In the previous articles of this series
KMeans as a classifier for the WIFI and MNIST datasets – I – Cluster analysis of the WIFI example
KMeans as a classifier for the WIFI and MNIST datasets – II – PCA in combination with KMeans for the WIFI-example
I applied KMeans to the “WIFI” dataset – a small and rather simple training set of the UCI Irvine. The 7 dimensional feature space for this example is defined by the strength of seven different WLAN-signals. The data samples are labeled by numbers specifying four different rooms. We just have 2000 samples. But “simple” does not mean that one cannot learn something of it.
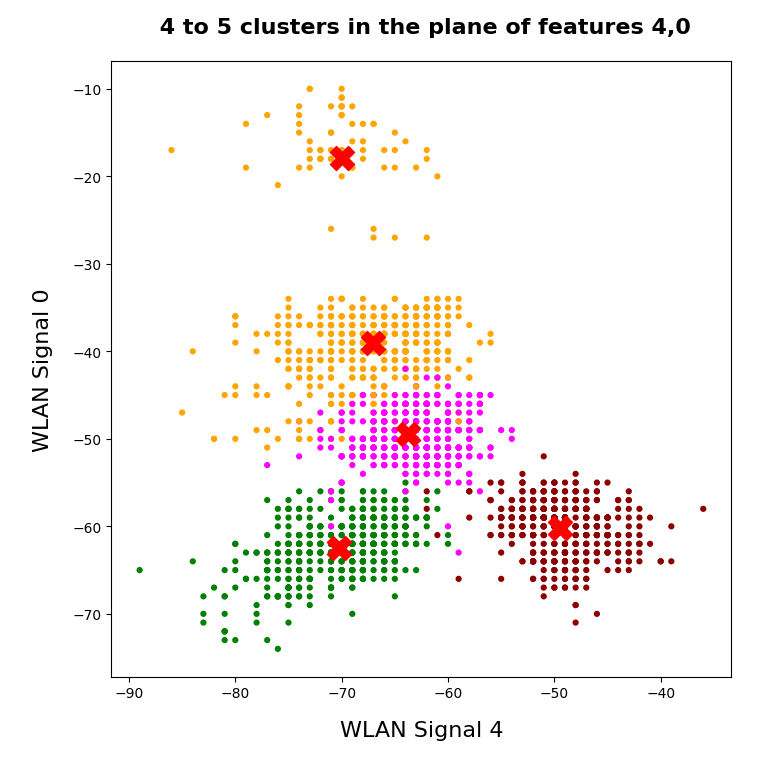
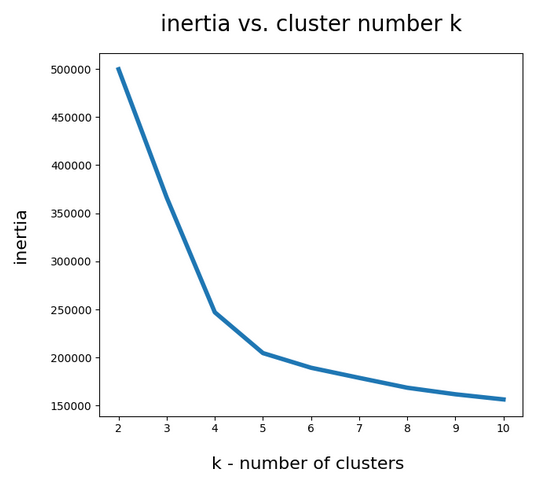
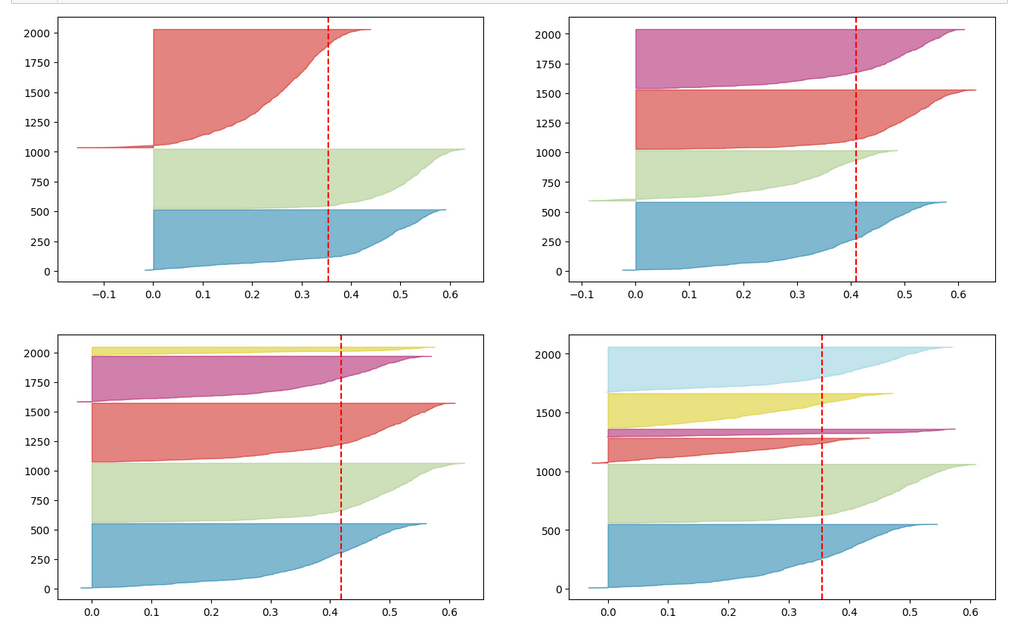
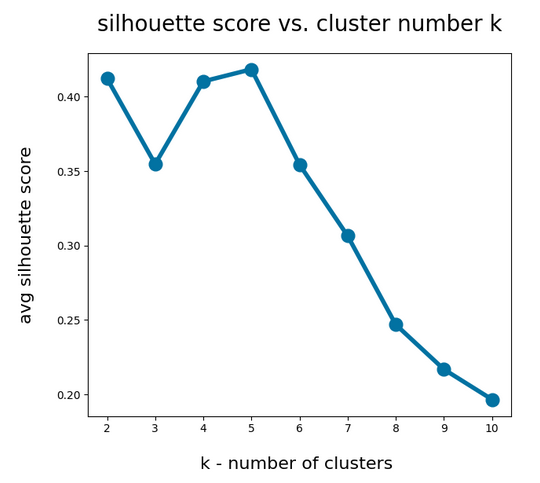
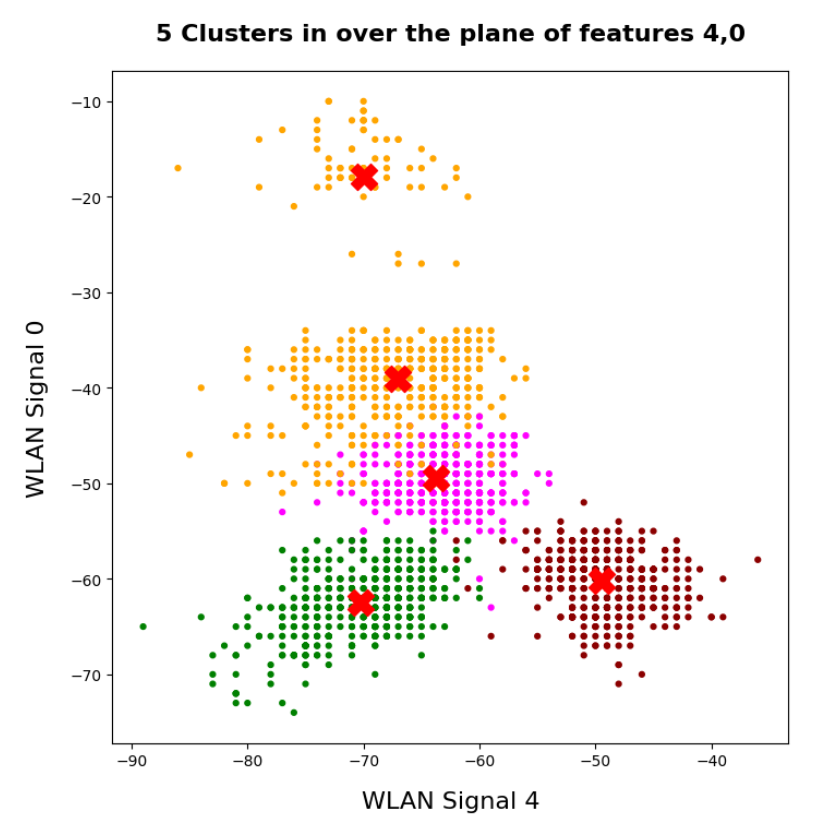
An elbow and a silhouette analysis indicated that the data can well be described by 4 to 5 clusters.
