
Vor etwa 2 Jahren hatte ich in diesem Blog mehrere Artikel zur Einrichtung der Xonar D2X unter Linux – genauer unter Opensuse 13.1 (mit KDE) – verfasst. Ein Fazit war, dass Pulseaudio für diese Karte nicht vernünftig funktionierte. Zumindest dann nicht,
- wenn man Stereo-Signale auf mehrere Ausgangskanäle upmixen will
- und wenn man seine relativen Volume-Einstellungen für die verschiedenen analogen Ausgangskanäle nicht ständig bei Lautstärke-Änderungen unter dem Mixer von “pavucontrol” verlieren will.
Die Karte selbst nimmt keinen Mix auf N.1-Ausgabe-Systeme vor; das direkt unterstützte Mixing blendet den Center und Bass-Speaker aus.
Die Xonar D2X läuft bei mir inzwischen unter Leap 42.1. Dass der Pulseaudio-Layer mit pavucontrol als Mixer trotz diverser optischer Aufbesserungen inzwischen besser mit Mehrkanalkarten umgehen könne, sehe ich nicht. Ich bleibe dabei: Pulseaudio schafft mehr Probleme als es löst. Das liegt weniger an der Idee eines auf Alsa und anderen Soundsystemen aufsetzenden Zwischenlayers als an der schlechten Umsetzung dieses Layers für verschiedene Karten – im besonderen Multikanal-Karten. Problematisch ist dabei, dass für eine evtl. mögliche Reproduktion der Mixing- und PCM-Plugin-Optionen von Alsa unter Pulseaudio aus meiner Sicht erhebliche Detailkenntnisse von Pulseaudio erforderlich sind. Ganz schlimm wird es nach meiner Erfahrung dann, wenn das System mehrere Multikanal-Soundkarten enthält.
Im letzten meiner Artikel zur D2X
Asus Xonar D2X unter Linux / Opensuse 13.1 – III – Alsa Upmix 2.0 auf 5.1
hatte ich eine Muster-Datei “~/.asoundrc” für das Upmixing von Stereo-Eingangssignalen angegeben und die völlige Deaktivierung von Pulseaudio empfohlen. Über die “.asoundrc” wurde auch ein SW-Volume-Regler angelegt, um für alle Quellen und über alle Output-Kanäle der D2X hinweg die Lautstärke regeln zu können, ohne die relative Laustärke-Gewichtung der Kanäle zueinander zu verändern.
Probleme mit Firefox und mit KDE5
Leider verlassen sich offenbar immer mehr Entwickler auf ein laufendes Pulseaudio – so schlecht das auch sein mag. Das führt dann bei denjenigen, die aus guten Gründen nur mit Alsa arbeiten wollen, zu mehr oder weniger großen Problemen. Ein schlimmer Bug ist aus meiner Sicht der, dass z.B. unter KDE 5 (unter OS Leap 42.1) von bei mir über 20 verfügbaren HW und virtuellen PCM Alsa-Devices nur noch genau eines angezeigt wird, wenn Pulseaudio deaktiviert ist (s. https://bugs.kde.org/show_bug.cgi?id=362476). Dennoch sind die Devices da und aktiv – wie etwa die Device Übersichten unter Amarok oder VLC beweisen.
Richtig übel wurde es aber, als Firefox [FF] plötzlich keinen Sound mehr ohne Pulseaudio zu liefern schien.
Auch ein Leser, der meinen Vorschlägen aus dem oben genannten Artikel gefolgt ist, ist nun über dieses Problem gestolpert, dass auch mich schon seit einiger Zeit geplagt hat:
https://wiki.gentoo.org/wiki/ALSA und dort den Bereich “Troubleshooting” oder auch https://bbs.archlinux.org/viewtopic.php?id=186650.
Bei mir dagegen war das Problem mit FF anders gelagert. Vielleicht helfen die nachfolgenden Ausführungen deshalb auch dem einen oder anderen Leser weiter, der sein Firefox-Problem bislang nicht lösen konnte.
