
Webalizer ist neben “awstats” ein Urgestein zur Analyse des Verlaufs von Webseitenzugriffen. Webalizer wertet Webserver-Log-Dateien aus; letztere müssen dafür eines unter mehreren normierten Formaten (z.B. das clf-Format; s. https://en.wikipedia.org/ wiki/ Common_Log_Format) aufweisen.
Ergebnis der Auswertung sind HTML-Seiten und Grafiken, die man z.B. über einen Webserver abrufen kann. Man installiert das Tool deshalb normalerweise auf einem zentralen Analyse-Webserver. Über periodische cron-Jobs
- sammelt man sich dann regelmäßig aktuelle Log-Dateien anderer, zu analysierender produktiver Webserver zusammen,
- transferiert die Logs dann zu der zentralen webalizer-Installation auf dem Analyse-Server,
- lässt dort die Analyse durchführen
- und ruft dann nach Bedarf die aufbereiteten Ergebnis-HTMLs auf.
Hört sich kompliziert an. Tatsächlich kann man sich als Anfänger schon mal im Gestrüpp der Konfigurationsoptionen und des Webserver-Setups verheddern. Die meisten Manuals und “docs” konzentrieren sich auf das obige Szenario – und verstellen so leider ein wenig den Blick auf das Wesentliche. In vielen Fällen geht es nämlich auch viel einfacher:
“webalizer” lässt sich auch auf der Kommandozeile einsetzen und ein Webserver ist überhaupt nicht nötig, wenn man mal ad hoc eine Log-Auswertung durchführen möchte oder muss.
Vor kurzem hatte ich einen solchen Fall – und fand das interessant genug, diesen kleinen Blog-Post zu schreiben.
Die Aufgabenstellung
Vor ein paar Tagen wandte sich ein Bekannter aus Norwegen, dessen Webseite plötzlich über fast 48 Stunden nicht mehr erreichbar war, an meine Frau. Als Ursache ergab sich schließlich, dass der dortige Weg-Hosting-Provider, der interessanterweise über einen sekundären Provider in den USA hosten lässt, Parameter zur Begrenzung der Bandbreite der Webserver-Zugriffe gesetzt hatte. (Off Topic: Dieses gestaffelte Hosting (man spricht auch von “Web-Hotels” – ist in Norwegen Gang und Gebe – ohne dass die Kunden erfahen würden, dass ihre Daten in die USA wandern. Aber da der Durchschnittsnorweger nach meiner Erfahrung an Datenschutz kaum interessiert ist, ist das dort auch kein Thema.)
Gedacht war die Bandbreitenbegrenzung nach erhaltener Auskunft wohl als einfache Sicherheitsmaßnahme; akut führte das Überschreiten der relativ geringen Grenzwerte aber zum Ausfall der Website über fast 2 Tage hinweg.
Nun hätte man ja vielleicht erwarten können, dass sich der norwegische Provider auch um die Ursache der offenbar gestiegenen Bandbreitenanforderungen kümmern würde. Auf Anfrage hatte unser Bekannte aber nur die lapidare Auskunft erhalten, es handele sich wohl um einen “normalen Anstieg des Datenverkehrs auf der Webseite”. So etwas macht mich immer misstrauisch. Es ist zwar nicht unser Job, die Webseite zu überwachen, aber wir haben uns dann im Auftrag des Bekannten mal die Apache Log-Dateien vom Provider zuschicken lassen.
Ich war gerade unterwegs und hatte nur meinen Laptop dabei, als die Log-Dateien eines ganzen Jahres per Mail eintrafen. Für eine erste Analyse genügten dann tatsächlich ein
- Internetzugang (inkl. DNS-Server-Zugang),
- “webalizer” auf der Kommandozeile
- und ein Browser.
Einen Internetzugang erhielt ich über das Hotel, in dem ich abgestiegen war. Die bescheidenen Voraussetzungen sind natürlich nützlich, wenn man mal aus der Ferne Ursachenforschung betreiben soll und keinen Zugang zum betroffenen Webserver hat.
Webalizer auf der Kommandozeile
Man hat also
einen Haufen von Log-Dateien vorliegen und will die auswerten. Wie geht man vor?
