
Vor wenigen Wochen lief bei Opensuse und bei Ubuntu der Supportzeitraum für die jeweils vorletzten Versionen ab. Ein Leser des Blogs hat mich angeschrieben und gebeten, mal für einen Linux-Einsteiger zu beschreiben, wie ich denn bei System-Upgrades “immer wieder auftauchenden Problemen aus dem Weg” ginge.
Erste spontane Antwort: Gar nicht 🙂 ; Probleme tauchen halt auf und sind zu lösen oder zu umgehen. Ich habe die Frage dann aber mal wie folgt interpretiert:
Wie erhält man sich trotz möglicher Upgrade-Probleme die Fähigkeit zum beruflich dringend erforderlichen Weiterarbeiten, wenn es nach dem Upgrade Probleme gibt?
Das ist durchaus ein paar Betrachtungen wert. Gerade Freiberufler können sich Arbeitsausfälle aufgrund “zerschossener” Systeme nicht leisten. Das betrifft bei mobilen Beratern u.a. Laptop-Installationen.
Beim Schreiben fiel mir allerdings auf, dass ich vor Upgrades/Updates alleinstehender Linux-Systeme zu Methoden greife, in die sich ein “Einsteiger” erst mal einarbeiten muss und die selbst auch ein gewisses Gefahrenpotential in sich bergen. Leute, das kann ich euch leider nicht ersparen. Deshalb vorweg:
Bitte seid bei einer Nachahmung der nachfolgenden Vorschläge extrem vorsichtig, macht Backups und testet erstmal in einer risikofreien Umgebung – im Besonderen das Kopieren von Festplatten-Partitionen. Ich hafte nicht bei Schäden.
Ferner benötigt man für meinen Ansatz HDs/SSDs mit 500GB aufwärts; man braucht Plattenplatz. Dennoch hat sich die nachfolgend beschriebene Methodik bewährt; sie hat mir schon des öfteren wertvolle Zeit für Problemlösungen verschafft. Die Vorgehensweise hat aber nur einen Sinn auf Einzelplatz-Systemen; sie ist nicht (!) für Server oder Firmen-Installationen geeignet. Und: Sie ersetzt keineswegs (regelmäßige) Backups auf externe Medien!
Frust nach und mit Upgrades/Updates unter Linux? Ja, das gibt es …
Viele Linux-Einsteiger beschreiben ein gar nicht so seltenes Erlebnis mit ihrem Desktop- oder Laptop-System so: “Dann hab’ ich mein Linux upgedated bzw. upgegradet und dabei wohl was falsch gemacht – und mir das System zerschossen. Musste neu installieren.“. (Siehe u.a. Linux-Foren unter Facebook). Das sollte eigentlich unter Linux nicht so ablaufen … passiert aber dennoch.
Ein Grund ist vermutlich: Für Einsteiger ist schwer zu erkennen, was mögliche Ursachen für das “Zerschießen” sind und wo bzw. wie man die richtigen Maßnahmen zur Korrektur einleitet. Der Wunsch, möglichst schnell wieder arbeiten zu können, führt dann gerade bei Windows-Umsteigern fast reflexartig zu Neuinstallationen.
Was manchmal schon im Zuge komplexer Packet-Updates passiert, gilt erst recht für Linux-System-Upgrades, bei denen womöglich auch noch an Grundfesten des Systems gerüttelt wird (wie etwa bei der Einführung von systemd, neuen KDE-Haupt-Versionrn, etc…). Spätestens nach der ersten schlechten Erfahrung mit einem System-Upgrade stellt man sich beim nächsten Mal Fragen:
Soll ich (nach einer Datensicherung) die neue Linux-Version auf einer neuen oder der bisherigen System-Partition ganz von Null neu installieren? Oder die alte Installation durch komplizierte Schritte auf die neue Version bringen? Mit dem Risiko, dass dabei etwas schiefgeht, das System nicht mehr bootet, man sich nicht mehr einloggen kann oder die graphische Oberfläche nicht mehr läuft? Und man nicht mehr produktiv arbeiten kann?
Das sind alles berechtigte Fragen! Frustrierende Erlebnisse mit System-Komponenten, die nach Updates/Upgrades nicht mehr erwartungsgemäß funktionieren, haben nämlich auch erfahrene Linux-User immer wieder. Glaubt keinem, der etwas anderes behauptet!