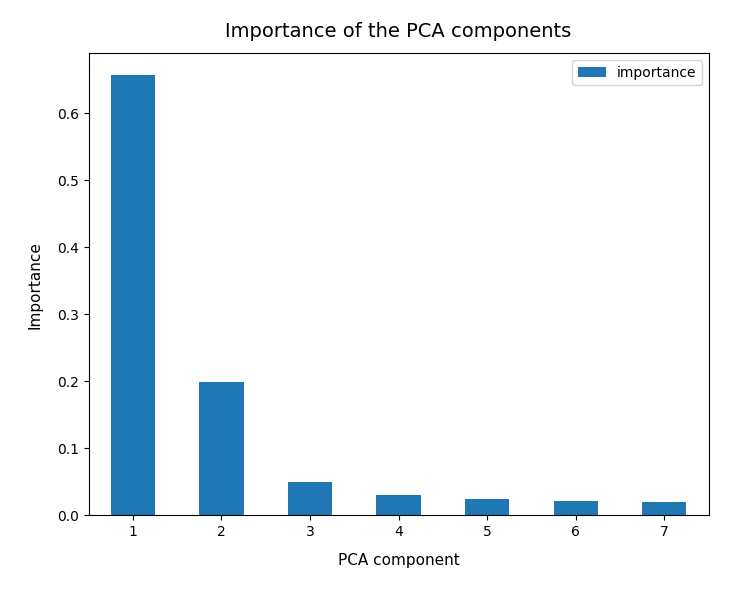
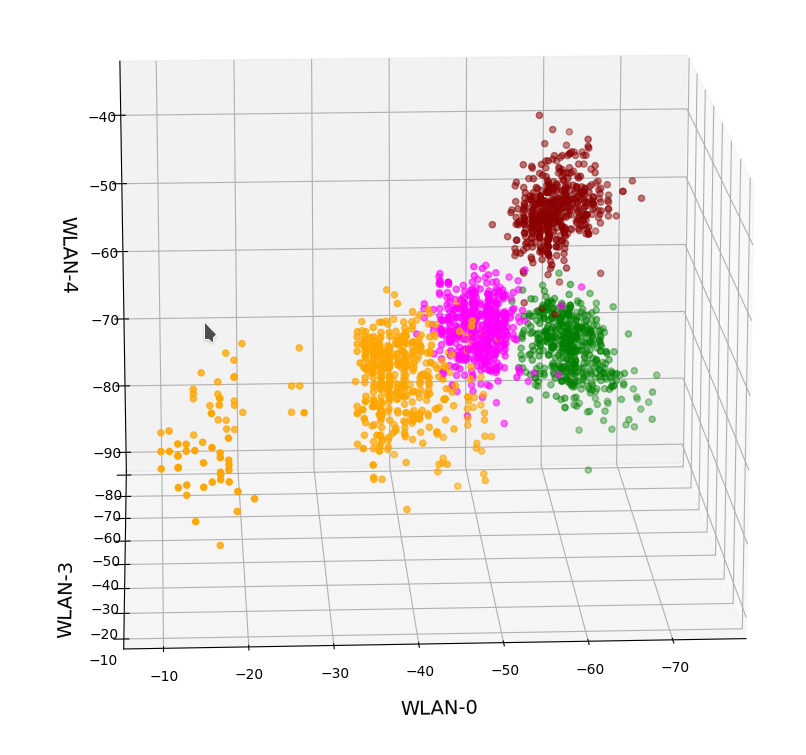
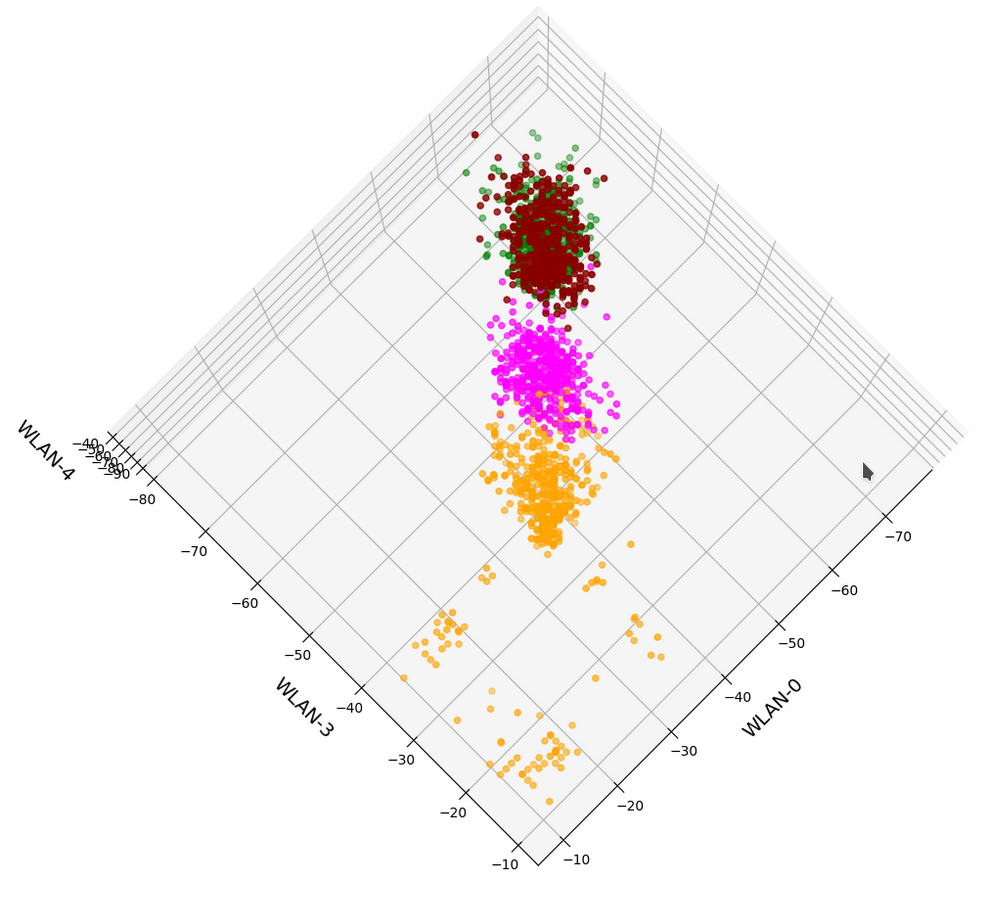
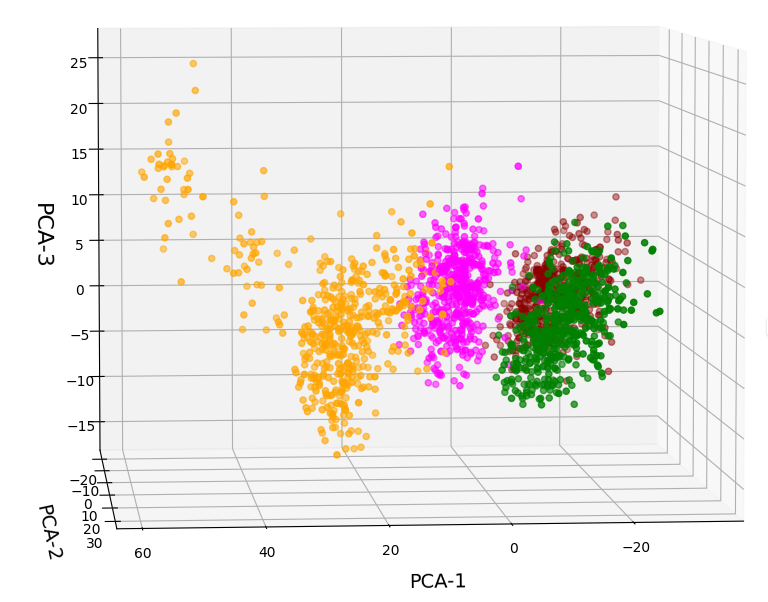
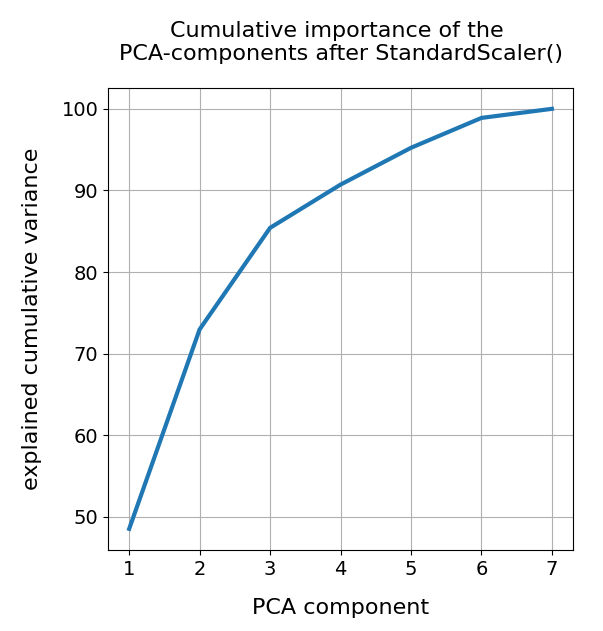
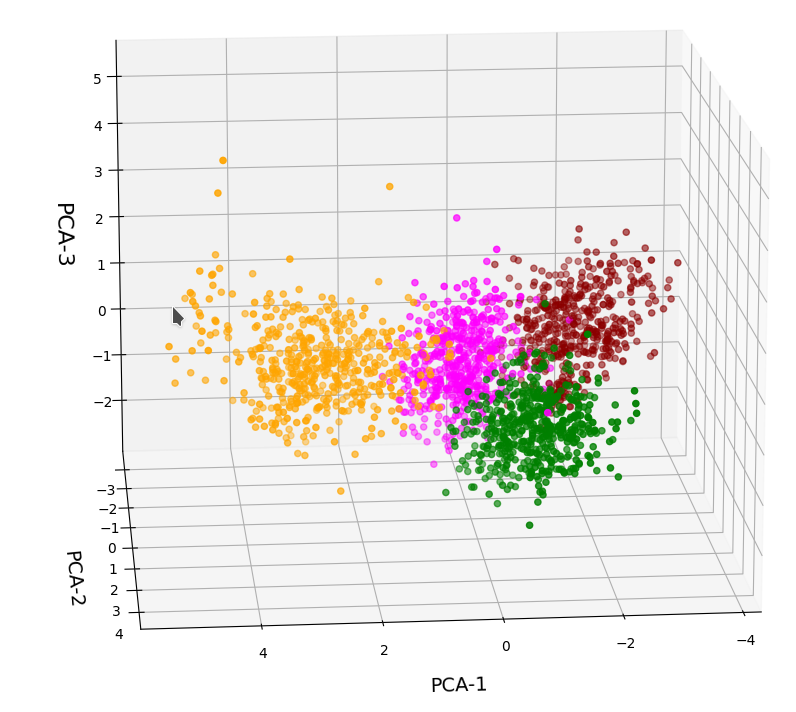
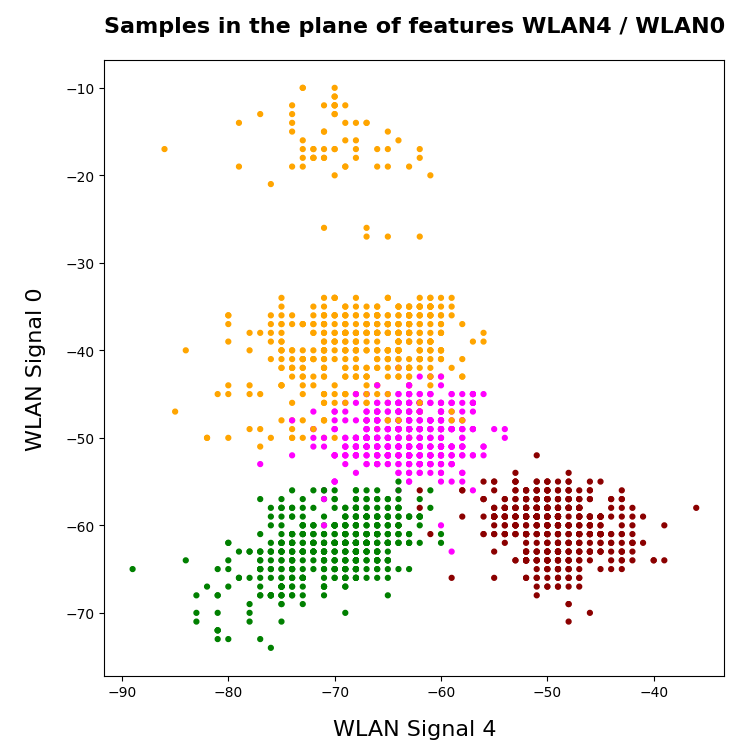
A detailed PCA analysis helped us to understand that the data could basically be described by two primary components whose axes were defined by a diagonal in a two-dimensional sub-space of the original feature space (defined by the features “WLAN-0” and “WLAN-3”) plus an orthogonal axis (defined by “WLAN-4”). As the data points segregated into well separated clusters in the coordinate system of the primary components we could expect that they also segregate well when projected onto two 2-dim sub-spaces of the feature space defined by the signal combinations {WLAN-0/WLAN-4} and {WLAN-3/WLAN-4}.
