My last blog post
Webclipse JSjet, Eclipse Neon 2 and the Outline View – what I like and what not – part I
started a mini series about JSjet, a product sold by the company Genuitec. In the first post I discussed some advantages “Webclipse JSjet” offers regarding the Outline View for Javascript code in Eclipse Neon 2 and 3 – at least in comparison with Eclipse’s present JSDT. A first test showed that we get a lot more information – especially on ES6 classes or constructor functions – than the present JSDT plugin of Eclipse is able to provide. This was a promising result and proofed basic claims of Genuitec.
However, I also indicated already in the last post that there are some points of JSjet’s information provision which are ambivalent and could be criticized. I even raised the question whether all the information presented by JSjet in the Eclipse Outline View is really valid. For a better analysis I set up a test file with valid Javascript code – but a relatively chaotic code structure.
The objectives and the results of my limited test are discussed below. The results were a bit surprising.
For reasons of completeness I add that I used a licensed Webclipse JSjet version 1.72.201703081933 / 2017 CI 3b. JSjet internally uses Tern modules. I do not distinguish between these two below and shall not speculate which component is responsible for what. When I name JSjet I always mean the duo of Webclipse JSjet and Tern. And I must warn you: This is going to be a long article – not only about JSjet but also about some Javascript aspects, which not everybody may be familiar with.
The presentation of code hierarchy levels in an Outline view is not all one needs during a Javascript coding process; in addition one expects a reasonable quality of the code analysis concerning variable types and variable/function association with objects or classes.
Any information regarding the origin of variables and a clear distinction between the following variables/functions would be valuable for a Javascript developer – especially if he/she had to deal with code designed by others:
- specific variables/functions set for and added to a specific object by related explicit statements in the JS code after object creation,
- member variables/functions set by a constructor function at the creation of an object. (Rmemeber: the “this”-operator in a constructor function refers to the object being created by the constructor!)
- and variables inherited as members of a prototype object (e.g. the prototype of a constructor function). (Remember: the protoype object of a constructor function is linked to the __proto__ property of the objects created with the help of the constructor).
Actually, JSjet and Tern do provide type hints in the Outline View and mark things they regard as “prototypes” with a “P” and specific objects derived from a constructor function (and its prototype) with an “O“. (The latter is, of course, also true for object literals.) Elements of classes, constructor functions and prototypes are displayed as sub-elements of a related “P“-section in the Outline View. The type of such variables and functions is revealed – if JSjet can determine it.
JSjet does, however, not distinguish between (this.)elements of a constructor function or elements (functions, variables) added explicitly to the prototype of the constructor function. Under a “P” section for a constructor function ”
F()” you would see everything that would be available in a specific object created by a “new F()” statement.
This is a bit problematic as it mixes different categories of variables/functions – the one’s that are directly created in a new object by the constructor and the variables plus functions coming from the inherent prototype object of the function F(). But OK …
The relation of a specific object with its constructor and prototype is indicated in the Outline View (at least in most cases) by a reference to the name of the basic class or the constructor function used during object creation.
Thus the type of information JSjet basically provides would certainly be sufficient
- if you never changed the type of defined properties (i.e. member variables) by assigning “values” or code elements with different types after object creation in your code. I.e. if the types of member variables defined in the constructor or in parent prototypes would be kept throughout the whole code execution.
- if you never extended certain objects by new (!) properties and methods.
- if you only used conventional prototype or class oriented patterns for inheritance.
- if you never used some specific objects directly as a prototype for Child constructor functions.
Meaning: If you followed a strict and conservative coding philosophy, where everything (!; i.e. all variables and methods used in the code), is based on classes or explicitly defined elements (properties/functions) of constructor functions and/or (their) prototypes.
But Javascript allows for two interesting things which give you a lot of flexibility:
- The extension of existing specific objects by explicitly adding new property variables and new functions/methods – i.e. beyond the prototype members and the constructor variables provided at the object’s creation. You can always perform such an extension without modifying prototypes/constructors in the inheritance chain up to your specific object. Such properties/functions would, however, only be accessible by and through the particular object.
- A direct prototypal pattern for object inheritance where the prototype of a temporary constructor (e.g. K()={};), which later on is used to create a “Child object” (e.g. “C”), is directly linked to an existing “Parent object” (e.g. “U”; K.prototype = U; C=new K();). This works because a prototype basically is nothing else than a special object. This is a kind of classless and very pragmatic inheritance pattern; it concentrates on the reuse of an existing object and its properties/methods for yet other derived objects. The latter then inherit all properties and functions defined so far for its/their Parent object. In contrast to other inheritance patterns we do not care about the history of the Parent object or the existence of a constructor function for it. In this approach – and close to the very core of Javascript – all that counts are objects and not abstract “classes”.
