Im letzten Beitrag
Upgrade-Zeit – Vorsorge durch Fallback-Installationen – I
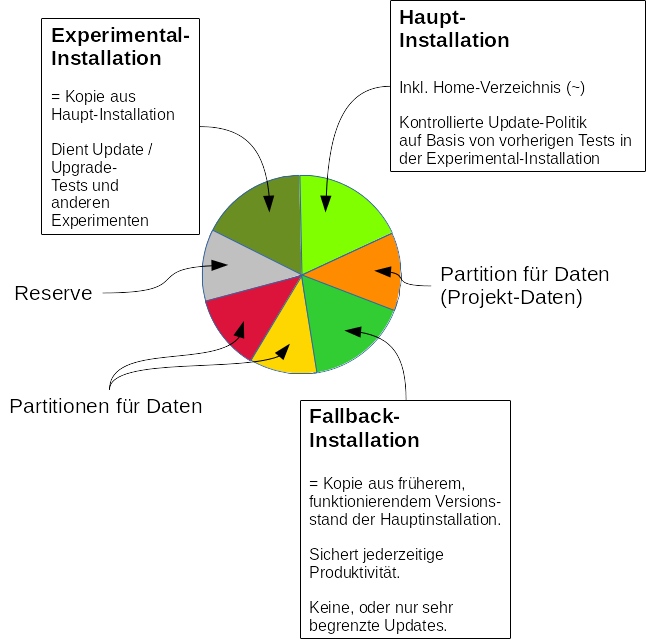
hatte ich versucht darzustellen, wie man mehrere parallele, bootfähige Linux-Installationen auf einem Einzelplatzsystem (PC, Laptop) nutzen kann, um die Arbeitsfähigkeit im Fall von Update/Upgrade-Problemen zu sichern. Man arbeitet normalerweise auf einer “Hauptinstallation“, die zu einer bestimmten Partition (z.B. “/dev/sdf7”) gehört.
Eine Fallback-Installation auf einer separaten Partition (z.B. “/dev/sdf9”) wird dagegen zu geeigneten Zeitpunkten als Abbild (Partitionskopie) eines funktionierenden Zustands der Hauptinstallation erzeugt und danach hinsichtlich von Updates extrem konservativ behandelt.
Updates/Upgrades werden grundsätzlich erst in einer dritten “Experimental-Installation” (z.B. auf “/dev/sdf3”) für Experimente getestet, bevor sie in der Hauptinstallation nachgezogen werden.
Nutz- und Projektdaten des/der Anwender werden dagegen auf speziellen Datenpartitionen untergebracht, die man in den jeweiligen Installationen bei oder nach einem Bootvorgang auf vorgegebene Knoten des Verzeichnisbaumes mountet. Das geschieht auf Basis gleichartiger Einträge für die Datenpartition(en) in den “/etc/fstab”-Dateien der verschiedenen Installationen; z.B.
myexp:~ # cat /etc/fstab
...
UUID=24f67362-236e-49ea-ba38-31c1c2541630 /projekte ext4 defaults 1 2
....
Diese Einträge werden beim Kopieren der entstehen im Rahmen der Erstellung der Fallback- und Experimental-Installation als Kopie der Hauptinstallation automatisch übernommen.
Der Ablauf zur Erstellung und Nutzung der verschiedenen Installationen (auf jeweils unterschiedlichen Partitionen) ist in folgender Abbildung dargestellt:
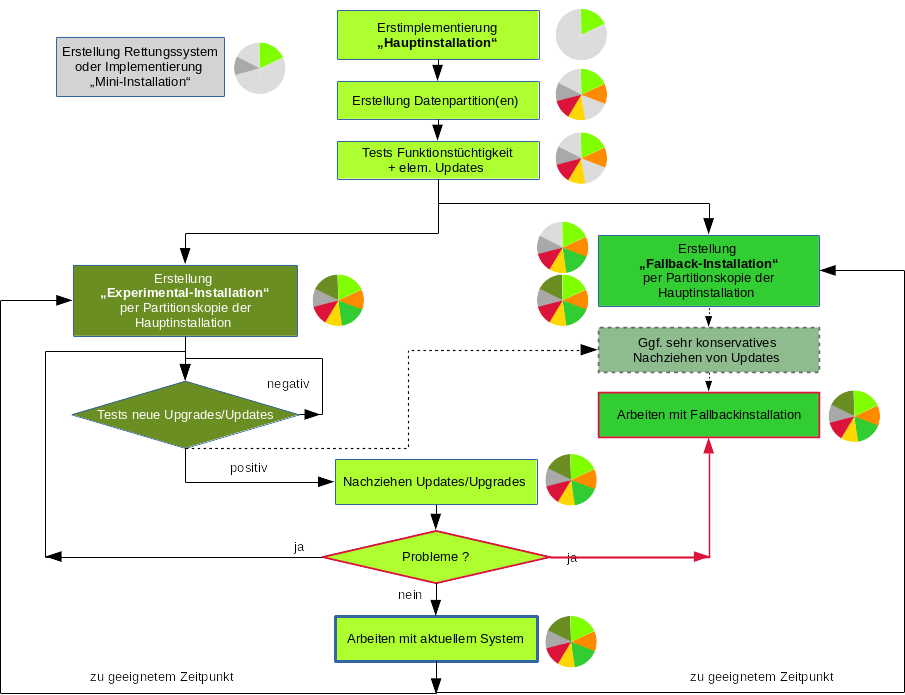
Die Kuchendiagramme deuten die (wachsende) Partitionsverteilung an. Wir gehen nachfolgend auf einige wichtige Punkte ein, die bei der Erstellung von Partitionskopien als Grundlage der Fallback- und Experimental-Installation zu beachten sind.
