Im vorhergehenden Teil dieser kleinen Reihe zum Aufsetzen eines LAMP-Systems auf einem Strato-V-Server
https://linux-blog.anracom.com/2013/10/03/virtueller-strato-v-server-mit-opensuse-12-3-i/
hatten wir einen kurzen Blick auf die durchaus begrenzte Verwaltungsoberfläche für das Serverpaket geworfen, die Strato anbietet. In diesem Beitrag installieren wir auf dem bereitsgestellten V-Server zunächst Opensuse 12.3. Danach treffen wir erste Maßnahmen, um die Sicherheit des Systems etwas zu verbessern. Dies betrifft das Hochfahren einer einfachen Firewall, aber auch einige Maßnahmen in puncto SSH-Zugang. Die Nummern unserer “Schritte” zur Installation zählen wir einfach weiter hoch.
Schritt 2: Installation eines “Opensuse 12.3”-Minimalsystems
Die Linux V-Server von Strato sind nach ihrer Bereitstellung mit Ubuntu ausgestattet. Wir möchten jedoch gerne Opensuse 12.3 nutzen. (Liegt in diesem Fall nicht nur an mir, sondern auch am Kunden). Der Menüpunkt “Neuinstallation” des Strato-Verwaltungsmenüs hilft uns hier weiter. Dort können wir das zu installierende Betriebssystem auswählen.
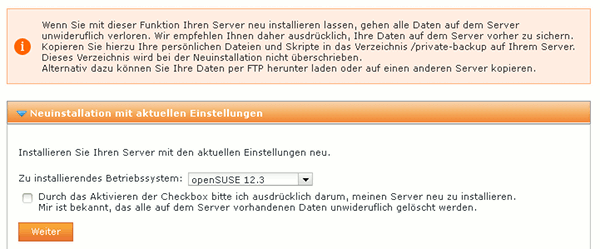
Der Neuinstallationsprozess dauerte bei uns ca. 45 Minuten. Danach war das Strato-System wieder zugänglich. Wer erwartet, nun eine umfangreiche Installation mit Serverdiensten vorzufinden, irrt. Es wird lediglich ein (32Bit-) Minimalsystem mit SSH-Zugang installiert. Die weitere Bestückung mit Serverdiensten obliegt dem Kunden selbst. Hierzu muss er entweder die Web-Administrationsoberfläche “Plesk” verwenden, oder er legt – wie wir – selbst Hand an. [ Ich werde hier nicht in eine unergiebige Diskussion einsteigen, warum ich aufgrund früherer Erfahrungen für die Einrichtung des Servers nicht Plesk verwende].
Um auf dem Server arbeiten zu können, benötigen wir einen Shell-Zugang über SSH.
Schritt 3: Erster SSH-Zugang
Nach der Suse-Installation kann der Standard “ssh-Port 22” für den Shell-Zugang genutzt werden. Die erforderlichen Informationen zum Root-Zugang erhält man unter dem Strato-Verwaltungs-Menüpunkt “Serverkonfiguration >> Serverdaten”. Also auf dem eigenen System (hier mit “mylinux” bezeichnet)
mylinux:~ # ssh root@hxxxxxx.stratoserver.net
mit seiner Serverkennung hxxxxxx eingeben und die Frage nach dem Passwort beantworten. Man landet dann auf einem normalen (roten) SuSE-Shell-Prompt
hxxxxxxx:~#
Die Opensuse Paketverwaltung für die ASCII-Terminaloberfläche ist über das Kommando “yast” selbstverständlich zugänglich. Mit dem SW-RPM-Management (yast-Punkt: “SW installieren oder löschen”) kann man sich dann mal ansehen, was alles installiert ist. Das ist nicht viel. Die vorhandenen Installationsquellen beschränken sich auf die elementaren Repositories und die installierten SuSE-Paketgruppen bzw. Patterns im wesentlichen auf das Basissystem.