- Schritt 1: Zunächst muss man sich webalizer natürlich aus einem Paket-Repository seiner Linux-Distribution installieren. Dabei treten nach meiner Erfahrung keine Besonderheiten auf.
- Schritt 2: Um die Arbeit etwas zu organisieren, sollte man sich ein “Log-Verzeichnis” zur Aufbewahrung der Log-Dateien bzw. ein “Zielverzeichnis” für die von webalizer erzeugten Output-Dateien anlegen. Bezeichnen wir die Pfade für unseren Fall mal mit “Path_To_Logs/logs_nw” bzw. “Path_To_Results/webalizer_nw”. Für systematische Arbeiten sollten die Verzeichnisse natürlich sprechende Namen bekommen.
- Schritt 3: Es schadet nie, einen kurzen filternden Blick in die man-Seiten eines neuen Kommandos zu werfen. Wir lassen uns durch die Vielfalt der dortigen Optionen zu webalizer aber nicht verwirren. Die Kommandostruktur ist einfach:
“webalizer [Optionen] Pfad_zu_einer_Log-Datei”.Nun zu den Optionen:
- “-v” für “verbose” ist für das Experimentiern mit Linux-Kommandos immer gut.
- Ferner erschient es logisch, dass wir die Ergebnisse irgendwie bezeichnen müssen; wir entdecken hierzu die Optionen “-n” und “-t” .
- Dann ist klar, dass wir mehrere Dateien hintereinander auswerten müssen, ohne die Ergebnisse vorheriger Arbeit verlieren zu wollen. Wir finden hierzu die Option “-p” für “Incremental”.
- Das Output-Verzeichnis muss bekannt gegeben werden; hierzu dient die Option “-o”.
Für alles andere verlassen wir uns im Moment mal optimistisch auf Standardwerte.
- Schritt 4: Wir bemühen schließlich die Kommandozeile – in meinem Fall mit:
ich@mytux:~>webalizer -v -p -n norway-domain -t nw-since-2016 -o Path_To_Results/webalizer_nw Path_To_Logs/logs_nw/LOG_FILE
“LOG_FILE” ist oft von der Form “Domain-Bezeichnung_Monat-Jahr.gz” – z.B.: anracom.com-Jan-2016.gz”. Ja, gezippte Dateien sind zulässig; webalizer kümmert sich intern selbst um den Aufruf von “gunzip”.
Das war’s auch schon. Nun kann man auf der Kommandozeile seine vielen Log-Files händisch aufrufen. Oder aber ein kleines Script schreiben, das den Aufruf der verschiedenen Logdateien und die nötige Variation des Zeitanteils im Dateinamen für einen erledigt.
Während der Auswertung (mit der Option “-v”) erhält man auf der Standardausgabe (im Terminalfenster) typischerweise viele Meldungen zur Reverse-DNS-Analyse.
Ergebnisdarstellungen
Sieht man in das Zielverzeichnis und auf die dort erzeugten Dateien, so bietet sich einem ausschnittsweise etwa folgendes Bild

Es gibt also viel Grafik-Dateien, weitere Hilfsdateien und eine “index.html“-Datei. Letztere können wir aber im Browser unserer Wahl (meist über einen Menüpunkt “Datei öffnen”) direkt aufrufen.
