In den ersten beiden Beiträgen zu SSD-Raid-Arrays unter Linux
SSD Raid Arrays unter Linux – I – ein facettenreiches Thema
SSD Raid Arrays unter Linux – II – Hardwarecontroller ?
hatte ich angekündigt, die Frage zu beantworten, ob sich auf einem Linux-System der Einsatz des Intel-Z170-SATA3-Controllers als iRST-Controller im Gegensatz zur Erstellung eines nativen Linux-SW-Raids lohnen würde.
iRST bedeutet Intel Rapid Storage Technologie; sie erlaubt eine Bündelung von Platten, die an den Z170-Onboard-Controller angeschlossen sind, zu einem Raid-Verbund (Raid 0, 1, 10, 5, 6) – und zwar erfolgt die Konfiguration dabei über BIOS-Funktionalitäten.
Einen iRST-fähigen Raid-Controller findet man im Moment auf vielen aktuellen Consumer-Mainboards mit Intel-Chipsätzen vor. Ein Beispiel liefert das von mir auf einem Testssystem eingesetzte Board “ASRock Z170 Extreme 7”.
Die vorweggenommene Antwort auf die Eingangsfrage ist aus meiner Sicht: Nein – zumindest nicht aus Performancegründen.
Das gilt, obwohl einfache Performance-Tests für RAID 10-Arrays zunächst das Gegenteil anzudeuten schienen.
Intels Z170 SATA3 Controller im iRST-Modus entspricht einem Raid-Fake-Controller mit minimaler Intelligenz – aber guter Boot-Unterstützung. Im AHCI-Modus behandelt der SATA3-Controller die angeschlossenen SSDs über das SATA3-Interface als einzelne Platten. Der iRST-Modus lässt sich im BIOS dagegen über die Option “Array” statt AHCI aktivieren. Die Platten werden dann zu einem sog. Container-Verband (Raid) zusammengeschlossen, auf dem wiederum Volumes definiert werden können.
Konfigurationsoptionen im (UEFI-) BIOS
Der iRST-Modus zieht eine Zwischenschicht zum (UEFI-) BIOS ein. Je nach Board, BIOS und OpRom-Einstellungen ist das iRST-Setup-Menü über eine spezielle Tastenkombination (Ctrl-I) während des BIOS Self-Tests oder durch einen Menüpunkt im UEFI-Interface selbst zugänglich. Oft unter “Advanced” – nach dem man vorher unter einem Punkt “Storage” (o.ä.) die Behandlung der SSDs von “AHCI” auf “RAID” umgestellt hat.
Eigenes Containerformat “imsm”
iRST benutzt für die Datenorganisation eines Raid-Verbunds ein eigenes Container-Metaformat (das sog. “imsm”-Format; man spricht von sog. “imsm”-Containern; dei Abkürzung steht für “Intel Matrix Storage Manager”). Ein Container bindet mehrere Platten zu einer Gruppe zusammen. Bei hinreichender Plattenanzahl können auch mehrere Raid-Container angelegt werden, die sich über jeweils unterschiedliche, disjunkte Gruppen von vorhandenen Platten erstrecken. Hat man einen Raid-10-Verbund als Ziel und nur 4 Platten zur Verfügung, so ist jedoch bereits mit einem Container das Ende der Fahnenstange erreicht.
Genau zwei Volumes pro Container
Ein imsm-Raid-Container, der sich über n definierte Platten hinweg erstreckt, kann genau zwei sog. Raid-Volumes (entspricht landläufigen Raid-Arrays) enthalten.
Für das erste Volume ist die Kapazität (also die Größe in MByte) noch festlegbar; das zweite nutzt dann aber den kompletten Rest der verbliebenen Container-Kapazität. Die einmal definierten Kapazitäten sind im Nachhinein nicht dynamisch veränderbar. Das ganze Raid-System ist bei notwendigen Modifikationen neu anzulegen.