Die Erst-Installation eines Linux-Systems (z.B. Opensuse Leap 42.2) erfolgt wie üblich aus dem Netz oder per DVD. Man richtet dann seine Datenpartitionen ein und legt zugehörige Mount-Einträge in der “/etc/fstab” fest. Unter Opensuse unterstützt einen dabei der YaST-Partitioner. Dann “gewöhnt” man sich an das neue System und führt erste sinnvolle Updates durch.
Für die Erstellung der Fallback-Installation wollen wir den Inhalt der Partition, die die Hauptinstallation in einem definierten Zustand enthält, in eine andere (freie) Partition kopieren. Eine Kopie des gemounteten Root-Filesystems kann und sollte aber nicht aus der laufenden Hauptinstallation heraus erstellt werden. Der Grund ist einfach: Während der Kopie würden im Hintergrund stattfindende Schreiboperationen beim Kopieren nicht konsistent abgebildet werden. Das gleiche Thema gibt es ja bereits für Backups.
Wir benötigen daher eine weitere unabhängige Minimalinstallation (ohne grafischen Schnickschnack) in einer separaten Partition. Das dortige System booten wir dann zum Erstellen von Kopien anderer nicht gemounteter Partitionen. Alternativ können wir zum Kopieren natürlich auch ein ein Linux-Live-System einsetzen. Für Opensuse
Tumbleweed existieren entsprechende ISO-Images (siehe https://de.opensuse.org/openSUSE:Tumbleweed_installation).
Eine andere Alternative bietet ein Rettungssystem, wie es auf Installations-DVDs etlicher Distributionen vorhanden ist. Ein Rettungs- oder Live-System ist aber auch leicht zu erstellen (s. etwa http://www.system-rescue-cd.org/Download/, https://en.opensuse.org/SDB:Live_USB_stick, https://linux-club.de/wiki/opensuse/Installationsmedien_zu_openSUSE).
Hat man später bereits eine Experimental-Installation angelegt, so kann man natürlich auch die einsetzen, um die Partition der Hauptinstallation für eine Fallback-Installation auf eine andere Partition zu kopieren.
Eine Fallback-Installation entsteht am einfachsten durch Kopie der Partition mit der Hauptinstallation auf eine andere (Ziel-) Partition – und einige nachfolgende Schritte. Die Ziel-Partition muss man natürlich vor dem Kopiervorgang angelegt haben. Hierbei ist folgender Punkt wichtig:
Die Zielpartition muss mindestens die gleiche Größe haben wie die Original-Partition; die Zielpartition kann aber auch größer sein. Das gewährleistet man bei der Erstellung durch geeignete Wahl des Start- und Zielsektors (bzw. des Start- und End-Zylinders). Die Differenz – also die Anzahl der Sektoren (bzw. Zylinder) in der Zielpartition – sollte den gleichen Wert haben wie beim Original.
(Das Zusammenfallen von Partitionsgrenzen mit Zylindergrenzen ist ein Spezialthema für HDs mit MBR und sog. CHS-Adressierung; ich kann hier nicht darauf eingehen. Partitionierungstools achten in der Regel bei der Partitionsanlage auf eine entsprechende Optimierung. Auf Platten mit GPT-Partitionstabelle und LBA-Adressierung operiert man sehr viel einfacher mit Sektoren.)
Es gibt eine Reihe von Tools, um Partitionen aufzulisten, anzulegen und zu verändern. Für Opensuse hatten wir ja schon den “YaST-Partitioner” erwähnt. Interessanterweise bietet dieses Tool eine Dimensionierung neuer GPT-Partitionen über die Eingabe von Start/End-Zylinder an. Ein distributionsübergreifendes grafisches Tool ist “gparted” (welches auf dem CLI-Tool “parted” aufsetzt). gparted unterstützt natürlich GPT-HDs/SSDs und zeigt Start- und End-Sektoren für Partitionen an.
