
Wieder mal ein Beitrag aus dem bunten Linux-Alltag. Diesmal zum Thema Wörterbücher. Auch hier nimmt die Vielfalt und damit die Verwirrung des Anwenders zu, wie ich heute wieder erfahren durfte.
Das Vielfalts-Problem
Meine liebe Anne ist Norwegerin und benutzt ein Opensuse Linux mit deutschem KDE 4. Nun steht sie natürlicherweise immer mal wieder vor folgenden Aufgaben
- Verfassen von E-Mails auf Norwegisch mit Thunderbird
- Verfassen von E-Mails auf Norwegisch auch mal mit Kmail
- Verfassen von norwegischen Texten mit Openoffice
In all diesen Fällen möchte sie natürlich gerne eine Prüfung der Rechtschreibung der Wörter in norwegischer Sprache vornehmen lassen, um Tippfehler schnell korrigieren zu können.
Leider ist es nun nicht so, dass für diese Aufgabe unter Linux/KDE ein einheitlicher Spell-Checking-Mechanismus herangezogen würde, der sich auch einheitlich bedienen ließe. Und deswegen lief bei der guten Anne heute das Linux-Frustrations-Fass mal wieder über – mit der unmissverständlichen Aufforderung, ihr gefälligst ein brauchbares Arbeitsgerät bereitzustellen.
Tatsächlich muss man feststellen, dass in puncto “spell checking” zur Verzweiflung des Anwenders eine Vielfalt blüht, die nicht nur applikations- sondern auch noch versionsabhängig ist. Und in den von meiner Frau benutzten Anwendungen muss man doch recht spezielle Schritte unternehmen, um zum Erfolg zu kommen.
So wurde bei Openoffice mit dem Übergang von OO 2.4 auf OO 3.0 von “myspell” auf “hunspell” gewechselt. Gleichzeitig kam für den Anwender (oder den Admin) die Notwendigkeit, “add-ons” installieren zu müssen. So mancher Admin, der sich nicht um individuelle EInstellungen kümmern mochte, vergaß allerdings, seine Kollegen/innen auf diesen Umstand hinzuweisen.
Ähnliches gilt für Thunderbird und Firefox; auch hier wurde mit der Version 3 auf “hunspell” gewechselt. Blöd nur, dass einige der für Firefox und Thunderbird bereits etablierten “add on” Wörterbucher – leider auch die norwegischen – wegen Kleinigkeiten eine ganze Weile lang nicht mehr mit Firefox Version 3.6 und Thunderbird Version 3.x kompatibel waren.
KDE 4 setzt dagegen auf die GNU “aspell”-engine, die “ispell” ablöste und mit UTF-8 umgehen kann. Hier müssen die notwendigen Basis-Einstellungen für eine Reihe von KDE-Applikationen nicht in den Applikationen selbst, sondern in den KDE-Systemeinstellungen vorgenommen werden.
Was also muss man unter Opensuse 11.2 und KDE 4.4.3 für die oben genannten Anwendungen genau tun, um z.B. ein norwegisches Spell Checking hinzubekommen?
Maßnahmen für KDE und damit auch für Kontact/Kmail
Man installiere (z.B. über Yast) zunächst die erforderlichen “aspell”-Sprach-Pakete (myspell-Pakete nutzen hier nix!). Im Fall von Norwegisch sind das die Pakete “aspell-nb” (bokmaal) und “aspell-nn” (nynorsk). Danach kann man unter KDE4 über die Systemeinstellungen
“Systemeinstellungen >> Land/Region und Sprache >> Rechtschreibprüfung”
kontrollieren, dass die Korrekturmöglichkeiten für die neuen Sprachen zur Verfügung stehen. Die “automatische Prüfung” aktiviert man über die entsprechende Checkbox. Einzelne KDE-Applikationen haben aber wieder eigene Schalter, die die Aktivierung oder Deaktivierung einer automatischen Rechtschreib-Prüfung während der Texteingabe steuern.