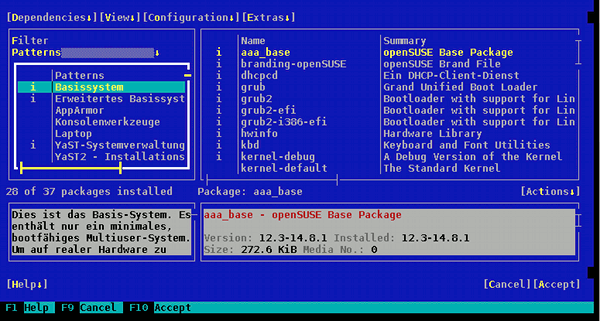
Um das System zu beschäftigen, während wir uns gleich weiteren administrativen Aufgaben zuwenden, installieren wir im Hintergrund mittels “yast” die RPMs des Patterns “WEB- und LAMP-Server”. Ferner installieren wir das RPM-Paket “rkhunter”.
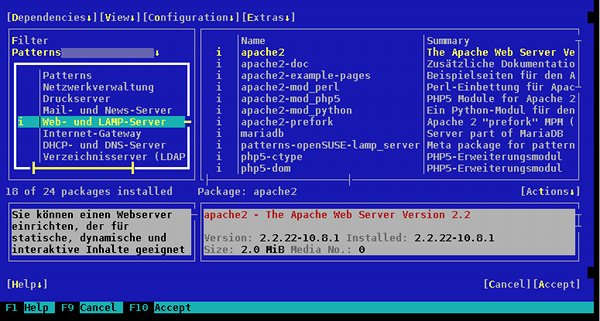
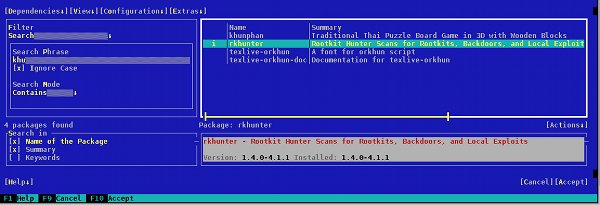
Letzteres Paket liefert ein Programm, das den Host nach Rootkits durchforstet. Wenn man die anlaufende Installation parallel verfolgen will, z.B. um ein Gefühl für die die Netzperformance zu bekommen, öffne man einfach eine zweite Shell auf dem Server.
Schritt 4: Firewall aktivieren
Ein Absetzen des Befehls
hxxxxxxx:~# iptables -L
und ein Blick mit “yast >> Sicherheit und Benutzer >> Firewall” belehren einen darüber, dass auf dem Minimalserver keine Firewall läuft. Andererseits zeigt ein
hxxxxxxx:~# lsof -i
doch einige offene Ports an (sunrpc, ipp,..). Das gefällt uns erstmal nicht. Um die Ports nicht gleich schließen zu müssen, aber doch den Schutz etwas zu verbessern, fahren wir deshalb eine minimale Firewall in Form der Suse-Firewall2 (“yast >> Sicherheit und Benutzer >> Firewall”) hoch.
Achtung- im Umgang mit einer Firewall auf einem Remote-System gibt es ein paar wichtige “Trivialitäten” zu beachten :
- Beim Einrichten einer Firewall auf einem Remote-Server ist eine regelmäßige Grundübung die, darüber nachzudenken, dass man sich nicht selbst aussperrt. Dies impliziert die Freigabe bestimmter Dienste (für bestimmte eigene IP-Adressen) und ggf. auch ein Nicht-Hochfahren der Firewall bei einem Reboot als letztem Rettungsanker.
- Wir müssen bei der Konfiguration der SuseFirewall und vor deren Start erst einmal den Standard “SSH-Port/SSH-Dienst” freigeben. Das ist essentiell, sonst sperren wir uns mit dem Start der Firewall unmittelbar selbst aus.
