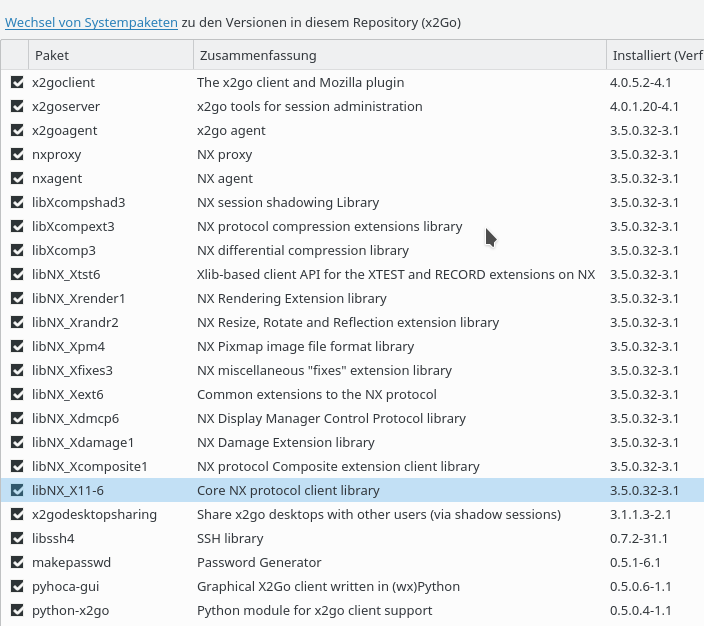
Wir machen weiter mit unserer Einführung von Git – genauer EGit – unter Eclipse. Im ersten Post dieser Serie
Erste Schritte mit Git für lokale und zentrale Repositories unter Eclipse – I
hatten ich ein einfaches Szenario vorgegeben und zugehörige Aufgaben für die Arbeit mit Git unter Eclipse definiert. Im zweiten Post
Erste Schritte mit Git für lokale und zentrale Repositories unter Eclipse – II
hatte ich gezeigt, wie man unter Eclipse ein vorhandenes Projekt mit einem Git-Repository versieht.
Ich fasse nochmal die dort geleisteten Schritte unter EGit für Eclipse zusammen:
- Vorhandenes Projekt unter Eclipse vorbereiten und von SVN-Resten befreien.
- Target-Verzeichnis für das Git-Repository anlegen.
- Git-Repository im Target-Verzeichnis initialisieren und EGit den Transfer aller Projekt-Dateien in den “Working Tree” im Target-Verzeichnis vornehmen lassen. Dazu ein dortiges Verzeichnis angeben.
- Alle Projekt-Verzeichnisse/-Dateien für eine Indizierung/Behandlung in der Git-Versionsverwaltung vormerken. Dabei eclipse- und projektspezifische Dateien/Verzeichnisse gezielt außen vor lassen.
- Alle Projekt-Verzeichnisse/-Dateien erstmalig “committen”. Im Staging View den Commit mit Informationen zum Autor und Committer sowie mit hinreichenden Kommentaren versehen.
Das führte zu folgendem Bild im Eclipse-View “Git-Repositories”:
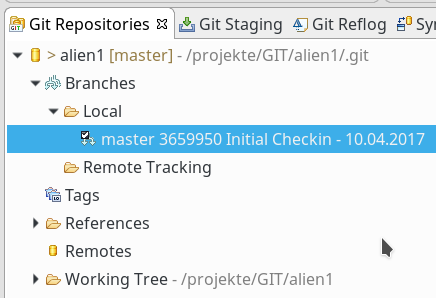
Die Anzeige dieses Views erhält man übrigens über den Menüpunkt “Window=> Show View => Other => GIT => Git Repositories”. Es lohnt sich übrigens gleich auch noch prophylaktisch den View “Git Staging” zu laden.
Wir wenden uns nun der Aufgabe 4 unseres Aufgabenkataloges zu:
- Aufgabe 4: Durchführung von Änderungen im Verzeichnisbaum des Projekts und Testen nachfolgender “Commits”. Blick auf die Git-Versionshistorie auf dem PC. Identifizierung des HEAD-Commmits bzw. -Knotens.
Wer das EGit-Interface nach diesem Artikel genauer studieren will, nutze bitte das Handbuch unter: http://wiki.eclipse.org/EGit/User_Guide
Testverzeichnis und Testdatei
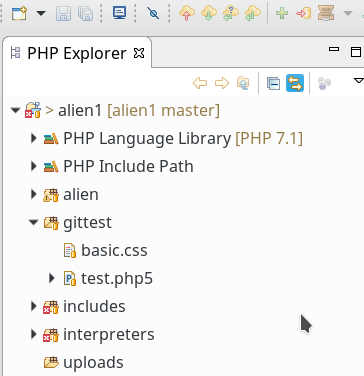
Um die Inhalte des Working Tree nicht zu zerstören, lege ich ein Testverzeichnis “gittest” mit zwei Dateien an : “test.php5” und “basic.css”. Deren Inhalt ist sehr simpel; s.u. Nach der Anlage sieht das im PHP-Explorer so aus:
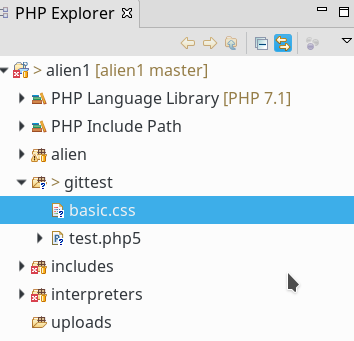
Man beachte die kleinen symbolischen Fragezeichen; sie deuten an, dass der Git-Status noch undefiniert ist.
Zu diesem Zeitpunkt sind die neuen Dateien noch nicht ohne ein “Refresh” (F5) im Working Tree des Views “Git-Repositories” zu sehen:
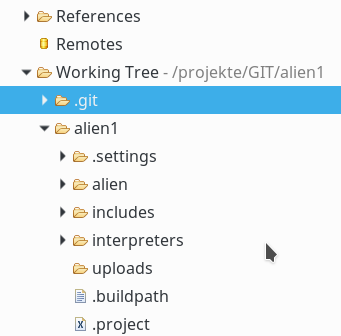
obwohl sie dort natürlich vorhanden
sind. Also F5 drücken.