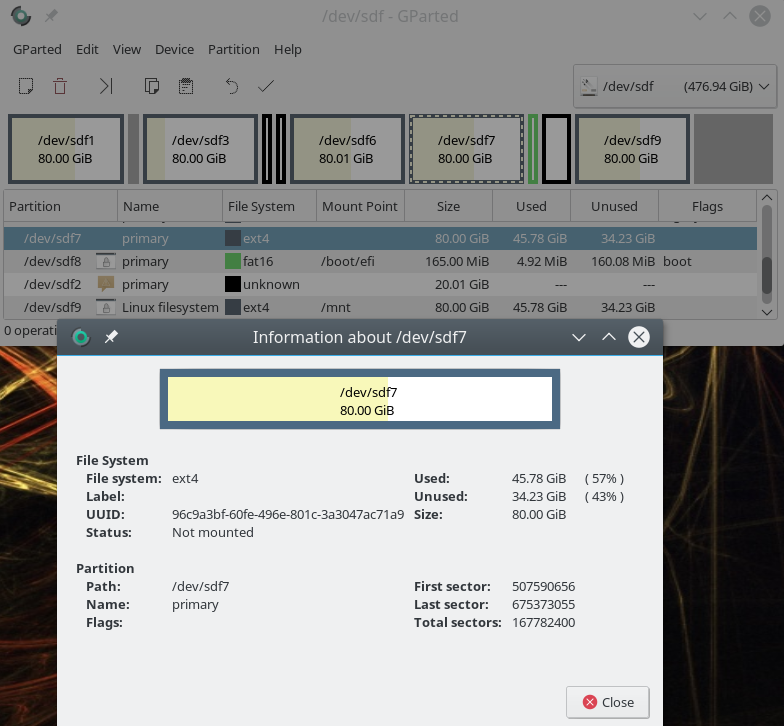
Daneben findet sich das CLI-Tool “fdisk“, das inzwischen auch mit GPT-Disks umgehen kann. Speziell für GPT-HDs/SSDS ist das CLI-Tool “gdisk” gedacht. Auch mit gdisk können wir die Größe neuer Partitionen präzise über Angaben zu Sektoren festlegen.
Die Sektor-Information sieht z.B. für zwei gleich große Partitionen “dev/sdf3”, “/dev/sdf7” einer Platte “/dev/sdf” unter fdisk wie folgt aus:
myexp:~ # fdisk -l /dev/sdf
Disk /dev/sdf: 477 GiB, 512110190592 bytes, 1000215216 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 04AD1B2B-6934-444D-BD93-83FE4A3AE15C
Device Start End Sectors Size Type
...
/dev/sdf3 171960320 339742719 167782400 80G Linux filesystem
...
/dev/sdf7 507590656 675373055 167782400 80G Linux filesystem
Ich ziehe auf GPT-Platten für eine präzise Dimensionierung jedoch meist “gdisk”
heran:
myexp:~ # gdisk -l /dev/sdf
GPT fdisk (gdisk) version 0.8.8
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Disk /dev/sdf: 1000215216 sectors, 476.9 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 04AD1B2B-6934-444D-BD93-83FE4A3AE15C
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 1000215182
Partitions will be aligned on 2048-sector boundaries
Total free space is 286739053 sectors (136.7 GiB)
Number Start (sector) End (sector) Size Code Name
1 2048 167766015 80.0 GiB 8300 primary
....
3 171960320 339742719 80.0 GiB 8300 primary
....
7 507590656 675373055 80.0 GiB 8300 primary
8 675373056 675710975 165.0 MiB EF00 primary
myexp:~ #
myexp:~ # gdisk /dev/sdf
GPT fdisk (gdisk) version 0.8.8
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Command (? for help): i
Partition number (1-8): 7
Partition GUID code: 0FC63DAF-8483-4772-8E79-3D69D8477DE4 (Linux filesystem)
Partition unique GUID: 85C6892A-D709-4A3F-9758-D521A7A11F68
First sector: 507590656 (at 242.0 GiB)
Last sector: 675373055 (at 322.0 GiB)
Partition size: 167782400 sectors (80.0 GiB)
Attribute flags: 0000000000000000
Partition name: 'primary'
Command (? for help): i
Partition number (1-8): 3
Partition GUID code: 0FC63DAF-8483-4772-8E79-3D69D8477DE4 (Linux filesystem)
Partition unique GUID: 4C6C4872-1C36-465A-A09F-7CC0EF542E4D
First sector: 171960320 (at 82.0 GiB)
Last sector: 339742719 (at 162.0 GiB)
Partition size: 167782400 sectors (80.0 GiB)
Attribute flags: 0000000000000000
Partition name: 'primary'
Wie erstellt man nun eine weitere neue Partition mit identischer Größe? Wir machen das mal versuchsweise mit “gdisk”; dort gibt es dafür das Subkommando “n” (für “new”). Ein Blick in die man-Seiten zu “gdisk” zeigt übrigens auch, dass Änderungen erst dann wirksam werden, wenn wir unter gdisk abschließend den “w”-Befehl absetzen.
myexp:~ # gdisk /dev/sdf
GPT fdisk (gdisk) version 0.8.8
Partition table scan:
...
Found valid GPT with protective MBR; using GPT.
Command (? for help): n
Partition number (9-128, default 9):
First sector (34-1000215182, default = 717672448) or {+-}size{KMGTP}:
Last sector (717672448-1000215182, default = 1000215182) or {+-}size{KMGTP}: +167782400
Current type is 'Linux filesystem'
Hex code or GUID (L to show codes, Enter = 8300):
Changed type of partition to 'Linux filesystem'
Command (? for help): p
Disk /dev/sdf: 1000215216 sectors, 476.9 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 04AD1B2B-6934-444D-BD93-83FE4A3AE15C
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 1000215182
Partitions will be aligned on 2048-sector boundaries
Total free space is 118956653 sectors (56.7 GiB)
Number Start (sector) End (sector) Size Code Name
1 2048 167766015 80.0 GiB 8300 primary
...
3 171960320 339742719 80.0 GiB 8300 primary
...
