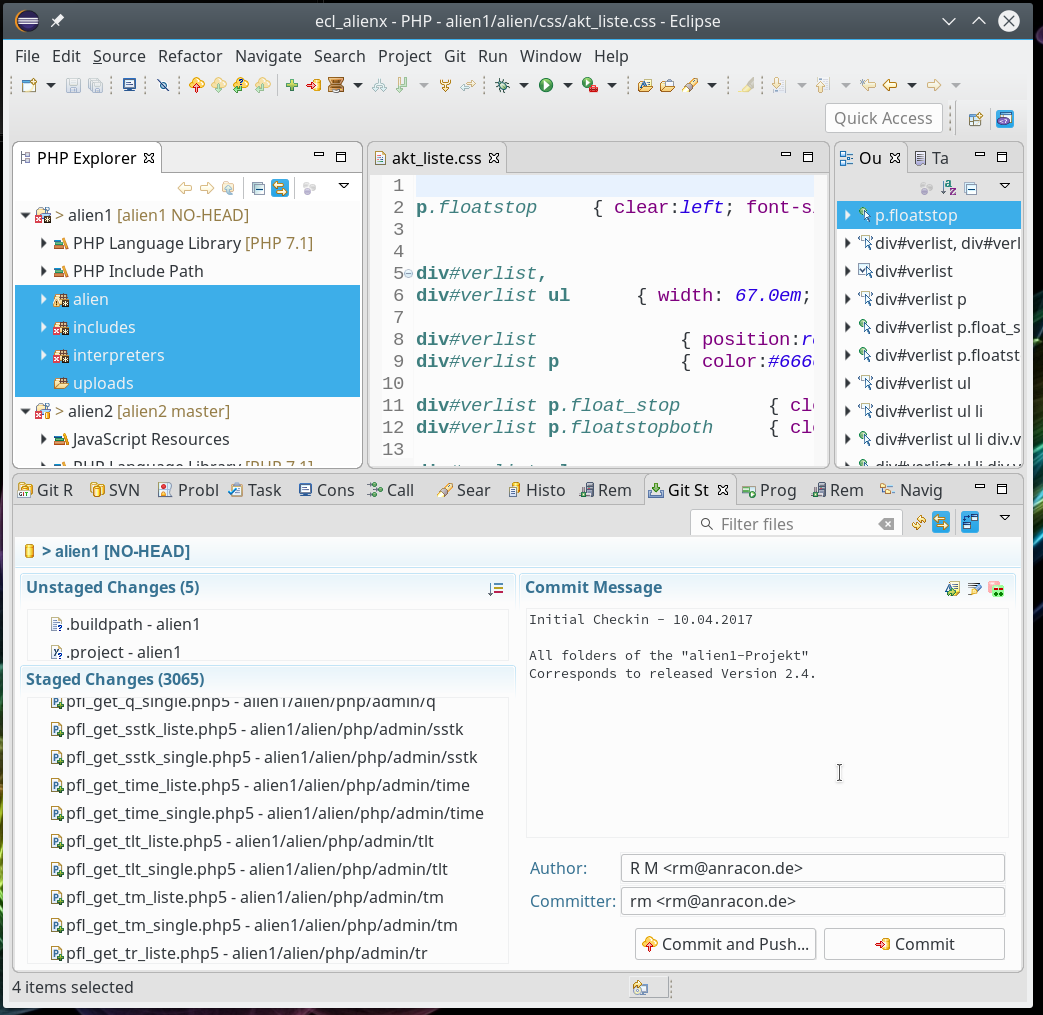
Im linken Bereich sehen wir im Bereich “Unstaged Changes” Dateien (nur 2 von 5 sind sichtbar), die bislang nicht für Commits vorgemerkt wurden. Es handelt sich in unserem Fall um Eclipse-Konfigurationsdateien für das spezielle Projekt. Darunter sehen wir im Bereich “Staged Changes” allerdings die für das Commit vorgemerkten Dateien. In unserem Fall alle Projektdateien. (Es handelt sich offenbar um eine größeres Projekt, zu dem über 3000 einzelne Dateien beitragen.)
Im rechten Bereich des “Staging View” können (besser müssen) wir unseren Commit noch mit einem Kommentar verzieren. Unterhalb sollten auch Author und Committer angegeben werden; dabei sind bestimmte Formatanforderungen zu erfüllen, die wir nach einem Klick in das jeweilige Feld gefolgt von einem “Ctrl-Space” angezeigt bekommen. Die entsprechenden Werte lassen sich auch in den Eclipse-Preferences für Git hinterlegen. Man findet Git-Preferenzen wie üblich unter dem Menüpunkt “Window => Preferences => Team => Git”.
Wir klicken nun auf den Button “Commit“. Es wird jetzt eine erste Komplettversion im sog. “master”-Branch unseres Repositories erzeugt. Genauer: Zuerst wird der Master-Branch generiert; dann wird n einer ersten Projektversion auf diesem Branch der aktuelle Inhalt aller ausgewählten Projektdateien erfasst. Das Erzeugen der zugehörigen initialen Objekte des Repositories und deren Komprimierung dauert in meinem Fall wegen der großen Menge der Dateien ein paar Augenblicke.
Jeder Commit führt zu einem neuen Versionsstatus des gesamten Branches (sozusagen über alle modifizierten Dateien hinweg). Auf der Branch-Ebene entspricht ein Commit in seiner Gesamtheit somit einem eindeutigen Knoten (s. hierzu den letzten Post). Die Identität des Knotens wird durch einen eindeutigen Hash gekennzeichnet, dessen erste Buchstaben wir im Git-Repository-View auch angezeigt bekommen. Diesem Hash sind wiederum Hashes für die einzelnen erfassten Objekte (Dateien bzw. komprimierte Blobs zu deren Änderungen) zugeordnet. Auch die Änderungen selbst (bzw. zugehörige Objekte in einem Binärformat) werden also über Hashes identifiziert.