Note that the prototypal pattern is implemented in ES5 via the function Object.create().
A first warning regarding prototypal patterns:
As we shall see, JSjet does NOT display an existing specific object, which is used as the prototype of a new constructor function, as a structured “P” element in the Outline View.
I guess it was difficult to decide whether one should stress the role of such an object as an existing “object” or as a “prototype” for other objects. Whatever the reason, my JSjet version had no solution to offer for indicating both aspects of an object, which was used both in its role as an object AND as a prototype for other objects. But all properties/functions of such an object
would appear below the new constructor function “K()“.
But I would have hoped that at least the dependency of the new Child constructor function on the specific object was somehow indicated. But this is not the case either – as we shall see.
Expectation: Distinction of object specific properties from properties created by constructors or delivered via prototypes
However, as JSjet distinguishes between a constructor function (including its prototype) and objects derived from it, we would expect a proper distinction of variables added to a specific object on one side and the variables of the constructor function/prototype used to build the object on the other side. In addition variables or functions added to an object, which itself is used as a new prototype for further CHILD objects in the prototypal pattern should be associated correctly.
Unfortunately, regarding these points I stumbled over – in my opinion – problematic aspects of JSjet/Tern, which I want to discuss below.
Let us now look at a “chaotic” test script and the resulting Outline information of JSjet. Why do I want to use a seemingly unorganized “chaotic” code example instead of a ordered one? Well, I do not exactly know how a code analyzer works; but it seems reasonable to assume that it must pick up information whilst parsing the Javascript code of a file; furthermore the gathered information has to be systematically ordered afterwards and analyzed for relations between objects and their constructors/prototypes. Global