I continue with my series on methods to access the graphical Spice console of virtual machines [VM] based on the KVM/Qemu-hypervisor combination on a Linux host.
KVM/Qemu VMs with a multi-screen Spice console – III – local access with remote-viewer via a Unix socket
KVM/Qemu VMs with a multi-screen Spice console – II – local access with remote-viewer via a network port
KVM/Qemu VMs with a multi-screen Spice console – I – Overview over local and remote access methods
In the last article we saw that “remote-viewer” can be used locally on the KVM-host to directly access the Qemu-emulator of a specific VM via a Unix socket instead of a network port. Its a simple and fairly effective method – though not well documented. We confined the right to access the socket for a VM to a specific group of users.
Actually, the socket based access method also provides the basis for a simple remote scenario in an Intranet – namely via ssh -X. This is the topic of this article.
Such a method requires relatively high data transfer rates across the network – but in a switched Gigabit LAN the rates are within reasonable limits …. And despite a lack of OpenGL HW acceleration Spice reacts very responsively to mouse operations and window movements. In the course of our experiments I will also introduce another virtual “video” device model which can be used together with our VM – namely a “virtio” device with multiple heads. As the QXL device it corresponds to a kind of virtual graphics card.
I assume that the reader is familiar with SSH and the setup of the SSH-service on a Linux system. Some knowledge about Pulseaudio is helpful, too.
Why do we care about remote Spice scenarios in an Intranet?
Why do I discuss remote scenarios for a “one seat” console of a VM in an Intranet at all? One answer is:
Any free-lance consultant or developer must think about a systematic way of how to organize data and work for customers in accordance with security requirements like the EU-GDP or the German DSGVO. Personally, I strongly recommend to confine the work and all data exchange processes for a selected customer to a specific VM on a well managed Linux server host. You then can encrypt the virtual disks and isolate the VM(s) pretty well by configuring both firewalls in the virtual network, on each VM as well as on the KVM-host and on routers in your LAN. Backup, recovery and machine extensions are easy to manage, too.
But you may need to access a VM’s desktop graphically from a client system (PC, laptop). This is were Spice comes into the game – at least in a Linux environment. Being able to work with a full fledged graphical desktop of a VM from different clients and locations in your LAN might be a basic requirement for preparing presentations, documents and maybe some development work in parallel on the VM.
I myself, for instance, often access the full desktop of server-based VMs from my Linux workstation or from a Linux laptop. Via SSH and the Spice console. We shall see below that the network data transfer rates for applications as Libreoffice Draw via SSH to the KVM host and using the Spice console can become smaller than in a situation where we open Libreoffice remotely by a direct “ssh -X” call to the VM itself. And the situation is even better in other scenarios we shall study in forthcoming articles.
In general it will be interesting to watch the objective data transfer rates plus the felt
responsiveness of Spice clients in remote scenarios throughout all our coming experiments.
Encryption requirements – the advantages of SSH
Even in the LAN/Intranet of a free-lancer or in a home-office with multiple users encryption for remote interactions with VMs may be required. We have two main options to achieve this for remote-viewer:
- We use SSH on the remote system, connect to the KVM-host and start remote-viewer there.
- We start remote-viewer on the remote system and encrypt the connection to the VM on the KVM host with TLS.
Both methods have their advantages and disadvantages. In the end usability on the remote system is an important criterion. A TLS setup will be discussed in a forthcoming post. Note that we also can use remote-viewers’ sister application “virt-viewer” in a SSH-based scenario – but this is a different story, too.
It is clear that using “ssh -X” is a simple approach which just uses the X11-protocol capabilities to realize a remote scenario. But it has some major advantages over other scenarios:
- We get encryption almost for free. Most SSH implementations on Linux systems work out of the box.
- We can enforce the use of secure Opensource encryption algorithms – both for the asymmetric KEX and authentication mechanisms and for the symmetric encryption parts of the data exchange. (See https://stribika.github.io/2015/01/04/secure-secure-shell.html)
- We get user authentication based on a public key algorithm almost for free.
- We can use a “ssh-agent” on the remote client to control the different authentication keys for different users allowed to access different VMs.
- It is sufficient to open a SSH-port on the server. We do not need to open extra network ports for the Spice protocol.
- We can get encrypted audio data transfer with some simple tricks in combination with Pulseaudio.
Therefore, it is really worthwhile to test a combination of “ssh -X” with starting remote-viewer on the KVM host. I shall, however, not discuss basics of SSH server and client configurations in this article. The preferred or enforced use of certain encryption algorithms for specific SSH connections is something a Linux user should be or become familiar with.
Regarding authentication I assume a standard configuration where private and public authentication keys are organized in the folders “~./ssh/” both for the involved user on the remote client system and the invoked user on the KVM/Qemu server host, respectively.