Um das neue Verzeichnis samt Dateien der Versionsverwaltung zu unterwerfen, müssen wir das neue Verzeichnis in PHP-Explorer auswählen und zunächst in den Index des Repositories aufnehmen. Hierzu benutzen wir, wie im letzten Artikel beschrieben, den Button mit dem grünen “+”-Zeichen in der Git-Bedienleiste unter Eclipse:
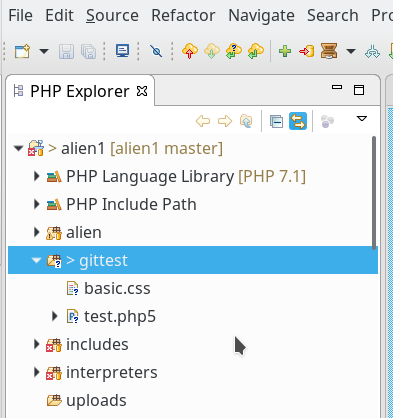
Im “Git Staging View” erhalten wir dann automatisch die Möglichkeit, einen Kommentar einzugeben:
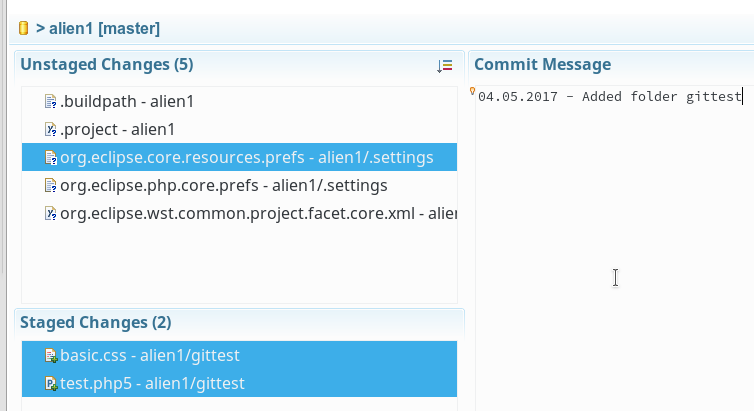
Danach drücken wir rechts unten auf den “Commit”-Button. Anschließend sind die Fragezeichen-Symbole verschwunden:
Der Master-Branch hat sich entsprechend verändert:
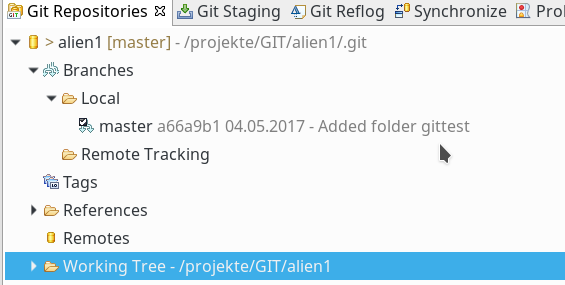
Man beachte die Anzeige des verkürzten Hashes für den Commit, der zur HEAD-Version des aktuellen Branches (im Moment der Master-Branch) führte!
Nun können wir uns mal die sog. “Historie” für “test.php5” ansehen. Dazu rufen wir im Kontext-Menü dieser Datei den Menüpunkt “Team=>Show in History” auf. Im sich öffnenden Historie-View erhalten wir dann:

Es wird der Originaltext der committeten Datei angezeigt. Im Zusammenhang mit dieser Datei gibt es bislang nur einen Knoten, der dem letzten Knoten des Masterbranches entspricht (Man vergleiche die Hashnummern!). Siehe auch, dass im unteren Bereich des Views der aktuelle Stand der Datei “test.php5” mit “/dev/null” verglichen wird!
Dateiänderungen, Commits und Anzeige der Dateiinhalte für verschiedene Knoten
Wir ändern nun den Inhalt der PHP-Datei; wir setzen einen Variablen-Wert um (aus var $a=100; wird var $a=200;) und speichern dann die Datei:
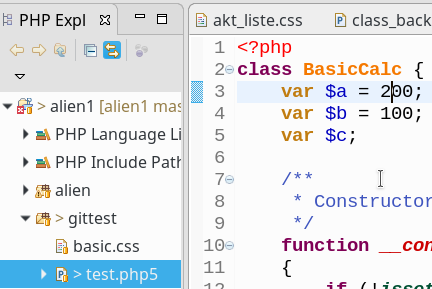
Eclipse zeigt uns (ähnlich wie bei SVN auch) an, dass die Datei zwar geändert wurde, aber die Änderung noch nicht “committed” worden ist. Man erkennt das z.B. am “>”-Symbol an der Datei im Datei- bzw. PHP-Explorer. Um die Änderung im Repository zu erfassen, müssen wir den “Commit”-Button in der Git-Bedienleiste (gelber Zylinder mit rotem Pfeil nach rechts) betätigen. Wie erwartet öffnet sich wieder der “Staging View”, in dem wir die Änderung kommentieren können. Danach drücken wir wieder den Button “Commit”. Ergebnis im Repository-View:
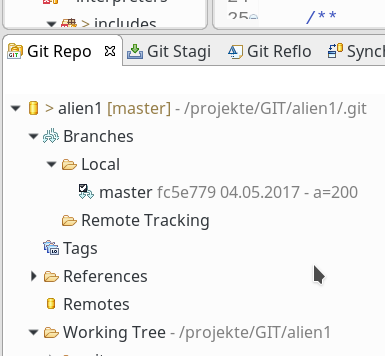
Interessanter ist nun ein Blick in den
View “History”; dort wird die Historie auch in Form eines Graphen angezeigt; die Knoten sind dabei streng gemäß der zeitlichen Historie angeordnet:
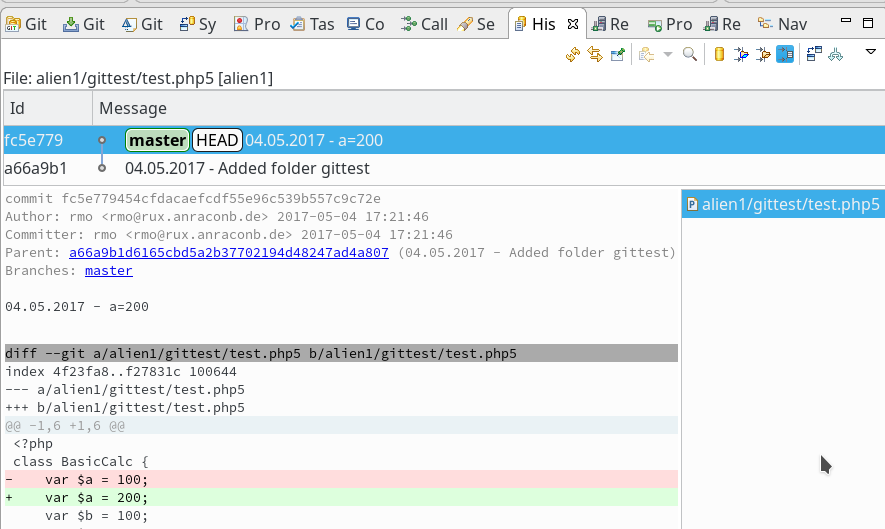
Ggf. nochmal F5 drücken, falls im unteren Bereich die Differenzen nicht angezeigt werden sollten. Wir erkennen nun zwei Knoten (mit unterschiedlichen Hashes), die die Historie dieser Datei betreffen. Netterweise wird uns auch die Änderung zur Vorgängerversion angezeigt. Das ist komfortabel!
Ein Doppelklick auf einen Knoten oder aber auf einen der mit einem Knoten verbundenen Dateinamen rechts unten im History-View öffnet übrigens die durch die Versionsänderung betroffene Datei im jeweiligen Zustand des Knotens im Editorbereich – dort wird hinter dem Namen dann auch der Hash des Commits angezeigt. Sind mehrere Dateien betroffen, wird die erste ausgewählte geöffnet.