Ausgangssituation mit der Xonar D2X als primärer Soundkarte
In meinem aktuellen Arbeitsplatzsystem befinden sich mehrere Soundkarten. Ich befasse mich in diesem Artikel aber nur mit dem Fall, dass lediglich die Xonar D2X als primäre Karte genutzt wird. Unter Opensuse (in meinem Fall in der Version Leap 42.1) kann man die Grundeinrichtung etwa mit YaST vornehmen:
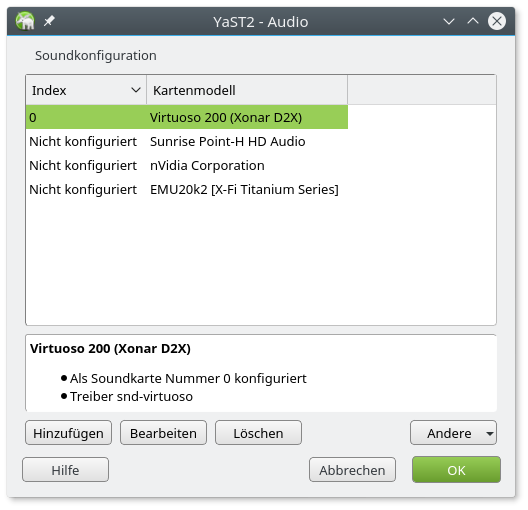
Mit Hilfe der Funktionalität von YaST’s Sound-Einrichtung deaktivieren wir zudem das Pulseaudio-System mittels entsprechender Optionen unter dem Button “Andere” >> “Pulseaudio-Konfiguration” vollständig. (Unter anderen Linux-Varianten sind zur Deaktivierung von Pulseaudio andere Schritte erforderlich). Danach sichern wir die Einstellungen und starten das System neu.
Die explizite Einrichtung der D2X mittels YaST bewahrt uns ggf. noch nicht zwingend vom Laden weiterer Kernelmodule und Treiber für andere Soundkarten durch udev. Wir müssen daher für die nachfolgenden Alsa-Einstellungen prüfen, an welcher Position die D2X unter den verschiedenen Soundkarten tatsächlich erkannt wird.
Die grundsätzlich verfügbaren Karten zeigen folgende Befehle; die D2X ist u.a. als “C-Media Electronics Inc CMI8788 [Oxygen HD Audio]” unter den PCI-Devices erkennbar.
me@mysystem:~> aplay -l | grep Karte rmo@rux:/proc/asound> aplay -l | grep Karte Karte 0: D2X [Xonar D2X], Gerät 0: Multichannel [Multichannel] Karte 0: D2X [Xonar D2X], Gerät 1: Digital [Digital] Karte 1: PCH [HDA Intel PCH], Gerät 0: ALC1150 Analog [ALC1150 Analog] Karte 1: PCH [HDA Intel PCH], Gerät 1: ALC1150 Digital [ALC1150 Digital] Karte 2: NVidia [HDA NVidia], Gerät 3: HDMI 0 [HDMI 0] Karte 2: NVidia [HDA NVidia], Gerät 7: HDMI 1 [HDMI 1] Karte 2: NVidia [HDA NVidia], Gerät 8: HDMI 2 [HDMI 2] Karte 2: NVidia [HDA NVidia], Gerät 9: HDMI 3 [HDMI 3] Karte 3: XFi [Creative X-Fi], Gerät 0: ctxfi [Front/WaveIn] Karte 3: XFi [Creative X-Fi], Gerät 1: ctxfi [Surround] Karte 3: XFi [Creative X-Fi], Gerät 2: ctxfi [Center/LFE] Karte 3: XFi [Creative X-Fi], Gerät 3: ctxfi [Side] Karte 3: XFi [Creative X-Fi], Gerät 4: ctxfi [IEC958 Non-audio]
und
root:~ # lspci -nn | grep Audio 00:1f.3 Audio device [0403]: Intel Corporation Sunrise Point-H HD Audio [8086:a170] (rev 31) 01:00.1 Audio device [0403]: NVIDIA Corporation Device [10de:0fba] (rev a1) 02:00.0 Audio device [0403]: Creative Labs EMU20k2 [X-Fi Titanium Series] [1102:000b] (rev 03) 04:04.0 Multimedia audio controller [0401]: C-Media Electronics Inc CMI8788 [Oxygen HD Audio] [13f6:8788]
Nach der Konfiguration der D2X mit YaST und einem Neustart des Systems finden wir unter Opensuse folgenden Eintrag in der Datei “/etc/modprobe.d/50-sound.conf” vor:
options snd slots=snd-virtuoso # rChK.j3r564qQSgF:Virtuoso 200 (Xonar D2X) alias snd-card-0 snd-virtuoso
Wir lassen diesen Eintrag unverändert.
