Datenbank-Replikationen sind nützlich und können in vielen Anwendungen einen Gleichstand von Daten über System- und Netzgrenzen hinweg ermöglichen. Es ist relativ einfach, eine Master-Slave-Replikation mit MariaDB oder MySQL zu implementieren. Ich verwende solche Replikationen inzwischen häufig, um Ergebnisdaten komplexer Berechnungen zwischen RDBMS-Serversystemen zu übertragen.
Je nachdem, wie groß
- die Übertragungsrate des Netzwerkes zwischen den RDBMS-Servern ist,
- wie groß die Transfergeschwindigkeit zum Storage-Sub-System auf jedem der Server ist
- und wie die Parametrierung der Replikation erfolgt
kann man dabei Überraschungen mit den “CatchUp“-Zeiten erleben. Unter der CatchUp-Zeit verstehe ich hier die Zeit, die das Slave-System hinter dem Status seines Master-Systems hinterherhinkt.
Relevant werden diese Zeiten natürlich vor allem dann, wenn auf dem Master über einen längeren Zeitraum hinweg die Änderungsrate durch INSERTs und UPDATEs kontinuierlich hoch bleibt. Sprich: Wenn das RDBMS des Masters richtig unter Last steht und neben den eigentlichen SQL-Statements permanent Log-Einträge zum Slave-System geschaufelt werden müssen.
In einem Lastszenario mit Perioden dauerhafter Last muss man natürlich auch an die Fähigkeit zur Restaurierung des gesamten RDBMS-Verbundes denken. Dass man regelmäßige Backups braucht, ist sowieso klar. Es stellt sich aber auch die Frage, wie man die Replikation nach Crashes eines der beteiligten Systeme wieder aufsetzen kann.
Folgt man dem Standardwerk “High Performance MySQL” von Schwartz, Zaitsev, Tkachenko (O’Reilly Verlag, 3rd Ed.), so erhält man den Eindruck, dass man vor Crashes gehörigen Respekt haben sollte. Die Autoren empfehlen deshalb in mehreren Abschnitten (sehr von Vorsicht geprägte) Einstellungen zur Synchronisation von “Binary Log Files” und “Information Log Files” mit den Storage-Systemen – sowohl auf dem Master- wie auch auf dem Slave-System.
Es ist grundsätzlich interessant, sich das mal anzusehen. Ferner gilt: Replizierende Systeme haben nicht immer ein identisches Leistungsvermögen. Wie wirken sich SYNC-Einstellungen dann auf CatchUp-Zeiten aus? Bei einem Kunden ergab sich vor einiger Zeit zudem die Frage, wie es eigentlich mit einer “Master/Slave-Master/Slave”-Replikation aussieht. Gemeint waren hier gegenseitige Replikationen mit vertauschten Master/Slave-Rollen für zwei unterschiedliche Datenbanken; beide RDBMS-Systeme spielen dabei sowohl Master als auch Slave, nur eben für verschiedene Datenbanken (Schemata).
Zeit, mal einen Blick auf das grundsätzliche Replikationsverhalten für 2 Server in unserem LAN zu werfen. Im vorliegenden Artikel bespreche ich, wie man eine einfache Master/Slave-Replikation aufsetzt. Der Text ist also auch für Leute gedacht, die MySQL/MariaDB zwar nutzen, sich dem Thema Replikation aber noch nie genähert haben. Die angegebenen Kommandos sind einfach nachzustellen. Ein zweiter Artikel greift dann die komplexere “Master/Slave-Master/Slave”-Konstellation auf.
Eigentliches Ziel beider Artikel ist es aber, herauszuarbeiten, ob und wie man ggf. an SYNC-Einstellungen drehen kann, um die CatchUp-Zeit möglichst gering zu halten.
Die nachfolgende Skizze zeigt den Testaufbau schematisch:
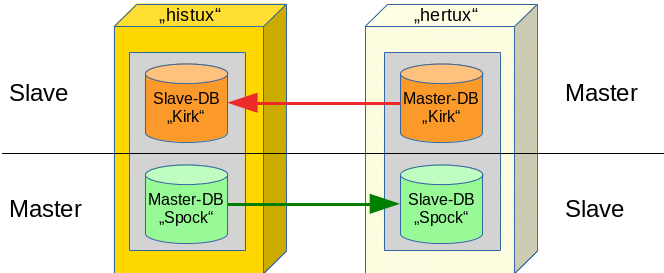
Wir haben zwei RDBMS-Serversysteme “histux” und “hertux“. Wir betrachten nachfolgend zunächst nur den oberen Teil der Skizze – also ein reines Master/Slave-Szenario bzgl. der
Datenbank “Kirk”. “hertux” fungiert dabei als Master, “histux” als Slave.