variables have to be detected, global functions have to be distinguished form encapsulated ones, and, and, and … A code analysator for Outline purposes probably will not be so “intelligent” as the interpreter itself, but it must do a reasonable reordering of code fragments to display the structural code and object hierarchy and to point out relations between defined elements correctly.
For testing a code analysis tool a test script, therefore, should contain code in “chaotic” order – and it should, of course, comprise not only the most simple language constructs. Actually, for the purpose of a provocative testing we would also like to do things, which we normally would not do. The test code displayed in the next picture was compressed to get it onto one page; it has an erratic, jumpy order of statements – on purpose. Normally, I do not write such chaotic code; but the more unstructured, the better for this type of a test. If you do not understand it at once – why should a machine ….
So, how does it look like – and what does JSjet make of it and what does it reveal in the Outline View? Just click on image or download it in case it is too small to read its content. Or download the following txt file with the code jsjet_test_code – if you want to experiment with it.
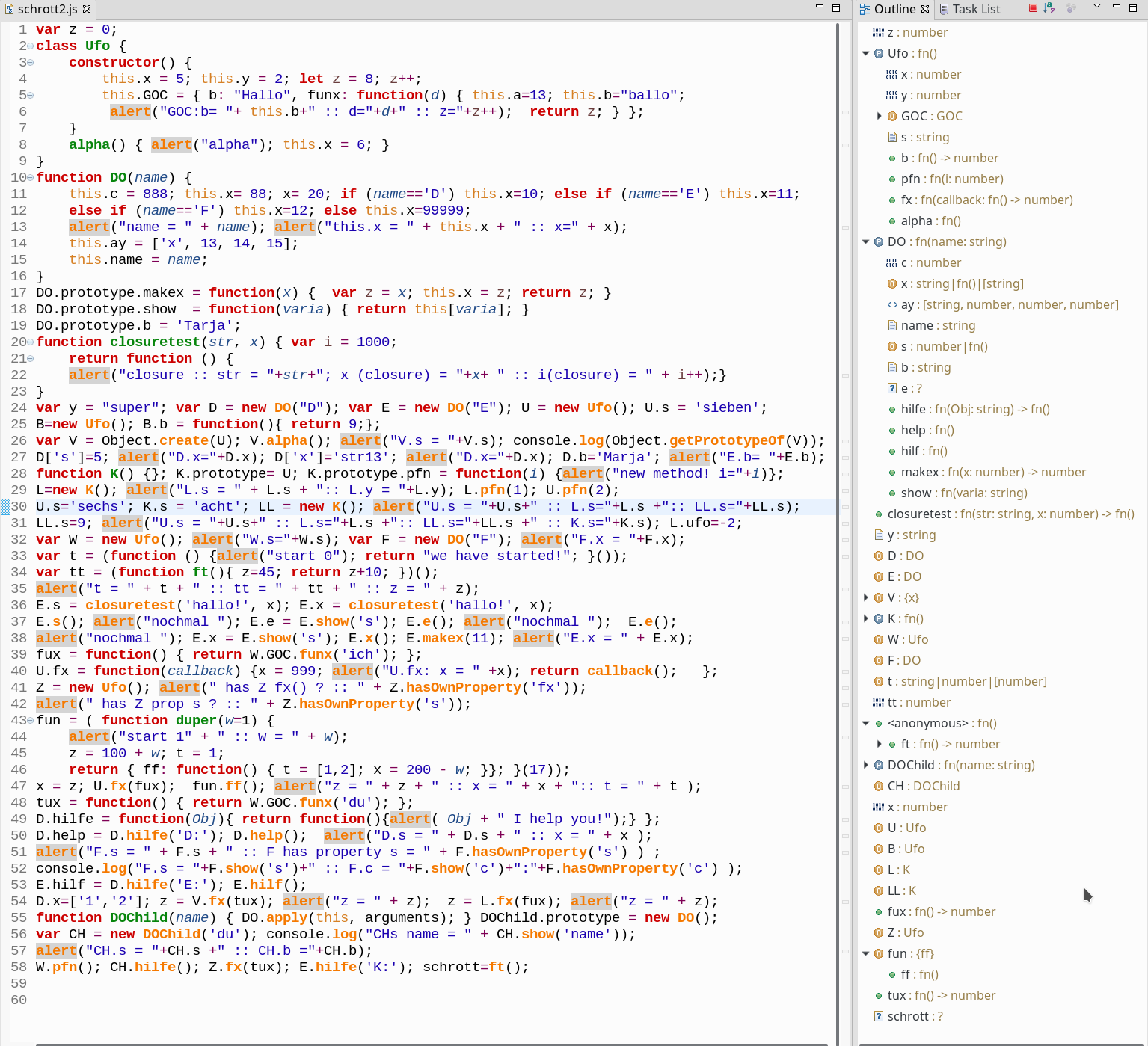
With the exception of the statements in the last line – this is all valid Javascript code and can be tested. I used “alerts” instead of “console.log” statements to save some space. As you see, I have included some relatively advanced constructs like closures, immediate function declarations, callbacks and two most simple inheritance patterns. Note in addition that each of the last six statements would result in a Javascript error. All in all this limited script is certainly not a totally simple test task for the code analysis capabilities of JSjet.
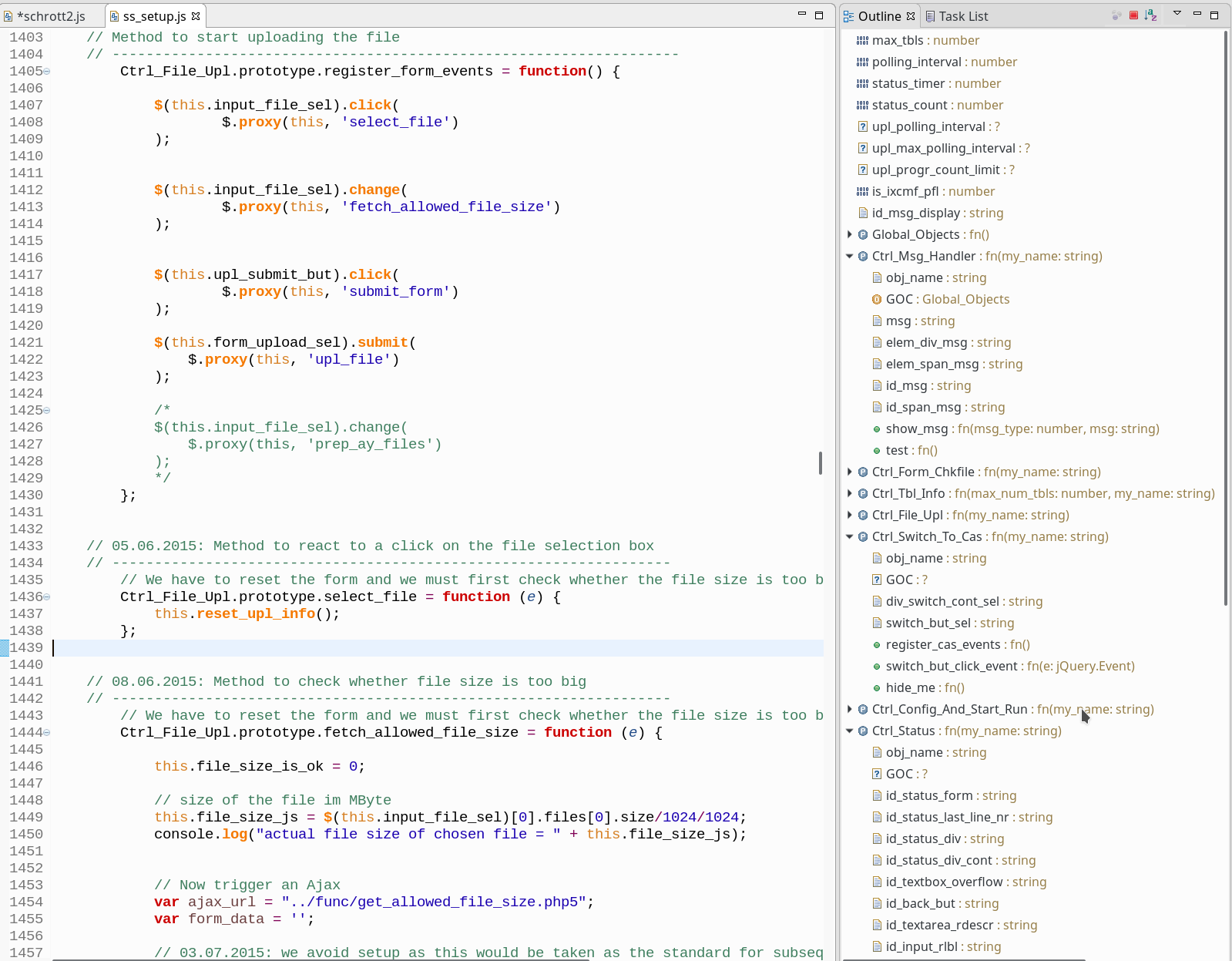
So… what do we make of the information in the Outline View? Let me walk through some aspects of the information displayed
in the Outliner. I have closed some hierarchy parts of the Outline View to get it onto one page; but I shall show the contents of these points where necessary.