Die zwei möglichen Volumes erstrecken sich über dieselbe Anzahl an Platten; sie können aber 2 verschiedenen Raid-Levels (z.B. Raid 1 und
Raid 10) zugeordnet werden (das ist gerade das Kennzeichen der Intel Raid Matrix Technologie).
Ein Volume – also ein Raid Array – steht unter Linux (mit aktiven Raid-Modulen) dann als ein partitionierbares Block-Device zur Verfügung.
Der/die Raid-Container mit jeweils maximal 2 Raid-Volumes können bereits im (UEFI)-BIOS (über ein OpROM Optionsmenü für Storagesysteme) erstellt werden. Die Möglichkeit zur Anlage von Raid-Containern und Arrays über BIOS-Funktionen ist im Besonderen für Dual-Boot-Systeme mit Windows nützlich.
Anlage von imsm-Containern über mdadm unter Linux
Auf einem reinen Linux-System kann man Container wie Volumes im laufende Betrieb aber auch über das Raid-Administrations-Tool mdadm erstellen und verwalten – unter Angabe des imsm-Metadaten-Formats (mdadm-Option “-e imsm”). Bei Linux-Installern, die während des Install-Prozesses den Rückgriff auf Terminals erlauben, geht das auch während des Installierens.
So weit, so gut. Es ist auf den ersten Blick durchaus bequem, bereits vor einer Linux-Installation die Raid-Arrays über UEFI-BIOS-Funktionen anzulegen, um sie dann schon während der Installation als einfache Pseudo-Laufwerke vorzufinden, die man direkt formatieren kann. Unter Opensuse Leap 42.1/42.2 klappt das ohne Probleme.
Die Volumes der angelegten Container sind auf einem Dual-Boot-System auch von der Windows-Installation aus ansprechbar, formatier- und bootbar. Das ist ein echter Vorteil des iRST.
Links zu iRST
Details zu iRST – im Besonderen zur Einrichtung unter Linux mit Hilfe von mdadm – findet man hier:
http://www.intel.com/content/dam/www/public/us/en/documents/white-papers/rst-linux-paper.pdf
https://en.wikipedia.org/wiki/Intel_Matrix_RAID
http://www.intel.de/content/www/de/de/support/boards-and-kits/000005789.html
http://www.intel.de/content/www/de/de/support/boards-and-kits/000006040.html
http://www.intel.com/content/dam/support/us/en/documents/solid-state-drives/RSTe_NVMe_for_Linux_SW_User_Guide.pdf
http://www.intel.com/content/dam/support/us/en/documents/
chipsets/rste/sb/intelr_rste_linux.pdf
Es stellen sich die Frage:
- Wer oder was steuert eigentlich bei einem laufenden Betriebssystem [OS] die Datenverteilung auf die Platten? Das Betriebssystem [OS] oder der iRST-Controller?
Hierzu ist Folgendes zu sagen:
Die Funktionalität der definierten Container und ihrer Arrays hängt völlig von den Treibern und den Fähigkeiten des gebooteten Betriebssystems ab. Der iRST wird unter Linux durch angepasste Komponenten/Module des “md”-Raid-Systems und administrationsseitig durch mdadm unterstützt. Ohne eine vorhandene Linux-Steuer-SW und zugehörige Kernel-Module (u.a. md_mod, raid5, raid10, etc.) bringt iRST unter Linux gar nichts.
Ein iRST-Controller ist also tatsächlich ein sog. Fake Controller:
Die Hauptarbeit wird nicht durch den Controller selbst, sondern durch das Betriebssystem und zugehörige Software (Treiber) geleistet. Es ist deshalb zwar nicht ausgeschlossen, aber zumindest unwahrscheinlich,
dass der in mdadm integrierte spezielle iRST/imsm-Treiber unter Linux besondere Performancevorteile gegenüber einem reinen, nativen SW-Raid, das man auch mit mdadm aufsetzt, bieten wird.