Im zweiten Artikel dieser Serie ergänzen wir dann das Master/Slave-Szenario mit umgekehrtem Vorzeichen für eine weitere Datenbank “Spock” (unterer Teil der Skizze). “histux” wird dann für die Datenbank “Spock” die Rolle des Masters übernehmen, “hertux” die des Slaves. Es entsteht so das dargestellte “Master/Slave – Master/Slave” Szenario. Beide Server spielen darin gleichzeitig sowohl Master, als auch Slave für jeweils eine der Datenbanken [DBen].
Ich verwende in meinem Setup übrigens Systeme mit einer MariaDB – und nicht mit einem originalen MySQL-RDBMS. In meinem Fall ist das “histux”-System etwas schwächer ausgelegt als das “hertux”-System; das betrifft den Prozessor, aber auch das Storage-System (einfache HD vs. einfache SSD; für Tests mit schnellen SSD-Raid-Verbänden hatte ich noch keine Zeit …).
Ich betrachte nachfolgend nur InnoDB-Tabellen, deren Änderungen (Inserts) mit einer sog. row-basierten Replikation (s.u.) auf die jeweiligen Slave-Server übertragen werden sollen. Um der Replikation eine Chance zu geben, werden die Änderungen (Inserts) durch echte Einzelstatements für jeden Record erzeugt. Inserts, Updates für mehrere Datensätze werden also nicht in einem SQL-Statement gebündelt.
Die DB “Kirk” existiere zunächst als einzige DB in den RDBMS der Server “histux” und “hertux“. Die notwendigen Konfigurationsstatements für die RDBMS-Replikation sind dann recht einfach; wir tragen folgende Zeilen in die Datei “/etc/my.cnf” des Master-Systems “hertux” ein:
# Binary Log file / Log Method
log_bin=/var/lib/mysql/mysql-bin
binlog_format=row
# binlog_format=mixed
# Syn des Logfiles auf die Platte
sync_binlog=1
#ID des Servers
server-id=2
Wir gehen kurz die drei Einstellungsgruppen durch:
Binary-Log-File und Log- bzw. Replikations-Verfahren
Transaktionen auf einem System werden in sog. “Binary Log”-Dateien protokolliert. Die ersten zwei Statements legen fest, wo das Binary-Log-File gelagert wird und welches Format des Loggings verwendet wird:
Eine Replikation kann (SQL-) statement-bezogen oder row-bezogen durchgeführt werden.
Im ersteren Fall werden SQL-Statements vom Master auf den Slave übertragen und dort nachgefahren. Im zweiten Fall werden Daten-Änderungen betroffener Tabellen-Rows übertragen. Je nach Art von (komplexen) SQL-Statements kann das Nachfahren solcher Statements auf dem Slave deutlich aufwändiger sein, als die Änderungen der betroffenen Datensätze selbst nachzuziehen. Andererseits gilt evtl. genau das Umgekehrte für Massenänderungen über viele Rows hinweg. Man sollte die Art des Loggings also an der Charakteristik seiner SQL-Anwendungen ausrichten. Das gilt im Grunde aber auch für den Einsatz von MyISAM vs. InnoDB-Tabllen. Im Kontext von InnoDB-Tabellen und Anwendungen mit Einzeländerungen verwende ich selbst oft eine row-basierte Replikation. Stehen dagegen Massenänderungen vieler numerischer Daten im Fokus einer Anwendung weiche ich oft auf MyISAM-Tabellen und statement-basierte Replikation aus. Pauschalisieren lässt sich das aber nicht.
Synchronisation mit dem Storage-Subsystem
Das Statement “sync_binlog=1” legt fest, dass das Binary Log File mit dem Storage-Systems des Servers (z.B. einer lokalen Harddisk) nach jedem Commit synchronisiert werden soll. Das sichert gegenüber Datenverlust während Systemcrashes ab; aber eine solche Synchronisation ist eine durchaus aufwändige Operation, die die Performance bei vielen Änderungen pro Sekunde
beeinträchtigen kann. In kleineren Firmen sind hier batteriegepufferte Caches von Raid-Controllern ggf. ein Ausweg.