Auch unter Linux gilt: Shit happens! Und oft genug liegt die Schuld nicht mal bei einem selbst … Linux
ist halt ein komplexes Konglomerat aus unterschiedlichen Komponenten, die von unterschiedlichen Teams entwickelt werden. Die Zusammenstellung übernehmen Distributoren, die auch nicht jede mögliche Installationsvariante testen können. Hinzu kommen ggf. problematische Treiber, u.a. für Grakas. Ergebnis: Fehler treten häufiger auf, als einem als Linux-Fan lieb wäre ….
Vorsorge und Arbeits-“Continuity”
Erfahrene Linux-Nutzer sorgen vor, indem sie eine funktionierende Arbeitsumgebung vorhalten. Komplette Neuinstallationen sind bei Update-Problemen nur selten der richtige Weg: erstens lernt man durch Neuinstallationen nichts und zweitens besteht die Gefahr, wieder in die gleiche Falle zu tappen. Im Falle von System-Upgrades führt eine Neuinstallation dagegen zum mühsamen Nachziehen von bereits getroffenen Konfigurationsentscheidungen – und ohne Rückgriff auf eine noch funktionierende Installation ist das Arbeiten in dieser Phase ggf. eingeschränkt.
Natürlich denkt man vor Updates/Upgrades an Backups der vorhandenen funktionstüchtigen Installation auf externe Medien. Das setzt voraus, dass man sich mit der Restaurierung ganzer Betriebssysteme und den zugehörigen Linux-Tools befasst. Zu dieser wichtigen Grundübung findet man viele hilfreiche Artikel im Internet. Ich möchte in diesem Artikel aber eine andere, zusätzliche Maßnahme besprechen – und zwar den den Ansatz einer
vorsorgenden Partitionierung – unter Einschluss jederzeit bootbarer “Fallback- und Experimental-Partitionen”.
Das ersetzt (regelmäßige) Backups (u.a. für den Fall vom Plattendefekten) keineswegs, erleichtert aber den Umgang mit komplexen Updates oder System-Upgrades.
Motivation ist die Aufrechterhaltung der Möglichkeit zum schnellen Fortsetzen der produktiven Arbeitfür den Fall, dass beim Updaten/Upgraden etwas schief geht. Man spricht auch von ArbeitsKontinuität oder neudeutsch “Continuity“, die eben die Verfügbarkeit funktionierender Installationen voraussetzt.
Nun höre ich schon die Profis fragen: Schon mal was von Snapshots gehört? Ja, aber der von mir beschriebene Ansatz ist auch dann wirkungsvoll, wenn man sich mit Snapshot-Systemen (wie etwa auf Basis von BtrFS oder LVM2) noch nicht auskennt. Zudem sind Filesystem-Snapshots bei vollständigen System-Upgrades eher in Frage zu stellen.
Voraussetzungen und Zielgruppe
Der Artikel richtet sich an Linux-Ein/Um-Steiger, die schon ein paar Schritte mit dem System gegangen sind und sich bereits ein wenig in Plattenpartitionierung wie den Systemstart über Boot-Manager eingearbeitet haben – oder willens sind, das zu tun. So setze ich voraus,
- dass man weiß, was Partitionen (oder ggf. LVM-Volumes) und Filesysteme sind, wie man die mit entsprechenden Tools seiner Linux-Distribution oder auf der Kommandozeile erstellt, dimensioniert und in den Hauptverzeichnisbaum einhängt (mounted),
- dass man bereit ist, sich mit den Befehlen “dd”, “uuidgen” und “tune2fs” auseinanderzusetzen
- dass man keine Scheu hat, System-Dateien zu editieren.
- dass man bereit ist, sich ein wenig um Grub2 als Boot-Manager auseinanderzusetzen.
- dass genügend Festplattenplatz vorhanden ist, um 3 Betriebssystem-Partitionen mit einer Größe von etwa 40 bis 80 GByte aufzunehmen.
Der letzte Punkt mag dem einen oder anderen als Platzverschwendung erscheinen. Ja, das erscheint mir aber in der Abwägung gegenüber dem Punkt “kontinuierliche Arbeitsfähigkeit” und auch gegenüber der Schonung von Nerven zweitrangig.
