In the last post of this series
Fun with veth-devices, Linux bridges and VLANs in unnamed Linux network namespaces – VII [Theoretical considerations regarding the connection of a network namespace or container to two separated VLANs]
we discussed two different approaches to connect a network namespace (or container) “netns9” to two (or more) separated VLANs. Such a network namespace could e.g. represent an administrative system (for example in form of a LXC container) for both VLANs. It has its own connection to the virtual Linux bridge which technically defines the VLANs by special port configurations. See the picture below, where we represented a VLAN1 by a member network namespace netns1 and a VLAN2 by a member netns4:
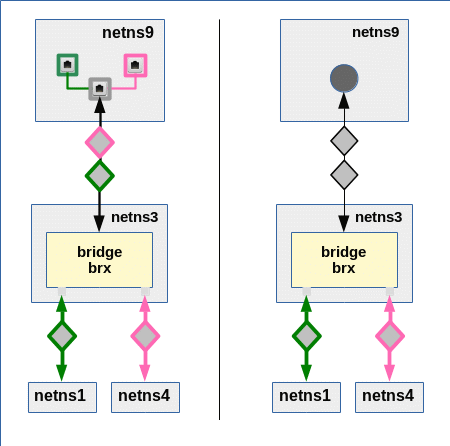
The solution on the left side is based on a bridge in an intermediate network namespace and packet tagging up into the namespace for the VLANs’ common member system netns9. The approach on the right side of the graphics uses a bridge, too, but without packet tagging along the connection to the common VLAN member system. In our analysis in the last post we assumed that we would have to compensate for this indifference by special PVID/VID settings.
The previous articles of this series already introduced general Linux commands for network namespace creation and the setup of VLANs via Linux bridge configurations. See e.g.: Fun with … – IV [Virtual VLANs for network namespaces (or containers) and rules for VLAN tagging at Linux bridge ports]. We shall use these methods in the present and a coming post to test configurations for a common member of two VLANs. We want to find out whether the theoretically derived measures regarding route definitions in netns9 and special PVID/VID-settings at the bridge work as expected. A test of packet filtering at bridge ports which we regarded as important for security is, however, postponed to later posts.
Extension of our test environment
First, we extend our previous test scenario by yet another network namespace “netns9“.
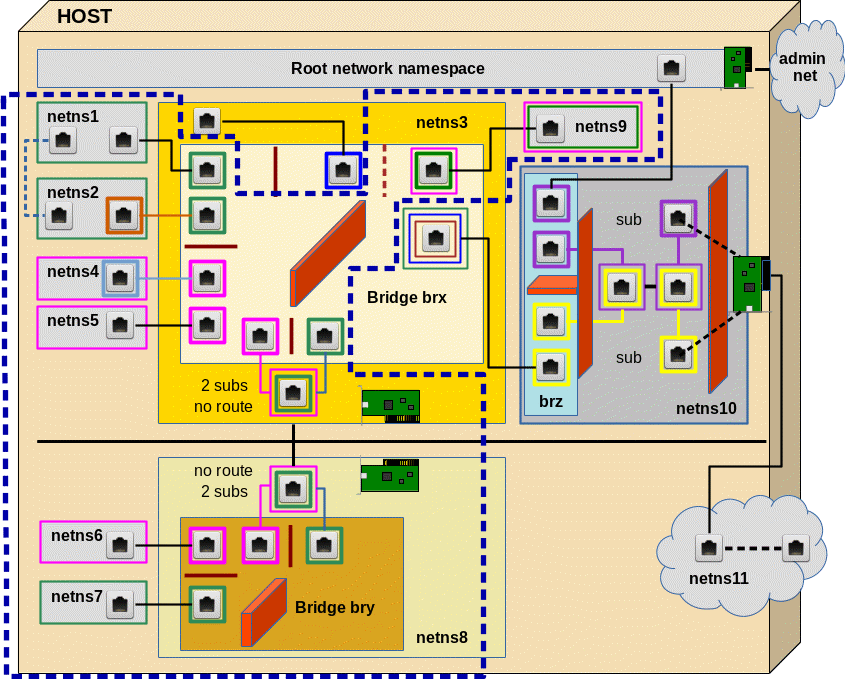
Our 2 VLANs in the test environment are graphically distinguished by “green” and “pink” tags (corresponding to different VLAN ID numbers). netns9 must be able to communicate with systems in both VLANs. netns9 shall, however, not become a packet forwarder between the VLANs; the VLANs shall remain separated despite the fact that they have a common member. We expect, that a clear separation of communication paths to the VLANs requires a distinction between network targets already inside netns9.