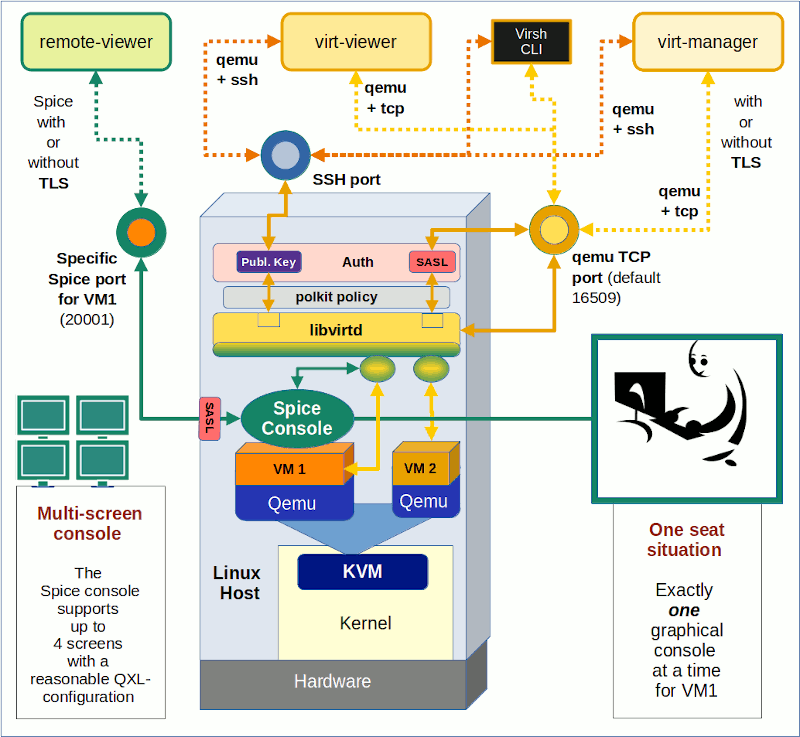
Schematic drawing
I have not yet depicted the SSH scenario with remote-viewer in any of my schematic drawings so far. The combination of remote-viewer with SSH is a variant of a local scenario as we open the “remote-viewer”-application on the KVM host [MySRV] and just transfer its graphical output via SSH to the X-Server of a remote Linux workstation [MyWS].
We do not care about the transfer of audio data during our first steps. We shall cover this problem in some minutes.
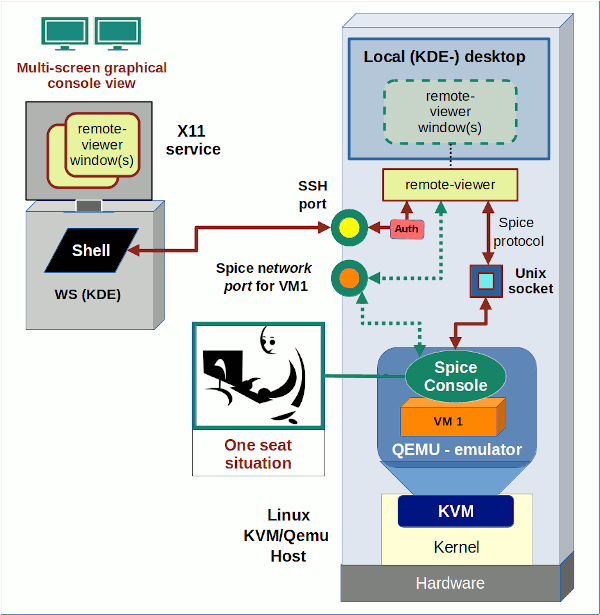
On the left side we see a Linux workstation from which a user logs into our KVM host as user “uvmb”. I assume that user “uvmb” has become a member of the special group “spicex” on the KVM host which we gave read/write access to the Spice UNIX socket created by Qemu (see my last post). On the right side we have our a KVM/Qemu server host. The user starts the remote-viewer application there (i.e. on the KVM
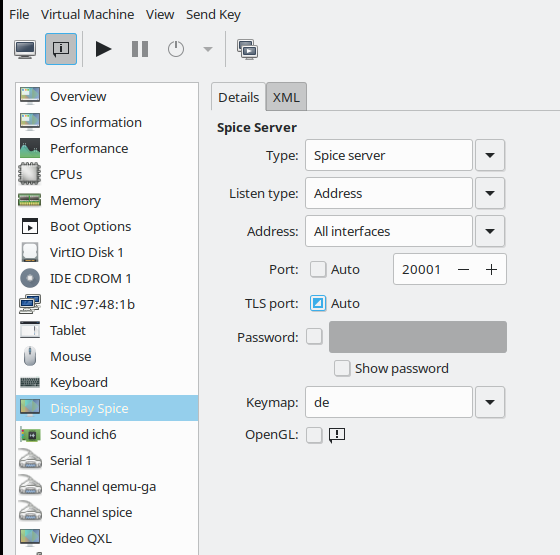
host), but gets its graphical output on his desktop on the remote workstation. On the KVM/Qemu host we, of course, use the fastest method for the remote-viewer application to exchange data with the Qemu-emulator process – namely via a Unix socket. See the definitions for the VM’s XML file (for libvirt applications) discussed in the last post:
<graphics type='spice' autoport='no' keymap='de' defaultMode='insecure'>
<listen type='socket' socket='/var/spicex/spice.socket'/>
<image compression='off'/>
<gl enable='no'/>
</graphics>
This scenario may appear a bit strange for those among my readers who know that remote-viewer is a network client application: Remote-viewer is normally used on a remote client systems to connect to the Qemu process for a VM on a server host via TCP over a LAN. In our present scenario, however, we start remote-viewer on the server host itself and achieve network capabilities only by making use of SSH. But such a scenario sets comparison standards regarding data transfer rates. Any real client/server solution should provide advantages over such a simple approach. We come back to such comparisons in the forthcoming articles of this series.
An interesting question, for example, is whether the whole data exchange will resemble more a transfer of image data in the case of a full desktop presentation by remote-viewer or a transfer of X commands for constructing individual desktop contents. We should not forget that Spice and remote-viewer have their own handling of graphical data and a special client-server model for it.
A first disadvantage of our simple SSH-based scenario could result from the following fact:
Spice does not accept an activation for the compression of image data for a local socket-based configuration. As we start remote-viewer in our scenario on the KVM host we, therefore, cannot use the image-compression option for the Spice configuration. If a reduction of data transfer rates is required due to a limited LAN bandwidth our only chance is to use data compression for SSH. SSH uses gzip; due to extra CPU activities on both sides using compression may reduce the performance of application which exchange many data between the SSH client and server during user interactions.
