
Ajax and PHP programs run in a more or less complex environment. Very often you want to transfer data from a browser client via Ajax to a PHP server and save them after some manipulation into a MariaDB or MySQL database. As you use Ajax you expect some asynchronous response sent from the PHP sever back at the client. This answer can have a complicated structure and may contain a combination of data from different sources – e.g. the database or from your PHP programs.
If and when all components and interfaces [web pages, Ajax-programs, the web server, files, PHP programs, PHP/MySQL interfaces, MySQL …) are set up for a UTF-8 character encoding you probably will not experience any problems regarding the transfer of POST data to a PHP server by Ajax and further on into a MySQL database via a suitable PHP/MySQL interface. The same would be true for the Ajax response. In this article I shall assume that the Ajax response is expected as a JSON object, which we prepare by using the function json_encode() on the PHP side.
Due to provider restrictions or customer requirements you may not always find such an ideal “utf-8 only” situation where you can control all components. Instead, you may be forced to combine your PHP classes and methods with programs others have developed. E.g., your classes may be included into programs of others. And what you have to or should do with the Ajax data may depend on settings others have already performed in classes which are beyond your control. A simple example where a lack of communication may lead to trouble is the following:
You may find situations where the data transfer from the server side PHP-programs into a MySQL database is pre-configured by a (foreign) class controlling the PHP/MySQL interface for a western character set iso-8859-1 instead of utf-8. Related settings of the MySQL system (SET NAMES) affect the PHP mysql, mysqli and pdo_mysql interfaces for the control program. In such situations the following statement would hold :
If your own classes and methods do not provide data encoded with the expected character set at your PHP/MySQL interface, you may get garbage inside the database. This may in particular lead to classical "Umlaut"-problems for German, French and other languages.
So, as a PHP developer you are prepared to decode the POST or GET data strings of an Ajax request properly before transferring such string data to the database! However, what one sometimes may forget is the following:
You have to encode all data contributing to your Ajax response – which you may deliver in a JSON format to your browser – properly, too. And this encoding may depend on the respective data source or its interface to PHP.
And even worse: For one Ajax request the response data may be fetched from multiple sources – each encoded for a different charset. In case you want to use the JSON format for the response data you probably use the json_encode() function. But this function may react allergic to an offered combination of strings encoded in different charsets! So, a proper and suitable encoding of string data from different sources should be performed before starting the json_encode()-process in your PHP-program ! This requires a complete knowledge and control over the encoding of data from all sources that contribute strings to an Ajax response !
Otherwise, you may never get any (reasonable) result data back to your javascript function handling the Ajax response data. This happened to me lately, when I deployed classes which worked perfectly in a UTF-8 environment on a French LAMP system where the PHP/MySQL interfaces were set up for a latin-1 character set (corresponding to iso-8859-1). Due to proper decoding on the server side Ajax data went correctly into a database –
however, the expected complex response data comprising database data, data from files and programs were not generated at all or incorrectly.
As I found it somewhat difficult to analyze what happened, I provide a short overview over some important steps for such Ajax situations below.
Setting a character set for the PHP/MySQL interface(s)
The character code setting for the PHP/MySQL-connections is performed from the PHP side by issuing a SQL command. For the old interface mysql-interface, e.g., this may look like
$sql_unames = “SET NAMES ‘latin1′”;
mysql_query($sql_unames, $this->db);
Note that this setting for the PHP/MySQL-interfaces has nothing to do with the MySQL character settings for the base, a specific table or a table row! The NAMES settings actually prepares the database for the character set of incoming and outgoing data streams. The transformation of string data to (or from) the character code defined in your database/tables/columns is additionally and internally done inside the MySQL RDBMS.