7 507590656 675373055 80.0 GiB 8300 primary
8 675373056 675710975 165.0 MiB EF00 primary
9 717672448 885454847 80.0 GiB 8300 Linux filesystem
Command (? for help): i
Partition number (1-9): 9
Partition GUID code: 0FC63DAF-8483-4772-8E79-3D69D8477DE4 (Linux filesystem)
Partition unique GUID: 696C551B-591D-4411-A951-18D337F548D9
First sector: 717672448 (
at 342.2 GiB)
Last sector: 885454847 (at 422.2 GiB)
Partition size: 167782400 sectors (80.0 GiB)
Attribute flags: 0000000000000000
Partition name: 'Linux filesystem'
Command (? for help): q
Man beachte hier die GUID, die eine Partition in eindeutiger Weise auf einem Device identifiziert. Die GUID ist von einer sog. “UUID” des Filesystems (s.u.) in einer Partition zu unterscheiden !
Schreibt man die geänderte Partitionstabelle im letzten Schritt tatsächlich mit “w” auf die Platte, informiert “gdisk” den laufenden Kernel nicht über die Änderungen! Das geschähe ohne weitere Maßnahmen erst bei einem Reboot. Will man das vermeiden, hilft das CLI-Kommando “partprobe“, das zusammen mit dem Tool “parted” installiert wird.
myexp:~ # partprobe /dev/sdf
es geht alternativ auch
myexp:~ # /sbin/blockdev --rereadpt /dev/sdf
Ein “geeigneter Zeitpunkt” zum Erstellen einer Kopie der Hauptinstallation ergibt sich im laufenden Betrieb im Zuge von Updates nach einer Phase zufriedenstellender täglicher Arbeit. Steht man vor einer Upgrade-Aktion für sein Linux-System, wird man die laufende Hauptinstallation in jedem Fall kopieren und daraus eine bootfähige Fallback-Installation herstellen.
Für eine bitweise Kopie ist der Einsatz des CLI-Kommandos “dd” am einfachsten. Siehe zu einer Einführung bzgl. “dd” etwa https://wiki.ubuntuusers.de/dd/ und https://wiki.archlinux.de/title/Dd). “dd” ist unter Linux ein wirkliches wichtiges Werkzeug, das man in Kombination mit “gzip” und “tar” nicht zuletzt auch für die Erzeugung von Updates nutzen kann! Man sehe sich also zu “dd” unbedingt mal die man-Seiten und auch unten angegebene Links an.
Nehmen wir an, unsere aktuell benutzte Hauptinstallation liegt auf einer Partition “/dev/sdf7”. Auf der gleichen Platte befinde sich bereits eine Partition “dev/sdf9” gleicher Größe (man prüfe hierzu die Sektor- oder Zylinderanzahl in einem Partitionierungstool; s.o.). Aktuell gebootet worden sei eine Installation auf einer Partition “/dev/sdax” (x im Beispiel ungleich 7 oder 9) oder eben ein Live- oder Rettungs-System. Im gebooteten System erreicht man dann eine bitweise Kopie von “/dev/sdf7” auf “/dev/sdf9” per
myexp:~ # dd if=/dev/sdf7 of=/dev/sdf9 bs=1M
Zum Parameter “bs” siehe die man-Seiten! Auf einer optimal angebundenen SSD dauert ein solcher Kopier-Prozess für eine “80 GByte”-Partition deutlich weniger als 10 Minuten.
myexp:~ # dd if=/dev/sdf7 of=/dev/sdf9 bs=1M
81925+0 records in
81925+0 records out
85904588800 bytes (86 GB, 80 GiB) copied, 418.97 s, 205 MB/s
Die SSD operiert hier mit ca. 400 MB/s, da sie ja lesen und schreiben muss.
Haben wir damit schon unsere gewünschte “Fallback-Installation” erstellt? Da wir ja mit der Partition auch das dortige Filesystem samt Inhalten bitweise kopiert haben, könnte man meinen, dass mit der Kopie schon alles erledigt sei – und man nur noch den Bootmanager “Grub2” unter Einbeziehung aller verfügbaren OS-Installationen (z.B. mittels YaST2 >> Bootloader” neu schreiben lassen muss.
Das ist ein gewaltiger Irrtum!:
Warnung: Bitte schreibt nach Kopie einer Partition mit einer Betriebssysteminstallation nicht den Boot-Manager neu – und schon gar nicht unter Einbeziehung aller bootbaren Filesysteme.
Warum? Die Antwort gibt der nächste Abschnitt …
Wenn wir eine Partition bitweise kopieren, wird der gesamte Inhalt (Filesystem + dessen Inhalte) 1:1 in die Zielpartition übertragen. Jedes Filesystem hat nun aber eine ID, die sog. “UUID“, die in einem System eindeutig sein sollte.