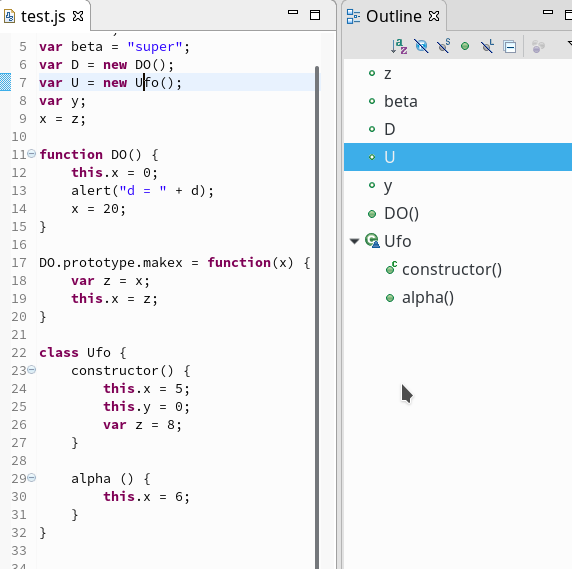
I start with a positive point: Global variables not explicitly declared via “var” or “let” statements are gathered at the end of the Outline View – in our case starting with the variable “x”. Yes, in contrast to JSDT JSjet detects all global variables and displays them! However, one would wish a better distinction of these variables introduced in the code on the fly from explicitly declared variables.
Furthermore the object “GOC” included as a property in class Ufo’s constructor is analyzed for its elements:

Note, that the local variable “z” is missing however. We shall come back to this point.
But there are other more confusing things to talk about first ….
The first line that really looks fishy in the Outline View is the line that displays a property “s” : If we take the information of the Outliner literally we would assume that “s” is an element of our class Ufo (or of the respective internal constructor function and the latter’s prototype). However, we never declared any “s” as part of the class Ufo, Ufo‘s constructor or Ufo‘s methods!
Instead: “s” is added to a specific object “U” based on the constructor of class “Ufo” in the course of our test code (line 24 and 30).
Hmm, who else besides object U in our code example would really know about this property “s”? Who could use it? Have a look at the U-based objects “V” (line 26) and “L” (line 29). We recognize a very simple prototypal inheritance pattern for “L” in line 28/29 and for V via Object.create() in line 26. Yes, I mixed the ES6 class syntax with old fashioned prototype manipulations in lines 28/29. Not nice, but valid. What does it mean for the derived new constructor function “K()” – and how is the relation between K() and U represented in the Outline view?

The constructor function “K()” and its prototype U are analyzed by JSjet; reasonably enough all U-properties, including those coming from its class “Ufo”, are shown in the Outline view. We, therefore, expect the properties “x” and “y” to appear below K. But we would also expect the newly added property “s” of “U” in K’s outline, because U is used as a prototype for “K()“. (Ignore the other elements for a moment.)
