Ich setze mit diesem Blog-Post meine kleine Serie von Artikeln zum Thema GIT-Einsatz unter Eclipse fort. Im ersten Beitrag
Erste Schritte mit Git für lokale und zentrale Repositories unter Eclipse – I
hatte ich ein einfaches Einsatz-Szenario für freiberufliche Entwickler dargestellt, die mobil unterwegs sein müssen und ihre Versionsentwicklung regelmäßig zwischen PCs, Laptops und einem oder mehreren zentralen Servern abgleichen müssen:
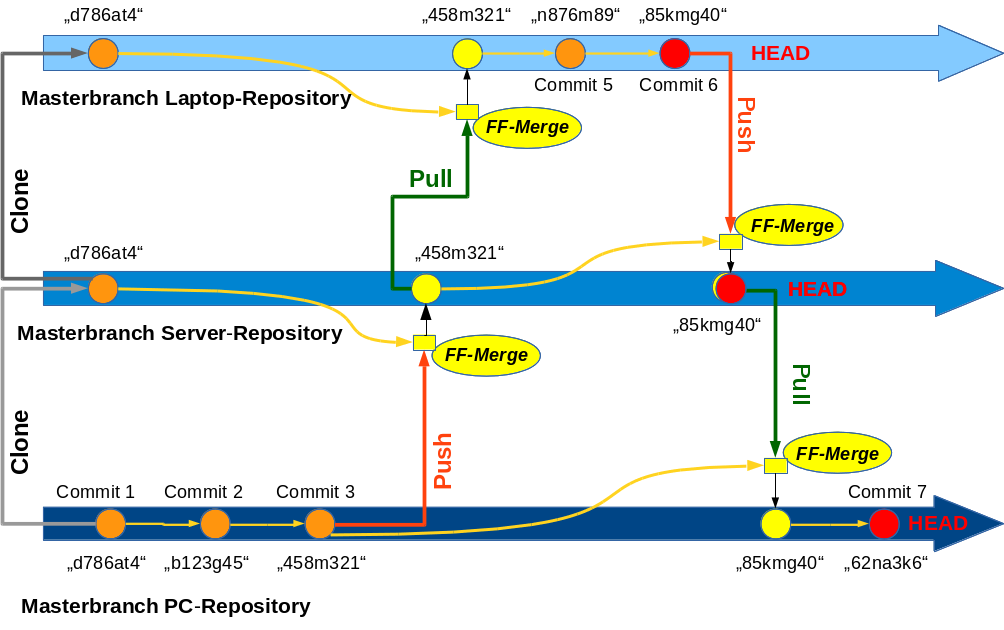
Im LAN des Homeoffice wird mit einem lokalen Git-Repositories auf dem Arbeitsplatz-PC gearbeitet. Änderungen sollen schon aus Backup-Gründen zeitnah in ein zentrales Git-Repository im LAN überführt werden. Über den LAN-Server soll bei Bedarf aber auch ein Laptop versorgt werden; das dortige lokale Repository wird zum Arbeiten während Reisen benutzt. Zur Sicherheit wird der Status auf dem Laptop mit einem zentralen Repository im Internet abgeglichen, wann immer sich dazu die Gelegenheit bietet.
Die Frage ist: Wir organisiert man das unter Eclipse? In den letzten zwei Beiträgen
Erste Schritte mit Git für lokale und zentrale Repositories unter Eclipse – II
Erste Schritte mit Git für lokale und zentrale Repositories unter Eclipse – III
habe ich mich deshalb zunächst mit der Anlage eines lokalen Repositorys auf einem PC mit Hilfe des EGit-Plugins unter Eclipse beschäftigt. [EGit ist übrigens auch als standalone Product unter dem Namen “GitEye” verfügbar.] Wir haben uns anschließend angesehen, wie man Commits durchführt, wie man Branches erzeugt und auch wieder mergt.
Im Zentrum dieses und kommender Blog-Beiträge steht aber vor allem ein zentraler Branch, der sog. “Master”-Branch”. Er stellt in unserem Szenario das wichtigste Bindeglied zwischen den verschiedenen Repositories auf PC, Laptop und zentralen Servern dar. Alle Entwicklungsaktivitäten werden in unserem Szenario letztlich auf ihn ausgerichtet. Wir merken aber bereits an dieser Stelle an, dass sich alle später dargestellten Abgleichverfahren zwischen lokalen und zentralen Repositorys realtiv zwanglos auf mehrere Branches erweitern lassen.
Ich wende mich in diesem Artikel der Anlage eines zentralen Repositorys auf einem Server im LAN zu. In einem zweiten Schritt binde ich dann das erzeugte LAN-Repository an das lokale Repositories unseres Entwicklungs-PCs an. Abschließend wird eine Änderung im lokalen Repository auf das zentrale Repository übertragen (“Push”-Operation). Das Spektrum der behandelten Themen entspricht in etwa der Lösung der Aufgaben 4 bis 7 des ersten Artikels.
SVN-Nutzer wissen, dass ein SVN-Server eine spezielle Konfiguration über definierte Konfigurationsdateien und -verzeichnisse erfordert. U.a sind dabei spezielle Zugriffsrechte festzulegen. Weitere Sicherheitsaspekte sind zu berücksichtigen, wenn man SVN-Dienste über einen Webserver und “https” anbieten will.
Aus meiner Sicht ist die Einrichtung eines GIT-Servers für unser Szenario (aber nicht nur dafür) relativ einfach: Benötigt wird im Grunde nur ein hinreichend konfigurierter SSH-Server, auf dem man den Zugriff auf Verzeichnisstrukturen und Objekte eines “.git”-Verzeichnisses über User- und Gruppen-Accounts steuert. Ansonsten muss dort unter Linux nur das für die jeweilige Distribution passende Git-Paket installiert sein. Mehr ist zum Aufsetzen eines privaten Git-Servers unter SSH fast nicht erforderlich! Hinzu kommen lediglich zwei weitere, einfache Schritte:
- Das auf einem PC bereits
vorhandene Repository (hier für das Eclipse-Projekt “alien1”) ist zu klonen.
- Der Git-Repository-Clone ist in ein definiertes Zielverzeichnis auf dem SSH-Server zu transferieren.
Man kann die oben genannten beiden Punkte mittels GIT theoretisch auch in einem Schritt erledigen; ich ziehe es aber der besseren Kontrolle wegen vor, hier zweistufig vorzugehen. Alle später einzurichtenden Git-Clients nehmen dann auf die URI des angelegten Git-Verzeichnisses auf dem Server Bezug.
Hinweis: Es gibt natürlich auch Möglichkeiten, eigene Git-Server über andere Protokolle und im Rahmen von Web-Server-Diensten einzurichten. Ich gehe in dieser Artikelserie aber nicht darauf ein. Ich sehe auch keinen Grund dafür, für unser einfaches privates Szenario nicht eine simple und sichere SSH-Variante zu nutzen.
Ich gehe in diesem Artikel zudem nicht auf die Bereitstellung und Konfiguration von SSH auf einem Server ein. Das habe ich an anderer Stelle dieses Blogs schon beschrieben. Ich gehe im LAN ferner von einem einfachen UID-bezogenen Login auf dem SSH-Server mittels eines Passwortes aus; für einen später zu kontaktierenden SSH-Server im Internet setze ich dagegen einen Login per RSA-Key (hinreichender Länge plus sicherem elliptischem KEX-Verfahren) voraus.