In my test setup the KVM-host is controlled by an Opensuse Leap 15.2 OS, whereas the remote client system – a laptop (MyLAP) – runs Opensuse Leap 15.1. (Yes, I should have upgraded it already …).
Requirements for a reasonable performance of remote scenarios with SSH, remote-viewer and Spice
“ssh -X” is not the most efficient way of transferring graphical data. The performance experience depends a bit on the symmetric encryption algorithm and very much on the bandwidth of your network. To make a long story short:
For the QXL device temporary peaks of the data transfer rate can reach 60 MiB/s to 90 MiB/s for some window operations on a Spice console. Such rates may e.g. occur appear when you move complex and large windows quickly around with the mouse on the displayed VM’s desktop – with transparency effects of a XRender compositor being active. With the “virtio” graphics device we reach a rate of around and below 40 MBit/s.
Such rates may seem quite high – and they indeed are. But a quick test shows that you reach 25 – 45 MiB/sec already when quickly moving around a complex transparent pattern within a “Libreoffice Draw” sketch remotely over a network connection with SSH. The presentation of transparent windows within a KDE desktop with compositor dependent effects is far more complex. So Gigabit NICs are required.
If your network becomes a limiting factor you can use the “-C”-option of SSH to enable data compression. This may give you a factor between 8 and 10 for the reduction of transfer data rates. In a test
case with remote-viewer I could reduce the data transfer rate below 8 MiB/s from something of 80 MiB/s without compression. This is an impressive reduction of data.
But there is a caveat of compression, too. The compression has to happen very (!) quickly for fast user interactions with the displayed VM-desktop in the Spice windows. So, you may get a delayed response now for some fast actions on the displayed desktop due to the compression overhead. Now you need pretty fast CPU cores on the KVM/Qemu host and the remote client system! Depending on your system and your LAN I would experiment a bit with and without compression.
A first test
I use a laptop with the hostname “MyLAP” with an Opensuse Leap 15.1 installation for a quick test. The VM (with a KALI 2020.4 OS) is located on a server host “MySRV” with Opensuse Leap 15.2 (see the last articles of this series for its configuration).
On the laptop I start a KDE session as user “myself”. We have a SSH authentication key pair prepared. Our (private) key resides in “~/.ssh/id_rsa_vm”. We have exported the public key to the KVM host into the “~/.ssh/”-directory of the user “uvmb” there (probably “/home/uvmb/.ssh/”). User “uvmb” is a member of the group who got “rw”-access by ACL rules on the KVM-server to the specific UNIX socket used by our test VM “debianx” (see the previous articles).
On the KVM host a privileged user “uvma” has already started the VM “debianx” (with a local socket configuration) for us. Just to be on the safe side we open a desktop session for user “uvmb” on the KVM/Qemu” server and test remote-viewer there:
All Ok here.
Now, we move to the laptop. There we open a KDE session, too, as user “myself”. In a terminal we start the ssh-session:
myself@mylap:~/.ssh> ssh -X -i ~/.ssh/id_rsa_x uvmb@mysrv Enter passphrase for key '/home/myself/.ssh/id_rsa_x': Last login: Thu Mar 25 09:54:53 2021 from 192.168.2.22 Have a lot of fun... uvmb@mysrv:~> uvmb@mysrv:~> remote-viewer spice+unix:///var/spicex/spice.socket & [1] 5041 uvmb@mysrv:~> (remote-viewer:5041): GStreamer-WARNING **: 12:37:49.271: External plugin loader failed. This most likely means that the plugin loader helper binary was not found or could not be run. You might need to set the GST_PLUGIN_SCANNER environment variable if your setup is unusual. This should normally not be required though. (remote-viewer:5041): GSpice-WARNING **: 12:37:49.409: Warning no automount-inhibiting implementation available
We ignore the warnings – and get our two Spice windows (on the KDE desktop of the laptop).
So far so good.
Let us move a complexly structured window (Firefox or the KDE settings window with a significant size (800×800)) around on the VM’s desktop in the Spice window of the laptop, with the help of fast mouse movements. Whilst we do this we measure the data transfer rates over the relevant NIC on the KVM server:
![]()
If you enlarge the picture you see peak rates of 85 MiB/s for data sent to the SSH-client.
In my network this has, fortunately, no major effect on the interaction between laptop and the VM – no major delay or lagging behind. And due to a fast switch my wife can nevertheless stream videos over a gateway system from the Internet. 🙂
How can we explain such transfer rates? Well, the window within the Spice screen I moved around had a size of around 800×800 px. Assume a 32 Bit color depth and a refresh rate of the pixel information on the virtual screen of around 30 times a second. You can do the calculation by yourself. The data fit well to the observations. Thus, we probably transfer changed image data of the window area on the VM’s desktop.
Reducing data transfer rates by SSH integrated (gzip) compression
We end the Spice session now on the laptop (by closing the Spice windows) and log out of the SSH session. Then we restart a new SSH-session with
<pre>myself@mylap:~/.ssh> ssh -XC -i ~/.ssh/id_rsa_x uvmb@mysrv Enter passphrase for key '/home/myself/.ssh/id_rsa_x': Last login: Thu Mar 25 09:54:53 2021 from 192.168.2.22 Have a lot of fun... uvmb@mysrv:~> uvmb@mysrv:~> remote-viewer spice+unix:///var/spicex/spice.socket & [1] 5041 uvmb@mysrv:~>
Note the “C“-option for the ssh-command!