Die UUID eine Filesystems ist eine (hoffentlich eindeutige) Kombination aus alphanumerischen Zeichen. S. die nachfolgende Abbildung:
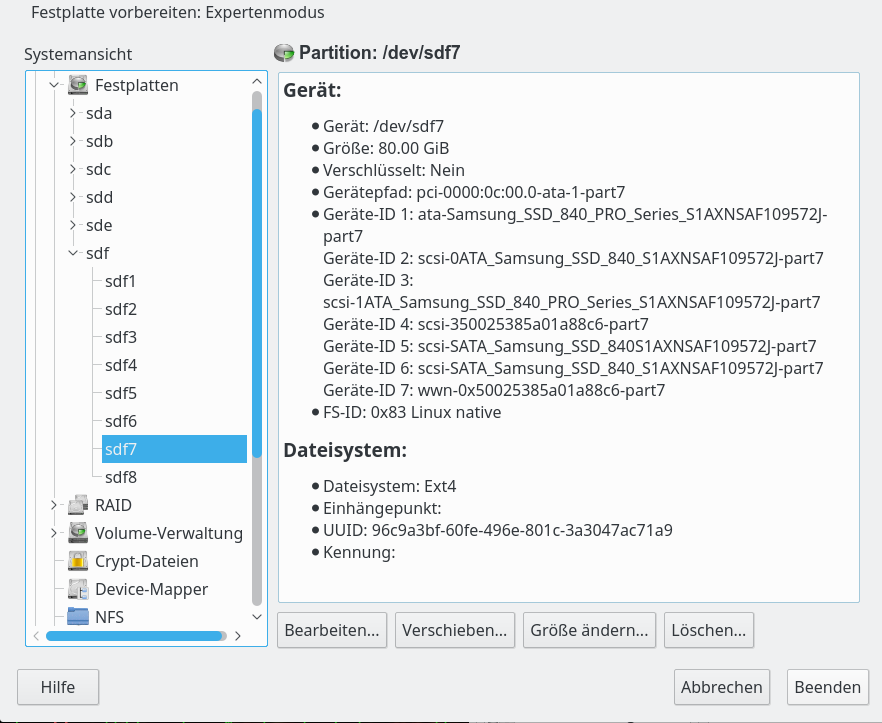
Die UUID vorhandener Partitionen kann man sich mit vielen Partitionstools und auch dem Kommando “tune2fs” anzeigen lassen. Ein geeignetes Kommando für die Kommandozeile ist aber auch “blkid“. Testet man unmittelbar nach unserem Kopiervorgang von “/dev/sdf7” auf “/dev/sdf9”, so erhält man
myexp:~ # blkid | grep "sdf7\|sdf9"
/dev/sdf7: UUID="96c9a3bf-60fe-496e-801c-3a3047ac71a9" TYPE="ext4" PARTLABEL="primary" PARTUUID="85c6892a-d709-4a3f-9758-d521a7a11f68"
/dev/sdf9: UUID="96c9a3bf-60fe-496e-801c-3a3047ac71a9" TYPE="ext4" PARTLABEL="Linux filesystem" PARTUUID="6b579030-567a-4c7a-b705-34b55113d6d5"
Diese leider von uns selbst erzeugte Uneindeutigkeit hat nach dem Kopiervorgang noch keine unmittelbaren Folgen. Der Befund ist aber dennoch außerordentlich problematisch, denn es gilt:
Aktuelle Linux-Distributionen identifizieren zu mountende oder im Bootprozess anzusprechende Filesysteme (bzw. Partitionen) nämlich genau über die “UUID”.
Siehe zu der Thematik auch: https://wiki.ubuntuusers.de/UUID/. Unter Opensuses “YaST Partitioner” gibt es hierzu übrigens eine Grundeinstellung, die man auch modifizieren kann:
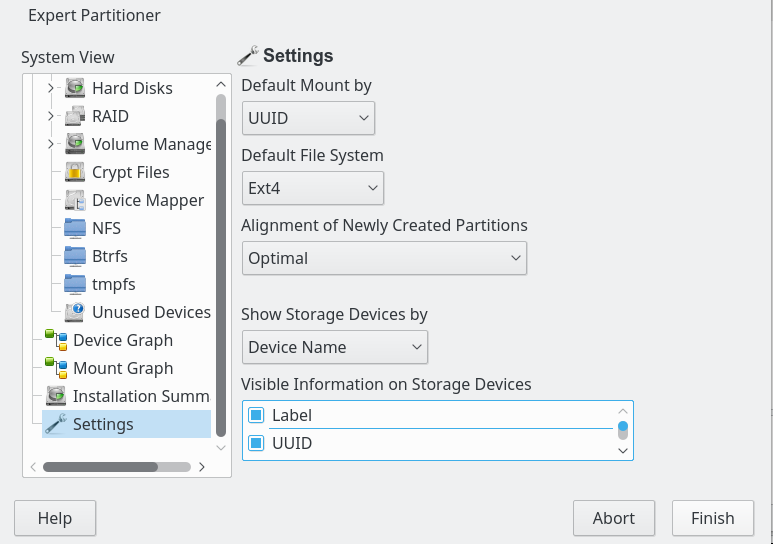
Unter Linux steuert u.a. die Datei “/etc/fstab” bekanntermaßen das Mounten von Filesystemen – u.a. auch des root-Filesystems – in bestimmten Phasen des Systemstart mit. Werden nun die zu mountenden Filesysteme (Partitionen) in der Datei “/etc/fstab” tatsächlich durch UUIDs gekennzeichnet, können schon beim nächsten Bootvorgang ernsthafte Probleme auftreten; es gibt nach unserer Partitionskopie mittels “dd” ja zwei Filesysteme mit derselben UUID!