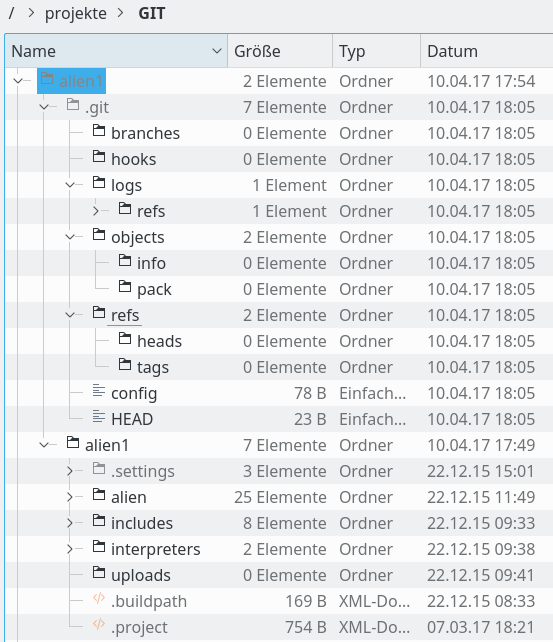
Unser LAN-Server heiße “debian8” und sei einer lokal definierten Domäne “lanracon.de” zugeordnet. Der Server sei aufgrund entsprechender DNS-Einträge aber auch direkt unter “debian8” ansprechbar. Ich gehe davon aus, dass wir auf diesem Server z.B. Giggle oder QGit installiert haben, um dort einen Blick auf neu installierte Repositories werfen zu können (s. hierzu auch den vorhergehenden Blog-Artikel). Das übergeordnete Zielverzeichnis für Git-Repositorys auf dem Server sei “/projekte/GIT/”. Das zentral zu erzeugende Repository beziehe sich in unserem Beispiel – wie das zuletzt betrachtete PC-Repository auch – auf unser PHP-Eclipse-Projekt namens “alien1”.
Auf einem Git-Server benötigen wir in der Regel keinen Working Tree. Das Erzeugen eines Clones ohne Working Tree gelingt mit Hilfe des “git clone”-Befehls und bestimmter Optionen.
Ich bemühe an dieser Stelle die Kommandozeile einer Shell. Man kann zwar auch mit EGit ein vorhandenes Repository in lokale Verzeichnisse klonen; aber wir wollen ja anschließend die Clone-Dateien auch noch auf den Server bringen. Das ginge theoretisch zwar auch über geeignete grafische Eclipse-Tools für den Remote-Systems-Zugriff; warum aber mit Kanonen auf Spatzen schießen?
Das Repository und der Working Tree unseres Beispiels aus den letzten Blog-Posts waren auf unserem Entwicklungs-PC im Verzeichnis “/projekte/GIT/alien1” beheimatet. Ich lege mir für die Zwischenspeicherung des Clones und den anschließenden Transfer auf den Server im vorhandenen GIT-Verzeichnis des PCs (oder Laptops) aber ein separates Verzeichnis an – hier namens “alien1trans“. Also
myself@mytux:/projekte/GIT> mkdir alien1trans
myself@mytux:/projekte/GIT> cd alien1trans/
Die Struktur des notwendigen “clone”-Befehls ist:
git clone --bare <em>Repo-Pfad Target-Dir-Pfad</em>
Für die Erzeugung eines Repositorys ohne “Working Tree”-Verzeichnis sorgt die Option “–bare“. Wird der Target-Dir-Pfad des Verzeichnisses, in das geklont werden soll, nicht angegeben, wird der Clone im aktuellen Verzeichnis (Working Directory) angelegt. In unserem Fall ergibt sich:
myself@mytux:/projekte/GIT/alien1trans> git clone --bare ../alien1
Klone in Bare-Repository 'alien1.git' ...
Fertig.
myself@mytux:/projekte/GIT/alien1trans> ls -la
insgesamt 12
drwxr-xr-x 3 myself entw 4096 6. Mai 09:28 .
ndrwxr-xr-x 6 myself entw 4096 6. Mai 09:27 ..
drwxr-xr-x 7 myself entw 4096 6. Mai 09:28 alien1.git
myself@mytux:/projekte/GIT/alien1trans> du -s -h
60M .
myself@mytux:/projekte/GIT/alien1trans> cd ../alien1
myself@mytux:/projekte/GIT/alien1> du -s -h
225M .
myself@mytux:/projekte/GIT/alien1> du -s -h .git
60M .git
myself@mytux:/projekte/GIT/alien1>
myself@mytux:/projekte/GIT/alien1> cd ../alien1trans/
myself@mytux:/projekte/GIT/alien1trans> mv alien1.git/ .git
myself@mytux:/projekte/GIT/alien1trans> ls -la
insgesamt 12
drwxr-xr-x 3 myself entw 4096 6. Mai 11:25 .
drwxr-xr-x 6 myself entw 4096 6. Mai 09:27 ..
drwxr-xr-x 7 myself entw 4096 6. Mai 09:28 .git
Wie man sieht, habe ich im Anschluss an das Klonen die korrekte Größe des Clone-Verzeicnisses geprüft. Das reine Repository (hier “alien1.git”) ist offenbar deutlich kleiner als der Working Tree selbst! Am Schluss habe ich das Repository-Verzeichnis des Clones, das als Anteil immer den Namen des Ursprungsrepositories erhält, noch in “.git” umbenannt. Grund: Viele Git-GUI-Programme suchen automatisch nach einem Verzeichnis namens “.git”.
Ok, wir haben nun einen Clone auf unserem PC. Wie bringen wir den jetzt auf den Server “debian8.lanracon.de”? Natürlich mittels SSH. Ich gehe mal davon aus, dass der User “myself” aus der Gruppe “entw” auch auf dem Server vertreten ist und sich dort per Passwort anmelden darf. Er verfüge über die notwendigen Schreibrechte im übergeordneten Zielverzeichnis auf dem Server, in dem wir spezifische GIT-Repositories aufbewahren wollen. Zunächst legen wir auf dem Server ein spezielles Zielverzeichnis für das “alien1”-Repository an:
myself@mytux:/projekte/GIT/alien1trans> ssh myself@debian8
Password:
Last login: Sat May 6 11:41:46 2017 from xxx.xxx.xxx.xxx
Have a lot of fun...
myself@debian8:~> cd /projekte/GIT
myself@debian8:/projekte/GIT> mkdir alien1
myself@debian8:/projekte/GIT> exit
Abgemeldet
Connection to debian8 closed.
myself@mytux:/projekte/GIT/alien1trans>
Ich habe hier mal angenommen, dass wir auf dem Server bereits eine ähnliche Verzeichnisstruktur wie auf dem PC angelegt hatten. Das muss natürlich nicht so sein. Also das Zielverzeichnis bitte dort anlegen, wo man seine GIT-Repositories verwalten will.
Hinweis: An dieser Stelle können bereits Rechte (im Besonderen Gruppenrechte) eine Rolle für die spätere Nutzung des Repositories durch andere User spielen. Ich regele die korrekten Rechte auf Servern, die ich selbst komplett unter Kontrolle habe, meistens über ACLs und/oder das SGID-Bit. Das erspart einem viel Arbeit. Egal wie – es ist jedenfalls dafür zu sorgen, dass das Verzeichnis die richtige Gruppe und einen passenden Rechtekamm erhält.