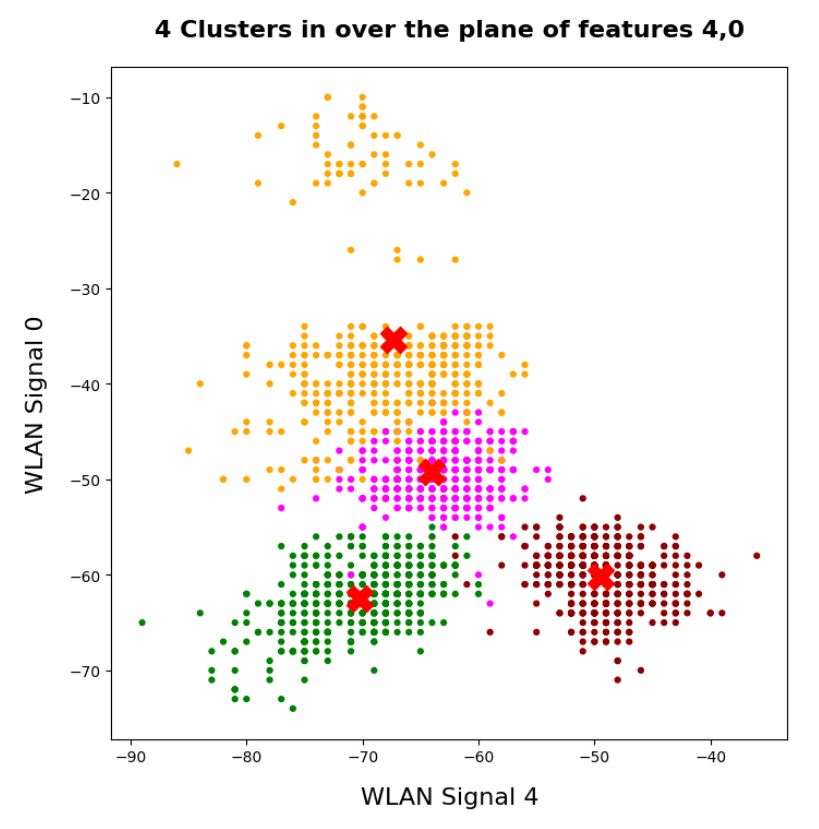
So we projected the results of a KMeans analysis into a 2-dim sub-space of the 7-dim feature space spanned by two selected “features” (WLAN signals WLAN-0 and WLAN-4). And indeed: For 2 special signal- or feature-combinations we saw a field with 4 to 5 well separated clusters.
As we have well separated clusters – either in sub-planes of the feature space or the space defined by the dominant two PCA components – a legitimate question is: Can we use the cluster information for classifying?
Clusters and classification
In the special example of the WIFI data the data points can obviously be divided into different “groups” filled by data points which belong to a certain “label” or class (in the WIFI case: a room):
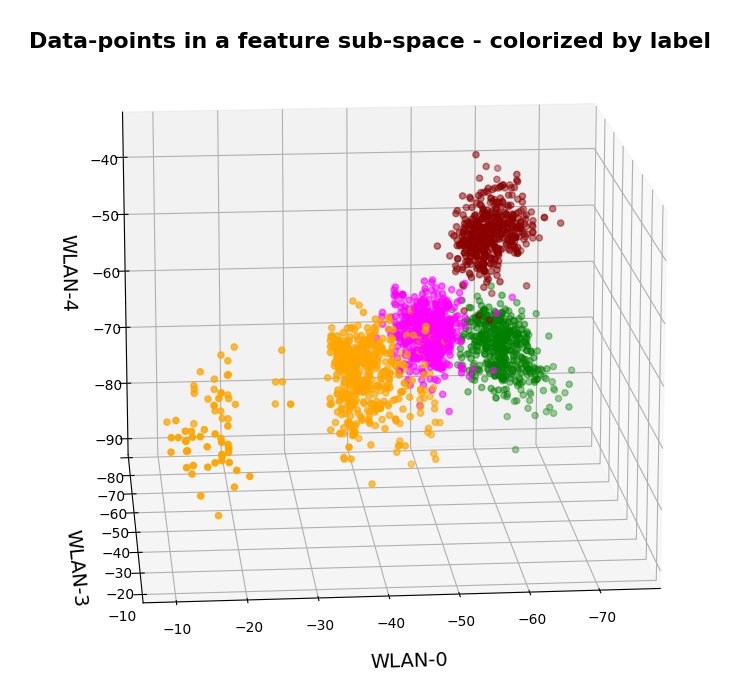
In the plots above the colorization of the data points is given by their label in the plot above. However:
Does this mean that these spatially separated “groups” coincide with the clusters detected by KMeans?
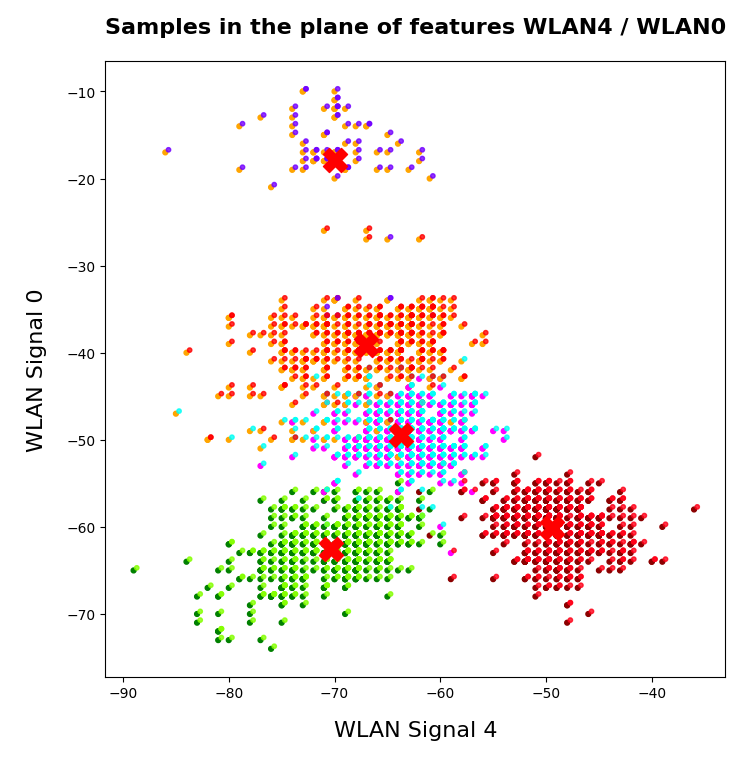
In the next plots I superimposed the data points – first colorized by class and then by cluster with different colors and a slight spatial deviation.
