Im letzten Beitrag hatte ich eine row-basierte Master/Slave-Replikation zwischen zwei MariaDB-Servern konfiguriert und mit kontinuierlichen INSERTs getestet. Ein Ergebnis war, dass es bei einer Dauerlast auf dem Master und einer hochfrequenten Synchronisation der Log-Files auf dem Slave-System mit Festplatten durchaus zu einem systematischen Anwachsen der “Catch Up”-Zeit zwischen Master- und Slave-System kommen kann. Als Ursache erschien plausibel, dass der Slave mehr mit Updates der Logfiles und deren Synchronisation [SYNC] in Richtung Storage-System beschäftigt ist als mit der Durchführung der SQL-Änderungen in der Datenbank selbst.
Ein Heilmittel bestand darin, die Sychronisation der Log-Files im Bedarfsfall nicht, wie üblicherweise empfohlen, nach jeder Änderung sondern erst nach mehreren Änderungen vornehmen zu lassen. Das RDBMS kann dann wieder Commits in hinreichender Anzahl ausführen und der Änderungsfrequenz auf dem Master-RDBMS nahtlos folgen.
Im vorliegenden Beitrag überprüfen wir diesen Befund nun mittels eines etwas komplexeren Szenarios – nämlich einer parallel stattfindenden “Master/Slave – Master/Slave”-Replikation zwischen zwei Servern für zwei unterschiedliche Datenbanken (Schemata).
Die Skizze aus dem letzten Beitrag zeigt die Konfiguration schematisch:
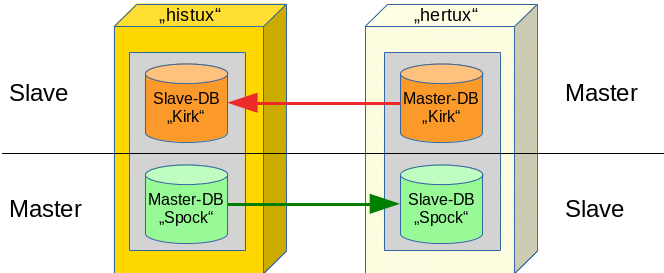
Wir haben zwei RDBMS-Serversysteme “histux” und “hertux“. “hertux” fungiert als Master bzgl. der Datenbank “Kirk”, “histux” dagegen als Master bzgl. der Datenbank “Spock”. Repliziert wird zum jeweils anderen Server.
Die für die Replikation relevanten Einträge in der Konfigurationsdatei “/etc/my.cnf” auf dem Server “hertux” sehen dann etwa wie folgt aus:
Server “hertux”:
[mysqld]
# Enforce GTID consistency
#gtid-mode=ON
#enforce_gtid_consistency=1
# Binary Log
log_bin=/var/lib/mysql/mysql-bin
binlog_format=row
binlog_do_db='Kirk'
# Slave with respect to "Spock"
relay_log=/var/lib/mysql/relay-bin
skip_slave_start
log_slave_updates=1
slave-parallel-threads=10
replicate_do_db='Spock'
# SYNC statements
sync_binlog=1
sync_master_info=2
sync_relay_log=2
sync_relay_log_info=2
# Server ID
server-id = 2
# These are commonly set, remove the # and set as required.
# port = 3306
...
...
Die meisten Einträge kennen wir bereits aus dem letzten Artikel. Die Statements, die sich auf die Slave-Rolle beziehen, wurden dort für das System “histux” erläutert. Sie sind nun in gleicher Weise auf dem System “hertux” für die Datenbank “Spock” zur Anwendung zu bringen.
Neu ist dagegen das Statement
binlog_do_db=’Kirk’
Dieses Statement schränkt die Aufzeichnung der zu replizierenden Master-Änderungen(SQL-Statements oder Row-Änderungen) im Binary Log File auf die Datenbank “Kirk” ein! Das ist im vorliegenden Fall harmlos. Anders sähe die Situation dagegen im Fall einer statement-basierten Replikation aus: Die Einschränkung bezieht sich nämlich immer nur auf die aktive Bank! Das hat Auswirkungen bei bank-übergreifenden SQL-Statements! Im Fall statement-basierter Replikaton sollte man deshalb die Warnungen unter “https://dev.mysql.com/doc/refman/5.7/en/replication-options-binary-log.html” beachten:
Zitat bzgl. der Variable “binlog-do-db=db_name”:
…. Statement-based logging: Only those statements are written to the binary log where the default database (that is, the one selected by USE) is db_name. To specify more than one database, use this option multiple times, once for each database; however, doing so does not cause cross-database statements such as UPDATE some_db.some_table SET foo=’bar’ to be logged while a different database (or no database) is selected. …” (Hervorhebung durch mich).