Nun kopieren wir einfach die Dateien des geklonten “.git”-Verzeichnisses per “scp” vom PC auf den Server:
myself@mytux:/projekte/GIT/alien1trans> scp -r .git myself@debian8:/projekte/GIT/alien1/
Password:
...
....
99eaff29e3720789e5e75e9e8999a5bde77733 100% 290 0.3KB/s 00:00
a816f7c5ebab36333b9fd8574d459176f3ff07 100% 2416 2.4KB/s 00:00
5f11c90dbb0170c0b2082f1d5fec9a0e10522b 100% 17KB 17.1KB/s 00:00
101f6958c4e18057cfdf7c975a1483eeeddea9 100% 1349 1.3KB/s 00:00
2fd38f7570791c179ec4c94b886ec62027d3a3 100% 9190 9.0KB/s 00:00
config
100% 127 0.1KB/s 00:00
description 100% 73 0.1KB/s 00:00
packed-refs 100% 289 0.3KB/s 00:00
pre-commit.sample 100% 1642 1.6KB/s 00:00
pre-rebase.sample 100% 4951 4.8KB/s 00:00
pre-receive.sample 100% 544 0.5KB/s 00:00
prepare-commit-msg.sample 100% 1239 1.2KB/s 00:00
post-update.sample 100% 189 0.2KB/s 00:00
commit-msg.sample 100% 896 0.9KB/s 00:00
pre-applypatch.sample 100% 424 0.4KB/s 00:00
applypatch-msg.sample 100% 478 0.5KB/s 00:00
pre-push.sample 100% 1348 1.3KB/s 00:00
update.sample 100% 3610 3.5KB/s 00:00
HEAD 100% 23 0.0KB/s 00:00
exclude 100% 240 0.2KB/s 00:00
myself@mytux:/projekte/GIT/alien1trans>
Je nach Größe des Repositorys rast hier eine Reihe von Dateien, die mit Hashes bezeichnet sind, an uns vorüber. Um zu prüfen, ob das Verzeichnis auf dem Server richtig aussieht, nutze ich z.B. Giggle:
myself@mytux:/projekte/GIT/alien1trans> ssh myself@debian8
Password:
Last login: Sat May 6 11:48:46 2017 from xxx.xxx.xxx.xxx
Have a lot of fun...
myself@debian8:~> export NO_AT_BRIDGE=1
myself@debian8:~> giggle &
Hinweis:
Mir passiert es auf Servern mit etwas älterem Kernel regelmäßig, dass ich die Umgebungsvariable NO_AT_BRIDGE mittels
export NO_AT_BRIDGE=1
auf dem Server setzen muss, um Giggle oder QGit (über SSH) zum Laufen zu bringen. Siehe hierzu: https://wiki.archlinux.de/title/GNOME#Tipps_und_Tricks und https://bbs.archlinux.org/viewtopic.php?id=176663 sowie auch https://bugzilla.redhat.com/show_bug.cgi?id=1056820
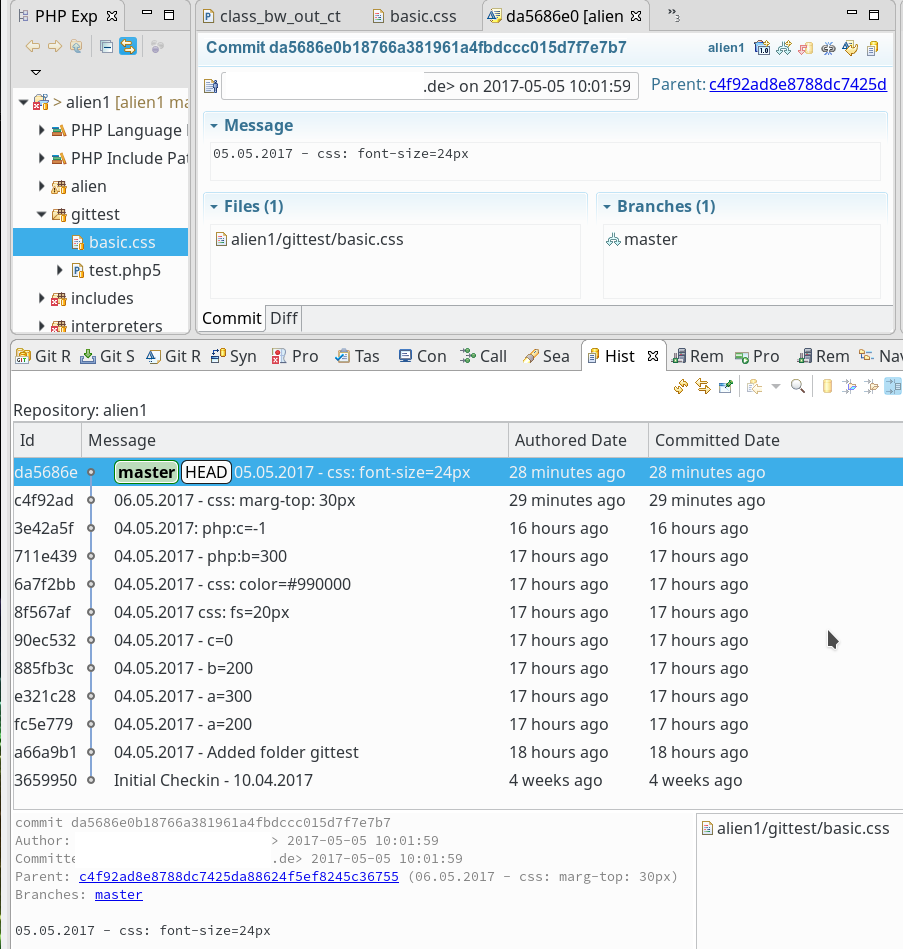
Unter Giggle muss man dann das “Projekt” alien1 unter dem entsprechenden Pfad zum Repository öffnen. Ich gehe auf die Bedienung von Giggle oder QGit nicht näher ein. Die meisten Git-Anwendungen sind nach ein wenig Beschäftigung mit Git weitgehend selbsterklärend. Das Ergebnis ist jedenfalls:
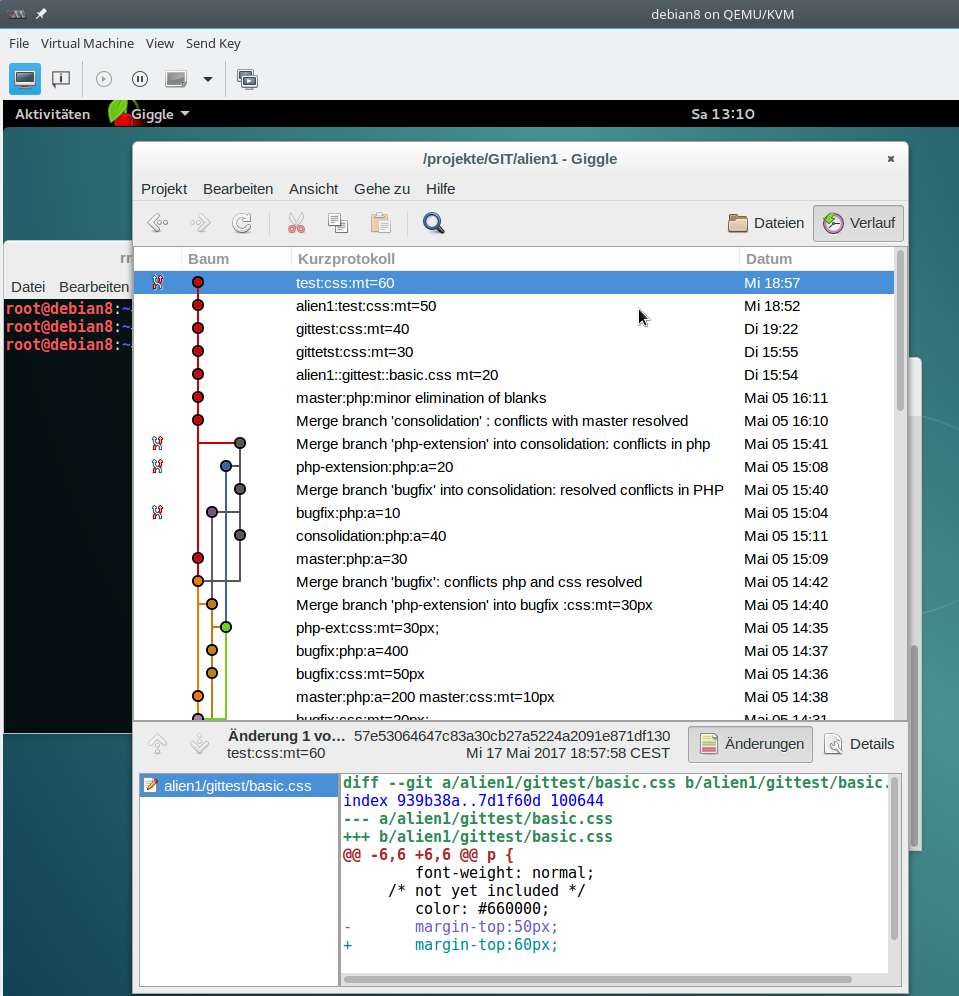