Übrigens: Bis auf spezielle EFI- und Swap-Partitionen, verwende ich den Begriff “Partition” nachfolgend auch synonym für logische LVM2-Volumes. Das ist technisch natürlich nicht korrekt; der Unterschied tut
hier aber nichts zur Sache. LVM2 ist im besonderen mit dem Grub2-Boot-Manager kompatibel. Wem die Begriffe LVM2 und LVM-Volume nichts sagen, kann deren weitere Erwähnung in Klammern erstmal getrost ignorieren.
Ich erläutere die hier verfolgte Philosophie einer Fallback-Partition für Desktop-Systeme und Laptops anhand von Opensuse. Die Grundprinzipien lassen sich meist aber einfach auf andere Distributionen wie etwa Ubuntu abbilden – auch wenn sich ein paar Bezeichnungen von Dateien oder Programmen leicht unterscheiden. Es geht mir auch nur um alleinstehende Desktop-/Laptop-Systeme, auf denen man weitgehend der Herr des Geschehens ist – nicht aber um Server-Systeme oder server-basierte Installationen; letztere erfordern andere Fallback- und Continuity-Strategien.
Vier Maxime für den Umgang mit Updates/Upgrades
Beim Umgang mit kritischen Updates von Systemkomponenten oder gar Upgrades des Betriebssystems orientiere ich mich an folgenden Leitlinien:
- Never touch a running system – ohne die Konsequenzen zu kennen oder solide einschätzen zu können.
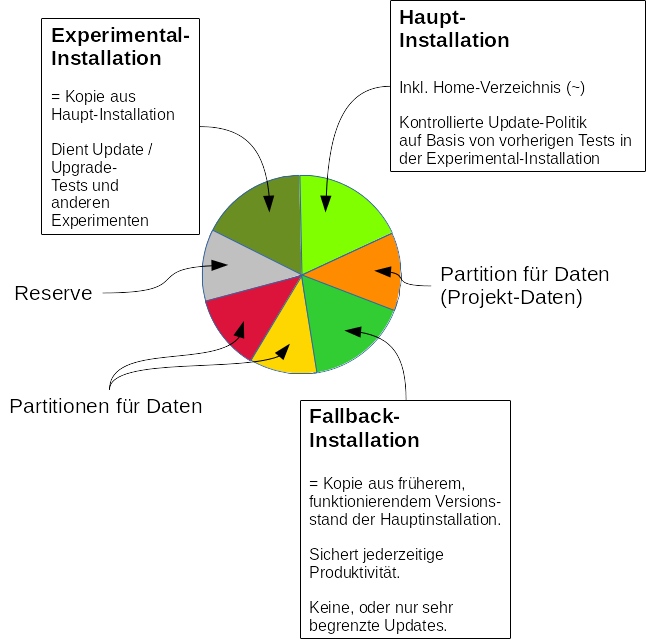
- Haupt-Installation und separate Partitionen für Nutz- und Anwendungsdaten: Die Betriebssystem-Installation für den täglichen Gebrauch erfolgt auf einer Festplattenpartition begrenzter Größe. Es wird von vornherein eine getrennte Ablage von OS-System-Dateien einerseits und späteren Projekt-Daten (Applikationsdaten, Nutzerdateien, ggf. Virtualisierungsumgebungen) andererseits auf unterschiedlichen Partitionen (LVM-Volumes) der Systemplatte(n) angestrebt.
- Fallback-Installation: Im beruflichen Einsatz muss man bei Problemen schnell auf eine noch funktionierende Installation zurückgreifen können – hierzu braucht es eine jederzeit bootbare Fallback-Installation auf einer weiteren, separaten Partition der HD/SSD des Systems.
- Experimental-Installation: Man braucht eine Spielwiese, um neue Programme, aber auch umfassendere oder kritische Updates/Upgrades gefahrlos ausprobieren zu können. Eine entsprechende dritte Betriebssystem-Installation sollte auf einer weiteren eigenen Partition (Volume) untergebracht werden.
Während die erste Maxime übergreifend gilt, haben die anderen drei offenbar eine Auswirkung auf die Partitionierung (und/oder das LVM-Layout) des Systems. Die “Methodik” zur Erhaltung der Arbeitsproduktivität besteht also darin,
- dass man eine garantiert funktionsfähige Fallback-Installation in bootfähigem Zustand bereit hält,
- dass man komplexe Updates/Upgrades erstmal auf einer Experimental-Installation austestet, bevor man die Updates/Upgrades auf der Haupt-Installation nachzieht.