Für die im aktuellen Szenario verwendete “row-basierte” Replikation ist die Situation jedoch einfacher.
Zitat:
“… Row-based logging: Logging is restricted to database db_name. Only changes to tables belonging to db_name are logged; the default database has no effect on this. Suppose that the server is started with –binlog-do-db=sales and row-based logging is in effect, and then the following statements are executed:
USE prices;
UPDATE sales.february SET amount=amount+100;
The changes to the february table in the sales database are logged in accordance with the UPDATE statement; this occurs whether or not the USE statement was issued. However, when using the row-based logging format and –binlog-do-db=sales, changes made by the following UPDATE are not logged:
USE prices;
UPDATE prices.march SET amount=amount-25;
Even if the USE prices statement were changed to USE sales, the UPDATE statement’s effects would still not be written to the binary log. ….”
Das entspricht aus meiner Sicht doch recht gut der Erwartungshaltung eines Anwenders.
Bzgl. seiner zweiten Rolle als Slave-Systems schränkt das Statement
replicate_do_db=’Spock’
die Replikation auf die Bank “Spock” ein; “replicate_do_db” ist das slave-bezogene Gegenstück zum Statement “binlog_do_db” für die Master-Rolle.
Im Falle einer Replikation mehrerer Datenbanken ist zudem folgender Punkt zu beachten:
“To specify multiple databases you must use multiple instances of this option. Because database names can contain commas, the list will be treated as the name of a single database if you supply a comma-separated list.“
Für den Server “histux” nehmen wir eine gespiegelte Konfiguration vor:
Server “histux”
[mysqld]
# Enforce GTID consistency
#gtid_mode=ON
#enforce_gtid_consistency=1
# Binary Log File
log_bin=/var/lib/mysql/mysql-bin
binlog_format=row
binlog_do_db='Spock'
# Slave with respect to database "Kirk"
relay_log=/var/lib/mysql/relay-bin
skip_slave_start
log_slave_updates=1
slave-parallel-threads=10
replicate_do_db='Kirk'
# SYNC statements
sync_binlog=1
sync_master_info=2
sync_relay_log=2
sync_relay_log_info=2
#Server ID
server-id = 3
# These are commonly set, remove the # and set as required.
port = 3386
...
...
Wir haben hier zusätzlich den MySQL-Port geändert! Natürlich müssen festgelegte Ports für die Replikation in evtl. zwischengeschalteten Firewalls geöffnet werden.
Auf beiden Servern sehen wir – wie im letzten Artikel beschrieben – einen manuellen Start der Replikation vor (skip_slave_start !). Den priviligierten Datenbank-User für die Durchführung von Replikationen hatten wir bereits im letzten Artikel auf beiden RDBMS angelegt.
Wie im letzten Artikel erzeugen wir auf beiden Servern für eine begrenzte Zeit von ca. 80 Sek. eine
Dauerlast durch permanente Durchführung von 10000 Einzel-INSERTs in Tabellen der Bank “Kirk” auf “hertux” und nun such in Tabellen der Bank “Spock” auf “histux”. Nach dem Start des Testprograms starten wir auf beiden Servern etwas zeitversetzt die jeweilige Slave-Replikation. Vor dem Replikationsstart auf “hertux” müssen wir allerdings noch (einmalig) die Daten für den Master-Server “histux” (DB Spock) am MySQL-Prompt setzen; dies geschieht in Anlehnung an das Vorgehen im letzten Artikel durch folgende Statements:
MariaDB [Spock]> CHANGE MASTER TO MASTER_HOST='histux.mynet.de', MASTER_USER='repl', MASTER_PASSWORD='MyReplPasswd', MASTER_PORT=3386;
MariaDB [Spock]> CHANGE MASTER TO master_use_gtid=slave_pos;
MariaDB [Spock]> START SLAVE;
Für SYNC-Werte
sync_binlog=1
sync_master_info=2
sync_relay_log=2
sync_relay_log_info=2
auf beiden Servern erhielt ich für meine HW-Konfiguration ein systematisch anwachsendes Nachlaufen eines der beiden RDBMS:
30 < Catch Up-Zeit < 60 Sekunden
Welcher Server hinterherhinkte und welchen genauen Wert die Catch Up-Zeit annahm, hing u.a. davon ab
- auf welchem Server die INSERTs zuerst gestartet wurden,
- und wie groß der zeitliche Versatz des Starts der Slave-Replikationen gewählt wurde.