Note, however, that the relation of the new constructor function K() to U is not directly reflected in the Outline View; but this is no real issue.
Technical aspects: The prototype of the constructor function K() points to object U. So, actually, object L, which is based on K(), should also know about a property “s” : namely by or the provided through prototype object U. The “Object.create()” function does something similar when creating object “V“. Also object “LL” defined in
line 30 knows about “s”.
But note: Any change of “U.s” would show up in the derived objects, too – at least and as long as we do not assign own s-value to our objects L, V, LL. So the outcome for the alert statement in line 31 is:
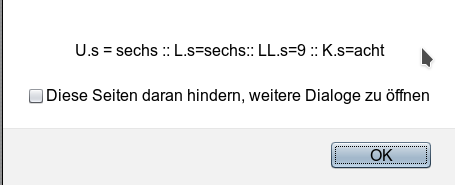
However, neither the constructor function of class Ufo nor its prototype are really affected by all these manipulations of object “U” and the objects based on “U” ! So, it makes NOT much sense to display “s” as an element of Ufo; it is an element of U, i.e. K’s prototype, of V, L, LL.
This is very clearly tested by creating an additional object “W” based on Ufo after all the fuss with the extension of U. As expected W does NOT know anything about a property “s”.
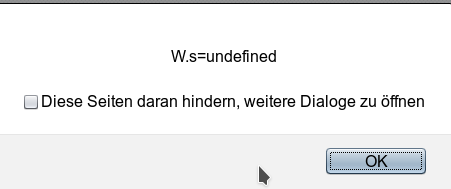
Nevertheless, even the code completion context menu of JSjet offers “s” as a possible property element of W. The next picture resulted from the code completion support triggered via “Ctrl+Space” after typing a “W.” in the code:
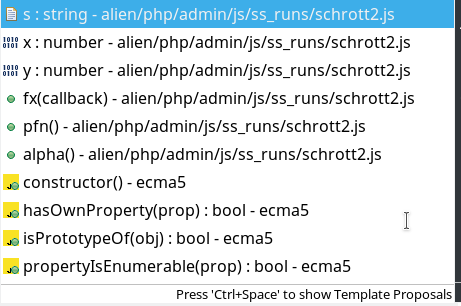
Is this problematic? Well, in our simple example picking up an “undefined” property form the code completion dialog would not matter much. But things would become much more dangerous if the JSjet code completion window offered undefined functions/methods! Guess what: It does! See below.
First conclusion
From our example we get the following impression: During code analysis JSjet picks up new properties (and possibly functions,too,) added to specific objects, which themselves were derived from a class constructor. JSjet then associates these properties/functions with the original class constructor; JSjet presents them as if they were elements of the related constructor/prototype and thus at the inheritance origin of all derived objects. This is misleading.
Just a strange way to analyze the ES6 “class” syntax? Well, you see this (misleading) pattern again when you look at how the property “ufo”, which is added to object L at the end of line 31, is reflected in the Outline information about the constructor function “K()” (see the picture on K above).
Note that in addition to “s” JSjet displays two methods/functions “pfn()” and “fx()” as elements of our class “Ufo” [better: its constructor/prototype] . But again: We never declared these methods for class “Ufo”!
Instead we did something very different: We added function “pfn()” to the prototype of K() (and thus indirectly to object U) (line 28). And much later (after the creation of V and L) we added function “fx()” directly to our object U (see line 40). So, after this point in the code both V, L and LL would know about fx(), too, and could execute it properly. Normally, one would not program in this dangerous way – but it is possible.
But what about W and another object “Z” based on the original class “Ufo“?
W and Z never see anything of pnf() or fx(). They do nothing about these functions! Therefore, if we called W.pfn() the Javascript code would run into an exception and stop. And as expected it really does at the first statement of the last code line:

Nevertheless, we get both functions offered as valid elements in the JSjet code completion support window when typing “W.“:
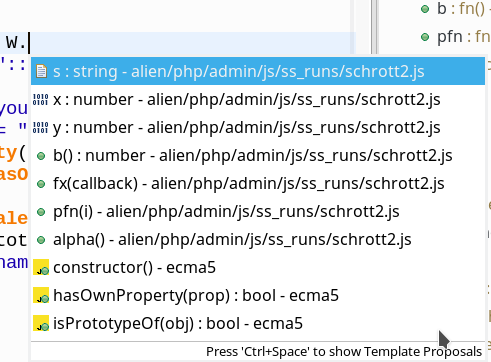
So:
Picking functions from the JSjet code completion dialog window whilst coding in Eclipse can under certain circumstances lead to code errors!