Die aktuell gültige Reihenfolge der Karten ist auch wie folgt erkennbar:
me@mysystem:~> cat /proc/asound/cards
0 [D2X ]: AV200 - Xonar D2X
Asus Virtuoso 200 at 0xd000, irq 16
1 [PCH ]: HDA-Intel - HDA Intel PCH
HDA Intel PCH at 0xdf640000 irq 146
2 [NVidia ]: HDA-Intel - HDA NVidia
HDA NVidia at 0xdf080000 irq 17
3 [XFi ]: SB-XFi - Creative X-Fi
Creative X-Fi 20K2 Unknown
Die D2X wird also von ALSA definitiv als erste Soundkarte (mit der Nummer 0) verwendet – was immer udev sonst entdeckt und an Modulen nachgeladen haben mag. Wäre dies nicht der Fall, hätten wir dies in der Datei “/etc/modprobe.d/50-sound.conf” durch Festlegung von “index”-Parameter-Werten für die Module festlegen müssen (s. hierzu etwa https://bbs.archlinux.org/viewtopic.php?pid=1445611#p1445611).
Eine mit Firefox nicht funktionierende “.asoundrc”
Meine ursprüngliche “~/.asoundrc” für diesen Fall sah (etwas verkürzt) etwa so aus:
pcm.dmix51 {
type asym
playback.pcm {
type dmix
# Don't block other users
# http://www.alsa-project.org/alsa-doc/alsa-lib/pcm_plugins.html
ipc_key_add_uid true
ipc_key 5678293
ipc_perm 0660
ipc_gid audio
slave {
# 2 for stereo, 6 for surround51, 8 for surround71
channels 6
pcm {
# mplayer chooses S32_LE, but others usually S16_LE
#format S24_LE
format S16_LE
# 44100 or 48000
# 44100 for music, 48000 is compatible with most h/w
rate 44100
#rate 48000
type hw
card 0
device 0
subdevice 0
}
#period_size 512
period_size 1024
#period_size 512
# 4096 might make sound crackle
# mplayer2 chooses 8192. Half-Life 2 chooses 16384.
# If too large, use CONFIG_SND_HDA_PREALLOC_SIZE=2048
buffer_size 16384
}
}
capture.pcm "hw:0"
}
ctl.dmix51 {
type hw
card 0
}
pcm.upmix {
type plug
slave.pcm "dmix51"
#front
ttable.0.0 1
ttable.1.1 1
#side / rear -left
ttable.0.2 1.0
#side / rear - right
ttable.1.3 1.0
#center
ttable.0.4 0.5
ttable.1.4 0.5
# bass
ttable.0.5 0.2
ttable.1.5 0.2
}
pcm.!default {
type softvol
slave.pcm "upmix"
control {
name "SW master"
card 0
}
}
Diese Datei mit ihren verketteten Upmixing-Definitionen (Stereo zu 5.1) und dem initial definierten Softvol-Regler funktioniert für praktisch alles – nur nicht für Firefox!