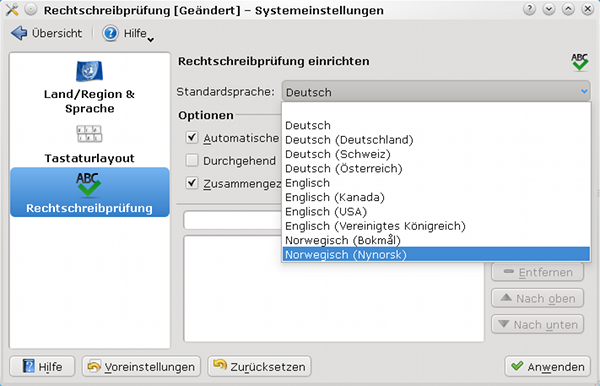
Als Standardsprache haben wir in unserem
Fall “Deutsch” als Einstellung belassen. (Wenn man aber eher Texte in einer anderen Sprache verfasst, lohnt sich ggf. eine andere Einstellung.)
Unter Kmail setzt man das Spell Checking für Norwegisch dann nach dem Öffnen des Mail-Editors für eine neue E-Mail wie folgt ein:
Erst einmal die “automatische Rechtschreibprüfung” über den Menüpunkt “Optionen >> automatische Rechtschreibprüfung” deaktivieren, um bei der Eingabe des norwegischen Textes nicht von vornherein durch irritierende rote Linien gestört zu werden. Danach die ersten Zeilen schreiben. Dann “Extras >> Rechtschreibung” wählen. In der Dialogbox die richtige norwegische Sprache auswählen und nach Bedarf korrigieren. Danach kann man übrigens die “Automatische Korrektur” auch wieder anschalten. Der Spell Checker merkt sich diese Einstellung für die aktuelle Mail.
Es gibt jedoch ein vereinfachtes Vorgehen: Im Kopf der zu verfassenden Mails kann man sich eine Combox anzeigen lassen, die einem eine Combox “Wörterbuch” zur Sprachauswahl für die zu erstellende Mail anbietet. Diese Anzeige steuert man im E-Mail-Editor über den Menüpunkt “Ansicht” und die dort verfügbaren Optionen.
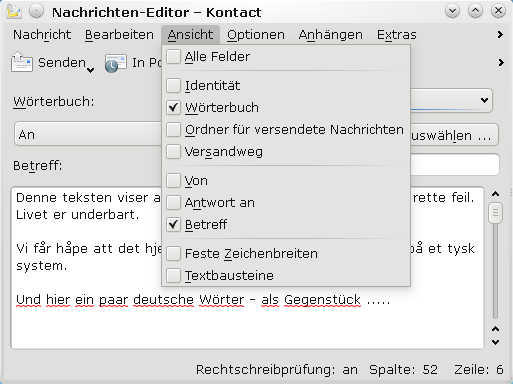
Das vereinfacht den Einsatz des Spell Checkings pro Mail natürlich kolossal: Im Gegensatz zum oben beschriebenen “Umweg” über die Menüpunkte legt man die für die neue E-Mail geltende Sprache gleich nach dem Öffnen des Mail-Editors fest. Die automatische Korrektur kann dann immer aktiviert bleiben.
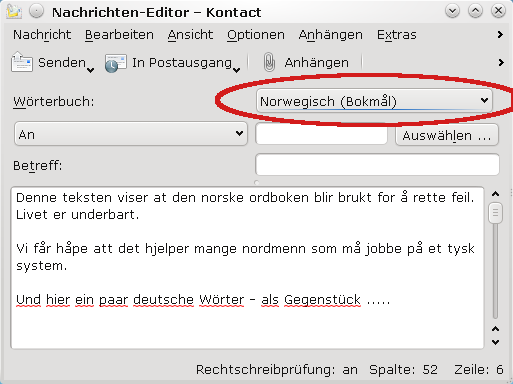
Die Combobox ist vor allem dann wirklich sehr nützlich, wenn man abwechselnd Mails in unterschiedlichen Sprachen erstellt und dabei fortlaufend den Spell Checker einsetzen will.
