There are many PROs and CONs regarding the choice of a Machine Learning [ML] framework for private studies on a Linux Workstations. Two mainly used frameworks are PyTorch and a Keras/Tensorflow combination. One aspect for productive work with ML models certainly is performance. And as I personally do not have TPUs or other advanced chips available, but just a consumer Nvidia 4060 TI graphics card, performance and optimal GPU usage are of major interest – even for the training of relatively small models.
With this post I just want to point out that the question of performance advantages of some framework on a CUDA controlled graphics card can not be answered in a unique way. Even for small neural network [NN] models the performance may depend on a variety of relevant settings, on jit-/xla-compilation and the chosen precision level of your training or inference runs.
People doing Machine Learning [ML] experiments on their own Linux PCs or laptops know that the numerical training runs put a heavy load on the graphics cards and consume a lot of energy as a direct consequence. Especially in a hot summer like we have it in Germany right now, cooling of your systems may become a problem. And as energy has a high price tag here, any method to reduce the load and/or power consumption is welcome.
But I think that caring about energy consumption is a topic which we as a Linux and ML enthusiasts should keep in mind in general. Some big tech companies will probably not do it – as long as their money machinery works and as some heads follow fantasies about building small nuclear power plants for their big AI data centers. But we Opensource people would like to see more AI- and ML-services independent of the monopolists and their infrastructure, anyway. Not only for reasons of data and privacy protection.
As soon as we, however, proclaim and work for a development that favors local and resource optimized installations of AI and ML tools both for private people and companies, we have to care about side effects: We have to bring the energy consumption down for these many local installations substantially in parallel. Otherwise, centralized solutions may have a better energy efficiency than decentralized solutions.
For me as a retired person in Germany the general financial pressure is high enough to enforce a careful use of my private resources. With this post I want to draw your attention to two points which may help you, too, to save energy during your ML-experiments. (In addition to or aside of standard measures like saving certain model states during training runs to get better starting points for new runs.)
Working with Machine Learning and Deep Neural Networks not only requires GPU drivers, but in case of Nvidia GPUs also the installation of CUDA and cuDNN. This process is always a bit tricky as additional environment variables have to be set for IPython-based Jupyterlab or classic Jupyter Notebook. On an Opensuse system one must in addition take care of the right settings in /etc/alternatives.
I hope this helps people who want to use Leap 15.5 for Machine Learning with Nvidia GPUs, Keras/Tensorflow 2 and Jupyterlab.
Important addendum 01/27/2024:
Although the combination of CUDA 12.3, cuDNN 8.9.7, Tensorflow 2.15 and Nvidia drivers 545.29.06 works regarding AI-models, there is another major problem:
Nvidia’s driver 545.29.06 is buggy – at least for Leap 15.5, KDE/Plasma with multiple screens. The bug affects Suspend-to-RAM. Suspend-to-RAM seems to work in the suspend phase, and the system also comes up afterward in a seemingly proper state of your KDE/Plasma interface (on your screens).
However, the problems begin when you want to change to another virtual screen via Ctrl-Alt-Fx. You wait and wait and wait … The same for changing the run-level or systemd target state or when you want to shut the system down. This makes Suspend-to-RAM with driver 545.29.06 impossible to use.
Recommendation:
If you have a working older Nvidia driver (e.g. a stable 535 version) do not change to 545.29.06. Unfortunately, it is a mess on a multiscreen Leap 15.5 system to return to an older driver version. The Nvidia community repository does not offer you a choice. (Why by the way ????). Downloading an older proprietary driver from Nvidia and trying to install it afterward on a console terminal (after having stopped X11 or Wayland) did not work in my case – the screens displaying the terminal changed their resolution and froze afterward. So, you may have to completely uninstall the present driver 545 completely, go back to standard VGA and then try to install an older driver via Nvidias install mechanism. As I said: It is a mess …
Last week I stared preparing posts for my new blog on Machine Learning topics (see the blog-roll). During my studies last week I came across a scientific publication which covers an interesting topic for ML enthusiasts, namely the question what kind of statistical distributions we may have to deal with when working with data of natural objects and their properties.
The reference is:
S. A. FRANK, 2009, “The common patterns of nature”, Journal of Evolutionary Biology, Wiley Online Library Link to published article
I strongly recommend to read this publication.
It explains statistical large-scale patterns in nature as limiting distributions. Limiting distributions result from an aggregation of the results of numerous small scale processes (neutral processes) which fulfill constraints on the preservation of certain pieces of information. Such processes will damp out other fluctuations during sampling. The general mathematical approach to limiting distributions is based on entropy maximization under constraints. Constraints are mathematically included via Lagrangian multipliers. Both are relatively familiar concepts. The author explains which patterns result from which basic neutral processes.
However, the article also discusses an intimate relation between aggregation and convolutions. The author furthermore presents an related interesting analysis based on Fourier components and respective damping. For me this part was eye-opening.
The central limit theorem is explained for cases where a finite variance is preserved as the main information. But the author shows that Gaussian patterns are not the only patterns we may directly or indirectly find in the data of natural objects. To get a solid basis from a spectral point of view he extends his Fourier analysis to the occurrence of infinite variances and consequences for other spectral moments. Besides explaining (truncated) power law distributions he discusses aspects of extreme value distributions.
All in all the article provides very clear ideas and solid arguments why certain statistical patterns govern common distributions of natural objects’ properties. As ML people we should be aware of such distributions and their mathematical properties.
we have studied the transformation of an ellipse by a shear operation. The coordinates of points on an ellipse and the components of respective position vectors fulfill a quadratic equation (quadratic form):
The superscript “T” symbolizes the transposition operation. The symmetric (2×2)-matrix \( \pmb{\operatorname{A}}_q^O \) defines the original, unsheared ellipse. The suffix “q” indicates the quadratic form. I have shown how the shear parameter λS impacts the coefficients of a corresponding (2×2)-matrix \(\pmb{\operatorname{A}}_q^S \) that defines the sheared ellipse.
