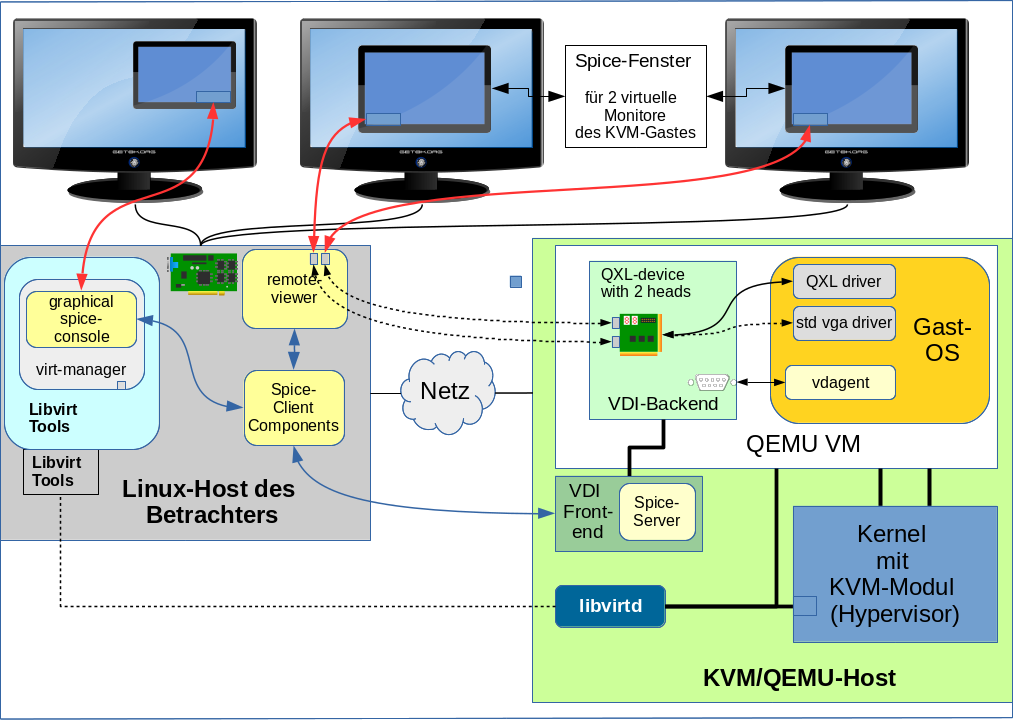
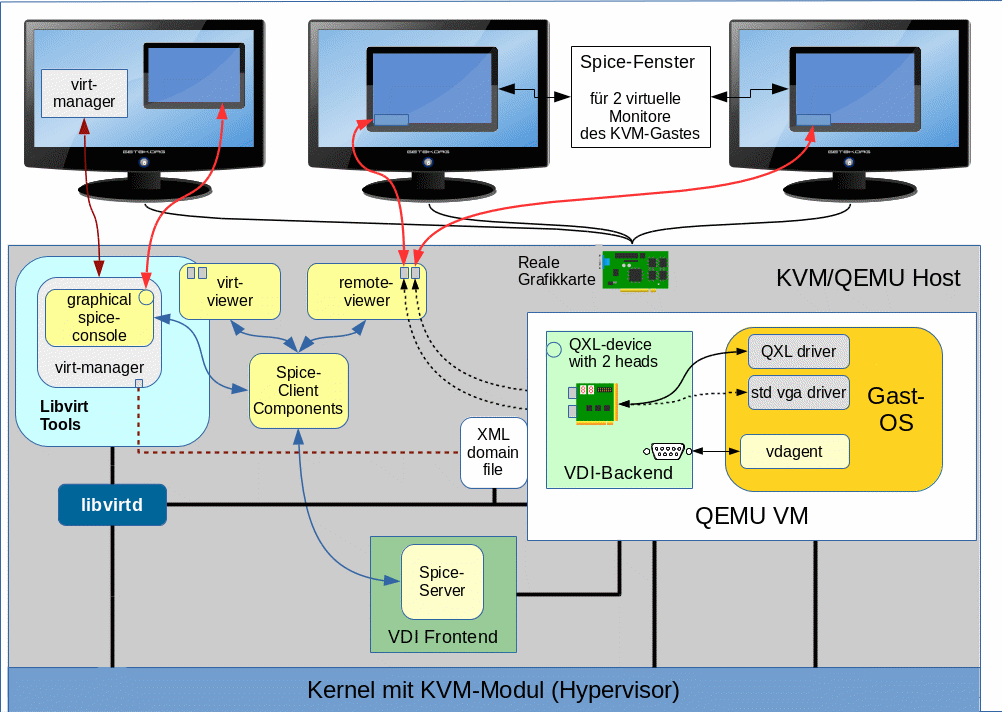
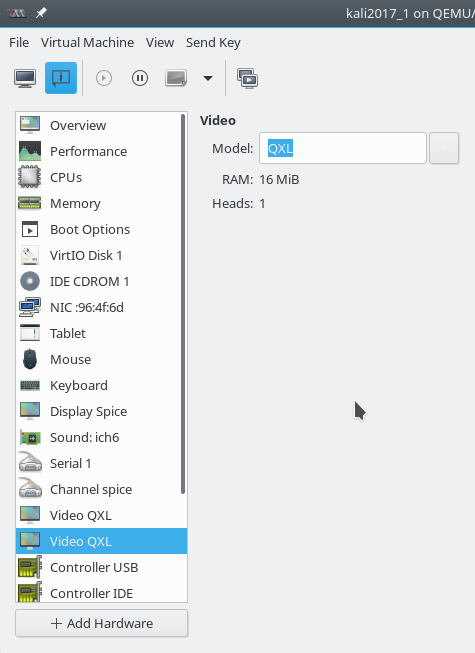
Will man auf einer Linux-Workstation den Desktop eines virtualisierten KVM/QEMU-Gastsystems [VM] nutzen, so wird man typischerweise auf die Kombination QXL und Spice-Client-Fenster setzen. Der Desktop des virtualisierten Gastsystems wird dann im Spice-Fenster auf dem normalen Desktop der Workstation dargestellt. In den letzten Artikeln dieser Serie hatten wir uns mit Konfigurationsmöglichkeiten zur Nutzung hoher Auflösungen auseinandergesetzt. Der erste Artikel
KVM/qemu mit QXL – hohe Auflösungen und virtuelle Monitore im Gastsystem definieren und nutzen – I
befasste sich mit Konfigurationsmöglichkeiten des QXL-Devices (memory, heads), die sich nicht direkt über das Tool “virt-manager” beeinflussen lassen. Ich hatte u.a. für die Memory-Dimensionierung Formeln angegeben; die resultierenden Daten kann man in die Konfigurationsdateien der virtuellen “Domäne” (also der VM) einbringen. Im zweiten Artikel
KVM/qemu mit QXL – hohe Auflösungen und virtuelle Monitore im Gastsystem definieren und nutzen – II
hatte ich dann den Einsatz von “xrandr” für hohe Auflösungen des “Desktops auf dem Betrachtersystem” und des darzustellenden “Desktops des QEMU-Gastes” vertieft. Dabei waren wir auch auf den QXL-Treiber und die Bedeutung des “spice-vdagents” (bzw. des zugehörigen Services) im Gastsystem eingegangen. Der letzte Artikel
KVM/qemu mit QXL – hohe Auflösungen und virtuelle Monitore im Gastsystem definieren und nutzen – III
zeigte dann, dass man für den Desktop des QEMU-Gastes auch Auflösungen und Vertikalfrequenzen anfordern kann, die durch den Monitor auf dem Betrachtersystem mit seinen Spice-Clients physikalisch nicht unterstützt werden. Anschließend wurden Möglichkeiten diskutiert, gewünschte Modline- und xrandr-Einstellungen im jeweiligen Linux-System persistent zu verankern.