Maßnahmen für Openoffice (OO) 3.x
Zunächst prüft man mit Hilfe des Paketmanagers seines Vertrauens, dass “hunspell” installiert ist. Bei dieser Gelegenheit das Paket für den Openoffice-Thesaurus für “Norwegeisch-Bokmaal” installieren (Paket “OpenOffice_org-thesaurus-nb”), falls das Paket angeboten wird.
Danach ein aktuelles “Add-on” für die norwegische Sprache aus dem Fundus der OO 3 Extensions installieren. Fündig wird man auf der Webseite
http://extensions.services.openoffice.org/en/dictionaries
Von dort lädt man für das Norwegische das oxt-File
“dictionary-no-NO-1.0.oxt”
herunter und installiert es in OO 3.0 über den Menüpunkt “Extras >> Extension Manager”. Danach OO neu starten. (oxt steht für Openoffice extension).
Die Rechtschreibungprüfung steht unter OO 3 ggf. bereits über ein Symbol in der Haupt-Toolbar-Leiste zur Verfügung. Wenn nicht kann man sich die Leiste um das entsprechende Icon erweitern. Ansonsten benutzt man “F7” und/oder die Sub-Menüpunkte unter dem Menüpunt “Extras” :
“Rechtschreibung und Grammatik, Sprache, Language Tool”
Im Dialogfenster zur “Rechtschreibung und Grammatik” kann man schließlich die Sprache für die Analyse des Dokumentes oder eines markierten Abschnittes auswählen. In unserem Fall stehen nach Installation des oben genannten oxt-Files die zwei norwegischen Sprachen “bokmaal” und “nynorsk” zur verfügung. Die Anwendung der Rechtschreibhilfe im Rahmen des Dialog ist intuitiv möglich. Auch die (begrenzte) Prüfung der Grammatik kann
man aktivieren.
Für das Anschalten einer automatischen Prüfung ist ein Punkt unter “Optionen” im Dialog-Fenster zuständig. (Oder alternativ ein Icon in der Toolbar).
Erstellt man Dokumente mit Abschnitten, die in unterschiedlichen Sprachen verfasst sind, legt man die Sprache pro Abschnitt über den Menüpunkt
“Extras >> Sprache >> Für den Absatz ”
fest. Das ist aus meiner Sicht eine wirklich nützliche Funktion! OO merkt sich die Sprach- und damit auch die einzusetzenden Prüf-/Korrektur-Module für die jeweilige Sprache abschnittsweise.
Natürlich kann man aber auch die Sprache für das gesamte Dokument festlegen. Diese Einstellung oder noch globalere sind auch über
“Extras >> Optionen >> Spracheinstellungen >> Sprachen ”
und
“Extras >> Optionen >> Spracheinstellungen >> Linguistik”
möglich. Der letztere Menüpunkt gibt zudem einen interessanten Einblick in die verwendeten Sprach- und Hyphenation-Module – es lohnt sich, da mal reinzuschauen.
Maßnahmen für Thunderbird und Firefox 3.x
Der Entwickler Håvar Henriksen hat für Bokmaal und Nynorsk schon im Jahr 2008 geeignete Wörterbücher als Add-Ons zu den Mozilla-Applikationen zur Verfügung gestellt. Leider liefen diese eine Weile nicht mit den neuesten Versionen von FF und Thunderbird zusammen. In der aktuellen Form der Bereitstellung gibt es aber keine Probleme mehr. Die folgenden Schritte sind praktisch identisch für FF und Thunderbird:
Zunächst den Menüpunkt “Extras >> Add-ons ” anklicken.
Im sich öffnenden Dialog den Menüpunkt “Alle Add-ons ansehen” wählen . Auf der sich öffnenden Webseite in der rechten oberen Combobox den Punkt “Wörterbücher” für die Suche auswählen. Dann die Suche starten und in der Liste blättern. Ca. auf Seite 3 findet man dann die “Norsk Bokmaal ordliste”. Das entsprechende xpi-File
“norsk_bokm__l_ordliste-2.0.10.0-fx+tb+sm.xpi”
lädt man sich am besten auf seinen Rechner herunter (für den Fall späterer Neuinstallationen).