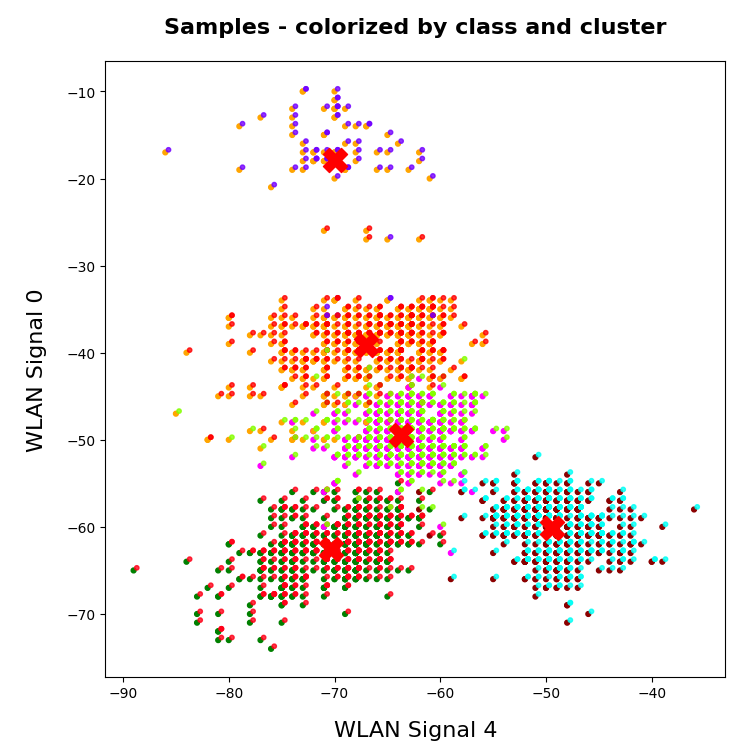
We see that the border of the class related points on average overlaps well with the border of the clusters. Only a few points show a major deviation.
Is this always the case? Of course not!
We see this already when we we just use 2 clusters and colorize the data points according to cluster membership in one of the two clusters:
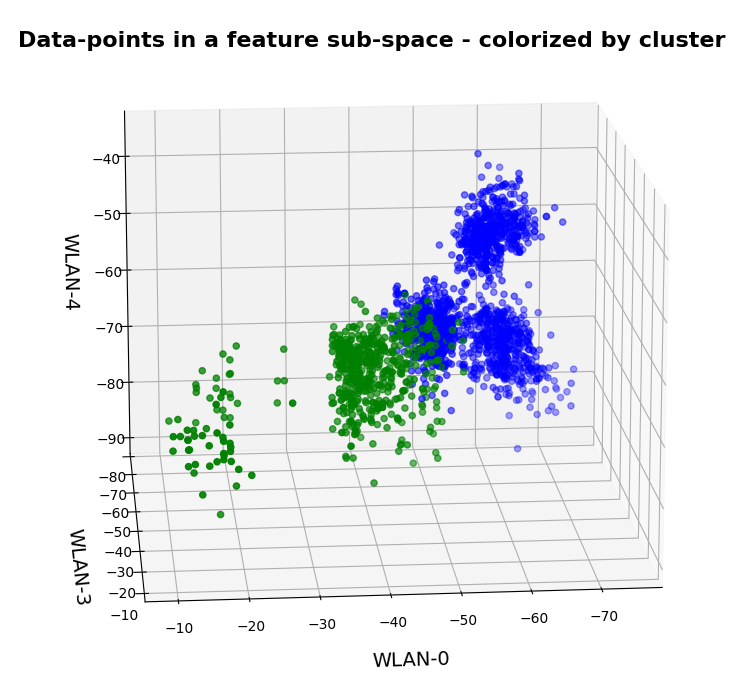
Oops, all the beauty is gone! Members of the previously visual dark-red, green and pink “clusters” would now certainly be members of the first defined “green” cluster. And members of the visual pink and orange clusters would now be members of the “defined” blue cluster. So: Labels may but do strong>not always define clusters.
An important thing we learned by this consideration is that we should at least use a number of cluster greater or equal the number of labels.
But even then the separation may not work. Let us imagine three rooms: In room “A” we only have male persons, in room “B” only female persons and in the third room “C” female persons on one side of the room and male persons on the other – like in some old fashioned dancing courses. If we used the persons’ coordinates to define features and the “male”/”female” attributes as labels and tried a cluster analysis in the feature space we would clearly identify three clusters. However, in the cluster for room “C” we would find a mixture of samples with different labels. Spatial vicinity in the feature space does not mean class identity and a label does not necessarily mean a big distance in the feature space.
Hyperplanes and clusters
The only thing you can hope for with respect to a solvable ML problem is that the data points for different labels may be distributed such that a complicated and curved hyperplane can be found in the multidimensional feature space which separates groups of data points with the same label sufficiently well. But this hyperplane does not necessarily coincide with fictitious borders of some clusters identified by KMeans. We are lucky if the topologically closed surface of a cluster lies completely in a region of the hyperspace separated by complex and topologically open hyperplanes separating data points belonging to one class from other feature space regions which contain data points with different labels.
Not all data ensembles in ML will fall apart in extended clusters each of which dominated by some specific label. Ring like distributions of data samples with identical labels may pose a problem to cluster algorithms – mot only in 2 dimensions.
On the other side: If the labeled data – after some useful transformation – are not well separable in the feature space, then the posed ML task is problematic anyway and the chosen feature definitions may not be appropriate.
Granularity: Hope for label dominance in sufficiently fine grained clusters
What does a label-cluster correlation depend on? Well, if there is an important factor regarding the position of the centroids of KMeans then it is the number of clusters. In the extreme case of as many clusters as data points a super-well defined cluster/label-association exists – but it is not of much use for ML-task. It just represents the most extreme case of overfitting you can think of. It will be useless for new unknown samples.
But the example with the distribution of male/female samples gives you an indication of what we should try: With a growing number of cluster the chances for a fine grained separation into clusters residing on one side of a hyperplane separating samples of different labels rises and with it the chance for a clearer dominance of one label per cluster. This is even true for ring like data distributions: With more then 4 clusters we may even describe a ring like data distribution quite well.
Therefore: If the sample distribution has some reasonable separation hyperplane at all there is a chance that you may find a number of clusters for which each cluster is dominated by a specific label.