Now the measured transfer rates on the KVM-server are less than 9 MiB/s.
![]()
However, I notice some lagging of the moved windows reaction to quick mouse cursor changes on the remote client. Not, that it affects normal working – but palpable. I cross checked by working with complex figures within Libreoffice Draw – absolutely no problems with the performance there. So, the reduced responsiveness is mainly due to operations which trigger the VM’s window manager and the re-drawing of the windows as well as the desktop within the Spice induced X-window on the client-system. In our case fast mouse movements to change the position of some application windows on the displayed VM desktop quickly and erratically ….
I see the lagging also with the Gnome desktop of the Kali guest – especially, when moving transparent terminal windows. In my opinion the lagging is even more pronounced. So, KDE 5 is not so bad after all 🙂 . And then its time for optimizing via desktop settings. Remember that you can switch off a compositor totally for the KDE desktop.
I also found that the decline of responsiveness with SSH data compression also depended somewhat on the number of opened Spice “displays” or “screens” and their sizes. Responsiveness is better with just one Spice window open on the remote system. In our SSH-based scenario responsiveness depends
- on the number of virtual Spice displays,
- on the size of the moved window,
- on the complexity and to a minor degree also on transparency effects.
I could also see these dependencies for a “ssh -XC” when I exchanged the QXL device with a so called “virtio”-video-device.
Using a “virtio” video device
So far we have worked with the QXL device for a virtual graphics card device in the VM’s configuration. Let us try an alternative – namely a so called “virtio”-video-device. “virtio”-devices for virtual NICs and virtual storage devices enhance performance due to special interaction concepts with the real hardware; see the links at the bottom of this post for more information on the ideas behind virtio-drivers. Can we get a performance improvement in our scenario by a “virtio” device for the virtual graphics card?
Our configuration for the VM then, for example, looks like
<graphics
type='spice' keymap='de' defaultMode='insecure'>
<listen type='socket' socket='/var/spicex/spice.socket'/>
<image compression='off'/>
<gl enable='no'/>
</graphics>
...
...
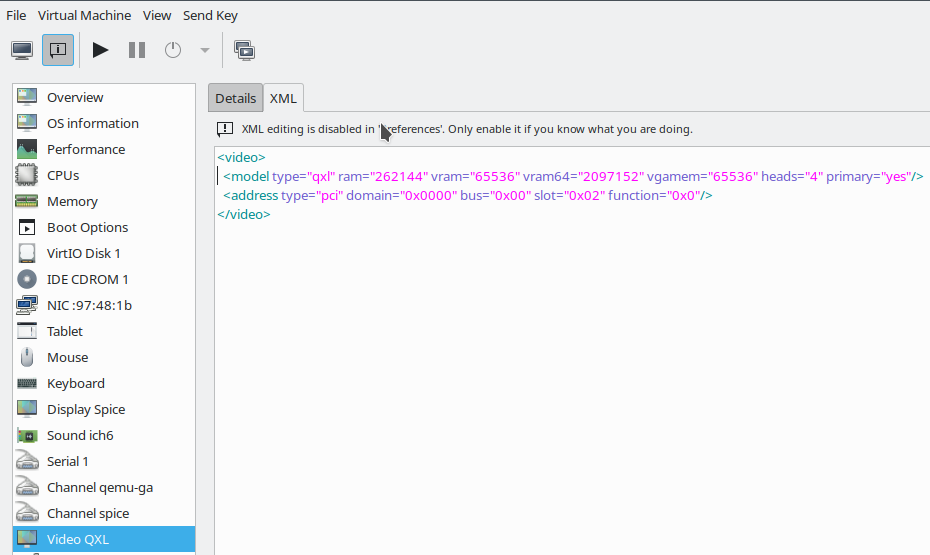
<video>
<model type='virtio' heads='2' primary='yes'>
<acceleration accel3d='yes'/>
</model>
<address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/>
</video>
...
You see that we can set multiple heads for a virtio video device, too. A big advantage is that we do not need any special memory settings as for the QXL device.
When you try this setting, you will found out that it works quite well, too. And there is a remarkable difference regarding data transfer rates:
![]()
The maximum rates for the same kind of window movements are now well below 48 MiB/s. For the same kind of fast movements of complex windows across the desktop surface in the Spice window.
Now, if you in addition use SSH compression (ssh -XC) you get the rates down to 8.2 MiB/s – but with only a slightly better responsiveness of windows to the mouse movement on the remote Spice window than for a QXL setup.
In my opinion a virtio-display device is something worth to experiment with (even without 3D acceleration).
Libreoffice Draw as a real world test case
Let us briefly compare data rates for something more realistic in daily work.
In the tests described below I firstly open Libreoffice [LO] Draw by a direct “ssh -X” call to the VM itself. Then I open LO Draw within the remotely displayed desktop of the VM based on a “SSH -X” connection to the KVM server. This means a major difference regarding the SSH connection and the data transfer requests!