Wir hatten ferner gesehen, dass man Spice-Fenster auch mit einer speziellen Option „Auto resize VM with window“ benutzen kann. Diese Option sorgt dafür, dass sich die Auflösung des Gast-Desktops automatisch an die Größe des Spice-Fensters anpasst. Das ist u.a. nützlich für den Einsatz von ausgedehnten Spice-Clients auf einem Multi-Monitor-System des Betrachters. Voraussetzung ist für sehr hohe Auflösungen eine hinreichende Ausstattung des QXL-Devices mit Video RAM.
Gibt es Defizite für die Praxis? Ja …
Der Desktop des virtualisierten Systems lässt sich nämlich mit den bisher diskutierten Verfahren nicht angemessen in mehrere Darstellungsflächen unterteilen. Natürlich stehen unter dem Desktop des Linux-Gastes alle Optionen für virtuelle Arbeitsflächen und Aktivitäten innerhalb dieses Desktops zur Verfügung. Aber:
Man kann das Spice-Fenster in der bisher benutzten grafischen “spice-console” des “virt-managers” nicht in mehrere unabhängig positionierbare Fenster auf dem Desktop des Betrachters unterteilen.
So ist es mit der Spice-Konsole nicht möglich, z.B. 2 verschiedene Applikationen des virtualisierten Systems unabhängig voneinander und jede in einer bestimmten Fenstergröße auf dem Desktop des Betrachters (z.B. auf der Workstation) anzuordnen. Wäre das möglich, dann könnte man als Nutzer gleichzeitig etwas in Richtung einer sog. “seamless integration” unternehmen.
Hinweis: Einen echten “Seamless Mode” wie ihn etwa VMware oder Virtual Box anbieten, gibt es zur Zeit nicht. Aber man arbeitet wohl daran: https://www.spinics.net/lists/spice-devel/msg30180.html
Jedenfalls ist es aus prinzipiellen Gründen und wegen einer verbesserten Ergonomie im Umgang mit virtualisierten Systemen interessant, sich den Desktop eines QEMU-Gastes unter Spice und QXL mal mit mehreren “virtuellen Monitoren” anzusehen. In der Spice-Terminologie ist hier von virtuellen “Displays” die Rede. Die sind Thema dieses Artikels.