Danach wechselt man wieder zum immer noch offenen “Add-On”-Dialog-Fenster der Mozilla-Applikation (das Fenster hatte man mit “Extras >> Add-ons” geöffnet). Dort findet man links unten einen Button “Installieren …”, den man anklickt. Der Rest der Installation wird über Dialogboxen geführt; man sucht die eben heruntergeladene Datei und startet den Installationsvorgang.
In Thunderbird 3..0.2 bedient man sich des installierten Wörterbuchs nun über einen entsprechenden Punkt in der Toolbar. Hier verbirgt sich rechts neben dem Schalter übrigens (ähnlich wie bei Kmail) auch eine Combobox; diese erlaubt einem, das einzusetzende Wörterbuch für die jeweilige Sprache auf einfache Weise auszuwählen.
Ansonsten kommt man auch über den in diesem Zshg. missverständlich lautenden Menüpunkt “Einstellungen” zum Ziel. Dort findet man den Submenü-Punkt “Rechtschreibprüfung”, den man anklickt. Die sich öffnende Dialogbox ist einfach zu bedienen. Eine automatische Prüfung während der Texteingabe aktiviert man in Thunderbird über “Einstellungen >> Sofort-Rechtschreibprüfung”.
Fazit
Das Einstellen der Rechtschreibprüfung auf der Basis passender Wörterbücher zeichnet sich unter
Linux noch durch eine wenig anwenderfreundliche Heterogenität aus, ist aber durchaus möglich. Selbst meien Anne war nach getaner Arbeit zufrieden.
In diesem Sinne wünsche ich den Linux-Usern also viel Spass in Zukunft beim Einsatz des “Spell Checkings” für unterschiedliche Sprachen unter KDE, Kontact/Kmail, Openoffice und Firefox/Thunderbird !
Von den Entwicklern wünsche ich mir dagegen eine Strategie zur Vereinigung der “Spell Checking”-Verfahren.
Anhang 1 – Tastaturlayouts nicht vergessen!
Unter KDE ist es natürlich flankierend wichtig, Tastatur-Layouts einzurichten. Das Norwegische kennt wie vele andere Sprachen auch Sonderzeichen, die auf bestimmte Tasten gelegt sind. Die Anne will beim Tippen in norwegischer Sprache natürlich so arbeiten wie auf einer norwegischen Tastatur.
Zu den Tastatur-Layout-Einstellungen gelangt amn unter KDE 4 über die “Systemeinstellungen >> Land/Region und Sprache >> Tastaturlayout”. Im Dialogfenster aktiviert man die gewünschten Tastaturbelegungen für unterschiedliche Sprachen und das Anzeigesymbol in der KDE Kontroll-Leiste. Da Leute wie die Anne mit unterschiedlichen Anwendungen in unterschiedlichen Sprachen arbeiten, habe ich ihr unter dem Reiter “Umschalt-Einstellungen” das Umschaltverfahren auf die jeweilige “Anwendung” bezogen eingestellt – statt der Einstellung “Global”, die die Sprache für die gesamte Oberfläche und alle Anwendungen umschaltet.
Anhang 2 – KDE-Koffice-Frust
In den aktuellen Koffice2-Programmen funktioniert das Spell Checking unter Opensuse 11.2 und KDE 4.4 überhaupt nicht.
Aber das ist eh’ egal, weil die Koffice-Entwickler nicht willens sind oder zu wenig Ressourcen haben, um das grauenvolle Font-Rendering unter Koffice 2 abzustellen. Die wiederholten Hinweise im Web, doch für KOffice2 bitte das Subpixel-Hinting bei der Font-Glättung abzustellen, ist einfach indiskutabel. Hier wedelt aus Anwendersicht der Schwanz mit dem Hund. KOffice2 soll sich bitte in KDE einfügen und seinen Einsatz nicht von einer Maßnahme abhängig machen, die zur Verschlechterung der Schriftendarstellung auf der gesamten Oberfläche führen würde. Tja, der User hat’s mit einigen KDE-Entwicklern nicht immer leicht. Sorry ….
Links
http://en.wikipedia.org/wiki/MySpell
http://en.wikipedia.org/wiki/Hunspell
http://en.wikipedia.org/wiki/GNU_Aspell