- dass man zu geeigneten Zeitpunkten sowohl die Fallback-Installation als auch die Experimental-Installation als Kopie eines funktionierenden Zustands der Hauptinstallation erneuert. (Falls in zeitlicher Nähe: zuerst die Experimental-Installation und dann die Fallback-Installation.)
Das ist zunächst mal einfach und hoffentlich auch einleuchtend. Wie man die Partitions-“Kopien” erzeugt und dabei Boot-Probleme vermeidet, besprechen wir später. Zunächst gilt:
“Continuity” erfordert, mehrere funktionierende Betriebssystem-Installationen auf ein und demselben System vorzuhalten. Eine dient als Fallback für das produktive Arbeiten, wenn es mal zu Problemen mit der “Haupt-Installation” kommt. Die Fallback-Installation ist daher bzgl. Updates extrem vorsichtig zu behandeln. Ggf. wird man Updates sogar völlig unterlassen. Die Funktionstüchtigkeit dieser Installation ist wichtiger als ein aktueller Paket-Status!
Alle drei in der Liste angesprochenen Installationen müssen separat bootbar sein – und die Daten, mit denen man kontinuierlich (weiter-) arbeiten will, müssen deshalb unabhängig von den einzelnen OS-Installationen gelagert werden.
Ein Zugriff auf produktive Projekt-Daten muss von jeder der drei Installationen aus durch ein “Mounten” des Filesystems der Datenpartitionen in definierte Knotenpunkte des jeweiligen Verzeichnisbaums in gleichartiger Weise ermöglicht werden (s.u.).
Wir benötigen jedenfalls mehrere Partitionen (oder LVM-Volumes) auf der/den Systemplatte/n. Das kann dann in etwa so aussehen:
Die erste Aufgabe für den Linux-Einsteiger, der der obigen Philosophie folgen will, ist also:
Mache dich mit der Partitionierung einer Festplatte und Tools wie etwa “gdisk“, “gparted” oder unter Opensuse auch mit dem “Yast Partitioner” vertraut. Zur Einrichtung eines reinen Linux-Systems sollte man dabei auch schon mal was von ein GPT-Layout von Festplatten gehört haben – und sich (soweit möglich) von veralteten Dingen wie “erweiterten Partitionen” aus MSDOS- bzw. MBR-Zeiten lösen. Siehe etwa: https://wiki.ubuntuusers.de/Partitionierung/Grundlagen/, http://www.linux-community.de/Internal/Artikel/Print-Artikel/EasyLinux/2016/01/OpenSuse-Leap-42.1, https://kofler.info/opensuse-leap-42-1/.
(Merke nebenbei: MS Windows gehört unter Linux eigentlich ins “Fenster”; genauer in eine virtuelle Maschine; zumindest dann, wenn man Windows nicht für 3D-Games benötigt. Auf sowas wie eine primäre NTFS-Partition in einem MBR-Plattenlayout kann man dann völlig verzichten. Will man eine vorhandene NTFS-Windows-Partition aber aus berechtigten (!) Lizenz-Ängsten und auf UEFI-Systemen aus Ängsten vor Boot-Fehlern nicht zerstören, sollte man sie in jedem Fall verkleinern. Die meisten Linux-Installationsprogramme bieten das an.)
Partitionsgrößen für die Betriebssystem-Installationen relativ klein halten!
Als Einsteiger tendiert man dazu, während der Linux-Erstinstallation ein vom Installer der jeweiligen Distribution vorgeschlagenes Partitionsmuster für die Festplatten zu übernehmen. Die meist vorgeschlagenen 2 oder 3 Linux-Partitionen (neben einer Swap- und ggf. auch einer EFI-Partition) umfassen dann insgesamt oft den gesamten Plattenplatz. Kennt man sich dann aber nicht mit so schönen Dingen wie LVM aus, nimmt einem das erhebliche Flexibilität!
Leuten mit ein wenig Erfahrung rate ich deshalb eher dazu, sich im Vorfeld einer Installation genau zu überlegen, welche Partitionen man tatsächlich für welche Zwecke auf seinem Desktop-System benötigt. Den Platz für die zu hauptsächlich zu nutzende Betriebssystem-Installation sollte man dabei auf das Notwendige (s.u.) begrenzen und den Rest der Platte erstmal frei halten.