- Den automatischen Start der Firewall haken wir auf der entsprechenden YaST-Konfigurationsseite (zunächst) nicht an. Dies gibt uns die Chance, bei Fehlern mit der Firewall zumindest über einen Reboot wieder Zugang zum Serversystem zu erlangen.
Nachdem man mal eine laufende und getestete FW-Konfiguration erstellt hat, wird man einen entsprechenden Service zum Anlegen der iptables-Regeln natürlich mit dem Start des Systems automatisch hochfahren lassen. Bei dieser Gelegenheit ist die Anmerkung angebracht, dass Strato technisch begründete Restarts der V-Server oder deren Hosts normalerweise vorab mit E-Mails ankündigt. Man kann sich dann im Bedarfs- oder Zweifelsfall zur Not auch auf ein manuelles Hochfahren seiner Firewall einstellen.
Also:
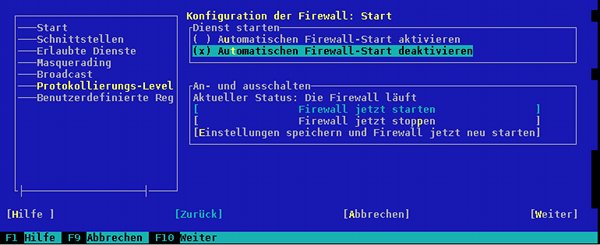
Erst jetzt starten wir die Firewall [FW] mit Hilfe der entsprechenden Optionen unter der YaST-Oberfläche für die SuseFirewall. Nach deren Start sollte man direkt in der geöffneten Shell weiterarbeiten können. Ein erneutes “iptables -L” zeigt uns nun allerdings eine Reihe aktiver Regeln an. Eine Abbildung der wichtigsten Regeln der SuSE-Firewall liefere ich weiter unten nach einer weiteren Einstellung nach.
Hinweis: Diese Firewall-Regeln werden uns später nicht mehr genügen. Im Bereich eingehender Verbindungen ist nun nur noch der SSH-Zugang erlaubt. Die FW läßt im Moment aber noch jede Art von ausgehender Verbindung zu. Das macht es später deutlich schwerer, illegale Aktivitäten
des Servers zu entdecken. Am Ende dieser Artikel-Reihe werden wir deshalb auch ausgehende Verbindungen drastisch beschränken.
Schritt 6: Root Kit-Scan
Bevor wir uns intensiver mit SSH befassen, ist es durchaus sinnvoll, zunächst einen Scan auf bekannte Linux-Root Kits durchzuführen. Als Grund führe ich die Welle an SSH-RootKits an, die Ende Februar dieses Jahres viele gehostete Server betroffen haben. Siehe hierzu die Links am Ende des Beitrags. Wir sollten uns vor weiteren sicherheitsrelevanten Maßnahmen sicher sein, dass wir uns über die Installation und den eigenen SSH-Zugang nicht bereits etwas auf dem System eingefangen haben.
Also :
hxxxxxxx:~# rkhunter -c
Es werden verschiedene Checks durchlaufen – u.a. eben auch auf RootKit-Merkmale. Auf dem Stratoserver mit Opensuse 12.3 kommt es dabei auch zu einigen interessanten Warnungen.
Im Bereich der RootKit-spezifischen Suchen sollte – oder besser muss – aber alles OK sein.