Bridge based solutions with packet tagging and veth sub-interfaces
There are two rather equivalent solutions for the connection of netns9 to brx in netns3; see the schematic graphics below:
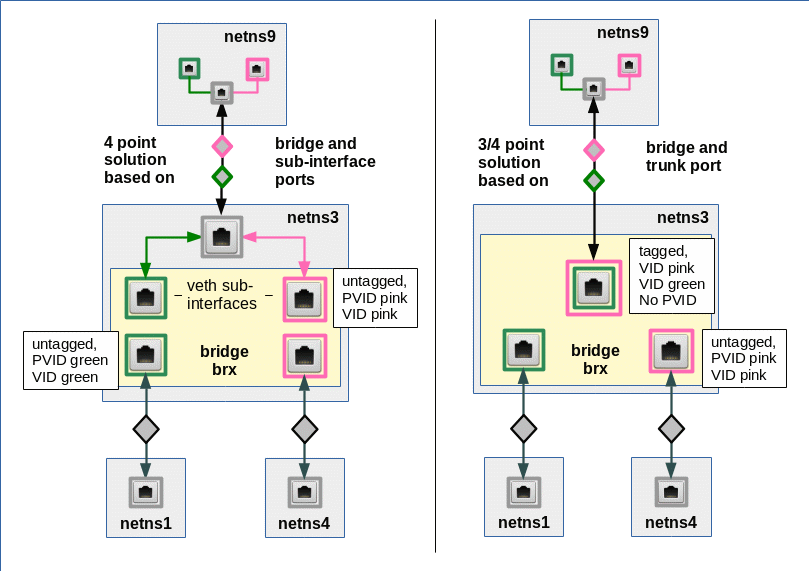
Both solutions are based on veth sub-interfaces inside netns9. Thus, both VLAN connections are properly terminated in netns9. The approach depicted on the right side of the graphics uses a pure trunk port at the bridge; but also this solutions makes use of packet tagging between brx and netns9.
Note that we do not need to used tagged packets along the connections from bridge brx to netns1, netns2, netns4, netns5. The VLANs are established by the PVID/VID settings at the bridge ports and forwarding rules inside a VLAN aware bridge. Note also that our test environment contains an additional bridge bry and additional network namespaces.
We first concentrate on the solution on the left side with veth sub-interfaces at the bridge. It is easy to switch to a trunk port afterwards.
The required commands for the setup of the test environment are given below; you may scroll and copy the commands to the prompt of a terminal window for a root shell:
unshare --net --uts /bin/bash &
export pid_netns1=$!
unshare --net --uts /bin/bash &
export pid_netns2=$!
unshare --net --uts /bin/bash &
export pid_netns3=$!
unshare --net --uts /bin/bash &
export pid_netns4=$!
unshare --net --uts /bin/bash &
export pid_netns5=$!
unshare --net --uts /bin/bash &
export pid_netns6=$!
unshare --net --uts /bin/bash &
export pid_netns7=$!
unshare --net --uts /bin/bash &
export pid_netns8=$!
unshare --net --uts /bin/bash &
export pid_netns9=$!
# assign different hostnames
nsenter -t $pid_netns1 -u hostname netns1
nsenter -t $pid_netns2 -u hostname netns2
nsenter -t $pid_netns3 -u hostname netns3
nsenter -t $pid_netns4 -u hostname netns4
nsenter -t $pid_netns5 -u hostname netns5
nsenter -t $pid_netns6 -u hostname netns6
nsenter -t $pid_netns7 -u hostname netns7
nsenter -t $pid_netns8 -u hostname netns8
nsenter -t $pid_netns9 -u hostname netns9
# set up veth devices in netns1 to netns4 and in netns9 with connections to netns3
ip link add veth11 netns $pid_netns1 type veth peer name veth13 netns $pid_netns3
ip link add veth22 netns $pid_netns2 type veth peer name veth23 netns $pid_netns3
ip link add veth44 netns $pid_netns4 type veth peer name veth43 netns $pid_netns3
ip link add veth55 netns $pid_netns5 type veth peer name veth53 netns $pid_netns3
ip link add veth99 netns $pid_netns9 type veth peer name veth93 netns $pid_netns3
# set up veth devices in netns6 and netns7 with connection to netns8
ip link add veth66 netns $pid_netns6 type veth peer name veth68 netns $pid_netns8
ip link add veth77 netns $pid_netns7 type veth peer name veth78 netns $pid_netns8
# Assign IP addresses and set the devices up
nsenter -t $pid_netns1 -u -n /bin/bash
ip addr add 192.168.5.1/24 brd 192.168.5.255 dev veth11
ip link set veth11 up
ip link set lo up
exit
nsenter -t $pid_netns2 -u -n /bin/bash
ip addr add 192.168.5.2/24 brd 192.168.5.255 dev veth22
ip link set veth22 up
ip link set lo up
exit
nsenter -t $pid_netns4 -u -n /bin/bash
ip addr add 192.168.5.4/24 brd 192.168.5.255 dev veth44
ip link set veth44 up
ip link set lo up
exit
nsenter -t $pid_netns5 -u -n /bin/bash
ip addr add 192.168.5.5/24 brd 192.168.5.255 dev veth55
ip link set veth55 up
ip link set lo up
exit
nsenter -t $pid_netns6 -u -n /bin/bash
ip addr add 192.168.5.6/24 brd 192.168.5.255 dev veth66
ip link set veth66 up
ip link set lo up
exit
nsenter -t $pid_netns7 -u -n /bin/bash
ip addr add 192.168.5.7/24 brd 192.168.5.255 dev veth77
ip link set veth77 up
ip link set lo up
exit
nsenter -t $pid_netns9 -u -n /bin/bash
ip addr add 192.