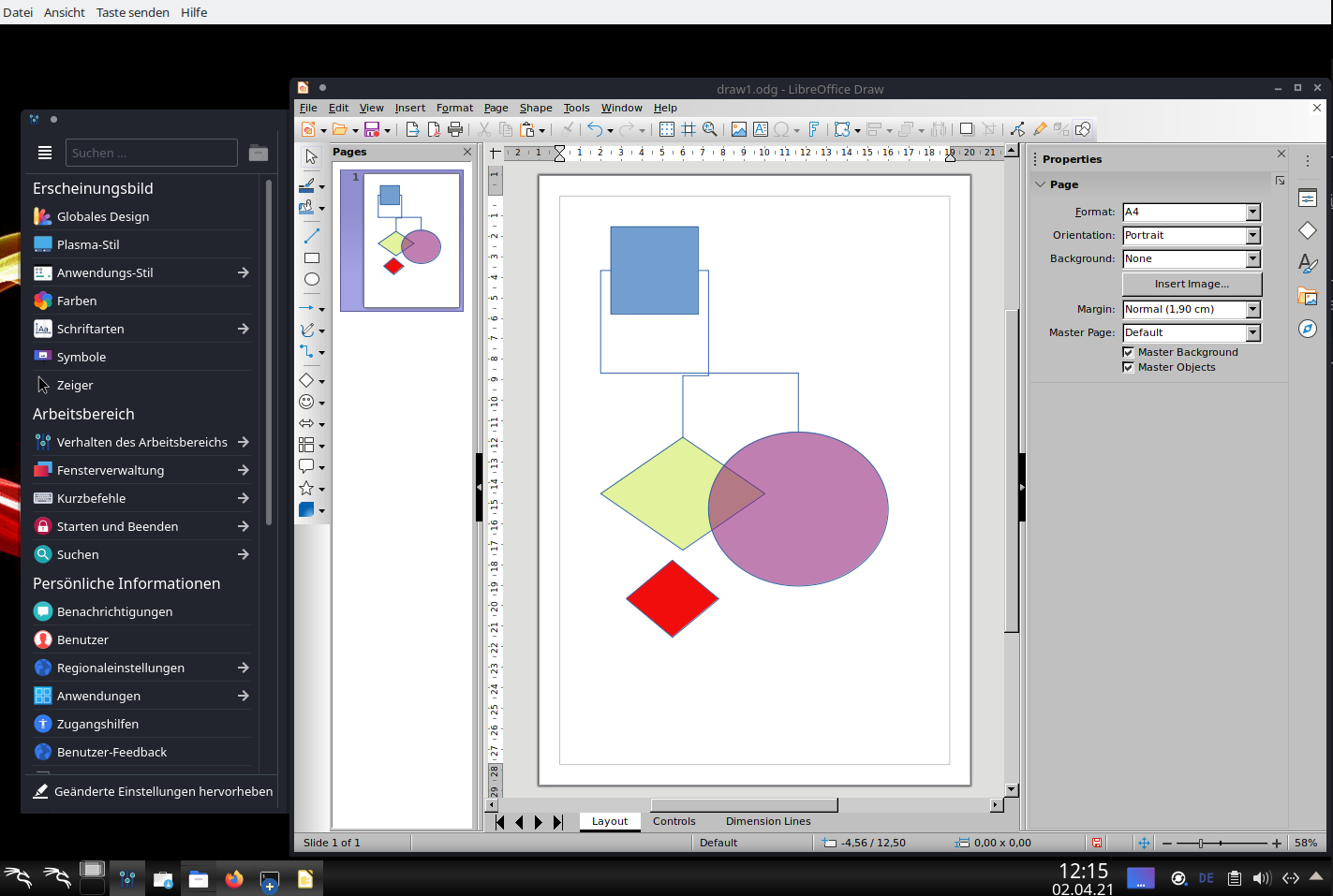
Within LO Draw I use a sketch like the following
![]()
and, later on, move the green or violet figures very fast around in the LO frame with the mouse. Transparency included.
So, for a first test, let us open the VM’s LO Draw on my laptop MyLAP via a direct “ssh -X” command (without data compression!) directed to the VM:
<pre>myself@mylap:~/.ssh> ssh -X -i ~/.ssh/id_rsa_x myself@debianx Enter passphrase for key '/home/myself/.ssh/id_rsa_x': Linux debianx 5.10.0-kali3-amd64 ...... ...... Last login: Fri Mar 26 17:38:16 2021 from 192.168.2.22 ... myself@debianx:~> myself@debianx:~$ libreoffice --draw
Note that “debianx” is now used as a host name! (The host name was chosen to be the same as the name of the VM in virt-manager; but the meaning in a network context, where “debianx” must be resolved to an IP, is now different. Note that the VM communicates to the outside world via a virtual network of the KVM host and routes defined on the VM and the KVM host directing data from the VM in the end over some NIC of the KVM host).
When moving the drawing’s figures around I measure data transfer rates on the relevant Ethernet device of the KVM-server:
![]()
Taking sent and received data together we have total rates around 25 MiB/s.
Now, in a second test, let us do something very different: We open Libreoffice Draw on the VM’s KDE desktop displayed in a Spice window, which in turn got transferred via SSH to the X11-service on my laptop:
And, again, we move the figures around very fast. The measured rates then are significantly smaller – below 4.4 MiB/s.
![]()
This proves the following statement which in turn justifies the whole Spice approach:
It may be more efficient to work remotely with a VM application on the VM’s desktop via Spice and a “SSH -X” connection to the KVM-server than requesting the graphical output of the VM’s application directly via “SSH -X” from the VM itself!
And what about sound?
We now turn to a topic which also deserves more documentation – namely the handling of sound with a remote solution like ours. We need Pulseaudio for a transfer of sound data from a VM (on the KVM/Qemu server) to the remote client system. Well, the very same Pulseaudio [PA] which often enough has ruined some of my nerves as a Linux user in the past 12 years or so. In combination with remote-viewer we simply cannot avoid it.