Den Softvol-Regler hatte ich, wie gesagt, am Anfang der Plugin-Kette angelegt, um den Input für die verschiedenen Kanäle der D2X an einer zentralen Stelle steuern zu können – bei gleichzeitiger
Aufrechterhaltung der relativen Lautstärke-Verhältnisse zwischen den Kanälen. Unter KMIX sieht das dann so aus:
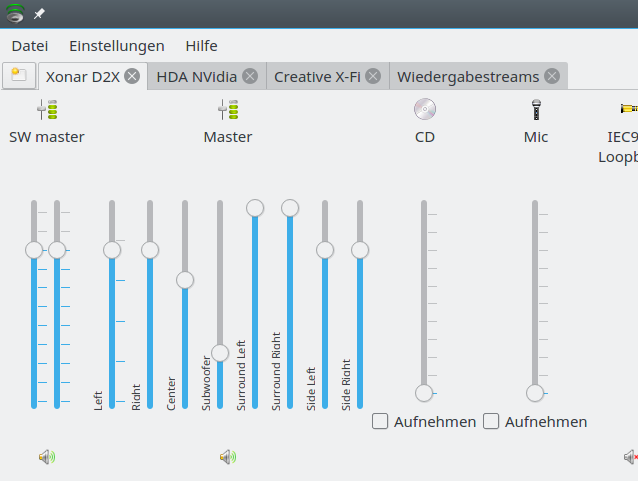
Den “SW-Master”-Regler kann man dann zum Hauptkanal für die Kmix-Einstellungen machen und damit die Lautstärke über einen (!) Regler auch im Systemabschnitt der KDE-Kontrolleiste anpassen, ohne die relativen Kanal-Lautstärken zu verändern.
Lösungsansatz für das Firefox-Problem
Nach etwas Rumprobieren kam ich schließlich auf den Gedanken, dass Firefox beim Default-Device – also am Anfang der Plugin-Kette für die Sound-Verarbeitung – möglicherweise ein PCM-Device vom Typ “plug” erwartet und mit dem “softvol”-Plugin nicht umgehen kann. Ich habe daher folgende Änderung vorgenommen:
defaults.pcm.card 0
defaults.pcm.device 0
defaults.ctl.card 0
pcm.dmix51 {
type asym
playback.pcm {
type dmix
# Don't block other users
ipc_key_add_uid true
ipc_key 5678293
ipc_perm 0660
ipc_gid audio
slave {
# 2 for stereo, 6 for surround51, 8 for surround71
channels 6
pcm {
#format S32_LE
format S16_LE
# 44100 or 48000
# 44100 for music, 48000 is compatible with most h/w
rate 44100
#rate 48000
type hw
card 0
device 0
subdevice 0
}
#period_size 512
period_size 1024
#period_size 512
buffer_size 16384
}
}
capture.pcm "hw:0"
}
ctl.dmix51 {
type hw
card 0
}
pcm.upmix {
type plug
slave.pcm "dmix51"
#front
ttable.0.0 1
ttable.1.1 1
#side / rear -left
ttable.0.2 1.0
#side / rear - right
ttable.1.3 1.0
#center
ttable.0.4 0.5
ttable.1.4 0.5
# bass
ttable.0.5 0.2
ttable.1.5 0.2
}
pcm.vol {
type softvol
slave.pcm "upmix"
control {
name "SW master"
card 0
}
}
pcm.!default {
# !!!
type plug
slave.pcm "vol"
}
(Die ersten Statements dienten nur der Sicherheit, dass in jedem Fall die erste Soundkarte genutzt wird. Mit der D2X funktioniert übrigens auch die Format-Festlegung “format S32_LE”).
Und siehe da:
Die vorgenommene kleine Änderung unter dem “pcm.!default”-Eintrag und das Verlagern des Volume-Reglers in ein eigenes Plugin “vol” brachte den Erfolg! Nach einem Ausloggen aus KDE und erneutem Einloggen produzierten Youtube-Videos unter FF plötzlich Töne – ohne dass ich irgendetwas an der vorherigen Funktionalität für die D2X verloren hätte.
Im Grunde ist durch das künstliche PCM-Device vom Typ “plug” mit dem Verweis auf das slave.pcm “vol” der SW-Volume-Regler nur als ein weiteres separates Glied der PCM-Plugin-Kette definiert worden.
Warum FF im Gegensatz zu anderen Browsern und Soundquellen so sensibel auf unterschiedliche Alsa-Plugin-Typen reagiert, ist mir unklar. Aber im Moment bin ich froh, das Problem wenigstens einer Lösung zugeführt zu haben, ohne Pulseaudio anwerfen zu müssen.
Viel Spass weiterhin mit der Xonar D2X – ohne Pulseaudio !




{kind=link}