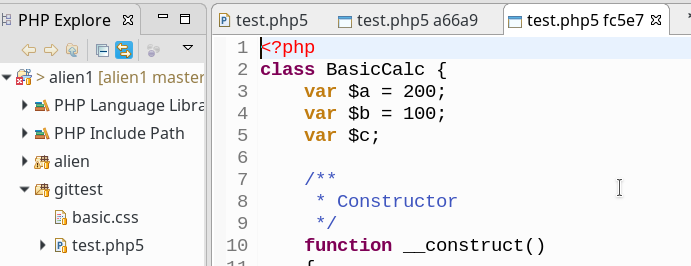
Klickt man allerdings in der Icon-Leiste, die sich im History View rechts oben befindet, das Icon für den “Compare Mode” (links neben dem Branch-Icon), so öffnet sich die Datei im “Compare-Modus”; die Inhalte der Version des früheren Knotens werden mit der aktuell vorhandenen Version des momentan gewählten Branches verglichen.
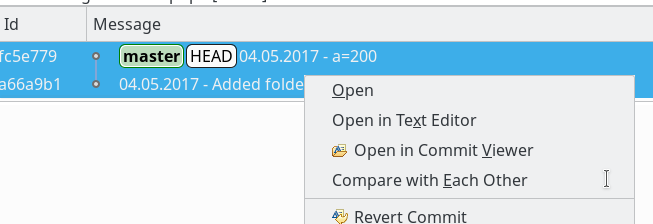
Ein Markieren zweier Knoten des Graphen und ein “rechter Mausklick” öffnet ein Kontextmenü; auch hierüber erhalten wir die Option (Menüpunkt “Compare with each other”), ein Vergleichsfenster für diese Versionen im Editorbereich von Eclipse zu öffnen:
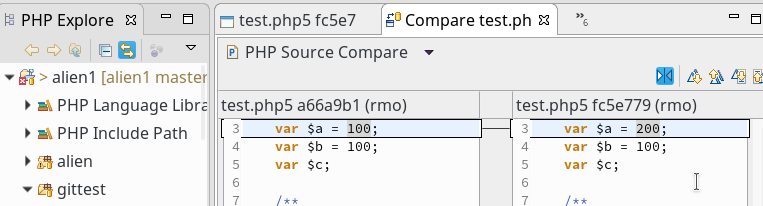
Das ist in unserem Fall trivial, da bislang ja nur zwei Knoten existieren. Die genannten Möglichkeiten des History-Views entfalten ihren vollen Nutzen natürlich aber vor allem bei längeren und komplexeren Historien.
Eine längere Änderungshistorie
EGit liefert noch sehr viel Möglichkeiten und Views mehr als oben beschrieben. Der Leser kann ja nun selbst mal eine Kette von Änderungen an verschiedenen Testdateien vornehmen und jede dieser Änderung committen. Natürlich ist das nicht die normale Situation in einem ernsthaften Entwicklungsprozess; wir spielen im Moment ja aber nur, um uns an EGit zu gewöhnen.
Die nachfolgende Darstellung zeigt dann das Ergebnis nach 5 bzw. 4 weiteren Änderungen an unseren beiden Testdateien “test.php” und “basic.css” im View “History“. Den History View erreicht man übrigens auch durch einen “rechte-Maus”-Klick auf den Branch im View “Git Repositories”; dort ist “Show In => History” zu wählen:
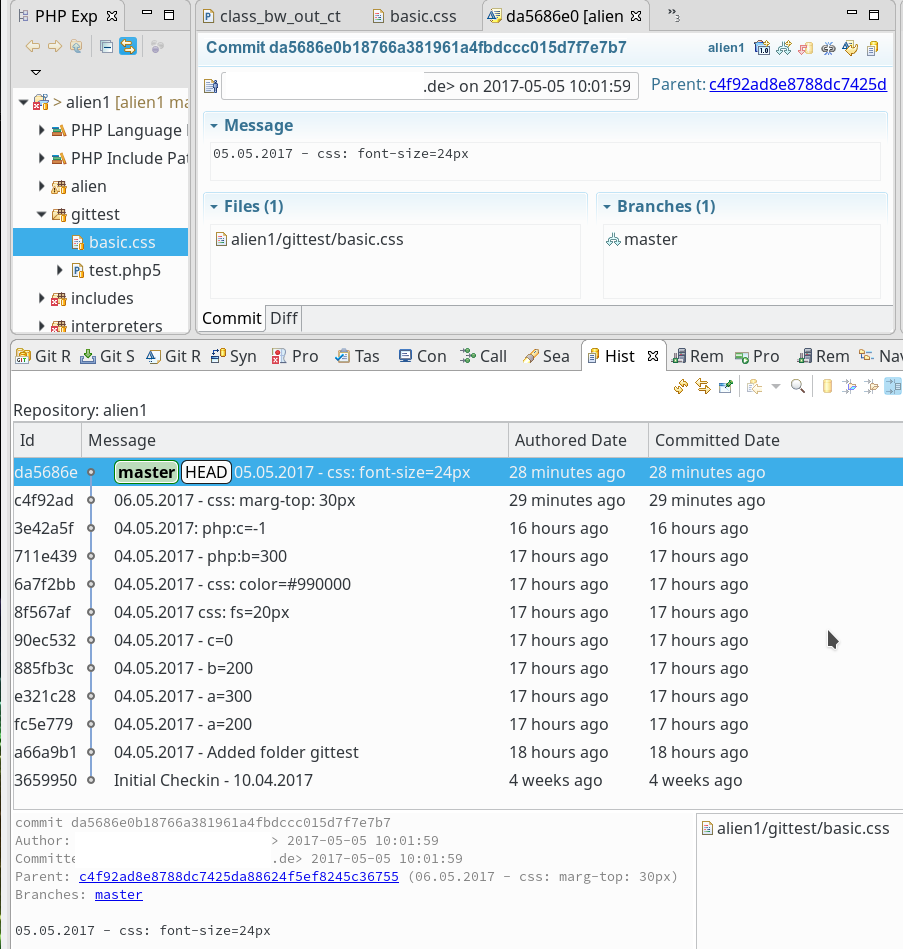
Wir bekommen nun eine etwas umfangreichere Darstellung der erstellten Knoten in unserem Master-Branch. Ein “Rechte-Maus-Klick” auf einen Knoten führt übrigens zu einem Kontextmenü, über dessen Punkt “Open in Commit Viewer” man auch eine Ansicht der zugehörigen Commit-Einträge (Kommentare etc.)
öffnen kann.
Unser lineare Graph ist im Moment allerdings immer noch etwas langweilig, da wir bislang kein Branching vorgenommen haben.
Testweises Branching
Branching gehört zwar nicht zum Umfang dieser Serie von Posts zu Git. Damit die Graphen jedoch nicht ganz so langweilig aussehen, müssen wir aber unseren Master-Branch durch weitere Entwicklungszweige ergänzen. Dort sind neue Knoten zu erzeugen und auch ein Zusammenführen von Entwicklungszweigen (Mergen) ist natürlich interessant. Ich gehe hier allerdings nur kurz auf diese Thematik ein. Das gewählte Beispiel ist entspricht dabei nur einer wenig sinnvollen, praxisfernen Spielerei; wer einen schnellen und realitätsnahen Überblick darüber gewinnen will, wie man Branching für verschiedene Situationen eines Entwicklungsprozesses effektiv nutzt, möge sich z.B. das Buch “Git” von Rene Preißel und Bjørn Stachmann (dpunkt.verlag) zu Gemüte führen.
Einen neuen Branch legt man im View “Git Repositories” z.B. über das Kontextmenü des Zweiges “Branches => Local” an.