Die Ergebnisse der Auswertungen werden uns danach in Form einfacher Tabellen und Grafiken im Browserfenster präsentiert. In meinem Fall ergab sich etwa folgende Einstiegsseite:
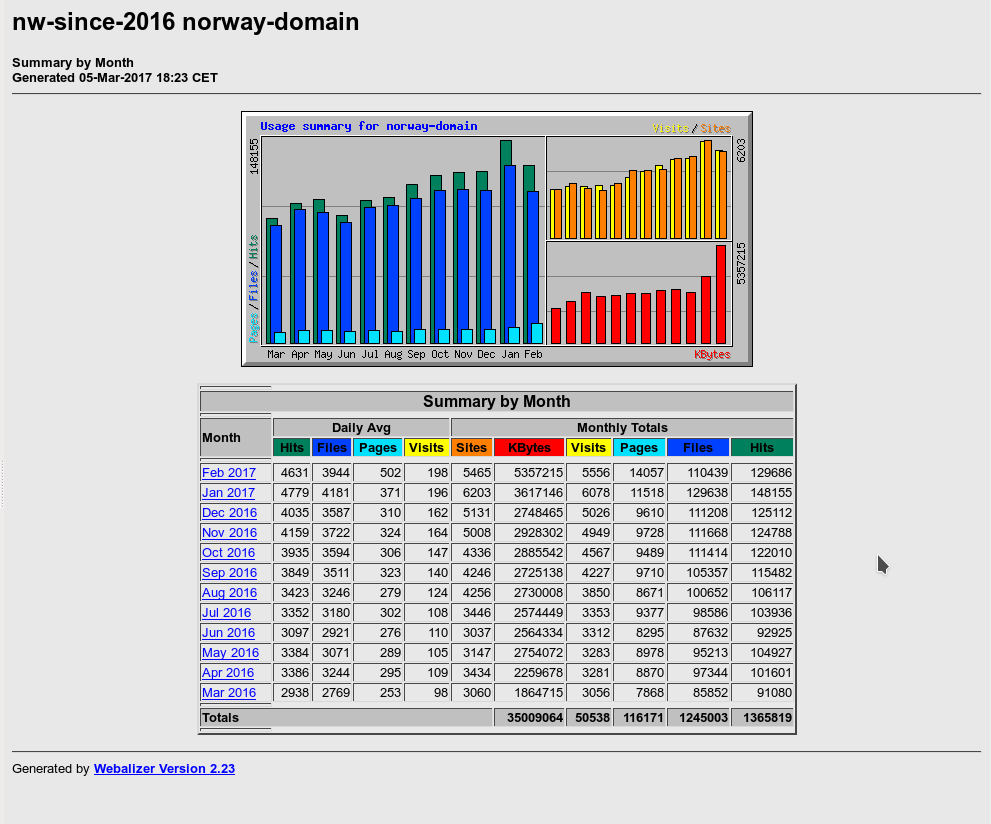
nExtrem auffällig ist hier sofort der ungewöhnlich hohe Wert an transferierten Daten – insbesondere im Februar 2017. Schauen wir uns das mal genau an, indem wir auf den Link für Februar klicken; ich zeige nachfolgend nur Ausschnitte aus der detaillierten Seite für selbigen Monat:
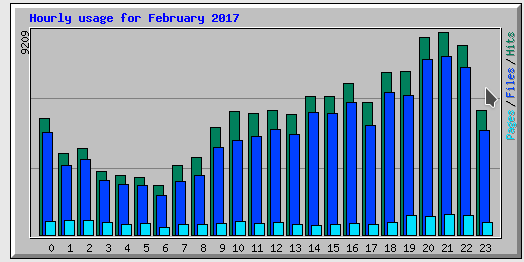
Diese Grafik spricht schon mal dafür, dass die Hauptzugriffe nicht aus einer mitteleuropäischen Zeitzone erfolgen. Faktisch zeigen weitere Graphen, die ich hier nicht abbilde, dass viele Besucher in den USA lokalisiert waren.
Es lohnt sich, danach eine Blick auf die vielen anderen Grafiken zu werfen, die einem webalizer zu anderen Zusammenhängen bzgöl. erfasster Zugriffsdaten anbietet. Als ich mir etwa die Zuordnung der Datentransfermenge zu Ursprungsadressen ansah, ergab sich Folgendes:

Aha, da erkennen wir, dass die großen Dateitransfers von einigen wenigen Hosts erzeugt werden. Eine genauere nachfolgende Analyse führt dann etwa über die Ermittlung der zugehörigen IP-Adressen (z.B. mit ping oder gezielten DNS-Abfragen) und ein systematisches Durchsuchen von Blacklists im Internet.