168.5.9/24 brd 192.168.5.255 dev veth99
ip link set veth99 up
ip link set lo up
exit
# set up bridge brx and its ports
nsenter -t $pid_netns3 -u -n /bin/bash
brctl addbr brx
ip link set brx up
ip link set veth13 up
ip link set veth23 up
ip link set veth43 up
ip link set veth53 up
brctl addif brx veth13
brctl addif brx veth23
brctl addif brx veth43
brctl addif brx veth53
exit
# set up bridge bry and its ports
nsenter -t $pid_netns8 -u -n /bin/bash
brctl addbr bry
ip link set bry up
ip link set veth68 up
ip link set veth78 up
brctl addif bry veth68
brctl addif bry veth78
exit
# set up 2 VLANs on each bridge
nsenter -t $pid_netns3 -u -n /bin/bash
ip link set dev brx type bridge vlan_filtering 1
bridge vlan add vid 10 pvid untagged dev veth13
bridge vlan add vid 10 pvid untagged dev veth23
bridge vlan add vid 20 pvid untagged dev veth43
bridge vlan add vid 20 pvid untagged dev veth53
bridge vlan del vid 1 dev brx self
bridge vlan del vid 1 dev veth13
bridge vlan del vid 1 dev veth23
bridge vlan del vid 1 dev veth43
bridge vlan del vid 1 dev veth53
bridge vlan show
exit
nsenter -t $pid_netns8 -u -n /bin/bash
ip link set dev bry type bridge vlan_filtering 1
bridge vlan add vid 10 pvid untagged dev veth68
bridge vlan add vid 20 pvid untagged dev veth78
bridge vlan del vid 1 dev bry self
bridge vlan del vid 1 dev veth68
bridge vlan del vid 1 dev veth78
bridge vlan show
exit
# Create a veth device to connect the two bridges
ip link add vethx netns $pid_netns3 type veth peer name vethy netns $pid_netns8
nsenter -t $pid_netns3 -u -n /bin/bash
ip link add link vethx name vethx.50 type vlan id 50
ip link add link vethx name vethx.60 type vlan id 60
brctl addif brx vethx.50
brctl addif brx vethx.60
ip link set vethx up
ip link set vethx.50 up
ip link set vethx.60 up
bridge vlan add vid 10 pvid untagged dev vethx.50
bridge vlan add vid 20 pvid untagged dev vethx.60
bridge vlan del vid 1 dev vethx.50
bridge vlan del vid 1 dev vethx.60
bridge vlan show
exit
nsenter -t $pid_netns8 -u -n /bin/bash
ip link add link vethy name vethy.50 type vlan id 50
ip link add link vethy name vethy.60 type vlan id 60
brctl addif bry vethy.50
brctl addif bry vethy.60
ip link set vethy up
ip link set vethy.50 up
ip link set vethy.60 up
bridge vlan add vid 10 pvid untagged dev vethy.50
bridge vlan add vid 20 pvid untagged dev vethy.60
bridge vlan del vid 1 dev vethy.50
bridge vlan del vid 1 dev vethy.60
bridge vlan show
exit
# Add subinterfaces in netns9
nsenter -t $pid_netns9 -u -n /bin/bash
ip link add link veth99 name veth99.10 type vlan id 10
ip link add link veth99 name veth99.20 type vlan id 20
ip link set veth99 up
ip link set veth99.10 up
ip link set veth99.20 up
exit
# Add subinterfaces in netns3
nsenter -t $pid_netns3 -u -n /bin/bash
ip link add link veth93 name veth93.10 type vlan id 10
ip link add link veth93 name veth93.20 type vlan id 20
ip link set veth93 up
ip link set veth93.10 up
ip link set veth93.20 up
brctl addif brx veth93.10
brctl addif brx veth93.20
bridge vlan add vid 10 pvid untagged dev veth93.10
bridge vlan add vid 20 pvid untagged dev veth93.20
bridge vlan del vid 1 dev veth93.10
bridge vlan del vid 1 dev veth93.20
exit
We just have to extend the command list of the experiment conducted already in the second to last post by some more lines which account for the setup of netns9 and its connection to the bridge “brx” in netns3.