Voraussetzung 1 der Nutzung mehrere virtueller Displays: Mehrere Heads, hinreichender Speicher des QXL-Devices und aktiver vdagent-Service
Als ich das erste Mal versucht habe, mehrere virtuelle Monitore auszuprobieren, funktionierte überhaupt nichts. Ursache:
Die Standardeinstellungen für das QXL-Device sind so, dass nur 1 Head aktiv ist. Zudem sind die Standardeinstellungen für den QXCL Video RAM unzureichend.
Beides ist zu ändern. Wir hatten die entsprechenden Einstellungen und Formeln für das QXL-Memory bereits im ersten Beitrag der Serie diskutiert. “virt-manager” bietet entsprechende Einstellungsoptionen zum QXL-Device aber nicht an. Man muss also zuerst mal die Domän-Datei “NAME.xml” im Verzeichnis “etc/libvirt/qemu” anpassen. “NAME” ist dabei der Name der virtuellen Maschine [VM]. Typische Memory-Werte für 4 Heads hatte ich bereits im ersten Artikel angegeben; s. dort für die notwendigen Schritte.
Das Gute an Linux-Gastsystemen ist, dass man danach außer der Aktivierung des QXL-Treibers und des “vdagents” (bzw. des zugehörigen Services) nichts anderes tun muss, um eine Unterstützung von bis zu 4 virtuellen Displays unter KVM/QEMU/Spice zu bekommen.
In gewisser Weise und im Gegensatz zu Tools wie X2GO arbeitet das Gastsystem hier keineswegs “headless”. Der Treiber des virtuellen QXL-Devices gaukelt dem Linux-System des Gastes vielmehr vor, dass das dortige QXL-Grafik-Device tatsächlich mehrere Ausgänge besitzt, die ein geeigneter Spice-Client dann (in Kooperation mit dem vdagent und dem QXL-Treiber) dynamisch mit angeschlossenen “Displays” belegt. Für deren Inhalt ist die Desktop-Umgebung des Gastes selbst verantwortlich. Spice übernimmt “nur” den Datenaustausch mit fenstern zur Darstellung dieses Desktops im Betrachtersystem.
Ich setze nachfolgend voraus, dass die QXL-Einstellungen entsprechend den Vorgaben des ersten Artikels für 4 Heads des QXL-Devices vorgenommen wurden. Getestet habe ich konkret mit folgenden QXL-Einstellungen:
<video>
<model type='qxl' ram='262144' vram64='2097152' vgamem='65536' heads='4' primary='yes'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/>
</video>
Dem “Debian 9-Gastsystem” selbst hatte ich großzügigerweise 4GB RAM (Hauptspeicher) spendiert.
Voraussetzung 2 für mehrere virtuelle Displays: Nutzung des “remote-viewers”
Die grafische “spice-console” des “virt-managers” unterstützt meines Wissens keine Darstellung des Gastdesktops in mehreren “Displays”. Ein passender Client hierfür ist dagegen der sog. “remote-viewer“.
Man kann den “remote-viewer” von einem Terminalfesnter starten, nachdem man die virtuelle Maschine per “virt-manager” gestartet hat. Wir betrachten hier den Aufruf auf einer Linux-Workstation, die gleichzeitig als KVM-Host dient (Aufrufe über Netz werden Thema eines eigenen Artikels):
myself@mytux:~> remote-viewer spice://localhost:5900 &
Die Portnummer muss man ggf. anpassen, wenn man hierfür eine abweichende Einstellungen vorgenommen hat.
Hinweis: Unter Opensuse und Debian muss man ggf. Mitglied der Gruppe “libvirt” sein, um den remote-viewer erfolgreich ausführen
zu können; unter Ubuntu Mitglied der Gruppe “libvirtd”.
Sollte man vorher bereits einen anderen Spice-Client zur Darstellung des Gast-Desktops gestartet haben, wird diese frühere Spice-Sitzung unvermittelt und ohne Warnung abgebrochen.
Aktivierung zusätzlicher Bildschirme
Ein Blick auf die verfügbaren Menüpunkte zeigt schnell Unterschiede zur “spice-console”. So bietet der Menüpunkt “Ansicht >> Displays” Checkboxen für 4 Monitore (entsprechend den 4 Heads unseres QXL-Devices).