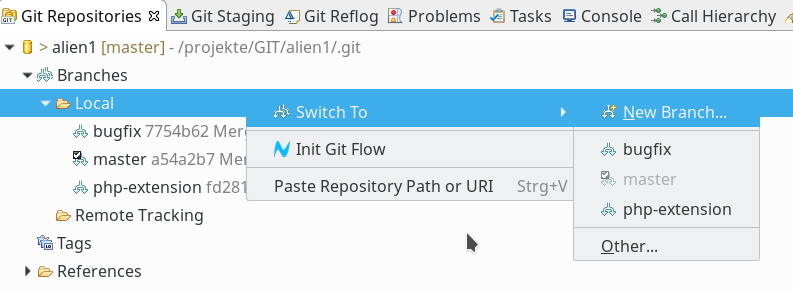
Danach gibt man in einem Popup-Formular den Namen des neuen Branches an; die Option “Checkout” zum Wechseln in den Branch ist bereits vorbelegt:
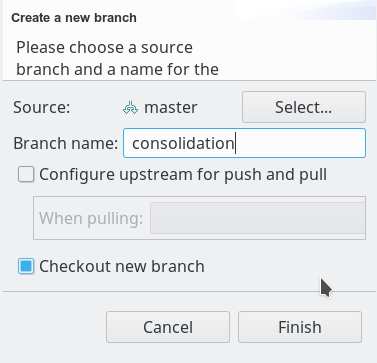
Man erkennt danach im View “Git Repositories”, dass der neue erzeugte Branch “Consolidation” auch der aktuelle (Arbeits-) Branch geworden ist (kleiner schwarzer Haken). Alle kommenden Änderungen finden auf den vorhandenen Dateiständen dieses Branches statt, bis man ggf. den Branch des Repositorys wieder gezielt wechselt.
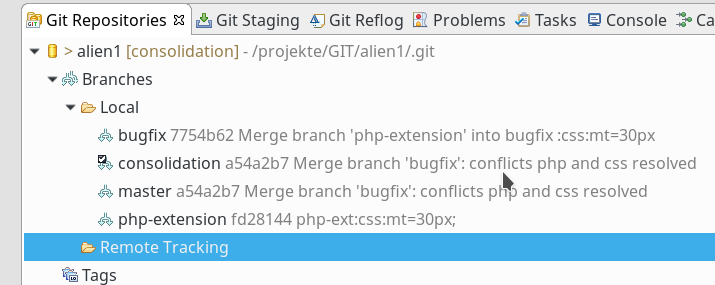
Man erkennt an der Abbildung, dass ich auf diese Weise bereits insgesamt 4 Branches zu meinem Repository angelegt habe – neben dem “master” die Brances “bugfix”, “consolidation” und “php-extensions”. Nun kann man in diesen Branches testweise die gleiche Datei (test.php5) in unterschiedlicher, aber konflikterzeugender Weise editieren und dann im jeweiligen Branch durch Commit einen neuen Knoten erzeugen. Die jeweiligen Dateiversionen in den jeweiligen Branches sollen danach einander widersprechende Inhalte besitzen.
Ich ändere beispielsweise im Branch “bugfix” den Wert von $a auf “$a=10” ab. Dazu muss ich zuerst in den Branch “bugfix” wechseln. Dies geht wieder im Kontextmenü von “Local”:
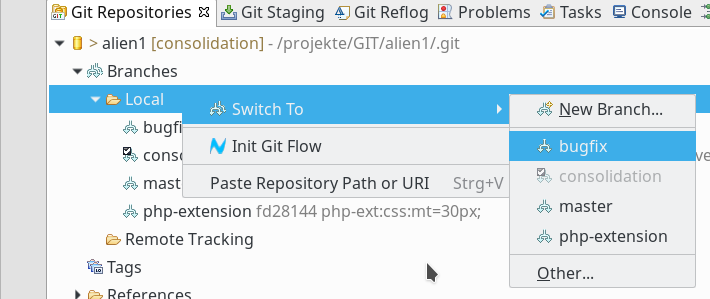
Ist die Datei “test.php5” schon im Editor-Bereich geöffnet, ändert sich der Editor-Inhalt automatisch auf den des aktuellen Branches. Nach dem Branch-Wechsel führen wir die Änderung “$a=10;” durch und committen die neue Version. Dann machen wir eine entsprechende unabhängige Änderung “$a=20” in der gleichen Datei des Branches “php-extensions” und committen auch dort. Abschließend nehmen wir eine Änderung “$a=30” im Branch “master” vor. Schließlich wechseln wir in den Branch “consolidation”. Dort setzen wir “$a=40” und committen.
Wir “mergen” nun in einem weiteren Schritt den Branch “bugfix” in den Branch “consolidation”. Wir lösen den Merge-
Vorgang über das Kontextmenü des Branches “consolidation” aus:
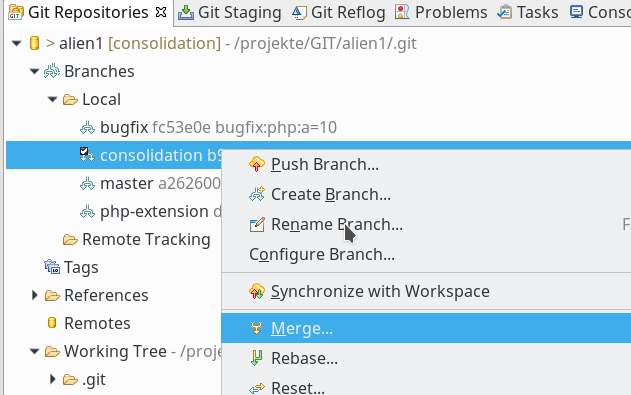
In unserem speziellen Fall muss das zu einem Konflikt führen. Grund ist, dass in den zu mergenden Dateien unterschiedliche Vorgaben in demselben betroffenen Zeilenbereich stehen und die logische Historie nicht eindeutig ist. Git kann nicht wissen oder erschließen, welche Änderung in welchem Branch die gewünschte sein soll. Beide Änderungen sind ja nach dem Zeitpunkt der Verzweigung in gleichen Codebereichen erfolgt. (In manchen Git-Tools kann man übrigens einstellen, ob man rein der zeitlichen Abfolge vertrauen soll. Ich nutze ein solche Option aber aus guten Gründen nie).
