
Einige meiner Leser wissen, dass ich mich für PHP-basierte Simulationsrechnungen mit dem Thema des Uploads von CSV-Daten-Files für viele Tabellen befassen muss. Nun haben wir eine Situation, in der eine Tabelle zwar viele Spalten enthalten kann, aber für bestimmte Simulationen nicht alle Spalten zwingend mit Werten gefüllt werden müssen. Um die Upload-Zeiten gering zu halten, werden diese Spalten in den CSV-Dateien gar nicht übermittelt. Das durchzuführende LOAD DATA INFILE Statement wird entsprechend angepasst und versorgt die Spalten, für die das File keine Daten liefert, mit Default-Werten.
Nun erfordert jede unserer Simulationsrechnungen eine vorherige Prüfung von Konsistenzbedingungen. Dabei ist es u.a. wichtig, welche Spalten ausschließlich mit Default-Werten gefüllt wurden und welche nicht. Die Meinung eines beteiligten Entwicklers war, dass man diese Information – wenn nötig – unmittelbar aus dem tatsächlich gegebenen Tabellenzustand ermitteln sollte, um immer eine verlässliche Entscheidungsgrundlage zu haben.
Als Voraussetzung nehmen wir an, dass wir aus Platzgründen keine Indices für die einzelnen oder gekoppelten Daten-Spalten der zu untersuchenden Tabelle angelegt haben.
Abfrage über mehrere SQL-Statements für jede Spalte
Der erste naive Anlauf war dementsprechend, in mehreren SQL-Abfragen Spalte für Spalte auf die Anzahl der gesetzten Default-Werte zu prüfen und mit der Gesamtzahl der Tabellen-Records zu vergleichen. Das einzelne Select würde dann etwa so aussehen:
SQL-Typ1:
SELECT COUNT(*) FROM myTable WHERE colx=defaultValue;
Das Ganze pro Spalte für alle zu untersuchenden Tabellen. Ein solches Vorgehen erschien mir ineffizient – insbesondere wenn eine Tabelle viele zu untersuchende Spalten aufweist und man das Ganze für viele Tabellen machen muss. Der Grund:
Jede dieser Abfragen führt einen Full Table Scan durch, denn man wird in den seltensten Fällen einen Index über jede einzelne Spalte oder alle Spalten gelegt haben.
Wir reden in unserem Fall zudem über potentiell große Tabellen mit mehreren 10-Millionen Einträgen.
Ist die Abfrage in einem einzigen SQL-Statement effizienter?
Zunächst dachte ich deshalb darüber nach, ob man die Aufgabe nicht in einem einzigen Statement durchführen kann. Ergebnis:
SQL-Typ 2:
SELECT
SUM(IF(col1 = default_val_col1, 1,0)) as num_def_col1,
SUM(IF(col2 = default_val_col2, 1, 0)) as num_def_col2,
SUM(IF(col3 = default_val_col3, 1, 0)) as num_def_col3,
…
…
SUM(IF(coln = default_val_coln, 1, 0)) as num_def_coln
FROM myTable;
Das ist zwar schön und der Ansatz ist sicher für bestimmte andere Auswertungen auch von grundsätzlichem Interesse (s. etwa: http://www.randomsnippets.com/2008/10/05/how-to-count-values-with-mysql-queries/). So kann man ähnliche Statements z.B. einsetzen, wenn man herausfinden will, wie oft vorgegebene, unterschiedliche Werte in genau einer Spalte vorkommen.
Aber ist das in unserem Fall vom Zeitbedarf her wirklich effizienter als der erste Ansatz? Die Antwort lautet: Nur geringfügig.