Server-ID
Sind in einem Netzwerkverbund mehrere Server vorhanden, so sollte jedes RDBMS mit einer netzwerkweit eindeutigen Server-ID versehen werden. Die Festlegung einer eindeutigen ID der MySQL/MariaDB-RDBMS ist notwendig, um sog. “Globale Transaktions IDs” [GTIDs] zu unterstützen. In die Transaktions-IDs geht u.a. die eindeutige ID eines Servers mit ein.
Ich weise daraufhin, dass Format/Implementierung von GTIDs einer MariaDB (> Version 10.0.3) anders aussehen als bei einer herkömmlichen MySQL-Datenbank. Siehe hierzu:
https://mariadb.com/kb/en/library/gtid/#setting-up-a-new-slave-server-with-global-transaction-id.
Mit der bisherigen Einstellung werden Änderungen aller Datenbanken [DBen] des MariaDB RDBMS “hertux” im “Binary Log File” des Masters aufgezeichnet. Wir werden das im nächsten Artikel durch einen einfachen Filter für DBen abändern.
Alle anderen Einstellungen (u.a. bzgl. der IO-capacity und Anzahl IO Threads für InnoDB, ..) bleiben in meinem Test auf Standardwerten.
Die “/etc/my.cnf” des Slave-Systems “histux” sieht etwas erwartungsgemäß anders aus:
# Binary Log file / Log Method
log_bin=/var/lib/mysql/mysql-bin
# binlog_format=mixed
binlog_format=row
# Relay Log File, automat. Starten der Replikation?
relay_log=/var/lib/mysql/relay-bin
skip_slave_start
# Log der Updates
log_slave_updates=1
# Threads
slave-parallel-threads=4
#ID des Servers
server-id=3
# read-only=1
Hinweise zu den Einstellungen:
Relay-Log-File
Auf dem Slave ist die Festlegung des Relay-Log-Files erforderlich. Hierhin werden die durchzuführenden Transaktionen des Masters übertragen; in unserem einfachen Fall, in dem keine Änderungen auf dem Slave durchgeführt werden, ergibt sich letztlich eine Kopie des Binary-Logs des Masters.
Kein automatischer Start der Replikation
Wir schalten über “skip_slave_start” ein automatisches Starten der Replikation nach dem Starten des RDBMS ab. Das ist für Testsituationen OK; auf Produktiv-Systemen mag der Bedarf anders sein. Die Replikation lässt sich manuell immer zu einem geeigneten Zeitpunkt starten. Z.B., wenn man sicher ist, dass der Master auch aktionsbereit ist; s.u.. Über weitere Parameter (s. die MariaDB-Dokumentation) kann man steuern, wie oft und in welchem zeitlichen Abstand der Slave einen Verbindungsversuch zum Master unternehmen soll.)
Eintrag der Slave-Aktionen im eigenen Binary-Log?
“log_slave_updates=1” sorgt dafür, dass die Replikationstransaktionen im eigenen Binary Log des Slaves vermerkt werden. (Das kann wichtig sein, wenn der Slave selbst wieder Master gegenüber dritten Systemen spielen soll).
Mehrere Threads zum Nachfahren der übermittelten Änderungen
Wir stellen zudem mehrere Threads zur Verfügung, um die einlaufenden row-basierten Änderungen ggf. parallel in die Bank zu übertragen Dies betrifft ausschließlich die SQL-Ebene; s. https://mariadb.com/kb/en/library/parallel-replication/. Welche Anzahl von Threads sinnvoll ist, hängt von der Änderungsrate auf dem Master UND der Leistungsfähigkeit des Slave-Systems ab. Man muss testen, bis zu welcher Thread-Anzahl sich noch eine Performanceverbesserung ergibt.
Auf dem
Slave “histux” könnte die Nutzung global auch auf “read-only” gesetzt werden, wenn die Datenbankinhalte wirklich nur replizierte Inhalte beinhalten sollen. In unserem Fall ist dies wenig sinnvoll, da “histux” ja später Master für die zusätzliche DB “Spock” werden soll. Das entsprechende Statement wurde daher auskommentiert.