Zweite Aufgabe für Umsteiger:
Bei der ersten Installation von Linux sollte man die Partition für das Root-Filesystem in der Größe begrenzen; sinnvolle Werte liegen nach meiner Erfahrung zwischen 40GB und 80GB. Das lässt einem genügend Luft für Programm-Installationen und Experimente. Persönlich nehme ich meist 80 GB. Den Vorschlag für eine Swap-Partition kann man übernehmen. Auf weitere Partitionen (etwa wie oft vorgeschlagene für “/home”) kann und sollte man dagegen erst mal verzichten; sie kann man später bei Bedarf immer noch anlegen.
(Bei Nutzung von LVM sollte man unabhängig von der zugrunde liegenden Partitionierung und Volume-Gruppen das logische Volume für das Root-Filesystem begrenzen). Auf einem reinen Linux-PC-System gibt es in meinem Ansatz daher zunächst nur : ggf. eine EFI-Partition, eine rel. kleine Swap-Partition (< 4GB) und eine Partition für das Root-/-Filesystem (mit 40 bis 80GB; in ext4-Formatierung, s.u). Sonst nix!
Wir nutzen den freigelassenen Plattenplatz für unsere Daten-Partition(en) und für weitere Partitionen (Volumes), die unsere Fallback- bzw. Experimental-Installation aufnehmen. Wir werden die Inhalte der Fallback-Partition und der Experimental-Partition später als Kopien eines bestimmten Zustands der Hauptinstallation erstellen. Wir benötigen also mindestens 2 x die Größe der Partition für die Hauptinstallation (also z.B. 3 x 80GB) als freien Plattenplatz; den Rest können wir für eine oder mehrere Datenpartitionen nutzen. (Hinweis: Will man mit schnellen Virtualisierungssystemen arbeiten, braucht man ggf. auch dafür weitere Partitionen (Volumes).)
Unter Opensuse wird während der Installation der sog. YaST-Partitionmanager angeboten. Er erlaubt eine Reduktion der Partitionsgröße im sog. “Expertenmodus”. Ein weiterer Punkt: Nehmt als Anfänger lieber “ext4” als Filesystem und nicht BtrFS. Ich habe hierfür gute Gründe, die ich aus Platzmangel an dieser Stelle aber nicht erläutern kann.
Hat man aber die Erstinstallation bereits hinter sich und wurden dabei zu große Partitionen angelegt, muss man im Nachhinein Platz schaffen. Hierbei muss man sich mit Hilfe der genannten Partitionierungstools dazu kundig machen, welche Partitionen im aktuellen Zustand noch wie weit verkleinert werden können. Danach kann man die vorhandenen Partitionen mit Hilfe der Partitionstools in der Größe reduzieren. Ggf. muss man dazu vorher ein Live-System oder eine Rettungsinstallation von CD/DVD oder USB-Disk booten.
Einsatz eines Bootmanagers – Grub2
Unsere Strategie läuft auf mehrere bootbare Linux-Installationen hinaus. Linux erlaubt über die Installation von sog. “Boot-Managern” das Booten verschiedener Betriebssystem-Installationen aus unterschiedlichen Partitionen der HDs/SSDs des Systems. Hierzu wird einem beim Systemstart eine Liste verfüg- und bootbarer Installationen angezeigt.
Bootmanager werden von den meisten Linux-Distributionen bereits im Rahmen der Erstinstallation des Systems eingerichtet. Der aktuelle distributionsübergreifende Standard ist hierbei wohl “Grub2“. Eine gute Übersicht über diesen relativ komplexen Bootmanager liefern folgende Artikel:
https://en.wikipedia.org/wiki/Grub2#GRUB_version_2
https://opensource.com/article/17/3/introduction-grub2-configuration-linux
https://wiki.ubuntuusers.de/GRUB_2/ und https://wiki.ubuntuusers.de/GRUB_2/Konfiguration/
Für Details siehe: https://www.gnu.org/software/grub/manual/grub/grub.pdf
Ich kann in diesem Artikel aus Platzgründen nicht auf Details von Grub2 eingehen. Für unsere Zwecke ist es ausreichend zu wissen, dass der Grub2-BootLoader in drei Schritten installiert oder modifiziert wird: Zunächst wird aus Vorgaben in der Definitionsdatei “/etc/default/grub” und weiteren Skript- und Konfigurations-Dateien unter dem Verzeichnis “/etc/grub.d/” eine temporäre Konfigurationsdatei erzeugt. Der notwendige Befehl ist je nach Distribution “grub-mkconfig” (z.B. Ubuntu) oder “grub2-mkconfig” (z.B. Opensuse). Das Ergebnis kann man dann über die Kommandozeile mit dem Kommando “update-grub” in die Datei “/boot/grub/grub.cfg” (Ubuntu) bzw. “/boot/grub2/grub.cfg” (Suse) schreiben lassen. Schließlich
schreibt man dann die notwendigen Informationen und Boot-Programme mittels des CLI-Befehls “grub-install” (Ubuntu) oder “grub2-install” (Suse) in bestimmte Plattenbereiche (die wiederum u.a. vom Platten-Layout, GPT oder MBR abhängen).