What I have not done in the last post is to show how our matrix \(\pmb{\operatorname{A}}_q^S \) is related to a shear matrix \(\pmb{\operatorname{M}}_{sh} \) (see the first post), which describes the effect of the shear on the vectors \( \left(\,x_o,\, y_o\,\right)^T \). I am going to discuss this below. The given matrix relations will also be valid for general n-dimensional ellipsoids.
Matrix relations as discussed below are helpful to accelerate numerical calculations as Numpy (in cooperation with libraries for your OS) provides highly optimized modules for matrix operations. n-dimensional ellipsoids furthermore characterize hyper-surfaces of multivariate normal distributions which appear in certain areas of Machine Learning and respective data.
Matrix describing a centered n-dimensional ellipsoid
We consider n-dimensional and centered ellipsoids whose symmetry centers coincide with the origin of the Euclidean coordinate system [ECS] we work with. A position vector \(\left(\,x_1^o,\, x_2^o\, \cdots x_n^o \right)^T \)
is a vector drawn from the origin to a point on the ellipsoid’s hyper-surface. Note that a general vector of a vector space has no reference to a coordinate system’s origin. Therefore the distinction. A general ellipsoid is defined by a quadratic form in the components of its position vectors. The quadratic form is equivalent to the following matrix equation
where \(\pmb{\operatorname{A}}_{qn}^O \) now represents a symmetric (nxn)-matrix. The “\( \circ \)” symbolizes a matrix product.
Note: A coefficient \( \delta \gt 0 \) which we have used in previous posts on the right side of the equation can be included in the coefficient values of the matrix).
Note that the equations above define an ellipsoid up to a translation vector. This is reflected in the fact that the above equation does not create any linear terms.
Quadratic forms not only define ellipsoids. For an ellipsoid we have to assume that the determinant of\(\pmb{\operatorname{A}}_{qn}^O \) is > 0 and that the matrix is invertible:
Note that you could choose an ECS in which the ellipsoid’s principal axes would align with the ECS’s coordinate axes. Such a choice would correspond to a PCA-transformation of the vector data. \(\pmb{\operatorname{A}}_{qn}^O \) would then become diagonal. This corresponds to the fact that a symmetric matrix always has an eigenvalue-decomposition.
Equation of the quadratic form for the sheared ellipsoid
In the first post of this series I have defined a (invertible) shear matrix as a unipotent matrix \( \pmb{\operatorname{M}}_{sh} \) with all coefficients of the lower triangular part, off the diagonal, being equal to 0.0 and all elements on the diagonal being equal to 1:
So an inverse matrix \( \pmb{\operatorname{M}}_{sh}^{-1} \) exists. Shearing our original ellipse (with position vectors \( \pmb{x_o} \)) leads to new vectors \( \pmb{x_S} \):
Σ is a diagonal (nxm)-matrix with singular values. The column-vectors of U and V are orthogonal singular vectors. Geometrically, U and V can be interpreted s rotational operations.
Therefore, we can decompose a (nxn) upper triangular shear-matrix into two orthonormal (nxn)-matrices U and V plus a diagonal matrix Σ :
This gives us an alternative form to define the inverse shear matrix. Note that the order of the matrices in the matrix products is essential.
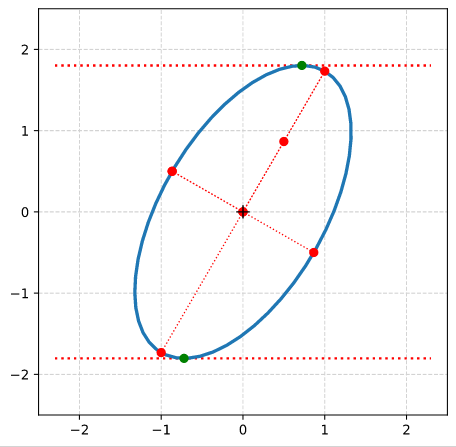
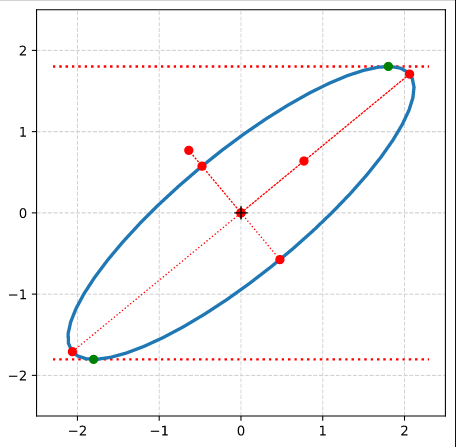
An example for the case of a sheared ellipse
We use the example of a sheared ellipse discussed in the last post to verify the results above numerically for a 2-dim case. To write a respective Python/Numpy-program is simple. I will just give you my numerical results below.
We have used an ellipse with the longer and shorter primary axes having values a = 2 and b = 1, respectively. The ellipse was rotated by 60° against the ECS-axes.
The respective (2×2)-matrix \( \pmb{\operatorname{A}}_q^O \) had the following coefficients
We have shown how a shear matrix \( \pmb{\operatorname{M}}_{sh} \) transforms the matrix \(\pmb{\operatorname{A}}_{qn}^O \) which defines an un-sheared n-dimensional ellipsoid into a matrix \(\pmb{\operatorname{A}}_{qn}^S \) defining its sheared counterpart. We have also had a glimpse on a SVD decomposition of a shear matrix. The results will enable us in the next post to apply shear operations on a concrete example of a 3-dimensional ellipsoid.