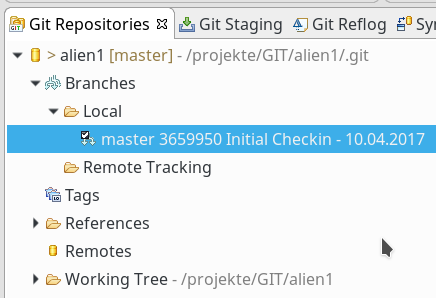
Gut! Wir können die Branches des geklonten Repositories offenbar auch auf dem Server mit graphischen Tools einsehen.
Hinweis:
Für diesen Artikel habe ich faktisch einen unter KVM angelegten Linux-Server auf einem Laptop benutzt. Im LAN kann man bzgl. graphischer Tools auf Servern noch performant genug mit “ssh -X” arbeiten. Wer hingegen mit einer graphischen Oberfläche auf echten Remote-Servern im Internet arbeiten muss, findet ggf. mit X2GO ein passendes Toolset; s. z.B.:
Remote Desktop für Debian 8 mit X2Go auf Strato-vServern.
Dem Leser werden Teile der Branch-Grafik bekannt vorkommen; einen ähnlichen Graphen hatte ich bereits gegen Ende des letzten Artikels abgebildet. Dort war der Zugriff aber auf das Repository des PCs erfolgt.
Hinweis: Wer Speicherplatz sparen will, kann nach diesem positiven Check das Zwischenverzeichnis “alien1trans” und seinen Inhalt löschen (“rm -r alien1trans”).
Das Repository auf dem Server ist relativ nutzlos, wenn wir es nicht in Verbindung mit lokalen Repositories auf unseren PCs oder Laptops bringen. Wie also können wir von Eclipse/EGit aus auf das eben auf dem Server eingerichtete Repository zugreifen und wie füllen wir es mit Commits, die wir lokal durchgeführt haben?
Es gibt unter Eclipse/EGit mehrere Wege, einen Branch eines Remote-Git-Repositorys an einen korrespondierenden Branch eines lokalen Repositorys anzubinden. Ich wähle hier den Weg über den Punkt “Remotes” im hierarchisch organisierten Eclipse-View “Git Repositories” für die Darstellung lokaler Repositorys:
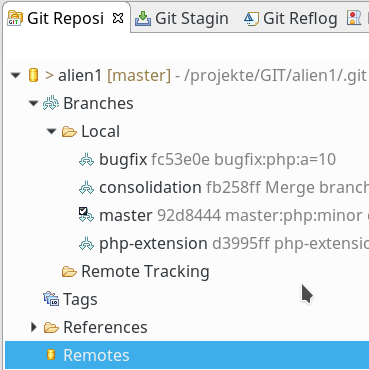
Im Kontextmenü zu “Remotes” findet sich ein Punkt “Create Remote”, den wir anklicken:
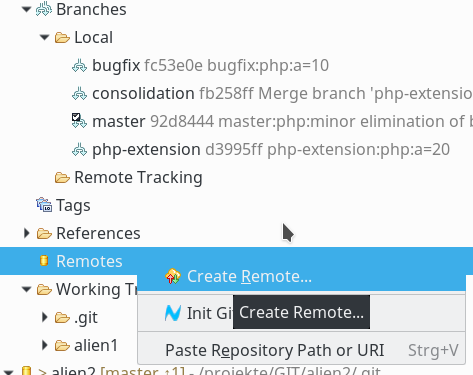
Im nächsten Popup-Dialog müssen wir der neuen “Remote-Git-Anbindung” einen Namen geben:
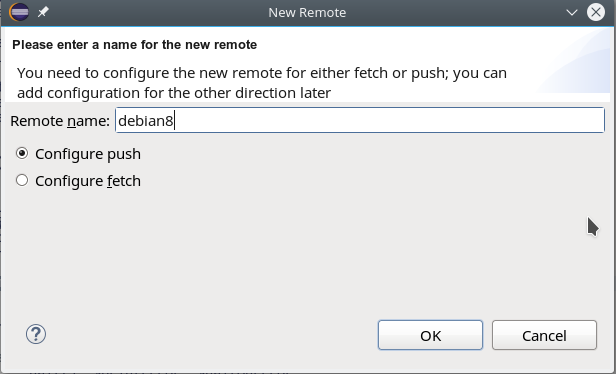
Die vorgewählte Radiobox für die Push-Konfiguration lassen wir in ihrem Zustand. Ich komme auf die Alternative in einem späteren Artikel zurück. Das Drücken des OK-Buttons führt zu einem weiteren Dialogfenster:
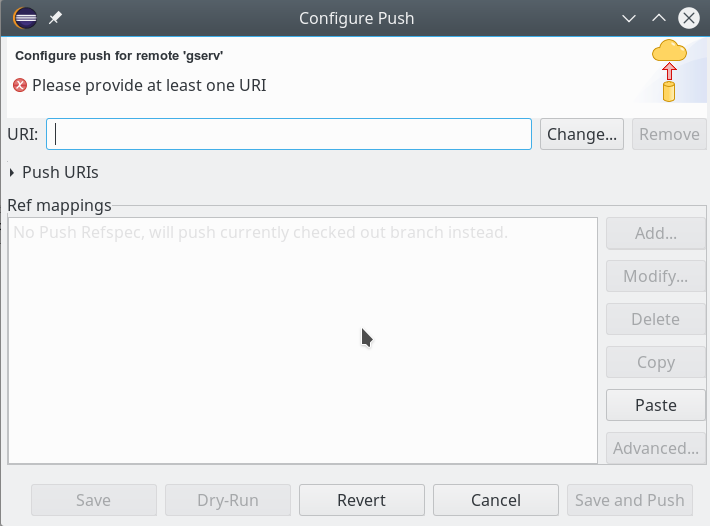
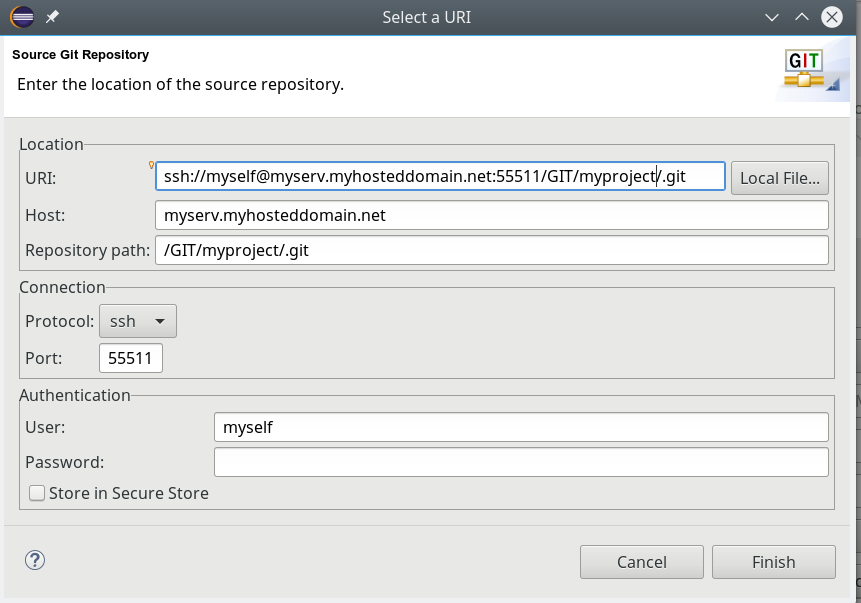
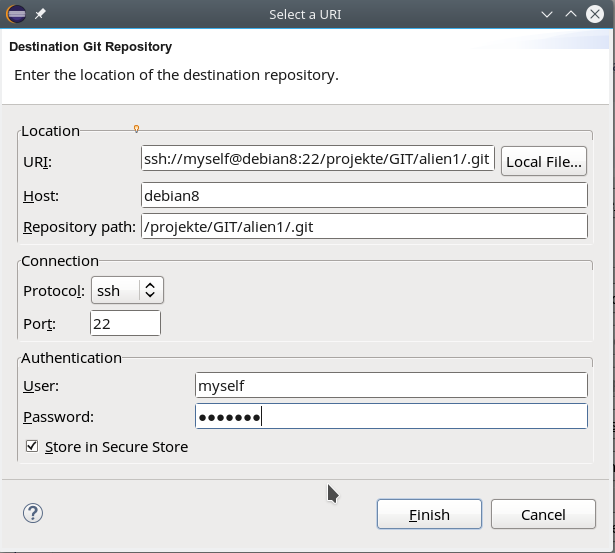
Dort wählen wir den Button “Change”, um die Verbindung zum Git-Server zu konfigurieren; es öffnet sich ein weiteres Dialogfenster (s.u.) mit mehreren Eingabefeldern, die wir wie folgt behandeln:
- In das Feld “URI” geben wir zunächst nur den Pfad zum Repository auf dem Server an – also in unserem Beispiel:
“/projekte/Git/alien1/.git”.
- In das Feld “Host” geben wir in unserem Fall natürlich “debian8” ein. In der Combobox “Protocol” wählen wir “ssh”; ggf. müssen wir auch noch einen Nicht-Standard-Port angeben, falls SSH auf dem Server unter einem speziellen Port angeboten wird.
- Im Feld “User” geben wir unsere UID auf dem Server ein – hier “myself”. Dann ergänzen wir noch das Password; das Feld “Store in Secure Store” lasse ich immer aktiv. Hier sammelt und verschlüsselt Eclipse die ihm anvertrauten Passwörter in einem Container, der wiederum ein Zugangspasswort erfordert.
Der Dialog baut den UR-Identifier im Zuge dieser Schritte vollständig auf:
Drücken auf den “Finish”-Button führt zum nächsten Dialog, der uns erlaubt, die sog. “Push-Reference”-Konfiguration vorzunehmen:
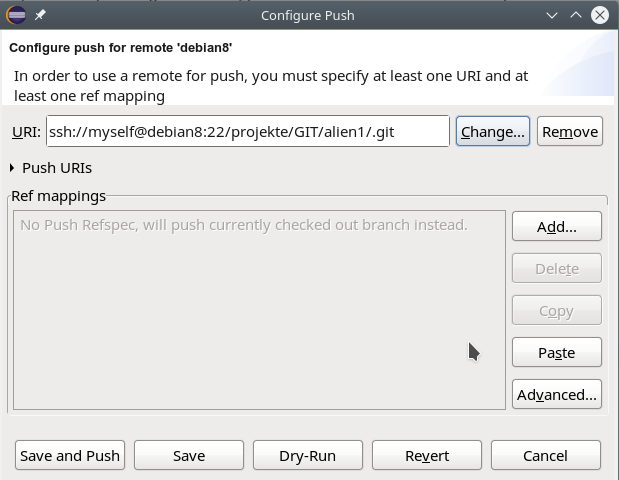
Worum geht es da? Für den Moment reicht es zu wissen, dass wir eine Beziehung zwischen einem lokalen Branch und einem Branch eines Remote-Repositories herstellen, so dass wir später neue, per Commit erstellte Knoten des lokalen Branches gezielt in den ausgewählten Remote-Branch überführen können.
Hinweis:
Faktisch kann man aber die nachfolgende einfache Konfiguration für genau einen Branch und einen Remote-Server auf verschiedene abzugleichende Branches und verschiedene Server im Rahmen ein und derselben Remote-Konfiguration ausdehnen. Dies ist insbesondere dann nützlich, wenn man lokale Repsitory-Änderungen gleichzeitig auf verschiedene Remote-Server übertragen will. Ich komme darauf in einem weiteren Blog-Beitrag zurück.
Wir drücken nun auf den Button “Add”. Folgende Schritte sind im nächsten Dialog zu leisten, um eine Referenz des Remote Master-Branches zum lokalen herzustellen; zunächst wählen wir den lokalen Branch; es genügt ein “m” in die betreffende Zeile einzugeben. Das Fenster bietet uns dann automatisch den (momentan einzigen) passenden Branch zur Auswahl an. Dann wählen wir den Remote-Branch:
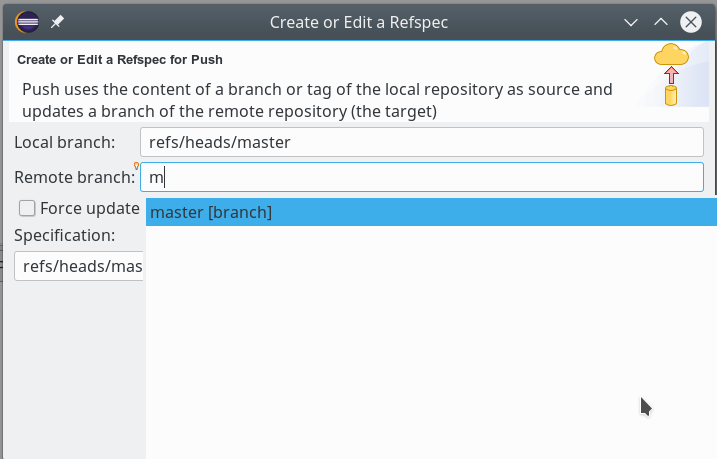
Bei letzterem Schritt muss die SSH-Verbindung bereits funktionieren! Auch hier sollte eine Vorgabe von “m” zur Auswahl des richtigen (Remote-) Master-Branches führen.