To be able to understand its configuration in a network with Opensuse Leap systems we must deal with the server properties of PA. See e.g. the following links for some explanation:
Free desktop Org documentation on Pulseaudio in a network
Archlinux documentation on PulseAudio
A Pulseaudio installation can work as a daemon-based service for other client-applications than the ones started locally during the desktop session of a user. Such clients can be applications started on other computers. PA’s client/server structure has network capabilities! To use PA in a network context some requirements must be fulfilled:
- The module “module-native-protocol-tcp ” must be loaded. On a standard Opensuse Leap system this is the case; see the settings in the files “/etc/pulse/default.pa” and for a specific user in “~/.config/pulse/default.pa“.
- For a direct connection between two PCs, as we need it for our present purpose, we can use a special TCP-port. The standard port is “4713“. For some first tests we will open this port for a directed transfer from the server to the client on local firewalls of the systems as well as on firewalls in between. But later we will rather integrate the port handling into our SSH tunnel.
- The PA service must be told to accept remote connections over TCP. We can use the “paprefs” application for it.
- We may require some form of authentication to grant access. We move this point to SSH by opening a remote tunnel – so we can forget about this point.
To get some information about
what is playing where during the next steps it is useful to have the applications “pavucontrol” (pulseaudio volume control) and “paman” (pulseaudio manager) running. You find the relevant packets in the standard Update Repository of your Leap distribution. The packet “qemu-audio-pa” should be installed, too, if it is not yet present on your system.
Where is sound of the VM played if we do nothing?
The funny thing about sound in our remote scenario with SSH and a Unix socket on the KVM host is the following:
When we start remote-viewer on the KVM-server in our scenario without any special measures for audio, we will see the graphical output on the remote client, but hear the sound on the speaker system of the server (if it has any). Well, in my test scenario the “server” has such an equipment.
well, let us start some sounds via the Spice windows on the client “MyLAP”. In the above images you saw that I had opened a directory with KDE sound files. Whilst we play them (e.g. with the parole player) we can at the same time have a look at the pavucontrol window on the KDE desktop of user “uvmb” on the server “MySRV”:
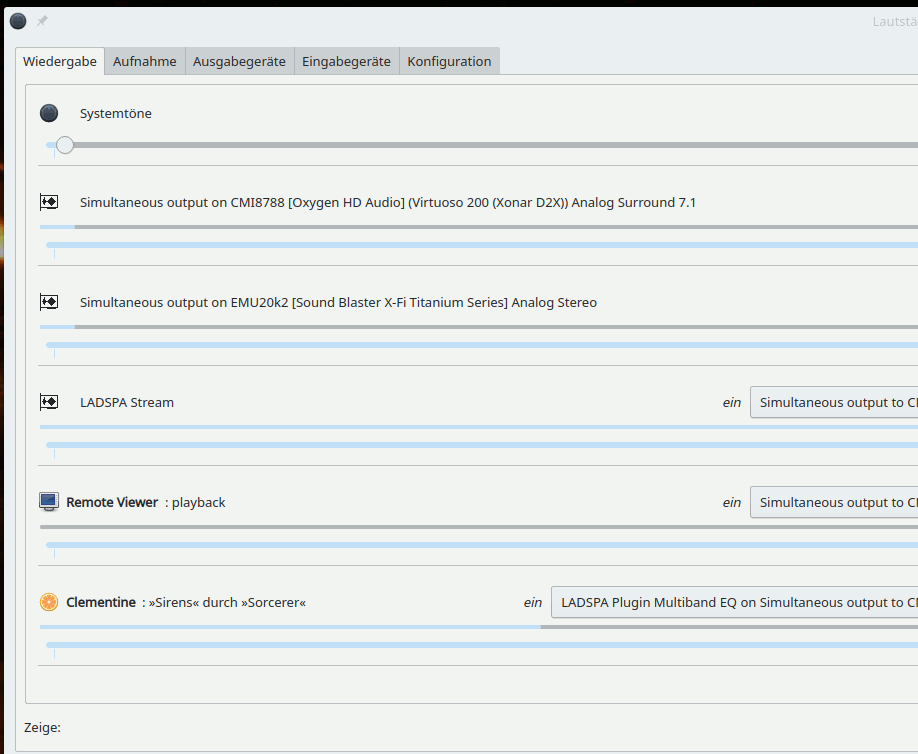
If you enlarge the image you see a PA-client there with the name “Remote Viewer”. This is not too astonishing as we had started remote-viewer on the KVM server and not on the remote laptop. And as a default remote-viewer interacts with the active PA on the system where remote-viewer itself is running:
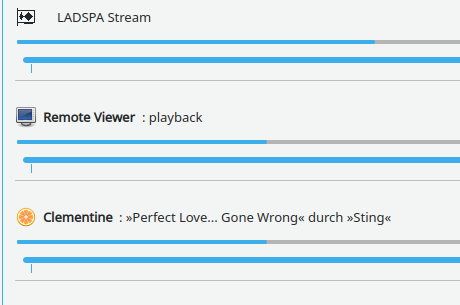
Well this might be okay if the client and the server are in the same room. But if you had moved with your laptop into another room you, of course, would like to hear the sound on your laptop’s speakers. To achieve this we have to redirect the audio data stream of an application of the VM to a remote PA service.
How do we transfer sound from a SSH-server to the PA-system on the client during a SSH session?
I assume now that port 4713 is open on all firewalls. Still we have to prepare the PA-service on the remote client system – here on our laptop “MyLAP”.
For this purpose we open “paprefs” on MyLAP (NOT in the VM displayed in the Spice windows there, but in a standard terminal window of MyLAP’s desktop):
myself@mylap:~> paprefs
we turn to the tab “network server” and activate the following options:

Your laptop (the SSH- and Spice-client) is then able to work as a sound-server within the LAN.