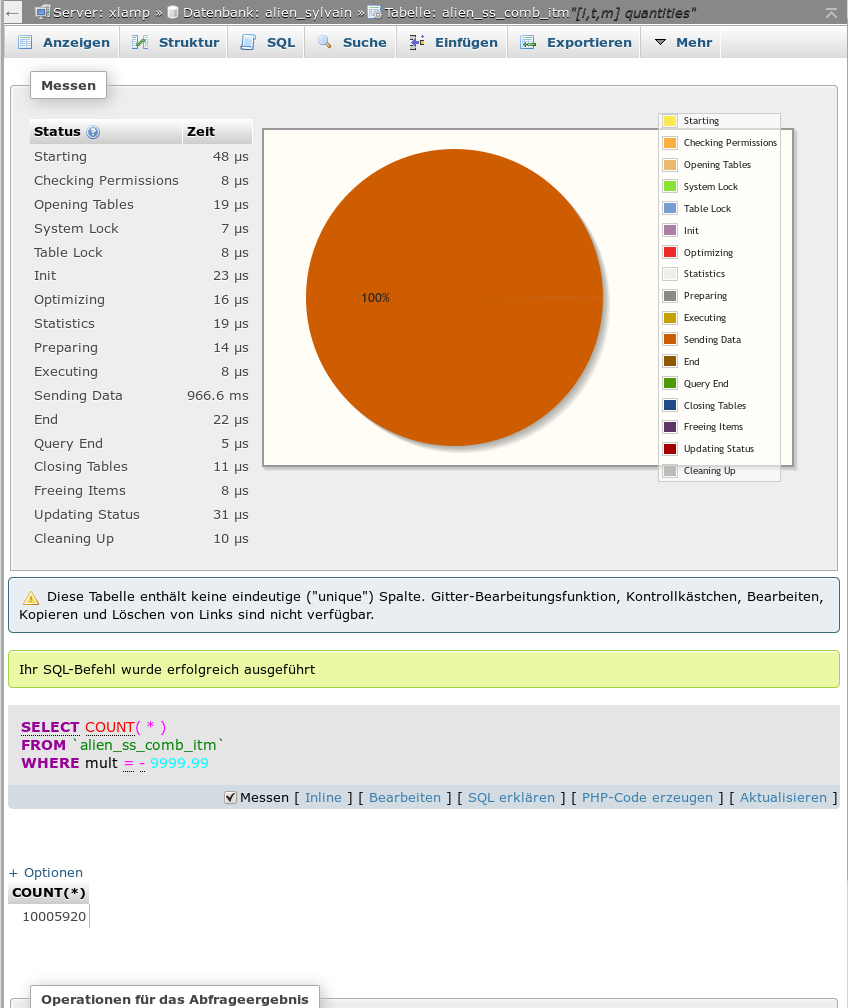
Die folgenden zwei Abbildungen zeigen typische Werte für SQL-Typ 1 und SQL-Typ2 auf einem einfachen Testserver für eine Tabelle mit ca. 10 Millionen Einträgen und 6 untersuchten Wertespalten:
Messung für Statement vom SQL-Typ1 für eine Spalte
Messung für Statement vom SQL-Typ2 für 6 (!) Spalten
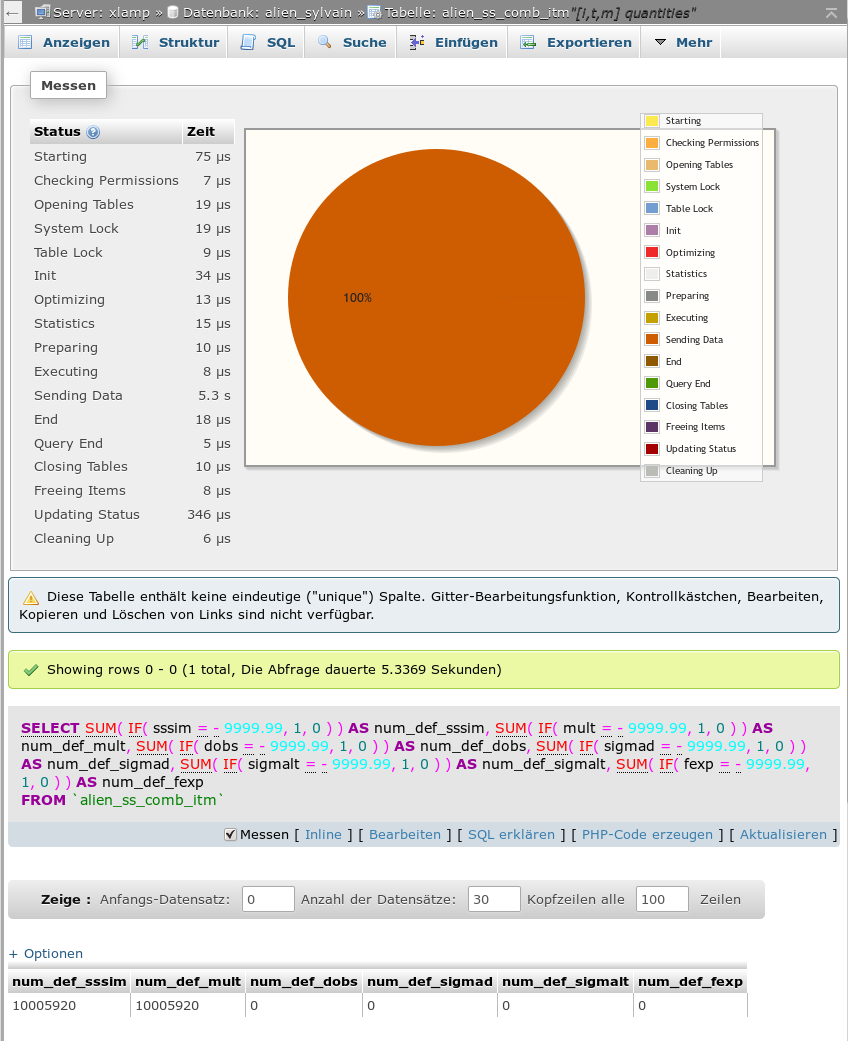
Wir kommen (nach Multiplikation mit der Anzahl der Spalten) auf etwa 6 sec für Typ1 und 5.3 sec Gesamtlaufzeit für Typ2. Der Unterschied ist also nicht weltbewegend. (Hinweis: Ein zusätzlich durchzuführendes Count(*) kostet praktisch keine Zeit; wir haben das hier deshalb weggelassen.)