Noch schlimmer werden die Verhältnisse, wenn wir auch noch die Grub2-Konfiguration unter Einschluss aller bootbaren Installation updaten; das ist dann ein sicherer Weg in den Abgrund; mit Doppelmounts auf “/” und nachfolgenden Katastrophen ist zu rechnen!
Deshalb gilt:
Warnung: Bevor man irgendetwas nach dem bitweisen Kopieren einer Partition in einen andere auf dem Datenträger ein und desselben aktiven Systems unternimmt, sollte man unbedingt die UUID des kopierten Filesystems ändern, sowie die Einträge in den dortigen Dateien “/etc/fstab” und “/boot/grub(2)/grub.cfg” an die neue Situation anpassen.
Nur dann werden wir die kopierten Installationen auch ohne Probleme bootfähig zu bekommen! Auf keinen Fall sollte man vor Erledigung dieser Schritte im aktuell gebooteten System die Bootloader-Konfiguration neu schreiben lassen.
Wie ändert man die UUID eines (kopierten) Filesystems? Hierzu braucht man zwei Schritte:
- Schritt 1: Generieren einer neuen UUID mittels des Befehls “uuidgen“
- Schritt 2: Ändern der UUID auf der kopierten Partition mittels des Kommandos “tune2fs device -U newUUID“
Wir führen das mal am Beispiel unseres kopierten Filesystem auf der Partition “/dev/sdf9” durch:
myexp:~ # uuidgen
a65d6a9b-cc87-4af7-95bf-f407f463f344
myexp:~ # tune2fs /dev/sdf9 -U a65d6a9b-cc87-4af7-95bf-f407f463f344
tune2fs 1.42.11 (09-Jul-2014)
myexp:~ # blkid | grep "sdf7\|sdf9"
/dev/sdf7: UUID="96c9a3bf-60fe-496e-801c-3a3047ac71a9" TYPE="ext4" PARTLABEL="primary" PARTUUID="85c6892a-d709-4a3f-9758-d521a7a11f68"
/dev/sdf9: UUID="a65d6a9b-cc87-4af7-95bf-f407f463f344" TYPE="ext4" PARTLABEL="Linux filesystem" PARTUUID="6b579030-567a-4c7a-b705-34b55113d6d5"
Damit sind wir aber keineswegs fertig …
Bevor wir den Bootloader neu schreiben lassen, ändern wir zunächst die Dateieen “/etc/fstab” und zur Sicherheit auch der “/boot/grub2/grub.cfg” ab. Hierzu mounten wir das frisch kopierte Filesystem im aktuell gebooteten System – z.B. auf “/mnt” -und ersetzen in der dortigen “fstab” (also in der /mnt/etc/fstab”) die Einträge mit der alten UUID:
myexp:~ # mount /dev/sdf9 /mnt
myexp:~ # cat /mnt/etc/fstab
UUID=d9a73a89-b89b-4fda-8c4c-9034e42d1274 swap swap defaults 0 0
UUID=96c9a3bf-60fe-496e-801c-3a3047ac71a9 / ext4 acl,user_xattr 1 1
UUID=73B4-E5BA /boot/efi vfat umask=0002,utf8=true 0 0
UUID=24f67362-236e-49ea-ba38-31c1c2541630 /projekte ext4 defaults 1 2
....
....
Problematisch ist vor allem der zweite Eintrag, der noch die kopierte UUID beinhaltet! Diese UUID ändern wir nun mit Hile eines Editors unserer Wahl auf die neue – per uuigen generierte und per tune2fs zugeordnete – UUID ab:
# cat /mnt/etc/fstab
UUID=d9a73a89-b89b-4fda-8c4c-9034e42d1274 swap swap defaults 0 0
UUID=a65d6a9b-cc87-4af7-95bf-f407f463f344 / ext4 acl,user_xattr 1 1
UUID=73B4-E5BA /boot/efi vfat umask=0002,utf8=true 0 0
UUID=24f67362-236e-49ea-ba38-31c1c2541630 /projekte ext4 defaults 1 2
....
Damit haben wir schon mal größeres Unglück verhindert. Eine Anpassung der “/etc/fstab” ist der wichtigste Schritt.
Ganz auf die sichere Seite gegenüber späteren manuell verursachten Fehlern kommen wir aber erst mit entsprechenden Änderungen in der Datei “/mnt/boot/grub2/grub.cfg” – oder aber einer Elimination der Datei für das (versehentliche) Schreiben des Bootloaders unter der neuen Installationm. .
In der “/mnt/boot/grub2/grub.cfg” finden sich Boot-Einträge der Form
menuentry 'openSUSE 42.2 (x86_64) (on /dev/sdf7)' --class suse --class gnu-linux --class gnu --class os $menuentry_id_option 'osprober-gnulinux-simple-96c9a3bf-60fe-496e-801c-3a3047ac71a9' {
insmod part_gpt
insmod ext2
set root='hd5,gpt7'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd5,gpt7 --hint-efi=hd5,gpt7 --hint-baremetal=ahci5,gpt7 96c9a3bf-60fe-496e-801c-3a3047ac71a9
else
search --no-floppy --fs-uuid --set=root 96c9a3bf-60fe-496e-801c-3a3047ac71a9
fi
linuxefi /boot/vmlinuz-4.4.104-18.44-default root=UUID=96c9a3bf-60fe-496e-801c-3a3047ac71a9 ro resume=/dev/disk/by-uuid/d9a73a89-b89b-4fda-8c4c-9034e42d1274 splash=silent quiet showopts elevator=deadline intel_pstate=disable swapaccount=1 pti=on
initrdefi /boot/initrd-4.4.104-18.44-default
}
submenu 'Advanced options ......