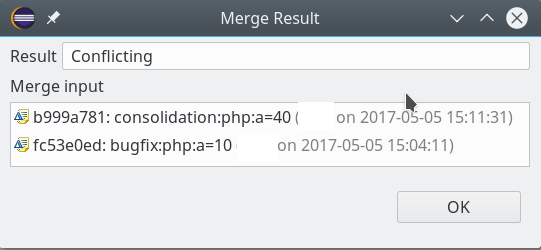
Der Konflikt wird auch an anderer Stelle deutlich markiert; im geöffneten Editor einer betroffenen Datei u.a. durch gezielt vorgenommene Einschübe:
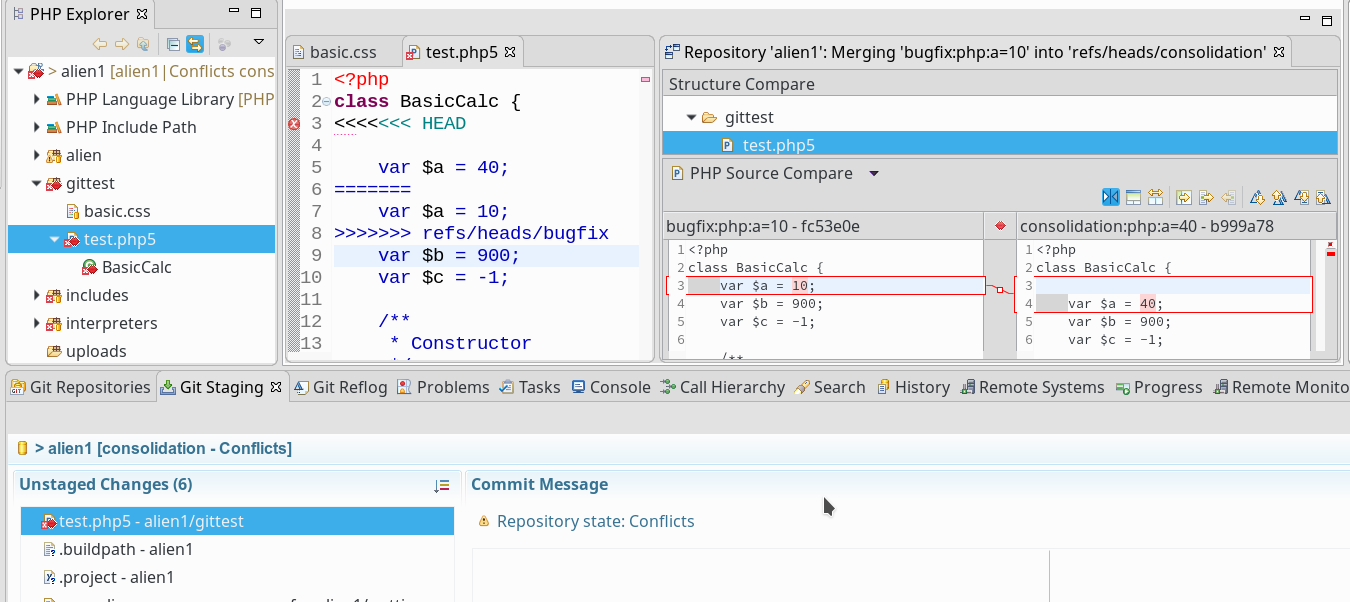
Man beachte die Markierung der verschiedenen Varianten im Editor durch “>>>” und “<<<” Zeilen. Im PHP Explorer View “Git Staging” ist der Konflikt dagegen durch eine deutliche rote Markierung am jeweiligen Dateieintrag hervorgehoben.
Rechts sieht man übrigens das sog. “merge tool”, dass man etwa über das Kontext Menü der Datei im unteren Bereich “Unstaged Changes” öffnen kann. Es geht aber immer auch über Unterfunktionen des Punktes “Team” im Kontext-Menü der Datei im PHP-Explorer.
Wir lösen den Konflikt im Editor auf; d.h. wir entscheiden uns dabei für eine der angedeuteten Varianten, z.B. die Variante vom Branch “bugfix” (a=10). Die nicht gewünschten Zeilen und die Markierungszeilen aus dem Merge-Prozess löschen wir.
Wir speichern die geänderte Datei dann ab; diese ist dadurch aber noch nicht in den Index des Branches aufgenommen. Aus Sicht des Views “Git Staging” ist der Konflikt somit noch nicht behoben; eine Aktualisierung F5 hilft nichts und auch ein “Commit” ist nicht möglich. Hier muss man vielmehr eine explizite Entscheidung zur Aufnahme der eben als künftiges Soll gespeicherten Version in den Index wählen; dies geschieht im Kontextmenü des Git-Staging-Views durch Auswahl des Punktes “Add to index“:
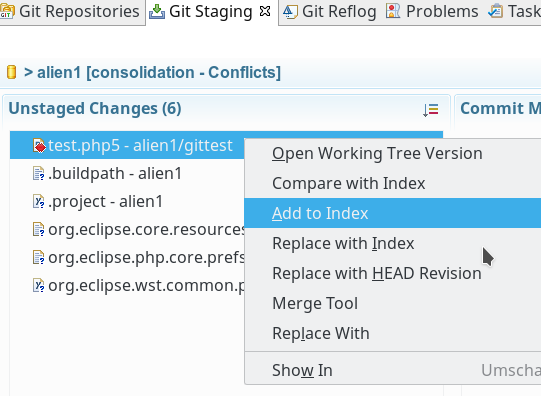
Danach ist ein Commit unserer neuen Dateiversion möglich:
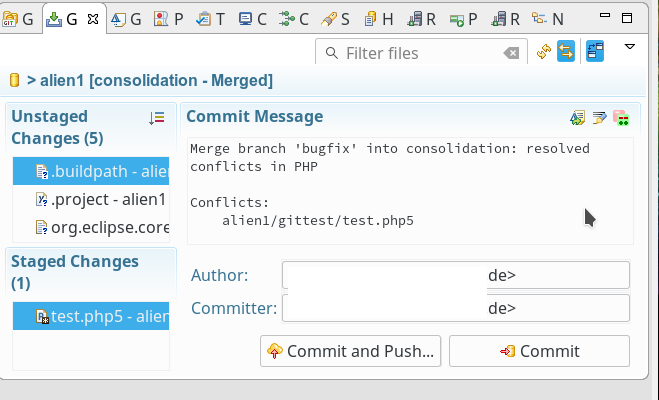
Hinweis:
Alternativ zu einer direkten Arbeit im Editor ist auch das Arbeiten über das “Merge Tool”, das im wesentlichen einer Diff-Azeige mit Zusatzfunktionen entspricht, möglich. Das mag jeder mal selber ausprobieren.
Wir committen und mergen danach in ähnlicher Weise den Branch “php-extension” in den Branch “consolidation”. Dabei entscheiden wir uns für den Wert von “$a=20” aus “php-extensions”.