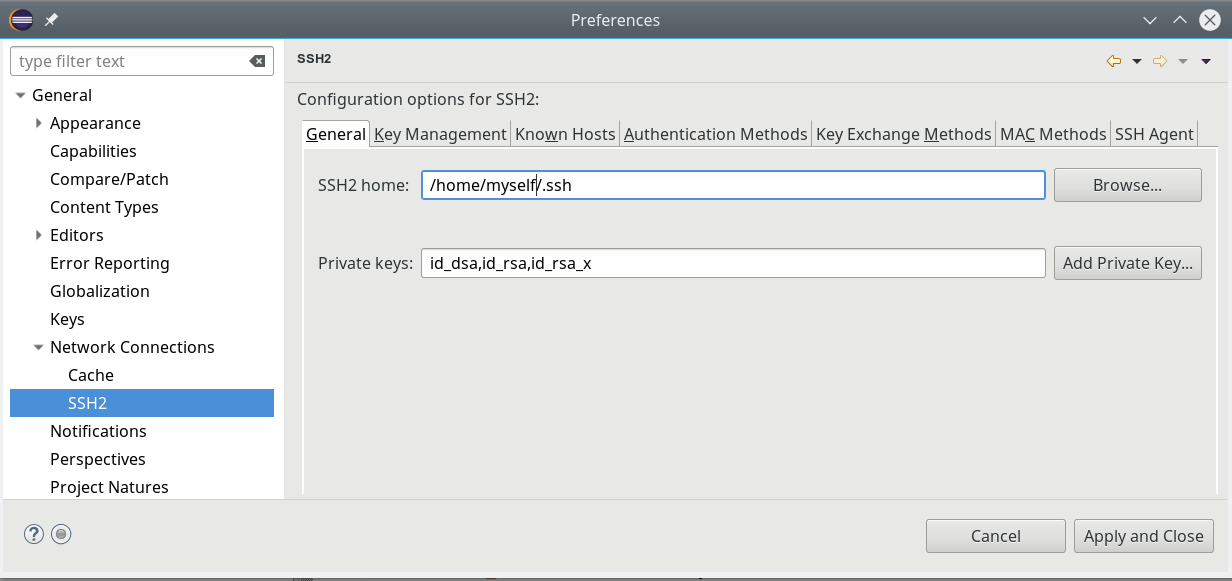
Übrigens: Bei Einsatz von asymmetrischen Schlüsseln zur SSH-Authentifizierung müssen diese vorab im Eclipse-Dialog SSH2-Dialog unter “Preferences => General => Network Connections => SSH2” definiert worden sein.
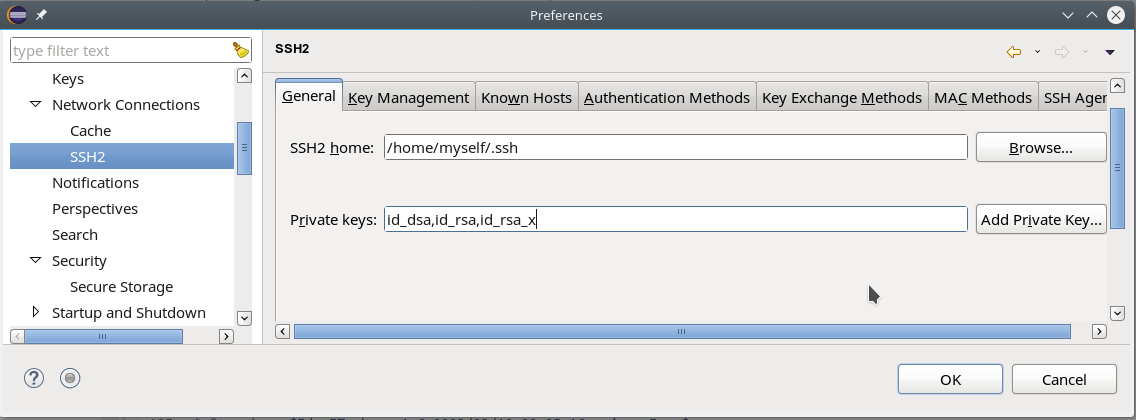
Man wird dann ggf. zur Eingabe der Passphrase für den lokalen Schlüssel aufgefordert.
Im unserem Push-Referenz-Dialog ergibt sich nun folgendes Bild:
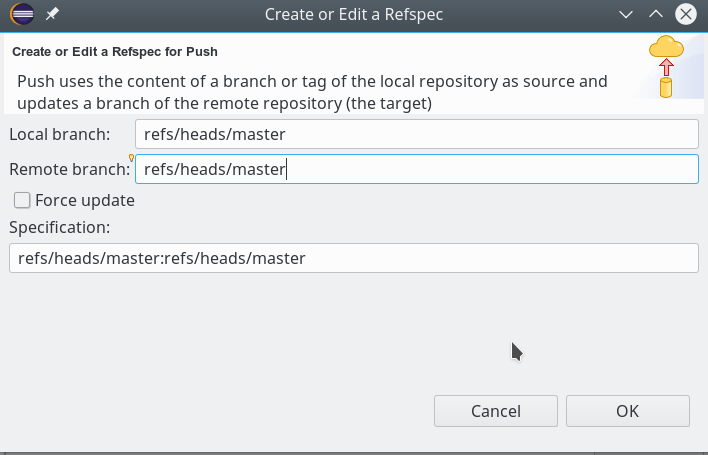
Und schließlich:
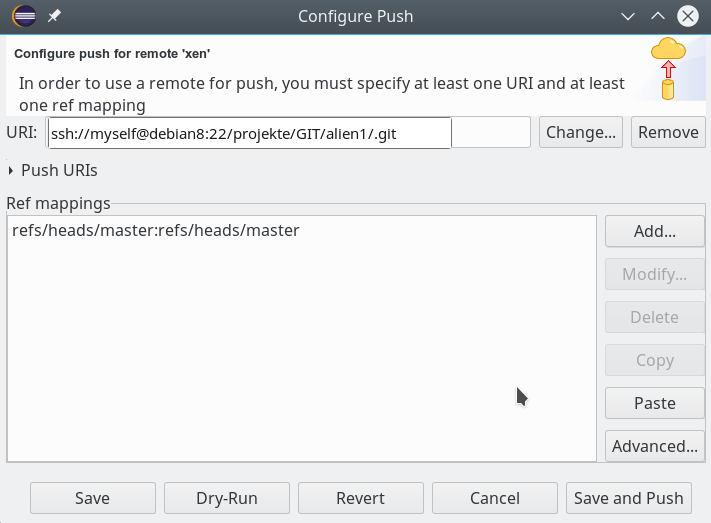
Ganz analog kann man nun weitere “Remotes” für andere Server anlegen – soweit das denn sinnvoll ist. Man erhält schließlich eine Kollektion verschiedener Remote-Verbindungen zu Git-Servern:
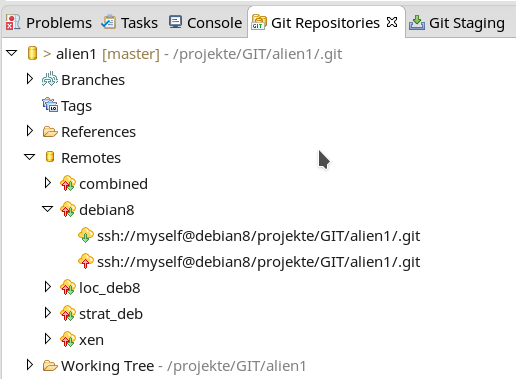
Jede dieser Remote-Anbindungen enthält eine separate “Push”-Konfiguration, die man nach Bedarf unabhängig von anderen Remote-Verbindungen für notwendige Abgleichvorgänge bedienen
kann. Aber Achtung:
In unserem Beispiel haben wir bisher nur eine funktionierende Push-Verbindung aufgebaut. Bereits die obige Abbildung verdeutlicht aber, dass es offenbar auch so etwas wie Fetch-Operationen gibt. Den Sinn und Zweck von “Fetches” behandle ich in einem kommenden Artikel.