Do not worry too much about the deactivated authentication. You can control in your firewall settings which system gets access – and later on we shall close port 4713 completely again for remote access by restrictive firewall rules. (If you really need authentication you must copy the cookie under “~/.config/pulse/cookie” from your laptop onto the server and uvmb’s folder structure.)
But now: How, do we tell an application started on the KVM-server to direct its audio output to the PA server on the laptop? Well, this is controlled by an environment variable “PULSE_SERVER”; see the documentation mentioned above about this.
You
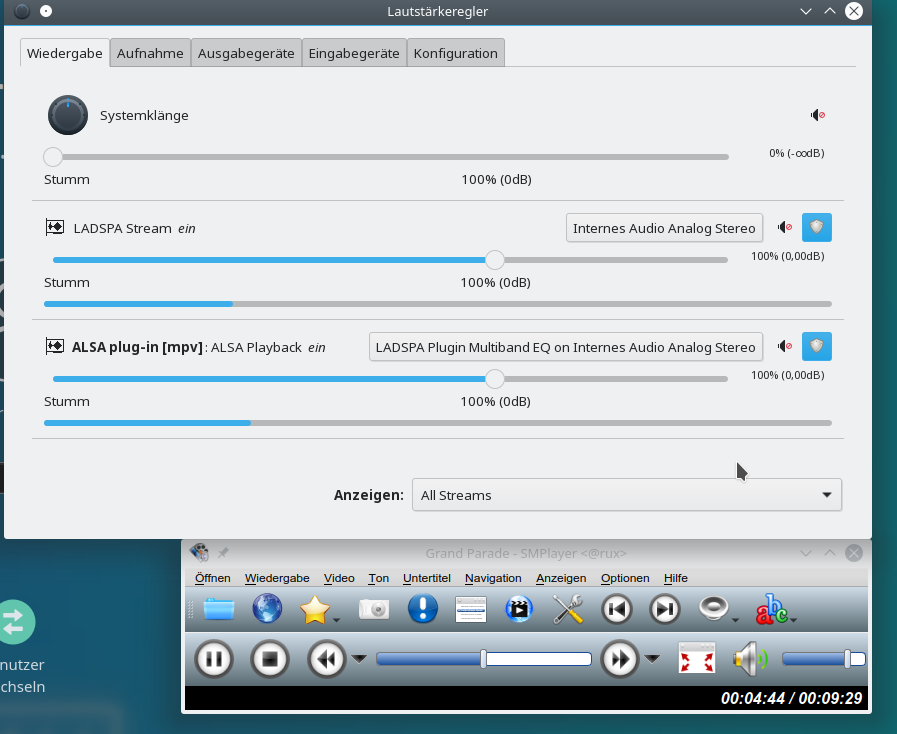
can easily test this by opening a “ssh -X” connection from your remote system to an SSH server and redirect the audio output of an application like smplayer to the PA on your remote system. In my case:
<pre>myself@mylap:~/.ssh> ssh -X -i ~/.ssh/id_rsa_x uvmb@mysrv Enter passphrase for key '/home/myself/.ssh/id_rsa_x': Last login: Thu Mar 25 09:54:53 2021 from 192.168.2.22 Have a lot of fun... uvmb@mysrv:~> uvmb@mysrv:~> env PULSE_SERVER=192.168.2.22 smplayer & [1] 5041 uvmb@mysrv:~>
Any sound played with smplayer is now handled by the PA on the laptop. See the screenshot from the laptop:
Now, we can of course do the same with our remote-viewer:
<pre>myself@mylap:~/.ssh> ssh -X -i ~/.ssh/id_rsa_x uvmb@mysrv Enter passphrase for key '/home/myself/.ssh/id_rsa_x': Last login: Thu Mar 25 09:54:53 2021 from 192.168.2.22 Have a lot of fun... uvmb@mysrv:~> uvmb@mysrv:~> env PULSE_SERVER=192.168.2.22 remote-viewer spice+unix:///var/spicex/spice.socket & [1] 5041 uvmb@mysrv:~>
You should hear any sound played with an audio application within the VM on the remote system (in my case on the laptop MyLAP):
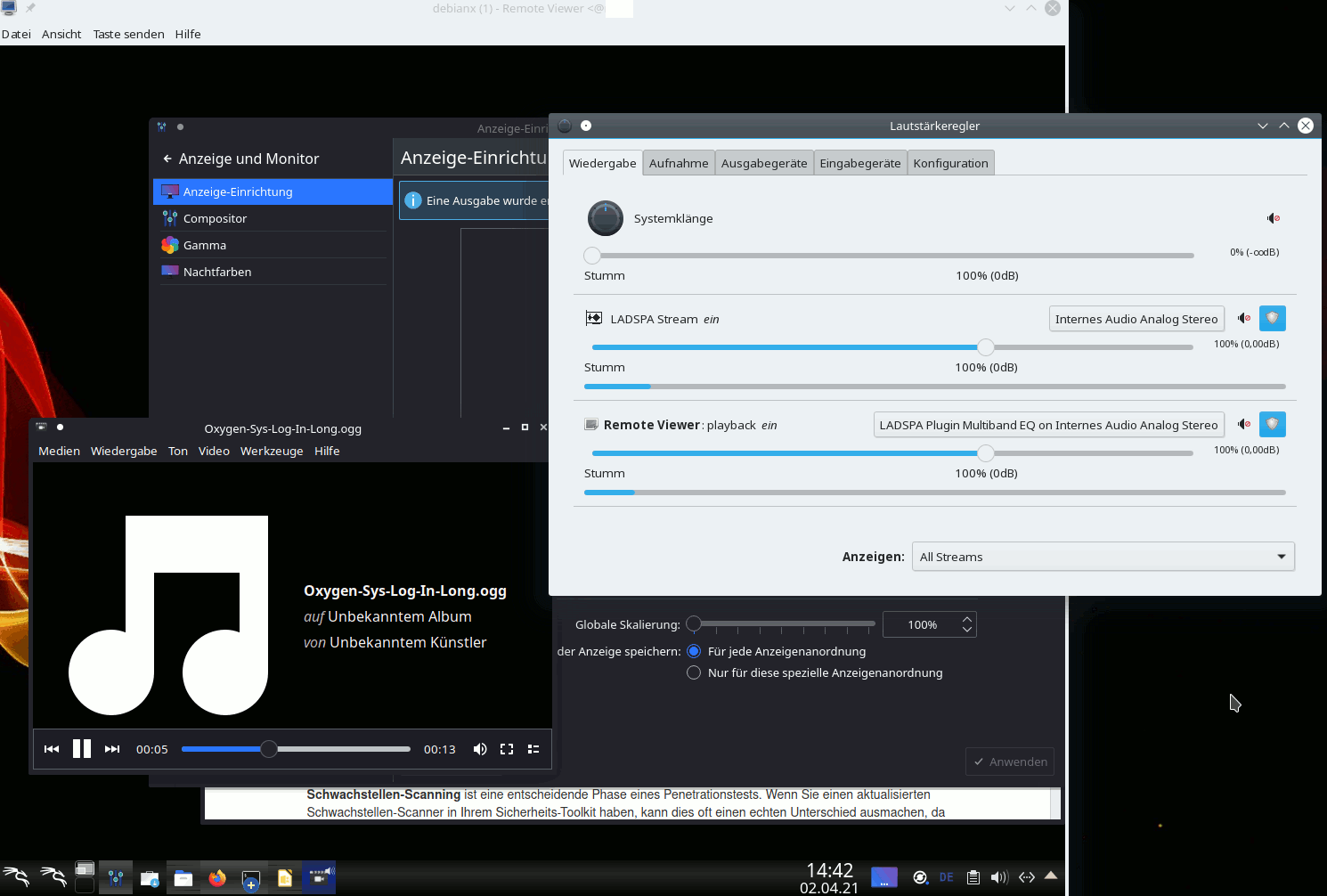
Isn’t it fun?
Remote SSH tunnel and port forwarding for the transfer of audio data
Ok, we have a sound transfer – but not encrypted. This can – dependent on your audio applications – be a security hole. In addition we lack control over the users who may access our PA-server on the remote system. To cover both problems we are going now to make use of the full power of SSH. We open a reverse SSH tunnel with port forwarding from some arbitrarily chosen port on the KVM/Qemu server to port 4713 on the laptop:
<pre>myself@mylap:~/.ssh> ssh -X -R 44713:localhost:4713 -i ~/.ssh/id_rsa_x uvmb@mysrv Enter passphrase for key '/home/myself/.ssh/id_rsa_x': Last login: .... from 192.168.2.22 Have a lot of fun... uvmb@mysrv:~> uvmb@mysrv:~> env PULSE_SERVER=tcp:localhost:44713 remote-viewer spice+unix:///var/spicex/spice.socket & [1] 5041 uvmb@mysrv:~>