Wir betrachten nachfolgend die Performance eines mit Hilfe des Z170-iRST-Controllers erstellten Raid10-Verbands aus 4 850 EVO SSDs von Samsung. Verglichen wird das iRST-Raid-Array mit einem reinen Linux-SW-Raid-Array, das mit denselben Platten aufgesetzt wurde.
Das Betriebssystem lag in beiden Fällen auf einer separaten SSD und nicht auf einer Partition des Raid-Verbunds. (Das gibt uns im Schnitt mindestens 10% Performance-Vorteile.)
Bei der Erstellung des iRST-Raid10-Volumes habe ich mich an die Default-Chunksize gehalten, die die BIOS Funktionen angeboten werden.
Default Chunk-Size des iRST: 32 KB
Ein Hinweis für diejenigen, die die Tests konkret nachstellen wollen:
Für die SW-Raid-Konfigurationen unter Linux sollte man den Controller in den AHCI-Modus für den SSD-Zugriff versetzen! Dies ist i.d.R. über eine Option im BIOS möglich!
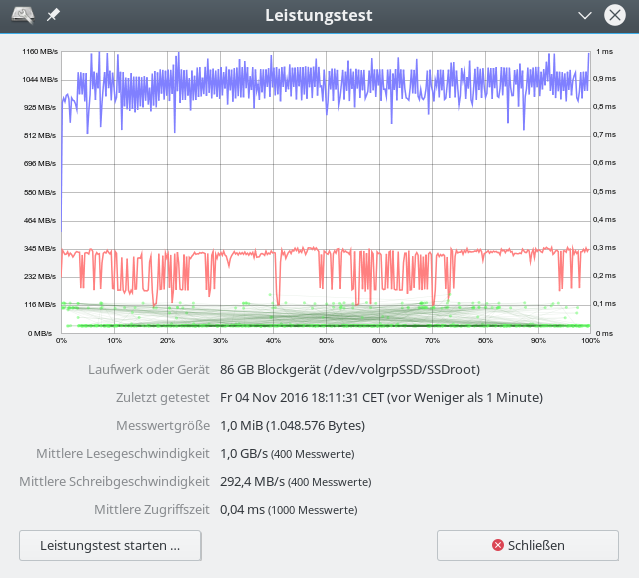
An dieser Stelle mag ein Blick auf Daten des Test-Tools “gnome-disks” genügen. Ich zeige hier Daten für Lese/Schreib-Zugriffe für relativ große sog. “Messwertgrößen” – was immer das genau bei diesem Test intern bedeutet. Aus bestimmten Gründen glaube ich nicht, dass es sich bei der “Messwertgröße” um die Blocksize von einzelnen Datenpaketen handelt; das verträgt sich nämlich nicht mit Daten aus anderen Tests. Aber im vorliegenden Artikel kommt es mir ja nur auf relative Verhältnisse an! Differenziertere und genauere Tests, die ich später mit dem Tool “fio” durchgeführt habe, ändern übrigens nichts am Ergebnis des hier präsentierten Vergleichs des iRST-Raids gegenüber einem Standard SW-Linux Raid.
Die untersuchten Partitionen waren (soweit nichts anderes angegeben ist) in beiden Fällen als LVM-Volumes erstellt worden.