Danach tauchen weitere Warnungen auf:
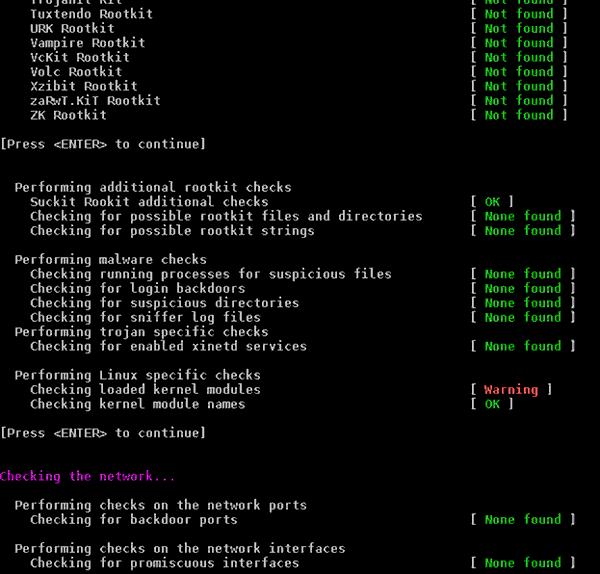
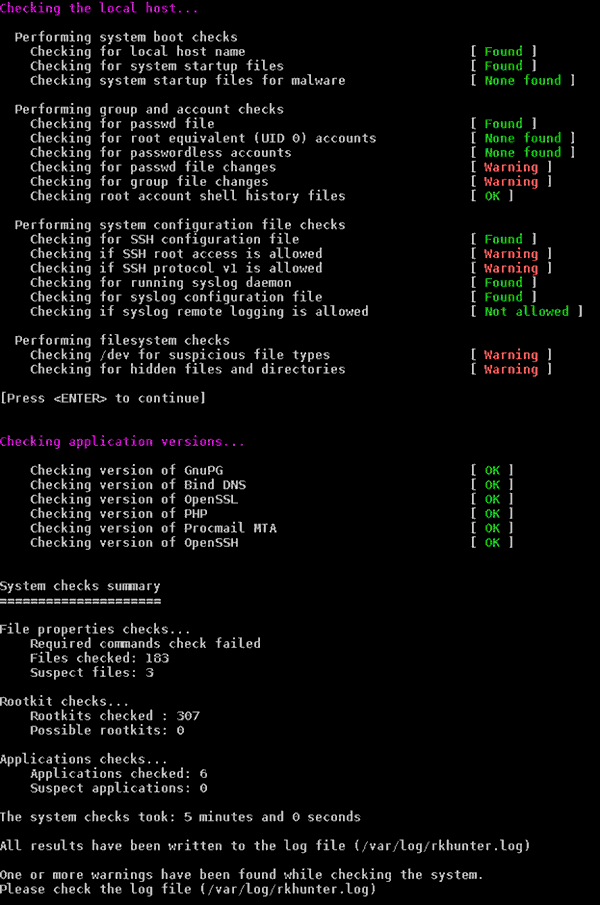
Die Warnungen sollte man übrigens durchaus ernst nehmen und ihnen durch Studium des Logfiles
/var/log/rkhunter.log
einzeln nachgehen. Ich habe das gemacht und in allen Fällen sehr plausible Gründe dafür gefunden, warum die bemängelten Dinge auf dem frisch installierten System dennoch in Ordnung waren. Die Warnungen zu den Kernel-Modules rührt u.a. daher, dass auf dem mit Parallells virtualiserten Systemen keine Kernelmanipulationen der Hosts erlaubt sind und “lsmod” und “modprobe” wegen des fehlenden Hostzugriffs nicht funktionieren. [Das ist anders als z.B. bei KVM.]
Schritt 6: SSH-Port verlagern
Es ist keine gute Idee, den SSH-Port auf der Standardeinstellung 22 zu belassen. Das hilft nur den Script-Kiddies. Ich wähle deshalb für die SSH-Kommunikation immer einen Port weit jenseits normaler hoher Ports. Diese werden nach meinen Erfahrungen nicht so häufig von scripts durchsucht. [Natürlich nutzt eine Port-Verlagerung nichts gegenüber professionellen Angreifern – aber getreu der Weisheit, mehrere Hürden zu staffeln, ist das ein erster ablenkender Schritt.]