With such a PHP/MySQL setting you may arrive at situations like the one displayed in the following drawing:
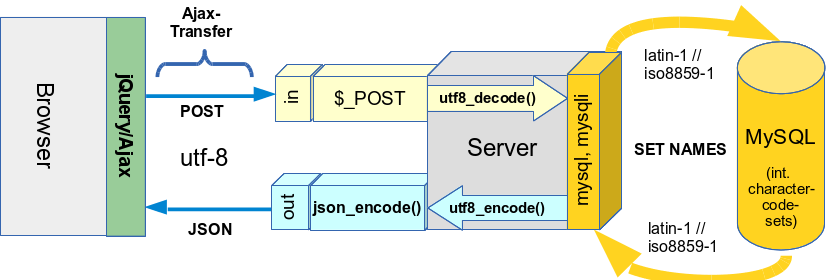
In the case sketched above I expect the result data to come back to the server in a JSON format.
Looking at the transfer processes, one of the first questions is: How does or should the Ajax transfer to the server for POST data work with respect to character sets ?
Transfer POST data of Ajax-requests encoded with UTF-8
Normally, when you transfer data for a web form to a server you have to choose between the GET or the POST mechanism. This, of course, is also true for Ajax controlled data transfers. Before starting an Ajax request you have to set up the Ajax environment and objects in your Javascript programs accordingly. But potentially there are more things to configure. Via e.g. jQuery you may define an option regarding the so called “ContentType” for the character encoding of the transfer data, the “type” of the data to be sent to the server and the “dataType” for the structural format of the response data:
$.ajaxSetup( { …..
ContentType : ‘application/x-www-form-urlencoded; charset=UTF-8’
type : ‘POST’
dataType : ‘json’
…});
With the first option you could at least in principle change the charset for the encoding to iso-8859-1. However, I normally refrain from doing so, because it is not compliant with W3C-requirements. The jQuery/Ajax documentation says:
" The W3C XMLHttpRequest specification dictates that the charset is always UTF-8; specifying another charset will not force the browser to change the encoding."
(See: http://api.jquery.com/jquery.ajax/).
Therefore, I use the standard and send POST data in Ajax-requests utf-8 encoded. In our scenario this setting would lead to dramatic consequences on the PHP/MySQL side if you did not properly decode the sent data on the server before saving them into the database.
In case you have used the “SET NAMES” SQL command to activate a latin-1 encoded database connection, you must apply the function utf8_decode() to utf-8 encoded strings in the $_POST-array before you want to save these strings in some database table-
fields!
In case you want to deploy Ajax and PHP codes in an international environment where “SET NAMES” may vary from server to server it is wise to analyze your PHP/MySQL interface settings before deciding whether and how to decode. Therefore, the PHP/MySQL interface settings should be available information for your PHP methods dealing with Ajax data.
Note, that the function utf8_decode() decodes to the iso-8859-1-charset, only. For some cases this may not be sufficient (think of the €-sign !). Then the more general function iconv() is your friend on the PHP side.
See: http://de1.php.net/manual/de/function.iconv.php.
Now, you may think we have gained what we wanted for the “Ajax to database” transfer. Not quite:
The strings you eventually want to save in the database may be composed of substrings coming from different sources – not only from the $_POST array after an Ajax request. So, you need to control where from and in which charset the strings you compose come from. A very simple source is the program itself – but the program files (and/or includes) may have another charset than the $-POST-data! So, the individual strings may require a different de- or en-coding treatment! For that purpose the general “Multibyte String Functions” of PHP may be of help for testing or creating specific encodings. See e.g.: http://php.net/manual/de/function.mb-detect-encoding.php
Do not forget to encode Ajax response data properly!
An Ajax request is answered asynchronously. I often use the JSON format for the response from the server to the browser. It is easy to handle and well suited for Javascript. On the PHP the json_encode() function helps to create the required JSON object from the components of an array. However, the strings combined into a JSON conform Ajax data response object may come from different sources. In my scenario I had to combine data defined
- in data files,
- in PHP class definition files,
- in a MySQL database.
All of these sources may provide the data with a different character encoding. In the most simple case, think about a combination (inclusion) of PHP files which some other developers have encoded in UTF-8 whereas your own files are encoded in iso-8859-1. This may e.g. be due to different standard settings in the Eclipse environments the programmers use.