Warum erhalten wir solch ein Ergebnis?
Nun die Anzahl der zu treffenden Entscheidungen ist praktisch identisch und gezählt wird in beiden Fällen. Demgegenüber tritt das mehrfache Durchlaufen der Tabelle bei Typ 1 zum systematischen Bereitstellen der Daten einer Zeile in den Hintergrund. Im besonderen, wenn die Tabelle schon im Cache vorliegen sollte.
Noch ineffizienter wird ein Ansatz, bei dem mit COUNT(Distinct) gearbeitet würde und bei den Spalten die nur einen Wert aufweisen, diesen Wert zusätzlich ermittelt würde :
Allein das Statement für unsere Testtabelle
SELECT COUNT( DISTINCT sssim ) AS dist_sssim, COUNT( DISTINCT mult ) AS dist_mult, COUNT( DISTINCT dobs ) AS dist_dobs, COUNT( DISTINCT sigmad ) AS dist_sigmad, COUNT( DISTINCT sigmalt ) AS dist_sigmalt, COUNT( DISTINCT fexp ) AS dist_fexp
FROM `alien_ss_comb_itm`
dauert hier 7.6 sec. Dies liegt daran, dass hier temporäre Datenstrukturen bzw. Tabellen erzeugt werden.
Die langsamste Abfrage-Alternative
Es gibt natürlich eine weitere Alternative zum Typ 1 – Statement:
SQL-Typ3:
SELECT colx as dist_colx, COUNT(colx) as num FROM myTable GROUP BY colx;
Die Anzahl der Treffer, der Ausgabewert “num” und der ggf. gefundene alleinige Wert können auch hier dafür verwendet werden, um festzustellen, ob die Spalte nur mit Default-Werten gefüllt ist.
Für dieses Statement dauert in unserer Testtabelle die Abfrage über eine einzige Spalte allerdings bereits 2.5 sec:
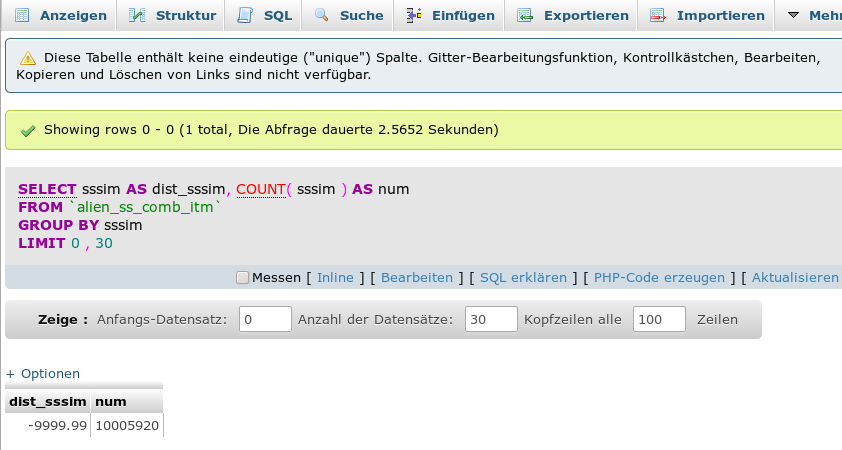
Auch hier ist das Anlegen von temporären Datenstrukturen und der erforderliche Einsatz von Filesort in der MySQL-DB die Ursache der schlechten Performance.