Now, we open a separate terminal, which inherits the defined environment variables (e.g. on KDE by “konsole &>/dev/null &”), and try a ping from netns9 to netns7:
mytux:~ # nsenter -t $pid_netns9
-u -n /bin/bash
netns9:~ # ping 192.168.5.1
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
^C
--- 192.168.5.1 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1008ms
netns9:~ # ping 192.168.5.7
PING 192.168.5.7 (192.168.5.7) 56(84) bytes of data.
^C
--- 192.168.5.7 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1006ms
netns9:~ #
Obviously, the pings failed! The reason is that we forgot to set routes in netns9! Such routes are, however, vital for the transport of e.g. ICMP answering and request packets from netns9 to members of the two VLANs. See the last post for details. We add the rules for the required routes:
#Set routes in netns9
nsenter -t $pid_netns9 -u -n /bin/bash
route add 192.168.5.1 veth99.10
route add 192.168.5.2 veth99.10
route add 192.168.5.4 veth99.20
route add 192.168.5.5 veth99.20
route add 192.168.5.6 veth99.10
route add 192.168.5.7 veth99.20
exit
By these routes we, obviously, distinguish different paths: Packets heading for e.g. netns1 and netns2 go through a different interface than packets sent e.g. to netns4 and netns5. Now, again, in our second terminal window:
mytux:~ # nsenter -t $pid_netns9 -u -n /bin/bash
netns9:~ # ping 192.168.5.1 -c2
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
64 bytes from 192.168.5.1: icmp_seq=1 ttl=64 time=0.067 ms
64 bytes from 192.168.5.1: icmp_seq=2 ttl=64 time=0.083 ms
--- 192.168.5.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.067/0.075/0.083/0.008 ms
netns9:~ # ping 192.168.5.7 -c2
PING 192.168.5.7 (192.168.5.7) 56(84) bytes of data.
64 bytes from 192.168.5.7: icmp_seq=1 ttl=64 time=0.079 ms
64 bytes from 192.168.5.7: icmp_seq=2 ttl=64 time=0.078 ms
--- 192.168.5.7 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.078/0.078/0.079/0.008 ms
netns9:~ # ping 192.168.5.4 -c2
PING 192.168.5.4 (192.168.5.4) 56(84) bytes of data.
64 bytes from 192.168.5.4: icmp_seq=1 ttl=64 time=0.151 ms
64 bytes from 192.168.5.4: icmp_seq=2 ttl=64 time=0.076 ms
--- 192.168.5.4 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.076/0.113/0.151/0.038 ms
Thus, we have confirmed our conclusion from the last article that we need route definitions in a common member of two VLANs if and when we terminate tagged connection lines by veth sub-interfaces inside such a network namespace or container.
But are our VLANs still isolated from each other?
We open another terminal and try pinging from netns1 to netns4, netns7 and netns2:
mytux:~ # nsenter -t $pid_netns1 -u -n /bin/bash
netns1:~ # ping 192.168.5.4
PING 192.168.5.4 (192.168.5.4) 56(84) bytes of data.
^C
--- 192.168.5.4 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2015ms
netns1:~ # ping 192.168.5.7
PING 192.168.5.7 (192.168.5.7) 56(84) bytes of data.
^C
--- 192.168.5.7 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1007ms
netns1:~ # ping 192.168.5.2
PING 192.168.5.2 (192.168.5.2) 56(84) bytes of data.
64 bytes from 192.168.5.2: icmp_seq=1 ttl=64 time=0.195 ms
64 bytes from 192.168.5.2: icmp_seq=2 ttl=64 time=0.102 ms
^C
--- 192.168.5.