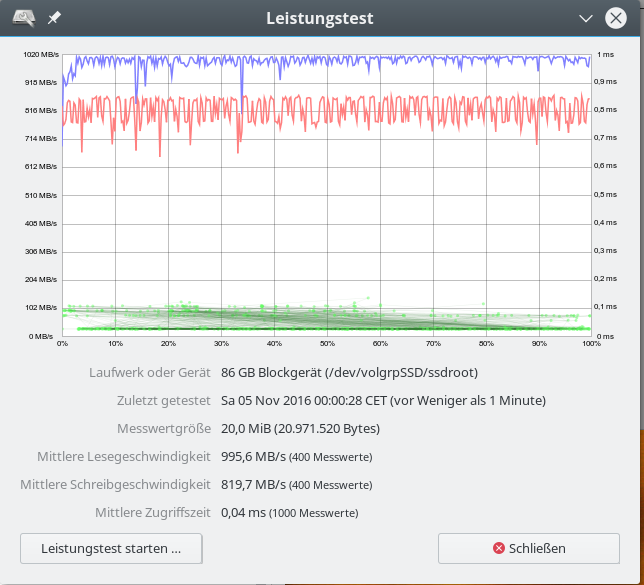
Daten für den iRST-Controller – 20 MB “Messwertgröße”
Daten für ein reines Linux SW-Raid – 20 MB “Messwertgröße”
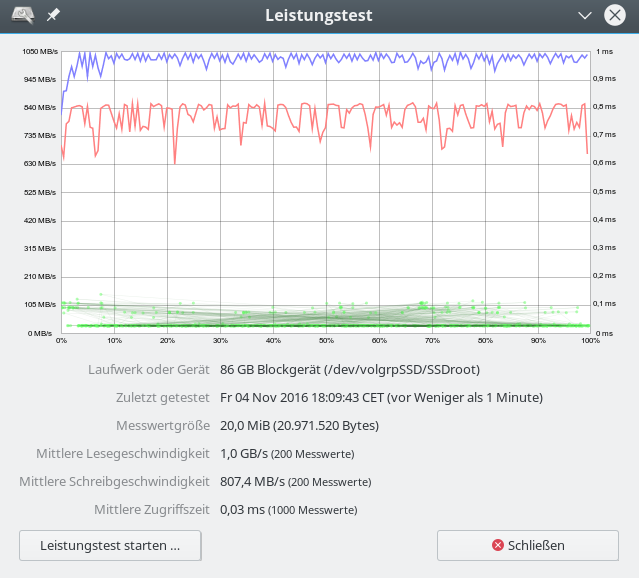
Die bereits hier erkennbare Tendenz etwas höherer Lese- und geringerer Schreibraten wird scheinbar noch deutlicher bei kleineren “Meßwertgrößen”:
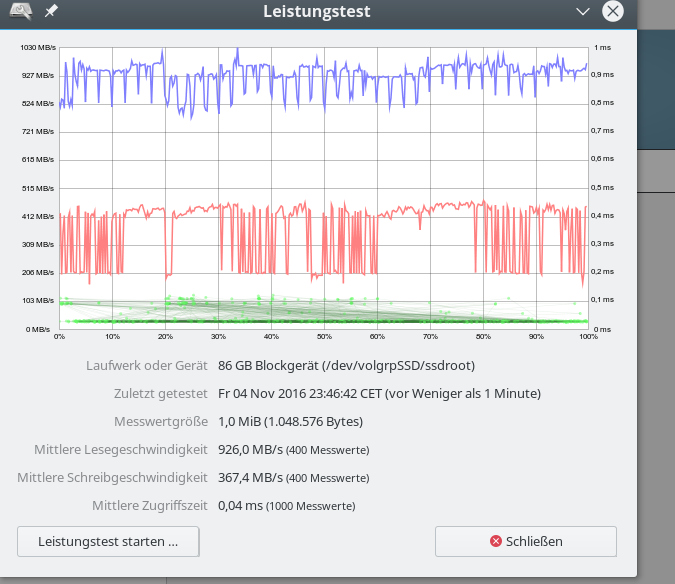
Daten für den iRST-Controller – 1 MB “Messwertgröße” – nach TRIM
Daten für den iRST-Controller – 1 MB “Messwertgröße” – Sättigung
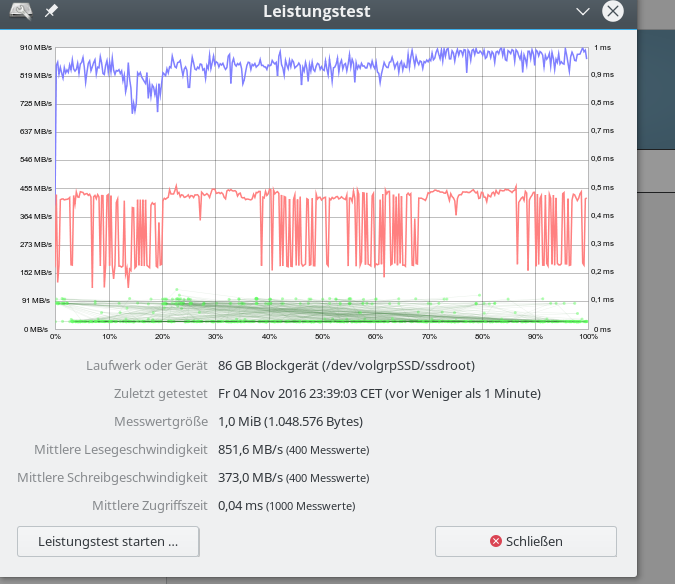
Dagegen:
Daten für eine reines Linux SW-Raid – 1 MB “Messwertgröße” – Sättigung
Zwischenergebnis:
Die obigen Daten wirken so, als ob ein reines SW-Raid unter Linux langsamer sei. Der
gemessene Unterschied in der Schreibrate von bis zu 100 MB/sec bei 1MB Daten (vermutlich mit deutlich kleinerer Blocksize geschrieben) bei einem Minimalwert von 290 MB/sec wiegt auf den ersten Blick schwer und entspricht einem relativen Unterschied von ca. 34%.
Zudem wird die theoretisch mögliche reine Datenschreibrate einer einzelnen EVO 850 SSD (zw. 300 und 490 MB/s je nach Testsetup und Größe der zu schreibenden Blöcke) durch das Raid-System bereits unterschritten.
Aber ist dieser Befund tatsächlich valide?
Bringt der iRST-NModus des Intel SATA-3-Controllers gegenüber einem reinen SW-Raid doch spürbare Vorteile? Nein, das obige Ergebnis täuscht in zweierlei Hinsicht.
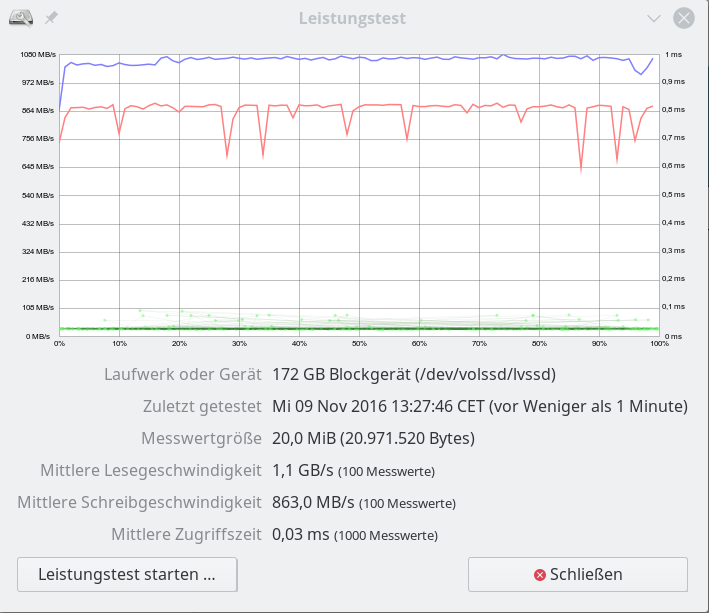
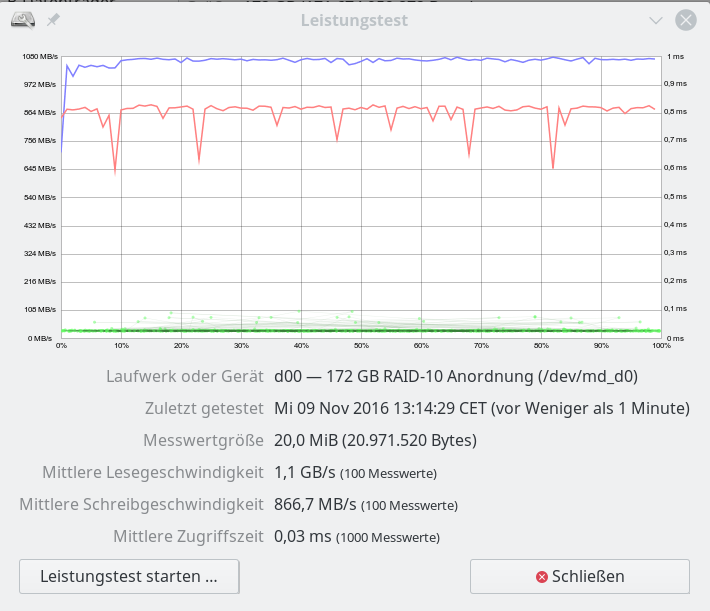
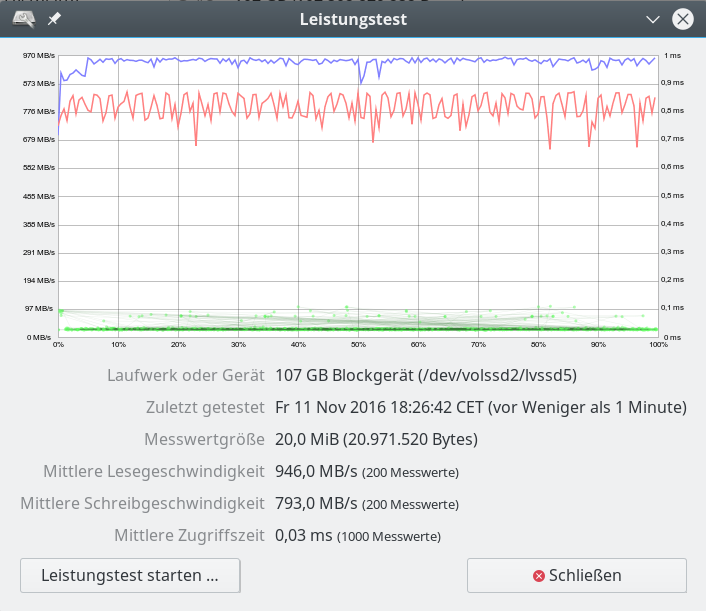
Nachfolgend betrachten wir zunächst die Daten für ein besser parametriertes reines SW-Raid-System: Die Performance wird nun mit der des iRST-Arrays vergleichbar wird.
Bei den nachfolgenden Abbildungen ist ferner zu beachten, dass die Unsicherheit der Daten (u.a. durch nicht getrimmtes Filesystem, interferierende Prozesse im OS) ca. 10 – 20 MB/sec ausmachen kann. Die dargestellten Abbildungen zeigen zufällige und nicht die in Tests zeitweise erreichten maximalen Werte.