Zu kostspielig? Alternativen?
Offenbar ist so eine Prüfung für große Tabellen relativ kostspielig. Mehrere Sekunden, um festzustellen, welche Spalten mit regulären Daten gefüllt wurden? Geht gar nicht …
Zugegeben: Das hängt immer davon ab, in welchen Zusammenhang – also Art von Upload- oder Serverlauf – man eine solche Prüfung einbettet. Dauert ein Simulationslauf für große Tabellen 15 Minuten, so sind 5 sec egal. Auch bei Uploadzeiten von 50 sec kann man 10% Zuwachs verschmerzen. Auch zugegeben: Man ist von keiner weiteren Information außer dem aktuellen Tabellenzustand selbst abhängig.
Würde das Anlegen eines Index pro Spalte helfen?
Natürlich würde das SQL-Statements vom Typ 1 extrem beschleunigen! Aber kann man sich Indices pro Spalte denn bei großen Tabellen überhaupt leisten? Wohl eher nicht: Indices kosten u.U. und je nach Kardinalität enorm viel Platz und ihr Anlegen erhöht den Bedarf an CPU-Zeit im Rahmen eines Dateiimports beträchtlich. Wenn man also Indices über einzelne Daten-Spalten nicht noch für andere Zwecke benötigt, sollte man deshalb eher die Finger davon lassen.
Beschleunigung von erforderlichen Abfragen auf den Füllgrad von Spalten mit
Defaultwerten über eine Hilfstabelle
Muss man die vorgesehene Prüfung überhaupt über SQL-Abfragen auf den Spalten der zu untersuchenden Tabelle machen?
In unserem Fall, in dem es nur darum geht, ob in einer Spalte aussschließlich Default-Werte vorliegen, natürlich nicht! Der einzig sinnvolle Weg führt mal wieder über eine Hilfstabelle, die bereits auf Grund einer Analyse des Aufbaus der importierten CSV-Datei erstellt wird.
Im Fall der Verwendung von “LOAD DATA INFILE” genügt dabei ein Check der ggf. vorhandenen Header-Zeile mit Spaltenbezeichnungen und der ersten Datenzeile; ein solcher Check ist sowieso obligatorisch, um das “LOAD DATA INFILE” Statement um explizite Angaben zum Füllen der Spalten zu ergänzen, für die die CSV-Datei keine Daten liefert. Ein so ergänztes “LOAD DATA INFILE”-Statement ist viel schneller als das Füllen mit Defaultwerte der Bank selbst zu überlassen. Einen Check der Korrektheit der Struktur der übergebenen Daten benötigt man im übrigen sowieso.
Lösung: Auf Basis der CSV-Datei-Analyse füllt man nach einem erfolgreichen Laden der CSV-Daten in die Ziel-Tabelle zusätzlich eine kleine Hilfstabelle, in der für jede Tabelle und Spalte Werte eingetragen werden, die besagen, wie oft der Default-Wert vorliegt und ob er ausschließlich vorliegt.
Alle nachfolgenden Prüfungen greifen dann auf den Inhalt dieser Hilfstabelle zu. Das ist selbst bei einem zusätzlichen Vergleich von Zeitstempeln zwischen Hilfs-Tabelle und Original-Tabelle um Größenordnungen schneller als ein Statement vom Typ 2 – nicht nur bei großen Tabellen.
Sollte die Hilfstabelle aus irgendeinem Grunde mal nicht gefüllt sein, oder die Zeitstempel nicht passen, kann man ja in dem Programm, das die Belegung von Spalten mit Defaultwerten prüfen will, immer noch auf das Statement vom Typ 2 als Fallback zurückgreifen. Aber das ist maximal nur genau einmal erforderlich!
Genau so haben wir es dann in unserem Projekt auch gemacht!
Es liegt im übrigen auf der Hand, wie man mit ein wenig Parametrierung eine allgemeinere PHP-Funktion erstellt, die ermittelt, wie oft spaltenspezifische, vorgegebene Werte in einer importierten Datentabelle auftauchen. So ist die (dynamische) Erzeugung von SQL-Statements vom Typ 2 für Tabellenspalten ohne Index also für bestimmte Auswertungen ggf. doch von Nutzen.