Zwischenzeitlich können wir immer mal den Zustand des jeweils aktiven Branches im
View “History” begutachten (zur Sicherheit dort F5 drücken):
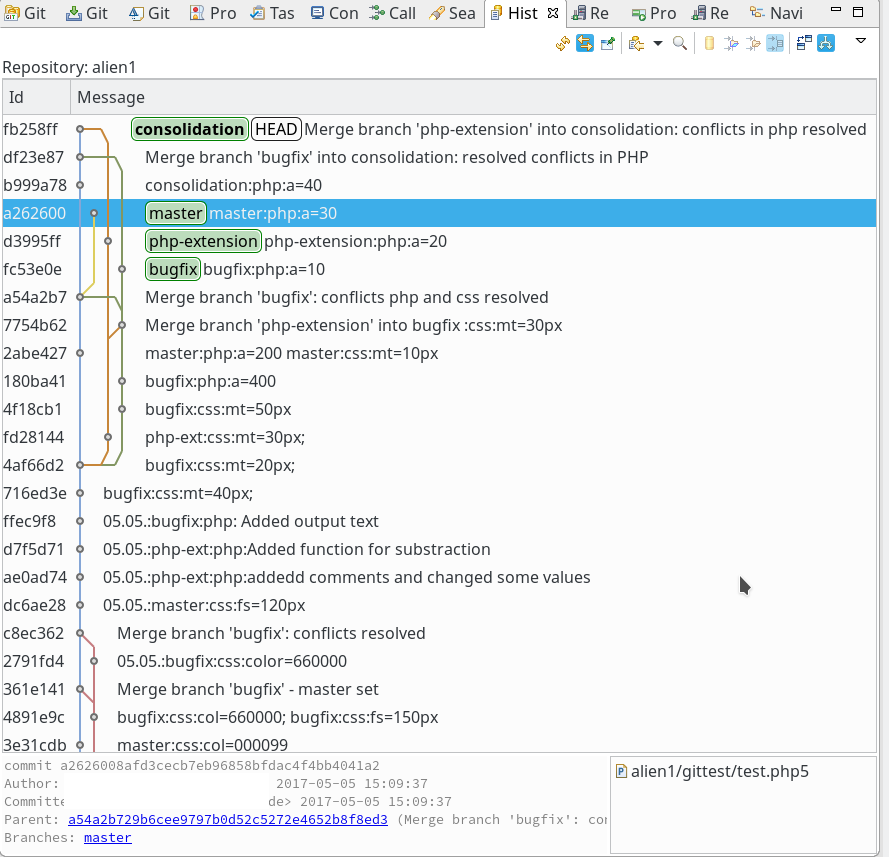
Bei mir sieht das so kompliziert aus, weil ich in den anderen Branches bereits früher Änderungen durchgeführt hatte. Der “consolidation”-Branch wurde ja aus dem Master-Branch im Zustand “a54a2b7” erzeugt; seine “Vergangenheit” davor ist mit der des Master-Branches identisch.
Durch Klicken des rechten Branch-Symbols oben rechts in der Icon-Leiste dieses Views erhält man übrigens eine graphische Ansicht aller vorhandenen Branches. Es gibt in dieser Icon-Leiste noch weitere interessante Möglichkeiten, deren Studieren sich lohnt. Interessant ist ferner das Markieren zweier Versionen aus dieser Ansicht, die man dann per Kontext-Menü direkt in einer “Compare”-Ansicht öffnen und vergleichen kann.
Schließlich mergen wir noch den “consolidation”-Branch in den Master-Branch und übernehmen dabei den Wert des “consolidation”-Branches. Wir erhalten am Ende eine recht komplex wirkende Branch-Historie; im oberen Bereich sind die hier angesprochenen Änderungen mit den Hash-Nummern “fc53e0e, d3995ff, a262600, b999a78, df23e87, fb258ff, f48c829” zu sehen:
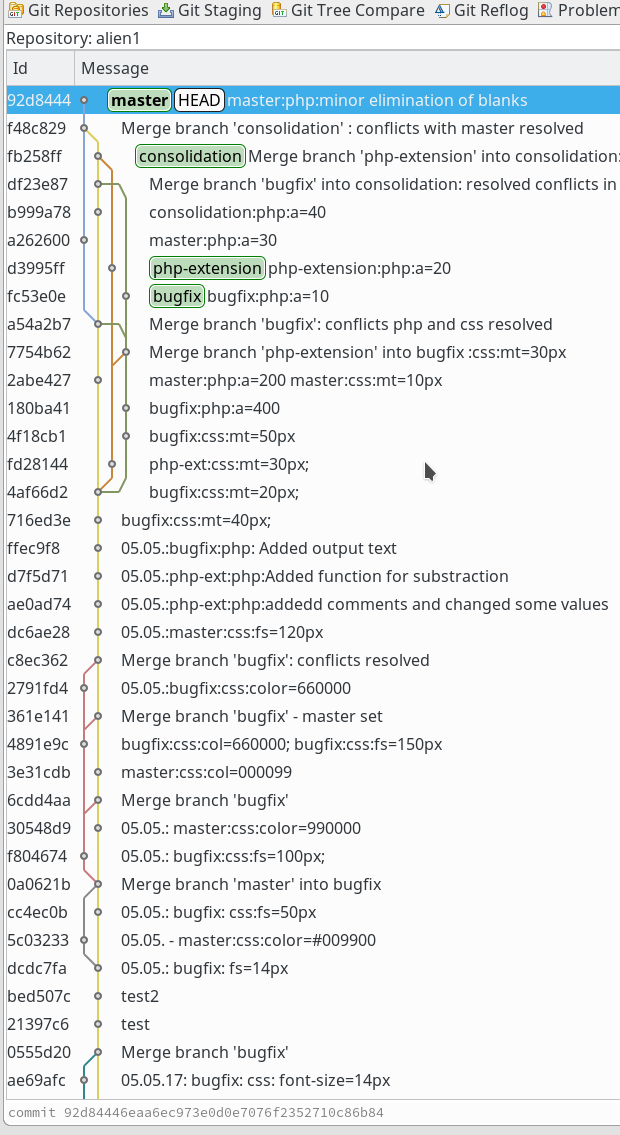
Hinweis zu sog. “Fast Forward Branches”:
In unserem Beispiel zu Branching haben wir gezielt Konflikte provoziert, die bei den verschiedenen Merges manuell beseitigt werden mussten. In vielen Fällen erfolgen aber Code-Änderungen z.B. durch Hinzufügen von Code-Fragmenten oder durch Code-Änderungen, die nicht in Konflikt mit der letzten gemeinsamen Version von zwei Branches stehen, wenn im Zielbranch an dem betroffenen Codesegment seit der Verzweigung nichts geändert wurde. Entsprechende Änderungen haben eine eindeutige logische Historie und können in Form sog. einfacher “Fast Forward Merges” [FFM] abgewickelt werden: EGit übernimmt die Änderungen dann einfach automatisch in die Target-Datei; ein manuelles Eingreifen ist nicht nötig. Ein “FFM” wird in einem Zwischendialog nach dem Mergeversuch angekündigt; das Merge-Popup (s.o.) erlaubt spezielle Einstellungen für FFMs.
Da Git aber nicht die Semantik der Änderungen überprüfen kann, muss man auf der Basis vorhergehender Codevergleiche natürlich auch im Fall von FFMs sicher sein, dass man mit der direkten Übernahme der Änderungen keinen Unsinn anrichtet. Das Denken nimmt einem Git nicht ab.
Andere Tools
Später werden wir zur Überwachung und ggf. Manipulation zentraler (!) Repositories auf den jeweiligen Servern (grafische) Tools installieren müssen, die unabhängig von Eclipse und EGit funktionieren. In Frage kommen aus dem Opensource Umfeld etwa:
GitGui (wird mit dem Git-Paket ausgeliefert; wirkt wegen Tcl/Tk etwas hausbacken, Graphen; umfangreicher Satz von Werkzeugen zur Repository-Pflege), Git Cola (Graphen; nützliche Funktionen zur Manipulation des Repositories), QGit (Graphen und einige einfache Manipulationsbefehle), GitG (web-ähnliche Oberfläche) sowie Giggle (Graph und Klon-Funktion). Die zugehörigen Pakete lassen sich für die jeweilige Linux-Distribution relativ einfach finden und installieren; ich gehe hier nicht darauf ein.
Alle genannten Tools erlauben eine Anzeige der vorhandenen Branches, ihrer Knoten und zumindest von Versions-Differenzen eines ausgewählten Knotens zur Vorgängerversion. Der Umfang an Funktionalitäten zur Pflege/Manipulation des Repositories ist unterschiedlich; hervorzuheben sind hier “Git
GUI” und “Cola Git”. Für eine einfache Graphenanzeige genügen GitG, QGit und Giggle.