2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.102/0.148/0.195/0.048 ms
netns1:~ #
And in reverse direction :
mytux:~ # nsenter -t $pid_netns5 -u -n /bin/bash
netns5:~ # ping 192.168.5.4
PING 192.168.5.4 (192.168.5.4) 56(84) bytes of data.
64 bytes from 192.168.5.4: icmp_seq=1 ttl=64 time=0.209 ms
64 bytes from 192.168.5.4: icmp_seq=2 ttl=64 time=0.071 ms
^C
--- 192.168.5.4 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.071/0.140/0.209/0.069 ms
netns5:~ # ping 192.168.5.1
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
^C
--- 192.168.5.1 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1008ms
netns5:~ #
Good! As expected!
Forwarding between two VLANs?
We have stressed in the last post that setting routes should clearly be distinguished from “forwarding” if we want to keep our VLANs separated:
We have NOT enabled forwarding in netns9. If we had done so we would have lost the separation of the VLANs and opened a direct communication line between the VLANs.
Let us – just for fun – test the effect of forwarding in netns9:
netns9:~ # echo 1 > /proc/sys/net/ipv4/conf/all/forwarding
netns9:~ #
But still:
netns5:~ # ping 192.168.5.1
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
^C
--- 192.168.5.1 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 1999ms
Enabling forwarding in netns9 alone is obviously not enough to enable a packet flow in both directions! A little thinking , however, shows:
If we e.g. want ARP resolution and pinging from netns5 to netns1 to work via netns9 we must establish further routes both in netns1 and netns5. Reason: Both network namespaces must be informed that netns9 now works as a gateway for both request and answering packets:
netns1:~ # route add 192.168.5.5 gw 192.168.5.9
netns5:~ # route add 192.168.5.1 gw 192.168.5.9
Eventually:
netns5:~ # ping 192.168.5.1
PING 192.168.5.1 (192.168.5.1) 56(84) bytes of data.
64 bytes from 192.168.5.1: icmp_seq=1 ttl=63 time=0.186 ms
64 bytes from 192.168.5.1: icmp_seq=2 ttl=63 time=0.134 ms
^C
--- 192.168.5.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.134/0.160/0.186/0.026 ms
netns5:~ #
So, yes, forwarding outside the bridge builds a connection between otherwise separated VLANs. In connection with a packet filter this could be used to allow some hosts of a VLAN1 to reach e.g. some servers in a VLAN2. But this is not the topic of this post. So, do not forget to disable the forwarding in netns9 again for further experiments:
netns9:~ # echo 0 > /proc/sys/net/ipv4/conf/all/forwarding
netns9:~ #
Bridge based solutions with packet tagging and a trunk port at the Linux bridge
The following commands replace the sub-interface ports veth93.10 and veth93.20 at the bridge by a single trunk port:
# Change veth93 to trunk like interface in brx
nsenter -t $pid_netns3 -u -n /bin/bash
brctl delif brx veth93.10
brctl delif brx veth93.20
ip link del dev veth93.10
ip link del dev veth93.20
brctl addif brx veth93
bridge vlan add vid 10 tagged dev veth93
bridge vlan add vid 20 tagged dev veth93
bridge vlan del vid 1 dev veth93
bridge vlan show
exit
Such a solution works equally well:
netns9:~ # ping 192.168.5.4 -c2
PING 192.168.5.4 (192.168.5.4) 56(84) bytes of data.
64 bytes from 192.168.5.4: icmp_seq=1 ttl=64 time=0.145 ms
64 bytes from 192.168.5.4: icmp_seq=2 ttl=64 time=0.094 ms
--- 192.168.5.4 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.094/0.119/0.145/0.027 ms
netns9:~ # ping 192.168.5.6 -c2
PING 192.168.5.6 (192.168.5.6) 56(84) bytes of data.
64 bytes from 192.168.5.6: icmp_seq=1 ttl=64 time=0.177 ms
64 bytes from 192.168.5.6: icmp_seq=2 ttl=64 time=0.084 ms
--- 192.168.5.6 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.084/0.130/0.177/0.047 ms
netns9:~ #
Summary and outlook
It is easy to make a network namespace or container a common member of two separate VLANs realized by a Linux bridge. You have to terminate virtual veth connections, which transport tagged packets from both VLANs, properly inside the common target namespace by sub-interfaces. As long as we do not enable forwarding in the common namespace the VLANs remain separated. But routes need to be defined to direct packets from the common member to the right VLAN.
In the next post we look at commands to realize a connection of bridge based VLANs to a common network namespace with untagged packets. Such solutions are interesting for connecting multiple virtual VLANs to routers to external networks.