You see the difference? We direct the audio output of remote-viewer on the KVM-host to port 44713 – and SSH does the rest for us via port-forwarding (plus encryption). (Control question: Which system does “localhost” in the SSH statement refer to? The laptop or the KVM/Qemu server?)
The result of this sound redirection looks, of course, the same on pavucontrol on our remote client system as before.
We now can close the port 4713 by some suitable firewall rule on our client system for any external access. Due to SSH port forwarding we only access the port locally there. You can even pin it on the “lo”-device with the SSH command. Read about it on the Internet.
The additional overhead of the audio data transfer is minimal in comparison to the video data transfer triggered by window manager operations:
![]()
We speak about some 600 KiB/s for some stereo sound.
To make things complete –
here are the data transfer rates for high resolution Live TV video streaming from the VM on the KVM-server over “SSH -X” to the remote client (without data compression):
![]()
You see: Its Easter time! Old Hollywood movies are running on German TV …
Conclusion
The method to access the Spice console of a VM with remote-viewer and via a Unix socket locally on the KVM host enabled a first secure remote scenario by simply redirecting the graphical data stream from the KVM-server to a remote X-window service with “SSH -X”.
The combination with a virtio-video device proved to deliver a relatively small peak data transfer rate around 45 MiB/s for complex window operations requiring a fast redraw of major parts of the desktop in the remote Spice windows. Without SSH data compression we got a very good responsiveness of complex windows to fast movements induced by the mouse cursor on the remotely displayed desktop of the VM. We saw that we could reduce the resulting data transfer rates below 9 MiB/s by using SSH data compression. However, this had some negative impact on the felt responsiveness of operations triggering the window manager of the VM’s graphical desktop.
However, working with graphical applications like Libreoffice Draw on the remotely displayed desktop of the VM via Spice and SSH required substantially smaller transfer rates than in a scenario where we requested a display of the application by a direct “ssh-X” connection to the VM itself.
I have shown in addition that we can easily transfer the sound created by audio applications within the VM via a remote SSH tunnel and port forwarding to the Pulseaudio server on the remote client system.
In the next article of this series we are preparing a TLS based remote solution for accessing the Spice console of a VM.
Links
SSH with compression
https://www.xmodulo.com/how-to-speed-up-x11-forwarding-in-ssh.html?format=pdf
SSH with Pulseaudio
https://askubuntu.com/questions/371687/how-to-carry-audio-over-ssh