Ich zeige abschließend den oberen Teil der Graphen in GitGui (gitk-Ansicht), QGit, Giggle, Cola-Git (DAG). Das ist alles recht ähnlich; die DAG-Ansicht finde ich eher verwirrend – hier wird die Logik zu stark komprimiert. Cola-Git bietet alternativ aber auch die gitk-Ansichten von GitGui.
GitGUI
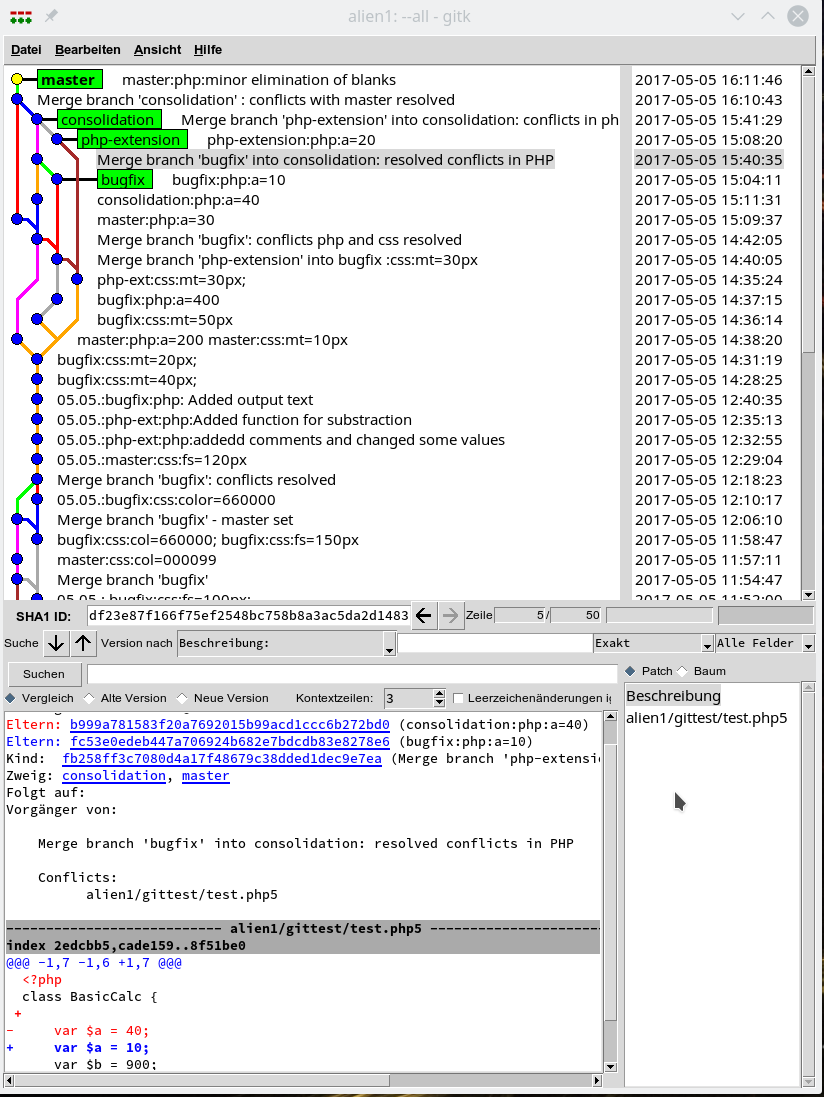
QGit
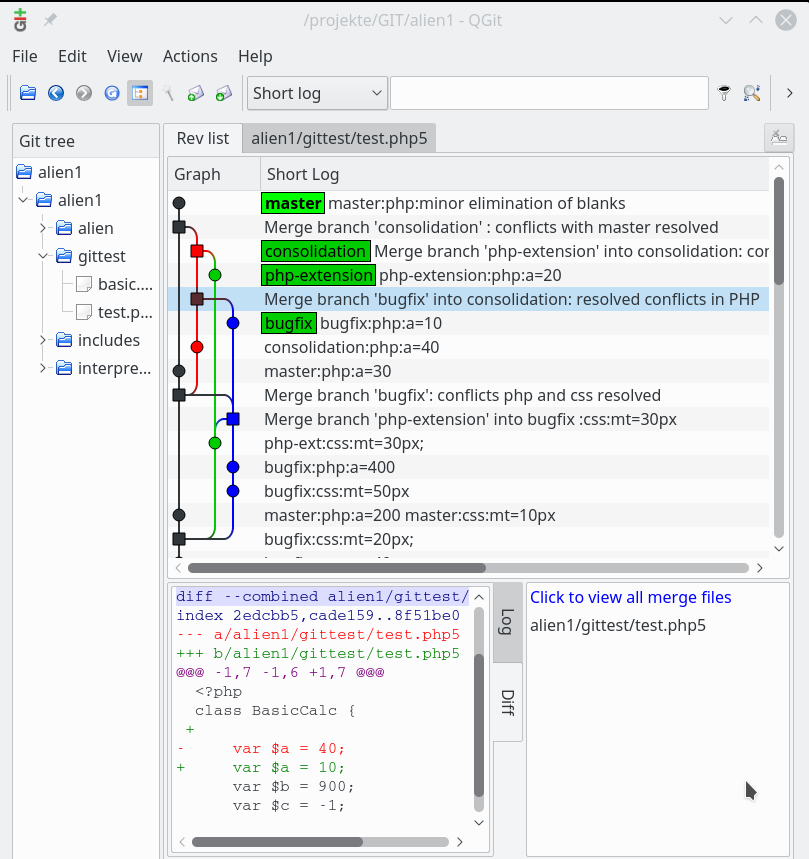
Giggle
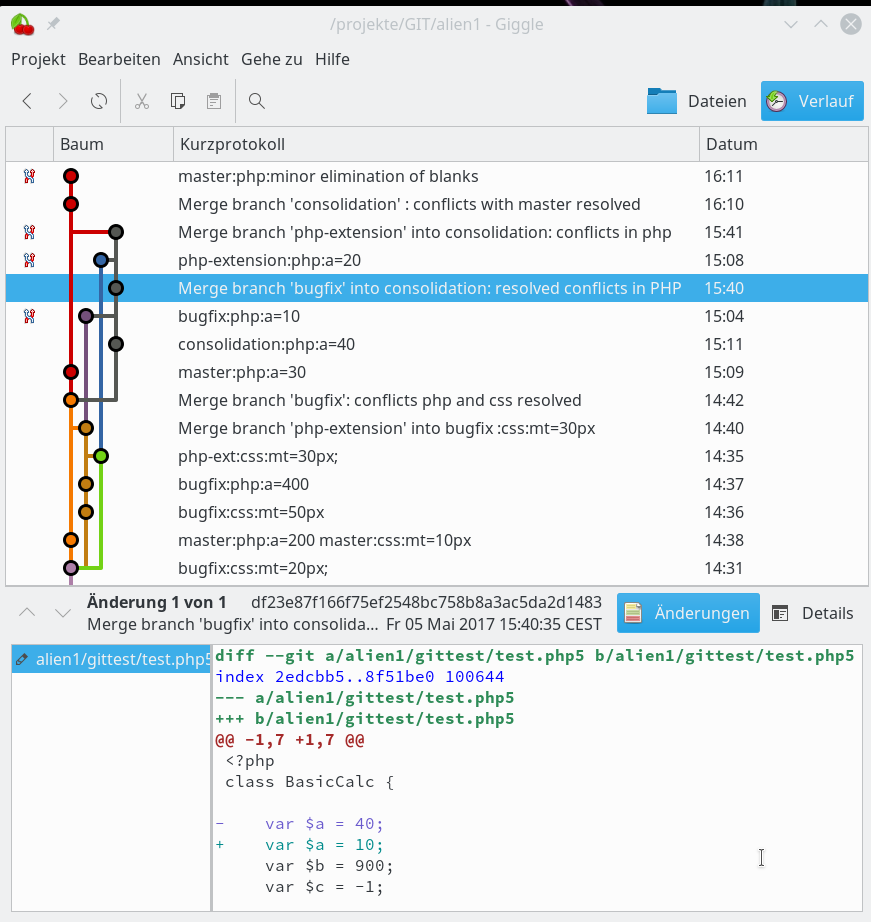
Cola-Git (DAG-Ansicht)
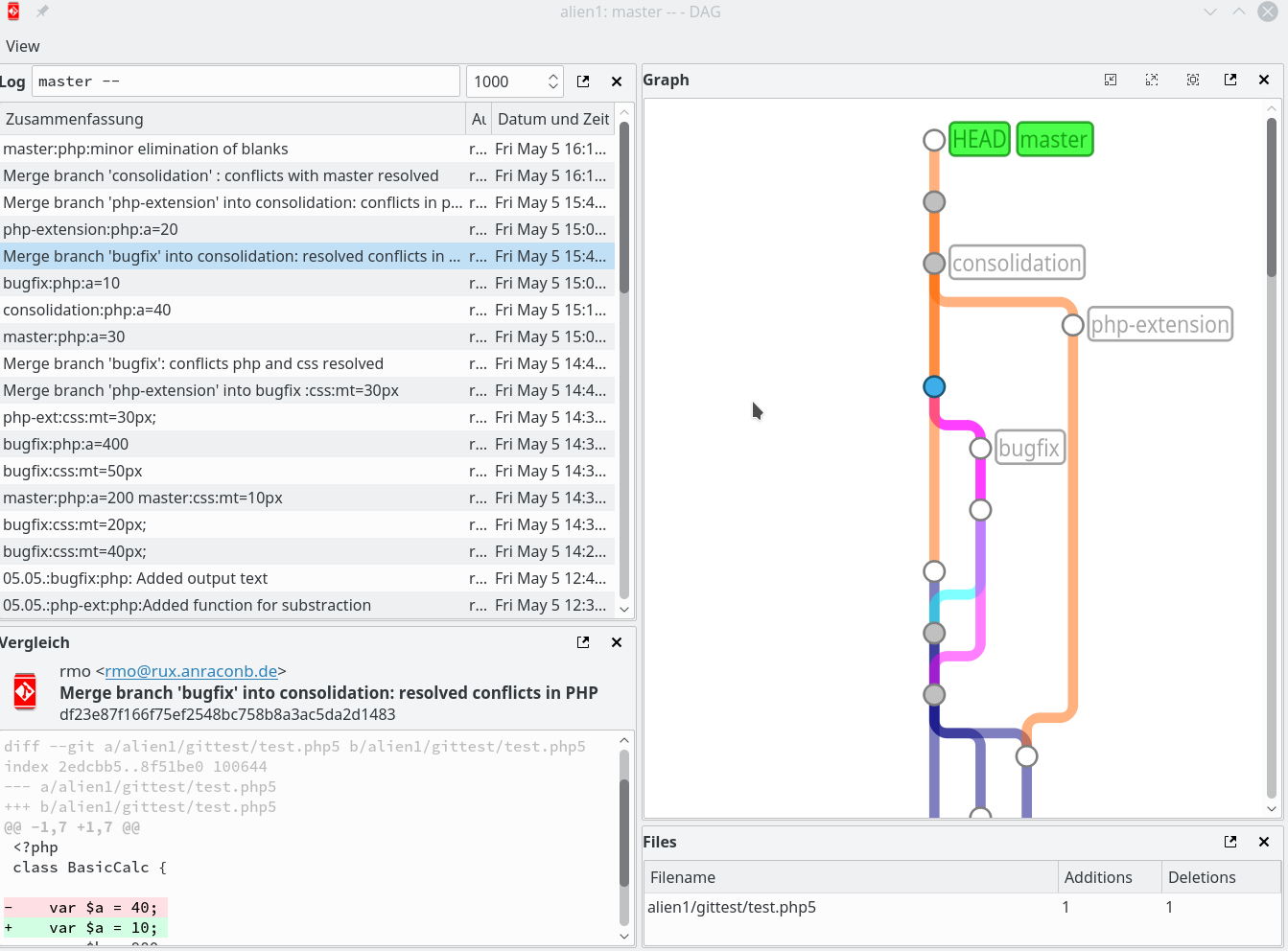
In GitG, GitGui, Cola Git (gitk) kann man zwischen einer rein chronologischen und einer topologisch-logischen Graphendarstellung wählen. Eine rein chronologische Darstellung hilft in einen komplizierten Situationen die Historie zu rekonstruieren.
Fazit
Das EGit-Plugin für Eclipse bietet einige hübsche Features an, um die Historie von Änderungen zu verfolgen. Wir haben in diesem Artikel allerdings nur an der Oberfläche gekratzt. Der Leser ist aufgerufen, weitere Möglichkeiten zu erkunden. Zumindest für ein lokales Repository werden dabei kaum Wünsche offen gelassen. Auch die Graphendarstellung für einzelne Branches im History-View braucht sich nicht zu verstecken. Die Knoten sind chronologisch geordnet – und neben jedem Knoten wird in einer separaten Spalte der zugehörige verkürzte Hash angezeigt. Das bietet komischerweise keines der anderen Tools an.