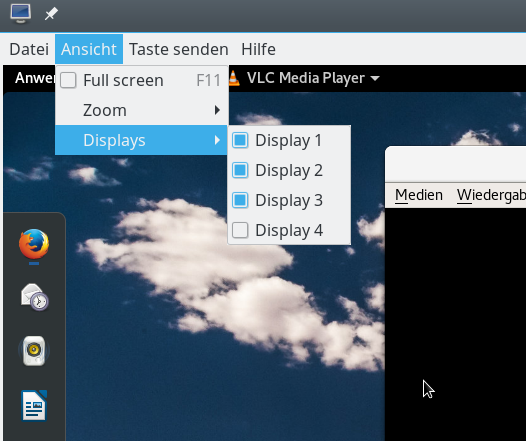
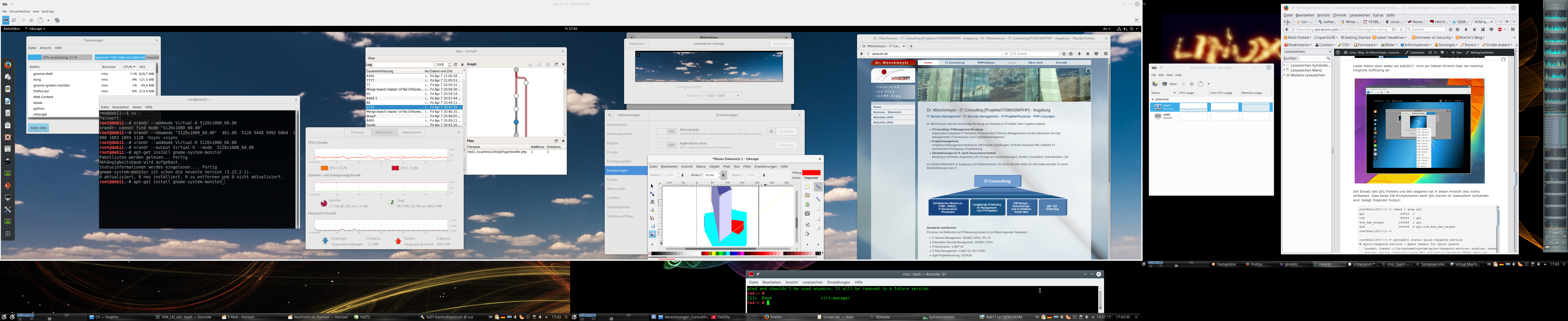
Man sieht, dass ich hier drei (virtuelle) “Displays” aktiviert habe. Der nachfolgende Screenshot zeigt diese “Displays” für die Darstellung des Desktops eines Debian 9-Gast-Systems auf einem von 3 physikalischen Monitoren einer Linux-Workstation, auf der selbst ein KDE-Desktop aktiv ist.
Zusätzliche virtuelle Displays erst nach dem Login aktivieren!
Der nächste Hinweis hat vielleicht nur Gültigkeit für einen Debian-Gast mit gdm3, aber mindestens mal da erweist sich der Tipp als nützlich:
Öffnet man im “remote-viewer” mehrere Displays, wenn noch die primäre Login-Maske von gdm3 angezeigt wird, so verschwindet die bei mir dann nach dem Aktivieren weiterer Displays – bzw. passte sich nicht mehr automatisch an den Fensterrahmen des ersten Displays an. Das ist wirklich unangenehm, weil man sich dann nicht mehr so ohne weiteres einloggen kann und zwischenzeitlich wieder auf die Spice-Konsole von virt-manager ausweichen muss. Also:
Erst einloggen, dann weitere virtuelle Displays aktivieren.
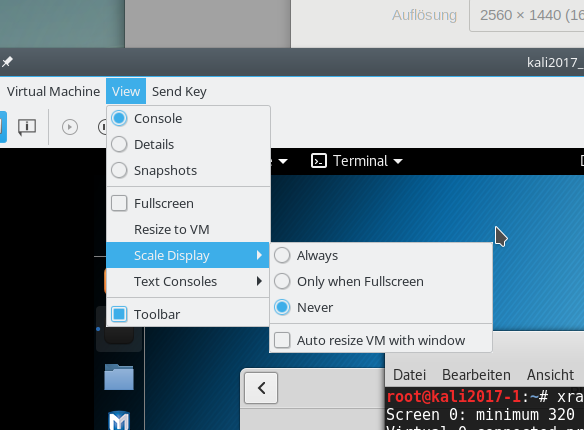
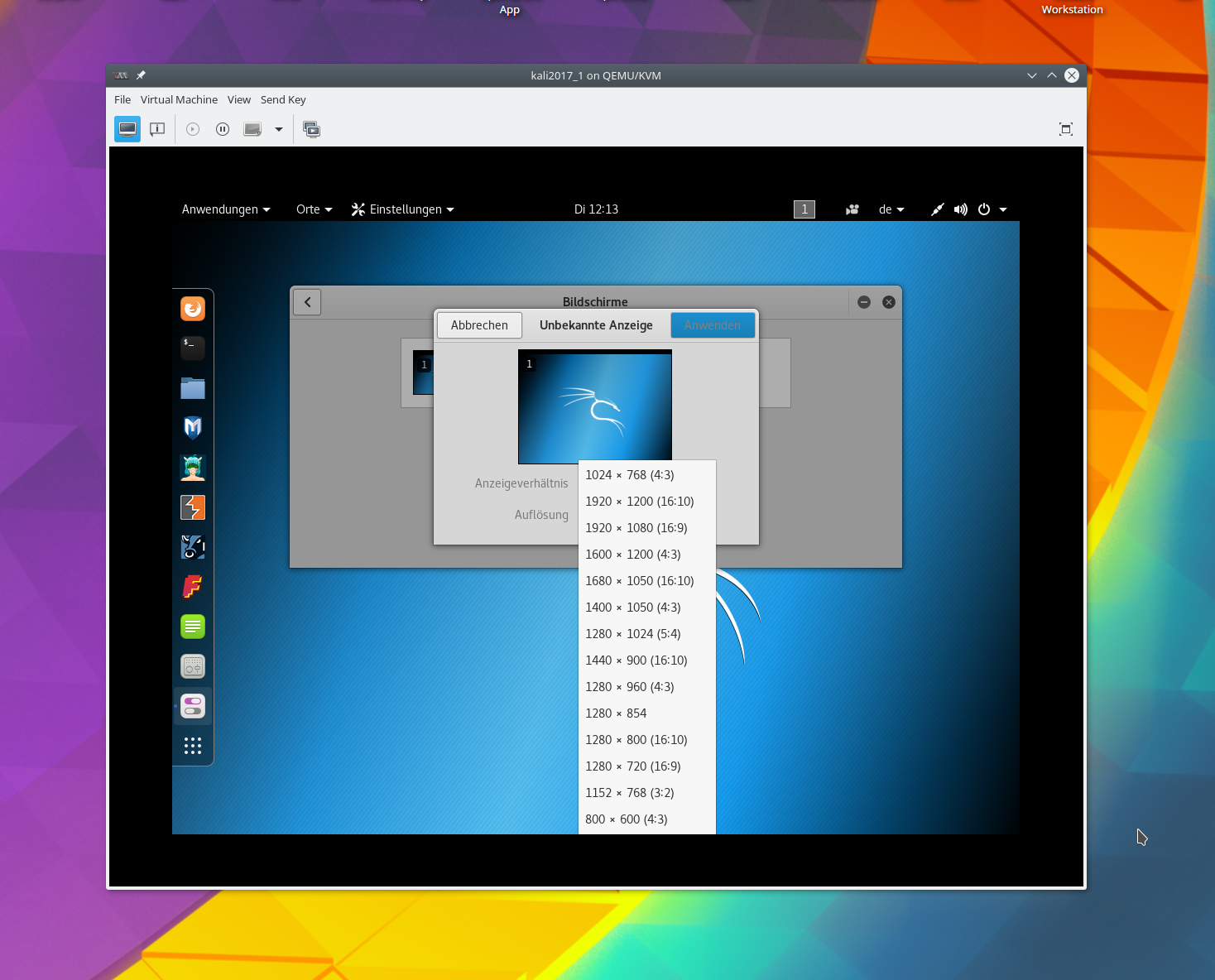
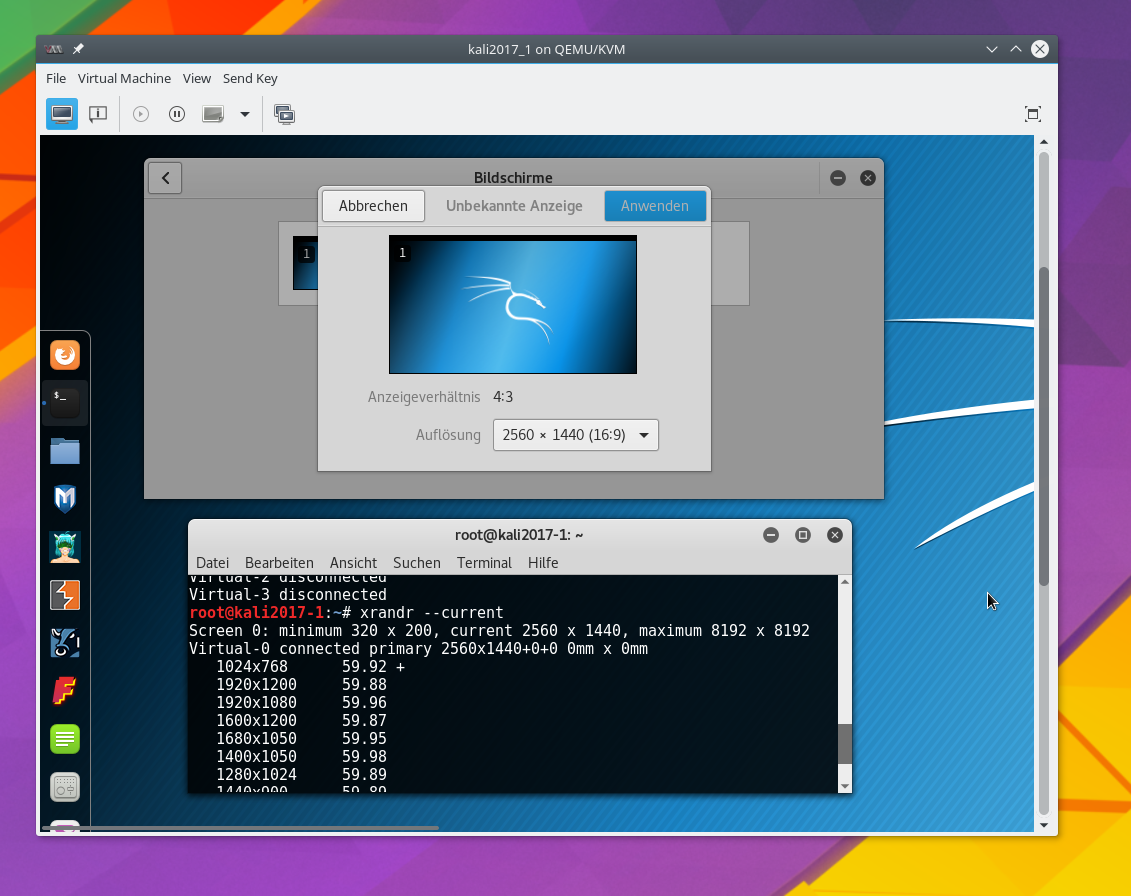
Automatische Auflösungsanpassung an die Größe der virtuellen Displays
Im “remote-viewer” gibt es keinen Menüpunkt zum Aktivieren/Deaktivieren einer automatischen Auflösungsanpassung an die Größe der aktivierten Displays. Das wird automatisch gemacht – unabhängig davon, was man vorher ggf. in der spice-console von virt-manager eingestellt haben sollte. Bei mir führte eine Veränderung der Größe irgendeines der geöffneten Displays zu einem Flackern aller virtuellen Displays, bis sich die neue Desktop-Darstellung aufgebaut hatte. Aber immerhin – die Anpassung funktioniert. Dabei gilt:
Die Spice-Fenster für die virtuellen Displays können völlig unterschiedliche Größen haben. Der Desktop des Gastes passt sich daran an!