We additionally check that the original class properties are kept and are not modified throughout the code via our object “Z“; see line 42 (result : false) and line 59 (error).
Second conclusion
Presenting variables and functions, which are added to a specific object, as elements of and within the scope of the object’s “class” in the JSjet Outline View is at least misleading. Personally, I would even say that it is wrong! Offering such functions in the code completion dialog as possible elements of newly created objects, which are based on the original class, may lead to errors!
Is this a systematic bug or does it somehow depend on the relatively new ES6 class definition syntax? Nope, it goes wrong also for prototype based declarations of objects; see below.
Interestingly enough JSjet does NOT see what object V inherits from the prototype delivered to “Object.create()” – in this case the object “U” itself. In the Outline View V is only presented as a literal object – for whatever reasons.

Only one variable, “x”, is displayed as an element of V. That it appears at all probably results from an analysis of Ufo‘s function alpha() which is called a bit later via “V.alpha()” … [This assumption can be tested by modifying alpha().] So JSjet knows about the indirect dependency of “V” on class Ufo – but this knowledge is not used for V‘s presentation the Outline View.
The next remarkable point in our Outline View is that we do not see our private variable “z” defined in the constructor of class “Ufo”. This is unfortunate; especially as we have defined a (different) global variable “z”, too. And even more unfortunate, the JSjet code completion dialog offers us only an unspecific “z” (described as an element of our js-file) when requesting code completion:
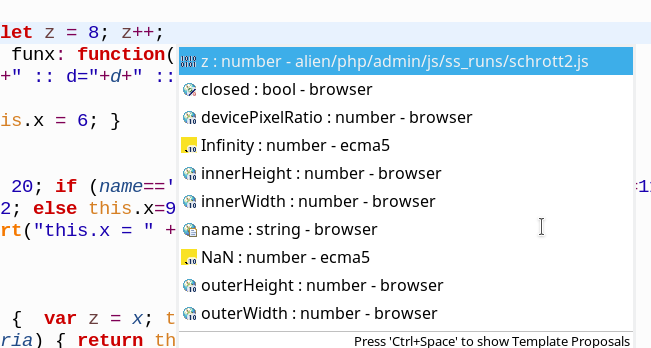
So, here we see a clear limitation of the analysis depth of JSjet/Tern: Private variables are neither shown in the Outline View nor do they appear in a safe and distinguished way in the code completion dialogs.
In general: Private variables defined in any kind of function are out of the scope of the Outliner. This is annoying; especially because the code analysis actually does seem to know something about the existence and even the
type of “z”: the type of the return value of the GOC-method funx(), namely “z”, is detected correctly.
Let us turn to the constructor function “DO()” (and its prototype): The Outliner tells us that there is a variable “x” having 3 different types. It is claimed that “x” is an object! But we did NOT define any string or array values for the variable “x” of function “DO()” or its prototype. Neither did we declare “x” as a function! Instead “x” was explicitly given a number-value in the DO-function’s body!
Again, our problem is that JSjet’s Outliner does not distinguish sufficiently enough between variables and functions of a specific object and variables/functions of the constructor or prototype, from which the object was derived. In the course of our (chaotic) code we assigned a string to an object “D“, which is based on the DO() constructor function, via D[‘x’] = ‘str13’ (line 27). In addition, near the end of the test code, we assigned an array to “D.x” via the statement “D.x=[‘1′,’2’]” (line 54). And in between we assigned a function to the member variable “x” of an object “E” via “E.x=closuretest(..)”; “E” was derived from the constructor function “DO()“, too.
But what do these object specific changes of properties have to do with the original variable “x” of the constructor function and its type there? Answer: Nothing! So, again JSjet/Tern provides us with somewhat misleading information about the elements of the DO() constructor.
In my opinion, the object specific modifications should have been displayed beneath the affected objects and not below the DO() function. The constructor itself will always deliver a “number” for the “x”-variable of any object created by “new DO()”.
The only piece of information that would make us suspicious in this case is the presentation of “x” as an object (!) in the Outliner. We could interpret this as a warning about how the variable “x” is used later on in specific objects; but even this would be confusing as, unfortunately, the original type of a number is not displayed.
As we did for our class “Ufo” we tested the consequences of an extension of objects created by a “new DO()“. We added again a variable “s” to some of these objects. Furthermore, we also supplemented functions – directly or indirectly. See the statements “D[‘s’]=5” in line 27, “E.s = closuretest(..);”, “E.x = closuretest(..);” in line 36 and E.e = E.show(‘s’) in line 37.
As a first consequence we get a variable “s” in the information about the constructor DO() (or its prototype). Which – in my opinion – is misleading and wrong. Again, “s” also and wrongly appears in the code completion dialog.