Im Git-Repository-View ergibt sich nach der Durchführung des Commits folgendes Bild :
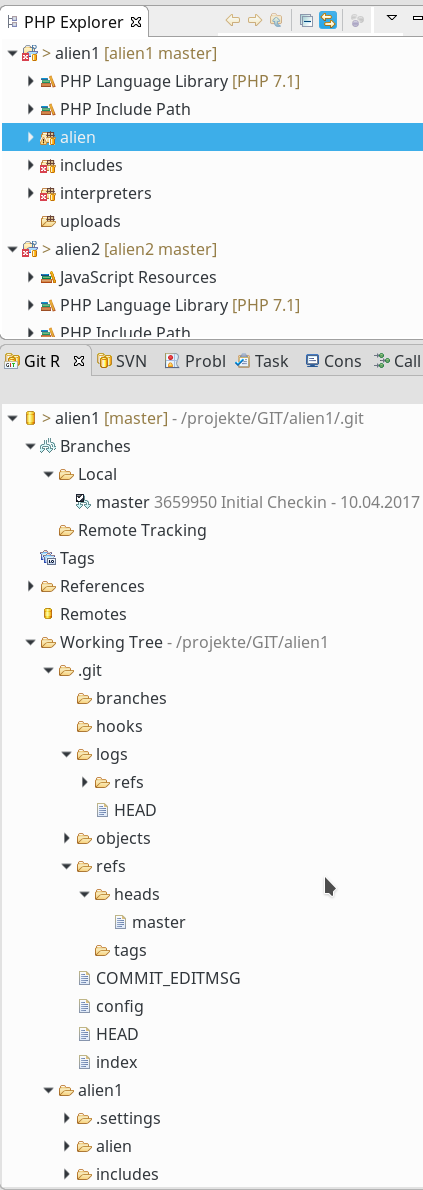
Nun existiert offenbar der ersehnte lokale Master-Branch. Daneben erkennen wir die ersten alphanumerischen Zeichen seines Hashes (hier: 3659950) und die Anfänge unseres eben erstellten Kommentars.
Unsere Verzeichnis-Symbole im PHP-Explorer weisen nun zudem das kleine orangefarbene zylinderartige Repository-Symbol auf – damit wird angezeigt, dass die Dateien in den betroffenen Verzeichnissen ordnungsgemäß versioniert wurden. Das Fehlen von “>”-Symbolen an den Verzeichnissen, die Dateien enthalten, zeigt an, dass im Repository auch alles auf dem aktuellsten Stand ist.
Neben dem Verzeichnissymbol zum Haupt-Directory “alien1” unseres Projekts wird freundlicherweise dargestellt, welchem Branch der Inhalt des “Working Trees” gerade zugeordnet ist. (In realen Projekten wird es ja ggf. mehrere Branches geben). Der geneigte Leser wird nun sicher auch selbst beantworten können, warum das “>”-Symbol neben dem Hauptverzeichnis “alien1” nicht verschwunden ist.
Der interessierte Leser mag in einem eigenen Beispiel zudem mal einen Blick in das Verzeichnis “/…./.git/objects” werfen; man wird feststellen, dass auch dieses Verzeichnis nach dem initialen Commit mit vielen Dateien in einem Binärformat gefüllt wurde.
Nach unserem initialen Commit ist die komplette Information über den Inhalt der Projekt-Dateien also redundant vorhanden – einmal im “Working Tree” und auch in der Objektdatenbank des Repositories.
Nach weiteren Commits enthält das Repository aber deutlich mehr Informationen als der Working Tree: Der Working Tree spiegelt dann nur den Zustand wider, der zum geöffneten letzten Knoten des aktiven Branches gehört – plus ggf. zwischenzeitlich vorgenommene Änderungen, die noch nicht committed wurden. Das Repository hingegen enthält dann die gesamte bisherige Änderungshistorie. Dank Komprimierungstechnologie und der Speicherung inkrementeller Änderungen ist der Platzbedarf des Workings Trees über lange Zeit hinweg dennoch meist deutlich geringer als der Platzbedarf des Working Trees.
Zusammenfassung und Ausblick
Wir haben im Zuge dieses Artikels zu einem vorhandenen Projekt eine voll funktionsfähige lokale Versionsverwaltung unter Git eingerichtet, mit der wir nun weitere Experimente durchführen können. Wir haben dabei gesehen, dass ein Repository nach seiner Anlage auch gefüllt werden muss. Dazu sind Dateien für die Erfassung und Verfolgung in der Versionsverwaltung zu markieren. Ein Commit besteht im Grunde aus drei Phasen :
- Phase 1: Auswahl und Staging der geänderten Dateien für die Durchführung des Commits.
- Phase 2: Eingeben eines Kommentars zum Commit. Benennung des Autors und des Committers.
- Phase 3: Technische Durchführung des Commits.
Ein Commit erzeugt einen eindeutig identifizierbaren Knoten in einem Branch. In einem initialen Commit werden der Master-Branch des Repositories und dessen erster Knoten erzeugt. Der Commit bzw. der korrespondierende Knoten im Branch sind durch einen eindeutigen Hash gekennzeichnet. Einem Commit sind ferner bestimmte (neu) angelegte Objekte im Verzeichnis “.git/objects” zugeordnet.
Im nächsten Blog-Post führen wir testweise einige Änderungen und zugehörige Commits durch. Wir betrachten dabei auch die Darstellung der Historie unter Eclipse. Zudem werfen wir einen ersten vergleichenden Blick auf die GUIs “GitG” bzw. “QGit”.