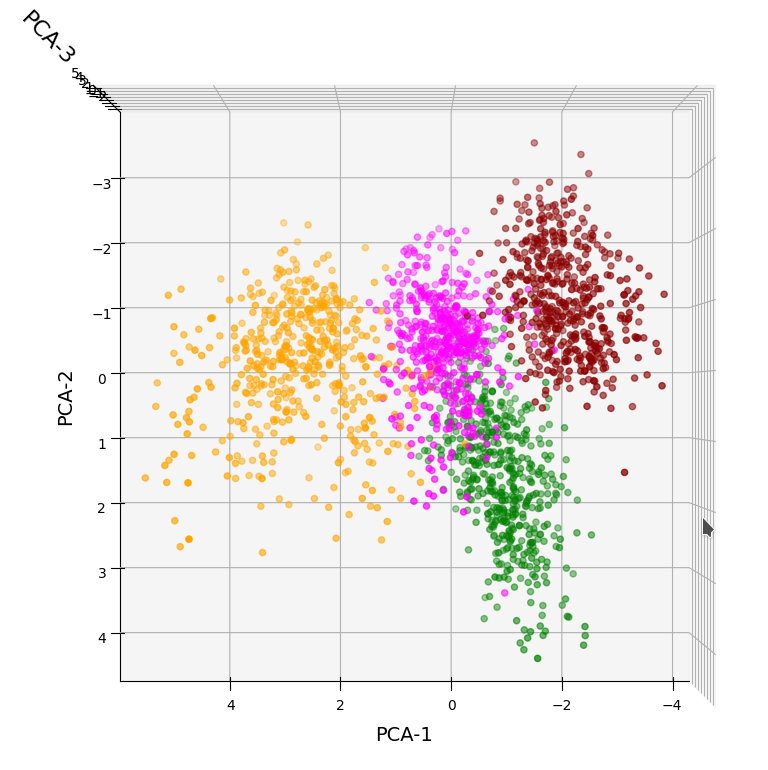
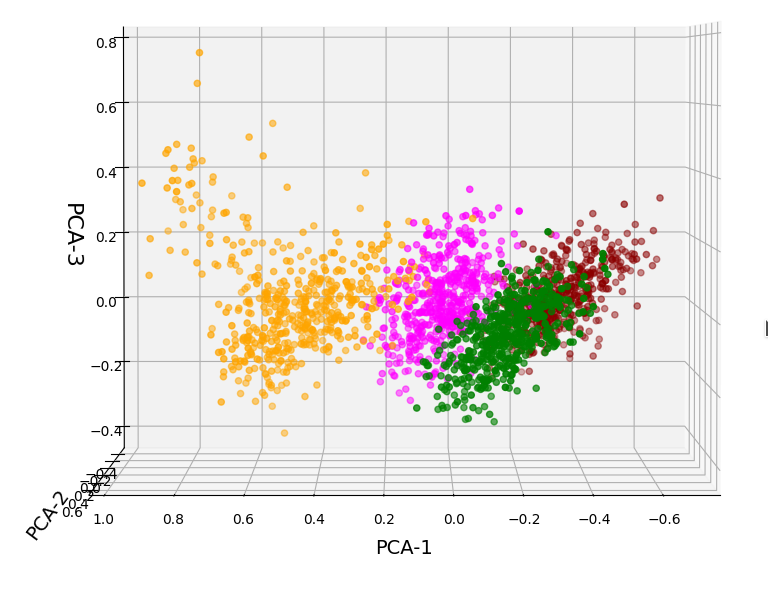
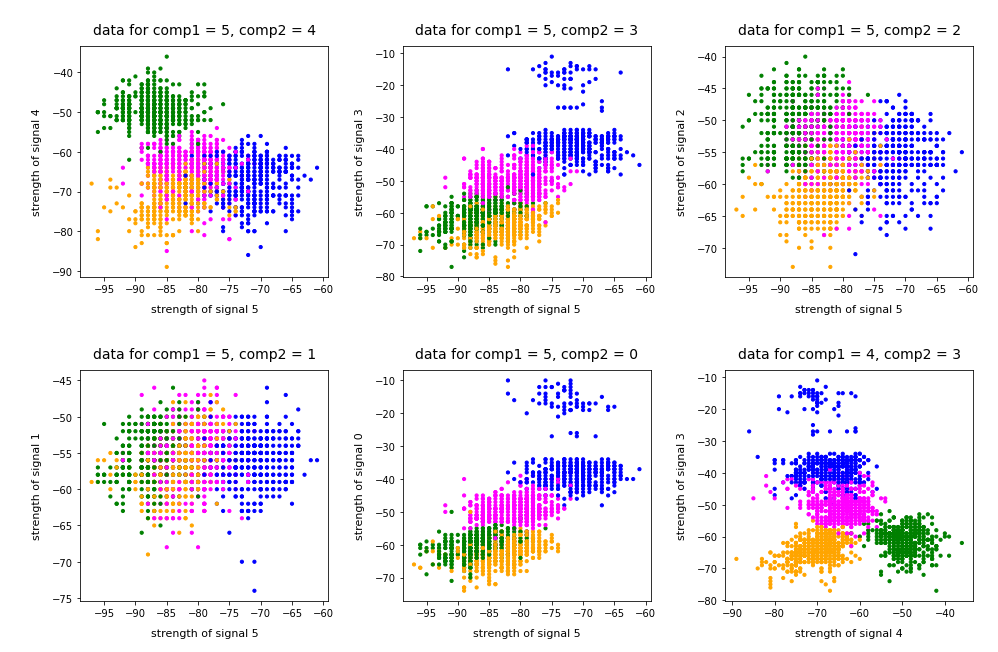
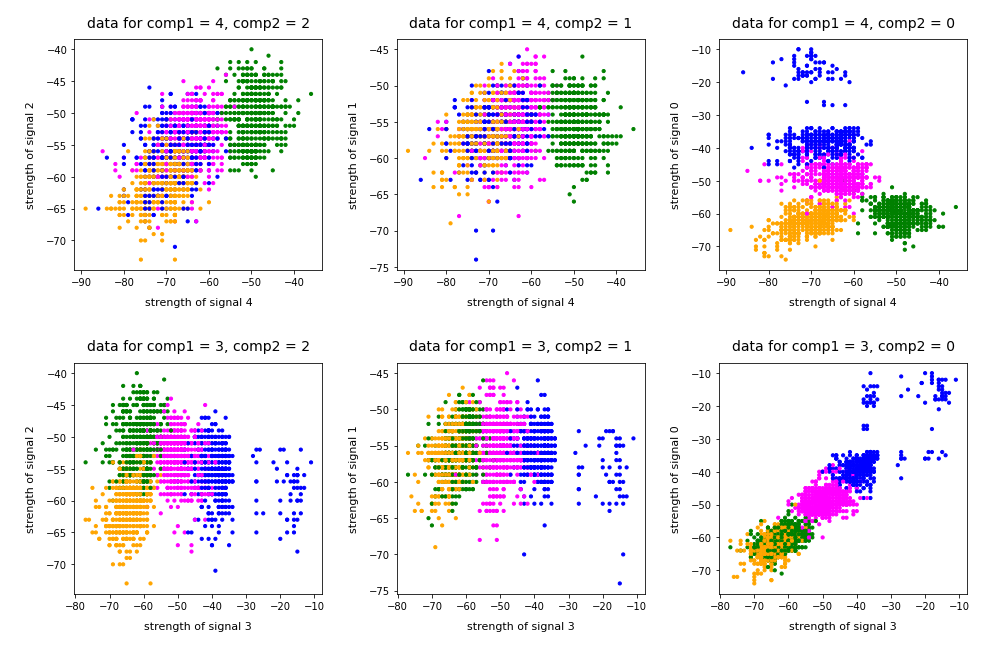
In the case of the WIFI example this is pretty obvious. The following first plot shows the data points colorized according to their labels:
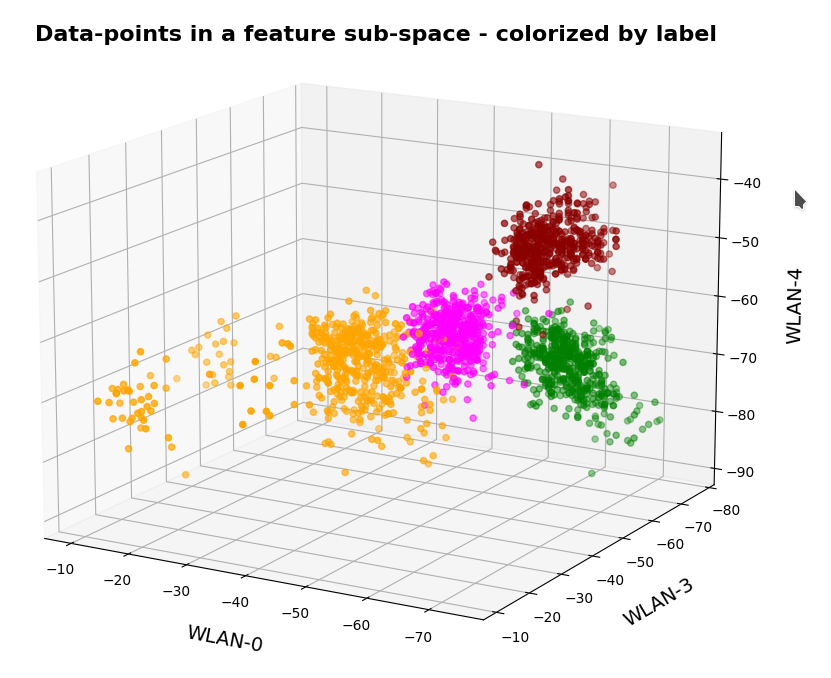
The next plot shows four cluster – with data points colorized according to their cluster membership:
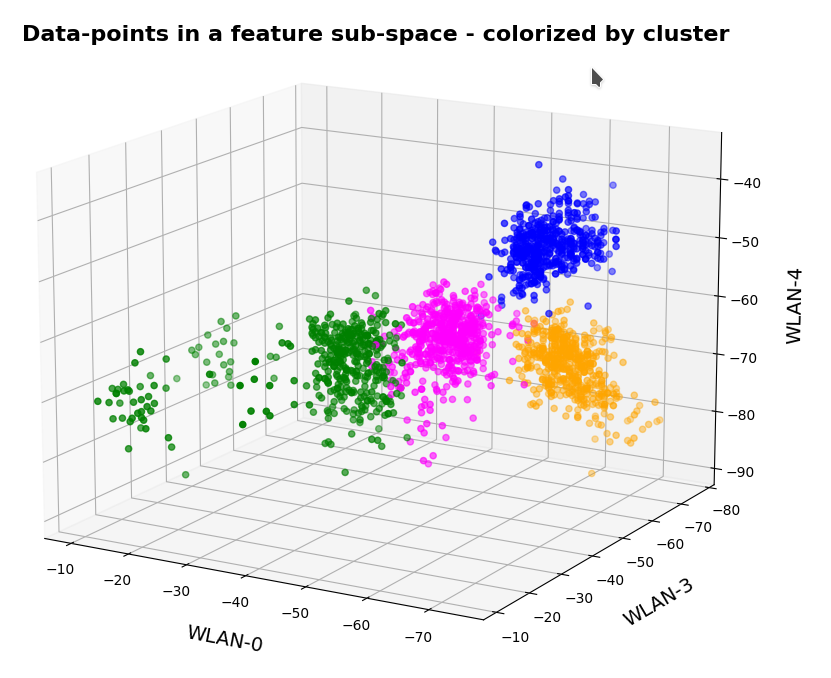
The colors are different (we have no control of it) – but the different data point “clouds” in the pictures coincide rather well. Only some data points do not behave well. We can again use the trick we iused in 2 dimensions and superimpose data points with colorization according to cluster and class:
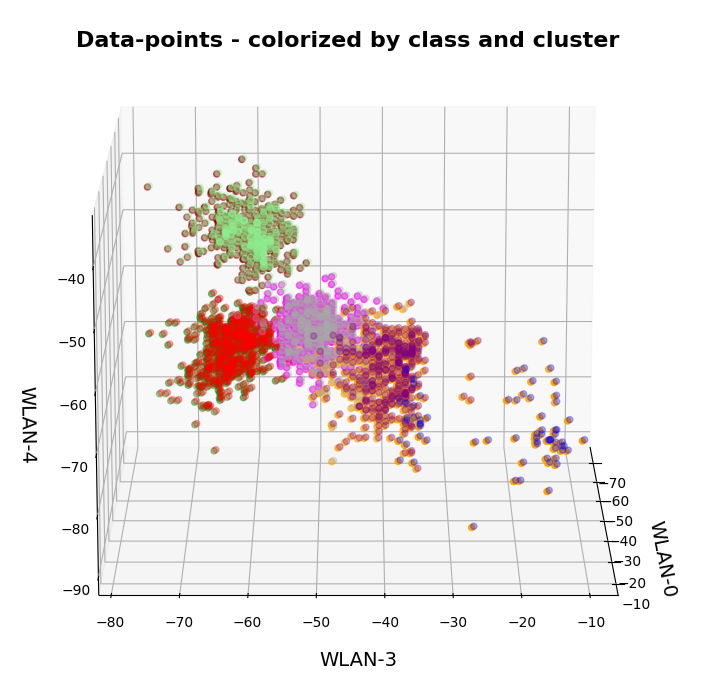
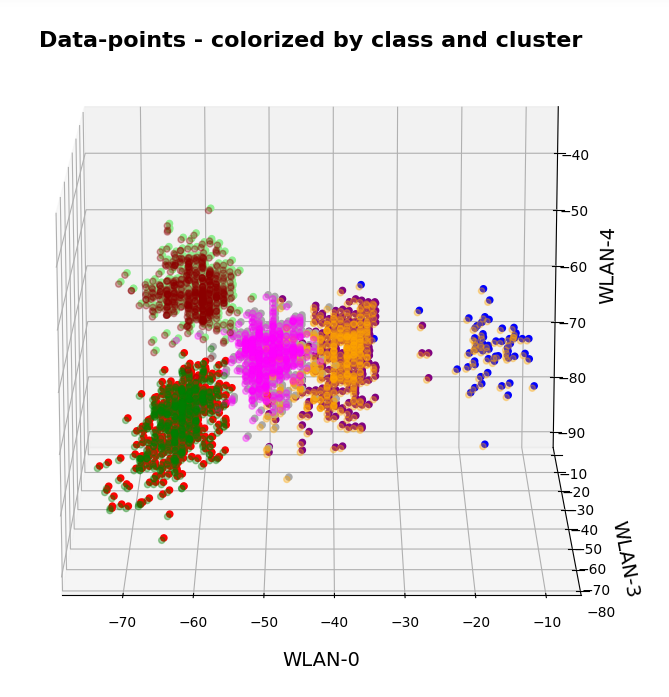
How do we define a classifier by the help of KMeans?
We need a predict()-function which predicts a label from a predicted cluster membership. The recipe is rather simple:
Define the number of cluster you want to use.
- Use KMeans for a cluster analysis of a training set of samples.
- Predict the cluster-membership of a sample with the help of the fitted kmeans-object and its predict()-function.
- Get the labels of the samples belonging to a specific cluster.
- Find out what the amount of samples with a certain label for a cluster is and compared the data.
- Find the label which contributes most samples to a cluster. Check the relative amount of deviating data points with other labels. Should be sufficiently small…
- Build a dictionary which associates the cluster number with its dominant label.
- Build a prediction function for yet unknown data points. It first predicts the cluster and then the associated label.
You should then test the accuracy of your new cluster-based classifier model on test data.
More clusters than labels?
What will happen to such an algorithm if you use more clusters than labels? Short answer: Nothing – as long as each cluster is really dominated by a specific label. More precisely: A vast majority of your clusters should exhibit contributions from data points with one specific label to an amount significantly far beyond the statistical average. Having more clusters means that under reasonable conditions we just have more than one cluster predicting a certain label. For the case of the WIFI example this means that we can work with five clusters without getting nervous.