Nahtloser Übergang zwischen den Displays
Es ist möglich, Applikationen nahtlos zwischen den verschiedenen Displays hin und her zu schieben. Dabei legt Spice in Abhängigkeit von verschiedenen Faktoren in sehr sinnvoller Weise fest, welches Display sich links oder rechts vom aktuellen Display befindet. Relevant ist dabei zum einen die Positionierung, die bei der letzten Größenänderung eines der Displays gegeben war:
Befand sich etwa “Display 3” bei der letzten links vom “Display 1”, so kann man eine Anwendung nach links aus dem “Display 1” in das “Display 3” bewegen – egal wo Display drei gerade ist.
Ein weiterer Faktor ist aber auch die Position der Maus – kommt die beim Ziehen in ein anderes Display (desselben Gastes), bewegt sich auch die Applikation dorthin.
Quasi-seamless Mode?
Wie gesagt, einen echten “Seamless Mode” bietet Spice noch nicht an. Aber: Wir können zumindest bis zu 4 Applikationen den Rahmen jeweils eines der 4 möglichen virtuellen Displays vollständig
füllen lassen – und auf dem Desktop der Workstation verteilen.
Das Schöne ist: Bei einer Größenänderung des jeweiligen virtuellen Displays passt sich die dort enthaltene Applikation dann automatisch an die Rahmengröße an.
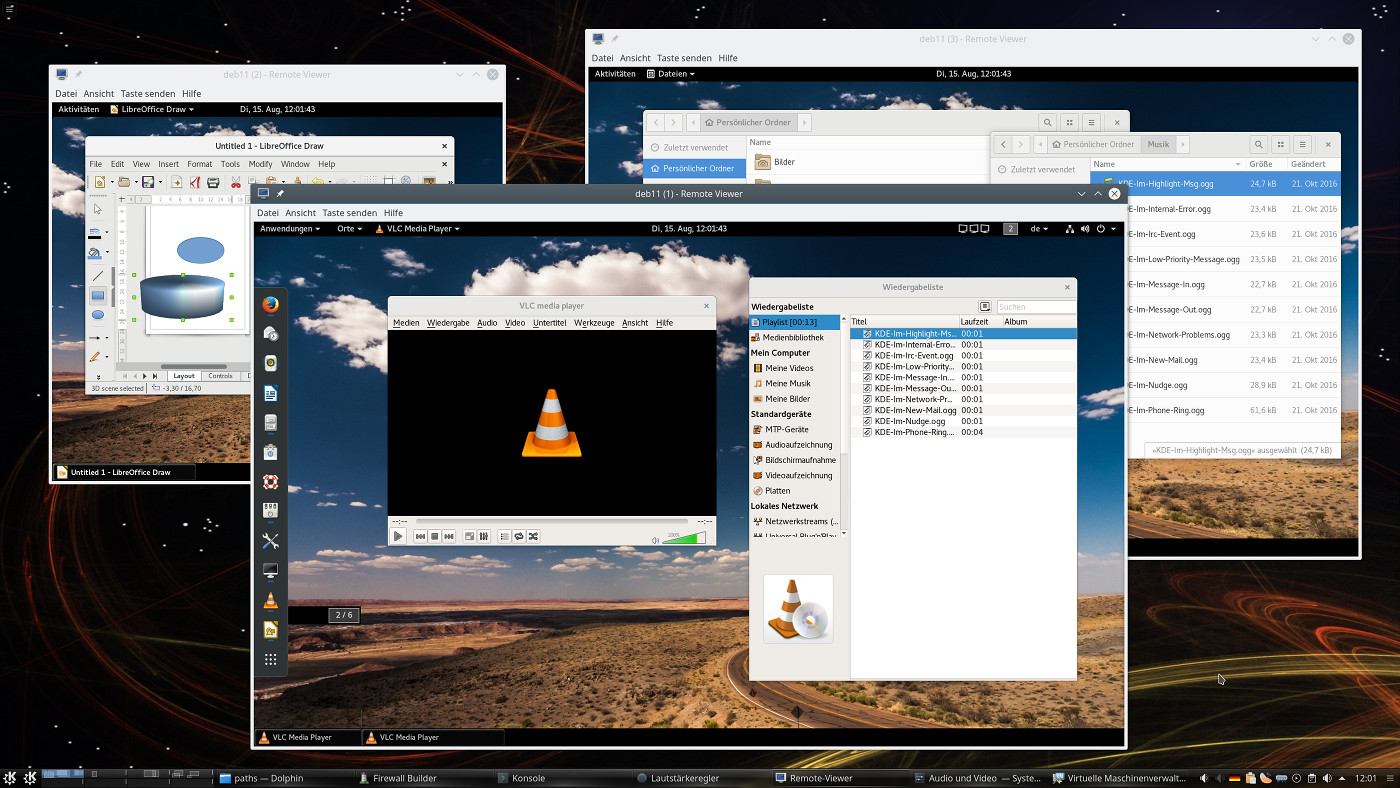
Das nachfolgende Bild zeigt hoffentlich, was ich meine:

Hier sieht man von links nach rechts:
- 1 virtuelles QXL/Spice-Display eines KVM/QEMU-Debian 9-Gastes mit Gnome, in dem VLC eine aktuelle ARD-Sendung abspielt.
- 2 Clementine-Fenster, die dem KDE-Desktop der Workstation originär zugehören.
- 1 virtuelles QXL/Spice-Display des KVM/QEMU-Debian 9-Gastes, in dem Libreoffice Draw geöffnet ist.
- 1 Libreoffice Draw-Fenster, dass originär im KDE-Desktop der Workstation gestartet wurden.
Auf den ersten Blick sind die verschiedenen “Fenster” aber nicht als originale Fenster des KDE-Desktops der Workstation oder als Spice-Displays für die Darstellung des Gastdesktops einzuordnen. Das ist fast seamless und damit kann ich gut leben …