Auf dem Master müssen wir einem Datenbank-User (hier: “repl”) Replikationsrechte einräumen; das zugehörige SQL-Statement, das wir nach Einloggen in das Master-RDBMS am MySQL-Prompt absetzen, ist:
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO repl@’192.168.0.%’ IDENTIFIED BY ‘MyReplPasswd’;
“repl” ist ein in priviligierter Account, der alle transaktionalen Änderungen auf dem RDBMS einsehen kann. Auch, wenn dieser Account an Datenbankeinträgen nicht direkt etwas ändern kann, können sich aus seinen Rechten dennoch sekundäre Sicherheitsprobleme ergeben. Also: Vorsicht! Der gleiche User sollte natürlich auch auf dem Slave angelegt werden.
Nun führen wir auf dem Master-Server und seiner/n Tabelle/n einen Schwung von SQL-Statements aus. Ich benutze dazu immer PHP-Test-Files, die hunderttausende von Inserts vornehmen.
Wir prüfen dann auf dem Master Server den Status und damit gleichzeitig den genauen Namen des Binary-Log-Files ab:
MariaDB [Kirk]> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000007 | 16601394 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
Man sieht hier, dass auf dem Master schon Einiges passiert ist.
Wir starten nun unsere erste Replikation. Wir melden uns dazu als Datenbank-User “root” am Slave RDBMS von “histux” an (“mysql -u root -p”). Am MySQL-Prompt geben wir ein:
MariaDB [Kirk]> CHANGE MASTER TO MASTER_HOST='hertux.mynet.de', MASTER_USER='repl', MASTER_PASSWORD='MyReplPasswd', MASTER_LOG_FILE='mysql-bin.000007;
MariaDB [Kirk]> CHANGE MASTER TO master_use_gtid=slave_pos;
MariaDB [Kirk]> START SLAVE;
Das erste Statement definiert den Master und seine Eigenschaften (dauerhaft) für das Slave-System! das zweite Statement setzt den Ausgangspunkt der Replikation auf die richtige Position im Binary File. Das ist im vorliegenden Fall natürlich die 0-Position. Das angegebene Statement
CHANGE MASTER TO master_use_gtid=slave_pos;
lässt sich im regulären Betrieb nach einem evtl. erfolgten Restart des Slaves oder einem Stop und Neustart der Replikation aber immer wieder einsetzen: Die Replikation soll ab der Position im Log-File ansetzen, zu der der Slave bislang gekommen war.
Die Master-Log-Files ändern im Lauf des Betriebs ihre Bezeichnung. Wir müssen uns im weiteren Normalbetrieb allerdings nicht mehr um die Angabe des richtigen Master-Log-Files kümmern. Der Slave erkennt dies in der Regel über GTIDs automatisch. Im Gegensatz zu früheren MariaDB-Varianten, in denen GTIDs nicht automatisch benutzt wurden, muss man sich nun im Normalbetrieb also keine Gedanken mehr zu Byte-bezogenen Positionen im binären Master-Log machen. Das Statement “CHANGE MASTER TO master_use_gtid=slave_pos;” sorgt dafür, dass der richtige Aufsetzpunkt für die Replikation im Verhältnis zum Status des Slaves gefunden wird.
Man kann den
Ablauf der Replikation auf dem Slave nun mit
MariaDB [Kirk]> SHOW SLAVE STATUS\G
verfolgen. Am Schluss des Nachfahrens aller bisherigen Einträge in unsere Test-DB “Kirk” erhält man dann etwas in der Art :
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: hertux.mynet.de
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000007
Read_Master_Log_Pos: 16601394
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 16601681
Relay_Master_Log_File: mysql-bin.000007
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 16601394
Relay_Log_Space: 16601972
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-2-311024
1 row in set (0.00 sec)
Wer mag kann den korrekten Tabellenstatus ja mit PhpMyAdmin kontrollieren. Nebenbei: Es lohnt sich, bei Gelegenheit die Features von PhpMyAdmin für Replikationseinstellungen und die Einsichtnahme in zugehörige Parameter des RDBMS zu studieren.
Interessant ist der Unterschied zwischen der GTID-Position und der Byte-Position:
Gtid_IO_Pos: 0-2-311024
Exec_Master_Log_Pos: 16601394
Verschiedene Infos; gleiche Positionierung in den Binary-Logs!