Zur Umlenkung des SSH-Ports gilt es, als root einen entsprechenden Port-Eintrag am Anfang der Datei “/etc/ssh/sshd_config” vorzunehmen:
Port XXXXX
Natürlich mit einer vernünftigen großen Zahl für den Port – ggf. oberhalb 60000. Wir speichern die Zeile in der sshd-config ab; wir starten den SSH-Service aber natürlich noch nicht neu. Achtung – vor dem Restart des SSH-Services ist zweierlei zu beachten :
- Den neuen Port muss man sich unbedingt merken ! Sonst kann man sich von seinem lokalen System aus später nicht mehr einloggen.
- Die laufende Firewall muss zuerst für den neuen Port geöffnet werden.
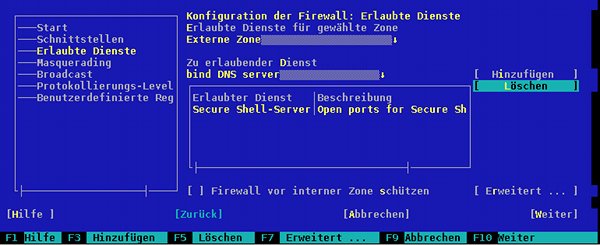
Letzteres erledigen wir wieder mit yast: Auf der Seite “Erlaubte Dienste” nutzen wir den Punkt
“Erweitert” und fügen folgende eigene Regel hinzu:
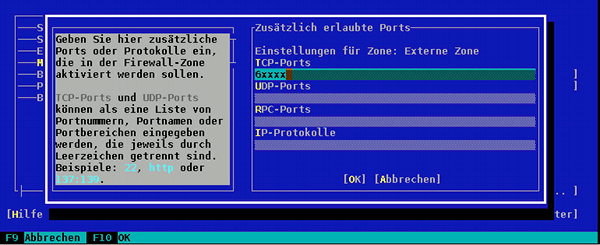
Achtung auch hier: die “6xxxx” sind natürlich nicht wörtlich zu nehmen; hier ist insgesamt exakt die oben in der sshd-Konfigurationdatei angegebene neue Nummer des SSH-Ports zu wählen. Mit F10 speichern wir die neue Firewall- Einstellung ab; den Standard-SSH-Port lassen wir auch noch erstmal offen.
Mit “iptables -L” überzeugen wir uns, dass nun extra Regeln gesetzt wurden, in denen der von uns gewählte Port auftaucht.
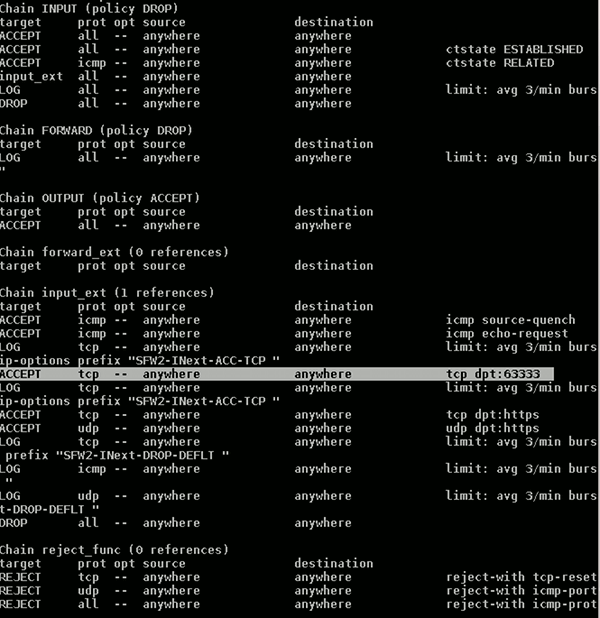
Erst jetzt – also nach dem Speichern und Starten der Firewall mit der neuen Zusatzeinstellung – starten wir den SSH-Service neu. Danach können wir auf der geöffneten Shell nicht nicht mehr weiterarbeiten, den der sshd-Dämon arbeitet nicht mehr auf dem von uns geöffneten Kommunikationsport. Also beenden wir auf dem lokalen System die Shell mit CTRL-C. Wir müssen uns neu mittels SSH anmelden – nun aber unter Angabe des zu verwendenden Ports:
mylinux:~ # ssh root@hxxxxxx.stratoserver.net -p 6xxxx
Und schon sind wir wieder drin.