Multi-Monitor-Support im Gnome-Desktop des Gastes
Obwohl spezifisch für Gäste mit Gnome3-Desktop, hier ein kleiner Hinweis zur Multimonitor-Unterstützung: Man sollte sich hierfür unedingt ein paar aktuelle “Gnome-Extensions” installieren.
Die aktuellste Version von “Dash to dock” etwa erlaubt etwa die Auswahl des Spice-Displays, auf dem das Dock-Panel angezeigt werden soll. Und dann gibt es auch noch die sehr nützliche Erweiterung “Multi-Monitors AddOn”; sie erlaubt es verschiedene Informationsleisten etc. auf allen Displays anzeigen zu lassen:

Off-Topic: Was ist eigentlich mit Sound?
Nachdem ich oben in einer Abbildung einen Fernsehstream in einem Linux-Gast laufen ließ: Ist eigentlich eine Übertragung von Sound aus dem virtualisierten Gast in die Workstation möglich? Ich gehe auf diesen Punkt nur kurz ein, da dieser eigentlich nicht Thema dieser Artikelserie ist. Mir sind zudem auch noch nicht alle Zusammenhänge für den Soundtransfer klar. Es scheint jedoch so zu sein, dass das weniger ein Spice- als vielmehr ein QEMU-Thema ist.
Tja, und dann stolpern wir bei Internet-Recherchen erwartungsgemäß mal wieder über das Thema “Pulseaudio“. Vermutlich muss QEMU nämlich das Sound-Backend des KVM-Hosts unterstützen. Die Unterstützung verschiedener Soundsysteme ist aber etwas, was man bereits bei der Kompilierung von QEMU einstellen muss. In den meisten Distributionen (hier Opensuse) ist das QEMU-Paket aber lediglich mit Pulseaudio- und nicht mit reiner Alsa/Gstreamer-Unterstützung erstellt worden. Ergebnis:
Mit dem Standardpaket von QEMU unter Opensuse habe ich auf einem KVM-Host nur eine problemfreie Soundübertragung hinbekommen, wenn sowohl im Gastsystem als auch im Hostsystem Pulseaudio aktiv waren. Pures Alsa auf einer Linux-Workstation und KVM/QEMU-Virtualisierung sind zusammen wohl nicht ohne experimentellen Aufwand zu haben.