....
......
Würden wir diese “grub.cfg” (nach einem Booten der kopierten Installation) dummerweise direkt zur Implementierung des
Bootloaders per “grub-install” nutzen, gäbe es ein vermeidbares Chaos.
In der Datei müssen wir deshalb natürlich alle Strings “96c9a3bf-60fe-496e-801c-3a3047ac71a9” ersetzen durch “a65d6a9b-cc87-4af7-95bf-f407f463f344”. Das geht mit Editoren wie “kate” relativ gefahrlos.
Ein noch einfacherer Schritt zur Absicherung gegenüber späteren potentiellen Unglücken durch manuelle Befehle zum Schreiben des Bootloaders ohne vorherige Neugenerierung der “boot.cfg” ist, die Datei schlicht umzubenennen – und damit für versehentliche Installationen auszuschalten:
myexp:~ # mv /mnt/boot/grub2/grub.cfg /mnt/boot/grub2/grub_before_copy_180219.cfg_orig
Natürlich schreiben wir den Bootloader aber eher von der funktionierenden “ursprünglichen” Hauptinstallation aus. Haben wir die “etc/fstab” in er kopierten Partition auf die neue UUID angepasst, können wir – ohne vorheriges Verändern des Grub2-Bootloaders – unser System getrost neu booten und dabei die ursprüngliche Hauptinstallation starten. Von dort aus nehmen wir nun eine Erweiterung des Bootloaders vor, so dass dei neue “Fallback”-Installation später im Grub2-Bootmenü mit angeboten wird.
Unter Opensuse nutzen wir dazu YaST’s Bootloader-Modul:
Dieses Programm bietet 3 per Reiter (Tabs) erreichbare Konfigurationsseiten an. Die letzte ist für unsere Zwecke am wichtigsten und sieht wie folgt aus:
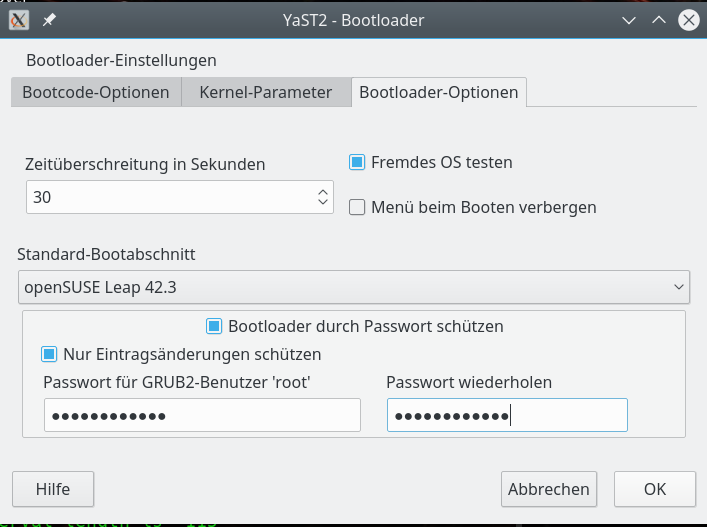
Hier müssen wir die Option “Fremdes OS testen” abhaken.
[Zu alternativen CLI-Kommandos “grub_mkconfig”, “update-grub” (Ubuntu) bzw. “grub2-mkconfig” (Opensuse) und “grub-install” siehe den letzten Beitrag und die Doku eurer Distribution. Unter Opensuse Leap prüft “grub2-mkconfig” durch Aufruf des “os-prober”-Skripts fremde OS gleich mit und schreibt den gesamten Output defaultmäßig in die “/boot/grub2/grub.cfg”.]
Danach finden wir in der Datei “/boot/grub2/boot.cfg” Einträge folgender Art zum Filesystem auf “/dev/sdf9” vor:
....
### BEGIN /etc/grub.d/30_os-prober ###
...
...