Den Transfer lokaler Repository-Änderungen auf das Remote-Repository bezeichnet man als Push-Operation. Je nachdem, wer wann welche Änderungen auf dem Server eingespielt hat, setzt dies ggf. vorhergehende komplexe Merge-Operationen mit lokalen Branches voraus. In unserem Szenario, in dem wir alleine den Master-Branch auf dem LAN-Server beliefern, ist das aber, zumindest im Moment, noch völlig unerheblich. Die Änderungen erfolgen gemäß unserer Szenario-Beschreibung im ersten Beitrag ja sequentiell.
Also probieren wir einfach mal aus, was ein Push im momentanen ReositoryZustand bewirkt. Hierzu führen wir einen Klick mit dem rechten Mousebutton auf einer unserer angelegten Remote-Verbindungen aus; es öffnet sich ein Kontext-Menü, das u.a. die Push-Operation anbietet:
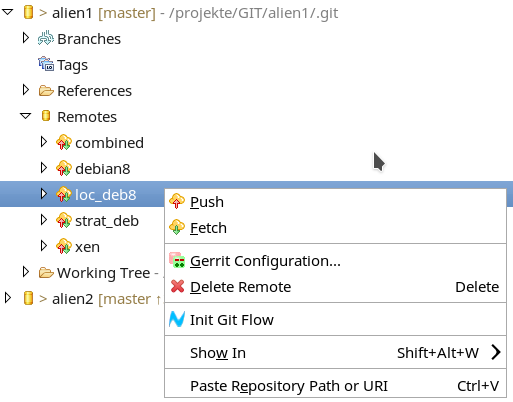
Ich habe die Push-Operation im abgebildeten Beispiel in Richtung auf einen Server durchgeführt, der sich in einem ähnlichen Zustand wie unser “debian8” aus der oben erläuterten Remote-Konfiguration befindet. Das führt dann zu folgender System-Reaktion und -Information:
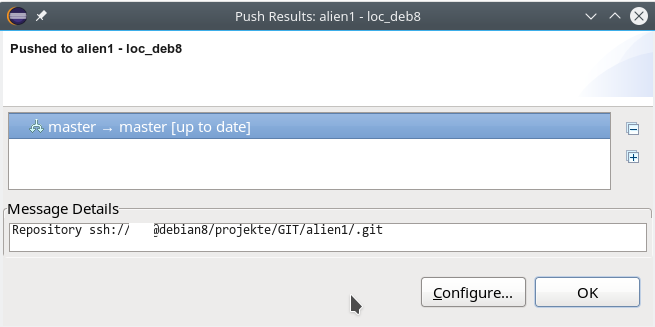
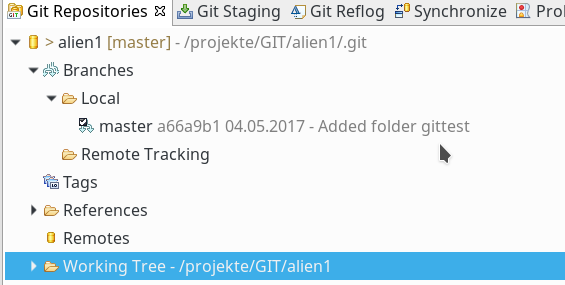
Dieses Ergebnis war zu erwarten; das geklonte Repository befindet sich ja immer noch im selben Zustand wie das aktuelle auf dem PC unter Eclipse. Wir müssen lokal natürlich zuerst eine Änderung comitten; erst die lässt sich dann sinnvollerweise zum Server weiterreichen. Um die Änderung und ihren Hash lokal wie remote verfolgen zu können, lassen wir uns im Git-Repository-View unsere Branches anzeigen und öffnen dann per rechtem Mausklick das Kontextmenü des “Master”-Branches. Dort klicken wir auf den Menüpunkt “Show In => History”. Der graphische History-View sieht in meinem Beispiel wie folgt aus:

Übrigens: Die Abbildung zeigt für den obersten Knoten auch, dass die HEAD-Version des Branches bislang mit denen definierter Remote-Server-Branches “loc_deb8/master” und “strat_deb/master” übereinstimmt!
Nun führen wir – wie im letzten Artikel erläutert – eine Änderung auf einer Testdatei aus und committen die über den Commit-Button des Git-Staging-Dialogs:
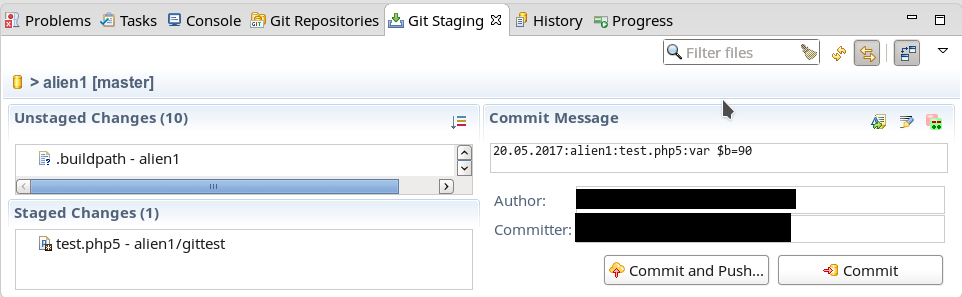
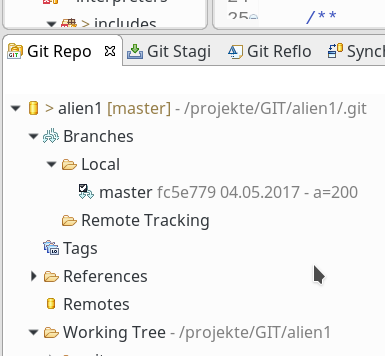
Wir erhalten dann nach einem Refresh des History-Views:
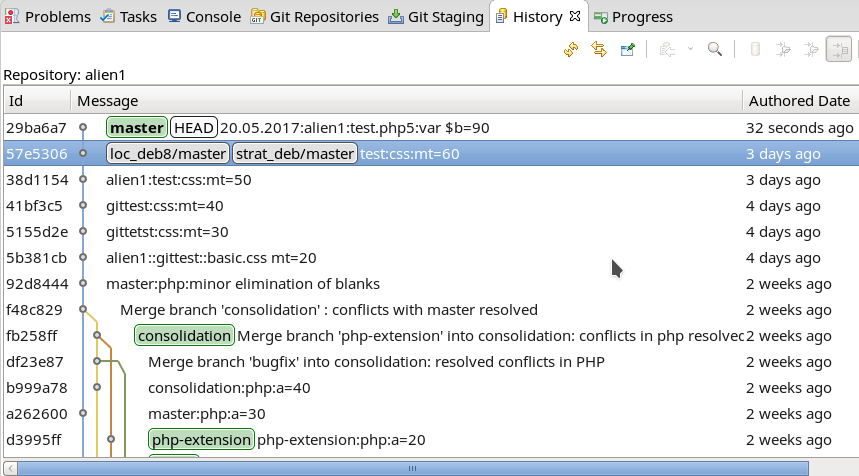
Hier erkannt man, dass sich die lokale Version nun von den letzten bekannten Versionen auf den Servern “loc_deb8/master” und “strat_deb/master”
abweicht. (Wie das lokale Eclipse auf unserem PC erfährt, ob sich inzwischen möglicherweise durch andere Nutzer etwas auf den Server-Repositories geändert hat, behandle ich in einem anderen Artikel.) Man merke sich nun den Hash des letzten Knotens.