Mit Pulseaudio klappt die Soundübertragung aber gut – soweit Pulseaudio halt selbst mit den Gegebenheiten der Arbeitsstation (Soundkarten, Anwendungen) vernünftig umgehen kann. Und da gibt es nach wie vor Zipperleins. Immerhin kann man den Sound der virtuellen Maschine über Spice dann auch durch den systemweiten Ladspa-Equalizer von PA auf dem Betrachtersystem – hier also der Workstation
selbst – jagen. Das sieht dann etwa so aus:
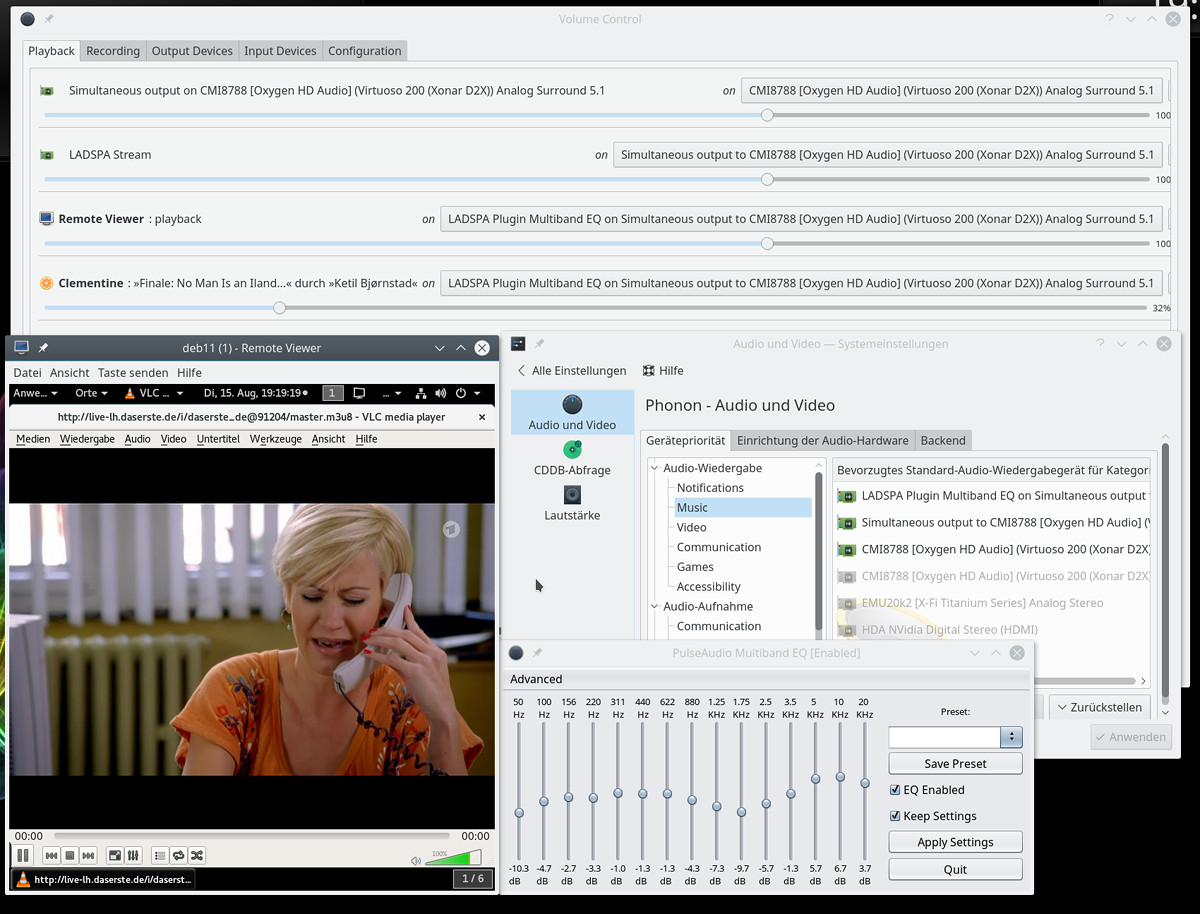
Man beachte den “Remote Viewer”-Kanal im Lautstärke-Regler und dessen Verlinkung mit dem Ladspa-Equalizer! Das Bild dient nur der Illustration – Clementine würde ich normalerweise direkt auf das Device “Simultaneous Output” abbilden und den in Clementine eingebauten Equalizer nutzen. Der ist nämlich für mein Gefühl in den Übergängen zwischen den verschiedenen Frequenzbereichen besser und sanfter abgestimmt.
Aber PA ist ja ein Thema für sich – auch wenn sich langsam das eine oder andere bessert und die Zahl der Ungereimtheiten im praktischen Betrieb wenigstens ein wenig zurück gegangen ist.
Ausblick
Es gibt zwei Themen, die bisher nur stiefmütterlich behandelt wurden:
- Die Netzwerkfähigkeit von libvirt und Spice.
- Der “virtio”-Grafiktreiber, der alternativ zum qxl-Treiber auf Workstations benutzt werden kann, die gleichzeitig als KVM-Host und Client zur Nutzung der VM dienen.
Beide Punkte werde ich in kommenden Artikeln behandeln, sobald ich Zeit dazu finde. In der Zwischenzeit wünsche ich dem Leser viel Spaß beim Einsatz von KVM, QXL, Spice und virtuellen Displays.
Links
Spice-Clients
http://www.datacenter-insider.de/die-besten-spice-clients-zur-erhoehung-der-netzwerk-und-festplatten-performance-a-468322/
In die Links wurden Minus-Zeichen eingefügt, um einen Umbruch zu erreichen. Die korrekte URL muss man sich über einen Rechtsklick besorgen.