Die aktuellen Positionen lassen sich auf Master und Slave übrigens jederzeit wie folgt abfragen:
Master
MariaDB [massa]> SELECT @@GLOBAL.gtid_binlog_pos;
+--------------------------+
| @@GLOBAL.gtid_binlog_pos |
+--------------------------+
| 0-2-331028 |
+--------------------------+
1 row in set (0.00 sec)
<strong>Slave</strong>
MariaDB [massa]> SELECT @@GLOBAL.gtid_slave_pos;
+-------------------------+
| @@GLOBAL.gtid_slave_pos |
+-------------------------+
| 0-2-331028 |
+-------------------------+
1 row in set (0.00 sec)
Für meinen Test zur CatchUP-Zeit verwende ich ein Skript, das fortlaufende Inserts in einer InnoDB-Tabelle vornimmt – und zwar Record/Row für Record/Row – inkl. paralleler Indexgenerierung. Ohne Prepared Statements. Es werden dabei mehrere Stringfelder eines neuen Datensatzes gefüllt.
Ich begrenze die Anzahl auf 10000 Inserts. Die Zeitdauer für meine Inserts beträgt 80 Sek..
Die Rate ist also nicht besonders hoch; das liegt u.a. an einer parallel stattfindenden Index-
Generierung und fehlender Optimierung. Die Insert-Rate lässt sich viel höher schrauben; allein eine Bündelung von Inserts in einem Statement und/oder die Nutzung von “prepared statements” würde Faktoren an Geschwindigkeit bringen. Aber es geht mir hier nicht um Optimierung; es kommt mir nur auf relative Anteile der CatchUp-Zeiten an.
Welche CatchUp-Zeit zieht eine solche Insert-Folge während der 80 Sekunden Laufzeit nach sich?
Wir greifen hierzu – während das Testprogramm mit den Inserts läuft – den Slave-Status am Slave ab:
MariaDB [massa]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: histux.mynet.de
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 1878830
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 1879117
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1878830
Relay_Log_Space: 1879408
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-2-332342
1 row in set (0.00 sec)
Relevant ist die Zeile:
Seconds_Behind_Master: 0
Wunderbar! Offenbar kann der Slave unter den herrschenden Bedingungen [LAN, keine SYNC-Prozesse] locker mithalten – obwohl er schwächer ausgelegt ist als der Master!
Auf den Master hat der Datenaustausch für die Replikation übrigens kaum Auswirkungen: Die benötigte Gesamtzeit steigt dort von etwa 80 Sekunden auf 84 Sekunden an.
Wir verändern die Einstellung des Slave-RDBMS bzgl. der Synchronisation von dortigen Log-Files zum Storage-System. Es gibt mehrere Dateien, die im Replikationsvorgang auf dem Slave-System fortgeschrieben werden (Relay-Log=> nachzufahrende Transaktionen / master.info-File: Infos über die Position des Masters / Relay_log.info-File => eigene Position im Relay-Log.) Wir folgen zunächst 1:1 den Empfehlungen des Buchs “High Performance MySQL”:
#sync_binlog=1
sync_master_info=1
sync_relay_log=1
sync_relay_log_info=1
Damit starten wir das MariaDB-RDBMS auf dem Slave-Server “histux” neu und loggen uns wieder mittels “mysql -u root -p” in das RDBMS ein. Am MySQL-Prompt verfolgen wir dann einen neuen Testlauf und fragen sukzessive den Slave-Status ab. Es zeigte für meine Systeme leider, dass die CatchUp-Zeit relativ zum Master-Status nun permanent und systematisch zunahm!:
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Queueing master event to the relay log
Master_Host: histux.mynet.de
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 6766074
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 5466
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5318184
Relay_Log_Space: 1453647
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 131
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-2-361783
1 row in set (0.12 sec)
Am Schluss erhielt ich als maximale Differenz:
Seconds_Behind_Master: 158 (Sekunden)
Es sieht also so aus, dass eine Synchronisation von Relay-Log-Dateien auf dem Slave sehr problematische Folgen haben kann: Immerhin ist der Zeitverlust gegenüber dem Master auf fast das Doppelte der für die DB-Transaktionen benötigten Zeit angewachsen!
In anderen Tests mit über 100000 Inserts wuchs der Zeitverlust weiter extrem an – auf über 3 Stunden!