Or let’s take another more realistic example fitting our scenario above:
Assume you have to work with some strings which contain a German “umlaut” as “ü”, “ö”, “ä” or “ß”. E.g., in your $_POST-array you may have received (via Ajax) some string “München” in W3C compliant UTF-8 format. Now, due to database requirements discussed above you convert the “München” string in $_POST[‘muc’] with
$str_x = utf8_decode($_POST[‘muc’]);
to iso-8859-1 before saving it into the database. Then the correct characters would appear in your database table (a fact which you could check by phpMyAdmin).
However, in some other parts of your your UTF-8 encoded PHP(5) program file (or in included files) you (or some other contributing programmers) may have defined a string variable $str_x that eventually also shall contribute to a JSON formatted Ajax response:
$str_y = “München”;
Sooner or later, you prepare your Ajax response – maybe by something like :
$ay_ajax_response[‘x’] = $str_x;
$ay_ajax_response[‘y’] = $str_y;
$ajax_response = json_encode($ay_ajax_response);
echo $ajax_response;
n
(Of course I oversimplify; you would not use global data but much more sophisticated things … ). In such a situation you may never see your expected response values correctly. Depending on your concrete setup of the Ajax connection in your client Javascript/jQuery program you may not even get anything on the client side. Why? Because the PHP function json_encode() will return “false” ! Reason:
json_encode() expects all input strings to be utf-8 encoded !
But this is not the case for your decoded $str_x in our example! Now, think of string data coming from the database in our scenario:
For the same reason, weird things would also happen if you just retrieved some data from a database without thinking about the encoding of the PHP/MySQL interface. If you had used “SET NAMES” to set the PHP/MySQL interface to latin-1, then retrieved some string data from the base and injected them directly – i.e. without a transformation to utf-8 by utf8_encode() – into your Ajax response you would run into the same trouble as described in the example above. Therefore:
Before using json_encode() make sure that all strings in your input array – from whichever source they may come – are properly encoded in UTF-8 ! Watch out for specific settings for the database connection which may have been set by database handling objects. If your original strings coming from the database are encoded in iso-8859-1 you can use the PHP function ut8_encode() to get proper UTF-8 strings!
Some rules
The scenario and examples discussed above illustrate several important points when working with several sources that may use different charsets. I try to summarize these points as rules :
- All program files should be written using the same character set encoding. (This rule seems natural but is not always guaranteed if the results of different developer groups have to be combined)
- You should write your program statements such that you do not rely on some assumed charsets. Investigate the strings you deal with – e.g. with the PHP multibyte string functions “mb_….()” and test them for their (probable) charset.
- When you actively use “SET NAMES” from your PHP code you should always make this information (i.e. the character code choice) available to the Ajax handling methods of your PHP objects dealing with the Ajax interface. This information is e.g. required to transform the POST input string data of Ajax requests into the right charset expected by your PHP/MySQL-interface.
- In case of composing strings from different sources align the character enprintcoding over all sources. Relevant sources with different charsets may e.g. be: data files, data bases, POST/GET data, ..
- In case you have used “SET NAMES” to use some specific character set for your MySQL database connection do not forget to decode properly before saving into the database and to encode data fetched from the base properly into utf-8 if these data shall be part of the Ajax response. Relevant functions for utf-8/iso-8859-1 transformations may be utf8_encode(), utf8_decode and for more general cases iconv().
- If you use strings in your program that are encoded in some other charset than utf-8, but which shall contribute to your JSON formatted Ajax response, encode all these strings in utf-8 before you apply json_encode() ! Verify that all strings are in UTF8 format before using json_encode().
- Always check the return value of json_encode() and react properly by something like
if (json_encode($…) === false
) {
…. error handling code …
} - Last but not least: When designing your classes and methods for the Ajax handling on the PHP side always think about some internal debugging features, because due to restrictions and missing features you may not be able to fully debug variables on the server. You may need extra information in your Ajax response and you may need switches to change from a Ajax controlled situation to a standard synchronous client/server situation where you could directly see echo/print_r – outputs from the server. Take into account that in some situation you may never get the Ajax response to the client …
I hope, these rules may help some people that have to work with jQuery/Ajax, PHP, MySQL and are confronted with more than one character set.