So erhalten wir für den Hauptbösewicht “ec2-52-3-105-23.compute-1.amazonaws.com” (IP: 52.3.127.144), der sich auf er Website des Bekannten schon in früheren Monaten hervorgetan hatte, einen Eintrag bei https://www.abuseipdb.com/ und http://ipaddress.com/blacklist-check/:
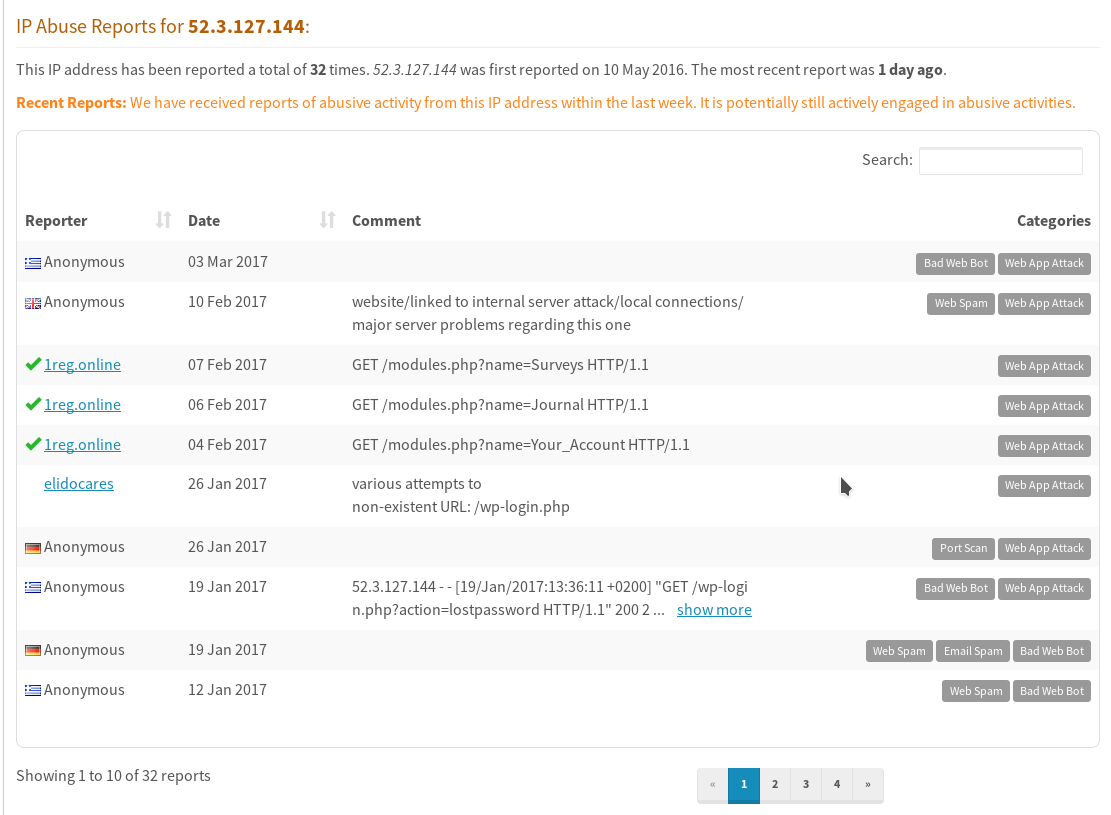
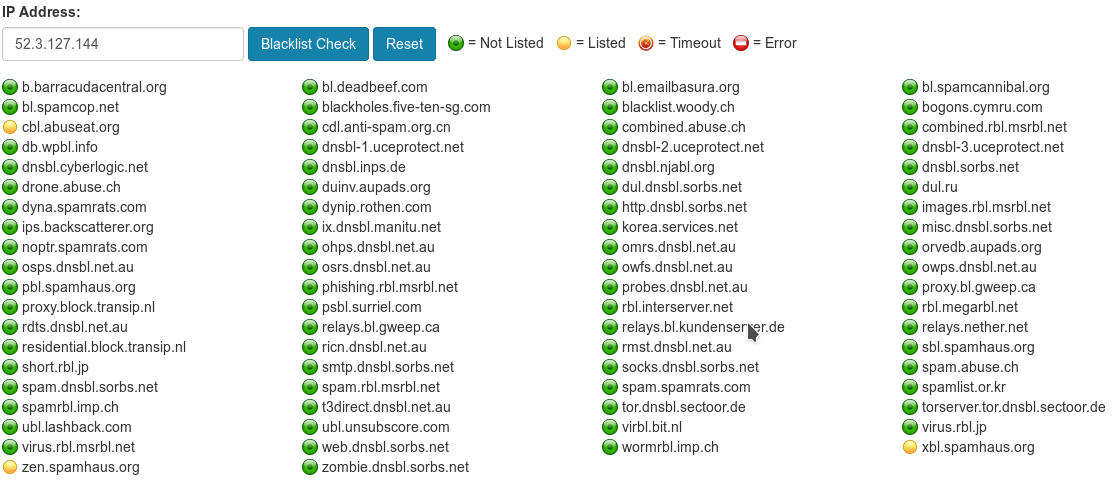
Und auch hier ist der ungebetene Gast des norwegischen Bekannten zu finden: https://myip.ms/view/blacklist/872644496/52.3.127.144 und http://whatismyipaddress.com/blacklist-check
Fazit: This guy is up to no good!