Daten für besser parametriertes reines SW-Raid – mit LVM – 20 MB “Messwertgröße”
Daten für besser parametriertes reines SW-Raid-Array – ohne LVM – 20 MB “Messwertgröße”
Daten für besser parametriertes reines SW-Raid-Array – mit LVM – Chunk Size: 16KB – 20 MB “Messwertgröße”
Für die Messgröße 1MB betrachten wir nun mal den Einfluss der sog. Chunk-Size des Arrays etwas genauer:
Daten für ein besser parametriertes reines SW-Raid-Array – ohne LVM – Chunk Size: 512KB – 1 MB “Messwertgröße”
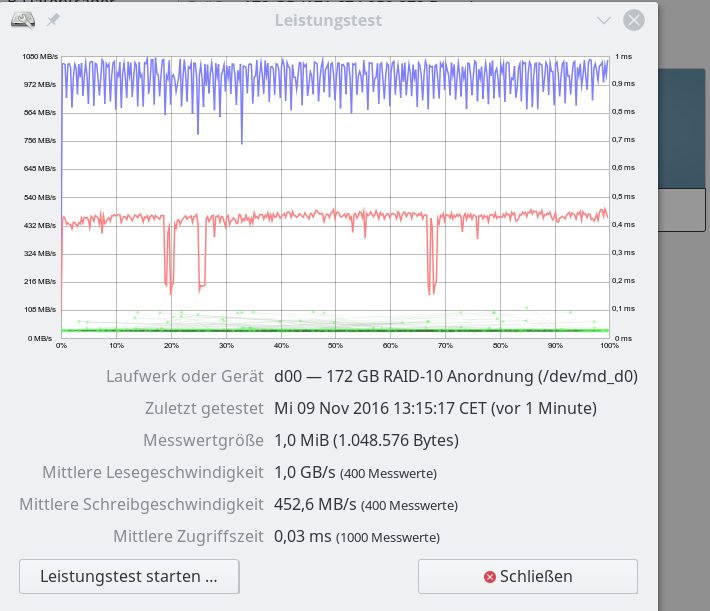
Daten für ein besser parametriertes reines SW-Raid-Array – mit LVM – Chunk Size: 64KB – 1 MB “Messwertgröße”
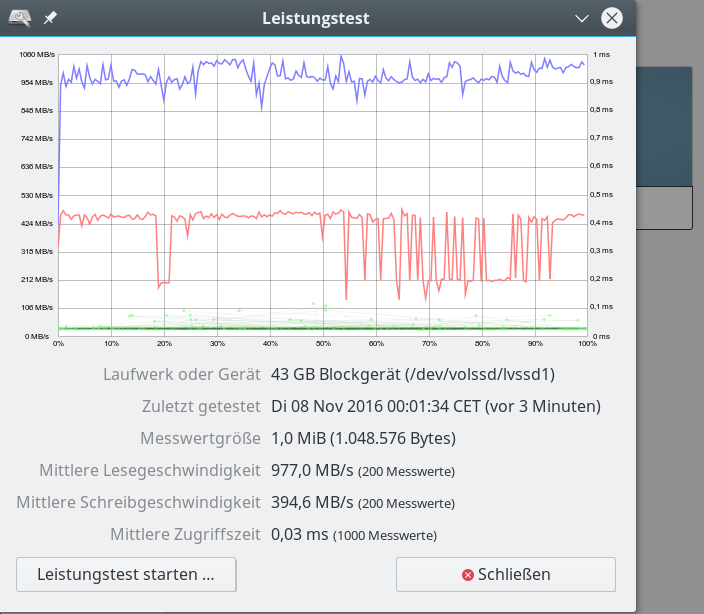
Daten für besser parametriertes reines SW-Raid-Arrays – mit LVM – – Chunk Size: 32KB – 1 MB “Messwertgröße”
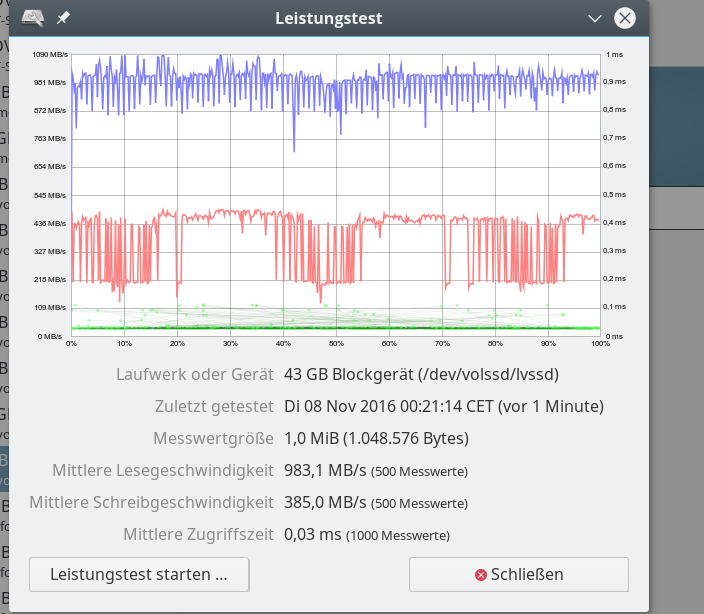
Die letzten Bilder deuten bereits an, dass die Chunk-Size eines Raid-Arrays gerade bei kleineren Datenblöcken offenbar einen größeren Einfluss auf die Performance – und im besonderen die Write-Performance – hat. Wir kommen hierauf in detaillierterer und systematischer Weise in einem späteren Beitrag zurück.