Spezialtools der verschiedenen Distributionen führen zumindest Teile oder gar alle dieser Schritte in einem Arbeitsvorgang durch:
Opensuse: Yast2 >> System >> Bootloader”
Ubuntu: z.B. Grub Customizer (https://www.pcwelt.de/ratgeber/Grub-Bootloader_anpassen-10017211.html, https://www.bitblokes.de/den-bootloader-via-gui-im-griff-grub-customizer/, https://wiki.ubuntuusers.de/GRUB_Customizer/)
Diese Tools erlauben es auch, die Systempartitionen nach anderen bootbaren Installationen durchsuchen zu lassen – und binden letztere in die Auswahlliste des Boot-Menüs ein.
In unserem Kontext ist/wird vor allem die Konfigrationsdatei “/boot/grub[2]/grub.cfg” relevant. Man kann diese Datei zur Not auch mit einem Editor modifizieren, wenn man sicher ist, was dabei zu tun ist. Wir werden weiter unten lediglich bestimmte begrenzte Strings der “grub.cfg” (in kopierten Partitionen) durch andere ersetzen.
Dritte Aufgabe für Umsteiger:
Befasst euch mit dem Boot-Vorgang und dem Grub2-Boot-Manager.
Nutzdaten auf separaten Partitionen – und die besondere Rolle des eigenen Home-Verzeichnisses “~”
In meiner “Methodik” ist die Unterscheidung zwischen Partitionen für die Systeminstallation einerseits und für Nutzdaten andererseits essentiell. Die meisten Nutzdaten, die man als Benutzer anlegt, lassen sich in Projekte und eigene Ordnerhierarchien gliedern und schlagen sich in dortigen Dateien nieder (z.B. Text-Dateien, Präsentationen, selbst entwickelte Programme, Bilder, Movies …). Hinzu kommen Daten wie Favoriten aus bestimmten Applikationen, die man meist aber zur Sicherungszwecken in separate Files exportieren und importieren kann. Selbst den Ablageort von Datenbank-Dateien kann man meist selbst festlegen. Für all diese Daten lege ich grundsätzlich eine oder mehrere eigene Partitionen (LVM-Volumes) mit zugehörigen Filesystemen (ext4) an, die auf selbst definierte Knotenpunkte im Dateibaum gemountet werden – etwa in Subverzeichnisse unter “/mnt” (/mnt/MyProjects, /mnt/MySamba, /mnt/MyPics …). Eine von der System-Installation unabhängige Datenhaltung vereinfacht im übrigen Backups erheblich.
Hat man die Nutzdaten erstmal vom OS-“Rest” absepariert, so können die Nutzdaten über Filesystem-Mounts in jede funktionierende und gebootete Betriebssysteminstallation eingebunden werden. Die Vorgaben dazu hinterlegt man in der jeweiligen Datei “/etc/fstab”; s. hierzu die man-Seiten oder https://wiki.ubuntuusers.de/fstab/. Unter Opensuse kann man die Einträge auch mit dem YaST-Partitionmanager vornehmen lassen. Natürlich muss man die Dateien und Mount-Punkte jeweils mit den nutzerbezogenen Rechten versehen.
Es ergibt sich also eine dritte Aufgabe für Ein- und Umsteiger:
Arbeitet euch in das “Mounten” von Filesystemen ein – studiert die Bedeutung der Einträge in der /etc/fstab.