Generell gilt, dass bei anonymen Bot-/Crawler-Systemen, die unter Amazon AWS gehostet sind und die Daten von Webseiten komplett herunterladen, Vorsicht geboten ist.
Unser Plagegeist gehört ferner zu einem Bot-Netz namens “ltx71”:
https://udger.com/resources/ua-list/bot-detail?bot=ltx71
https://myip.ms/view/web_bots/1239532/Known_Web_Bots_ltx71_http_ltx71_com.html
Was Gutes ist über “ltx71” im Internet nicht in Erfahrung zu bringen. Die “Homepage” beinhaltet nur 2 Sätze: Ja, wir crawlen das Netz, aber für Sicherheitszwecke. Echt? Menschheitsfreunde? Auch ansonsten findet man auffallend wenig:
http://review.easycounter.com/ltx71-scam-report
http://www.diamantnetz.de/ wzn/a_infos/ botdestages.php
http://scamanalyze.com/check/ltx71.com.html
http://www.scamaider.com/is-ltx71.com-safe-legal.html
Der größte Traffic zu ltx71 kommt ferner angeblich von russischen
Systemen. (Sagen Analyseseiten zu Domainen). Was immer das bedeutet … Zudem umgehen ltx71-Crawler blockierende Anweisungen in einer evtl. angelegten “robots.txt”-Datei einer Zieldomäne. Alles nicht gut!
Bzgl. der Analyse verfährt man dann genauso mit den anderen, von webalizer ausgewiesenen dubiosen Datengreifern. In unserem Fall stellte sich heraus, dass ein weiterer Besucher auch zu ltx71 gehört.
Für mich gilt in einer solchen, nicht völlig klaren Situation die Leitlinie: Es gibt keine Freunde im Internet.
Schon gar nicht, wenn deren Systeme meine teuer bezahlten Ressourcen für dubiose Zwecke verbrauchen würden.
Gegenmaßnahmen?
Wir konnten unserem norwegischen Bekannten jedenfalls Bericht erstatten und erste Hinweise geben. Kümmern muss sich nun sein Provider.
Nur der Vollständigkeit halber: Sperren könnte man die dubiosen Crawler-Bots zunächst mal über Einträge in einer “.htaccess”-Datei im Hauptverzeichnis auf dem Webserver nach dem Muster
order allow,deny
deny from 52.3.127.144
deny from 52.23.169.223
deny from 52.207.224.143
deny from 54.225.29.79
deny from 52.3.105.23
deny from 54.172.241.121
deny from 104.197.241.64
allow from all
Das wird auf Dauer bei einem Botnetz aber nicht viel helfen; es werden im nächsten Monat mit Sicherheit andere IP-Adressen auftauchen. Dann muss man zu anderen Mitteln greifen, die aber nicht Gegenstand dieses Posts sein sollen.
Jedenfalls kann man Betreibern von Websites, deren Ressourcen in ungewöhnlicher Weise mit Beschlag belegt werden, nur raten, sich die Logs der betroffenen Websites regelmäßig und genau anzusehen. Dabei kann der sehr einfache durchzuführende Einsatz von webalizer bereits erste wertvolle Erkenntnisse zeitigen.
Links
http://www.webalizer.org/
http://www.techrepublic.com/ article/ analyzing-web-sites-with-webalizer/
https://lf.net/support/ techinfo/webserver/ webalizer.php
http://www.linux-community.de/ Internal/Artikel/ Print-Artikel/LinuxUser/2011/04/Zugriffsdaten-auswerten-mit-Webalizer
https://privatstrand.dirkschmidtke.de/ 2011/05/10/ webalizer-auf-logfiles-loslassen/