Der Einsatz von LVM als Zwischenschicht zwischen Partitionen und Filesystem der LVM-Volumes fällt
dagegen kaum ins Gewicht.
Ich darf an dieser Stelle verraten, dass für die Annäherung an die bzw. das Übertreffen der iRST-Werte genau eine kleine Änderung bei der Erstellung des SW-Raids eine wesentliche Rolle spielte. Siehe hierzu einen der nächsten Beiträge in dieser Serie.
Die Graphiken zu den Schreibraten täuschen aber auch in anderer Hinsicht:
Sie geben nicht die tatsächlich erreichbaren Schreibraten wieder. Ein differenzierter und genauer einstellbarer Test mit dem Tool FIO liefert ganz andere und deutlich höher Schreibraten für Datenpaketgrößen von 1 MB. Ich komme hierauf in einem späteren Artikel der Serie zurück. Die “gnome-diskd”-Ergebnisse für die erreichbaren Schreibraten sind aus meiner Sicht also mit einem Fragezeichen zu versehen.
Die Antwort auf Frage ist klar Nein. Die obigen Daten belegen, dass Performance-Aspekte keinen Grund für oder gegen den Einsatz des iRST-Modus darstellen. Sie sprechen eher für den Einsatz eines reinen SW-Raid-Systems unter Linux:
Richtig konfiguriert, erreicht man bei den Schreibraten mindestens die Werte des iRST und in der Leserate übertrifft man sie regelmäßig.
Kein Argument für oder gegen den iRST-Einsatz stellt aus meiner Sicht zudem die CPU-Belastung dar. Ich konnte keine substanziellen Unterschiede erkennen:
Auf einem Linux-System mit 4 CPU Cores (i7 6700K) und Hyperthreading ist die CPU-Belastung für die 8 CPU-Threads außerhalb von (Re-)Sync-Phasen in der Praxis unerheblich, solange nicht viele große Raid-Verbände angesteuert werden müssen. Die Raid-Behandlung (Striping etc.) erfolgt in aktuellen Kerneln (seit Version 3.12) zudem multi-threaded.
Genug für heute. Im nächsten Artikel
SSD Raid Arrays unter Linux – IV – OS und Daten auf einem Raid-Array ?
gehe ich ein wenig auf die Datenverteilung ein. Sollte man z.B. das Betriebssystem samt root-Verzeichnis auf demselben Raid-Array installieren, das für hochperformante Datenzugriffe von Spezialanwendungen gedacht ist? Ich werde einen solchen Lösungsansatz kritisch hinterfragen.
Auf einem UEFI-System könnte sich anschließend folgende Frage stellen:
Muss nicht schon das UEFI-BIOS das Intel-RAID-System des Z170-Controllers genau kennen, damit über Grub2 ein Linux-OS, das auf einem SSD-Raid-Array am Intel-Controller installiert wird, anstandslos gebootet werden kann? Ist deswegen nicht zwingend iRST erforderlich?
Wir werden aber in einem kommenden Beitrag
SSD Raid Arrays unter Linux – V – SW-Raid vs. iRST-Raid – Boot-Unterstützung?
sehen, dass diese Sorgen ganz unbegründet sind.