The presentation of the functions “hilfe()“, “help()“, “hilf()” as elements of DO() is equally problematic. Again these functions are assigned to and cross referenced by properties added of specific objects! They are not part of the constructor function or its prototype. The Outliner does not make this clear! And the code completion window offers these functions unconditionally! E.g. for object D when typing “D.” followed by “Ctrl+Space”:
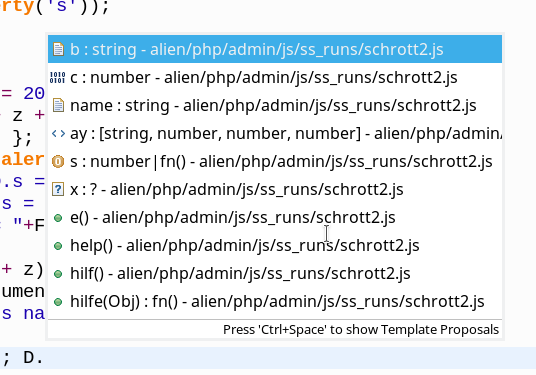
Now let us have a look at the information about ”
E.e“. The type of this member variable is not specified in the Outline View. This is interesting because “E.s” was correctly detected as a function before. “E.s” is a function assigned by a closure, and E.e uses E.s. But the fact that we set “E.e=E.show[‘s’]”, which only indirectly points to a the function E.s(), seems to block the type recognition. And after that even the explicit call as a function “E.e();” in the code does not help. But OK — it is always difficult to follow indirect assignments … What we must complain about, however, is again the fact that “e()” nevertheless is offered as a legitimate function (!) in the code completion menu for object D (see the picture above). But: E.e() will never be available for object D !
Third Conclusion
The problematic display of variables and functions, which are added to specific objects, as elements of the “prototype”, from which the object was derived, is also found when we use classical constructor functions (and their prototypes) for creating objects. In addition JSjet either does not recognize the relation of an object with a prototype object when Object.create() is used, or JSjet does not indicate this relation in the Outline View.
Regarding the global function “closuretest()” we again bemoan the missing display of the private variable “i”, which actually makes this function a closure (“i” is manipulated in the returned and encapsulated function’s body). Closures are one of the possibilities to provide real private variables in a lot of JS patterns – but JSjet/Tern does not help us here. In the code completion dialog the origin of the offered “i” is not specified either (we are only told that “i” appears in JS file). In this case i’s location and meaning would be clear; but what in longer real life codes?
The next strange point is the handling of an immediate function statement with a named (!) function inside; see the declaration of “var tt”, whose resulting type is recognized correctly. I admit: The naming (“ft”) of the encapsulated function does not make much sense, but interestingly the analysis of JSjet seems to run into an infinite loop for displaying the internal structure of the “anonymous” function block – containing the “ft()”. See the following picture! Really confusing! And compare this with the unnamed immediate function in the declaration of variable “var t”.

But it gets even more confusing! In the code that follows after the definition of “ft()” we find a direct counterexample – namely the definition for the variable “fun” in line 43 – which was not declared via a “var”-statement. Here we also have used a named function encapsulated in brackets for immediate execution. However, in this case we do NOT get a display of a seemingly infinite hierarchy structure in the Outline View!
And something positive In addition: The type of the global variable “fun” is recognized correctly as an object defined by a literal. But the encapsulated immediate function is ignored in the Outline View; function “duper()” does not appear there at all.
However: As soon as you replace the assignment statement by “var fun = “, an infinite hierarchy recursion appears for function “duper()” in the Outliner, too! Try it yourself, if you do not believe it!
At the end of our example code we test a simple kind of a 2 step inheritance pattern. The statement “DOChild.prototype = new DO();” leads to the fact that the internal structure displayed for “DOChild()” is exactly the same (and wrong) one as displayed above for DO itself.

Also there the variable “s” and functions as “hilfe()” etc. appear – which we know is wrong. But now we are a step further down in the prototype chain! So, it is even more misleading to display the elements in question in the Outline View for the Child constructor!