Application to the WIFI example
As the clusters represent the labels quite well we expect very good values for the recall values. The experiment is pretty simple. I just present the resulting confusion matrices for the four labels (identifying rooms) and different numbers of clusters “nclus”. I first show you a presentation with seaborn, which explains, how to interpret rows and columns:
nclus = 5
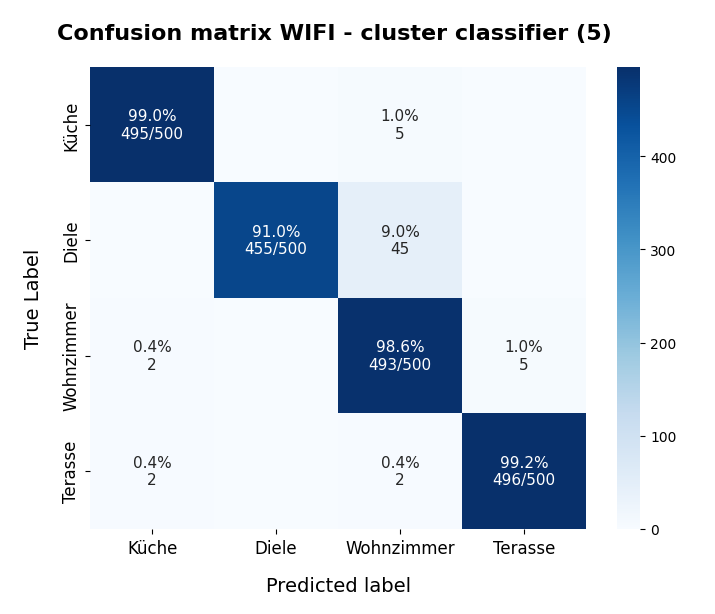
Here I used five (5) clusters and included all samples in the calculation. I.e. I did not separate a training set from a test set of data points.
Confusion matrices for different numbers of clusters
nclus = 4
[[496 0 4 0] [ 0 425 75 0] [ 2 0 492 6] [ 2 0 2 496]] num of wrongly predicted samples: 91 :: avg_err = 0.0455
The “avg_err” gives you the number of wrongly predicted samples divided by the total number of samples. We see that 4 clusters have a problem with the differentiation of the data points for the room “Diele”.
nclus = 5
[[495 0 5 0] [ 0 455 45 0] [ 2 0 493 5] [ 2 0 2 496]] num of wrongly predicted samples: 61 :: avg_err = 0.0305
nclus = 6
[[499 0 1 0] [ 0 452 48 0] [ 5 0 490 5] [ 2 0 2 496]] num of wrongly predicted samples: 63 :: avg_err = 0.0315
nclus = 7
[[499 0 1 0] [ 0 492 8 0] [ 4 38 455 3] [ 2 0 3 495]] num of wrongly predicted samples: 59 :: avg_err = 0.0295
nclus =
num wrongly predicted samples: 58 :: avg_err = 0.029
nclus = 9
[[499 0 1 0] [ 0 484 16 0] [ 4 16 476 4] [ 2 0 2 496]] num of wrongly predicted samples: 45 :: avg_err = 0.0225
All data above were derived for the same random_state-variable to KMeans.
However, this result depends on the initial shuffling of the samples, the random_state parameter and the initial statistical distribution of the centroids by KMeans. And other hyperparameters … The next plot shows a slightly different result for nclus = 9:
nclus = 9
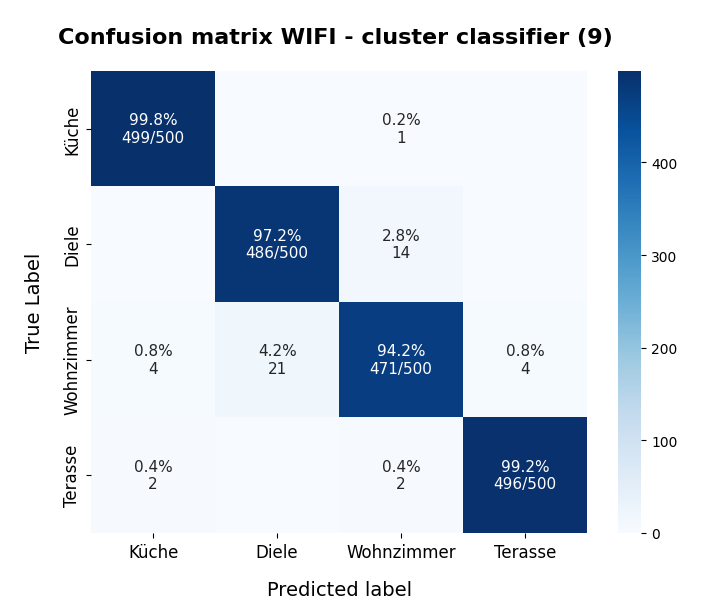
This means: Nine cluster give us a reasonably fine grained resolution in the case of the WIFI example.
But: Note that the problem areas in the confusion matrix have changed. “Diele” is handled a bit better, but “Wohnzimmer” is not so sharply separated as before. This is not astonishing as we saw a significant mix of data of different labels for different clusters above already:
After nclus = 9 we do not get much better – and dance around an average error of 0.025 => 2.5%:
nclus = 10
num of wrongly predicted samples: 55 :: avg_err = 0.0275
nclus = 11
num of wrongly predicted samples: 52 :: avg_err = 0.026
nclus = 25
num of wrongly predicted samples: 40 :: avg_err = 0.02
Being conservative we can say that our simple cluster based classifier approaches an accuracy around 97.4%. Not so bad regarding the crudeness of our approach! A random forest algorithm reaches something above 98.2%. This is not so much better.
Results after a separation of test data samples
I divided the data set than into 1500 train and 500 test samples.
For 9 clusters I got:
nclus = 9
[[374 0 1 0] [ 0 362 13 0] [ 3 17 352 3] [ 2 0 2 371]] num wrongly predicted train samples: 41 :: avg_err = 0.027333333333333334 num wrongly predicted train samples: 8 :: avg_err = 0.016
But these numbers depend strongly on the splitting – even if we split stratified. Another run gives:
nclus = 9
[[374 0 1 0] [ 0 352 23 0] [ 3 0 369 3] [ 1 0 2 372]] num wrongly predicted train samples: 33 :: avg_err = 0.022 num wrongly predicted test samples: 11 :: avg_err = 0.022
Other runs may even give higher average error values. The variation depend upon of how many critical data points in the intermixing zone were omitted in the train samples. At least the results are not too different from the ones named above.
Conclusion
In this article I presented a very simple method by which a cluster algorithm can be used as a classifier. When we applied the approach to the rather simple WIFI example we saw that this worked pretty well.
What we in addition should try is to combine the classifier with a dimension reduction based on a PCA-analysis. From the results of a previous post we would expect that a cluster classifier should work well on the WIFI data after a transformation and projection of the samples’ data points into a 3-dimensional space spanned by the most important orthogonal main component axes. This is the topic of the next post in this series:
KMeans as a classifier for the WIFI and MNIST datasets – IV – KMeans on PCA transformed data
Ceterum censeo: The worst fascist today who must be denazified is the Putler.