Die Funktionalitäten von EGit kann man übrigens auch in einer von Eclipse unabhängigen Form genießen. Hierzu lädt man sich die entsprechende Anwendung “GitEye” der Fa. CollabNet (s. https://www.collab.net/downloads/giteye) für Linux herunter. Das Archiv einfach expandieren und GitEye starten.
Im Vorgriff auf ein Monitoring und eine direkte Verfolgung von Änderungen eines zentralen Git-Repositories auf einem entfernten Host haben wir einen kurzen Blick auf andere Tools geworfen, die sich ebenfalls leicht installieren lassen und wie EGit eine grafische Aufbereitung bieten. Auch hier gilt es, sich mit den Möglichkeiten und Grenzen der Tools vertraut zu machen.
Im nächsten Artikel dieser Serie
Erste Schritte mit Git für lokale und zentrale Repositories unter Eclipse – IV
verfolgen wir allerdings die im ersten Artikel gesetzten Ziele weiter. U.a. werden wir ein zentrales Repository auf einem Host im LAN anlegen und auch dieses Repository mit Push-Befehlen auf einen aktuellen Stand bringen. Parallel werden wir uns die durchgeführten Änderungen auf dem zentralen Tool über QGit ansehen. Das entspricht den Aufgaben 5 -7 des ersten Artikels.