But it would be more dangerous if the code completion dialog of JSjet offered functions as “hilfe()” as valid elements of objects created with the DOChild() constructor! No object created with the help of the DOChild constructor (and its prototype) would know anything about these properties/functions! If we put “CH.hilfe();” as the first statement in line 59, we would get:
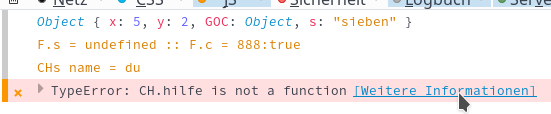
So, what happens in the code completion dialog? Actually, and somewhat surprisingly:
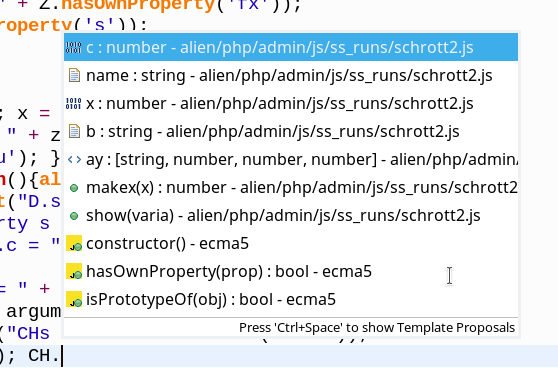
Good news! We do not see anything wrong! The information in the code completion dialog about available elements of a child object following a standard inheritance pattern is totally correct! This makes the appearance of the critical functions in the Outline View as elements of the constructor function DOChild() (or its prototype) even more mysterious!
OK, but what about the information transport across a prototypal inheritance pattern? To be able to test this we had created an object “B” based on Ufo in line 25. We equipped B with an added method “b()“. Now, e.g. LL is based on K() which uses U as a prototype. But not B! So, we should not see b() as a valid function offered for LL in the code completion. We are optimistic! However:
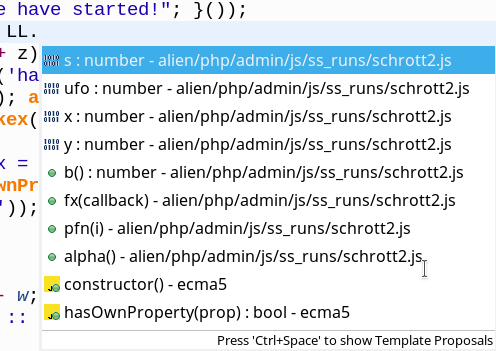
What a mess ! A method added to particular object derived from a parent class appears in the list of functions offered by JSjet’s code completion as valid members of a Child object created by the constructor of a prototypal chain based on another object. Not good !
Eventually, we may also remark that the results of the code analysis reflected in the Outline View depend a bit on the order of statements. I recommend to play a bit yourself with similar test codes and the order of statements before buying a license.
The amount of information given by JSjet/Tern in the Outliner is significantly bigger and contains more structural elements and type hints than the information provided by today’s JSDT. However, the depth and quality of the code and object structure analysis is limited – and some information is actually misleading.
In my opinion the most critical point is the fact that properties/functions added or supplemented to specific objects are gathered and displayed as if they were elements of the objects’ constructor function, its prototype or the objects’ basic class (if you used the ES6 class syntax) – i.e. as elements of the elementary constructor/prototype from which the particular objects were
derived.
This way of gathering and associating added variables and functions of specific objects can even affect the structural information about CHILD constructor functions defined in simple inheritance pattern: The Outline View displays all variables/functions added incoherently to various specific objects derived from a PARENT Constructor as valid elements of the CHILD constructor function (or its prototype).
The wrong association of new and object specific variables/functions with the basic constructor/prototype of these objects is unfortunately also transferred to the code completion support. This, already, may lead to coding mistakes! But, even worse: The information about the wrong association is transferred across a prototypal inheritance chain: Functions added only to specific objects, which are different from an object “U” but based on the same constructor as “U”, will appear in the code completion dialog for any Child object created with the help of a new constructor K() that used “U” (!) directly as its prototype.
I regard this as a really negative aspect of the JSjet/Tern toolset – which may even lead to coding errors!
However – and really surprisingly – as long as we follow a standard inheritance pattern for a Child constructor function the code completion dialog does NOT offer any critical undefined variables or functions. In contrast to the information provided in the Outline View! And in contrast to a prototypal approach.
What I would have expected of JSjet in any case is to display object specific elements below the respective objects in the Outline View and not below their classes/constructors. In addition: Such specific properties/functions of a particular object should only appear in a derived CHILD constructor function when and if this constructor function uses the particular object explicitly as its (i.e. the function’s) prototype.
I must say that the findings described above frustrated and depressed me a bit. However, you can still use the information in the JSjet Outline VIEW for navigation purposes. But you should be extremely careful with its interpretation and the use of the code completion!
And you should program cautiously and very conservatively!
I am a person who is very concerned about digital data privacy. So, beyond technical aspects I thought it would be interesting to investigate a bit whether and what data a licensed JSjet installation may gather about you or your interaction with Eclipse. See my next blog post for this topic:
Webclipse JSjet, Eclipse Neon 2 and the Outline View – what I like and what not – part III