Kann man das obige verheerende Ergebnis irgendwie beseitigen? Ein wenig Experimentierfreude zeigt schnell, dass eine Änderung der Parameter auf
log_slave_updates=0
sync_master_info=0
sync_relay_log=1
sync_relay_log_info=0
leider gar nichts bringt. Der systematisch größer werdenden Abstand zwischen Slave und Master legt den Schluss nahe, dass der Slave vor lauter SYNC-Prozessen gar nicht dazu kommt, seine SQL-Arbeit im RDBMS durchzuführen. Daten müssen über Netz vom Master geholt werden, Informationen über die Positionen des Masters und des Slaves auf dem Slave in Dateien geschrieben werden. Jede Datenbank-Transaktion am Slave führt dann zu zusätzlichen SYNC-Vorgängen, die unabhängig von den anwachsenden Master-Transaktionen durchzuführen sind. Zudem werden die Files bei einmal wachsender CatchUp-Zeit automatisch immer größer! Das riecht förmlich danach, dass unser Slave bei hoher Taktung der Änderungen auf dem Master in einen Teufelskreis gerät …
Wenn dies Theorie stimmt, dann sollten wir den Datenbanktransaktionen mehr Zeit gegenüber Synchronisationsprozessen einräumen. Die “1” als Parameter bei den 3 Slave-SYNC-Einstellungen bedeutet ja nicht ein Einschalten im Sinne eines boolschen Flags. Vielmehr kann hier ein numerischer Parameter angegeben werden: Er legt fest, nach wieviel Änderungen das jeweilige File auf dem jeweiligen Status
auf die Platten geschrieben werden soll. Wir sollten also versuchen, die SYNC-Parameterwerte zu erhöhen.
Tatsächlich ergibt sich bei einer Einstellung
relay_log=/var/lib/mysql/relay-bin
skip_slave_start
log_slave_updates=1
slave-parallel-threads=4
sync_master_info=4
sync_relay_log=4
sync_relay_log_info=4
das Ergebnis :
sync_relay_log=4, sync_master_info=4, sync_relay_log_info=4 => CatchUp-Zeit: 0 Sekunden
Geht man mit den sync-Parametern danach weiter runter, so erhalten wir wieder ein Anwachsen des Delays, wenn auch moderater als beim Wert “1”:
sync_master_info=2
sync_relay_log=2
sync_relay_log_info=2
sync_relay_log=4 => CatchUp-Zeit: 54 Sekunden
Bei einem Wert von “3”:
sync_relay_log=3 => CatchUp-Zeit: 3 Sekunden => 0 Sekunden
Wir können parallel auch mal die Anzahl der Slave-Threads erhöhen. So ergibt
slave-parallel-threads=10
sync_master_info=2
sync_relay_log=2
sync_relay_log_info=2
sync_relay_log=2 / slave-parallel-threads=10 => CatchUp-Zeit: max. 3 Sekunden => 0 Sekunden
Schon in einer normalen Master-Slave-Replikation gilt: Durch Synchronisation von Replikations-Log-Files mit dem HD- oder SSD-System auf dem Slave kann sich die CatchUp-Zeit systematisch erhöhen,
- der Takt der Änderungen auf dem Master konstant hoch ist
- wenn die Frequenz der SYNC-Prozesse zu hoch gewählt wird,
- und eine row-basierte Replikation für InnoDB-Tabellen konfiguriert wurde.
Im vorliegenden Fall erwies sich die Vorgabe, nach jeder Änderung alle Log-Files direkt auf die Platte zu schreiben einfach als zu ambitiös: Das Slave-System ist mehr mit SYNC-Prozessen beschäftigt als mit der eigentlichen Durchführung der Änderungen in der Datenbank. Gerät das System erst einmal außer Takt, wächst die CatchUp-Zeit des Slaves gegenüber dem Master bei einer kontinuierlichen Last kontinuierlich an. Relevant ist das vor allem für gekoppelte Systeme, die permanente Änderungsprozesse hoher Frequenz verkraften müssen.
Für replizierende MariaDB-Systeme ist es deshalb wichtig zu testen, ob nicht mehrere Änderungen (Commits) in der Bank abgewartet werden sollten, bevor ein Schreiben der Binary-Log- und Info-Files auf das Storage-System erfolgen soll. U.U. genügt hier schon die Wahl eines nur etwas erhöhten Wertes
sync_master_info=3 (oder 4)
sync_relay_log=3 (oder 4)
sync_relay_log_info=3 (oder 4)
um schon eine signifikante Verbesserung zu erreichen. Die Arbeit, nach einem Crash des Slaves, den richtigen Aufsetzpunkt für die Replikation zu finden, hält sich dann immer noch in relativ engen Grenzen.
Im kommenden Artikel betrachten wir die Parametrierung und die gleiche Situation für eine “Master/Slave – Master/Slave”-Konfiguration.
https://mariadb.com/kb/en/library/setting-up-replication/