Schritt 6: Standard SSH-Port in der SuSE-Firewall schließen
Hat unser Zugang über den neuen Port funktioniert, kann man nun den Standard SSH-Port aus der SuSE-Firewall ausschließen. Hierzu entfernt man in den zugehörigen YaST-Firewall-Einstellungen (s. oben) einfach wieder den anfänglich erlaubten SSH-Serverdienst – natürlich aber ohne aber unsere Zusatzeinstellung unter “Erweitert” für den anderen Port zu ändern.
Nächste SSH-Themen
Aber auch das ist bei etwas Nachdenken natürlich nicht eine hinreichend sichere Lösung. Denn:
- Der SSH-Port wurde zwar verschoben – aber er ist immer noch von überall her erreichbar.
- Die Möglichkeit eines Brute Force Angriffes bleibt durch den Passwort-bezogenen Authentifizierungsmechanismus bestehen.
- Root hat SSH-Zugang
Gerade der letzte Punkt ist ein latentes Sicherheitsproblem:
In den vergangenen Jahren gab es mehrere Beispiele dafür, wie Systeme durch Brute-Force-Angriffe auf ssh-Verbindungen auf einfache Weise kompromittiert werden konnten. Der root-User ist ja der am einfachsten zu erratende User-Account und der Brute-Force-Angriff kann sich auf das Knacken des Passwortes beschränken.
Es ist deshalb eine gute Idee, gar keinen SSH-Zugang für den User root, sondern nur für einen unpriviligierten User auf einem geänderten Port zuzulassen. Dadurch muss der Angreifer den Port ermitteln, den User-Namen und ein Passwort erraten. Und wenn ihm dann der Zugang geglückt sein sollte, hat er immer noch keine Root-Rechte, sondern muss nun zusätzlich auch das root-Passwort erraten. Das Sperren des SSH-Zugangs für root erhöht also den Aufwand für Angreifer.
Wie wir root vom SSH-Zugang zu unserem Stratoserver ausschließen, werde ich im nächsten Beitrag
Strato-V-Server mit Opensuse 12.3 – III – Stop SSH Root Login
beschreiben. Danach gehe ich dann auch auf einen zertifikatsbasierten SSH-Zugang ein.
Links
Rootkit Checks
http://xmodulo.com/ 2013/05/ how-to-scan-linux-for-rootkits.html
http://www.rackspace.com/ knowledge_center/ article/ scanning-for-rootkits-with-chkrootkit
Denjenigen, die am Sinn der hier besprochenen und noch kommenden SSH-Maßnahmen zweifeln, empfehle ich, sich in zwei ruhigen Stunden mal folgende Threads im Internet zu SSH-Rootkits, die im Frühjahr dieses Jahres gehostete virtuelle Server befallen haben, durchzulesen und einige der immer wieder auftauchenden Ratschläge bzgl. der Absicherung von SSH zu Herzen zu nehmen:
http://www.webhostingtalk.com/ showthread.php?s=714ab2598f1b14729348957 db7196325&t=1235797
http://forums.cpanel.net /f185/ sshd-rootkit-323962-p5.html
Sonstiges zur SSH-Absicherung
http://www.ibm.com/ developerworks/ aix/ library/ au-sshlocks/
http://www.rackaid.com/ resources/ how-to-harden-or-secure-ssh-for-improved-security/
http://stackful-dev.com/ linux-101-hardening-ssh.html
http://www.lowendguide.com/ 3/security/ how-to-harden-and-secure-ssh-for-improved-security/
http://linuxmoz.com/ how-to-secure-ssh-servers/