Festzuhalten bleibt aber auch diesmal, dass ein systematisches Anwachsen der Catch Up-Zeit durchaus möglich ist, wenn die SYNC-Parameter zu klein gewählt werden. Die absoluten Werte für die Catch Up-Zeit wirken klein; angesichts der gesamten INSERT-Zeit von ca. 80 Sekunden pro Server sind sie aber signifikant groß.
Wählt man hingegen SYNC-Werte von
# SYNC-Werte
sync_binlog=1
sync_master_info=3
sync_relay_log=3
sync_relay_log_info=3
und führt wieder zeitlich etwas versetzte INSERTS auf beiden Servern aus, so ergibt sich keine nenneswerte Catch Up-Zeit:
Server “histux”:
MariaDB [(none)]> SHOW SLAVE STATUS\G
....
Master_Host: hertux.mynet.de
Master_User: repl
Master_Port: 3306
....
Replicate_Do_DB: Kirk
....
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1660492
Relay_Log_Space: 943
....
Seconds_Behind_Master: 0
....
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-2-537280
1 row in set (0.00 sec)
Server “hertux”:
MariaDB [(none)]> SHOW SLAVE STATUS\G
Master_Host: histux.mynet.de
Master_User: repl
Master_Port: 3386
...
Replicate_Do_DB: Spock
... Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 342
Relay_Log_Space: 1671507
...
Seconds_Behind_Master: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-535624
1 row in set (0.00 sec)
Beide
Server arbeiten also synchron; auf beiden RDBMS gilt:
Seconds_Behind_Master: 0
Steht der bzw. stehen die Master-Server in einer Replikation vom Typ
- “Master-Slave”>
- oder “Master/Slave – Master/Slave”
unter dauerhafter Last, sollte man ein Auge auf die SYNC-Parametrierung für die Log-Files werfen. Ggf. sollten die slave-bezogenen SYNC-Variablen auf Werte > 2 gesetzt werden, um ein systematisches Anwachsen von Catch Up-Zeiten zwischen den RDBMS-Systemen zu vermeiden.
sync_binlog=1
sync_master_info=3
sync_relay_log=3
sync_relay_log_info=3
Der zu wählende Wert ist natürlich abhängig von der HW-Konfiguration.
Wir groß ist der potentielle Schaden im Fall eines Crashes, in dem Änderungen verloren gehen, die nicht rechtzeitig auf das Plattensystem geschrieben wurden? Aus meiner Sicht nicht groß. Relevant nach einem Systemcrash ist ja der zu wählende richtige Aufsetzpunkt für die jeweilige lave-Replikation. (Bzgl. der Änderungen in einer Master-Datenbank müssen sowieso Mechanismen der jeweiligen Applikation greifen.) Werden die SYNC-Parameter klein gewählt, sind nur einige wenige letzte Transaktionen vor dem Crash zu prüfen, um den richtigen Aufsetzpunkt (bzw. die zugehörige GTID) zu bestimmen. In einer Abwägung
zwischen einem nicht ganz nahtlosen Wiederaufsetzen der Replikation nach einem Crash
undeiner systematisch anwachsenden Catch UP-Zeit während der Replikation
erscheint mir der begrenzte Aufwand für die Identifikation der richtigen GTID das kleinere Übel zu sein.
https://mariadb.com/kb/en/library/gtid/
https://www.lexiconn.com/blog/2014/04/how-to-set-up-selective-master-slave-replication-in-mysql/
https://docs.jelastic.com/mariadb-master-slave-replication