menuentry 'openSUSE 42.2 (x86_64) (auf /dev/sdf9)' --class suse --class gnu-linux --class gnu --class os $menuentry_id_option 'osprober-gnulinux-simple-a65d6a9b-cc87-4af7-95bf-f407f463f344' {
insmod part_gpt
insmod ext2
set root='hd5,gpt9'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd5,gpt9 --hint-efi=hd5,gpt9 --hint-baremetal=ahci5,gpt9 a65d6a9b-cc87-4af7-95bf-f407f463f344
else
search --no-floppy --fs-uuid --set=root a65d6a9b-cc87-4af7-95bf-f407f463f344
fi
linuxefi /boot/vmlinuz-4.4.104-18.44-default root=/dev/sdf9
initrdefi /boot/initrd-4.4.104-18.44-default
}
submenu 'Erweiterte Optionen für openSUSE 42.2 (x86_64) (auf /dev/sdf9)' $menuentry_id_option 'osprober-gnulinux-advanced-a65d6a9b-cc87-4af7-95bf-f407f463f344' {
menuentry 'openSUSE 42.2 (x86_64) (auf /dev/sdf9)' --class gnu-linux --class gnu --class os $menuentry_id_option 'osprober-gnulinux-/boot/vmlinuz-4.4.104-18.44-default--a65d6a9b-cc87-4af7-95bf-f407f463f344' {
insmod part_gpt
insmod ext2
set root='hd5,gpt9'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd5,gpt9 --hint-efi=hd5,gpt9 --hint-baremetal=ahci5,gpt9
a65d6a9b-cc87-4af7-95bf-f407f463f344
else
search --no-floppy --fs-uuid --set=root a65d6a9b-cc87-4af7-95bf-f407f463f344
fi
linuxefi /boot/vmlinuz-4.4.104-18.44-default root=/dev/sdf9
initrdefi /boot/initrd-4.4.104-18.44-default
}
Diese Einträge im Boot-Menü hat YaSTs Bootloader-Modul dann auch schon gleich auf der Platte verewigt. Sie werden beim nächsten Bootvorgang mit angeboten.
Damit haben wir unsere durch “dd” erzeugte “Fallback-Installation” auf “/dev/sdf9” bootfähig verankert.
Eine Experimental-Installation” erzeugt man in einer weiteren Partition auf ganz ähnliche Weise wie oben beschreiben und macht auch diese nach UUID-Änderung und Anpassung der dortigen “/etc/fstab” bootfähig. Für die Experimentalinstallation kann man dann eine probeweises Upgrade vornehmen. (Im Beispiel von Opensuse Leap 42.2 auf Leap 42.3 …).
Das “Gefährliche” bestand bei unserem Vorgehen vor allem in der Duplizierung der UUID – und eventuellen diesbezüglichen Einstellungen in der “/etc/fstab”. Natürlich kann man die Einträge in der “/etc/fstab” auch auf Basis konventioneller Laufwerksbezeichnungen (“dev/sdxn”) vornehmen.
Der Yast-Partitioner bietet hierfür sogar eine Einstellungsoption an:
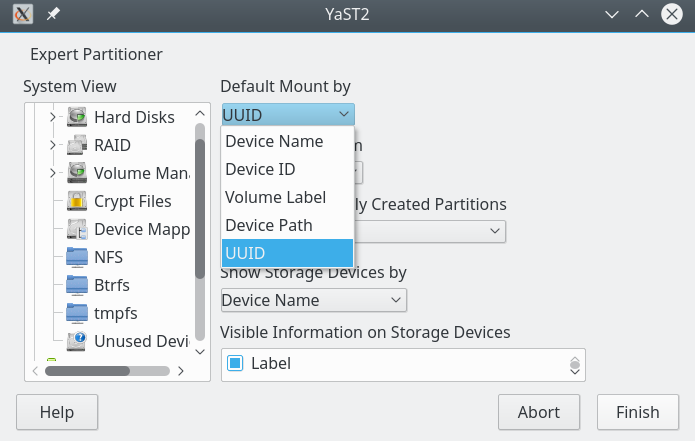
Einträge mit normalwer Bezeichnung sähen so aus:
/dev/sdf9 / ext4 acl,user_xattr 1 1
Dies befreit aber aus einer Vielzahl von Gründen nicht davon, die UUID des Filesystems trotzdem abzuändern.
Eine Kopie größerer Partitionen durchzuführen ist schreibintensiv. Nicht alle SSDs haben eine hinreichende Qualität, um solche Schritte oft durchführen zu können. Die SSD leidet darunter (wear leveling count). Man sollte die Erstellung einer neuen “Fallback-Installation” als Kopie der Hauptinstallation daher nur in größeren Zeitabständen vornehmen.
Hat man gute Erfahrungen mit Updates sowohl in der Experimental-Installation als auch auf der Hauptinstallation gemacht, spricht ja nichts dagegen, Updates auch auf der Fallback-Installation systematisch und kontrolliert nachzuziehen. Nur vor Upgrades erscheint mir die Anlage einer Fallback-Installation als Kopie der aktuellen Hauptinstallation unvermeidlich.
Ich hoffe, der eine oder andere hat beim Lesen ein paar Dinge aufgeschnappt, die er noch nicht kannte …
Übersicht GPT
https://en.wikipedia.org/wiki/GUID_Partition_Table
https://de.wikipedia.org/wiki/GUID_Partition_Table
https://www.thomas-krenn.com/de/wiki/GUID_Partition_Table
Übersicht Linux Partitioning Tools
http://dwaves.de/2017/05/23/linux-overview-partitions-difference-fdisk-gdisk-cfdisk-parted-gparted/
Partition Alignment
https://www.thomas-krenn.com/de/wiki/Partition_Alignment
UUID ändern
http://www.sudo-juice.com/how-to-change-the-uuid-of-a-linux-partition/
Backups mit dd
https://www.linux.com/learn/full-metal-backup-using-dd-command
https://wiki.archlinux.de/title/Image-Erstellung_mit_dd
https://www.thegeekstuff.com/2010/10/dd-command-examples/
http://www.linux-community.de/Archiv/Tipp-der-Woche/Mit-dd-schnell-Festplattenimages-erstellen
https://www.thomas-krenn.com/de/wiki/Dd_unter_Linux