
An so warmen Tagen wie heute, in denen sich das Thermometer im Arbeitsraum sich in die Nähe von 30° bewegt, kommt ab und zu Sorge über den Temperaturzustand und das Wohlbefinden der Desktop-Systeme auf. Manch einer, der vom Board-Hersteller seiner Wahl unter MS-Windows mit hübscher Zusatzsoftware verwöhnt wurde, mag sich dann fragen, wie er unter Linux an entsprechende Informationen gelangt. Unter einer aktuellen SuSE-Distribution ist das i.d.R. kein Problem dank umfänglicher Libraries und Module zur Unterstützung einer Vielfalt von Sensoren. Unter anderen Distributionen muss man sich ggf. ein kleines Startskript zum Laden der Module selbst schreiben.
Ksysguard, sensors-detect und sensors
Auf unseren Rechnern befinden sich in der Regel Asus-Boards. Nach dem Einrichten der jeweiligen Linux-Systeme (Opensuse) lassen wir immer auch das nette Tool “/usr/sbin/sensors-detect” laufen und nehmen zu den identifizierten Sensoren der Boards und des Prozessors die entsprechenden Konfigurationseinträge in der Datei /etc/modprobe.conf vor. Unter SuSE versehen wir zusätzlich die Datei “/etc/sysconfig/lmsensors” mit Einträgen wie von “sensors-detect” vorgeschlagen. Übrigens: Ein zusätzlicher Blick in die Datei “/etc/sensors.conf” ist in jedem Fall interessant und lehrreich.
Ein kleines Startscript startet dann unter Suse die Sensor-spezifischen Module während des Hochfahrens der Systeme. Ein ähnliches Skript kann man auch zum manuellen Start der Sensor-Module verwenden. Bei einem unserer Rechner sieht der zentrale Teil des Skripts etwa wie folgt aus:
modprobe i2c-nforce2
modprobe eeprom
modprobe it87
modprobe k8temp
# sleep 2 # optional
/usr/bin/sensors -s
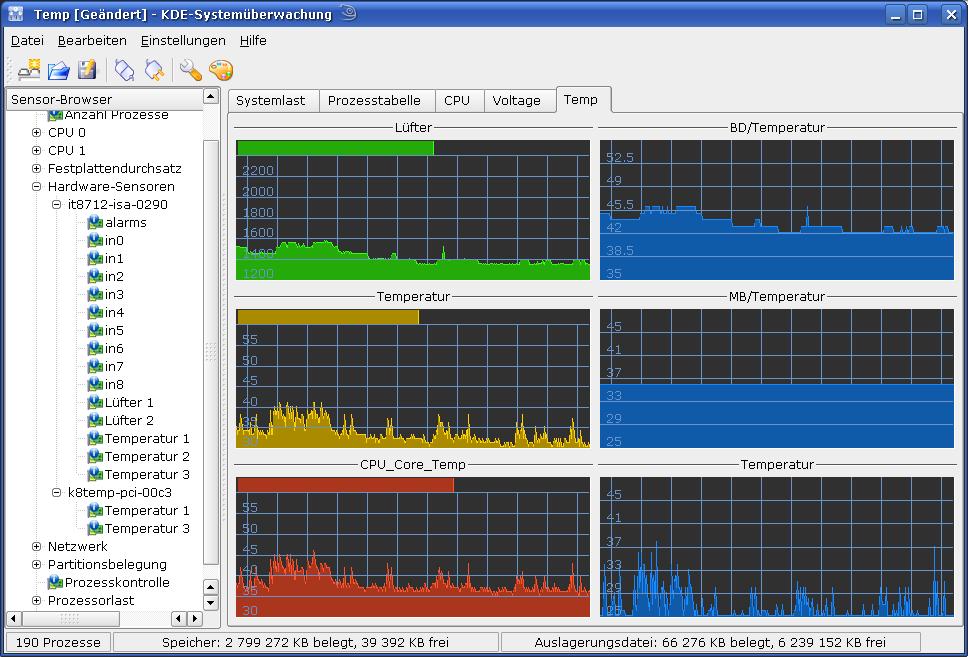
Danach bleibt eigentlich nur noch übrig, unter der KDE-Applikation “ksysguard” ein sog. “Arbeitsblatt” für die Temperatur und Lüfterdaten anzulegen und die Updatefrequenz vorzugeben. (Die verschiedenen verfügbaren Sensoren werden im linken Bereich des “ksysguard”-Fensters angezeigt.)
Unter KDE lasse ich mich dann nicht nur über die aktuellen internen Temperaturen des lokalen Rechners (s. Bild), sondern auch über den Zustand anderer Linux-Desktop-PCs informieren (per ssh -X Verbindung). Traut man den graphischen Bildern nicht oder braucht man Werte genauer, so hilft der Aufruf von “/usr/bin/sensors” im Terminal oder an der Konsole.
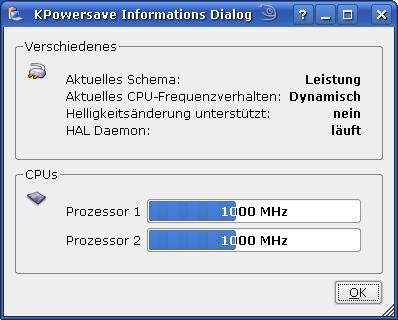
KPowersave
Hat man erst einmal vernünftige Informationen über die Temperaturen des Prozessors und des Chipsatzes am Display, so lohnt es sich, verschiedene Einflussfaktoren auf die Temperatur zu studieren. U.a. kann man ein wenig mit KPowersave herumzuspielen. Viele AMD- und Intel-Prozessoren können über entsprechende Schema-Einstellungen unter KPowersave auch dynamisch getaktet werden. Voraussetzung ist i.d.R., dass eine entsprechende Option im BIOS geschaltet ist (z.B. “AMD Cool and Quiet”). Meiner Erfahrung nach bringt das Umstellen des CPU-Frequenzschemas auf “dynamic” u.U. bis zu 8 ° Celsius Temperaturabsenkung im zeitlichen Mittel. Das ist an sehr heißen Tagen eine beträchtliche Reserve und man vermeidet unter normalen Lastanforderungen permanent hoch drehende CPU-Lüfter.
Zusätzlicher Seitenlüfter im Gehäuse bei Heatpipes auf dem Mainboard
Gerade bei Mainboards mit einer Heatpipe zur Kühlung des Chipsatzes lohnt sich evtl. auch der Einbau eines kleinen (leisen) Lüfters in die seitliche Gehäusewand, der vertikal kühle Luft von außen auf die Kühlbleche der Pipes lenkt. Dieser zusätzliche Lüfter brachte bei mir eine erhebliche Temperaturabsenkungen des Boards.