[Ergänzung für Fortgeschrittene: Persönlich halte ich meine Projektdateien zudem weitgehend in SVN- oder Git-Verzeichnissen, die mit einem zentralen SVN-/Git-Server abgeglichen wird. Das gilt auch für Dokument-Dateien. Serverbasierte Versionsmanagement-Systeme erlauben neben der Versionierung seiner Arbeiten zudem schnelle “Backups” durch Replikation der Dateien auf weitere Systeme (Server, PCs, mobile Laptops, …). ]
Ausnahmen von der Lagerung eigener “Daten” in
separaten Partitionen
Neben selbst erzeugten Projekt-Daten in Dateien gibt es auch automatisch generierte Konfigurationsdateien, die Einstellung zur persönlichen grafischen Desktop-Umgebung und persönliche Einstellungen zu bestimmten Applikationen betreffen. Auch diese Dateien werden meist in Unterordnern des eigenen Home-Verzeichnisses “/home/uid” [~] untergebracht – u.a. unter “~/.config”.
Diese “Konfigurations”-Dateien sind im Sinne einer schnellen Restauration der Produktionsfähigkeit wichtig! Sie sind ferner relativ eng mit anderen Bibliotheken einer Distributionsversion verzahnt. Wir wollen später mehrere Partitionen mit funktionstüchtigen Installationen, aber auf unterschiedlichen Versionsständen, durch das Kopieren von Partitionen einrichten. Das spricht dann dafür,
die Inhalte des eigenen Home-Verzeichnisses im Gegensatz zu sonstigen Nutzdaten nicht auf eine separate Partition zu legen.
Warum?
Der eigene grafische Desktop und OS müssen im Verbund funktionieren! Das führt dann beim Starten einer neuen Desktopversion u.U. zu automatischen Updates der Konfigurationsdateien. Diese Modifikationen kann man danach ohne Spezialkenntnisse nicht mehr so einfach zurückdrehen. Hat man also das eigene “~”-Verzeichnis auf eine separate Partition verlagert, die man dann nach einem Systemupgrade unter der neuen Installation mounted, so ist nach einem Start der neuen Desktop-Umgebung die spätere Nutzbarkeit der Konfigurationsdateien unterhalb von “~” in der noch vorhandenen alten Installation in Frage gestellt! Das muss man vermeiden – und deswegen ist es besser, das “/home”-Verzeichnis in unserem Verfahren nicht aus dem Root-Filesystem abzuseparieren.
In den turbulenten KDE4-Anfangszeiten (gerade mit Kontact/Kmail) ist mir schmerzlich bewusst geworden, dass es auf einem Stand-Alone-System kaum Sinn macht, das eigene Home-Verzeichnis mit seinen Konfigurationsdateien in eine separate Partition zu verlagern – auch wenn dass bei vielen Distributionen im Installationsprozess so vorgeschlagen wird. Man muss das alte Home-Verzeichnis dann in jedem Fall sichern, wenn man wieder auf die alte Installation zurück will. Dann kann man es in den unterschiedlichen Installationen gleich mit vorhalten – auch wenn das Platz kostet. (Das sieht auf einer serverbasierten Installation, bei der das Home-Verzeichnis ggf. auf einem zentralen NFS-Server liegt und über Netz auf dem lokalen PC gemountet wird, natürlich anders aus.)
Eine weitere Ausnahme bilden womöglich Mail- und Groupware-Daten, die zumeist ebenfalls in Unter-Ordnerhierarchien des persönlichen Desktops – also unterhalb irgendwelchen Konfigurationsordnern des eigenen Home-Verzeichnisses untergebracht werden. Entsprechende Dateien lassen wir mal außen vor – die Ursprungsdaten zu Mails gehören aus meiner Sicht eh’ immer auf einen (ggf. lokalen und virtualisierten) IMAP-Server. In lokalen Mailsystemen der Desktops sollten davon höchstens Kopien vorgehalten werden.
Zwischenfazit
Genug für heute! Es sollte klar geworden sein, dass ich die Kontinuität meiner Arbeitsfähigkeit gegenüber Update/Upgrade-Probleme neben Backups durch verfügbare Fallback-Installationen und eine Speicherung von Nutzdaten auf separaten Partitionen sicherstelle.
Im nächsten Beitrag
Upgrade-Zeit – Vorsorge durch Fallback-Installationen – II
bespreche ich dann den Einsatz des “dd”-Kommandos zum Anlegen von Partitionskopien – und bespreche, wie ihr ein mögliches Chaos beim Booten, das sich aus duplizierten sog. UUIDs der Filesysteme ergeben würde, vermeidet.