Nun führen wir nochmals die oben versuchte Push-Operation aus; ich nutze hier eine definierte Verbindung zu einem realen Server, die ich unter der Bezeichnung “loc_deb8” konserviert habe:

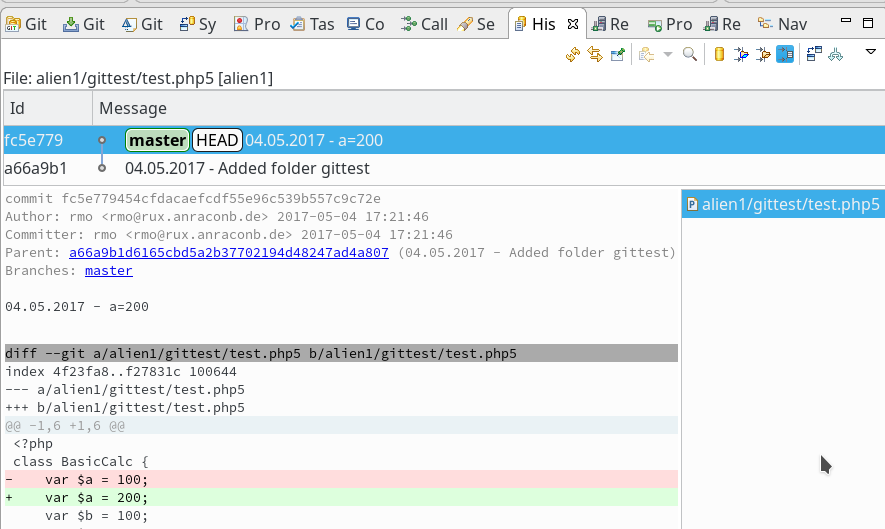
Wir klicken auf OK. Dann wechseln wir zur graphischen Oberfläche unseres Servers und refreshen das dort geöffnete Giggle (oder QGit, ..). Und tatsächlich:
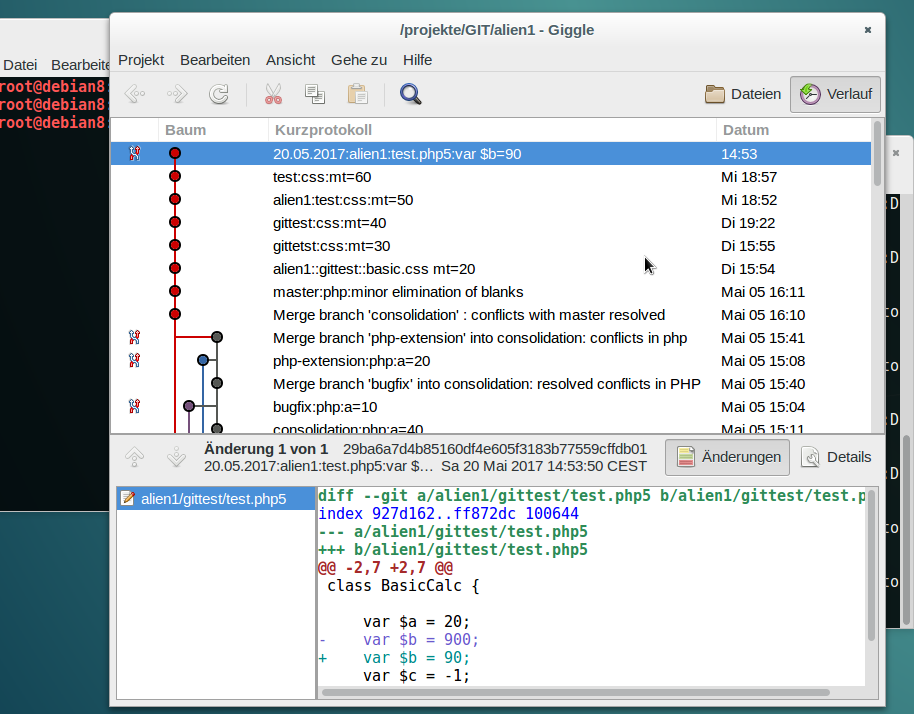
Unsere lokale Änderung ist wohlbehalten im Remote Repository unseres Servers angekommen. Die Hashes der Knoten sind identisch.
Damit man lokale Änderungen so einfach wie oben beschrieben pushen kann, müssen diese von Git als echte Nachfolger des letzten Knotens im Remote-Branch identifiziert werden können. Es ergeben sich dann um sog. Fast-Forward-Merges, die mit keinen direkten formalen Konflikten zwischen verschiedenen Änderungen gleicher Code-Bereiche verbunden sind.
Für unser einfaches sequentielles Änderungsszenario, das wir im ersten Artikel beschrieben haben, sind Fast-Forward-Merges aus offensichtlichen Gründen immer möglich.
Man stelle sich aber eine Situation mit mehreren Anwendern vor. Dann können andere Entwickler unser zentrales Repository bereits mit ähnlichen Änderungen upgedated haben – bevor wir unsere Änderung pushen. Das führt dann potentiell zu Konflikten zwischen den verschiedenen Änderungen, die GIT nicht ohne unser Zutun auflösen kann. Unsere Push-Operation kann in einem echten Entwicklungsszenario deshalb auch schief gehen – genauer: in einen manuell zu bereinigenden Konflikt münden. (In der Praxis vermeidet man häufige Kollisionen mit den Inhalten zentraler Repositories übrigens auch durch organisatorische Maßnahmen; etwa dadurch, dass man nicht verschiedene Entwickler parallel an den gleichen Dateien bzw. gleichen Codebereichen arbeiten lässt.)
Konflikte können aber auch in einem 1-Personen-Szenario auftreten, in dem man vergessen hat, seine Änderungen auf verschiedenen Entwicklungssystemen (Laptop, PC) systematisch und sequentiell über zentrale Server abzugleichen.
Um eventuelle Konflikte vorab zu erkennen und ggf. durch Merges zu bereinigen, die man lokal vor einem Push ausführt, benötigt man eine Übertragung des Zustands eines Remote-Repositorys in das lokale System. Hierzu dienen Fetch- und Pull-Operationen; sie werden u.a. Thema unseres nächsten Artikels.
Dort wollen wir uns ferner damit befassen, wie wir den Stand unseres zentralen Repositorys auf einen Entwicklungs-Laptop übertragen.